Django
- 1 了解简介
- 2 Django项目结构
- 3 url 地址 和视图函数
- 4 路由配置
- 5 请求及响应
- 6 GET请求和POST请求
- 查询字符串
- 7 Django设计模式及模板层
- 8 模板层-变量和标签
- 9 模板层-过滤器和继承
- 继承 重写
- 10 url反向解析
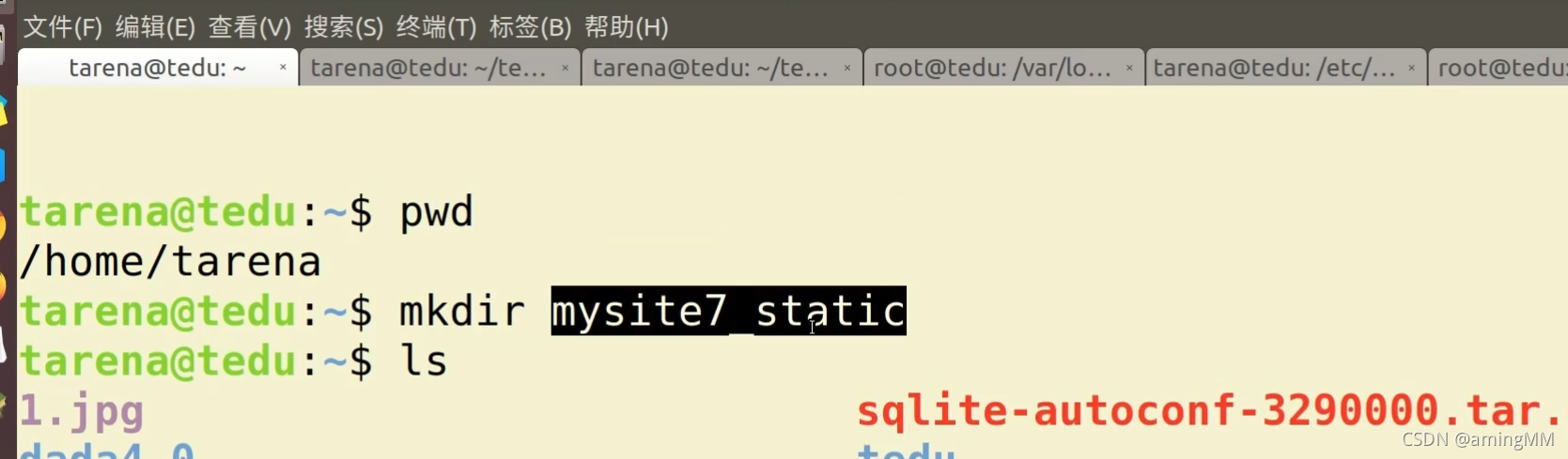
- 11 静态文件
- 12 Django 应用及分布式路由
- 创建之后 注册 一下
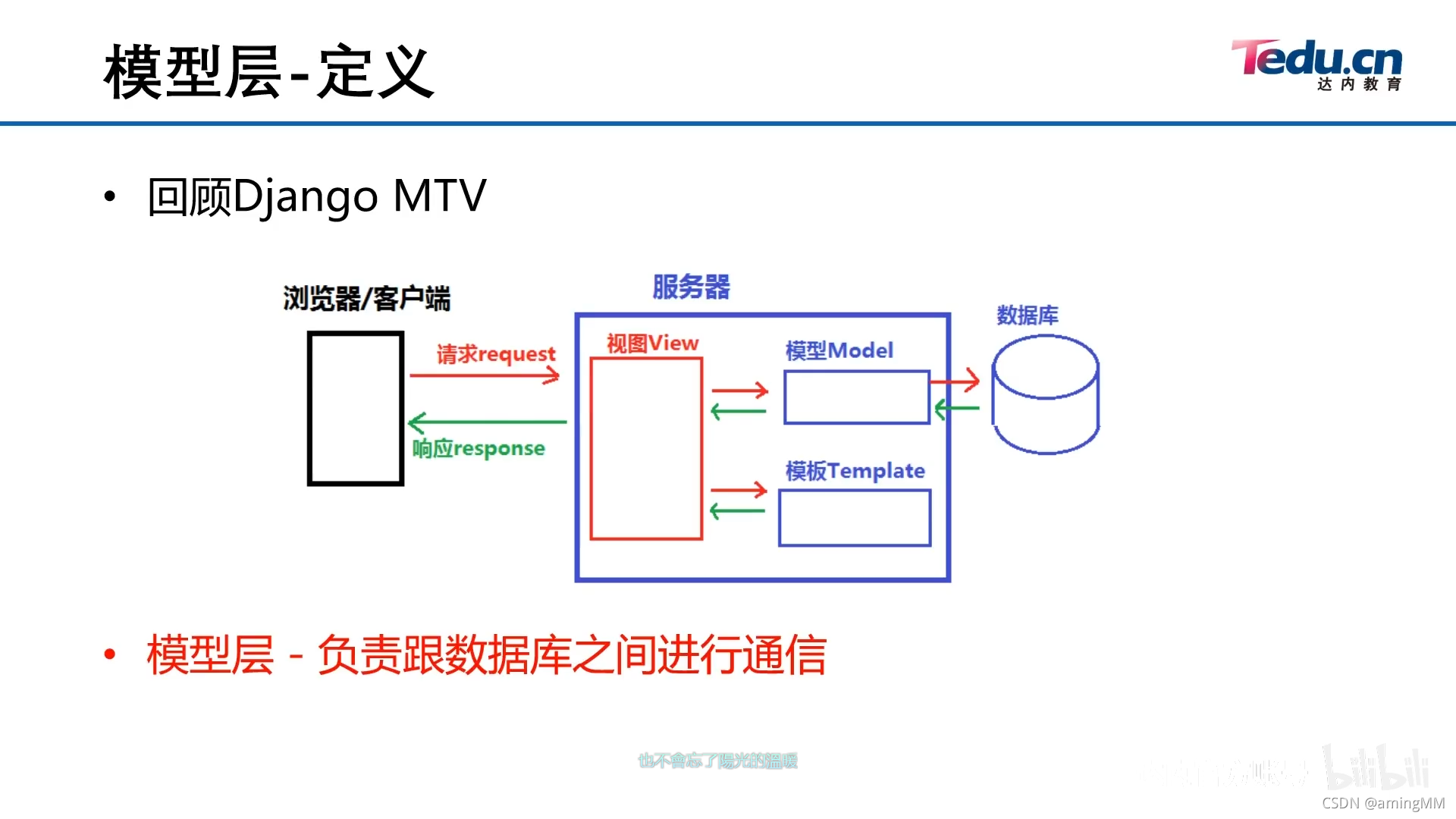
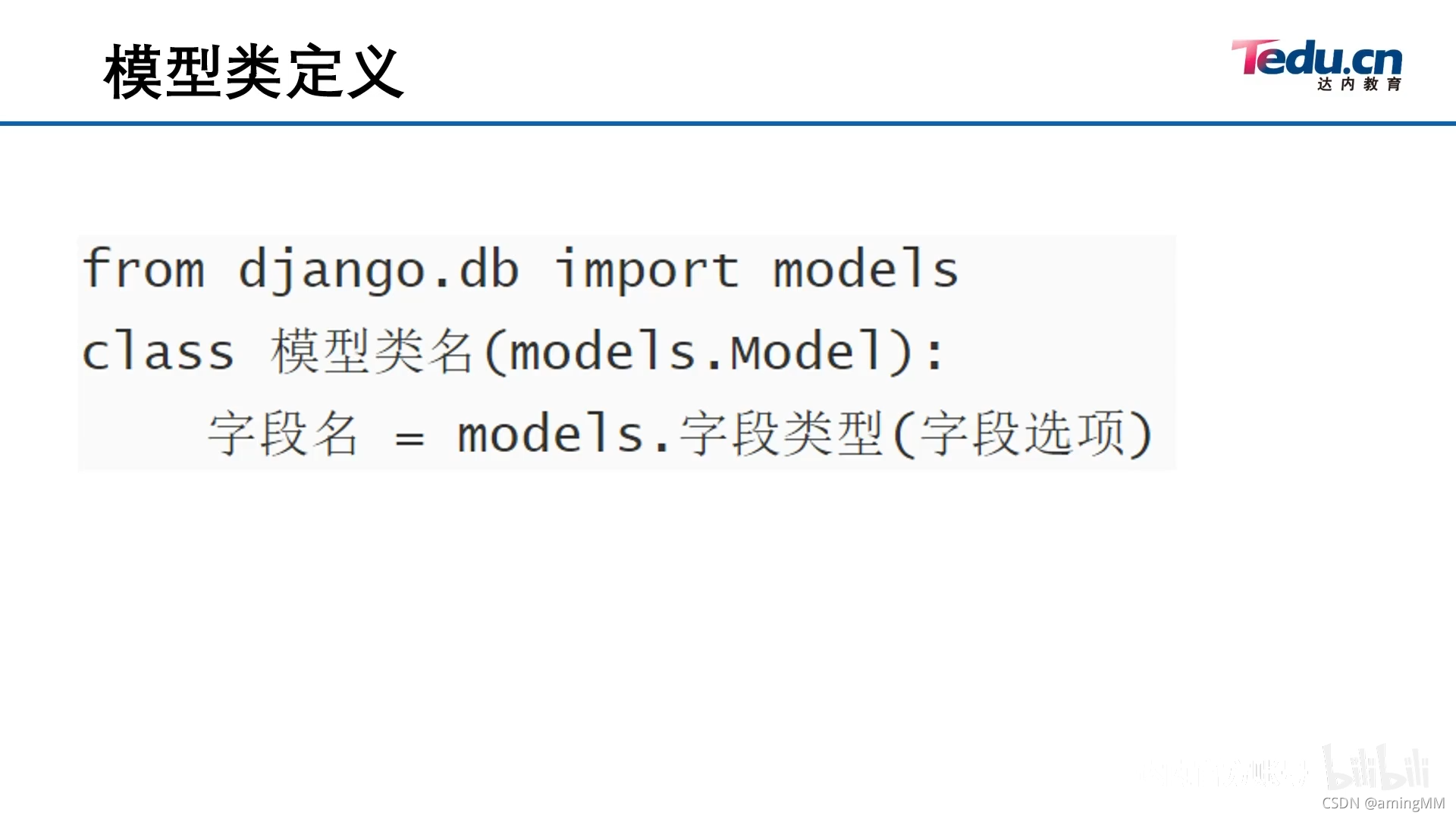
- 13 模型层及ORM介绍
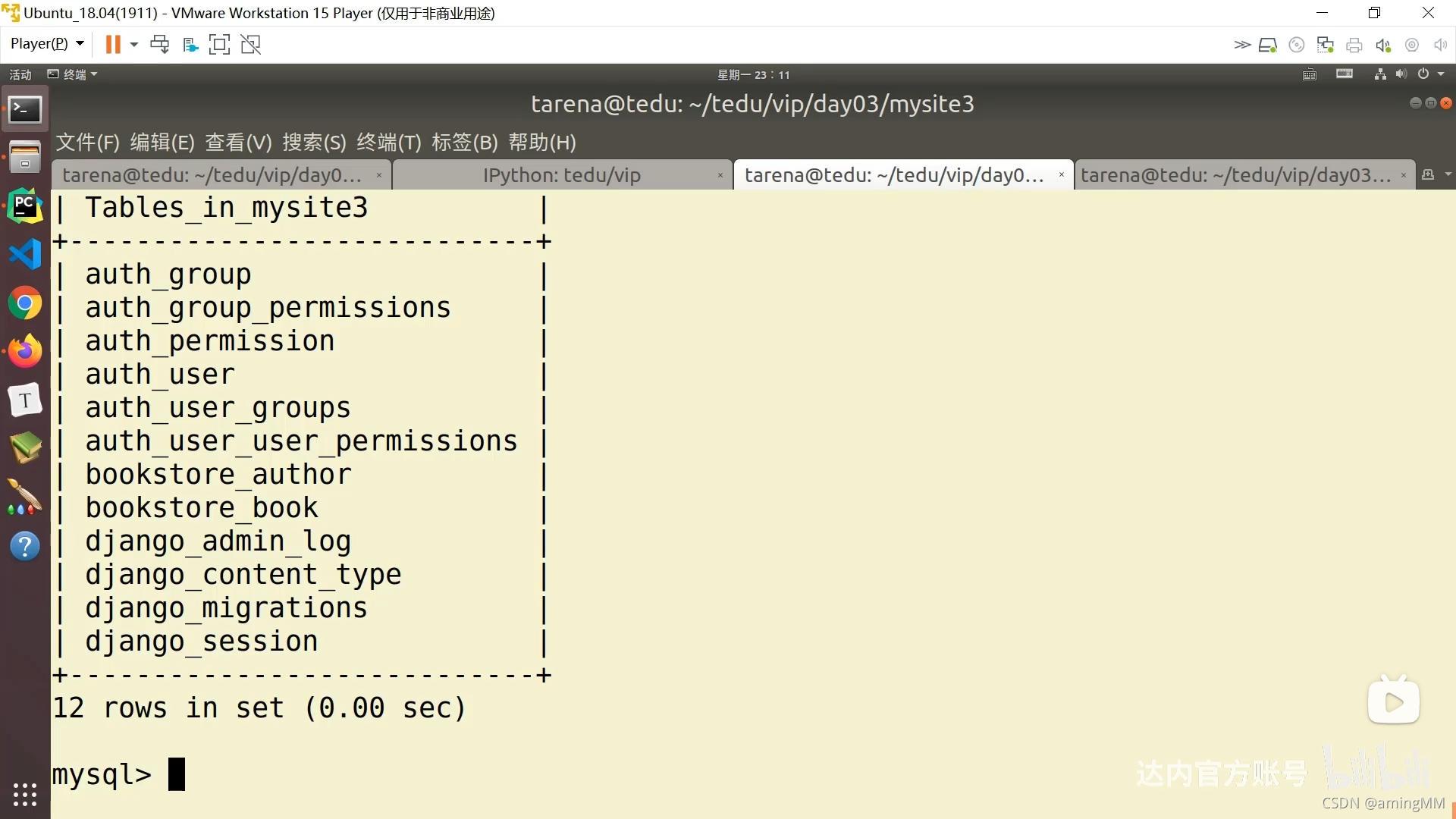
- 同步表结构
- 默认 初始化 id 自增
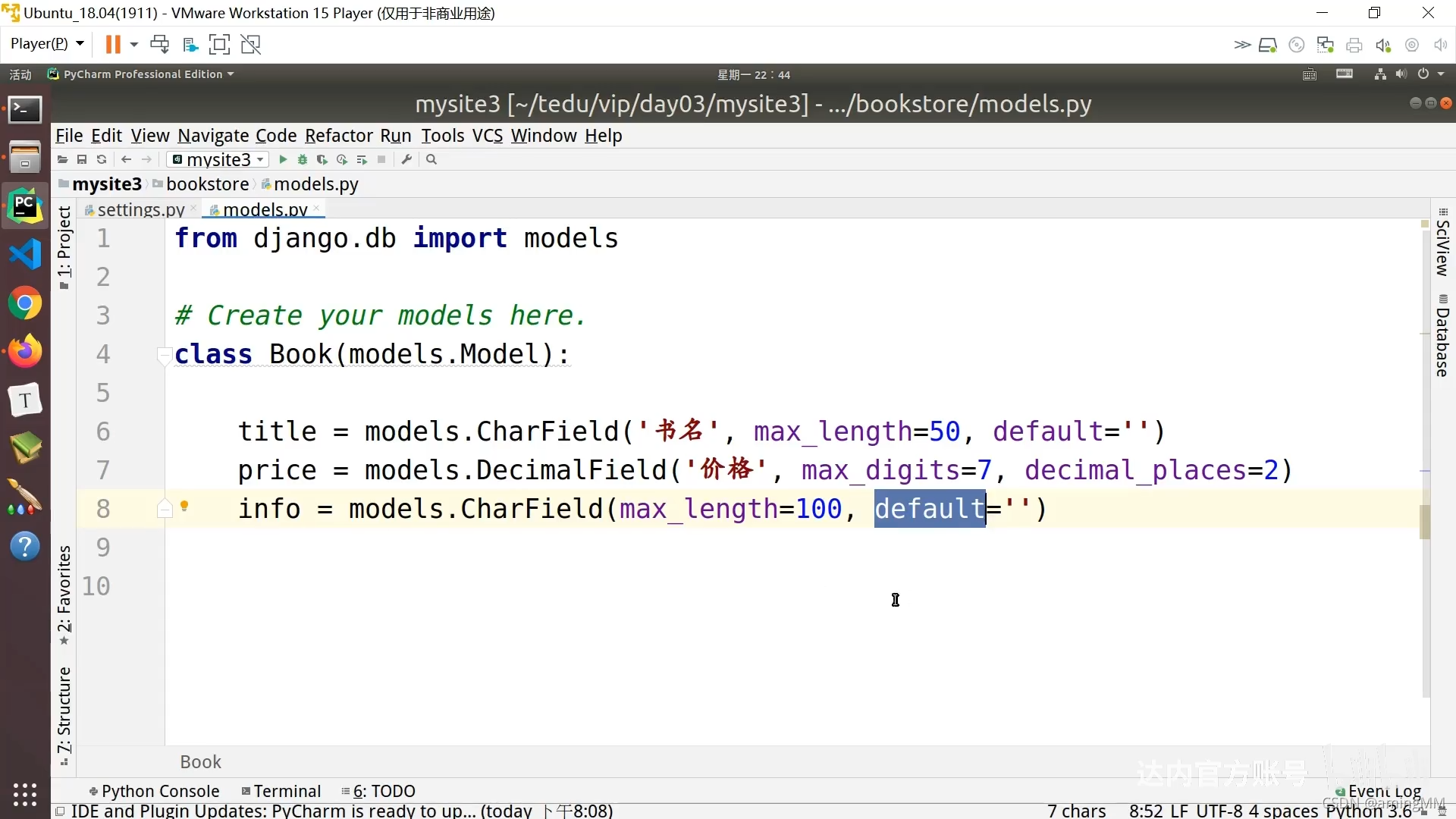
- 14 ORM-基础字段及选项
- django 模型models 常用字段
- 布尔型
- 变长字符
- 继承 Model 类属性
- 表明 app_模型类名
- 表 列 字段
- 15 ORM-基本操作-创建数据
- python3.7 mysql 部署 问题
- 只执行 增量 文件
- 对象 初始化 再 save
- 引進模型類
- P16 ORM-查询操作
- 模型 類 數組 循環 索引 切片 的 操作
- 類數組 [ <Object (id) > , ...... ]
- 不再是 类的 实例化对象 object
- 取值 用 字典 取 key 的 这种方式
- 元组 用 索引取值
- .all 的 排序 返回 object
- 灵活 组合 顺序 不用想
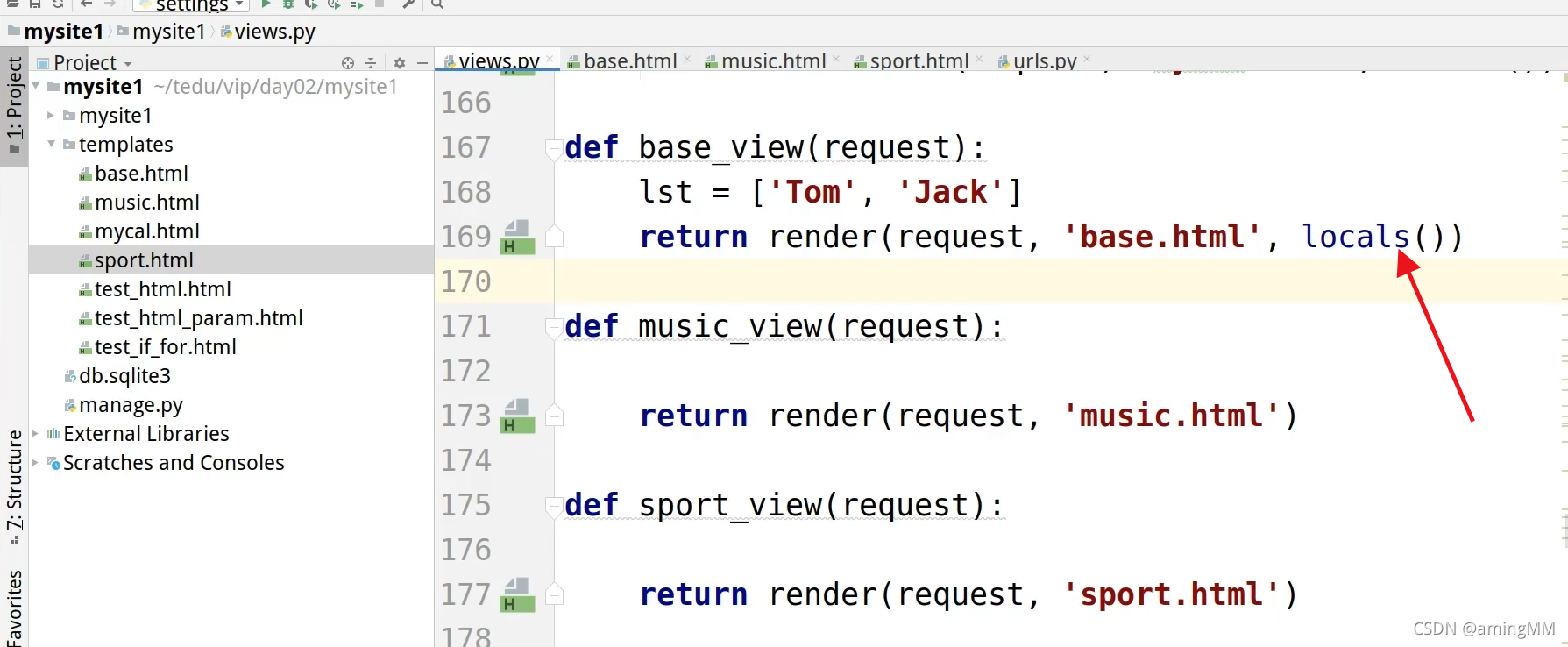
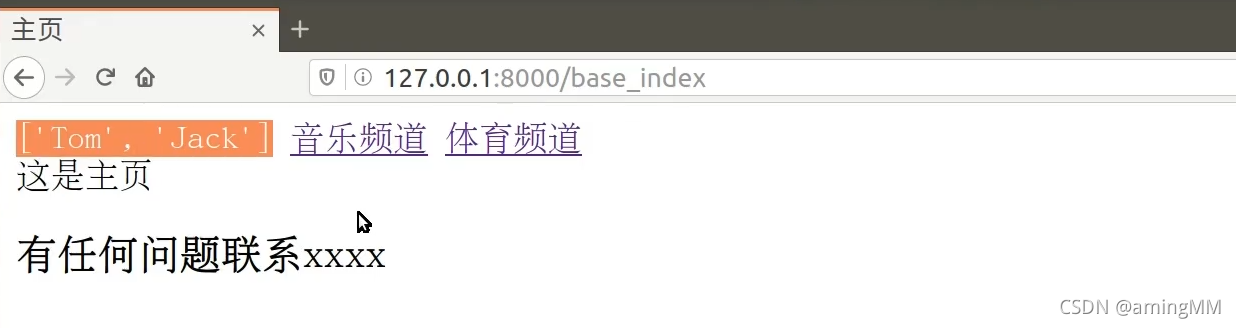
- locals 把 视图函数 的 局部变量 传到 视图里
- 结构 的 元素 表现形式 要注意 object 字典 元组
- 17 ORM-查询操作
- 条件查询
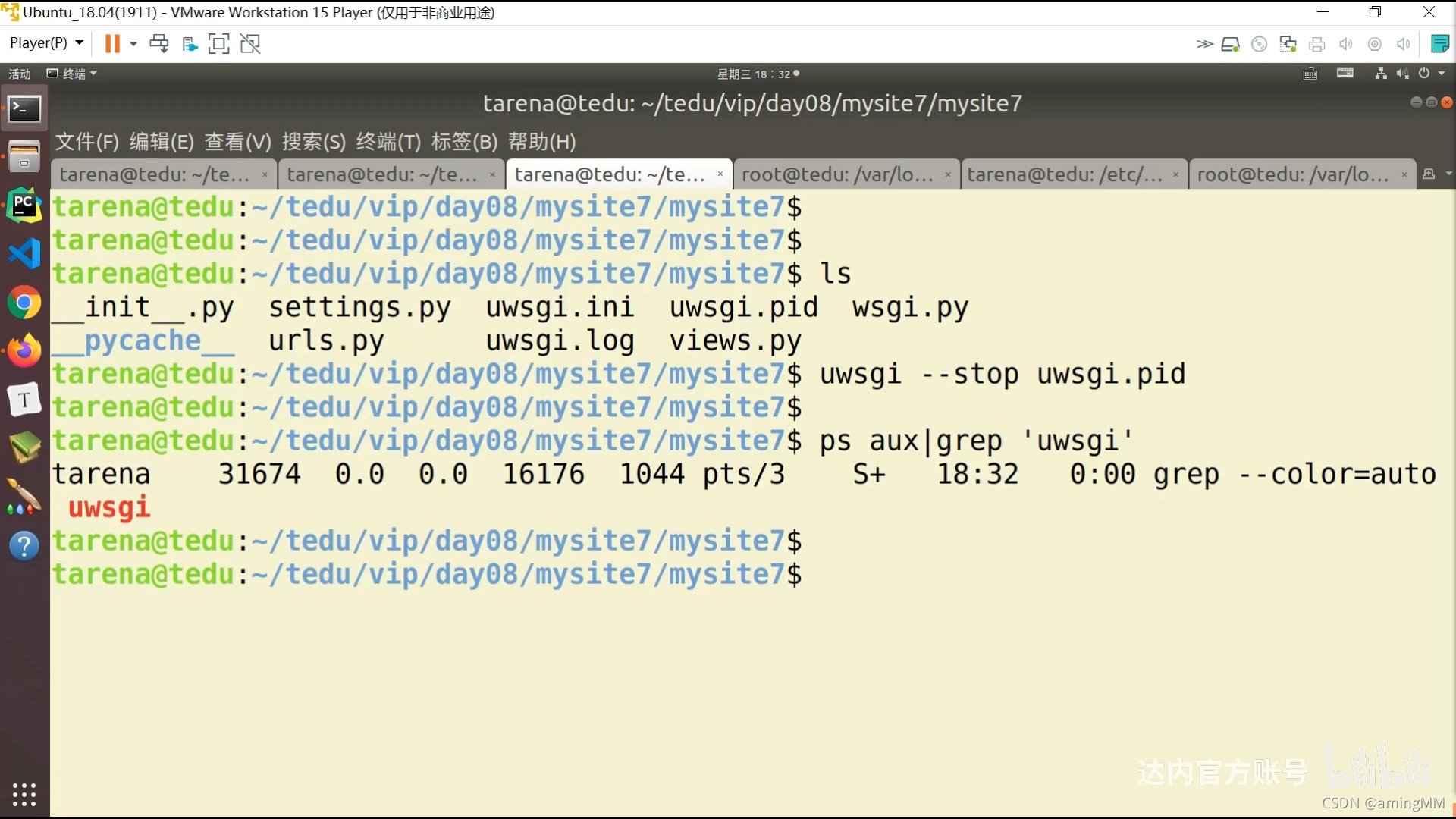
- P46 8.04-项目部署-uwsgi
- CentOS7安装uwsgi遇到的坑
- P47 8.05-项目部署-nginx
- 看日志
- P48 8.06-项目部署-nginx
- 关联查询
- on_delete参数的各个值的含义:
- Django常用的QuerySet操作
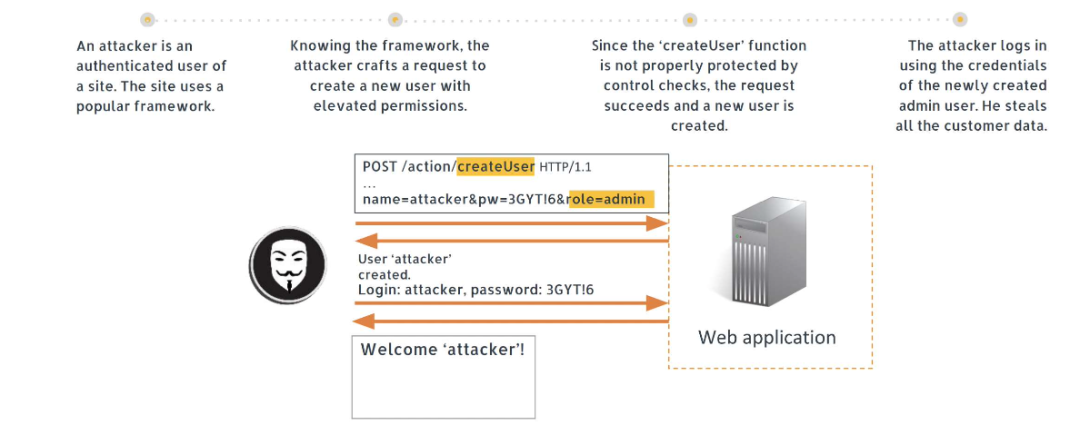
- 前后端分离跨域方案
- 跨域请求存在诸多安全问题,例如CSRF攻击等,
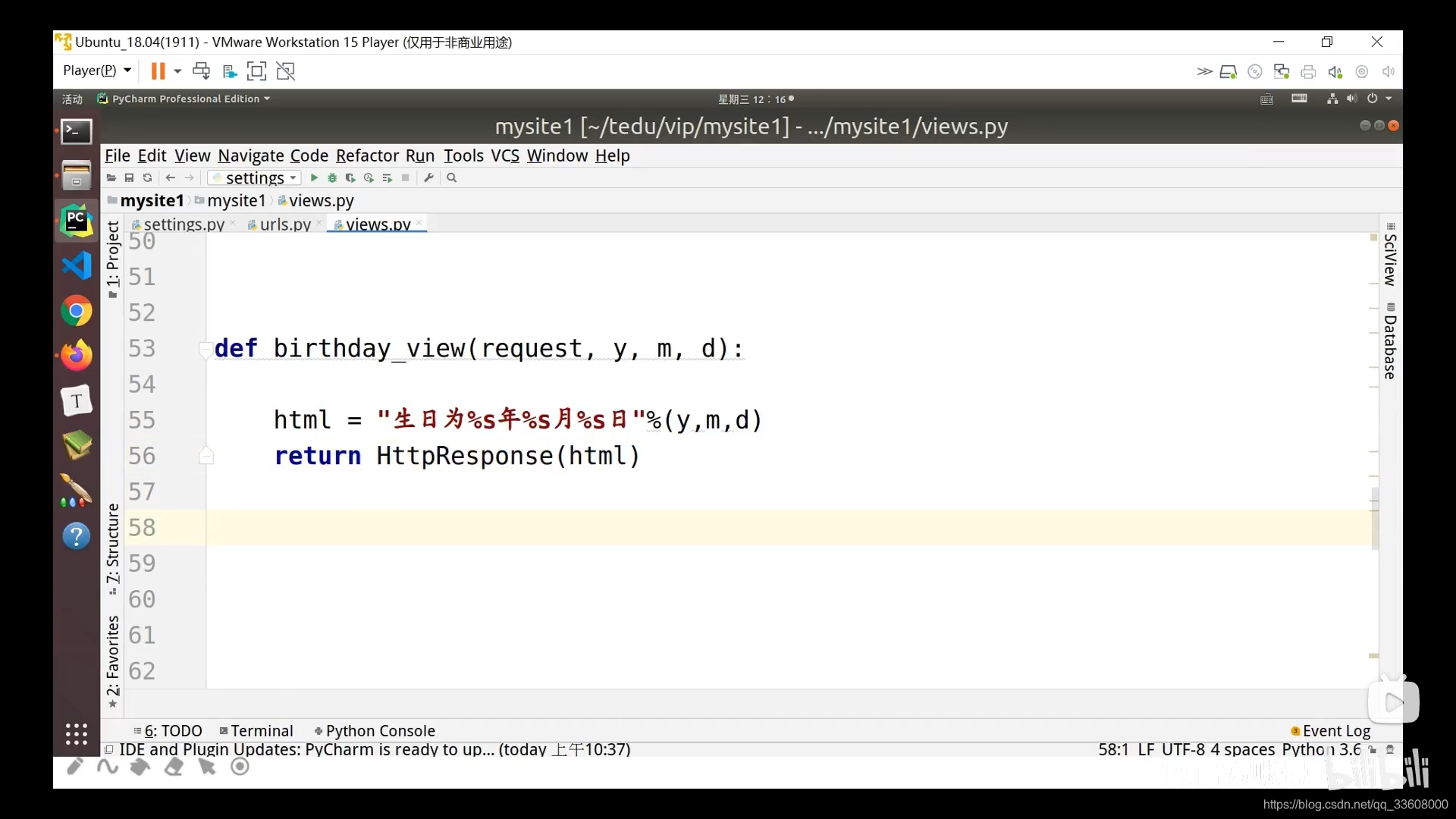
- 解决方案
- Django中如何使用CORS
- 打开cmd,执行命令:pip install django-cors-headers
- 修改django项目中的setting.py,
- centos django uwsgi 指定版本
- 系统版本
- 编译:
- 安装:
- 然后进行软链接、系统便能够识别uwsgi命令
- 使用Django生成验证码 并发送qq邮箱
https://www.bilibili.com/video/BV1vK4y1o7jH?from=search&seid=7358572781939588281
1 了解简介




