源代码: Lib/xml/etree/ElementTree.py
该xml.etree.ElementTree模块实现了一个简单高效的 API,用于解析和创建 XML 数据。
一、说明
这是一个简短的使用教程xml.etree.ElementTree(ET简而言之)。目标是演示该模块的一些构建块和基本概念。xml.etree是Python标准库中的一个子模块,用于处理XML(Extensible Markup Language)文档的解析和操作。它提供了一组简单的API,可以用于创建、处理、解析和生成XML文档。其中,ElementTree模块是最常用的模块,它提供了一种简单的方式来处理XML文档,包括读取、修改、创建和保存XML文档。由于XML在数据交换和数据存储方面的广泛应用,xml.etree在Python中具有重要的作用。
二、etree的基本概念
2.1 XML 树和元素
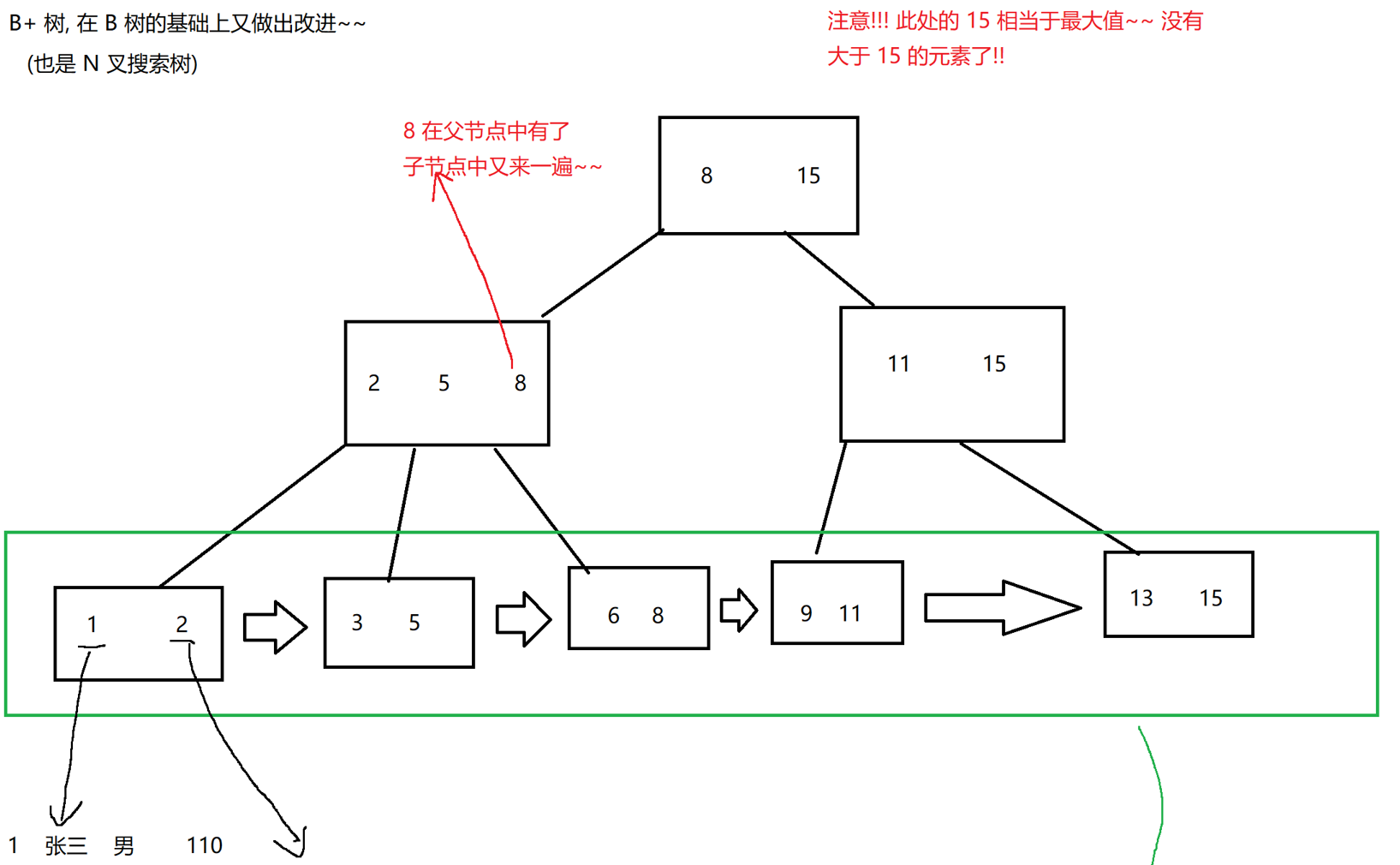
XML 本质上是一种分层数据格式,最自然的表示方式是使用树。 ET有两个类用于此目的 - ElementTree将整个 XML 文档表示为一棵树,并 Element表示该树中的单个节点。与整个文档的交互(从文件读取和写入)通常在级别上完成ElementTree。与单个 XML 元素及其子元素的交互是在该Element级别上完成的。
2.2 解析 XML
我们将使用以下 XML 文档作为本节的示例数据:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank>1</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank>4</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank>68</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
我们可以通过读取文件来导入这些数据:
import xml.etree.ElementTree as ET
tree = ET.parse('country_data.xml')
root = tree.getroot()
或者直接从字符串:
root = ET.fromstring(country_data_as_string)
fromstring()将 XML 从字符串直接解析为Element,它是解析树的根元素。其他解析函数可能会创建一个ElementTree. 检查文档以确定。
作为Element,root具有标签和属性字典:
>>> root.tag
'data'
>>> root.attrib
{}
它还具有我们可以迭代的子节点:
>>> for child in root:
... print(child.tag, child.attrib)
...
