1 什么是优化器
1.1 优化器介绍
在PyTorch中,优化器(Optimizer)是用于更新神经网络参数的工具。它根据计算得到的损失函数的梯度来调整模型的参数,以最小化损失函数并改善模型的性能。
即优化器是一种特定的机器学习算法,通常用于在训练深度学习模型时调整权重和偏差。是用于更新神经网络参数以最小化某个损失函数的方法。它通过不断更新模型的参数来实现这一目的。
优化器通常用于深度学习模型,因为这些模型通常具有大量可训练参数,并且需要大量数据和计算来优化。优化器通过不断更新模型的参数来拟合训练数据,从而使模型在新数据上表现良好。
1.2 优化器如何工作
在模型训练过程中,在损失函数中会得到一个loss值,即模型输出与真实值之间的一个差异
对于loss值我们通常会采取pytorch中的自动求导autograd模块去求取模型当中的参数的梯度grad
优化器拿到梯度grad后,进行一系列的优化策略去更新模型参数,使得loss值不断下降
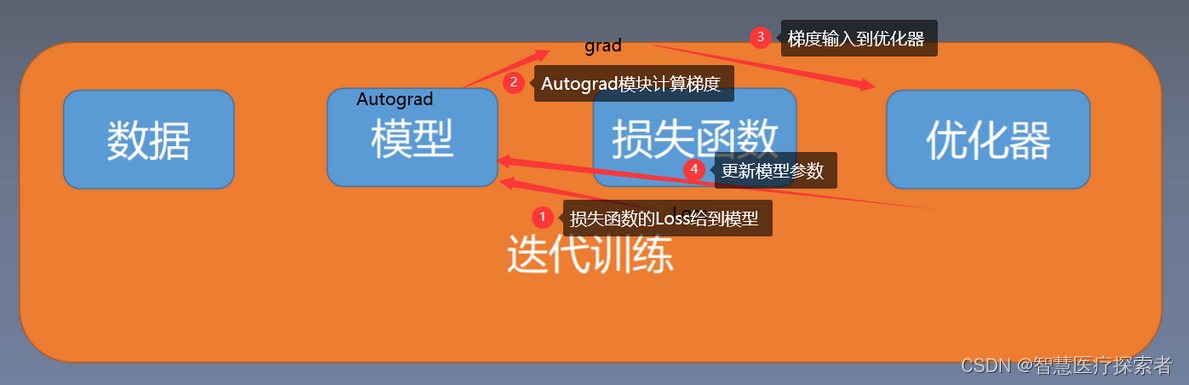
1.3 导数、方向导数与梯度
学习参数通常是指权值或者偏置bias,更新的策略在神经网络中通常都会采用梯度下降方法。
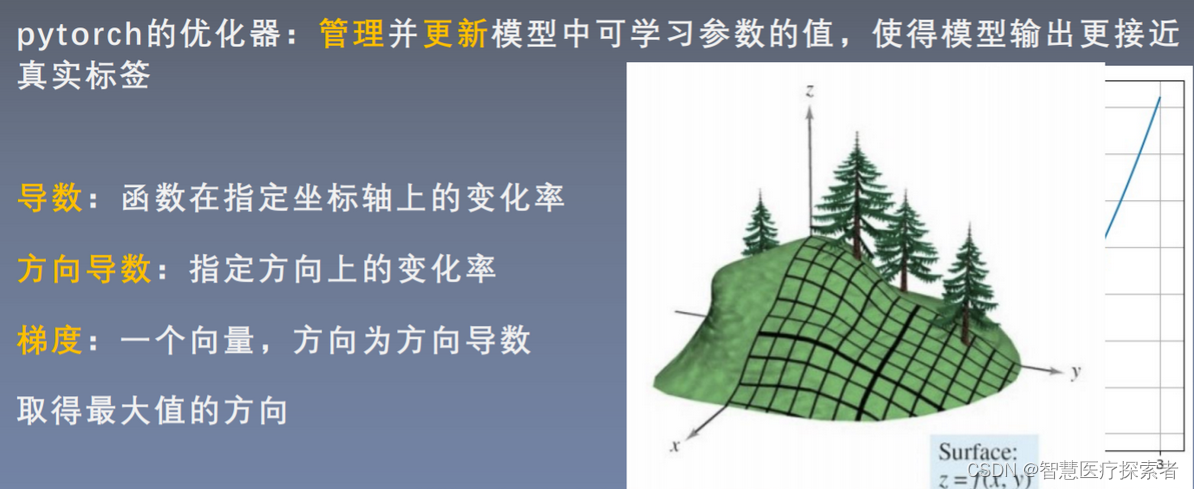
- 方向导数
两个自变量x,y,输出值为z可以认为是山坡的高度。多元函数的导数都是偏导,对x的偏导就是,固定y,求在x方向上的变化率;而方向有无穷多个,不仅仅x、y方向上有变化率,其他方向任意方向上都有变化率
- 梯度是一个向量,它向量的方向是使得方向导数最大的那个方向
梯度的方向为方向导数变化率最大的方向(方向为使得方向导数取得最大值的方向),朝着斜坡最陡峭的地方去。模长即为方向导数的值,即为方向导数的变化率。梯度就是在当前这个点增长最快的一个方向,模长就是增长的速度。梯度的负方向就是下降最快的。
2 优化器的属性与方法
为实现管理并更新模型中可学习参数的值,使得模型输出更接近真实标签,线面是优化器中的核心概念
- 导数:函数在指定坐标轴上的变化率
- 方向导数:指定方向上的变化率
- 梯度:一个向量,方向为方向导数取得最大值的方向
- 梯度下降:朝着梯度下降的负方向去变化,下降是最快的
2.1 基本属性
- defaults里面是基本的超参数:lr、momentum、dampending、weight_decay、nesterov等,用字典打包;
