前言
CNN(Convolutional Neural Network,卷积神经网络)是一种深度学习模型,特别适用于处理图像数据。它通过多层卷积和池化层来提取图像的特征,并通过全连接层进行分类或回归等任务。CNN在图像识别、目标检测、图像分割等领域取得了很大的成功。
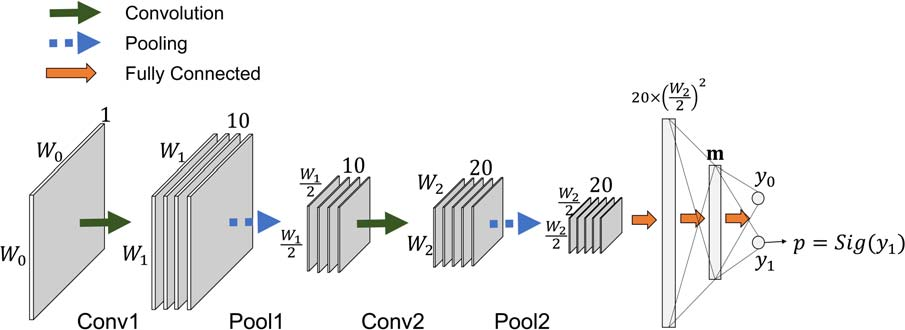
CNN网络结构
目标分类是指识别图像中的物体,并将其归类到不同的类别中。例如,猫狗分类就是一个目标分类的任务,CNN可以帮助我们构建一个模型来自动识别图像中的猫和狗。
如何入门CNN
要入门CNN,可以先了解深度学习的基本概念和原理,然后学习如何构建和训练CNN模型。可以选择一些经典的教材、在线课程或者教程来学习深度学习和CNN的基础知识。
实战案例分析
以下是一个简单的使用PyTorch构建CNN模型的示例代码:
1、导包
from PIL import Image
import torch
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, random_split, Dataset
from torchvision import datasets, models
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
from tqdm import tqdm2、设置数据集目录
# Setting the data directories/ paths
data_pth = '/你的数据集目录'
cats_dir = data_pth + '/Cat'
dogs_dir = data_pth + '/Dog'3、打印图像的数量
print("Total Cats Images:", len(os.listdir(cats_dir)))
print("Total Dogs Images:", len(os.listdir(dogs_dir)))
print("Total Images:", len(os.listdir(cats_dir)) + len(os.listdir(dogs_dir)))4、查看Cat数据
cat_img = Image.open(cats_dir + '/' + os.listdir(cats_dir)[0])
print('Shape of cat image:', cat_img.size)
cat_img5、查看Dog的数据
dog_img = Image.open(dogs_dir + '/' + os.listdir(dogs_dir)[0])
print('Shape of dog image:', dog_img.size)
dog_img6、自定义加载数据集方法
class CustomDataset(Dataset):
def __init__(self, data_path, transform=None):
# Initialize your dataset here
self.data = data
self.transform = transform
def __len__(self):
# Return the number of samples in your dataset
return len(self.data)
def __getitem__(self, idx):
# Implement how to get a sample at the given index
sample = self.data[idx]
try:
img = Image.open(data_pth + '/Cat/' + sample)
label = 0
except:
img = Image.open(data_pth + '/Dog/' + sample)
label = 1
# Apply any transformations (e.g., preprocessing)
if self.transform:
img = self.transform(img)
return img, label7、定义数据转换(调整大小、规格化、转换为张量等)
在训练目标分类模型时,我们通常会使用转换数据来对输入数据进行预处理,以便更好地适应模型的训练和提高模型的性能。
使用转换数据的原因包括:
-
调整大小:输入数据通常具有不同的尺寸和分辨率,为了确保模型能够处理这些不同尺寸的数据,我们需要将其调整为统一的大小。这样可以确保模型在训练和预测时能够处理相同大小的输入数据。
-
规格化:规格化是指将输入数据的数值范围调整到相似的范围,以便更好地适应模型的训练。规格化可以帮助模型更快地收敛,提高模型的稳定性和准确性。
-
转换为张量:在深度学习中,输入数据通常需要转换为张量形式,以便与神经网络模型进行计算。因此,我们需要将输入数据转换为张量形式,以便能够输入到模型中进行训练和预测。
总之,转换数据是为了确保模型能够更好地适应输入数据,并提高模型的性能和准确性。通过调整大小、规格化和转换为张量等操作,我们可以更好地准备输入数据,使其更适合用于训练目标分类模型。
