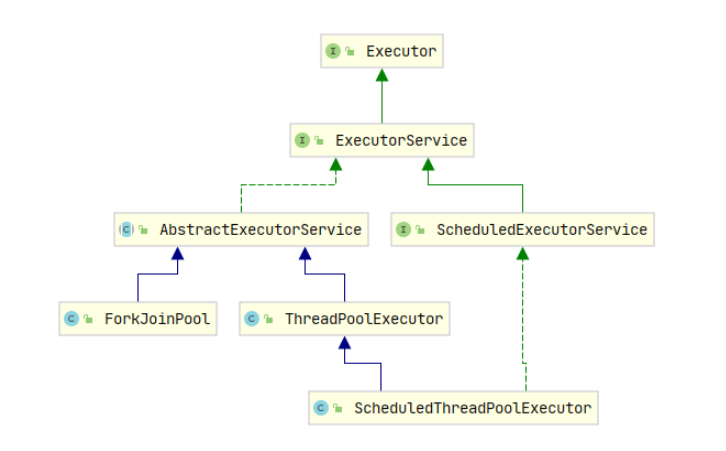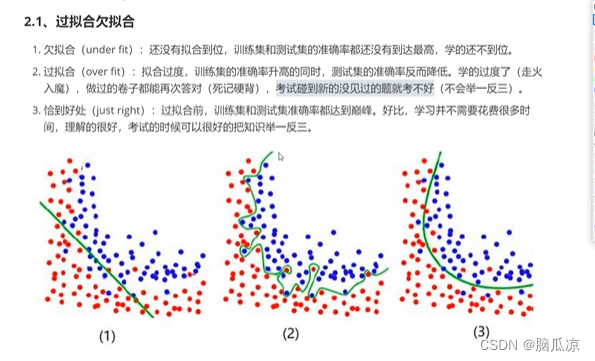
然后我们再来看一下,过拟合和欠拟合,现在,实际上欠拟合,出现的情况已经不多了,欠拟合是
在训练集和测试集的准确率不高,学习不到位的情况.
然后现在一般碰到的是过拟合,可以看到第二个就是,完全就把红点蓝点分开了,这种情况是不好的,
因为分开是对训练数据进行分开的,如果来了测试数据他的效果就不好了,也就说,泛化能力不行.
然后最理想的是第三个图.

可以看到如果我们有一个2图中的绿点,这个点可以看到,如果按照预测数据来说,也就是正常情况来说,应该分到蓝点部分里,但是,如果过拟合了,就会被分到红点里了,过拟合就会缺乏泛化能力

也就是说,这个模型的鲁棒性不强,什么是鲁棒性?就是健壮性
然后我们再看上面两个公式,实际上来说,参数w,小的好,越小,那么容错性就越好,因为比如,如果一个测试集[32,128],这个数据,如果带入的时候搞错了,弄成了[30,120],虽然,这里只变化了2对吧,但是
如果公式中的参数,w大的话,就会放大这种偏差,比如3*2 = 6 会放大偏差到6倍,而0.3*2 = 0.6
w小的只会放大偏差0.6倍对吧