flask 轻
手机游戏

请求响应 路由
MTV设计结构
HTTP状态的 cookie session











解释器 版本








2 Django项目结构

完善的 内部组件










ctrl shift T 新启终端



服务
地址 协议 状态码
前台服务 启动效果







默认数据库 存储 文件








项目目录
配置文件
路由文件
上线项目 运行文件

内置功能 运行规则 flask 就无
注意 格式


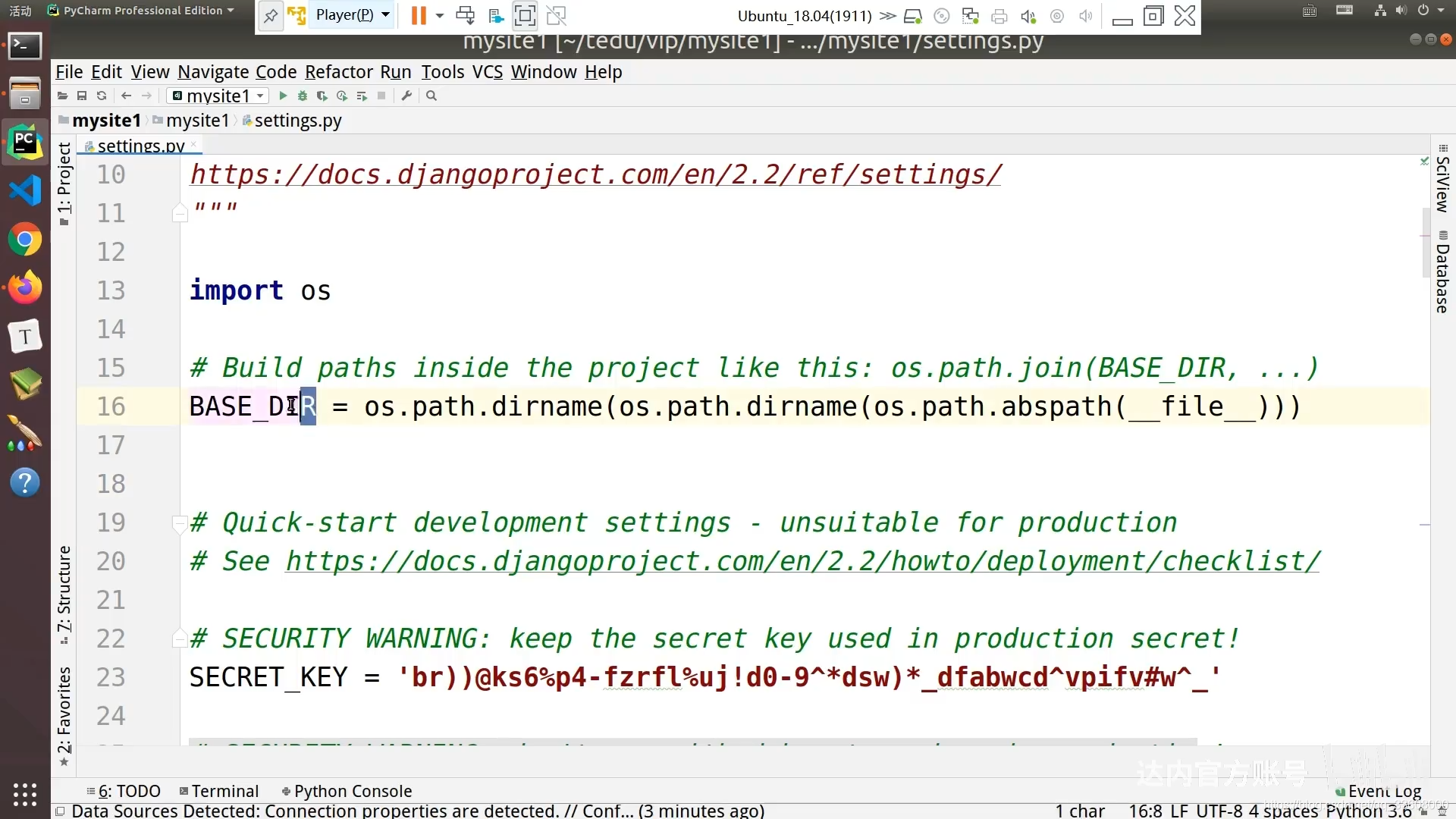

绝对路径

项目 绝对 路径






区分 虚拟网站 (一个 服务器 挂 好几个 网站 )