- state没有训练时为空;
- param_groups是一个list,list中每一个元素是一个字典,字典中的'params'才是我们真正的参数,'params'里面的数据又是一个list,list中的一个元素又是一组参数
- params里面的内容为网络的可学习参数,比如,00表示第一个卷积层权重,01表示bias
- _step_count记录更新次数,以便于调整训练策略,例如每更新100次参数,对学习率调整一下
2.2 基本方法
-
zero_grad()
在每一次反向传播过程中,需要对梯度张量进行清零,因为pytorch张量梯度不能自动清零,是累加的。
-
step()
执行,对参数进行更新。优化器保存的权值地址和真实权值的地址是一样的,说明优化器是通过地址去寻找权值
-
add_param_group()
通过参数组param_groups的概念来设置不同的参数有不同的学习率,在模型的fineturn中非常实用
-
state_dict() 与 load_state_dict()
state_dict()和load_state_dict()用于保存模型信息和加载模型信息,用于模型断点的续训练,一般在10个epoch或50个epoch的时候要保存当前的状态信息;
state_dict()返回两个字典,一个state用于保存缓存信息packed_state和一个param_groups;
load_state_dict()用于接收一个state_dict放在优化器中;
3 典型的优化器
3.1 SGD(Stochastic Gradient Descent)
3.1.1 思想
SGD是一种经典的优化器,用于优化模型的参数。SGD的基本思想是,通过梯度下降的方法,不断调整模型的参数,使模型的损失函数最小化。SGD的优点是实现简单、效率高,缺点是收敛速度慢、容易陷入局部最小值。
3.1.2 数学表达
通过如下的方式来更新模型的参数:

3.1.3 实际使用
在PyTorch中,可以使用torch.optim.SGD类来实现SGD。
# 定义模型
model = ...
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
# 训练模型
for inputs, labels in dataset:
# 计算损失函数
outputs = model(inputs)
loss = ...