country {'name': 'Liechtenstein'}
country {'name': 'Singapore'}
country {'name': 'Panama'}
子节点是嵌套的,我们可以通过索引访问特定的子节点:
>>> root[0][1].text
'2008'
笔记
并非 XML 输入的所有元素最终都会成为解析树的元素。目前,该模块会跳过输入中的任何 XML 注释、处理指令和文档类型声明。尽管如此,使用该模块的 API 而不是从 XML 文本解析构建的树可以在其中包含注释和处理指令;生成 XML 输出时将包含它们。TreeBuilder可以通过将自定义实例传递给构造函数来访问文档类型声明XMLParser 。
2.2.1 Pull API 用于非阻塞解析
该模块提供的大多数解析功能都要求在返回任何结果之前立即读取整个文档。可以使用 an XMLParser并将数据增量地输入其中,但它是一个推送 API,在回调目标上调用方法,这对于大多数需求来说太低级且不方便。有时,用户真正想要的是能够增量地解析 XML,而不阻塞操作,同时享受完全构造的Element对象的便利。
执行此操作的最强大工具是XMLPullParser. 它不需要阻塞读取来获取 XML 数据,而是通过XMLPullParser.feed()调用增量地提供数据。要获取已解析的 XML 元素,请调用XMLPullParser.read_events(). 这是一个例子:
>>> parser = ET.XMLPullParser(['start', 'end'])
>>> parser.feed('<mytag>sometext')
>>> list(parser.read_events())
[('start', <Element 'mytag' at 0x7fa66db2be58>)]
>>> parser.feed(' more text</mytag>')
>>> for event, elem in parser.read_events():
... print(event)
... print(elem.tag, 'text=', elem.text)
...
end
mytag text= sometext more text
明显的用例是以非阻塞方式运行的应用程序,其中 XML 数据从套接字接收或从某些存储设备增量读取。在这种情况下,阻塞读取是不可接受的。
因为它非常灵活,所以XMLPullParser对于更简单的用例来说可能不方便。如果您不介意应用程序阻塞读取 XML 数据,但仍希望具有增量解析功能,请查看iterparse(). 当您正在阅读大型 XML 文档并且不想将其完全保存在内存中时,它会很有用。
2.2.2 寻找有趣的元素
Element有一些有用的方法可以帮助递归地迭代它下面的所有子树(它的子树,它们的子树,等等)。例如 Element.iter():
>>> for neighbor in root.iter('neighbor'):
... print(neighbor.attrib)
...
{'name': 'Austria', 'direction': 'E'}
{'name': 'Switzerland', 'direction': 'W'}
{'name': 'Malaysia', 'direction': 'N'}
{'name': 'Costa Rica', 'direction': 'W'}
{'name': 'Colombia', 'direction': 'E'}
Element.findall()只查找带有当前元素直接子元素的标签的元素。 Element.find()查找具有特定标记的第一Element.text个子元素,并访问该元素的文本内容。 Element.get()访问元素的属性:
>>> for country in root.findall('country'):
... rank = country.find('rank').text
... name = country.get('name')
... print(name, rank)
...
Liechtenstein 1
Singapore 4
Panama 68
通过使用XPath可以更复杂地指定要查找的元素。
2.2.3 修改 XML 文件
ElementTree提供了一种构建 XML 文档并将其写入文件的简单方法。该ElementTree.write()方法用于此目的。
创建后,Element可以通过直接更改其字段(例如Element.text)、添加和修改属性(Element.set()方法)以及添加新的子对象(例如使用Element.append())来操作对象。
假设我们要为每个国家/地区的排名添加 1,并向updated 排名元素添加一个属性:
>>> for rank in root.iter('rank'):
... new_rank = int(rank.text) + 1
... rank.text = str(new_rank)
... rank.set('updated', 'yes')
...
>>> tree.write('output.xml')
我们的 XML 现在看起来像这样:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
我们可以使用 删除元素Element.remove()。假设我们要删除排名高于 50 的所有国家/地区:
>>> for country in root.findall('country'):
... # using root.findall() to avoid removal during traversal
... rank = int(country.find('rank').text)
... if rank > 50:
... root.remove(country)
...
