1.合同主体 1人 廖
2.财务条款、合同形式与生效 1人 黄
3.履行、验收、知识产权、不可抗力 1人 詹
4.违约责任、争议解决、保密、法律引用 1人 王
代码规范:
1.代码函数的层级
各审查点在json中分为3级层级,但用python写规则的时候,1级层级为py文件,2级为class类,3级为def函数。
2.代码书写
(1)py名、类、函数名按正规英语翻译(过长的可以简写)。 每个审查事项函数必须中文注明其审查的事项。
(2)每个审查事项函数传入参数均为已读取的docx文件内容,返回均为(ture或false)和审查事项的名称。False代表不存在此风险,ture代表存在此风险。
(3)每个类中除了每个审查事项函数外,还应该包括一个接收其他审查事项函数审查后的结果,并根据其他审查事项函数返回的是true的话,去审查点json文件里寻找此审查点的风险等级、风险提示、修改建议汇总成字典返回。最终把在最外圈写一个汇总全部类审查结果的函数。
时间截点: 12月1号前,每周一检查检查一次进度,一周至少完成7个及以上。(人均大概21-24个审查点)。
测试任务: 每周需要根据完成的审查点进行样本准确率测试,并和工程那边对接部署更新。
import json
big_class = "法律引用"
class Risk_of_misquoting_the_law:
"""
法律引用有误风险提示
"""
def __init__(self, doc):
self.doc = doc
self.type = "法律引用有误风险提示"
def full_title_mis(self):
#审查事项:法律全称引用有误
doc = self.doc
result = False
review_type = "法律全称引用有误"
"""
中间函数为寻找是否存在此风险项,随时改变result的真假,True表示存在此风险项
"""
return [result, review_type]
def abridge_title_mis(self):
#审查事项:法律简称引用有误
doc = self.doc
review_type = "法律简称引用有误"
result = False
"""
中间函数为寻找是否存在此风险项,随时改变result的真假,True表示存在此风险项
"""
return [result, review_type]
def summary_result(self):
"""
汇总其他审查点审查的结果,并返回并对此审查点的风险等级、风险提示、修改建议搜寻得到的字典,若无修改建议则填无
find_info为搜寻函数,去json审查点库里搜寻并返回相应内容,返回格式为:
{"审查事项":"法律简称引用有误",
"风险等级": "高风险",
"风险提示": "2021年1月1日民法典生效后,民法通则、合同法、担保法、物权法、民法总则等法律文件已经失效,建议将合同中引用的失效法律文件调整为《中华人民共和国民法典》。",
"修改建议": "无"
}
修改建议若有的话,返回格式为:
"修改建议": {"建议1": XXX, "建议2": XX}
"""
result_dict = []
if self.full_title_mis()[0]:
result_dict.append(find_info(big_class, self.type,self.full_title_mis()[1]))
if self.abridge_title_mis()[0]:
result_dict.append(find_info(big_class, self.type,self.abridge_title_mis()[1]))
return result_dict
def find_info(big_class, mid_class, small_class):
with open('通用审查点.json', 'r', encoding='utf-8') as f:
contents = json.load(f)
result = contents[big_class][mid_class][small_class]
result["审查点名称"] = small_class
return result
#print(find_info("财务条款", "价款构成范围审查", "价款构成范围缺失"))
def summary_results_law_risk(doc):
"""
汇总各个类的风险点审查结果,格式为列表
"""
law_cit_risk = Risk_of_misquoting_the_law(doc)
return law_cit_risk.summary_result()
import docx
#获取文档对象
file=docx.Document("E:\\研究生\\合同审查项目\\合同审查11.10\\test.docx")
#输出每一段的内容
document=""
for para in file.paragraphs:
document=document+para.text
risk=Risk_of_misquoting_the_law(document)
risk.full_title_mis()
财务条款
其余审查:
'''
审查事项:大小写金额不一致
风险等级:高风险
风险提示:
该笔款大小写金额不一致,请确认金额是否有误
您配置的款项小写金额规范的要求:
1)小写数字前有币种“¥”,或有货币名称“人民币”/“RMB”/“CNY”和货币单位“元”
2)不采用“万元”
3)采用三位分节制
4)数字明确至小数点后两位
'''
#对整个文本进行分句,根据个人统计和测试,只需要用逗号对文本分句足矣
content_split= re.split('。',document)
# print(content_split)
#如果一个句子中有“元”那么将该句子存放在一个临时变量temp_result_set中以供试用
temp_result_set = set()
str = '元'
for term in content_split:
if str in term:
temp_result_set.add(term)
# print(temp_result_set)
#将temp_result_set中含有数字的句子分离出来,最终结果为一个集合result_set
result_set = set()
for term in temp_result_set:
for ch in term:
if ch.isdigit():
result_set.add(term)
for text in result_set:
print("正在判断",text)
#判断:小写数字前有币种“¥”,或有货币名称“人民币”/“RMB”/“CNY”
if '¥' or '人民币' or 'RMB' or 'CNY' in text:
print('符合小写数字前有币种“¥”,或有货币名称“人民币”/“RMB”/“CNY”')
else:
print('不符合小写数字前有币种“¥”,或有货币名称“人民币”/“RMB”/“CNY”')
#判断:不采用“万元”
if '万' in text:
print('采用“万元”,不符合要求')
else:
print('不采用“万元,”,符合要求')
#判断:数字明确至小数点后两位
numbers = re.findall(r"[-+]?\d*\.\d+|\d+", text)
for num in numbers:
length=len(num.split('.'))
