Data Replication | ClickHouse Docs
副本的目的主要是保障数据的高可用性,即使一台 ClickHouse 节点宕机,那么也可以从其他服务器获得相同的数据
注意:
- clickhouse副本机制的实现要基于zookeeper
- clickhouse的副本机制只适用于MergeTree family
副本写入流程
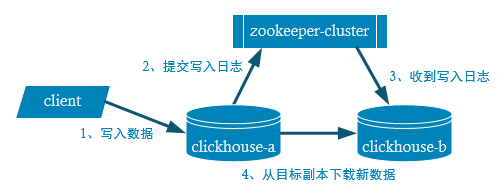
注意:两台clickhouse服务器没有主从之分
副本配置流程
1.启动 zookeeper 集群(版本:3.5.7)
通过prettyZoo可以实现zookeeper节点的可视化:

下载地址:Releases · vran-dev/PrettyZoo · GitHub
2.指定要使用的zookeeper服务器
有两种方法:
首先打开/etc/clickhouse-server/config.xml
搜索关键词zookeeper:
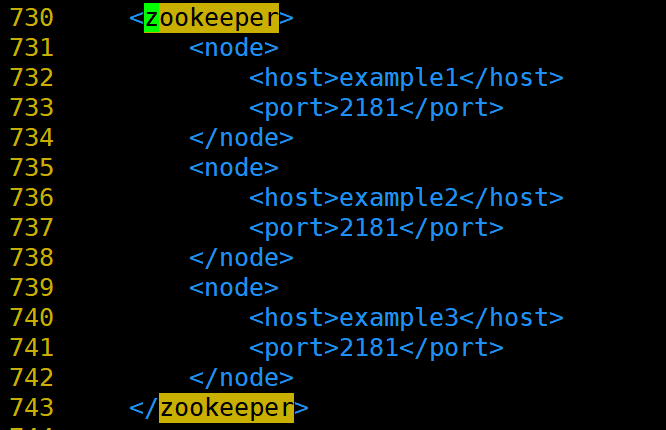
(730行)
方法①(内部设置):取消<zookeeper></zookeeper>之间内容的注释,按照自己zookeeper节点的配置修改host和port即可
方法②(外部设置)参考注释内容配置

首先在/etc/clickhouse-server/config.d文件夹下创建配置文件metrika.xml(配置文件路径以及文件名自定义即可,这里是官方的建议)
将以下内容写入配置文件中:
<?xml version="1.0"?>
<yandex>
<zookeeper-servers>
<node index="1">
<host>hadoop102</host>
<port>2181</port>
</node>
<node index="2">
<host>hadoop103</host>
<port>2181</port>
</node>
<node index="3">
<host>hadoop104</host>
<port>2181</port>
</node>
</zookeeper-servers>
</yandex>其中<zookeeper></zookeeper>之间的内容与内部配置基本一样
然后打开/etc/clickhouse-server/config.xml
添加以下内容:
<zookeeper incl="zookeeper-servers" optional="true" />
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>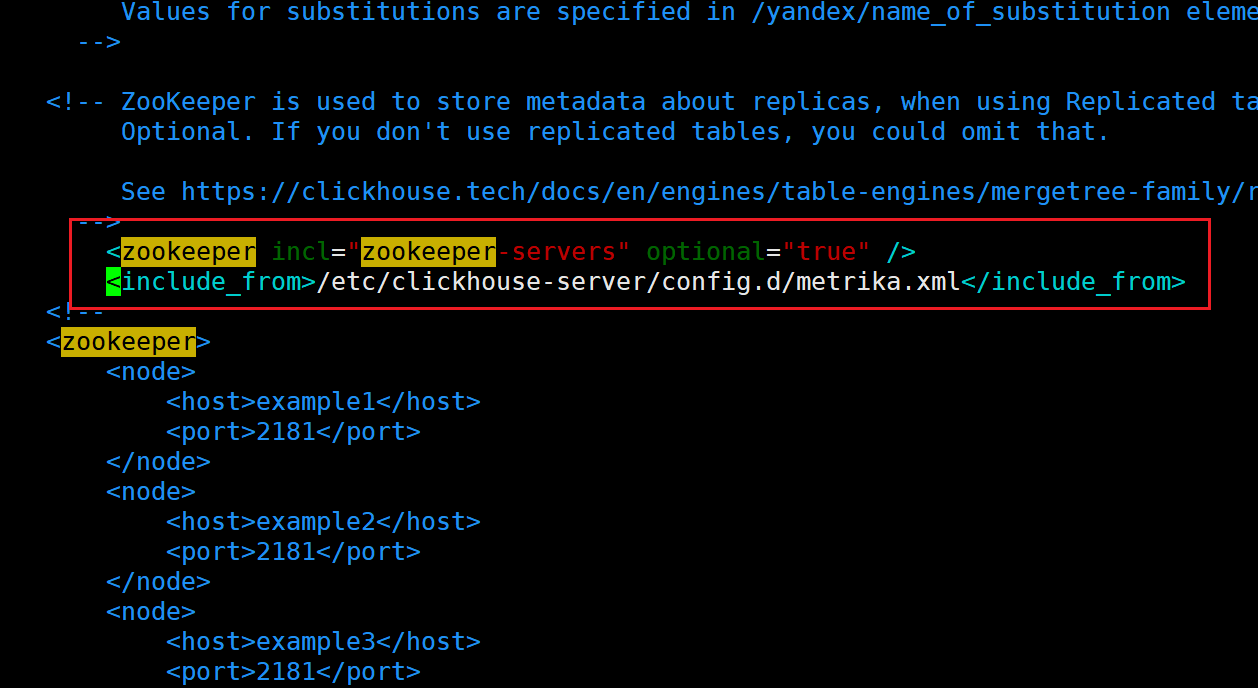
之后将配置同步到其他节点上即可
3.启动clickhouse集群
如果之前未启动,直接启动即可
如果已经启动,则需要重启
副本机制测试
需要注意:副本只能同步数据,不能同步表结构,所以我们需要在每台机器上自己手动建表
在hadoop102上
create table t_order_rep (\
id UInt32,\
sku_id String,\
total_amount Decimal(16,2),\
create_time Datetime\
) engine =ReplicatedMergeTree('/clickhouse/table/01/t_order_rep','rep_102')\
partition by toYYYYMMDD(create_time)\
primary key (id)\
order by (id,sku_id);其中指定引擎为:engine =ReplicatedMergeTree('/clickhouse/table/01/t_order_rep','rep_102')
通过官方文档可以得知,合并书家族的每一种引擎都有其对应的副本引擎:

