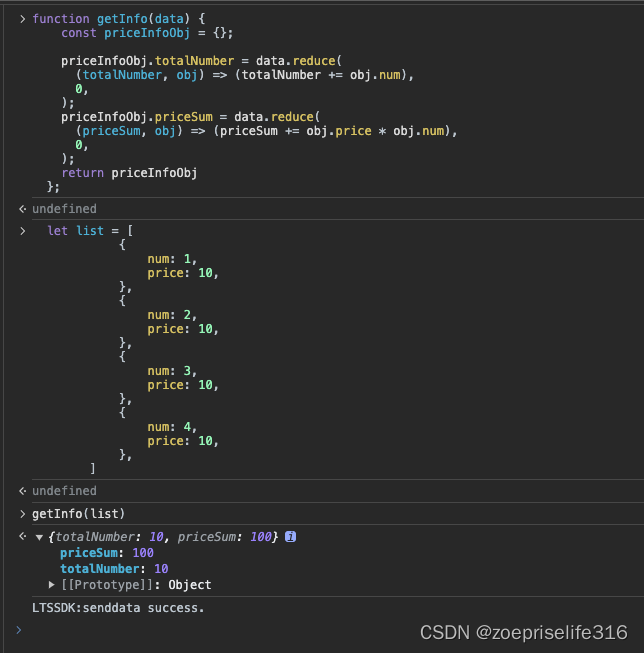
写了两张图像相加,以及图像滤波的的几个算子,分别采用shared memory 进行优化。
#include <stdio.h>
#include <cuda_runtime.h>
#include "helper_cuda.h"
#include "helper_timer.h"
#define BLOCKX 32
#define BLOCKY 32
#define BLOCK_SIZE 1024
#define PADDING 2
__global__ void filter5x5(float* in, float* out, int nW, int nH)
{
// 线程索引 ---> 全局内存索引
unsigned int row_idx = threadIdx.y * blockDim.x + threadIdx.x;
unsigned int col_idx = threadIdx.x * blockDim.y + threadIdx.y;
if (row_idx >= PADDING && col_idx >= PADDING && row_idx < nH - PADDING && col_idx < nW - PADDING)
{
int sum = 0;
for (int i = -PADDING; i <= PADDING; i++)
{
for (int j = -PADDING; j <= -PADDING; j++)
{
sum += in[(row_idx + i) * nW + col_idx + j];
}
}
out[row_idx * nW + col_idx] = sum / ((PADDING * 2 + 1) * (PADDING * 2 + 1));
}
}
__global__ void filter5x5shared(float* in, float* out, int nW, int nH)
{
// 声明动态共享内存
__shared__ int tile[BLOCKY + 4][BLOCKX + 4];
// 线程索引 ---> 全局内存索引
const int ig = blockIdx.x * blockDim.x + threadIdx.x;
const int jg = blockIdx.y * blockDim.y + threadIdx.y;
const int ijg = jg * nW + ig;
const int is = threadIdx.x;
const int js = threadIdx.y;
//position within smem arrays
const int ijs = (js + PADDING) * BLOCKX + is + PADDING;
// 共享内存 存储 操作
tile[js + PADDING][is + PADDING] = in[ijg];
//if (is == 0 && js == 0) //left top
//{
// for (int y = 0; y < PADDING; y++)
// {
// for (int x = 0; x < PADDING; x++)
// {
// if (jg - (PADDING - y) >= 0 && ig - (PADDING - x) >= 0)
// tile[js + y][is + x] = in[(jg - (PADDING - y)) * nW + ig - (PADDING - x)];
// else
// tile[js + y][is + x] = 0;
// }
// }
//}
//else if (is == 0 && js == blockDim.y - 1) //left bottom
//{
// for (int y = 0; y < PADDING; y++)
// {
// for (int x = 0; x < PADDING; x++)
// {
// if (jg + y < nH && ig - (PADDING - x) >= 0)
// tile[js + y][is + x] = in[(jg + y) * nW + ig - (PADDING - x)];
// else
// tile[js + y][is + x] = 0;
// }
// }
//}
//else if (is == blockDim.x - 1 && js == 0) //right top
//{
// for (int y = 0; y < PADDING; y++)
// {
// for (int x = 0; x < PADDING; x++)
// {
// if (jg - (PADDING - y) >= 0 && ig + x < nW)
// tile[js + y][is + x] = in[(jg - (PADDING - y)) * nW + ig + x];
// else
// tile[js + y][is + x] = 0;
// }
// }
//}
//else if (is == blockDim.x - 1 && js == blockDim.y - 1) //right bottom
//{
// for (int y = 0; y < PADDING; y++)
// {
// for (int x = 0; x < PADDING; x++)
// {
// if (jg + y < nH && ig + x < nW)
// tile[js + y][is + x] = in[(jg + y) * nW + ig + x];
// else
// tile[js + y][is + x] = 0;
// }
// }
//}
// if(is == 0) //left
// {
// for (int x = 0; x < PADDING; x++)
// {
// if (ig - (PADDING - x) >= 0)
// tile[js][is + x] = in[jg * nW + ig - (PADDING - x)];
// else
// tile[js][is + x] = 0;
// }
// }
// else if (js == 0) //top
// {
// for (int y = 0; y < PADDING; y++)
// {
// if (jg - (PADDING - y) >= 0)
