连接器
- Table API & SQL连接器
- 1.概述
- 2.支持连接器
- DataGen连接器
- 1.概述
- 2.SQL客户端执行
- 3.Table API执行
- FileSystem连接器
- 1.创建FileSystem映射表
- 2.创建source数据源表
- 3.写入数据
- 4.解决异常
- 5.查询fileTable
- 6.查看HDFS
- Kafka连接器
- 1.添加kafka连接器依赖
- 2.重启yarn-session、sql-client
- 3.创建Kafka映射表
- 4.创建source数据源表
- 5.插入Kafka表
- 6.查询Kafka表
- Upsert Kafka连接器
- 1.添加kafka连接器依赖
- 2.重启yarn-session、sql-client
- 3.创建upsert-kafka的映射表
- 4.创建source数据源表
- 5.插入upsert-kafka表
- 6.查询upsert-kafka表
- JDBC连接器
- 1.添加JDBC连接器依赖
- 2.重启flink集群和sql-client
- 3.创建JDBC表
- 4.创建JDBC映射表
- 5.写入数据
- 6.查询数据
- MongoDB连接器
- 1.添加依赖
- 2.示例
- 3.验证
- Elasticsearch连接器
- 1.添加依赖
- 2.示例
- 3.验证
Table API & SQL连接器
1.概述
Flink的Table API 和 SQL 程序可以连接到其他外部系统,以读写批处理和流式表。表源提供对存储在外部系统(例如数据库、键值存储、消息队列或文件系统)中的数据的访问。表接收器将表发送到外部存储系统。根据源和接收器的类型,它们支持不同的格式,例如CSV、Avro、Parquet 或 ORC。
2.支持连接器
Flink原生支持各种连接器,以下是所有可用的连接器。
| 名称 | 版本 | 数据源 | 数据接收器 |
|---|---|---|---|
| 文件系统 | 有界和无界扫描 | 流式接收器,批处理接收器 | |
| Elasticsearch | 6.x & 7.x | 不支持 | 流式接收器,批处理接收器 |
| Opensearch | 1.x & 2.x | 不支持 | 流式接收器,批处理接收器 |
| Apache Kafka | 0.10+ | 无界扫描 | 流式接收器,批处理接收器 |
| Amazon DynamoDB | 不支持 | 流式接收器,批处理接收器 | |
| Amazon Kinesis Data Streams | 无界扫描 | 流式接收器 | |
| Amazon Kinesis Data Firehose | 不支持 | 流式接收器 | |
| JDBC | 有界扫描,查找 | 流式接收器,批处理接收器 | |
| Apache HBase | 1.4.x & 2.2.x | 有界扫描,查找 | 流式接收器,批处理接收器 |
| Apache Hive | 支持的版本 | 无界扫描,有界扫描,查找 | 流式接收器,批处理接收器 |
| MongoDB | 有界扫描,查找 | 流式接收器,批处理接收器 |
注意:这些连接器可以使用FlinkTable API操作,也可以使用Flink SQL客户端操作。
DataGen连接器
1.概述
DataGen 连接器允许按数据生成规则进行读取。
每个列,都有两种生成数据的方法:
1.随机生成器:
默认的生成器,您可以指定随机生成的最大和最小值。char、varchar、binary、varbinary, string (类型)可以指定长度。它是无界的生成器。
2.序列生成器:
可以指定序列的起始和结束值。它是有界的生成器,当序列数字达到结束值,读取结束。
连接器参数说明:
| 参数 | 描述 |
|---|---|
| connector | 参数必须,指定要使用的连接器,这里是 ‘datagen’ |
| rows-per-second | 可选参数,默认值10000,每秒生成的行数,用以控制数据发出速率 |
| fields.#.kind | 可选参数,默认值random,指定 ‘#’ 字段的生成器。可以是 ‘sequence’ 或 ‘random’ |
| fields.#.min | 可选参数随机生成器的最小值,适用于数字类型 |
| fields.#.max | 可选参数随机生成器的最大值,适用于数字类型 |
| fields.#.length | 可选参数,默认值100,随机生成器生成字符的长度,适用于 char、varchar、binary、varbinary、string |
| fields.#.start | 可选参数,序列生成器的起始值 |
| fields.#.end | 可选参数,序列生成器的结束值 |
2.SQL客户端执行
在 Flink SQL客户端中创建DataGen表
Flink SQL> CREATE TABLE datagen (
id INT,
name STRING,
age INT,
ts AS localtimestamp,
WATERMARK FOR ts AS ts
) WITH (
'connector' = 'datagen',
'rows-per-second'='5',
'fields.f_sequence.kind'='sequence',
'fields.id.start'='1',
'fields.id.end'='50',
'fields.age.min'='1',