if length== 2:
print(f"{num} 保留了两位小数")
else:
print(f"{num} 没有保留两位小数")
价款大小写一致性审查
要求:

例子:
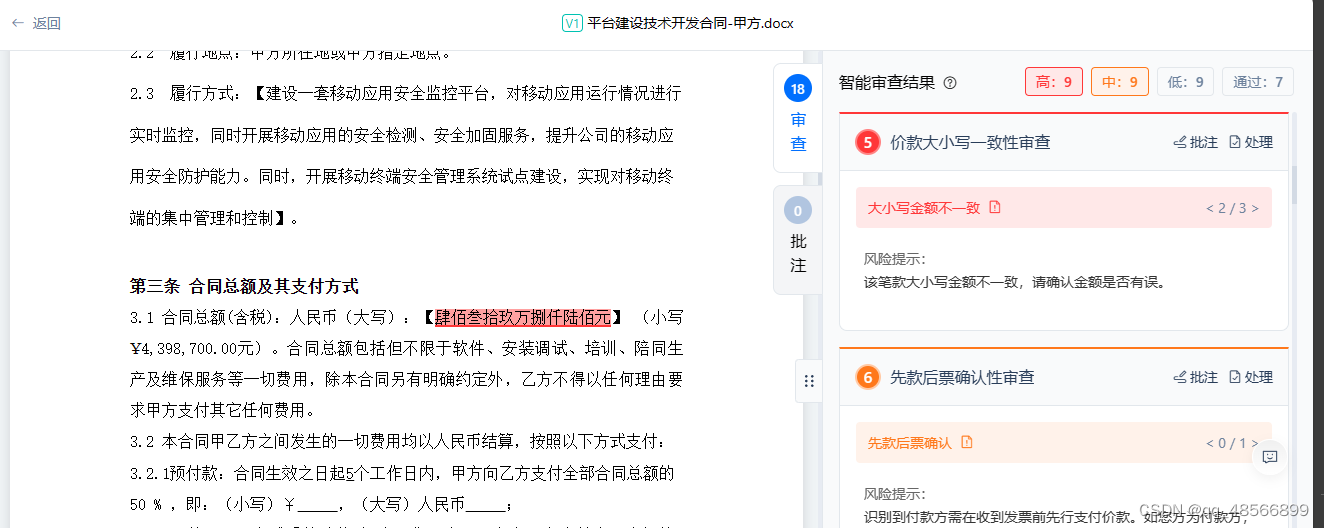
3.1 合同总额(含税):人民币(大写):【肆佰叁拾玖万捌仟陆佰元】 (小写Ұ4,398,700.00元)。
合同形式与生效
合同生效条件缺失审查
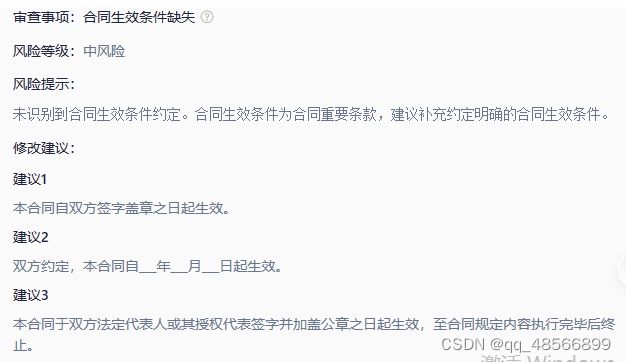
import json
big_class = "法律引用"
class Risk_of_misquoting_the_law:
"""
法律引用有误风险提示
"""
def __init__(self, doc):
self.doc = doc
self.type = "法律引用有误风险提示"
def effective_condition_mis(self):
#审查事项:合同生效条件缺失
doc = self.doc
review_type = "合同生效条件缺失"
result = True
sentence_list= re.split('。',document)
for sentence in sentence_list:
if '合同' in sentence and '生效' in sentence:
result=False
#print(sentence)#输出:合同生效条件
return [result, review_type]
import docx
#获取文档对象
file=docx.Document("E:\\研究生\\合同审查项目\\合同审查11.10\\test.docx")
#输出每一段的内容
document=""
for para in file.paragraphs:
document=document+para.text
risk=Risk_of_misquoting_the_law(document)
risk.effective_condition_mis()

合同编号未填写完整
合同编号缺失
import json
big_class = "法律引用"
class Risk_of_misquoting_the_law:
"""
法律引用有误风险提示
"""
def __init__(self, doc):
self.doc = doc
self.type = "法律引用有误风险提示"
def effective_condition_mis(self):
#审查事项:合同生效条件缺失
doc = self.doc
review_type = "合同生效条件缺失"
result = True
sentence_list= re.split('。',document)
for sentence in sentence_list:
if '合同' in sentence and '生效' in sentence:
result=False
#print(sentence)#输出:合同生效条件
return [result, review_type]
def identification_number_mis(self):
#审查事项:合同编号缺失
doc = self.doc
review_type = "合同编号缺失"
result = True
sentence_list= re.split('。',document)
for sentence in sentence_list:
if '合同编号' in sentence:
pattern = r'合同编号:[\w\-]+'
match = re.search(pattern, sentence)
if match:
contract_number = match.group(0).split(":")[1]
#print(f"提取的合同编号为:{contract_number}")
result=False
break
