目录
- 一、前言
- 二、如何通过Redis设计一个分布式全局唯一ID生成工具
- 2.1、使用 Redis 计数器实现
- 2.2、使用 Redis Hash结构实现
- 三、通过代码实现分布式全局唯一ID工具
- 3.1、编写获取工具
- 3.2、测试获取工具
- 四、总结
一、前言
在很多项目中生成类似订单编号、用户编号等有唯一性数据时还用的UUID工具,或者自己根据时间戳+随机字符串等组合来生成,在并发小的时候很少出问题,当并发上来时就很可能出现重复编号的问题了,单体项目和分布式项目都是如此,要想解决这个问题也有很多种方法,可以自己写一个唯一ID生成规则,也可以通过数据库来实现全局ID生成这个和使用Redis实现其实类似,还可以使用比较成熟的雪花算法工具实现,每种方法都有各自的优缺点这里不展开说明,这里详细说明如何使用Redis实现生成分布式全局唯一ID。
还有一个问题为什么不能直接使用数据库的自增ID,而是需要单独生成一个分布式全局唯一ID,类似订单IDON202311090001,在数据库中有自增ID,对于当前业务来说就是唯一的为什么不能用,还要去生成一个独立的订单ID,对于这个问题要从几个方面分析:
1、数据库自增ID是有序增长的很容易就被人猜到,比如我现在下一单看到的订单ID为999那么就知道你的系统里最多只有999单,还有如果接口设计不合理,比如取消订单接口只校验了用户是否登录没有校验订单是否属于该用户,接收一个订单ID就能将订单取消,那么这样很容易就被人抓住漏洞,类似的情况有很多,也很多人写接口是不会注意这个问题。
2、这种自增ID没有意义,而且不同业务的自增ID是重合的,对于信息区分度很低,而且考虑到多业务交互和用户端展示也都是不合适的,想想看要是你在某宝下单,订单ID是999,或者在对接别人订单系统时,给你的订单ID是999是不是很奇怪。
3、分库分表时自增ID会重复
需要集成文章可以查看:
SpringBoot集成Lettuce客户端操作Redis:https://blog.csdn.net/weixin_44606481/article/details/133907103
二、如何通过Redis设计一个分布式全局唯一ID生成工具
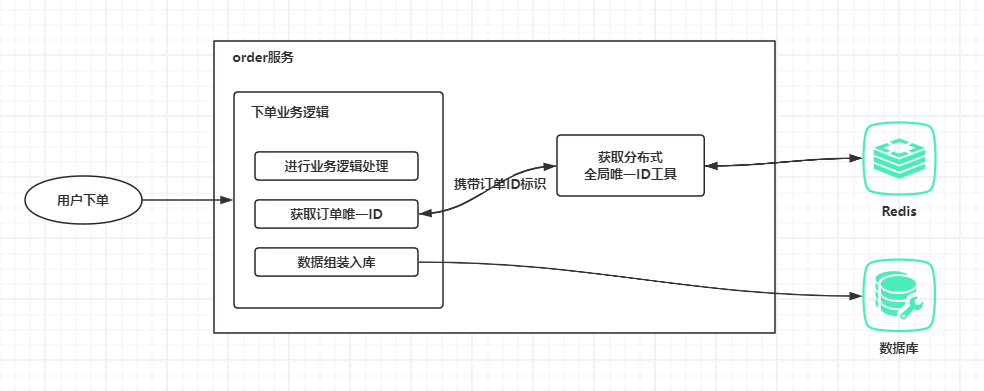
用户下单调用下单逻辑,先进行业务逻辑处理,然后携带订单ID标识通过分布式全局唯一ID工具获取一个唯一的订单ID,这个订单ID标识就是用于区分业务的,获取到订单ID后将数据组装入库,分布式全局唯一ID工具可以做成一个内嵌的utils,也可以封装成一个独立的jar,还可以做成一个分布式全局唯一ID生成服务供其它业务服务调用。
2.1、使用 Redis 计数器实现
Redis的String结构提供了计数器自增功能,类似Java中的原子类,还要优于Java的原子类,因为Redis是单线程执行的缓存读写本身就是线程安全的,也不用进行原子类的乐观锁操作,每一次获取分布式全局唯一ID时就将自增序列加1。
# 给key为GENERATEID:NO的value自增1,如果这key不存在则会添加到Redis中并且设置value为1
## GENERATEID:key前缀
## NO:订单ID标识
127.0.0.1:6379> incr GENERATEID:NO
(integer) 1
2.2、使用 Redis Hash结构实现
Redis Hash结构中的每一个field也可以进行自增操作,可以用一个Hash结构存储所有的标识信息和自增序列,方便管理,比较适合并发不高的小项目所有服务都是用的一个Redis,如果并发较高就不合适了,毕竟Redis操作普通String结构肯定比操作Hash结构快。
# 给key为GENERATEID,field为no的value自增1,如果这key不存在则会添加到Redis中并且设置value为1
## GENERATEID:分布式全局唯一ID Hash key
## NO:Hash结构中的field
127.0.0.1:6379> hincrby GENERATEID NO 1
(integer) 1
三、通过代码实现分布式全局唯一ID工具
这里使用Redis 计数器实现,自增序列以天为单位存储,在实际业务中,比如生成订单编号组成规则都类似NO1699631999000-1(业务标识key+当前时间戳+自增序列),这个规则可以自己定义,保证最终生成的订单编号不重复即可,不建议直接一个自增序列干到底,订单编号这类型的数据都是有长度限制的,或者是要求生成20字符的订单编号,如果增长的过长反而不好处理。
3.1、编写获取工具
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.time.LocalDate;
import java.util.concurrent.TimeUnit;
@Component
public class RedisGenerateIDUtils {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// key前缀
private String PREFIX = "GENERATEID:";
/**
* 获取全局唯一ID
* @param key 业务标识key
*/
public String generateId(String key) {
// 获取对应业务自增序列
Long incr = getIncr(key);
// 组装最后的结果,这里可以根据需要自己定义,这里是按照业务标识key+当前时间戳+自增序列进行组装
String resultID = key + System.currentTimeMillis() + "-" + incr;
return resultID;
}
/**
* 获取对应业务自增序列
*/
private Long getIncr(String key) {
String cacheKey = getCacheKey(key);