ctrl shift d 新建终端




应用

中间件

配置 主路由文件
模板


语言 配置
时区

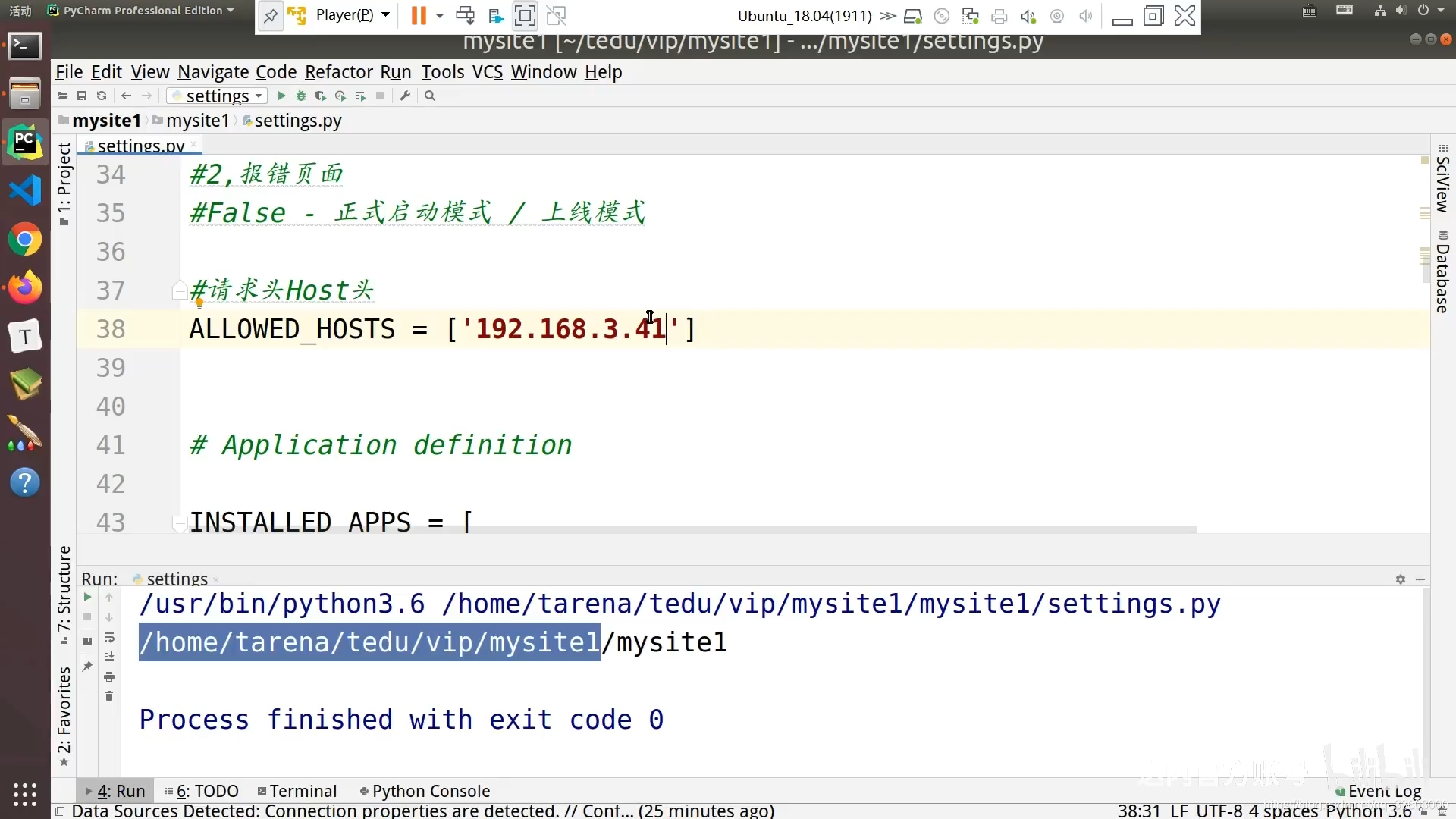
东八区 UTC/GMT+08:00




3 url 地址 和视图函数

协议 域名 ip 端口 路由 ?查询字符串 # 锚点








服务 在 主路由 中 配置好 参数 中 视图函数 写好
请求来了 就会有 相应的 响应

来个伪代码 顶替一下 视图函数


把 http 请求 抽象成 HTTPrequest 对象
给 request 函数

相对导入



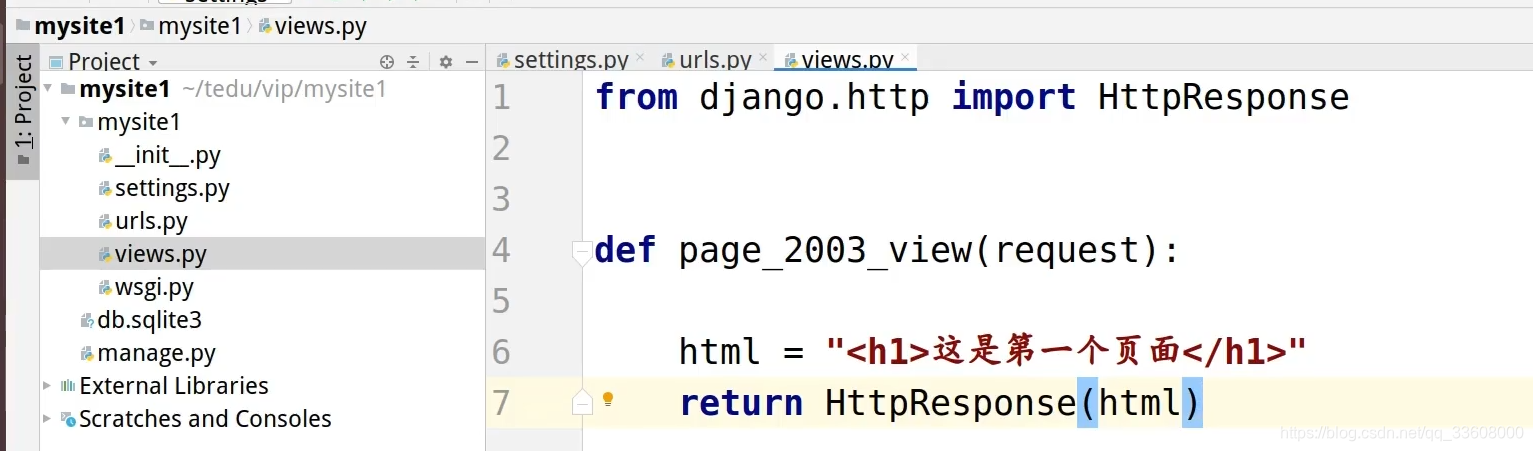
4 路由配置





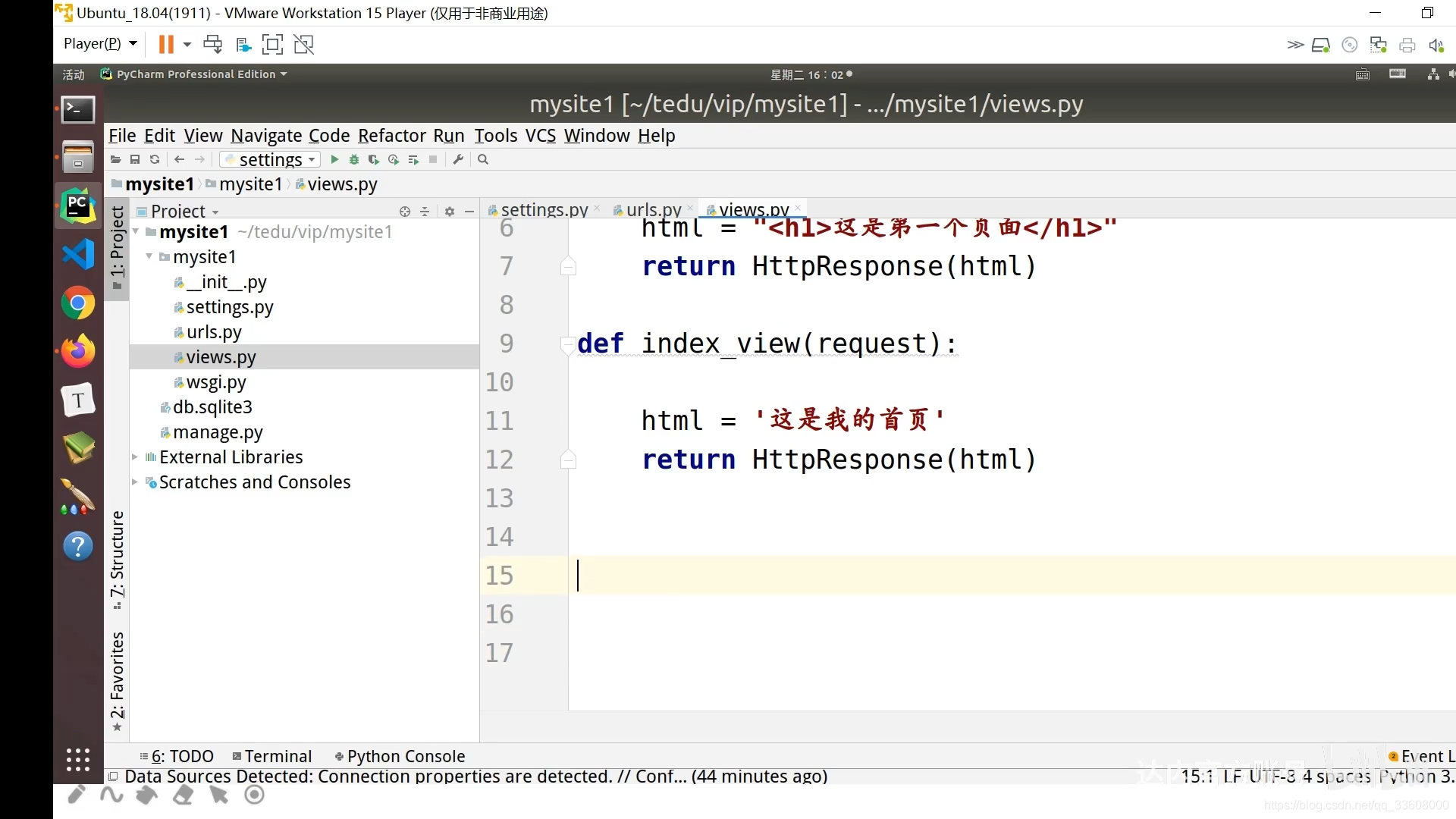







%s int + 字符串 %d

path 中 在 数组中 从上到下 匹配







\d 一到两位
\w+ 字符

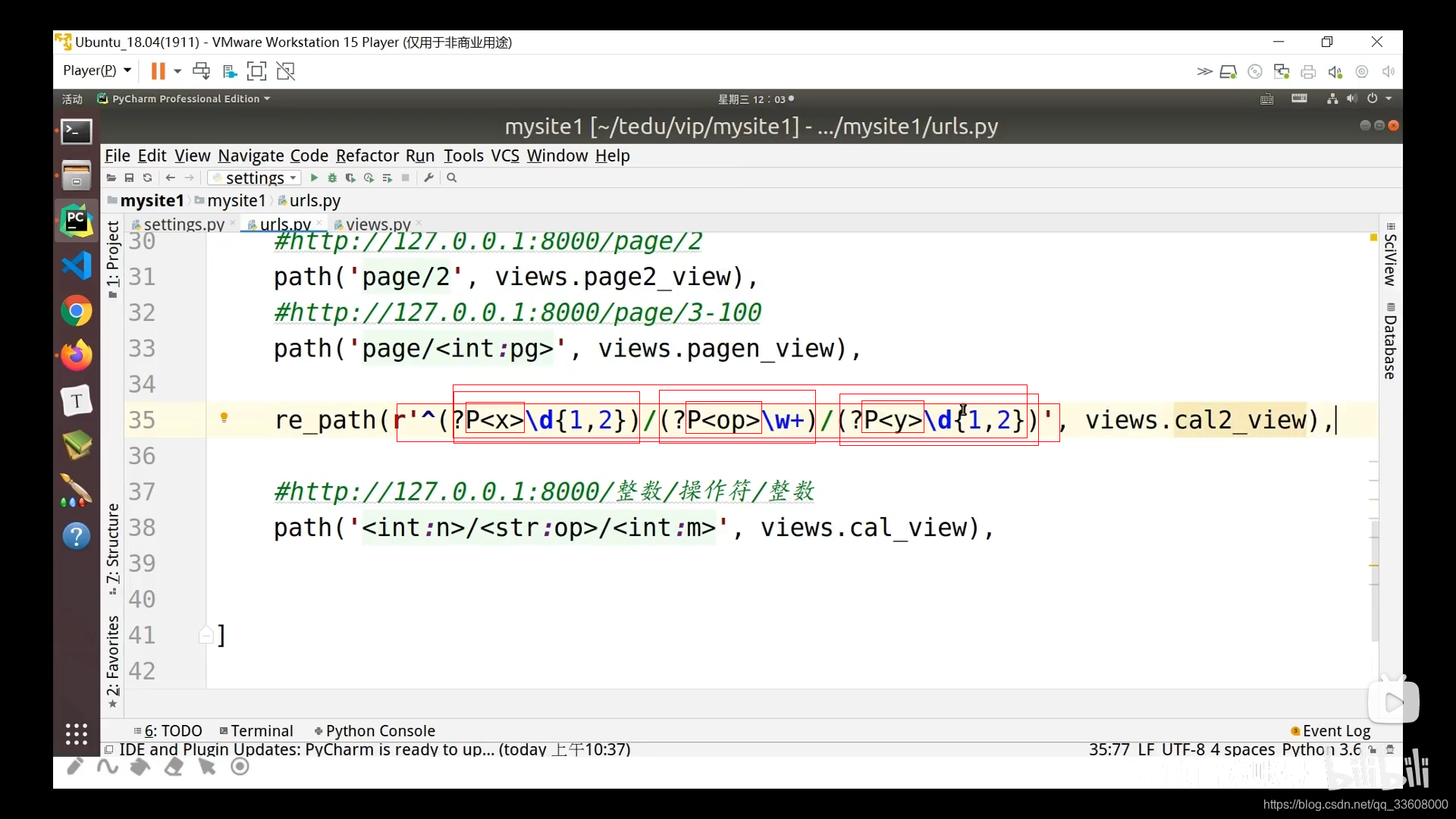







精准匹配



path <> path转换器
repath 升级版
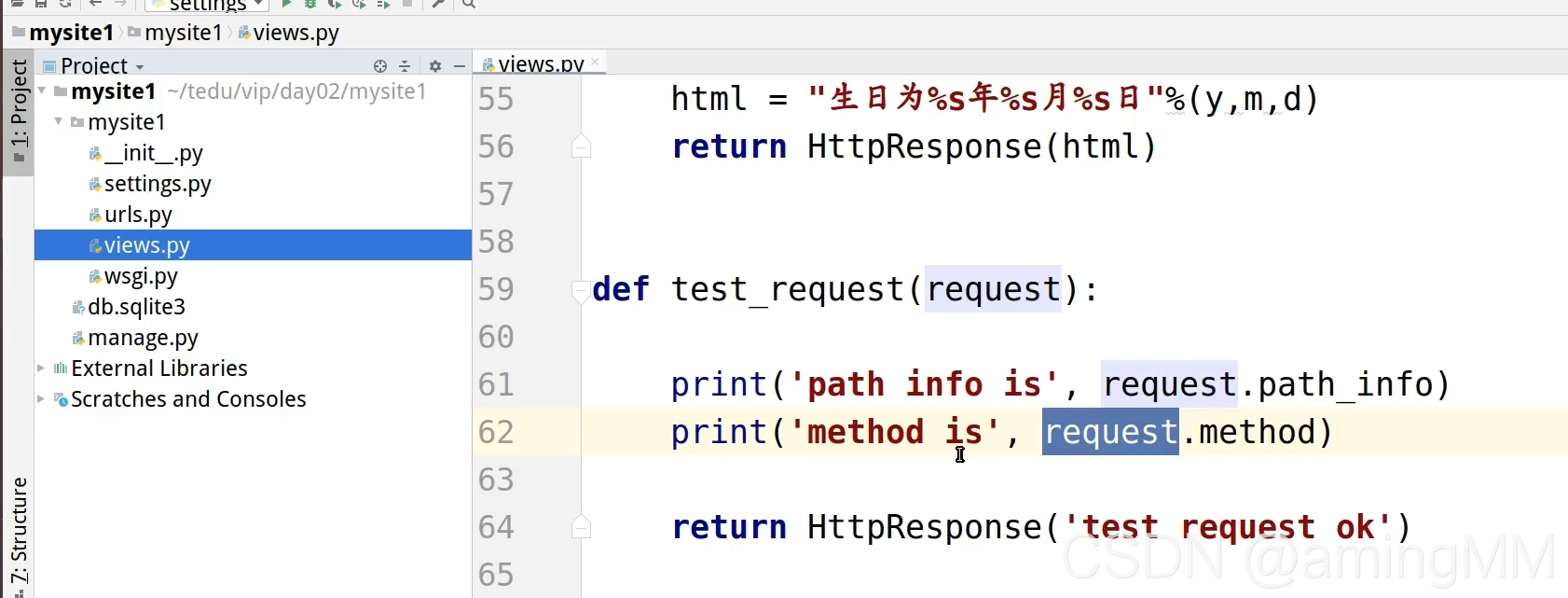
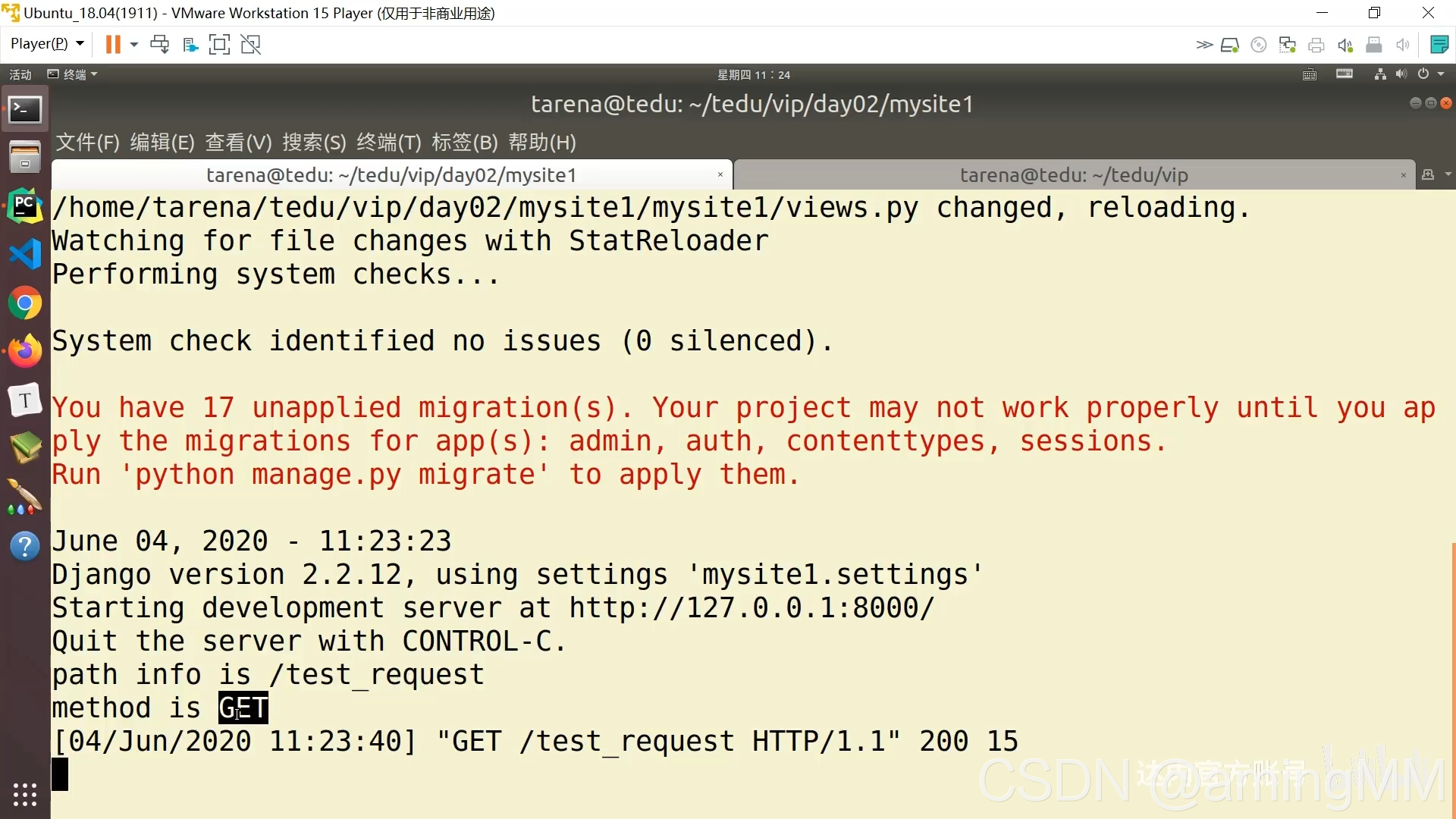
5 请求及响应