// tile[js + y][is] = in[(jg - (PADDING - y)) * nW + ig];
// else
// tile[js + y][is] = 0;
// }
// }
// else if (is == blockDim.x - 1) //right
// {
// for (int x = 0; x < PADDING; x++)
// {
// if (ig + x < nW)
// tile[js][is + x] = in[jg * nW + ig + x];
// else
// tile[js][is + x] = 0;
// }
//}
//else if (js == blockDim.y - 1) //bottom
//{
// for (int y = 0; y < PADDING; y++)
// {
// if (jg + y < nH)
// tile[js + y][is] = in[(jg + y) * nW + ig];
// else
// tile[js + y][is] = 0;
// }
//}
// 等待所有线程完成
__syncthreads();
if (jg >= 2 && ig >= 2 && jg < nH - 2 && ig < nW - 2)
{
int sum = 0;
for (int i = -2; i <= 2; i++)
{
for (int j = -2; j <= -2; j++)
{
sum += tile[js + i][is + j];
}
}
out[jg * nW + ig] = sum / 25;
}
}
__global__ void vectorAddition(const float* a, const float* b, float* result, int nW, int nH)
{
const int x = blockIdx.x * blockDim.x + threadIdx.x;
const int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < nW && y < nH)
{
result[x + y * nW] = a[x + y * nW] + b[x + y * nW];
}
}
__global__ void vectorAdditionOptimized(const float* a, const float* b, float* result, int nW, int nH) {
__shared__ float sharedA[BLOCKX * BLOCKY];
__shared__ float sharedB[BLOCKX * BLOCKY];
const int x = blockIdx.x * blockDim.x + threadIdx.x;
const int y = blockIdx.y * blockDim.y + threadIdx.y;
// Load data into shared memory
if (x < nW && y < nH)
{
sharedA[threadIdx.x + blockDim.x * threadIdx.y] = a[x + y * nW];
sharedB[threadIdx.x + blockDim.x * threadIdx.y] = b[x + y * nW];
}
else {
sharedA[threadIdx.x] = 0.0f;
sharedB[threadIdx.x] = 0.0f;
}
// Synchronize to make sure all threads have loaded their data
__syncthreads();
// Perform vector addition using data from shared memory
if (x < nW && y < nH)
{
result[x + y * nW] = sharedA[threadIdx.x + blockDim.x * threadIdx.y] +
sharedB[threadIdx.x + blockDim.x * threadIdx.y];
}
}
__global__ void vectorAddition(const float* a, const float* b, float* result, int size) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < size) {
result[tid] = a[tid] + b[tid];
}
}
__global__ void vectorAdditionOptimized(const float* a, const float* b, float* result, int size) {
__shared__ float sharedA[BLOCK_SIZE];
__shared__ float sharedB[BLOCK_SIZE];
int tid = blockIdx.x * blockDim.x + threadIdx.x;
// Load data into shared memory
if (tid < size) {
sharedA[threadIdx.x] = a[tid];
sharedB[threadIdx.x] = b[tid];
}
else {
sharedA[threadIdx.x] = 0.0f;
sharedB[threadIdx.x] = 0.0f;
}
// Synchronize to make sure all threads have loaded their data
__syncthreads();
// Perform vector addition using data from shared memory
if (threadIdx.x < size)
{
result[tid] = sharedA[threadIdx.x] + sharedB[threadIdx.x];
}
}
int main()
{
int nW = 1024;
int nH = 1024;
float* pHIn, * pHIn2, * pHOut, * pHOut2;
pHIn = new float[nW * nH];
pHIn2 = new float[nW * nH];
pHOut = new float[nW * nH];