Long increment = 0L;
// 判断Redis中是否存在这个自增序列,如果不存在添加一个序列并且设置一个过期时间
if (!redisTemplate.hasKey(cacheKey)) {
// 这里存在线程安全问题,需要加分布式锁,这里做简单实现
String lockKey = cacheKey + "_LOCK";
// 设置分布式锁
boolean lock = redisTemplate.opsForValue().setIfAbsent(lockKey, 1, 30, TimeUnit.SECONDS);
if (!lock) {
// 如果没有拿到锁进行自旋
return getIncr(key);
}
increment = redisTemplate.opsForValue().increment(cacheKey);
// 我这里设置24小时,可以根据实际情况设置当前时间到当天结束时间的插值
redisTemplate.expire(cacheKey, 24, TimeUnit.HOURS);
// 释放锁
redisTemplate.delete(lockKey);
} else {
increment = redisTemplate.opsForValue().increment(cacheKey);
}
return increment;
}
/**
* 组装缓存key
*/
private String getCacheKey(String key) {
return PREFIX + key + ":" + getYYYYMMDD();
}
/**
* 获取当前YYYYMMDD格式年月日
*/
private String getYYYYMMDD() {
LocalDate currentDate = LocalDate.now();
int year = currentDate.getYear();
int month = currentDate.getMonthValue();
int day = currentDate.getDayOfMonth();
return "" + year + month + day;
}
}
3.2、测试获取工具
import com.redisscene.utils.RedisGenerateIDUtils;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.concurrent.*;
@RunWith(SpringRunner.class)
@SpringBootTest(classes = RedisSceneApplication.class)
public class RedisGenerateIDTest {
@Autowired
private RedisGenerateIDUtils redisGenerateIDUtils;
@Test
public void t1() throws InterruptedException {
// 定义一个线程池 设置核心线程数和最大线程数都为100,队列根据需要设置
ThreadPoolExecutor executor = new ThreadPoolExecutor(100, 100, 10, TimeUnit.SECONDS, new LinkedBlockingQueue<>(10000));
CountDownLatch countDownLatch = new CountDownLatch(10000);
long beginTime = System.currentTimeMillis();
// 获取10000个全局唯一ID 看看是否有重复
CopyOnWriteArraySet<String> ids = new CopyOnWriteArraySet<>();
for (int i = 0; i < 10000; i++) {
executor.execute(() -> {
// 获取全局唯一ID
long beginTime02 = System.currentTimeMillis();
String orderNo = redisGenerateIDUtils.generateId("NO");
System.out.println("获取单个ID耗时 time=" + (System.currentTimeMillis() - beginTime02));
if (ids.contains(orderNo)) {
System.out.println("重复ID=" + orderNo);
} else {
ids.add(orderNo);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
// 打印获取到的全局唯一ID集合数量
System.out.println("获取到全局唯一ID count=" + ids.size());
System.out.println("耗时毫秒 time=" + (System.currentTimeMillis() - beginTime));
}
}
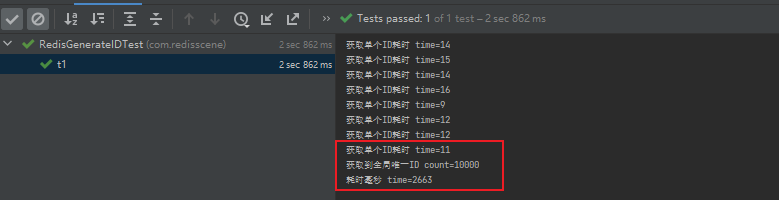
四、总结
通过测试可以看到100并发生成全局唯一ID是没问题的,而且获取单个ID耗时在10-20毫秒左右,一般的业务已经完全够用,这个耗时也要看Redis性能和项目配置决定的,如果对于这种唯一ID生成并发量非常高的业务,可以提前生成一个唯一ID池存储在本地内存中,业务要获取唯一ID先去池中获取,如果获取不到再去Redis获取,自增序列一次性增加多个,然后将这个区间的值存储在本地缓存即可。

![[Machine Learning] 多任务学习](https://img-blog.csdnimg.cn/2cb02ad1b9534645b82c801ba69bbbff.png#pic_center)