请求 路由 协议





增量开发



















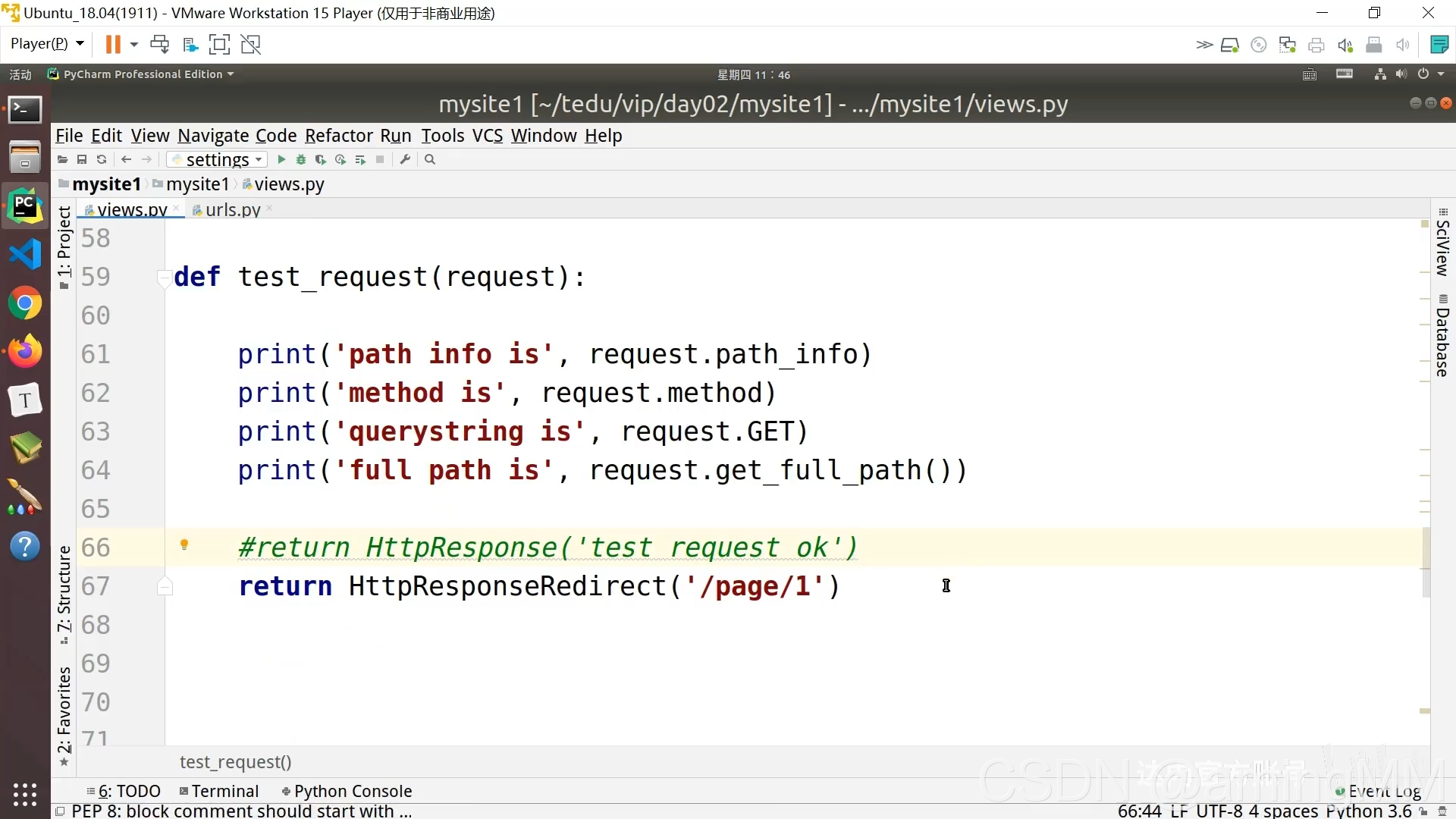

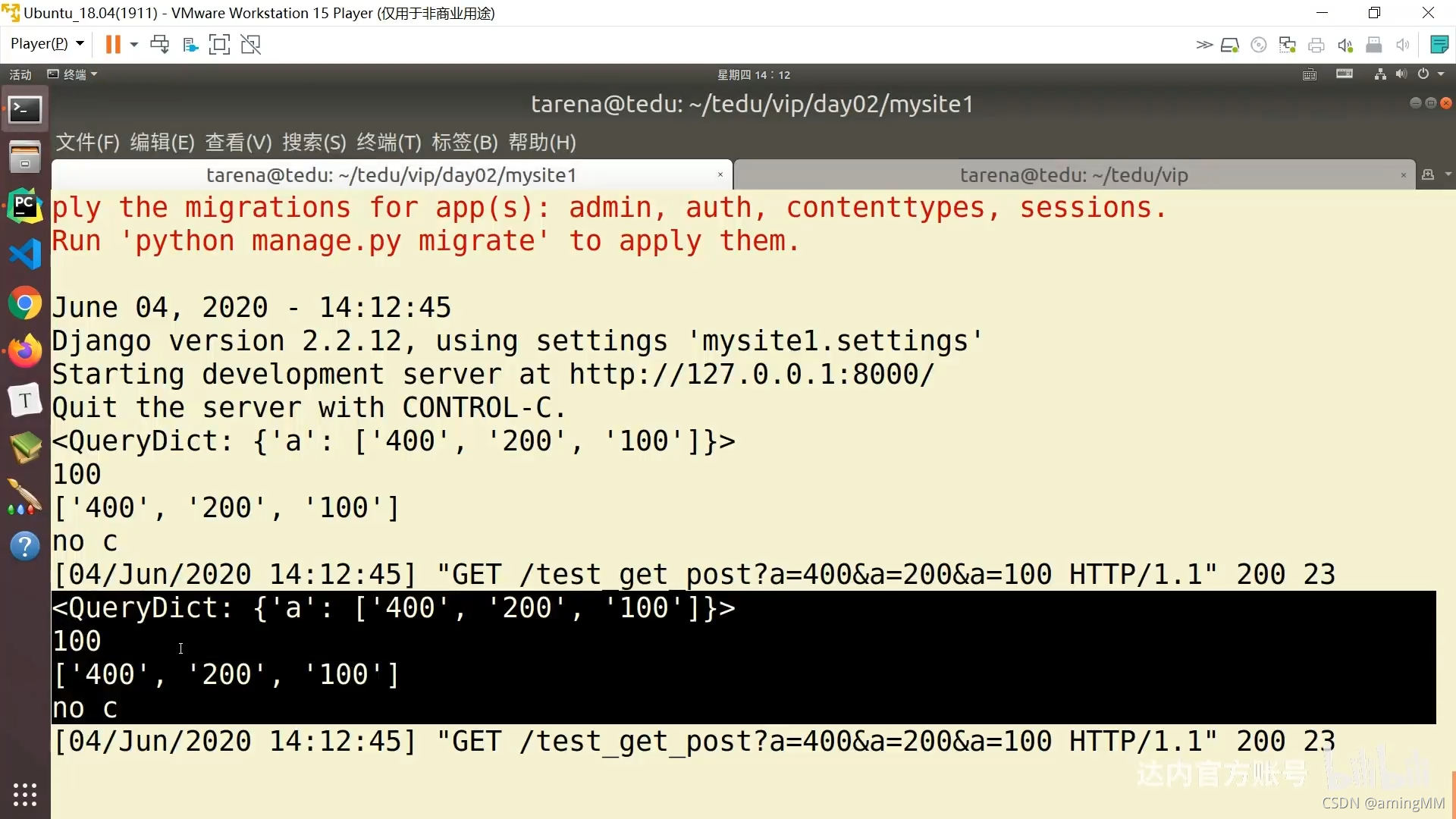
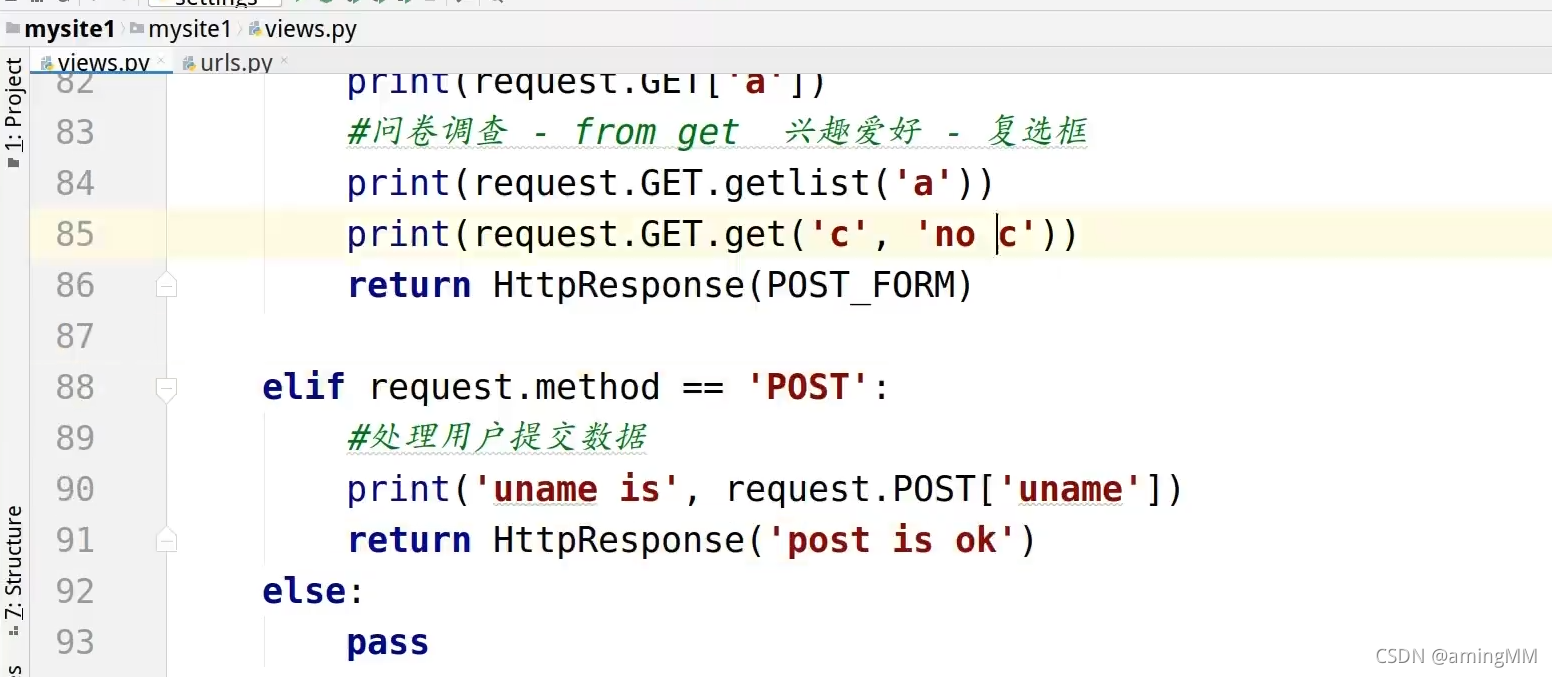
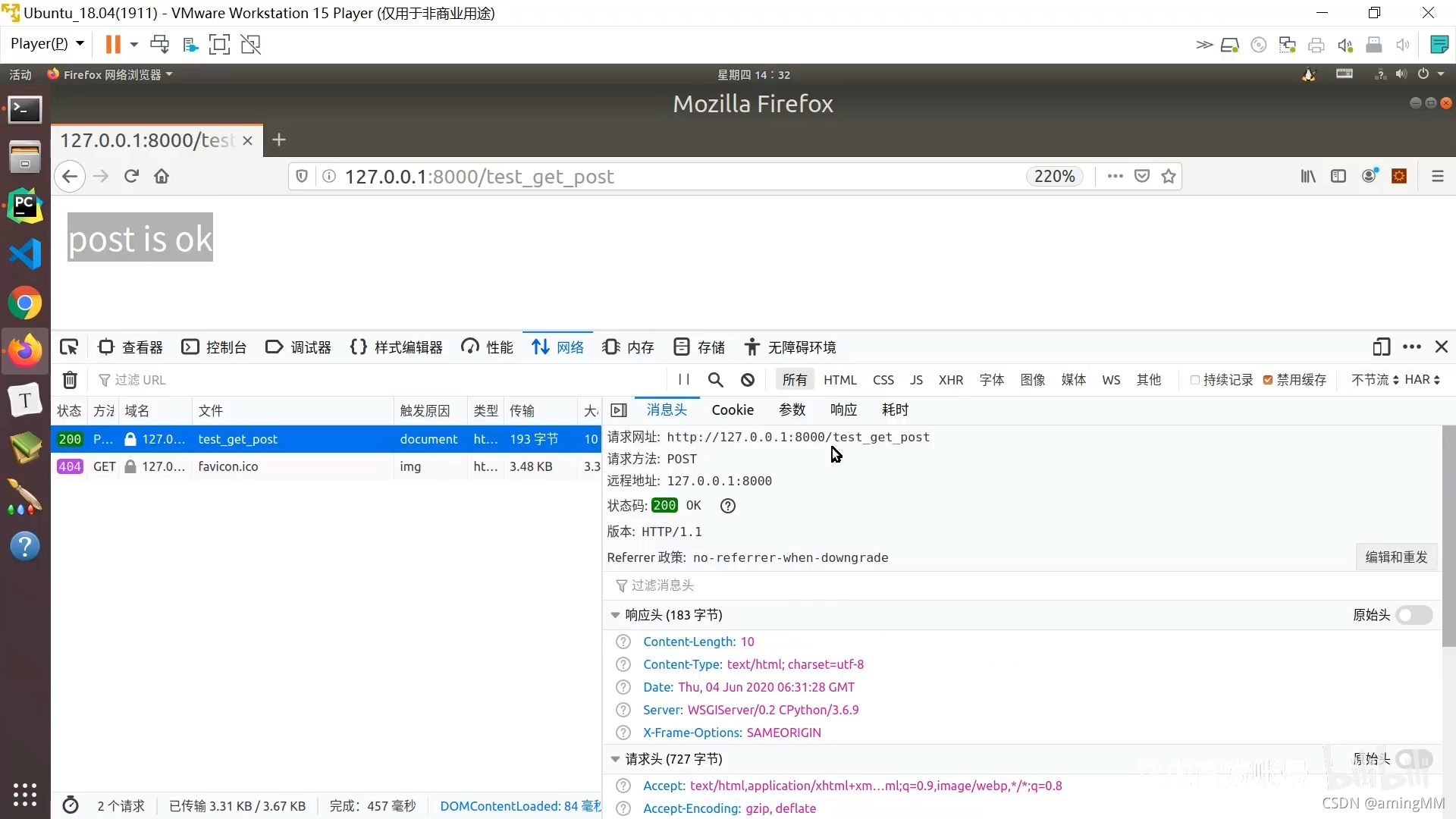
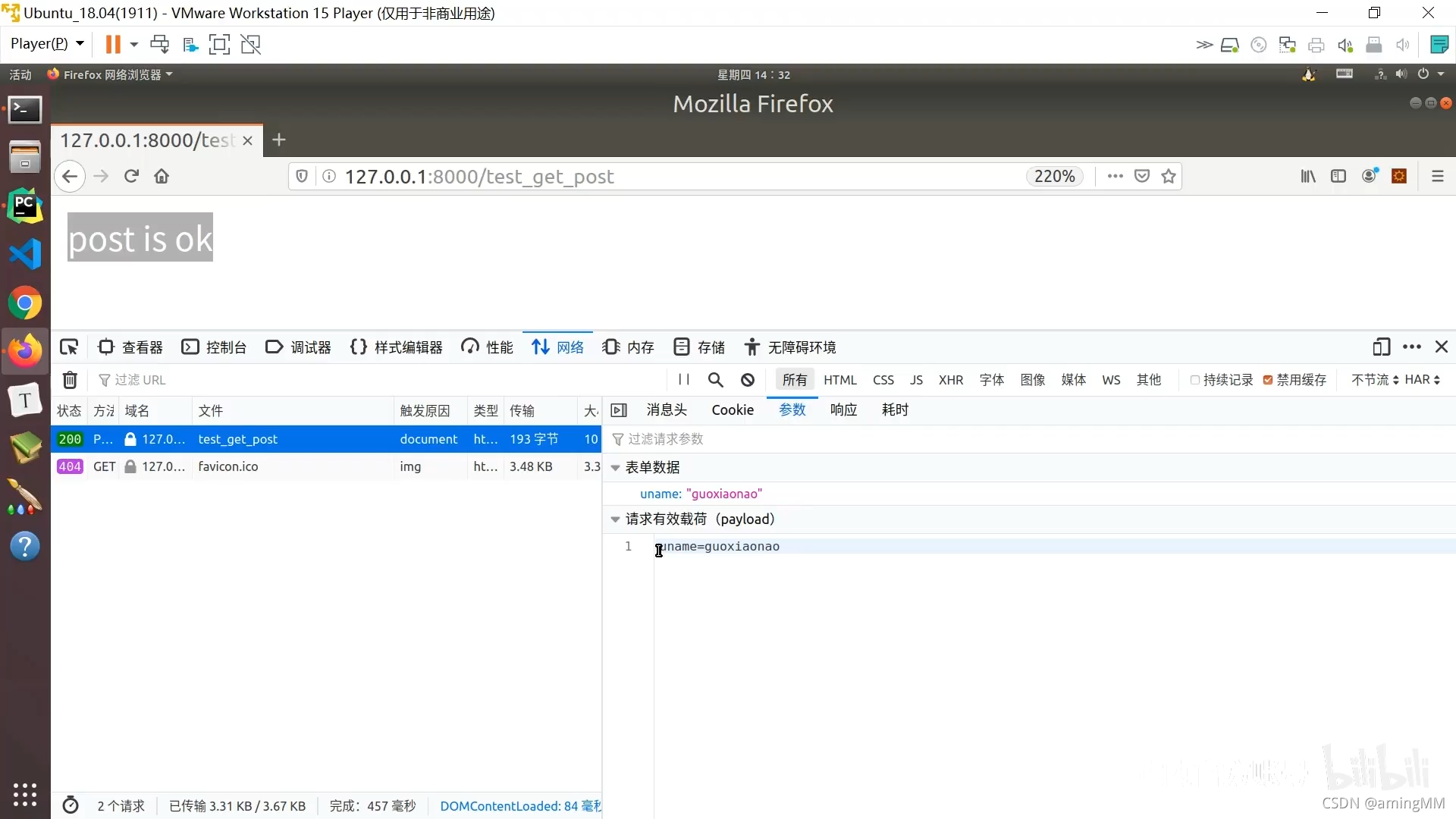
6 GET请求和POST请求


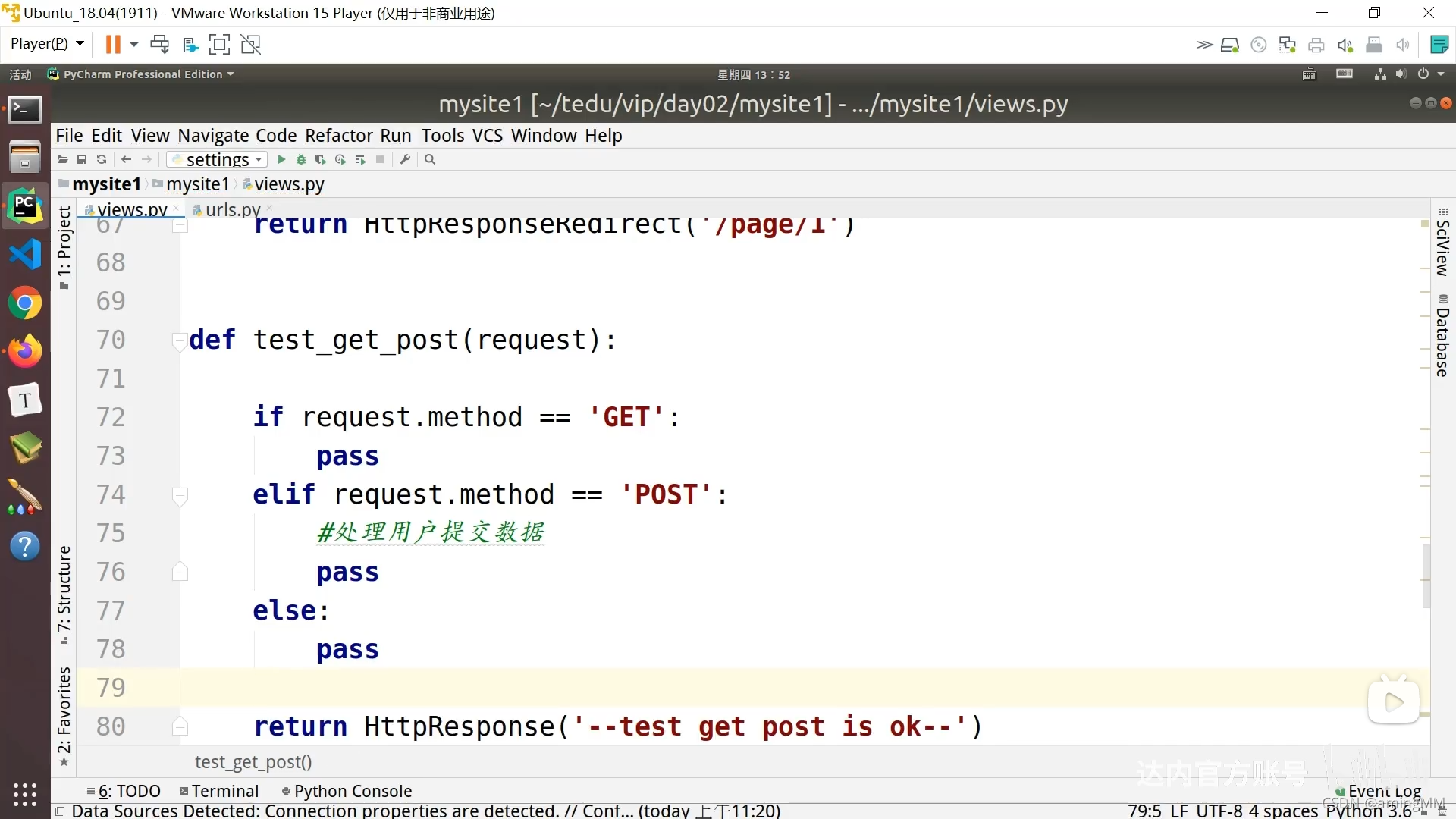


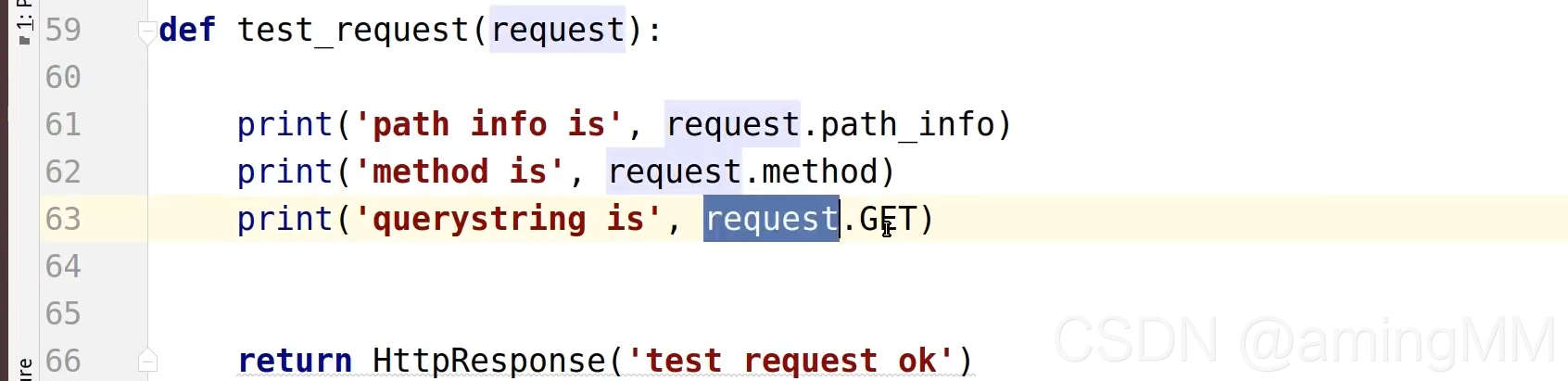
查询字符串
防止 明文传递 敏感数据

参数字典
get取值 默认值




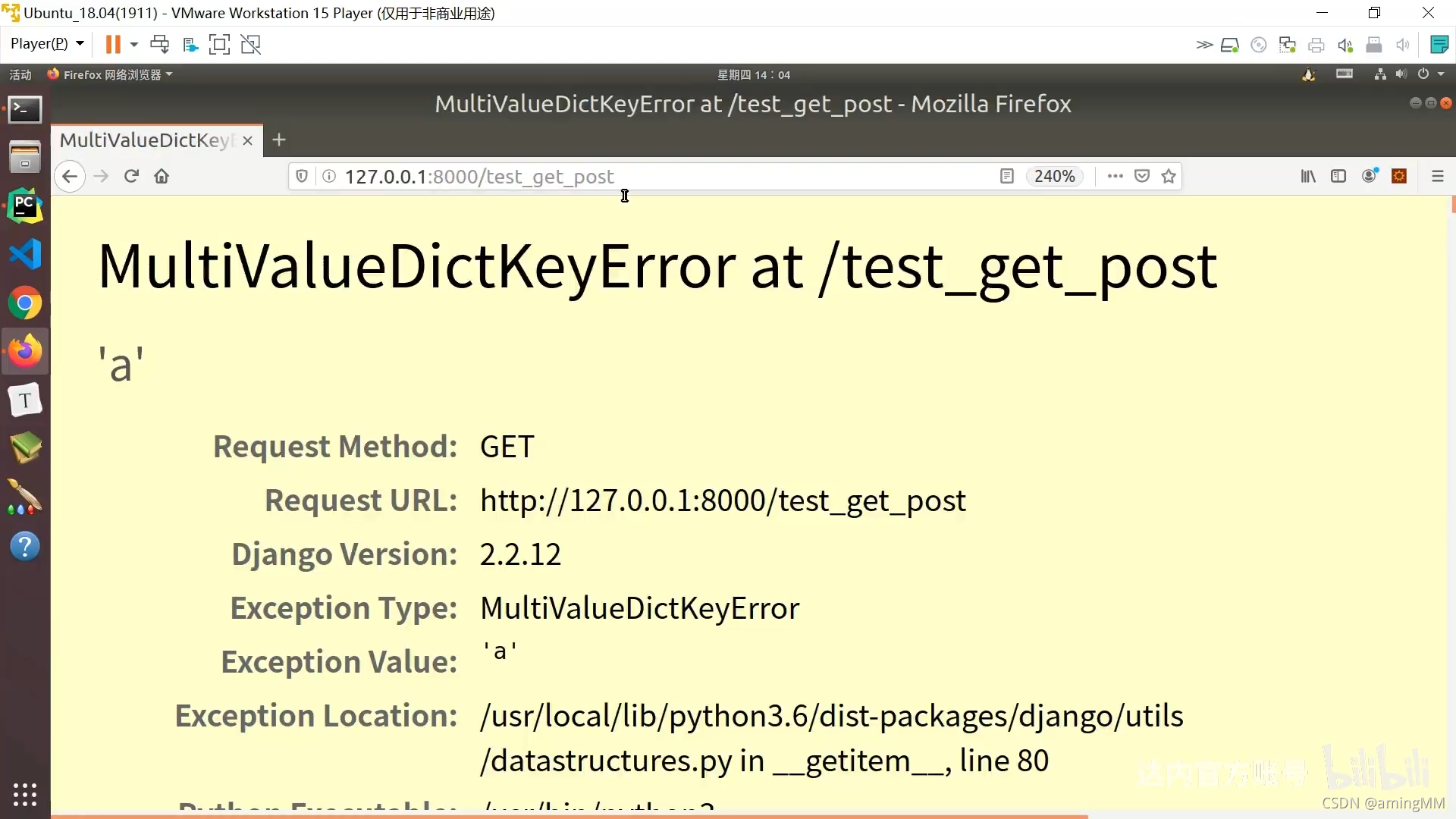
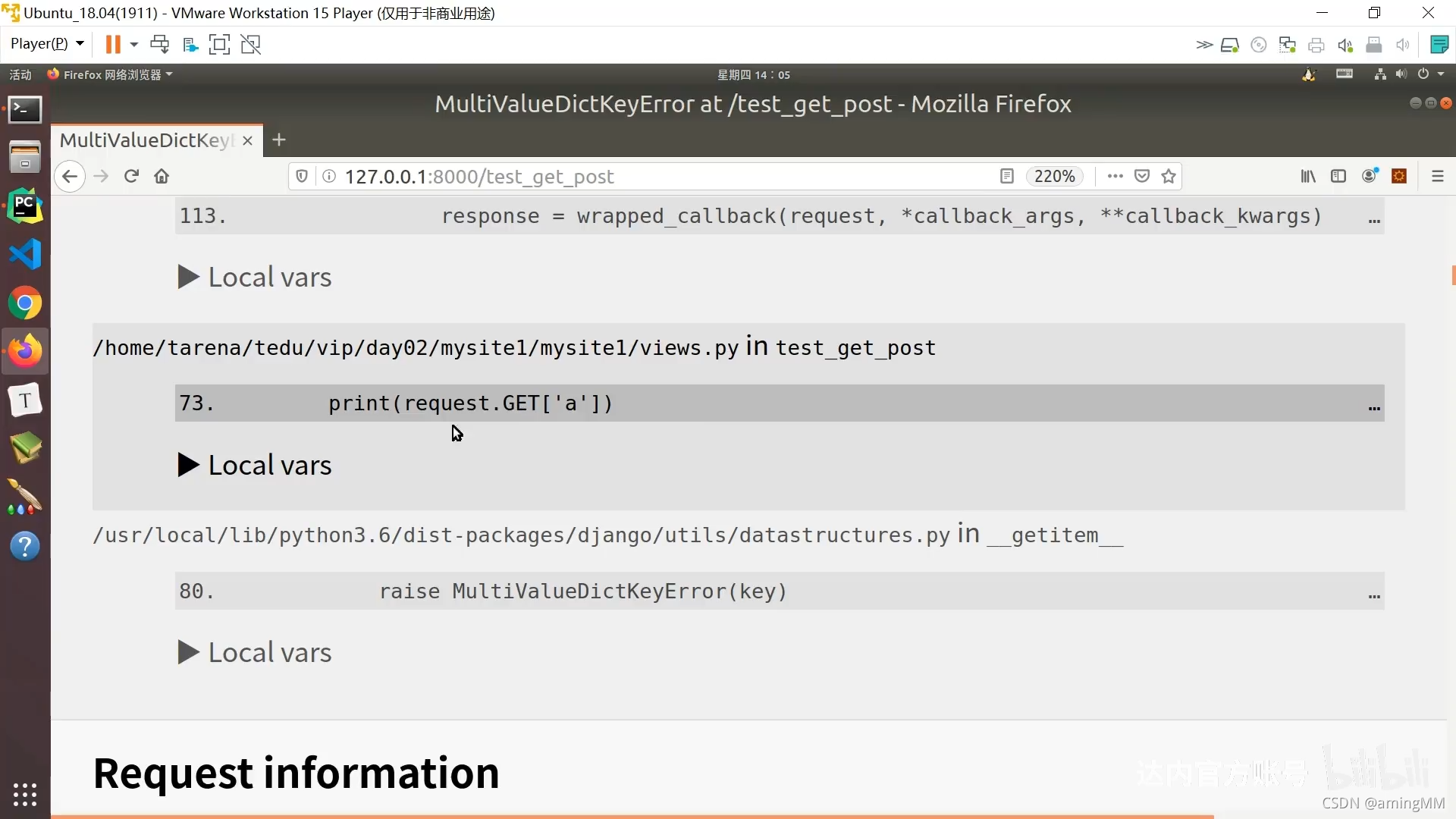