# 计算梯度
optimizer.zero_grad()
loss.backward()
# 更新参数
optimizer.step()本实例中首先定义了模型,然后定义了SGD优化器,并指定了学习率为0.1。接着,通过循环迭代数据集,计算损失函数和梯度,并更新模型的参数。通过这样的方式,就可以在PyTorch中使用SGD来训练模型了。
3.2 Adam(Adaptive Moment Estimation)
3.2.1 思想
Adam是一种近似于随机梯度下降的优化器,用于优化模型的参数。Adam的基本思想是,通过维护模型的梯度和梯度平方的一阶动量和二阶动量,来调整模型的参数。Adam的优点是计算效率高,收敛速度快,缺点是需要调整超参数。
3.2.2 数学表达
通过如下的方式来更新模型的参数:

3.2.3 实际使用
在PyTorch中,可以使用torch.optim.Adam类来实现Adam。
# 定义模型
model = ...
# 定义优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.1, betas=(0.9, 0.999))
# 训练模型
for inputs, labels in dataset:
# 计算损失函数
outputs = model(inputs)
loss = ...
# 计算梯度
optimizer.zero_grad()
loss.backward()
# 更新参数
optimizer.step()本实例中首先定义了模型,然后定义了Adam优化器,并指定了学习率为0.1, β1和β2的值分别为0.9和0.999。接着,通过循环迭代数据集,计算损失函数和梯度,并更新模型的参数。通过这样的方式,就可以在PyTorch中使用Adam来训练模型了。
3.3 RMSprop(Root Mean Square Propagation)
3.3.1 思想
RMSprop是一种改进的随机梯度下降优化器,用于优化模型的参数。RMSprop的基本思想是,通过维护模型的梯度平方的指数加权平均,来调整模型的参数。RMSprop的优点是收敛速度快,缺点是计算复杂度高,需要调整超参数。
3.3.2 数学表达
具体来说,RMSprop优化算法的公式如下:

3.3.3 实际使用
在PyTorch中,可以使用torch.optim.Adam类来实现Adam。
import torch
# 定义模型
model = MyModel()
# 如果可用则model移至GPU
if torch.cuda.is_available():
model = model.cuda()
# 设定训练模式
model.train()
# 定义 RMSprop 优化器
optimizer = torch.optim.RMSprop(model.parameters(), lr=0.01)
# 循环训练
for input, target in dataset:
# 如果可用则将input、target移至GPU
if torch.cuda.is_available():
input = input.cuda()
target = target.cuda()
# 前向传递:通过将输入传递给模型来计算预测输出
output = model(input)
# 计算损失
loss = loss_fn(output, target)
# 清除所有优化变量的梯度
optimizer.zero_grad()
# 反向传递:计算损失相对于模型参数的梯度
loss.backward()
# 执行单个优化步骤(参数更新)
optimizer.step()本实例中首先定义了模型,并将其转换为训练模式。然后定义了RMSprop优化器,并指定了要优化的模型参数,学习率为0.1, α的值为0.9。接着通过循环迭代数据集,计算损失函数和梯度,并更新模型的参数。通过这样的方式,就可以在PyTorch中使用RMSprop来训练模型了。
4 优化器的选择
除了上面提到的三种优化器,PyTorch还提供了多种优化器,比如Adadelta、Adagrad、AdamW、SparseAdam等。选择优化器时需要根据实际情况和需求进行综合考虑,以下是可参考的点:
- 优化器的收敛速度和稳定性:不同的优化器在收敛速度和稳定性方面表现不同。一般来说,随机梯度下降(SGD)和Adam具有较快的收敛速度,而动量(Momentum)和Adagrad则具有较好的稳定性。
- 优化器对数据集的处理能力:对于大规模数据集,SGD或Mini-batch SGD可能更合适,因为它们可以更好地处理大量数据,且计算成本较低。对于小规模数据集,Adam或其变体可能是一个更好的选择。
- 优化器对模型复杂度的处理能力:如果模型具有很多局部最小值或鞍点,动量优化器或其变体(如Nadam或AMSGrad)可能更好,因为它们可以在这些情况下提高稳定性。
- 优化器的适用场景:如果处理的是序列数据,自适应优化器,如RMSprop或Adagrad可能更好,因为它们可以更好地处理时间序列数据的稀疏性。
- 优化器的参数设置:不同的优化器具有不同的参数设置,如学习率、动量等。选择合适的参数设置可以显著提高模型的训练效果。
可以通过试验不同的优化器和调整参数来找到最适合的优化器。