# Define the data transformation (resize, normalize, convert to tensor, etc.)
transform = transforms.Compose([
transforms.Resize((224, 224)), # Resize images to a fixed size (adjust as needed)
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor(), # Convert images to PyTorch tensors
])
data = [i for i in os.listdir(data_pth + '/Cat') if i.endswith('.jpg')] + [i for i in os.listdir(data_pth + '/Dog') if i.endswith('.jpg')]
combined_dataset = CustomDataset(data_path=data, transform=transform)
#dataloader = torch.utils.data.DataLoader(custom_dataset, batch_size=64, shuffle=False)8、定义拆分比例(例如,80%用于培训,20%用于测试)
# Define the ratio for splitting (e.g., 80% for training, 20% for testing)
train_ratio = 0.8
test_ratio = 1.0 - train_ratio
# Calculate the number of samples for training and testing
num_samples = len(combined_dataset)
num_train_samples = int(train_ratio * num_samples)
num_test_samples = num_samples - num_train_samples
# Use random_split to split the dataset
train_dataset, test_dataset = random_split(combined_dataset, [num_train_samples, num_test_samples])
# Create data loaders for training and testing datasets
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)9、自定义CNN模型
# Define the CNN model
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 8, kernel_size=3, stride=2),
nn.MaxPool2d(2, 2),
nn.ReLU(),
nn.Conv2d(8, 16, kernel_size=3, stride=2),
nn.MaxPool2d(2, 2),
nn.ReLU(),
nn.Conv2d(16, 32, kernel_size=3, stride=2),
nn.MaxPool2d(2, 2),
nn.ReLU(),
)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(288, 128),
nn.ReLU(),
nn.Linear(128, 1),
nn.Sigmoid()
)
def forward(self, x):
x = self.conv(x)
x = self.fc(x)
return x10、GPU是否可用
# check if gpu is available or not
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)11、初始化模型、损失函数和优化器
训练过程中的关键步骤,其重要性如下:
-
初始化模型:模型的初始化是指对模型参数进行初始赋值。正确的初始化可以加速模型的收敛,提高训练的效率和稳定性。如果模型参数的初始值过大或过小,可能会导致梯度爆炸或梯度消失,从而影响模型的训练效果。
-
损失函数:损失函数是用来衡量模型预测结果与真实标签之间的差距。选择合适的损失函数可以帮助模型更好地学习数据的特征,并且在训练过程中不断优化模型参数,使得损失函数值逐渐减小。
-
优化器:优化器是用来更新模型参数的算法,常见的优化器包括随机梯度下降(SGD)、Adam、RMSprop等。选择合适的优化器可以加速模型的收敛,提高训练的效率和稳定性。不同的优化器有不同的更新规则,可以根据具体的任务和数据特点选择合适的优化器。
因此,初始化模型、损失函数和优化器是CNN训练过程中的关键步骤,它们的选择和设置会直接影响模型的训练效果和性能。
# Initialize the model, loss function, and optimizer
net = CNN().to(device)
criterion = nn.BCELoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)12 、开始训练数据
epochs = 5
net.train()
for epoch in range(epochs):
running_loss = 0.0
for idx, (inputs, labels) in tqdm(enumerate(train_loader), total=len(train_loader)):
inputs = inputs.to(device)
labels = labels.to(device).to(torch.float32)
optimizer.zero_grad()
outputs = net(inputs).reshape(-1)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch: {epoch + 1}, Loss: {running_loss}')
print('Training Finished!')13、验证数据
net.eval() # Set the model to evaluation mode
correct = 0
total = 0
with torch.no_grad():
for idx, (inputs, labels) in tqdm(enumerate(test_loader), total=len(test_loader)):
inputs = inputs.to(device)
labels = labels.to(device).to(torch.float32)
outputs = net(inputs).reshape(-1)
predicted = (outputs > 0.5).float() # Assuming a binary classification threshold of 0.5
correct += (predicted == labels).sum().item()
total += labels.size(0)
accuracy = correct / total if total > 0 else 0.0
print(f'Test Accuracy: {accuracy:.2%}')14、测试数据
label_names = ['cat', 'dog']
fig, ax = plt.subplots(1, 5, figsize=(15, 5))