所以ReplicatedMergeTree即支持副本机制的合并树引擎;
两个参数:
参数1—分片的 zk_path 一般按照:/clickhouse/table/{shard}/{table_name} 的格式,如果只有一个分片就写 01 即可
配置完成后可以在prettyzoo中查看到相应的内容:

参数2—副本名称(相同的分片副本名称不能相同)
在hadoop103上:
create table t_order_rep (\
id UInt32,\
sku_id String,\
total_amount Decimal(16,2),\
create_time Datetime\
) engine =ReplicatedMergeTree('/clickhouse/table/01/t_order_rep','rep_103')\
partition by toYYYYMMDD(create_time)\
primary key (id)\
order by (id,sku_id);之后在hadoop102上插入数据:
insert into t_order_rep values\
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),\
(102,'sku_002',2000.00,'2020-06-01 12:00:00'),\
(103,'sku_004',2500.00,'2020-06-01 12:00:00'),\
(104,'sku_002',2000.00,'2020-06-01 12:00:00'),\
(105,'sku_003',600.00,'2020-06-02 12:00:00');在hadoop103上进行查询,成功查询到数据:
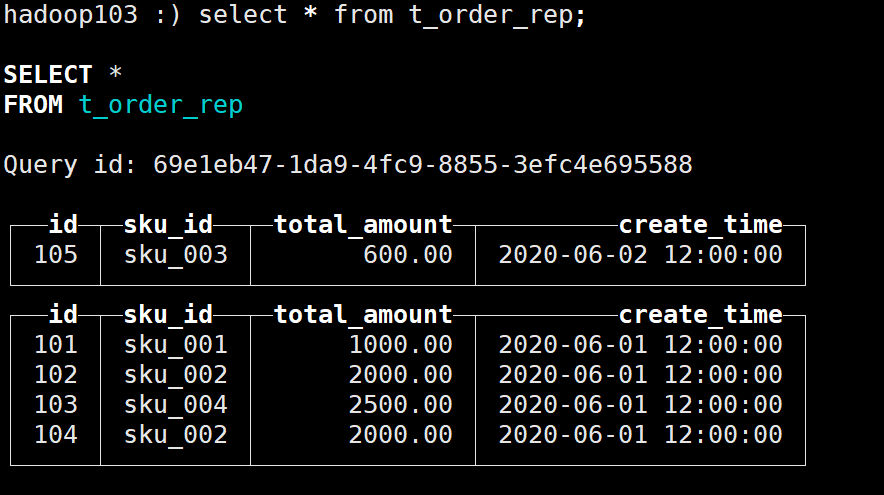
![[Android]_[初级]_[配置gradle的环境变量设置安装位置]](https://img-blog.csdnimg.cn/6ce7e1befbb146138f12b4cf76f5fc00.png)