>>> tree.write('output.xml')
请注意,迭代时并发修改可能会导致问题,就像迭代和修改 Python 列表或字典时一样。因此,该示例首先收集所有与 , 匹配的元素 root.findall(),然后才迭代匹配列表。
我们的 XML 现在看起来像这样:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
</data>
2.2.5 构建 XML 文档
该SubElement()函数还提供了一种为给定元素创建新子元素的便捷方法:
>>> a = ET.Element('a')
>>> b = ET.SubElement(a, 'b')
>>> c = ET.SubElement(a, 'c')
>>> d = ET.SubElement(c, 'd')
>>> ET.dump(a)
<a><b /><c><d /></c></a>
2.2.6 使用命名空间解析 XML
如果 XML 输入具有名称空间,则表单中带有前缀的标签和属性prefix:sometag将扩展为 前缀被完整URI{uri}sometag替换的位置。另外,如果有默认名称空间,则完整的 URI 会添加到所有非前缀标签的前面。
下面是一个包含两个命名空间的 XML 示例,一个带有前缀“fictional”,另一个用作默认命名空间:
<?xml version="1.0"?>
<actors xmlns:fictional="http://characters.example.com"
xmlns="http://people.example.com">
<actor>
<name>John Cleese</name>
<fictional:character>Lancelot</fictional:character>
<fictional:character>Archie Leach</fictional:character>
</actor>
<actor>
<name>Eric Idle</name>
<fictional:character>Sir Robin</fictional:character>
<fictional:character>Gunther</fictional:character>
<fictional:character>Commander Clement</fictional:character>
</actor>
</actors>
find()搜索和浏览此 XML 示例的一种方法是手动将 URI 添加到 a或的 xpath 中的每个标记或属性 findall():
root = fromstring(xml_text)
for actor in root.findall('{http://people.example.com}actor'):
name = actor.find('{http://people.example.com}name')
print(name.text)
for char in actor.findall('{http://characters.example.com}character'):
print(' |-->', char.text)
搜索命名空间 XML 示例的更好方法是使用您自己的前缀创建字典并在搜索函数中使用这些前缀:
ns = {'real_person': 'http://people.example.com',
'role': 'http://characters.example.com'}
for actor in root.findall('real_person:actor', ns):
name = actor.find('real_person:name', ns)
print(name.text)
for char in actor.findall('role:character', ns):
print(' |-->', char.text)
这两种方法都输出:
John Cleese
|--> Lancelot
|--> Archie Leach
Eric Idle
|--> Sir Robin
|--> Gunther
|--> Commander Clement
三、XPath 支持
该模块对 用于在树中定位元素的XPath 表达式提供有限的支持。目标是支持缩写语法的一小部分;完整的 XPath 引擎超出了该模块的范围。
3.1 示例
下面的示例演示了该模块的一些 XPath 功能。我们将使用解析 XMLcountrydata部分中的 XML 文档 :
import xml.etree.ElementTree as ET
root = ET.fromstring(countrydata)
# Top-level elements
root.findall(".")
# All 'neighbor' grand-children of 'country' children of the top-level
# elements
root.findall("./country/neighbor")
# Nodes with name='Singapore' that have a 'year' child
root.findall(".//year/..[@name='Singapore']")
# 'year' nodes that are children of nodes with name='Singapore'
root.findall(".//*[@name='Singapore']/year")
# All 'neighbor' nodes that are the second child of their parent
root.findall(".//neighbor[2]")
对于带有命名空间的 XML,请使用通常的限定{namespace}tag符号:
# All dublin-core "title" tags in the document
root.findall(".//{http://purl.org/dc/elements/1.1/}title")
3.2 支持的 XPath 语法
| 句法 | 意义 |
|---|---|
|
| 选择具有给定标签的所有子元素。例如, 版本 3.8 中的更改:添加了对星号通配符的支持。 |
|
| 选择所有子元素,包括注释和处理指令。例如, |
|
| 选择当前节点。这在路径的开头最有用,表明它是相对路径。 |
|
| 选择当前元素下所有级别上的所有子元素。例如, |
|
| 选择父元素。 |
|
| 选择具有给定属性的所有元素。 |
|
| 选择给定属性具有给定值的所有元素。该值不能包含引号。 |
|
| 选择给定属性不具有给定值的所有元素。该值不能包含引号。 3.10 版本中的新功能。 |
|
| 选择具有名为 的子元素的所有元素 |
|
| 选择完整文本内容(包括后代)等于给定 的所有元素 3.7 版本中的新功能。 |
|
| 选择其完整文本内容(包括后代)不等于给定 的所有元素 3.10 版本中的新功能。 |
|
| 选择具有名为 的子元素的所有元素 |
|
| 选择所有具有名为 的子元素, 3.10 版本中的新功能。 |
|
| 选择位于给定位置的所有元素。位置可以是整数(1 是第一个位置)、表达式 |
谓词(方括号内的表达式)前面必须有标记名称、星号或其他谓词。 position谓词前面必须有标记名称。
四、旧版参考资料
4.1 功能
1)规范化数据
xml.etree.ElementTree.canonicalize(xml_data=None, *, out=None, from_file=None, **options)
转换功能。
规范化是一种标准化 XML 输出的方法,允许逐字节比较和数字签名。它减少了 XML 序列化程序的自由度,而是生成更受约束的 XML 表示形式。主要限制涉及命名空间声明的放置、属性的顺序和可忽略的空格。
此函数采用 XML 数据字符串 ( xml_data ) 或文件路径或类文件对象 ( from_file ) 作为输入,将其转换为规范形式,并使用 out file (-like) 对象(如果提供)将其写出,或者如果没有,则将其作为文本字符串返回。输出文件接收文本,而不是字节。因此,应该以带有编码的文本模式打开它utf-8 。
典型用途:
xml_data = "<root>...</root>"
print(canonicalize(xml_data))
with open("c14n_output.xml", mode='w', encoding='utf-8') as out_file:
canonicalize(xml_data, out=out_file)
with open("c14n_output.xml", mode='w', encoding='utf-8') as out_file:
canonicalize(from_file="inputfile.xml", out=out_file)
配置选项如下( options ):
-
with_comments:设置为 true 以包含注释(默认值: false)
-
strip_text:设置为 true 以去除文本内容前后的空格
(默认值:假)
-
rewrite_prefixes:设置为 true 以用“n{number}”替换命名空间前缀
(默认值:假)
-
qname_aware_tags:一组 qname 感知标签名称,其中前缀
应在文本内容中替换(默认:空)
-
qname_aware_attrs:一组 qname 感知属性名称,其中前缀
应在文本内容中替换(默认:空)
-
except_attrs:一组不应序列化的属性名称
-
except_tags:一组不应序列化的标签名称
在上面的选项列表中,“一组”指的是任何字符串的集合或可迭代,不需要排序。
3.8 版本中的新功能。
2)注释
xml.etree.ElementTree.Comment(text=None)
注释元素工厂。此工厂函数创建一个特殊元素,该元素将由标准序列化程序序列化为 XML 注释。注释字符串可以是字节串或 Unicode 字符串。 text是包含注释字符串的字符串。返回表示评论的元素实例。
请注意,XMLParser会跳过输入中的注释,而不是为其创建注释对象。ElementTree仅当使用其中一种方法将注释节点插入到树中时,An才会包含注释节点Element。
3)转储
xml.etree.ElementTree.dump(elem)
将元素树或元素结构写入 sys.stdout。该函数只能用于调试。
确切的输出格式取决于实现。在此版本中,它被编写为普通的 XML 文件。
elem是元素树或单个元素。
版本 3.8 中的更改:该dump()函数现在保留用户指定的属性顺序。
4)从指定字符串解析文本
xml.etree.ElementTree.fromstring(text, parser=None)
从字符串常量中解析 XML 部分。与 相同XML()。 text 是包含 XML 数据的字符串。 parser是一个可选的解析器实例。XMLParser如果未给出,则使用标准解析器。返回一个Element实例。
5)从指定字符串list解析文本
xml.etree.ElementTree.fromstringlist (text, parser= None )
从一系列字符串片段中解析 XML 文档。 序列是包含 XML 数据片段的列表或其他序列。 parser是一个可选的解析器实例。XMLParser 如果未给出,则使用标准解析器。返回一个Element实例。
4.2 版本3.2中的新功能。
xml.etree.ElementTree.indent(tree, space=' ', level=0)
将空格附加到子树以在视觉上缩进树。这可用于生成打印精美的 XML 输出。 树可以是 Element 或 ElementTree。 space是将为每个缩进级别插入的空白字符串,默认情况下为两个空格字符。要在已缩进的树内缩进部分子树,请将初始缩进级别作为level传递。
4.3 新的3.9 版本中的新功能。
1)检查对象是否有效
xml.etree.ElementTree.iselement(element)
检查对象是否看起来是有效的元素对象。 element是一个元素实例。True如果这是一个元素对象,则返回。
2) 部分解析元素树
xml.etree.ElementTree.iterparse(source, events=None, parser=None)
将 XML 部分逐步解析为元素树,并向用户报告发生的情况。 source是包含 XML 数据的文件名或文件对象 。 events是要报告的一系列事件。支持的事件是字符串"start"、"end"、"comment"、 "pi"和"start-ns"("end-ns" “ns”事件用于获取详细的命名空间信息)。如果省略事件"end",则仅报告事件。 parser是一个可选的解析器实例。XMLParser如果未给出,则使用 标准 解析器。解析器必须是 的子类 XMLParser并且只能使用默认值TreeBuilder作为目标。返回一个提供对的迭代器;它有一个属性,一旦源被完全读取,该属性就会引用生成的 XML 树的根元素。(event, elem)root
请注意,在iterparse()增量构建树时,它会阻止对源(或其命名的文件)的读取。因此,它不适合无法进行阻塞读取的应用程序。有关完全非阻塞解析,请参阅XMLPullParser。
注意:iterparse()仅保证在发出“start”事件时看到起始标记的“>”字符,因此属性已定义,但此时 text 和 tail 属性的内容未定义。这同样适用于元素子元素;他们可能在场,也可能不在场。
如果您需要完全填充的元素,请查找“结束”事件。
自 3.4 版起已弃用:解析器参数。
版本 3.8 中进行了更改:comment添加pi了 和 事件。
xml.etree.ElementTree.parse(source, parser=None)
--解析元素
将 XML 部分解析为元素树。 source是包含 XML 数据的文件名或文件对象。 parser是一个可选的解析器实例。XMLParser如果未给出,则使用标准解析器。返回一个 ElementTree实例。