'fields.age.max'='150',
'fields.name.length'='10'
)
查询表
Flink SQL> show tables;
+------------+
| table name |
+------------+
| datagen |
+------------+
1 row in set
执行查询
Flink SQL> select * from datagen;
+----+-------------+--------------------------------+-------------+
| op | id | name | age |
+----+-------------+--------------------------------+-------------+
| +I | 1 | f82aac1d2e | 97 |
| +I | 2 | 09bc2c62a6 | 75 |
| +I | 3 | 9e3e0cca2f | 146 |
| +I | 4 | 05bca80edc | 61 |
| +I | 5 | 93bfca82f7 | 54 |
3.Table API执行
使用Table API操作,需要引入相关依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!--负责Table API和下层DataStream API的连接支持-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
</dependency>
<!--在本地的集成开发环境里运行Table API和SQL的支持-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-loader</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
</dependency>
在程序中通过Table API操作DataGen SQL连接器
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 创建表
tableEnv.executeSql("CREATE TABLE datagen (\n" +
" id INT,\n" +
" name STRING,\n" +
" age INT,\n" +
" ts AS localtimestamp,\n" +
" WATERMARK FOR ts AS ts\n" +
") WITH (\n" +
" 'connector' = 'datagen',\n" +
" 'rows-per-second'='5',\n" +
" 'fields.id.kind'='sequence',\n" +
" 'fields.id.start'='1',\n" +
" 'fields.id.end'='50',\n" +
" 'fields.age.min'='1',\n" +
" 'fields.age.max'='150',\n" +
" 'fields.name.length'='10'\n" +
");");
// 执行查询
tableEnv.executeSql("show tables;").print();
Table select = tableEnv.from("datagen").select($("id"), $("name"), $("age"));
// 打印
select.execute().print();
}
控制台执行结果如下:
+------------+
| table name |
+------------+
| datagen |
+------------+
1 row in set
+----+-------------+--------------------------------+-------------+
| op | id | name | age |
+----+-------------+--------------------------------+-------------+
| +I | 1 | f82aac1d2e | 97 |
| +I | 2 | 09bc2c62a6 | 75 |
| +I | 3 | 9e3e0cca2f | 146 |
| +I | 4 | 05bca80edc | 61 |
FileSystem连接器
文件系统连接器,不需要添加额外的依赖。相应的 jar 包可以在 Flink 工程项目的 /lib 目录下找到。从文件系统中读取或者向文件系统中写入行时,需要指定相应的 format。
1.创建FileSystem映射表
文件系统连接器允许从本地或分布式文件系统进行读写。文件系统表可以定义为:
CREATE TABLE fileTable( id int, name string, age int )
WITH (
'connector' = 'filesystem',
'path' = 'hdfs://node01:9000/flink/fileTable',
'format' = 'json'
);
2.创建source数据源表
CREATE TABLE datagen (
id INT,
name string,
age INT
) WITH (
'connector' = 'datagen',
'rows-per-second'='5',
'fields.id.kind'='sequence',
'fields.id.start'='1',
'fields.id.end'='1000',
'fields.age.min'='1',
'fields.age.max'='100',
'fields.name.length'='10'
);
3.写入数据
Flink SQL> insert into fileTable select * from datagen;
[ERROR] Could not execute SQL statement. Reason:
java.lang.ClassNotFoundException: org.apache.flink.table.planner.delegation.DialectFactory
4.解决异常
在执行插入操作出现如下异常:
[ERROR] Could not execute SQL statement. Reason:
java.lang.ClassNotFoundException: org.apache.flink.table.planner.delegation.DialectFactory
解决方案有两种:
1.由于flink/lib目录下存在flink-sql-connector-hive-2.3.9_2.12-1.17.0.jar导致,因此删除该Jar包
mv lib/flink-sql-connector-hive-2.3.9_2.12-1.17.0.jar lib/flink-sql-connector-hive-2.3.9_2.12-1.17.0.jar.back
重启Flink与SQL客户端,然后执行
Flink SQL> insert into fileTable select * from datagen;
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: c449c029599125c92da98514b512b0de
2.更换flink/lib目录下的flink-table-planner-loader-1.17.0.jar
通常会使用flink-sql-connector-hive连接器,所以不可能任意删除的,故先恢复
mv lib/flink-sql-connector-hive-2.3.9_2.12-1.17.0.jar.back lib/flink-sql-connector-hive-2.3.9_2.12-1.17.0.jar
注意:只有在使用Hive方言或HiveServer2时需要移动Jar操作,是Hive集成的推荐设置。
[root@node01 flink]# mv lib/flink-table-planner-loader-1.17.0.jar opt/
[root@node01 flink]# mv opt/flink-table-planner_2.12-1.17.0.jar lib/
重启Flink与SQL客户端,然后执行
Flink SQL> insert into fileTable select * from datagen;
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 7a2bc2fcb7407cec33530fb086f4242f
5.查询fileTable
Flink SQL> select * from fileTable where id=1;
+----+-------------+--------------------------------+-------------+
| op | id | name | age |
+----+-------------+--------------------------------+-------------+
| +I | 1 | 6a296add45 | 8 |
+----+-------------+--------------------------------+-------------+
Received a total of 1 row
6.查看HDFS
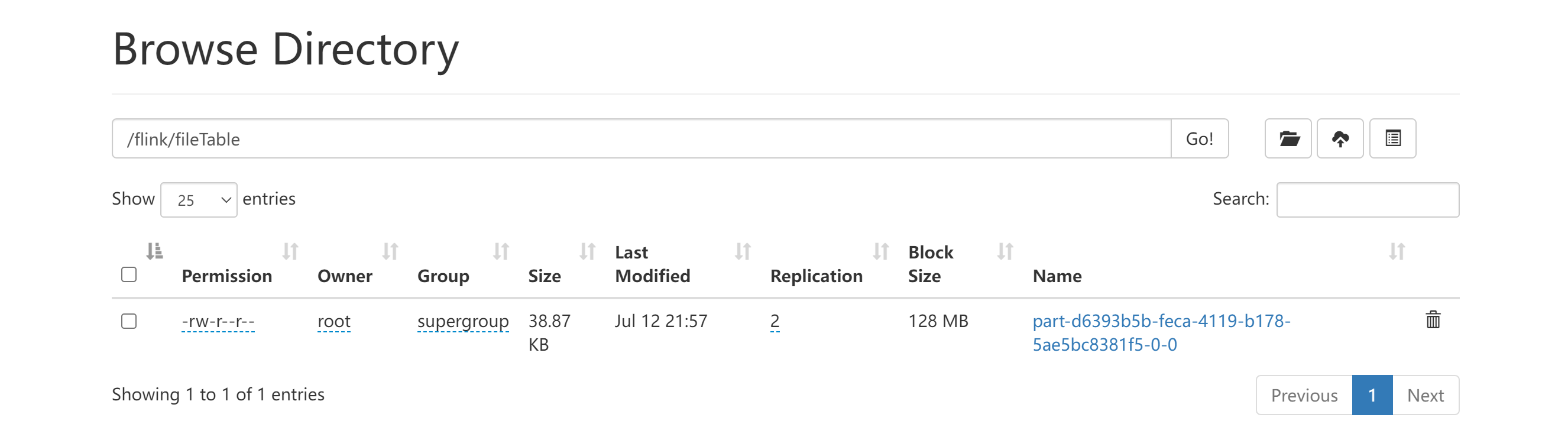
Kafka连接器
Kafka 连接器提供从 Kafka topic 中消费和写入数据的能力。
1.添加kafka连接器依赖
下载连接器:flink-sql-connector-kafka
将flink-sql-connector-kafka-1.17.0.jar上传到flink的lib目录
cp ./flink-sql-connector-kafka-1.17.0.jar /usr/local/program/flink/lib
2.重启yarn-session、sql-client
bin/start-cluster.sh
bin/sql-client.sh
3.创建Kafka映射表
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp',
--当列名和元数据名一致可以省略 FROM 'xxxx', VIRTUAL表示只读
`partition` BIGINT METADATA VIRTUAL,
`offset` BIGINT METADATA VIRTUAL
) WITH (
'connector' = 'kafka',
'topic' = 'testTopic',
'properties.bootstrap.servers' = 'node01:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