500 响应



















7 Django设计模式及模板层




Controller — 主路由



引擎 数据怎么来 怎么调用
把 Templates 位置 配置到 DIRS 里














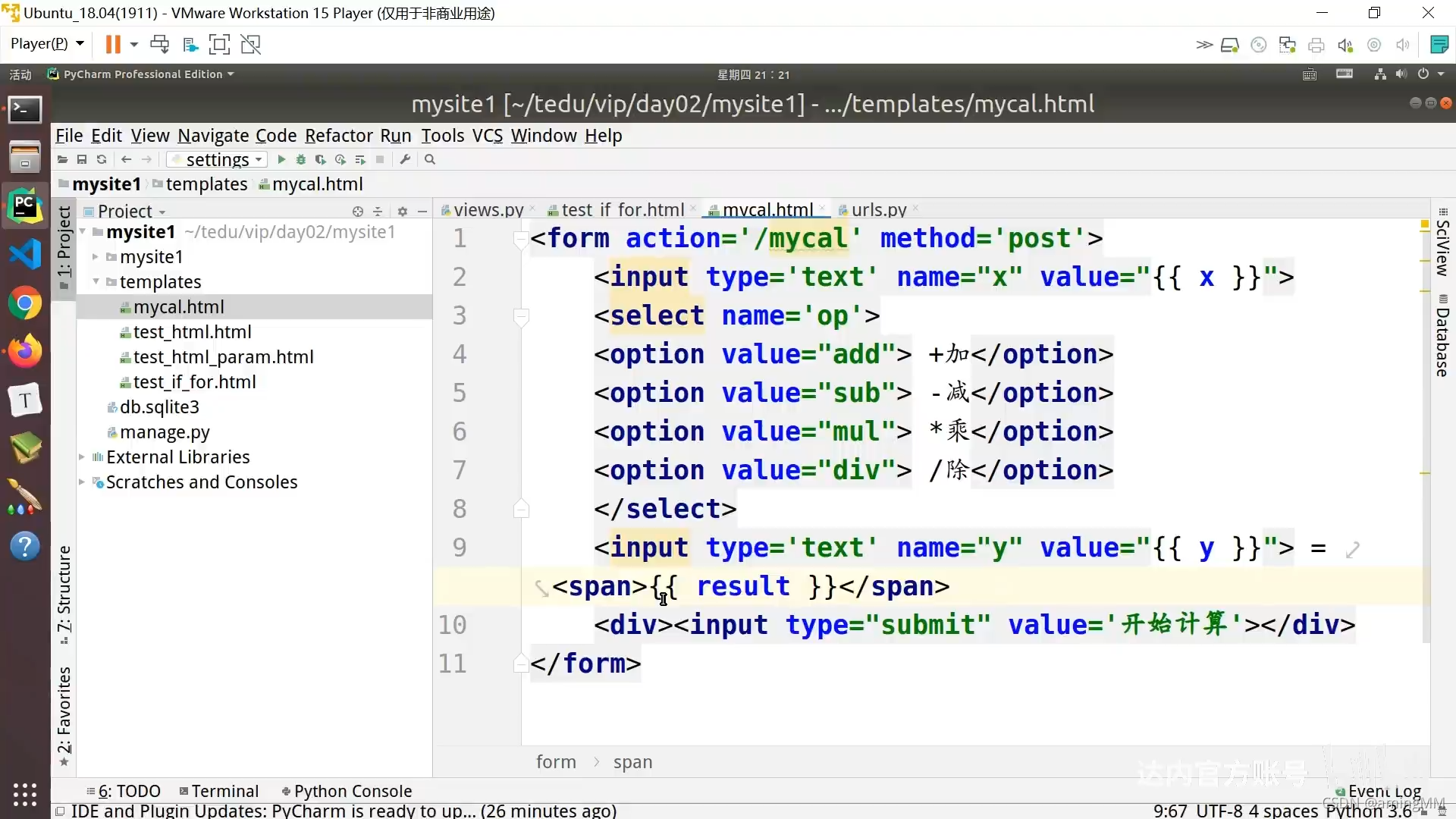
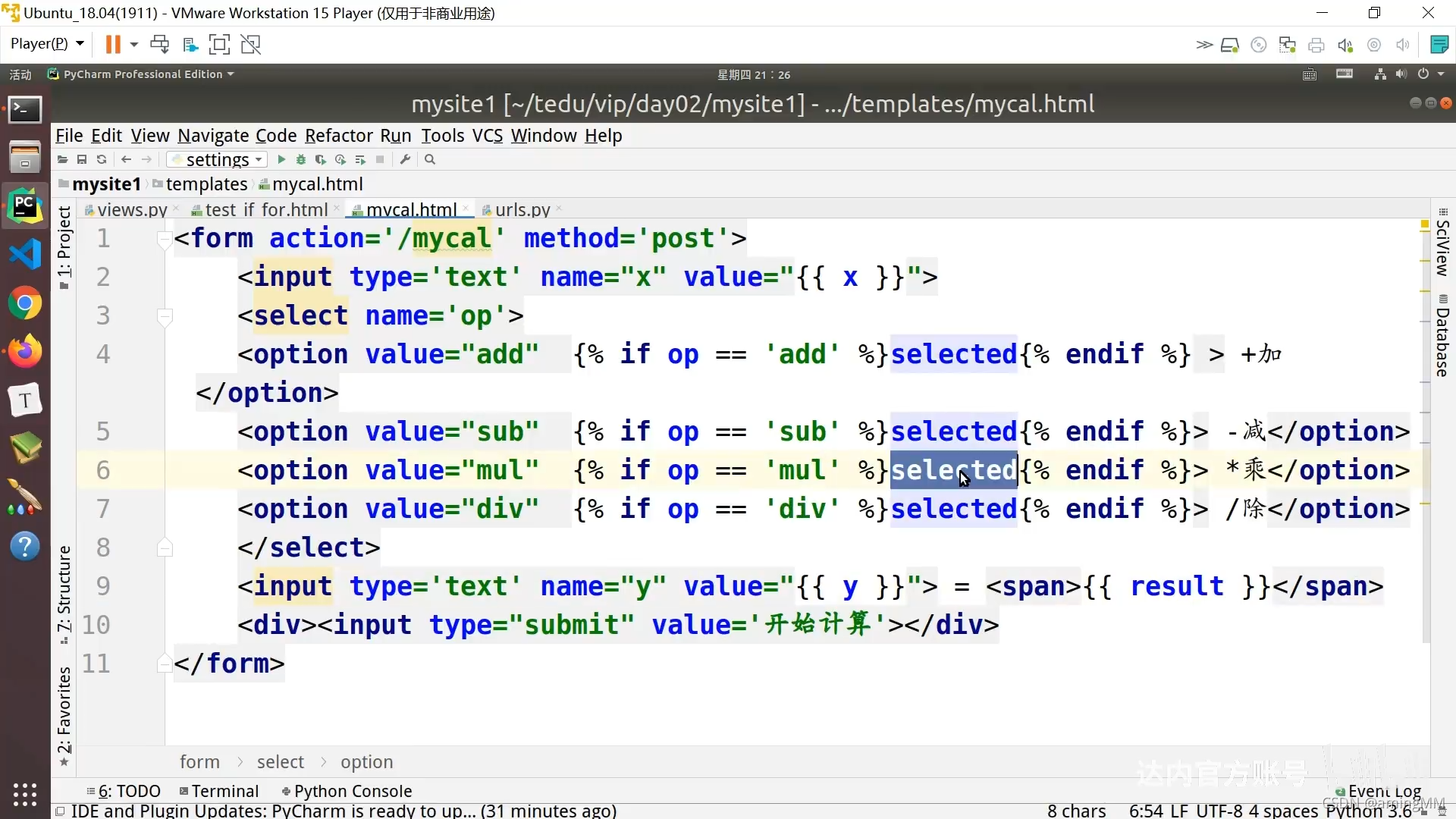
8 模板层-变量和标签





















ctrl alt L 格式化

局部变量 locals













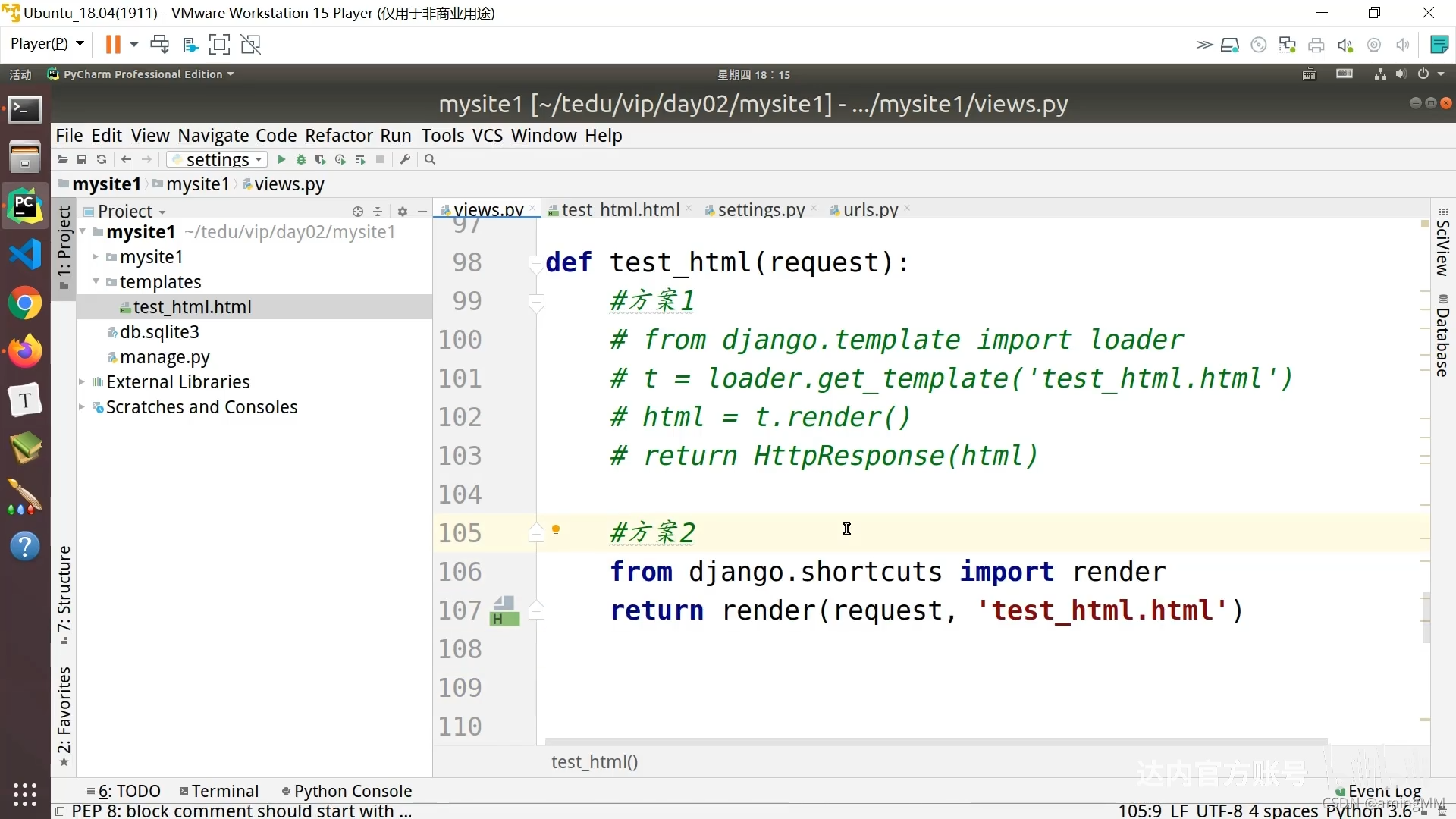
9 模板层-过滤器和继承



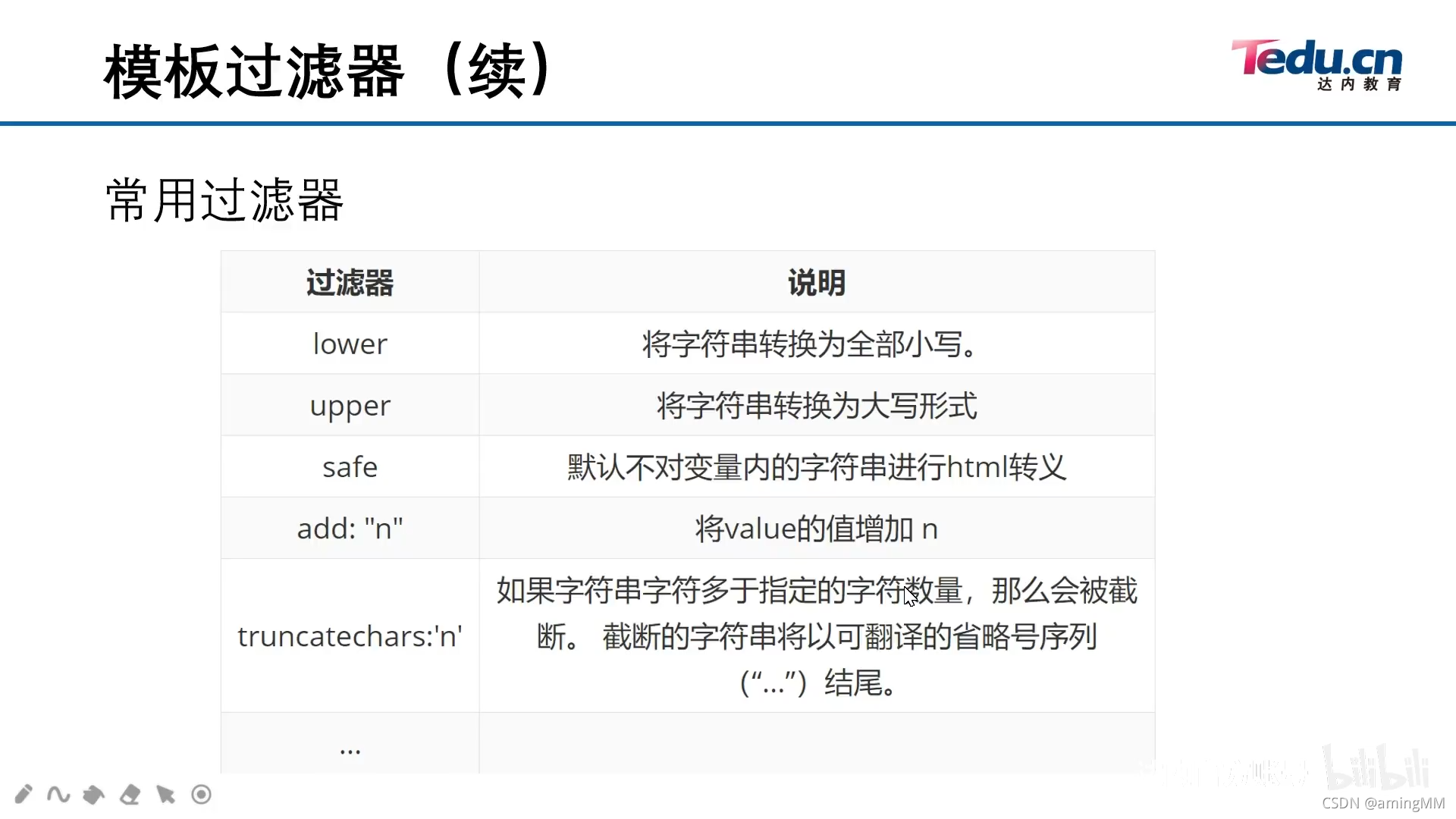





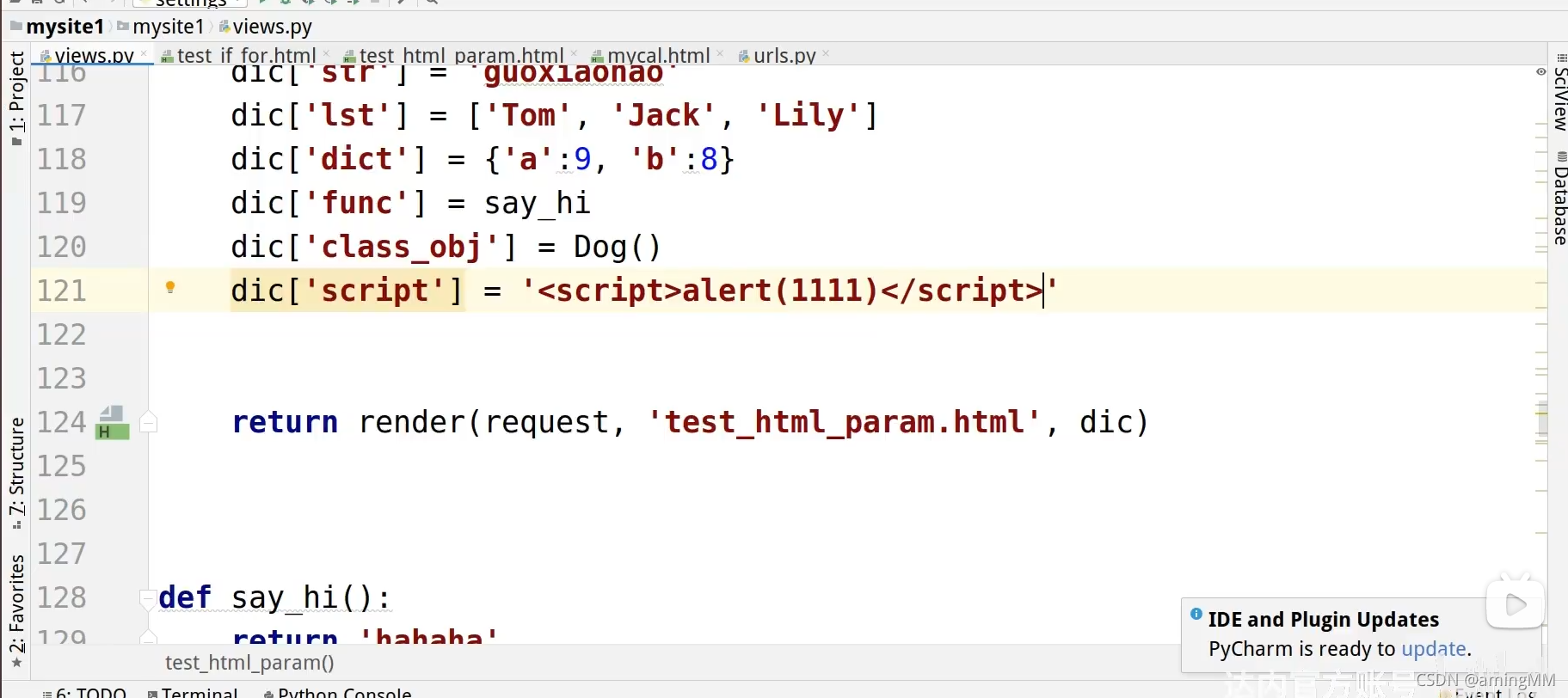
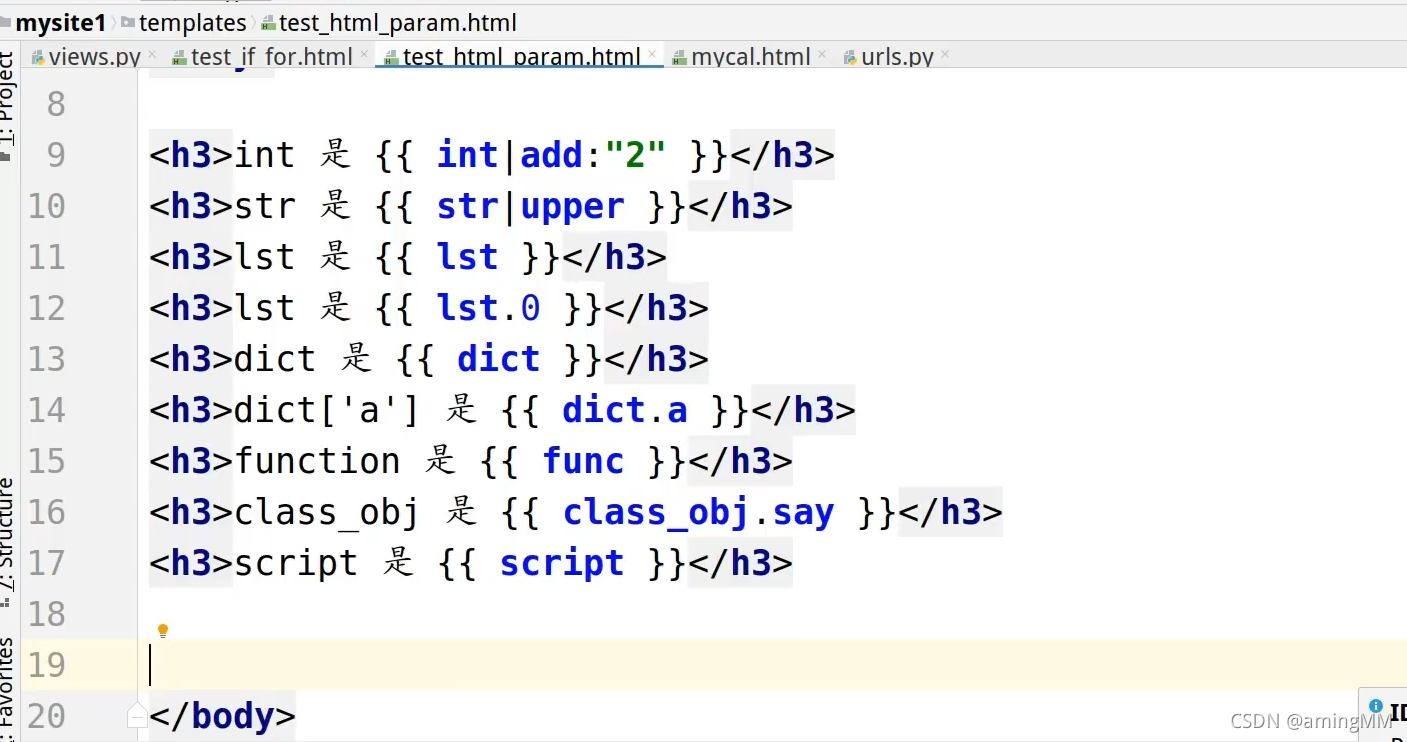