xml.etree.ElementTree.ProcessingInstruction(target, text=None)
--处理指令
PI元件工厂。该工厂函数创建一个特殊元素,该元素将被序列化为 XML 处理指令。 target是包含 PI 目标的字符串。 text是包含 PI 内容(如果给定)的字符串。返回一个元素实例,表示一条处理指令。
请注意,XMLParser跳过输入中的处理指令,而不是为其创建注释对象。ElementTree仅当使用其中一种方法将处理指令节点插入到树中时, An 才会包含处理指令节点Element。
xml.etree.ElementTree.register_namespace(prefix, uri)
注册命名空间
注册命名空间前缀。注册表是全局的,给定前缀或命名空间 URI 的任何现有映射都将被删除。 prefix是命名空间前缀。 uri是命名空间 uri。如果可能的话,此命名空间中的标签和属性将使用给定的前缀进行序列化。
3.2 版本中的新功能。
xml.etree.ElementTree.SubElement(parent, tag, attrib={}, **extra)
--子元素
子元素工厂。此函数创建一个元素实例,并将其附加到现有元素。
元素名称、属性名称和属性值可以是字节串或 Unicode 字符串。 Parent是父元素。 tag是子元素名称。 attrib是一个可选字典,包含元素属性。 extra包含附加属性,以关键字参数形式给出。返回一个元素实例。
xml.etree.ElementTree.tostring(element, encoding='us-ascii', method='xml', *, xml_declaration=None, default_namespace=None, short_empty_elements=True)
--生成 XML 元素(包括所有子元素)的字符串表示形式。
元素是一个Element实例。 编码 1是输出编码(默认为 US-ASCII)。用于encoding="unicode"生成 Unicode 字符串(否则,生成字节串)。 方法 是"xml","html"或"text"(默认为"xml")。 xml_declaration、default_namespace和short_empty_elements与 中的含义相同ElementTree.write()。返回包含 XML 数据的(可选)编码字符串。
3.4 版中的新功能:short_empty_elements参数。
3.8 版中的新增功能: xml_declaration和default_namespace参数。
版本 3.8 中的更改:该tostring()函数现在保留用户指定的属性顺序。
xml.etree.ElementTree.tostringlist(element, encoding='us-ascii', method='xml', *, xml_declaration=None, default_namespace=None, short_empty_elements=True)
--生成 XML 元素(包括所有子元素)的字符串表示形式。
元素是一个Element实例。 编码 1是输出编码(默认为 US-ASCII)。用于encoding="unicode"生成 Unicode 字符串(否则,生成字节串)。 方法 是"xml","html"或"text"(默认为"xml")。 xml_declaration、default_namespace和short_empty_elements与 中的含义相同ElementTree.write()。返回包含 XML 数据的(可选)编码字符串列表。它不保证任何特定的顺序,除了。b"".join(tostringlist(element)) == tostring(element)
3.2 版本中的新功能。
3.4 版中的新功能:short_empty_elements参数。
3.8 版中的新增功能: xml_declaration和default_namespace参数。
版本 3.8 中的更改:该tostringlist()函数现在保留用户指定的属性顺序。
xml.etree.ElementTree.XML(text, parser=None)
--从字符串常量中解析 XML 部分。
该函数可用于在 Python 代码中嵌入“XML 文字”。 text是包含 XML 数据的字符串。 parser是一个可选的解析器实例。XMLParser如果未给出,则使用标准 解析器。返回一个Element实例。
xml.etree.ElementTree.XMLID(text, parser=None)
-- 从字符串常量中解析 XML 部分,并返回一个从元素 id:s 映射到元素的字典。
text是包含 XML 数据的字符串。 parser是一个可选的解析器实例。XMLParser如果未给出,则使用标准 解析器。Element返回包含实例和字典的元组 。
4.3.1 X包括支持
该模块通过帮助程序模块为XInclude 指令提供有限的支持 xml.etree.ElementInclude。该模块可用于根据树中的信息将子树和文本字符串插入元素树中。
示例
下面是一个演示 XInclude 模块的使用的示例。要在当前文档中包含 XML 文档,请使用{http://www.w3.org/2001/XInclude}include元素并将parse属性设置为"xml",并使用href属性指定要包含的文档。
<?xml version="1.0"?>
<document xmlns:xi="http://www.w3.org/2001/XInclude">
<xi:include href="source.xml" parse="xml" />
</document>
默认情况下,href属性被视为文件名。您可以使用自定义加载程序来覆盖此行为。另请注意,标准帮助程序不支持 XPointer 语法。
要处理此文件,请照常加载它,并将根元素传递给模块xml.etree.ElementTree:
from xml.etree import ElementTree, ElementInclude
tree = ElementTree.parse("document.xml")
root = tree.getroot()
ElementInclude.include(root)
ElementIninclude 模块将该元素替换为source.xml{http://www.w3.org/2001/XInclude}include文档中的根元素。结果可能看起来像这样:
<document xmlns:xi="http://www.w3.org/2001/XInclude">
<para>This is a paragraph.</para>
</document>
如果省略parse属性,则默认为“xml”。href 属性是必需的。
要包含文本文档,请使用该{http://www.w3.org/2001/XInclude}include元素,并将parse属性设置为“text”:
<?xml version="1.0"?>