--消息体时使用的格式
'format' = 'json',
--fixed为flink实现的分区器,一个并行度只写往kafka一个分区
'sink.partitioner' = 'fixed'
);
查询表信息
Flink SQL> show tables;
+------------+
| table name |
+------------+
| KafkaTable |
+------------+
1 row in set
Flink SQL> desc KafkaTable;
+-----------+--------------+------+-----+-------------------------------+-----------+
| name | type | null | key | extras | watermark |
+-----------+--------------+------+-----+-------------------------------+-----------+
| user_id | BIGINT | TRUE | | | |
| item_id | BIGINT | TRUE | | | |
| behavior | STRING | TRUE | | | |
| ts | TIMESTAMP(3) | TRUE | | METADATA FROM 'timestamp' | |
| partition | BIGINT | TRUE | | METADATA VIRTUAL | |
| offset | BIGINT | TRUE | | METADATA VIRTUAL | |
+-----------+--------------+------+-----+-------------------------------+-----------+
7 rows in set
4.创建source数据源表
CREATE TABLE datagen (
user_id INT,
item_id INT,
behavior STRING
) WITH (
'connector' = 'datagen',
'rows-per-second'='5',
'fields.user_id.kind'='sequence',
'fields.user_id.start'='1',
'fields.user_id.end'='1000',
'fields.item_id.min'='1',
'fields.item_id.max'='1000',
'fields.behavior.length'='10'
);
5.插入Kafka表
Flink SQL> insert into KafkaTable(user_id,item_id,behavior) select * from datagen;
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: e4679f9e14823079d2ce355d592cae93
6.查询Kafka表
Flink SQL> select * from KafkaTable;
+----+----------------------+----------------------+--------------------------------+-------------------------+----------------------+----------------------+
| op | user_id | item_id | behavior | ts | partition | offset |
+----+----------------------+----------------------+--------------------------------+-------------------------+----------------------+----------------------+
| +I | 1 | 92 | c3baec3158 | 2023-07-11 23:22:45.564 | 0 | 0 |
| +I | 2 | 516 | 804b7f09a2 | 2023-07-11 23:22:45.565 | 0 | 1 |
| +I | 3 | 784 | 9940556819 | 2023-07-11 23:22:45.566 | 0 | 2 |
| +I | 4 | 62 | 053ec345db | 2023-07-11 23:22:45.566 | 0 | 3 |
| +I | 5 | 375 | b4aa55a998 | 2023-07-11 23:22:45.566 | 0 | 4 |
| +I | 6 | 507 | b31794a773 | 2023-07-11 23:22:45.566 | 0 | 5 |
Upsert Kafka连接器
Upsert Kafka 连接器支持以upsert方式从Kafka topic中读取数据并将数据写入Kafka topic。如果当前表存在更新操作,那么普通的kafka连接器将无法满足,此时可以使用Upsert Kafka连接器。
1.作为source
upsert-kafka连接器生产changelog流,其中每条数据记录代表一个更新或删除事件。数据记录中的 value被解释为同一 key的最后一个value的UPDATE,如果不存在相应的key,则该更新被视为INSERT。