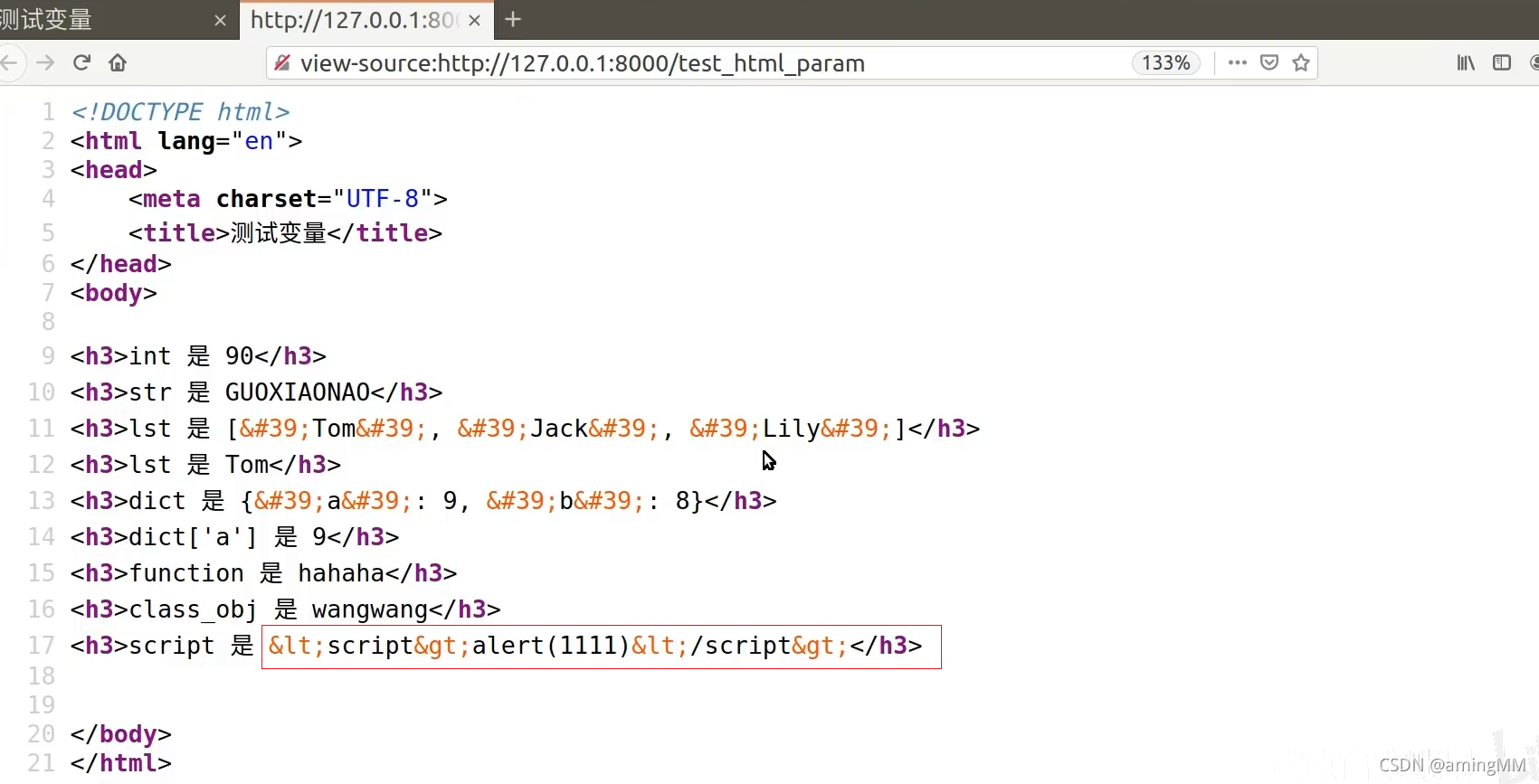
HTML 转义 <> 进行 转义




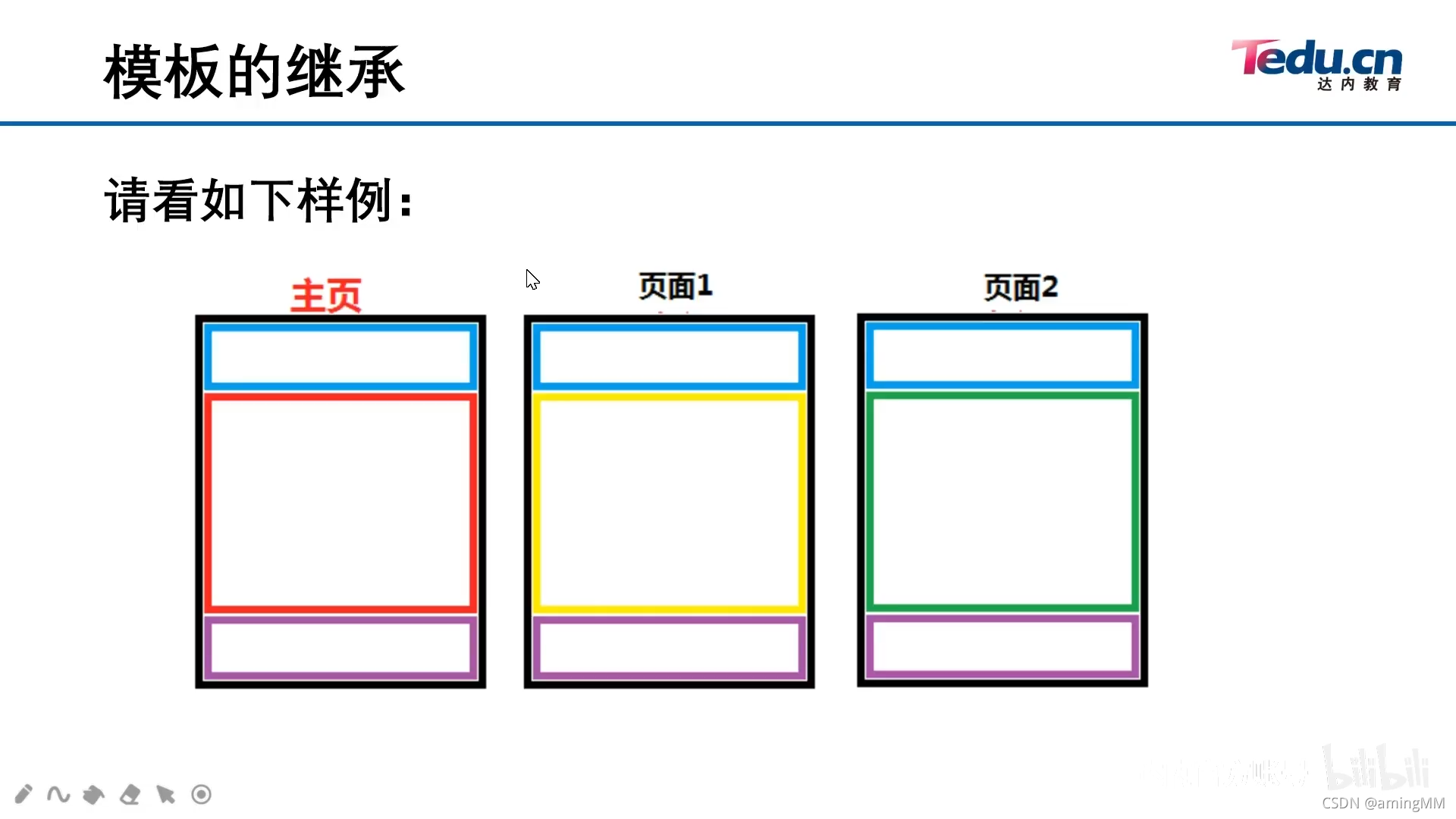



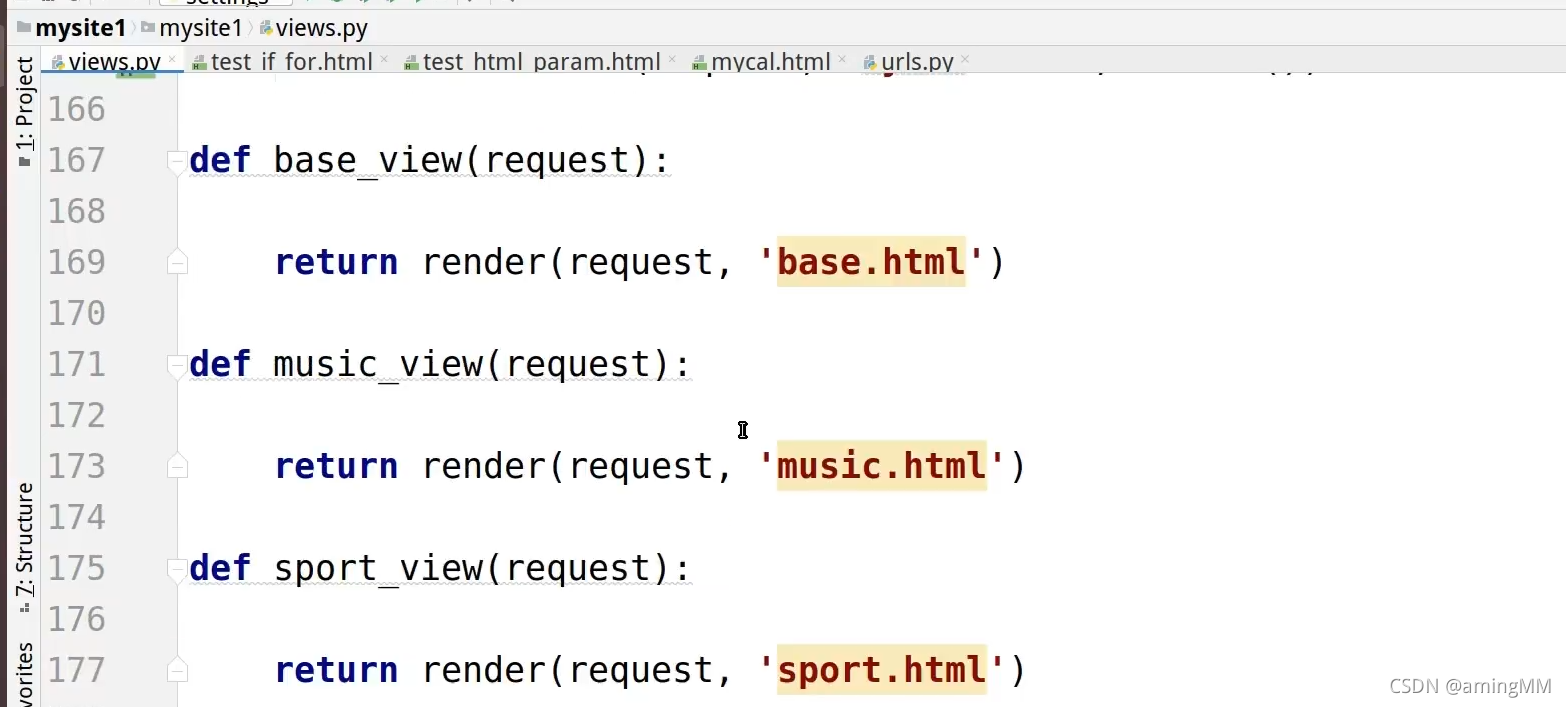
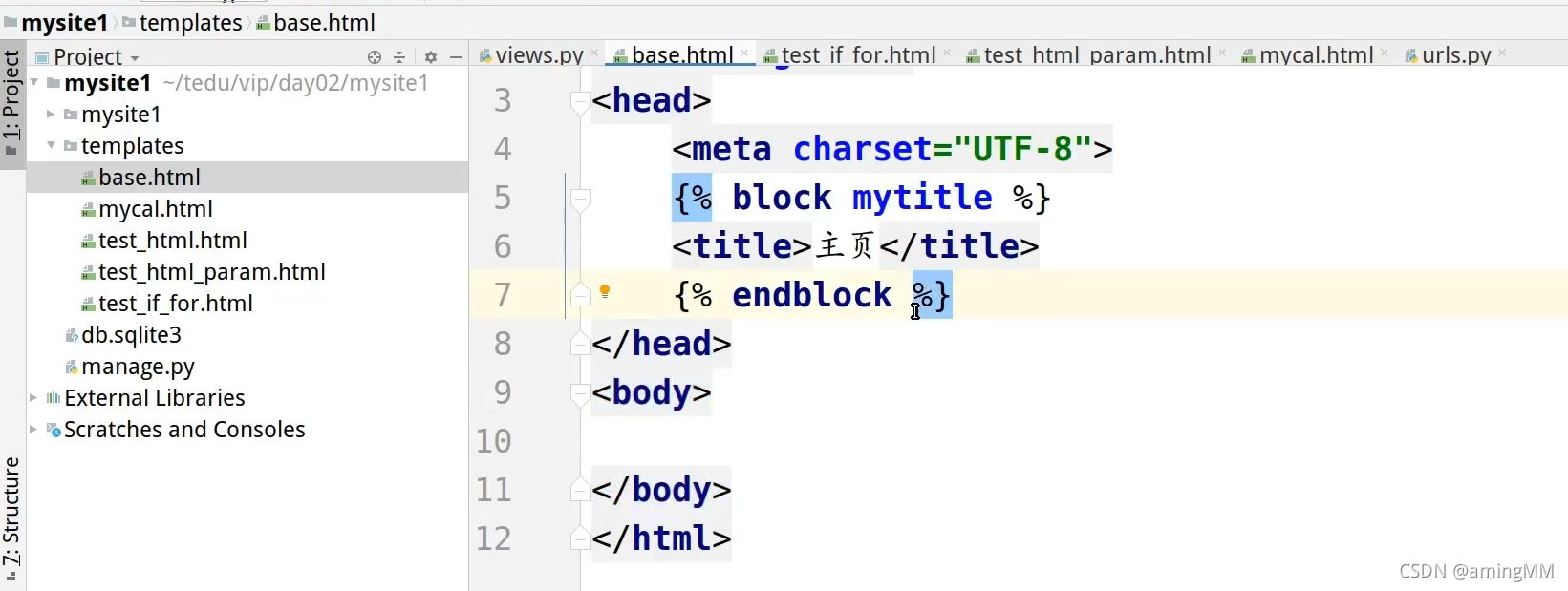

继承 重写







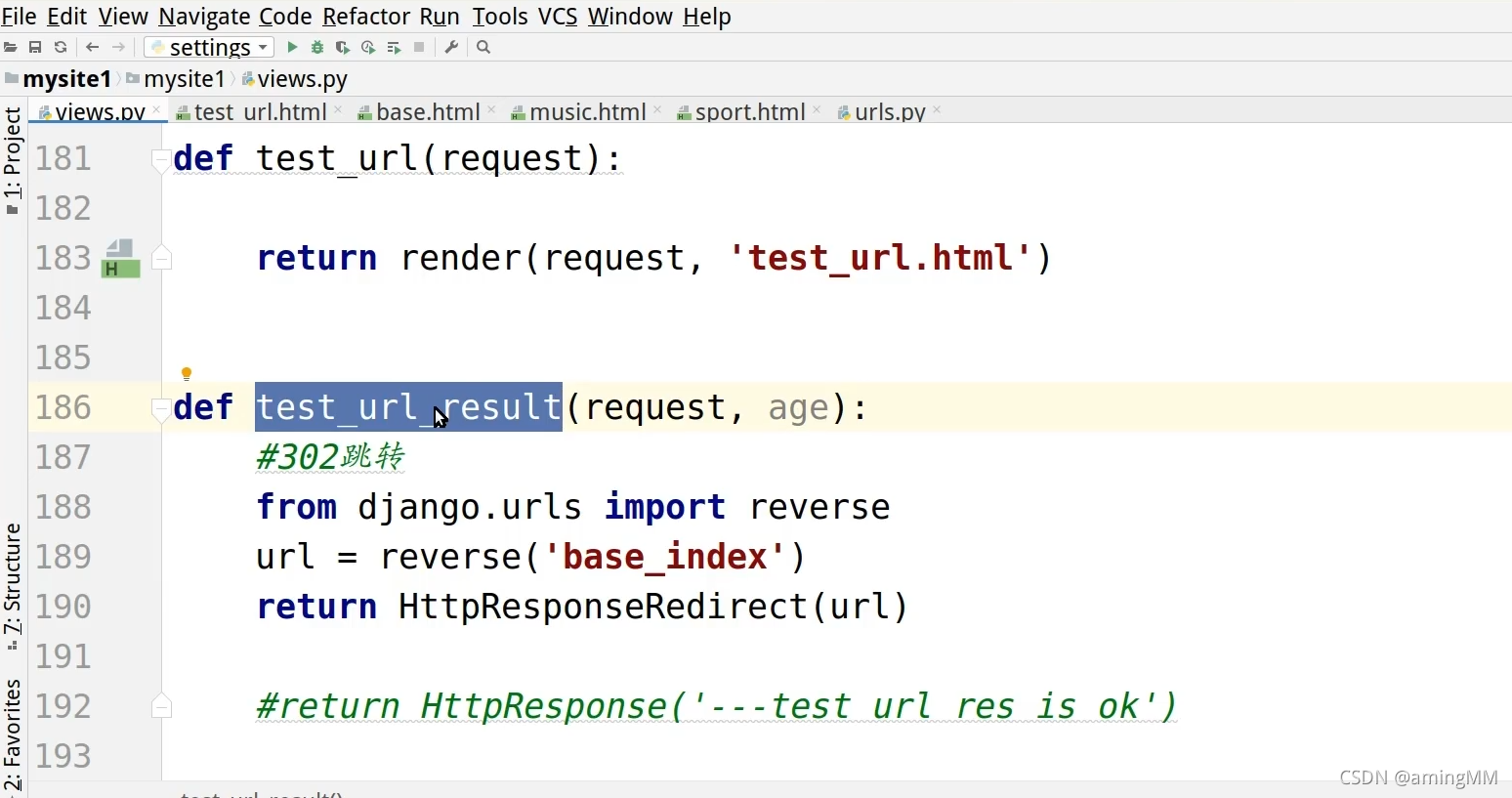
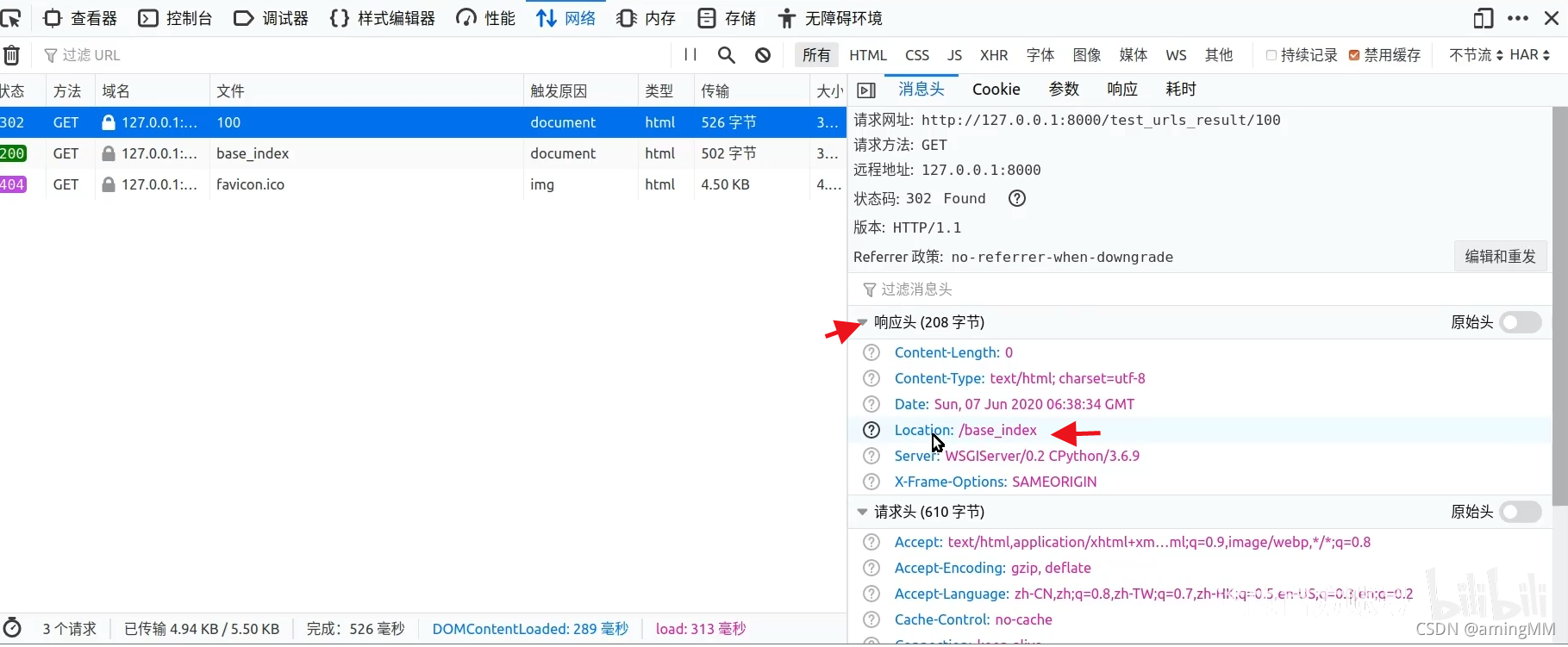
10 url反向解析