<document xmlns:xi="http://www.w3.org/2001/XInclude">
Copyright (c) <xi:include href="year.txt" parse="text" />.
</document>
结果可能类似于:
<document xmlns:xi="http://www.w3.org/2001/XInclude">
Copyright (c) 2003.
</document>
五、最新版功能资料
5.1 功能
xml.etree.ElementIninclude.default_loader(href、解析、编码=无)
默认加载程序。此默认加载程序从磁盘读取包含的资源。 href是一个 URL。 parse用于解析模式“xml”或“text”。 编码 是可选的文本编码。如果未给出,则编码为utf-8. 返回扩展的资源。如果解析模式为"xml",则这是一个 ElementTree 实例。如果解析模式为“text”,则这是一个 Unicode 字符串。如果加载器失败,它可以返回 None 或引发异常。
xml.etree.ElementIninclude。包括(elem, loader = None, base_url = None, max_depth = 6)
此函数扩展了 XInclude 指令。 elem是根元素。 loader是一个可选的资源加载器。如果省略,则默认为default_loader(). 如果给定,它应该是一个可调用的,实现与 相同的接口 default_loader()。 base_url是原始文件的基本 URL,用于解析相对包含文件引用。 max_depth是递归包含的最大数量。限制降低恶意内容爆炸的风险。传递负值以禁用限制。
返回扩展的资源。如果解析模式为 "xml",则这是一个 ElementTree 实例。如果解析模式为“text”,则这是一个 Unicode 字符串。如果加载器失败,它可以返回 None 或引发异常。
3.9 版本中的新功能: base_url和max_depth参数。
4.4.2 元素对象
xml.etree.ElementTree类 。元素(标签, attrib = {} , **额外)
元素类。此类定义了 Element 接口,并提供了该接口的参考实现。
元素名称、属性名称和属性值可以是字节串或 Unicode 字符串。 tag是元素名称。 attrib是一个可选字典,包含元素属性。 extra包含附加属性,以关键字参数形式给出。
标签
一个字符串,标识该元素代表什么类型的数据(换句话说,元素类型)。
文本
尾巴
这些属性可用于保存与元素关联的附加数据。它们的值通常是字符串,但也可以是任何特定于应用程序的对象。如果元素是从 XML 文件创建的,则text属性保存元素的开始标记与其第一个子标记或结束标记之间的文本,或者None,并且tail属性保存元素的结束标记与下一个标记之间的文本,或None。对于 XML 数据
<a><b>1<c>2<d/>3</c></b>4</a>
a元素具有Nonetext和tail属性,b元素具有text和tail 属性,c元素具有text和tail 属性,d元素具有text和tail属性。 "1" "4" "2" None None "3"
要收集元素的内部文本,请参阅itertext()例如"".join(element.itertext())。
应用程序可以在这些属性中存储任意对象。
属性
包含元素属性的字典。请注意,虽然 attrib值始终是真正的可变 Python 字典,但 ElementTree 实现可以选择使用其他内部表示形式,并且仅在有人要求时才创建字典。要利用此类实现,请尽可能使用下面的字典方法。
以下类似字典的方法适用于元素属性。
清除( )
重置一个元素。该函数删除所有子元素,清除所有属性,并将 text 和 tail 属性设置为None。
获取(键,默认=无)
获取名为key的元素属性。
返回属性值,如果未找到属性,则返回默认值。
项目( )
以(名称,值)对序列的形式返回元素属性。属性以任意顺序返回。
键( )
以列表形式返回元素属性名称。名称以任意顺序返回。
设置(键,值)
将元素上的属性key设置为value。
以下方法适用于元素的子元素(子元素)。
附加(子元素)
将元素子元素添加到该元素的内部子元素列表的末尾。TypeError如果子元素不是 则 引发Element。
扩展(子元素)
从具有零个或多个元素的序列对象追加子元素。TypeError如果子元素不是 则引发Element。
3.2 版本中的新功能。
查找(匹配,命名空间=无)
查找第一个匹配match的子元素。 匹配可以是标签名称或路径。返回一个元素实例或None. 命名空间是从命名空间前缀到全名的可选映射。作为前缀传递'',将表达式中所有无前缀的标签名称移动到给定的命名空间中。
findall (匹配,命名空间= None )
按标签名称或 路径查找所有匹配的子元素。返回一个列表,其中包含按文档顺序排列的所有匹配元素。 命名空间是从命名空间前缀到全名的可选映射。作为前缀传递'',将表达式中所有无前缀的标签名称移动到给定的命名空间中。
findtext (匹配,默认= None ,命名空间= None )
查找第一个匹配match的子元素的文本。 匹配可以是标签名称或路径。返回第一个匹配元素的文本内容,如果未找到元素,则返回默认值。请注意,如果匹配元素没有文本内容,则返回空字符串。命名空间是从命名空间前缀到全名的可选映射。作为前缀传递'',将表达式中所有无前缀的标签名称移动到给定的命名空间中。
插入(索引,子元素)
在此元素中的给定位置插入子元素。TypeError如果子元素不是 则引发 Element。
迭代器(标签=无)
创建一个以当前元素为根的树迭代器。迭代器按文档(深度优先)顺序迭代此元素及其下面的所有元素。如果tag不是None或,则迭代器仅返回tag'*'等于 tag 的元素。如果在迭代期间修改树结构,则结果是不确定的。
3.2 版本中的新功能。
iterfind (匹配,命名空间= None )
按标签名称或 路径查找所有匹配的子元素。返回一个可迭代对象,生成按文档顺序排列的所有匹配元素。命名空间是从命名空间前缀到全名的可选映射。
3.2 版本中的新功能。
迭代文本( )
创建一个文本迭代器。迭代器按文档顺序循环遍历该元素和所有子元素,并返回所有内部文本。
3.2 版本中的新功能。
makeelement (标签,属性)
创建与此元素类型相同的新元素对象。不要调用此方法,SubElement()而是使用工厂函数。
删除(子元素)
从元素中删除子元素。与 find* 方法不同,此方法根据实例标识而不是标记值或内容来比较元素。
Element对象还支持以下用于处理子元素的序列类型方法:__delitem__(), __getitem__(), __setitem__(), __len__()。
注意:没有子元素的元素将测试为False。在 Python 3.14 中,测试元素的真值已被弃用,并且会引发异常。使用特定len(elem)或测试代替:elem is None
element = root.find('foo')
if not element: # careful!