changelog流中的数据记录被解释为UPSERT,也称为INSERT/UPDATE,因为任何具有相同key的现有行都被覆盖。另外,value为空的消息将会被视作为DELETE 消息。
2.作为sink
upsert-kafka连接器可以消费changelog流。它会将 INSERT/UPDATE_AFTER数据作为正常的 Kafka 消息写入,并将 DELETE 数据以 value 为空的 Kafka 消息写入(表示对应 key 的消息被删除)。
Flink 将根据主键列的值对数据进行分区,从而保证主键上的消息有序,因此同一主键上的更新/删除消息将落在同一分区中。
1.添加kafka连接器依赖
下载连接器:flink-sql-connector-kafka
将flink-sql-connector-kafka-1.17.0.jar上传到flink的lib目录
cp ./flink-sql-connector-kafka-1.17.0.jar /usr/local/program/flink/lib
2.重启yarn-session、sql-client
bin/start-cluster.sh
bin/sql-client.sh
3.创建upsert-kafka的映射表
注意:必须定义主键
CREATE TABLE kafka(
user_id int ,
item_id int ,
behavior STRING,
primary key (item_id) NOT ENFORCED
)
WITH (
'connector' = 'upsert-kafka',
'properties.bootstrap.servers' = 'node01:9092',
'topic' = 'upsertTopic',
'key.format' = 'json',
'value.format' = 'json'
)
4.创建source数据源表
CREATE TABLE datagen (
user_id INT,
item_id INT,
behavior STRING
) WITH (
'connector' = 'datagen',
'rows-per-second'='5',
'fields.user_id.kind'='sequence',
'fields.user_id.start'='1',
'fields.user_id.end'='1000',
'fields.item_id.min'='1',
'fields.item_id.max'='1000',
'fields.behavior.length'='10'
);
5.插入upsert-kafka表
注意:当使用 GROUP BY 子句时,SELECT 子句中可以出现的列只能是分组键列或聚合函数应用的列。
insert into kafka
select sum(user_id) as user_id, item_id, behavior
from datagen
group by item_id, behavior;
6.查询upsert-kafka表
upsert-kafka无法从指定的偏移量读取,只会从主题的源读取。如此,才知道整个数据的更新过程。并且通过
-U,+U,+I等符号来显示数据的变化过程。
Flink SQL> select * from kafka;
+----+-------------+-------------+--------------------------------+
| op | user_id | item_id | behavior |
+----+-------------+-------------+--------------------------------+
| +I | 73 | 362 | bc998a7d48 |
| +I | 74 | 945 | 2237c26098 |
| +I | 75 | 755 | 2537957698 |
| -U | 70 | 604 | 6dce4c7081 |
| +U | 76 | 604 | 288d5d98f7 |
| +I | 77 | 228 | a6b76e7a0d |
| +I | 78 | 568 | 5dcd3a80f3 |
| -U | 65 | 623 | 9e2c52dec9 |
| +U | 79 | 623 | ba177640f7 |
| +I | 80 | 699 | 9fa8198fbd |
| +I | 81 | 489 | 2061468e63 |
| +I | 82 | 124 | 8d2405e54c |
| +I | 83 | 115 | 34d418f37c |
JDBC连接器
JDBC 连接器允许使用 JDBC 驱动向任意类型的关系型数据库读取或者写入数据。
Flink将数据写入外部数据库时,如果使用DDL中定义的主键,则连接器以upsert模式与外部系统交换 UPDATE/DELETE消息,否则连接器以append模式与外部系统交换消息且不支持消费 UPDATE/DELETE 消息。
在upsert模式下,Flink会根据主键插入新行或更新现有行,这样可以保证幂等性。
在追加模式下,Flink将所有记录解释为INSERT消息,如果底层数据库中发生了主键或唯一约束违反,则INSERT操作可能会失败。
为了保证输出结果符合预期,建议为表定义主键,并确保主键是底层数据库表的唯一键集或主键之一。