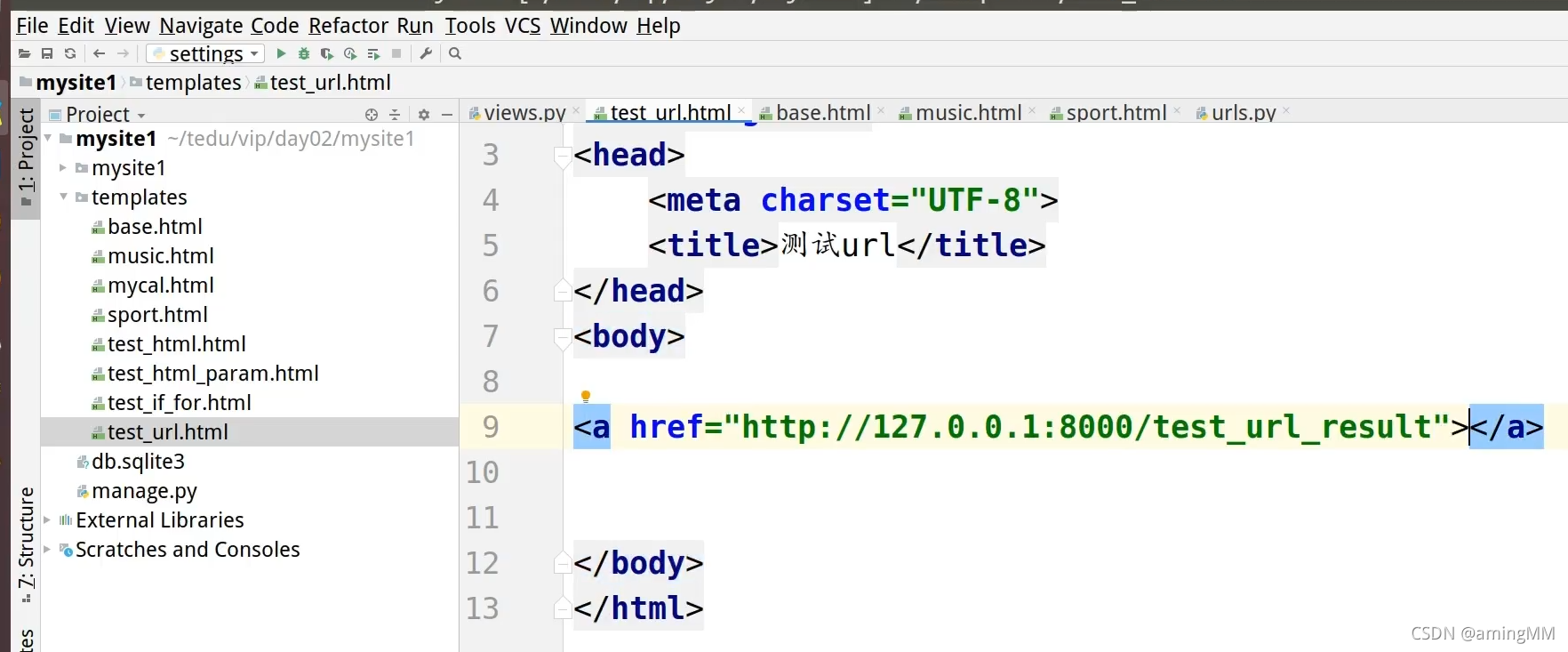



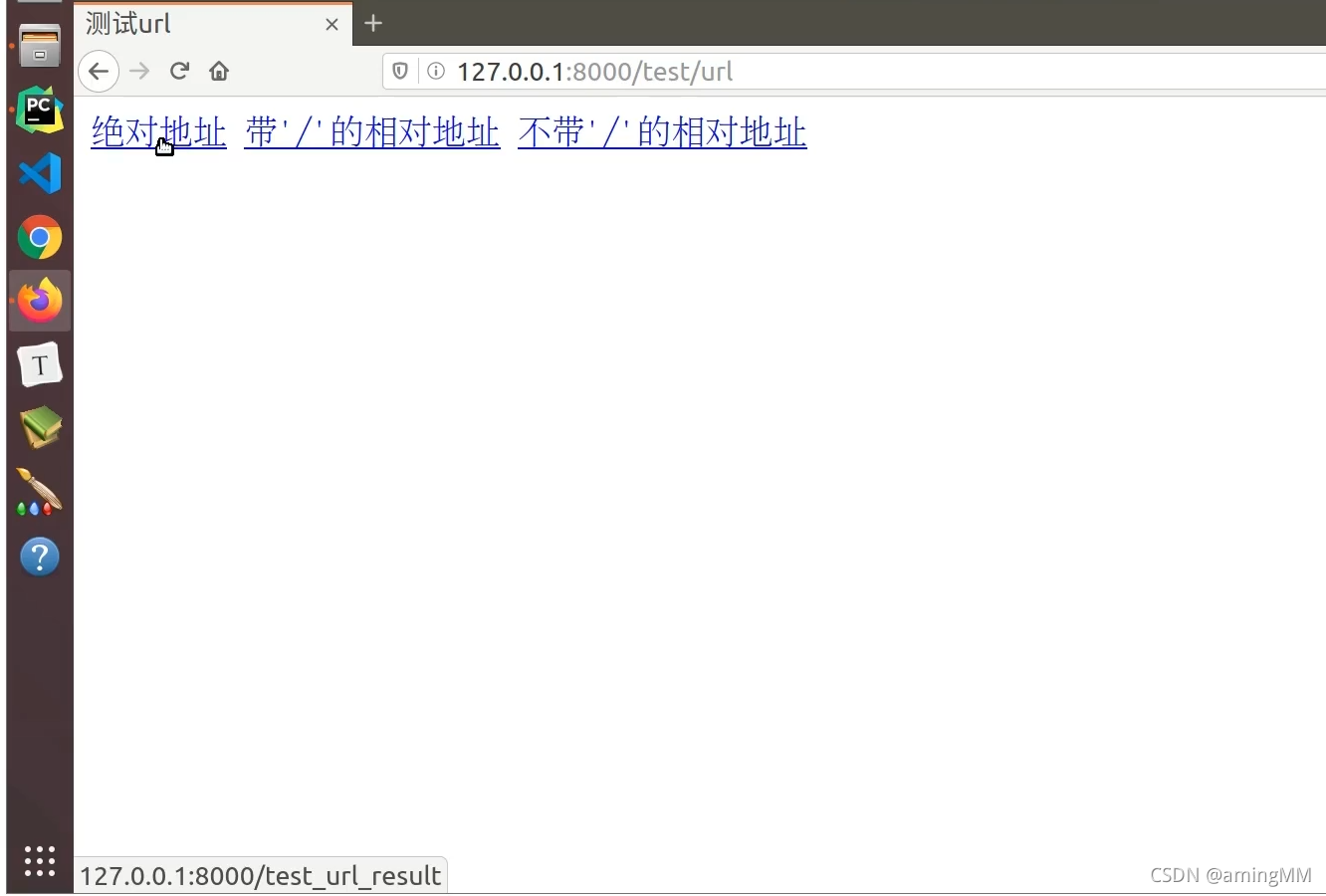



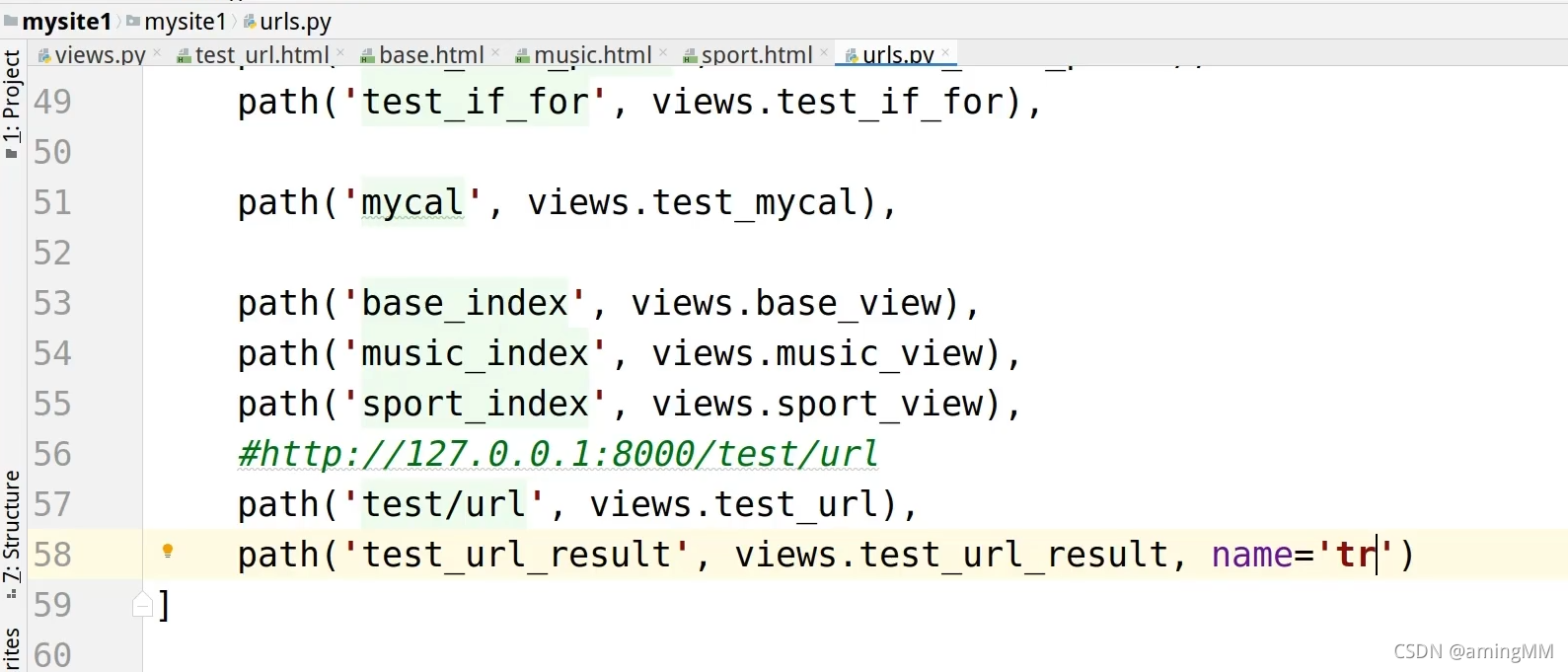

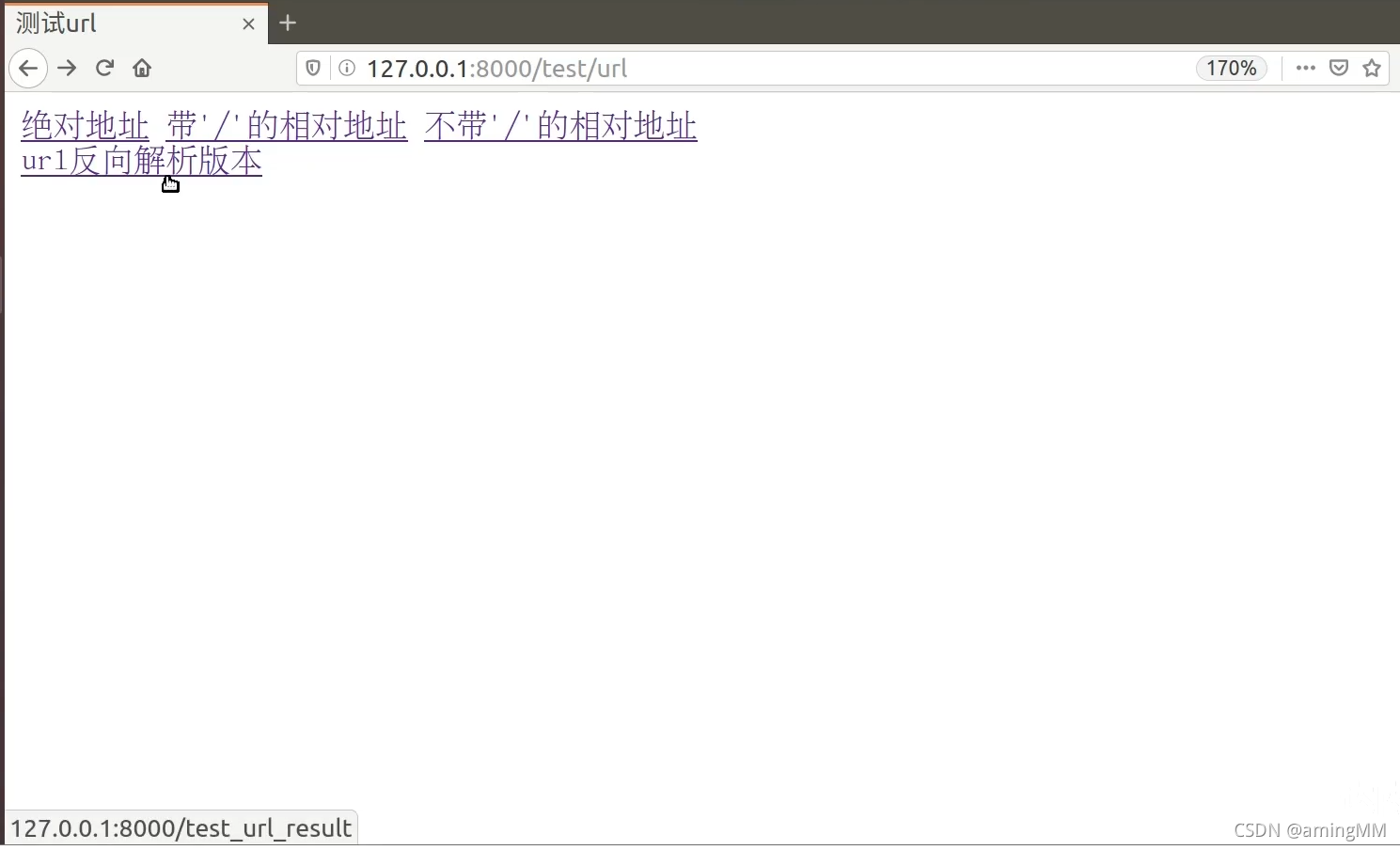


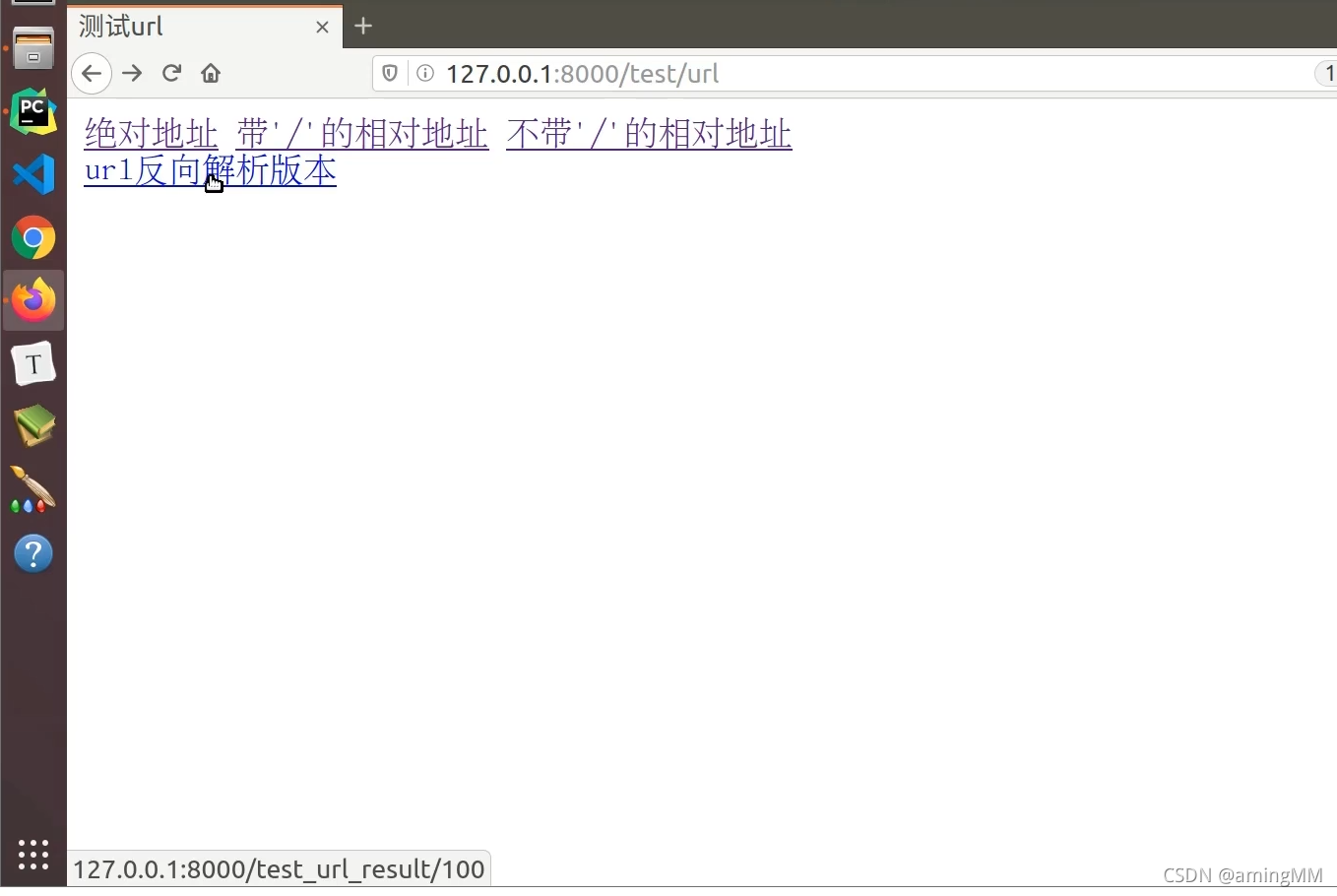

动态 解析




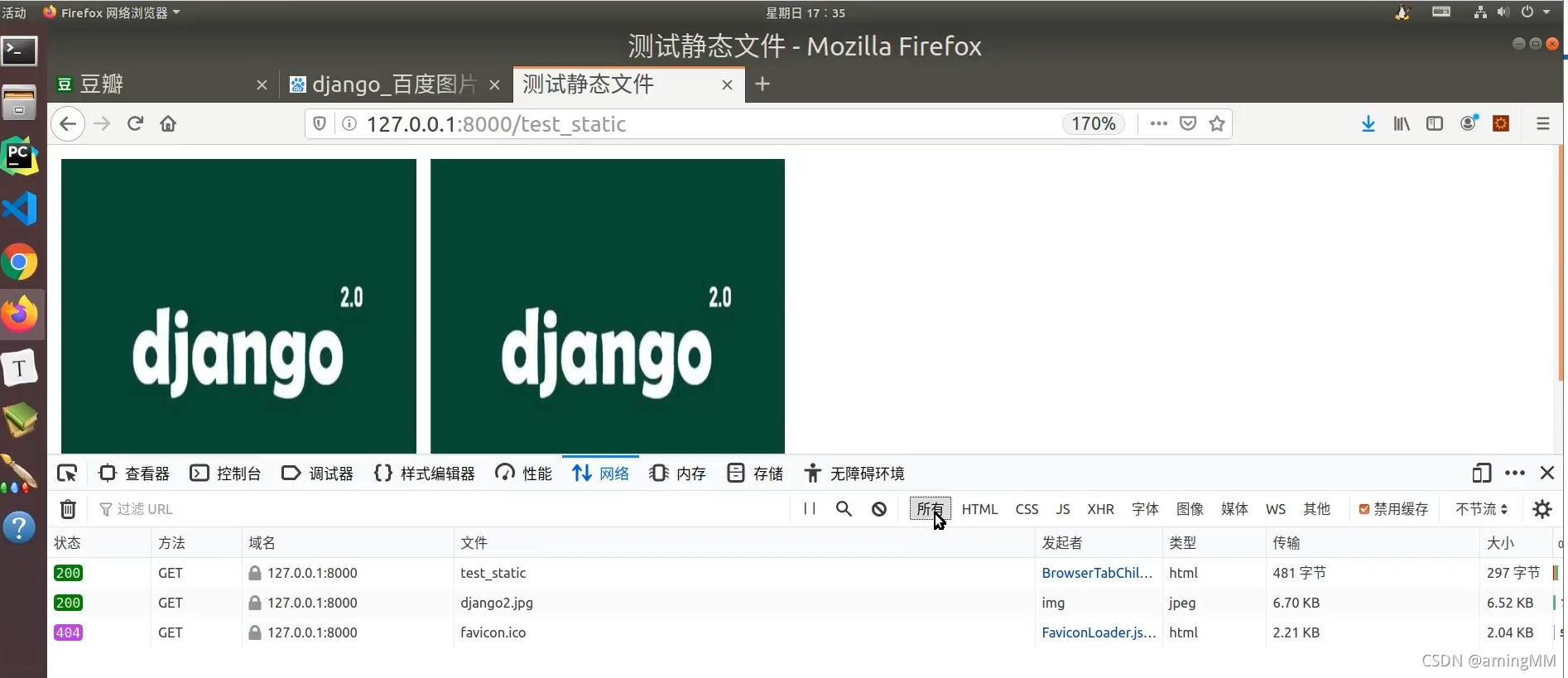
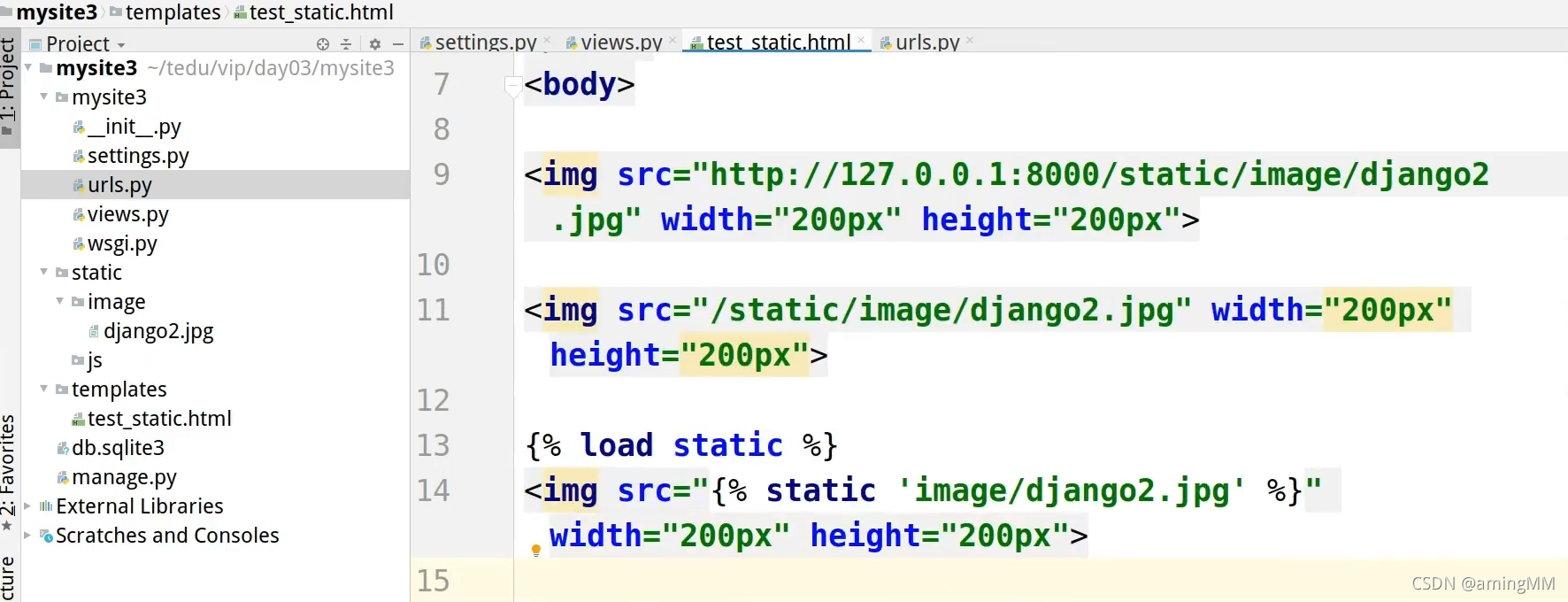