print("element not found, or element has no subelements")
if element is None:
print("element not found")
在 version 3.12 中更改:测试 Element 发出的真值DeprecationWarning。
在 Python 3.8 之前,元素的 XML 属性的序列化顺序是通过按属性名称排序来人为地预测的。基于现在保证的字典排序,这种任意重新排序在 Python 3.8 中被删除,以保留用户代码最初解析或创建属性的顺序。
一般来说,鉴于XML 信息集明确排除属性顺序来传递信息,用户代码应尽量不依赖于属性的特定顺序。代码应该准备好处理任何输入顺序。在需要确定性 XML 输出的情况下(例如,对于加密签名或测试数据集),该函数可以使用规范序列化canonicalize()。
在规范输出不适用但输出仍需要特定属性顺序的情况下,代码应旨在直接按所需顺序创建属性,以避免代码读者的感知不匹配。在难以实现的情况下,可以在序列化之前应用如下所示的配方,以独立于元素创建强制执行订单:
def reorder_attributes(root):
for el in root.iter():
attrib = el.attrib
if len(attrib) > 1:
# adjust attribute order, e.g. by sorting
attribs = sorted(attrib.items())
attrib.clear()
attrib.update(attribs)
4.4.3 元素树对象
xml.etree.ElementTree类 。ElementTree(元素=无,文件=无)
ElementTree 包装类。此类表示整个元素层次结构,并为与标准 XML 之间的序列化添加了一些额外的支持。
元素是根元素。该树使用 XML文件的内容(如果给定)进行初始化。
_setroot (元素)
替换该树的根元素。这将丢弃树的当前内容,并将其替换为给定元素。小心使用。 element是一个元素实例。
查找(匹配,命名空间=无)
与 相同Element.find(),从树的根部开始。
findall (匹配,命名空间= None )
与 相同Element.findall(),从树的根部开始。
findtext (匹配,默认= None ,命名空间= None )
与 相同Element.findtext(),从树的根部开始。
获取根目录( )
返回此树的根元素。
迭代器(标签=无)
创建并返回根元素的树迭代器。迭代器按节顺序循环遍历该树中的所有元素。 tag是要查找的标签(默认是返回所有元素)。
iterfind (匹配,命名空间= None )
与 相同Element.iterfind(),从树的根部开始。
3.2 版本中的新功能。
解析(源,解析器=无)
将外部 XML 部分加载到此元素树中。 source是文件名或文件对象。 parser是一个可选的解析器实例。XMLParser如果未给出,则使用标准解析器。返回节根元素。
写(文件,编码= 'us-ascii', xml_declaration = None, default_namespace = None,方法= 'xml', *, short_empty_elements = True)
将元素树以 XML 形式写入文件。 file是文件名,或 打开用于写入的文件对象。 编码 1是输出编码(默认为 US-ASCII)。 xml_declaration控制是否应将 XML 声明添加到文件中。 如果不是 US-ASCII、UTF-8 或 Unicode(默认为),则使用False“从不”、“True始终”、“仅”。 default_namespace设置默认的 XML 命名空间(对于“xmlns”)。 方法是,或(默认为 )。仅关键字的short_empty_elements参数控制不包含内容的元素的格式设置。如果(默认),它们将作为单个自闭合标签发出,否则它们将作为一对开始/结束标签发出。NoneNone"xml""html""text""xml"True
输出是字符串 ( str) 或二进制 ( bytes)。这是由编码参数控制的。如果编码为 "unicode",则输出为字符串;否则,它是二进制的。请注意,如果它是一个打开的 文件对象,这可能会与文件类型冲突;确保您不要尝试将字符串写入二进制流,反之亦然。
3.4 版中的新功能:short_empty_elements参数。
在 version 3.8 中更改:该write()方法现在保留用户指定的属性顺序。
这是将要操作的 XML 文件:
<html>
<head>
<title>Example page</title>
</head>
<body>
<p>Moved to <a href="http://example.org/">example.org</a>
or <a href="http://example.com/">example.com</a>.</p>
</body>
</html>
更改第一段中每个链接的属性“target”的示例:
>>> from xml.etree.ElementTree import ElementTree
>>> tree = ElementTree()
>>> tree.parse("index.xhtml")
<Element 'html' at 0xb77e6fac>
>>> p = tree.find("body/p") # Finds first occurrence of tag p in body
>>> p
<Element 'p' at 0xb77ec26c>
>>> links = list(p.iter("a")) # Returns list of all links
>>> links
[<Element 'a' at 0xb77ec2ac>, <Element 'a' at 0xb77ec1cc>]
>>> for i in links: # Iterates through all found links
... i.attrib["target"] = "blank"
...
>>> tree.write("output.xhtml")
4.4.4 QName 对象
xml.etree.ElementTree类 。QName ( text_or_uri , tag = None )
QName 包装器。这可用于包装 QName 属性值,以便在输出上获得正确的命名空间处理。 text_or_uri是一个包含 QName 值的字符串,格式为 {uri}local,或者,如果给出了 tag 参数,则为 QName 的 URI 部分。如果给出 tag ,则第一个参数被解释为 URI,并且该参数被解释为本地名称。QName实例是不透明的。
4.4.5 树构建器对象
xml.etree.ElementTree类 。TreeBuilder ( element_factory = None , * , comment_factory = None , pi_factory = None , insert_comments = False , insert_pis = False )
通用元素结构生成器。此构建器将一系列开始、数据、结束、注释和 pi 方法调用转换为格式良好的元素结构。您可以使用此类来使用自定义 XML 解析器或其他类似 XML 格式的解析器来构建元素结构。
element_factory当给定时,必须是一个可调用的,接受两个位置参数:一个标签和一个属性字典。预计会返回一个新的元素实例。
comment_factory和pi_factory函数在给出时,其行为应类似于和函数来创建注释和处理指令。如果没有给出,将使用默认工厂。当insert_comments和/或insert_pis为 true 时,如果注释/pi 出现在根元素内(但不在根元素之外),则它们将被插入到树中。Comment()ProcessingInstruction()