return [result, review_type]
#合同编号缺失
import docx
#获取文档对象
file=docx.Document("E:\\研究生\\合同审查项目\\合同审查11.10\\test.docx")
#输出每一段的内容
document=""
for para in file.paragraphs:
document=document+para.text
risk=Risk_of_misquoting_the_law(document)
risk.Incomplete_identification_number()
签订日期确认
签订日期缺失
import json
big_class = "法律引用"
class Risk_of_misquoting_the_law:
"""
法律引用有误风险提示
"""
def __init__(self, doc):
self.doc = doc
self.type = "法律引用有误风险提示"
def effective_condition_mis(self):
#审查事项:合同生效条件缺失
doc = self.doc
review_type = "合同生效条件缺失"
result = True
sentence_list= re.split('。',document)
for sentence in sentence_list:
if '合同' in sentence and '生效' in sentence:
result=False
#print(sentence)#输出:合同生效条件
return [result, review_type]
def identification_number_mis(self):
#审查事项:合同编号缺失
doc = self.doc
review_type = "合同编号缺失"
result = True
sentence_list= re.split('。',document)
for sentence in sentence_list:
if '合同编号' in sentence:
pattern = r'合同编号:[\w\-]+'
match = re.search(pattern, sentence)
if match:
contract_number = match.group(0).split(":")[1]
#print(f"提取的合同编号为:{contract_number}")
result=False
break
return [result, review_type]
def signature_date_mis(self):
#审查事项:合同签订日期缺失
doc=self.doc
review_type='合同签订日期'
result = True
sentence_list= re.split('。',document)
for sentence in sentence_list:
if '签订' in sentence and '合同' in sentence:
pattern = r'\d{4}年\d{1,2}月\d{1,2}日'
match = re.search(pattern, text)
if match:
date = match.group(0)
print(sentence)
print(f"提取的签订日期为:{date}")
break
else:
print("未找到合同编号")
return [result, review_type]
import docx
#获取文档对象
file=docx.Document("E:\\研究生\\合同审查项目\\合同审查11.10\\test.docx")
#输出每一段的内容
document=""
for para in file.paragraphs:
document=document+para.text
risk=Risk_of_misquoting_the_law(document)
risk.signature_date_mis()