outputs = outputs.cpu()
inputs = inputs.cpu()
labels = labels.cpu()
for i in range(5):
ax[i].imshow(inputs[i].permute(1,2,0))
ax[i].set_title(f'True: {label_names[labels[i].to(int)]}, Pred: {label_names[torch.where(outputs[i] > 0.5, 1, 0).item()]}')
ax[i].axis(False)
plt.show()至此,一个CNN训练模型从搭建到测试的完整实现过程就完成了,我们使用了PyTorch构建了一个简单的CNN模型,并使用猫狗分类的训练数据对模型进行训练。首先准备了训练数据集,然后构建了一个简单的CNN模型,定义了损失函数和优化器,最后进行了模型的训练。
数据集训练完整代码
from PIL import Image
import torch
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, random_split, Dataset
from torchvision import datasets, models
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
from tqdm import tqdm
data_pth = '/你的数据集目录'
cats_dir = data_pth + '/Cat'
dogs_dir = data_pth + '/Dog'
cat_img = Image.open(cats_dir + '/' + os.listdir(cats_dir)[0])
dog_img = Image.open(dogs_dir + '/' + os.listdir(dogs_dir)[0])
#定义加载数据集方法
class CustomDataset(Dataset):
def __init__(self, data_path, transform=None):
# Initialize your dataset here
self.data = data
self.transform = transform
def __len__(self):
# 返回数据集数量
return len(self.data)
def __getitem__(self, idx):
# 获取数据集对应的下标
sample = self.data[idx]
try:
img = Image.open(data_pth + '/Cat/' + sample)
label = 0
except:
img = Image.open(data_pth + '/Dog/' + sample)
label = 1
if self.transform:
img = self.transform(img)
return img, label
transform = transforms.Compose([
transforms.Resize((224, 224)), # Resize images to a fixed size (adjust as needed)
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor(), # Convert images to PyTorch tensors
])
data = [i for i in os.listdir(data_pth + '/Cat') if i.endswith('.jpg')] + [i for i in os.listdir(data_pth + '/Dog') if i.endswith('.jpg')]
combined_dataset = CustomDataset(data_path=data, transform=transform)
#划分数据集
train_ratio = 0.8
test_ratio = 1.0 - train_ratio
# Calculate the number of samples for training and testing
num_samples = len(combined_dataset)
num_train_samples = int(train_ratio * num_samples)
num_test_samples = num_samples - num_train_samples
# Use random_split to split the dataset
train_dataset, test_dataset = random_split(combined_dataset, [num_train_samples, num_test_samples])
# Create data loaders for training and testing datasets
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
#自定义CNN模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 8, kernel_size=3, stride=2),
nn.MaxPool2d(2, 2),
nn.ReLU(),
nn.Conv2d(8, 16, kernel_size=3, stride=2),
nn.MaxPool2d(2, 2),
nn.ReLU(),
nn.Conv2d(16, 32, kernel_size=3, stride=2),
nn.MaxPool2d(2, 2),
nn.ReLU(),
)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(288, 128),
nn.ReLU(),
nn.Linear(128, 1),
nn.Sigmoid()
)
def forward(self, x):
x = self.conv(x)
x = self.fc(x)
return x
#GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#初始化模型、损失函数和优化器
net = CNN().to(device)
criterion = nn.BCELoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
#开始训练
epochs = 5
net.train()
for epoch in range(epochs):
running_loss = 0.0
for idx, (inputs, labels) in tqdm(enumerate(train_loader), total=len(train_loader)):
inputs = inputs.to(device)
labels = labels.to(device).to(torch.float32)
optimizer.zero_grad()
outputs = net(inputs).reshape(-1)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch: {epoch + 1}, Loss: {running_loss}')
print('Training Finished!')数据集下载
百度网盘:https://pan.baidu.com/s/1CjTNLGvBBDxmKEADN3SNWw?pwd=o37e
提取码:o37e