这里使用MySQL JDBC连接器为例。
1.添加JDBC连接器依赖
下载:flink-connector-jdbc
下载:MySQL驱动包:mysql-connector-j
上传jdbc连接器的jar包和mysql的连接驱动包到flink/lib下
cp ./flink-connector-jdbc-3.1.0-1.17.jar /usr/local/program/flink/lib
cp ./mysql-connector-j/8.0.33/mysql-connector-j-8.0.33.jar /usr/local/program/flink/lib
2.重启flink集群和sql-client
bin/start-cluster.sh
bin/sql-client.sh
3.创建JDBC表
在MySQL中的demo数据库中创建表
CREATE TABLE `flinkTable` (
`id` bigint(20) NOT NULL,
`name` varchar(20) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
4.创建JDBC映射表
在 Flink SQL 中注册一张 MySQL 表
CREATE TABLE mysqlTable(
id BIGINT,
name STRING,
age INT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://node01:3306/demo?useUnicode=true&characterEncoding=UTF-8',
'username' = 'root',
'password' = '123456',
-- 连接到 JDBC 表的名称
'table-name' = 'flinkTable',
-- 最大重试超时时间,以秒为单位且不应该小于 1 秒
'connection.max-retry-timeout' = '60s',
--维表缓存的最大行数,若超过该值,则最老的行记录将会过期。
'sink.buffer-flush.max-rows' = '500',
--flush 间隔时间,超过该时间后异步线程将 flush 数据。
'sink.buffer-flush.interval' = '2s',
--查询数据库失败的最大重试次数
'sink.max-retries' = '3',
--用于定义 JDBC sink 算子的并行度。默认情况下,并行度是由框架决定:使用与上游链式算子相同的并行度
'sink.parallelism' = '1'
);
5.写入数据
Flink SQL> insert into mysqlTable values(1,'flink',20);
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 78eb69d8f16fd239bbb24ea4e13aac5c
6.查询数据
Flink SQL> select * from mysqlTable ;
+----+----------------------+--------------------------------+-------------+
| op | id | name | age |
+----+----------------------+--------------------------------+-------------+
| +I | 1 | flink | 20 |
+----+----------------------+--------------------------------+-------------+
Received a total of 1 row
MongoDB连接器
MongoDB 连接器提供了从 MongoDB 中读取和写入数据的能力。
连接器可以在 upsert 模式下运行,使用在 DDL 上定义的主键与外部系统交换 UPDATE/DELETE 消息
如果 DDL 上没有定义主键,则连接器只能以 append 模式与外部系统交换 INSERT 消息且不支持消费 UPDATE/DELETE 消息
1.添加依赖
使用Table API操作,需要额外引入MongoDB连接器依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-mongodb</artifactId>
<version>1.0.1-1.17</version>
</dependency>
2.示例
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 创建source数据源表
tableEnv.executeSql("CREATE TABLE datagen (\n" +
" id STRING,\n" +
" name STRING,\n" +
" age INT \n" +
") WITH (\n" +
" 'connector' = 'datagen',\n" +
" 'rows-per-second'='5',\n" +
" 'fields.id.kind'='sequence',\n" +
" 'fields.id.start'='1',\n" +
" 'fields.id.end'='10',\n" +
" 'fields.age.min'='1',\n" +
" 'fields.age.max'='150',\n" +
