在进行自然语言处理、文本分类聚类、推荐系统、舆情分析等研究中,通常需要使用新浪微博的数据作为语料,这篇文章主要介绍如果使用Python和Selenium爬取自定义新浪微博语料。因为网上完整的语料比较少,而使用Selenium方法有点简单、速度也比较慢,但方法可行,同时能够输入验证码。希望文章对你有所帮助~
源码下载地址:http://download.csdn.net/detail/eastmount/9501273
爬取结果
首先可以爬取用户ID、用户名、微博数、粉丝数、关注数及微博信息。其中微博信息包括转发或原创、点赞数、转发数、评论数、发布时间、微博内容等等。如下图所示: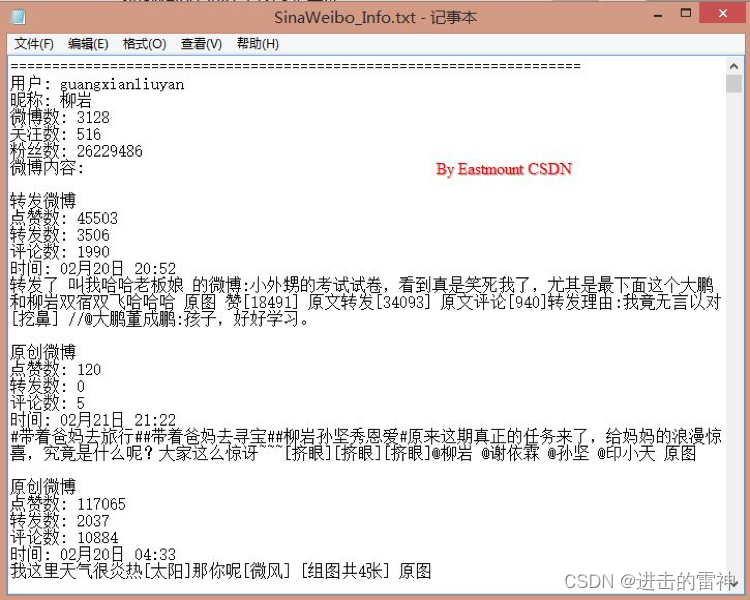
同时也可以爬取微博的众多用户的详细信息,包括基本信息、关注人ID列表和粉丝ID列表等等。如下图所示:
登录入口
新浪微博登录常用接口:新浪通行证登录
对应主界面: