阅读MARS
MARS创新点:
(1)实例感知。模拟器使用独立的网络分别对前景实例和背景环境进行建模,以便可以单独控制实例的静态(例如大小和外观)和动态(例如轨迹)属性。
(2)模块化。模拟器允许在不同的 NeRF 主干网络、采样策略、输入模式等之间灵活切换,基于Nerfstudio。
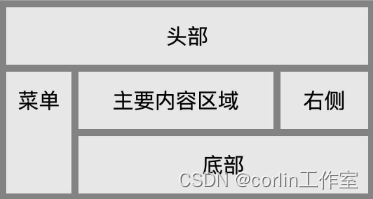
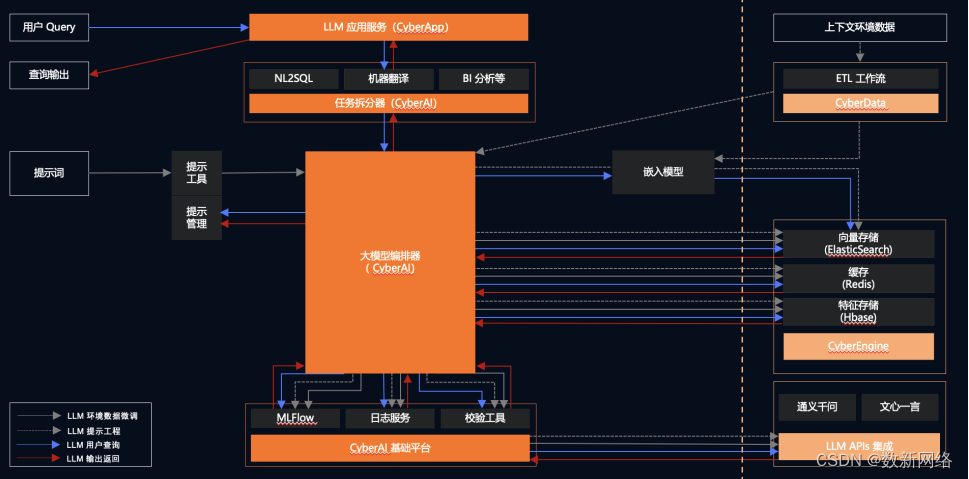
主要流程

框架模型由每个前景实例和背景节点组成。如图所示,当查询属性(RGB、深度、语义等)时,对于给定的光线r,首先计算其与所有可见对象的3D边界框的交点,以获得进入和离开距离[tin,tout]。之后,查询背景节点(图1左上)和前景对象节点(图1左下),其中每个节点对一组3D点进行采样,并使用其特定的神经表示网络来获得点属性(RGB,密度,语义等)。具体来说,查询前景节点,转换光线的来源和方向从世界空间到实例帧根据对象轨迹。最后,来自背景和前景节点的所有光线样本被合成并进行体渲染,以产生逐像素渲染结果(图右)。观察到背景节点(通常是无界的大规模场景)的性质不同于以对象为中心的前景节点,框架提供了一个灵活的和开源的框架,支持不同的设计选择的场景表示的背景和前景节点,可以很容易地将新的静态场景重建和对象为中心的重建的最先进的方法。
无冲突采样
每个模型单独的获得一组采样点,背景采样点如果落在前景的bounding box里面,前景的颜色就可能会学到背景,渲染背景时就会出现前景的车辆的颜色,论文提出正则化项,让落在前景的采样点的体密度趋近于0,如下图,灰色的点即没有被纳入计算的点。
 设计了一个正则化项,可以最小化背景截断样本的密度和,以最小化它们在渲染过程中的影响:
设计了一个正则化项,可以最小化背景截断样本的密度和,以最小化它们在渲染过程中的影响:

前景实例渲染
使用类别级前景物体表征作为默认配置,将每个实例用隐式编码建模
每个车使用一个nerf网络比较浪费,作者使用共享的MLP网络,学习每辆车的latent code(隐编码),下图右侧为该网络,只学一个车的模型,不同的车辆实例使用不同的隐式编码表示

整体网络结构图如下,除了相机位姿和查看方向之外,将车辆的形状编码和问题编码输入shape net和texture net中,得到颜色和密度

类别级的前景物体表征模型使用到了作者的之前工作:Car-Studio
背景渲染
需要分开背景和天空的渲染,引入了一个天空模型,使用了Urban Radiance Fields中的方法处理无限远区域的建模,并引入了正则化项,天空减少学习背景模型的颜色。


组合渲染
将所有背景、前景采样点进行整合,排序后组合渲染
损失函数

Lcolor是渲染的颜色损失

引入深度损失来解决无纹理区域和从稀疏视点观察到的区域。我们设计了两种监督几何形状的策略。给定深度数据,利用从Depth-supervised NeRF 导出的光线分布损失。另一方面,如果深度数据不可用,利用单深度网络并应用MonoSDF的单深度损失。
语义损失仿照Semantic NeRF进行损失计算
实验
下图列出了不同的设计选择在背景节点表示、前景节点表示等方面的影响。

可以看出带有提案采样器的基于网格的 NeRF 用于背景节点,以及类别级前景物体表示用于前景节点和从粗到细的采样器的效果最好。
当前问题:
具体训练细节还没有看明白,以及实验中没有得到正确的效果