关闭( )
刷新构建器缓冲区,并返回顶级文档元素。返回一个Element实例。
数据(数据)
向当前元素添加文本。 数据是一个字符串。这应该是字节串或 Unicode 字符串。
结束(标签)
关闭当前元素。 tag是元素名称。返回闭合元素。
开始(标签,属性)
打开一个新元素。 tag是元素名称。 attrs是包含元素属性的字典。返回打开的元素。
评论(文字)
使用给定的文本创建评论。如果insert_comments为真,这也会将其添加到树中。
3.8 版本中的新功能。
pi (目标,文本)
使用给定的目标名称和文本创建注释。如果 insert_pis为真,这也会将其添加到树中。
3.8 版本中的新功能。
此外,自定义TreeBuilder对象还可以提供以下方法:
doctype (名称, pubid ,系统)
处理文档类型声明。 name是文档类型名称。 pubid是公共标识符。 system是系统标识符。默认类中不存在此方法TreeBuilder。
3.2 版本中的新功能。
start_ns (前缀, uri )
每当解析器遇到新的命名空间声明时,在start()定义它的开始元素的回调之前调用。 前缀用于''默认命名空间,否则为声明的命名空间前缀名称。 uri是命名空间 URI。
3.8 版本中的新功能。
end_ns (前缀)
end()在声明命名空间前缀映射的元素的回调之后调用,其中前缀的名称超出了范围。
3.8 版本中的新功能。
xml.etree.ElementTree类 。C14NWriterTarget ( write , * , with_comments = False , strip_text = False , rewrite_prefixes = False , qname_aware_tags = None , qname_aware_attrs = None , except_attrs = None , except_tags = None )
C14N 2.0作家。参数与函数相同canonicalize()。该类不构建树,而是使用write函数将回调事件直接转换为序列化形式。
3.8 版本中的新功能。
4.4.6 XMLParser 对象
xml.etree.ElementTree类 。XMLParser ( * ,目标= None ,编码= None )
此类是模块的低级构建块。它用于 xml.parsers.expat高效、基于事件的 XML 解析。它可以使用该方法增量地提供 XML 数据,并且通过调用目标feed()对象上的回调将解析事件转换为推送 API 。如果省略目标,则使用标准。如果给出编码1 ,则该值将覆盖 XML 文件中指定的编码。TreeBuilder
版本 3.8 中已更改:参数现在仅包含关键字。不再支持html参数。
关闭( )
完成向解析器提供数据。返回调用构造时传递的目标close()方法的结果 ;默认情况下,这是顶级文档元素。
提要(数据)
将数据提供给解析器。 数据是编码数据。
XMLParser.feed()为每个开始标记调用target的方法,为每个结束标记调用 target 的方法,并通过 method 处理数据。有关更多支持的回调方法,请参阅该类。 调用 目标的方法。不仅可以用于构建树结构。这是计算 XML 文件最大深度的示例:start(tag, attrs_dict)end(tag)data(data)TreeBuilderXMLParser.close()close()XMLParser
>>> from xml.etree.ElementTree import XMLParser
>>> class MaxDepth: # The target object of the parser
... maxDepth = 0
... depth = 0
... def start(self, tag, attrib): # Called for each opening tag.
... self.depth += 1
... if self.depth > self.maxDepth:
... self.maxDepth = self.depth
... def end(self, tag): # Called for each closing tag.
... self.depth -= 1
... def data(self, data):
... pass # We do not need to do anything with data.
... def close(self): # Called when all data has been parsed.
... return self.maxDepth
...
>>> target = MaxDepth()
>>> parser = XMLParser(target=target)
>>> exampleXml = """
... <a>
... <b>
... </b>
... <b>
... <c>
... <d>
... </d>
... </c>
... </b>
... </a>"""
>>> parser.feed(exampleXml)
>>> parser.close()
4
4.4.7 XMLPullParser 对象
xml.etree.ElementTree类 。XMLPullParser (事件=无)
适合非阻塞应用程序的拉式解析器。它的输入端 API 与 的类似XMLParser,但不是将调用推送到回调目标,而是XMLPullParser收集解析事件的内部列表并让用户从中读取。events是要报告的一系列事件。支持的事件是字符串"start"、"end"、 "comment"、"pi"和"start-ns"("end-ns"“ns”事件用于获取详细的命名空间信息)。如果省略事件"end",则仅报告事件。
提要(数据)
将给定的字节数据提供给解析器。
关闭( )
向解析器发出数据流已终止的信号。与此不同的是 XMLParser.close(),此方法总是返回None。解析器关闭时尚未检索到的任何事件仍可以使用 读取read_events()。
读取事件( )
返回在馈送到解析器的数据中遇到的事件的迭代器。迭代器产生对,其中event是表示事件类型的字符串(例如) , elem是遇到的对象或其他上下文值,如下所示。(event, elem)"end"Element
-
start,end:当前元素。 -
comment,pi: 当前注释/处理指令 -
start-ns:命名已声明的命名空间映射的元组。(prefix, uri) -
end-ns:(None这可能会在未来版本中改变)
先前调用中提供的事件read_events()将不会再次产生。仅当从迭代器检索事件时,才会从内部队列消耗事件,因此多个读取器并行迭代从中获取的迭代器read_events()将产生不可预测的结果。
笔记
XMLPullParser仅保证在发出“start”事件时看到起始标记的“>”字符,因此属性已定义,但此时 text 和 tail 属性的内容未定义。这同样适用于元素子元素;他们可能在场,也可能不在场。
如果您需要完全填充的元素,请查找“结束”事件。
3.4 版本中的新功能。
版本 3.8 中进行了更改:comment添加pi了 和 事件。
4.4.8 例外情况
xml.etree.ElementTree类 。解析错误
XML 解析错误,当解析失败时由该模块中的各种解析方法引发。此异常实例的字符串表示形式将包含用户友好的错误消息。此外,它将具有以下可用属性:
代码
来自 expat 解析器的数字错误代码。xml.parsers.expat有关错误代码及其含义的列表,请参阅 的文档 。
位置
行号、列号的元组,指定错误发生的位置。
脚注
xml.etree.ElementTree — The ElementTree XML API — Python 3.12.0 documentation