pHOut2 = new float[nW * nH];
for (int y = 0; y < nW; y++)
{
for (int x = 0; x < nH; x++)
{
pHIn[x + y * nW] = rand() % 1000;
pHIn2[x + y * nW] = rand() % 1000;
}
}
float* pIn, * pIn2, * pOut, * pOut2;
cudaMalloc(&pIn, nW * nH * sizeof(float));
cudaMalloc(&pIn2, nW * nH * sizeof(float));
cudaMalloc(&pOut, nW * nH * sizeof(float));
cudaMalloc(&pOut2, nW * nH * sizeof(float));
cudaMemcpy(pIn, pHIn, nW * nH * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(pIn2, pHIn2, nW * nH * sizeof(float), cudaMemcpyHostToDevice);
dim3 threadsPerBlock(BLOCKX, BLOCKY);
dim3 blocksPerGrid((nW + BLOCKX - 1) / BLOCKX, (nH + BLOCKY - 1) / BLOCKY);
dim3 threadsPerBlock2(BLOCK_SIZE, 1);
dim3 blocksPerGrid2((nW * nH + BLOCK_SIZE - 1) / BLOCK_SIZE, 1);
StopWatchInterface* sw;
sdkCreateTimer(&sw);
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
//vectorAddition << <blocksPerGrid, threadsPerBlock >> > (pIn, pIn2, pOut, nW, nH);
//vectorAdditionOptimized << <blocksPerGrid, threadsPerBlock >> > (pIn, pIn2, pOut, nW, nH);
sdkStartTimer(&sw);
cudaEventRecord(start);
for (int i = 0; i < 100; i++)
{
//filter5x5 << <blocksPerGrid, threadsPerBlock >> > (pIn, pOut, nW, nH);
//vectorAdditionOptimized << <blocksPerGrid, threadsPerBlock >> > (pIn, pIn2, pOut, nW, nH);
vectorAddition << <blocksPerGrid2, threadsPerBlock2 >> > (pIn, pIn2, pOut, nW * nH);
}
cudaEventRecord(stop);
cudaDeviceSynchronize();
sdkStopTimer(&sw);
float ms1 = sdkGetTimerValue(&sw);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
std::cout << "Elapsed Time: " << elapsedTime << " milliseconds\n";
sdkResetTimer(&sw);
//vectorAddition << <blocksPerGrid, threadsPerBlock >> > (pIn, pIn2, pOut2, nW, nH);
//vectorAdditionOptimized << <blocksPerGrid, threadsPerBlock >> > (pIn, pIn2, pOut, nW, nH);
sdkStartTimer(&sw);
cudaEvent_t start1, stop1;
cudaEventRecord(start);
for (int i = 0; i < 100; i++)
{
//filter5x5shared << <blocksPerGrid, threadsPerBlock >> > (pIn, pOut2, nW, nH);
//vectorAddition << <blocksPerGrid, threadsPerBlock >> > (pIn, pIn2, pOut2, nW , nH);
vectorAdditionOptimized << <blocksPerGrid2, threadsPerBlock2 >> > (pIn, pIn2, pOut2, nW * nH);
}
cudaEventRecord(stop);
cudaDeviceSynchronize();
sdkStopTimer(&sw);
float ms2 = sdkGetTimerValue(&sw);
cudaEventElapsedTime(&elapsedTime, start, stop);
std::cout << "Elapsed Time: " << elapsedTime << " milliseconds\n";
std::cout << "ms1:" << ms1 << ",ms2:" << ms2 << std::endl;
cudaMemcpy(pHOut, pOut, nW * nH * sizeof(float), cudaMemcpyDeviceToHost);
cudaMemcpy(pHOut2, pOut2, nW * nH * sizeof(float), cudaMemcpyDeviceToHost);
for (int y = 0; y < nW; y++)
{
for (int x = 0; x < nH; x++)
{
if (abs(pHOut[x + y * nW] - pHOut2[x + y * nW]) > 0.01)
std::cout << "error" << std::endl;
}
}
cudaFree(pIn);
cudaFree(pOut);
return 0;
}
实际运行发现
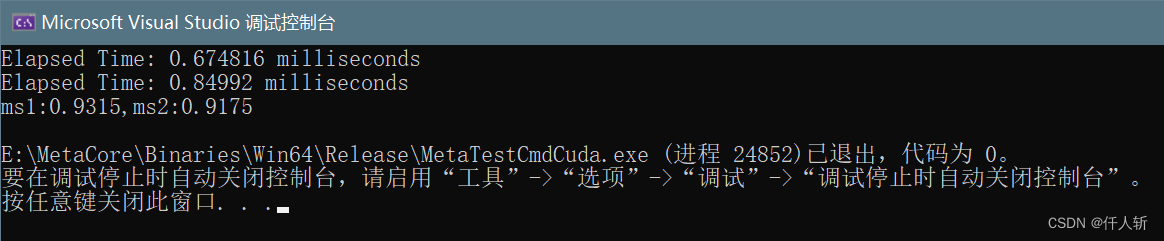
使用shared memory的效率反而下降了,实现结果是一致的。