" 'fields.name.length'='10'\n" +
");");
// 创建mongodb映射表
tableEnv.executeSql("CREATE TABLE tb_mongodb (\n" +
" _id STRING,\n" +
" name STRING,\n" +
" age INT,\n" +
" PRIMARY KEY (_id) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'mongodb',\n" +
" 'uri' = 'mongodb://IP:27017',\n" +
" 'database' = 'my_db',\n" +
" 'collection' = 'users'\n" +
");");
// 执行查询
tableEnv.executeSql("show tables;").print();
tableEnv.executeSql(" insert into tb_mongodb select * from datagen;").print();
Table tb_mongodb = tableEnv.from("tb_mongodb").select($("_id"), $("name"), $("age"));
// 打印
tb_mongodb.execute().print();
}
3.验证
查看MongoDB

Elasticsearch连接器
Elasticsearch连接器允许将数据写入到 Elasticsearch 引擎的索引中。
连接器可以工作在 upsert 模式,使用 DDL 中定义的主键与外部系统交换 UPDATE/DELETE 消息
如果 DDL 中没有定义主键,那么连接器只能工作在 append 模式,只能与外部系统交换 INSERT 消息
1.添加依赖
有2个版本
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch6</artifactId>
<version>3.0.1-1.17</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7</artifactId>
<version>3.0.1-1.17</version>
</dependency>
注意:需要引入flink-json,否则将出现如下异常
Caused by: org.apache.flink.table.api.ValidationException: Could not find any factory for identifier 'json' that implements 'org.apache.flink.table.factories.SerializationFormatFactory' in the classpath.
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
2.示例
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 创建表
tableEnv.executeSql("CREATE TABLE datagen (\n" +
" id STRING,\n" +
" name STRING,\n" +
" age INT \n" +
") WITH (\n" +
" 'connector' = 'datagen',\n" +
" 'rows-per-second'='5',\n" +
" 'fields.id.kind'='sequence',\n" +
" 'fields.id.start'='1',\n" +
" 'fields.id.end'='10',\n" +
" 'fields.age.min'='1',\n" +
" 'fields.age.max'='150',\n" +
" 'fields.name.length'='10'\n" +
");");
tableEnv.executeSql("CREATE TABLE tb_es (\n" +
" id STRING,\n" +
" name STRING,\n" +
" age BIGINT,\n" +
" PRIMARY KEY (id) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'elasticsearch-7',\n" +
" 'hosts' = 'http://IP:9200',\n" +
" 'index' = 'users'\n" +
");");
// 执行查询
tableEnv.executeSql("show tables;").print();
// 插入数据
tableEnv.executeSql(" insert into tb_es select * from datagen;").print();
}
注意:由于es的表不支持source,故不能查询,查询会报如下错误
Caused by: org.apache.flink.table.api.ValidationException: Connector 'elasticsearch-7' can only be used as a sink. It cannot be used as a source.
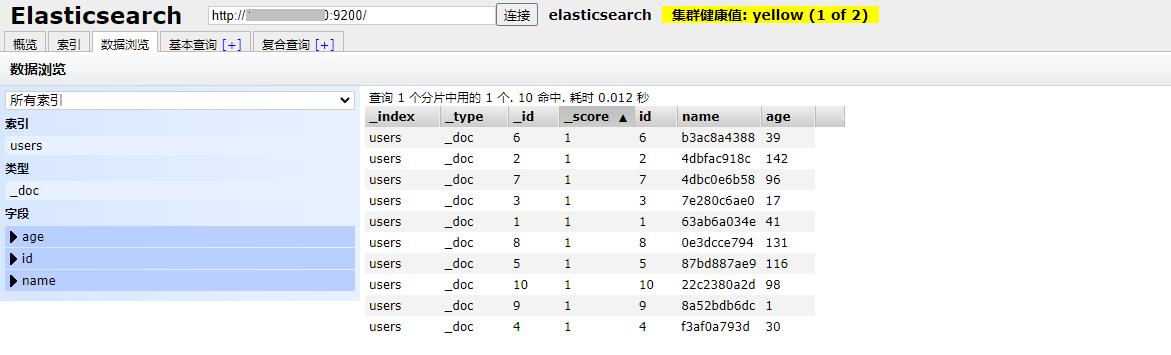
3.验证
使用ElasticSearch Head查看连接查看