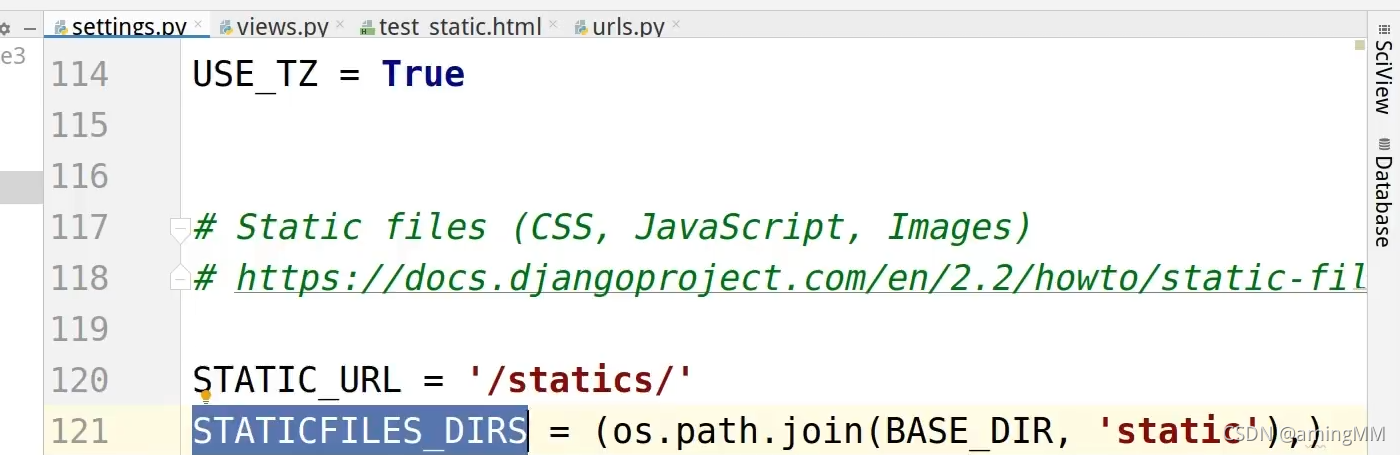
11 静态文件

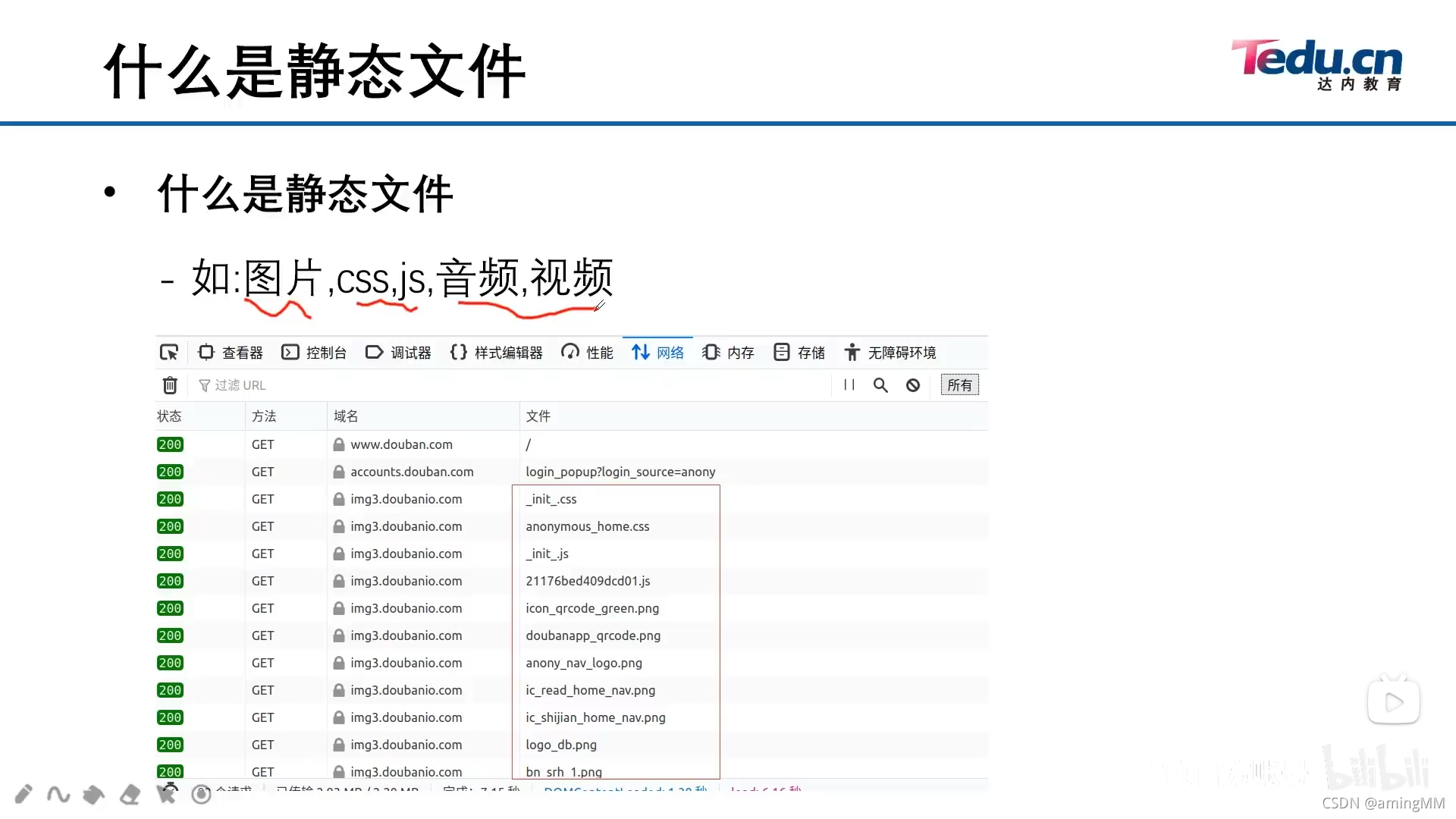

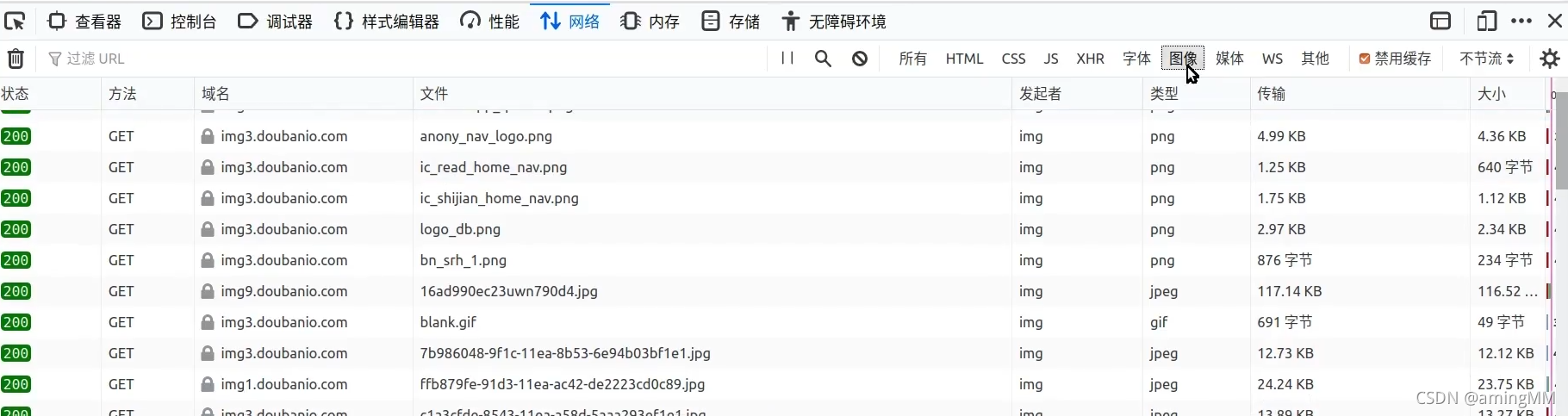



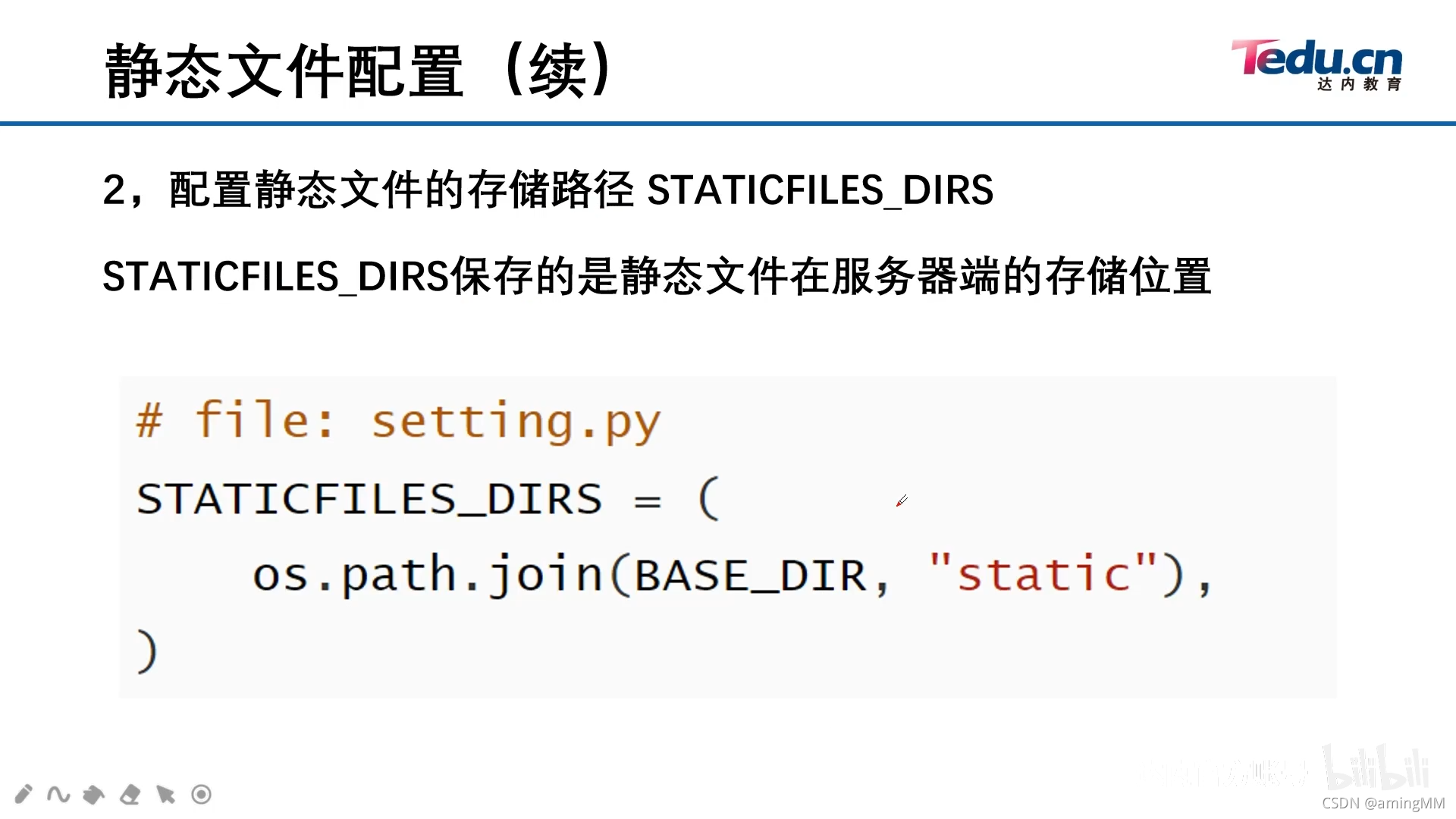
注意 元组 中的 逗号





















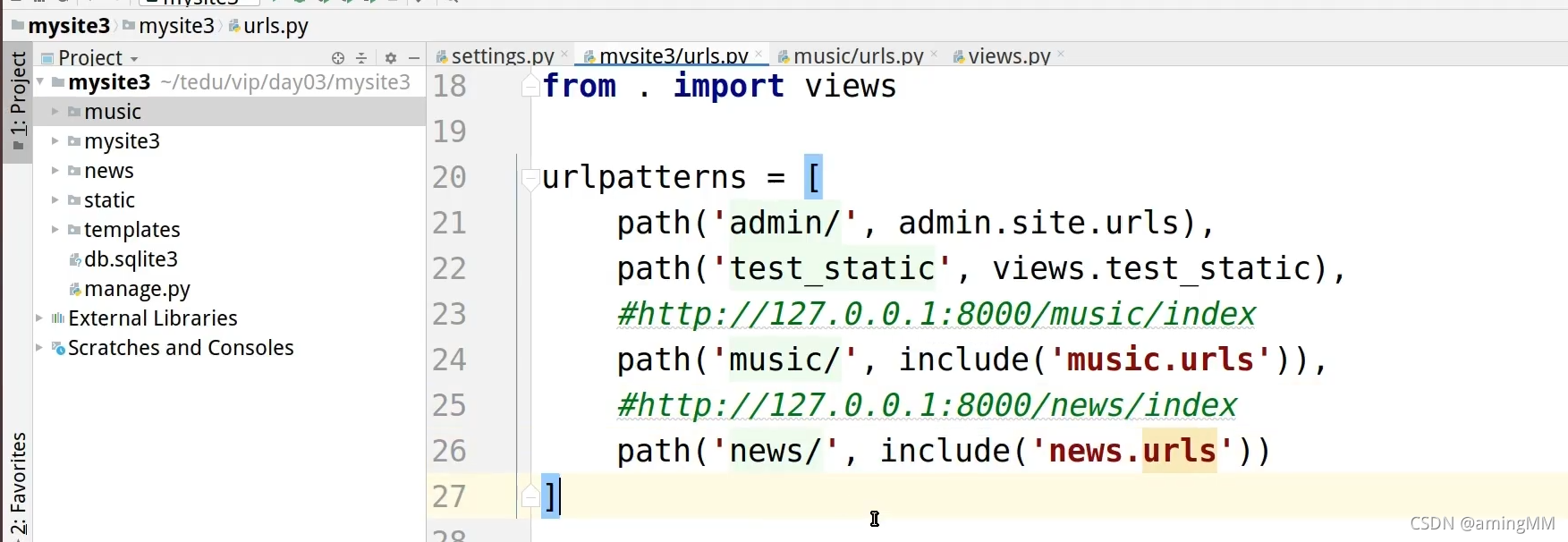
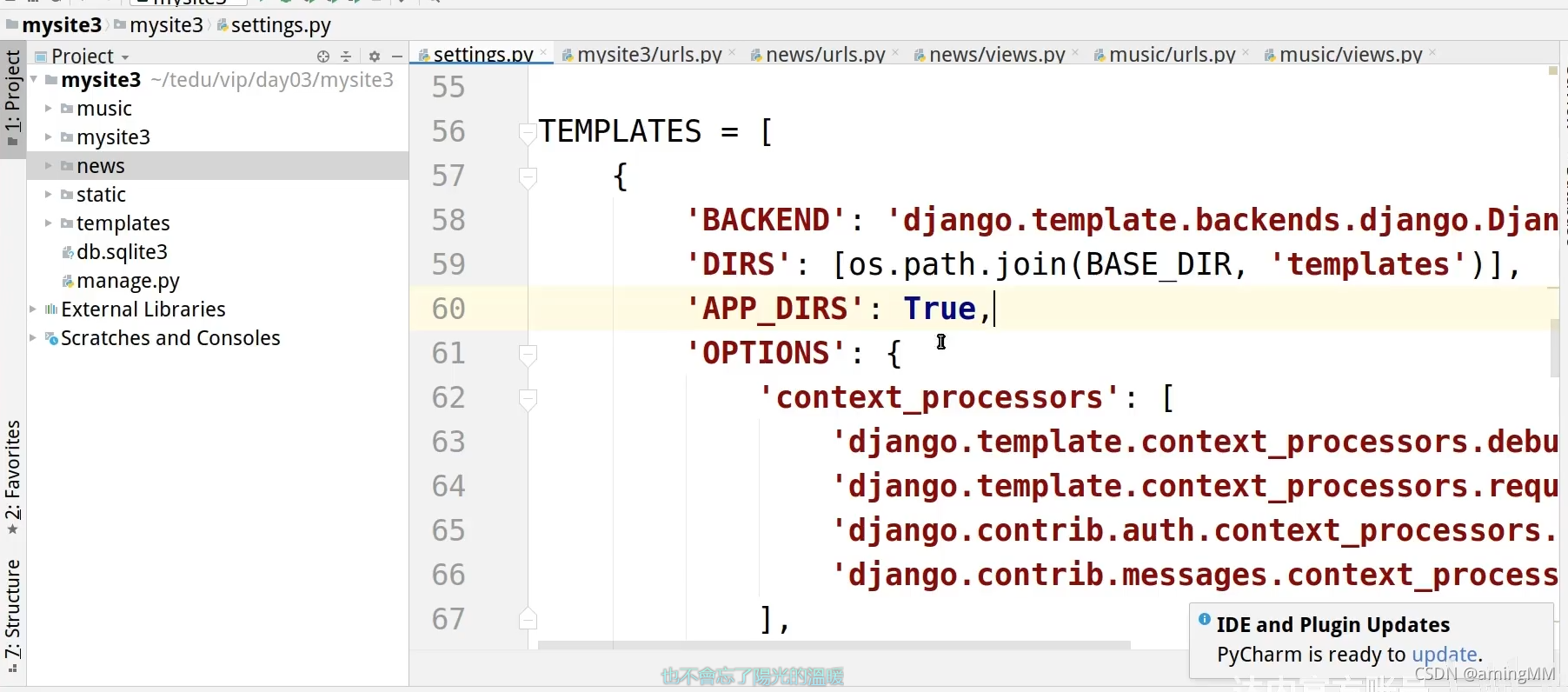
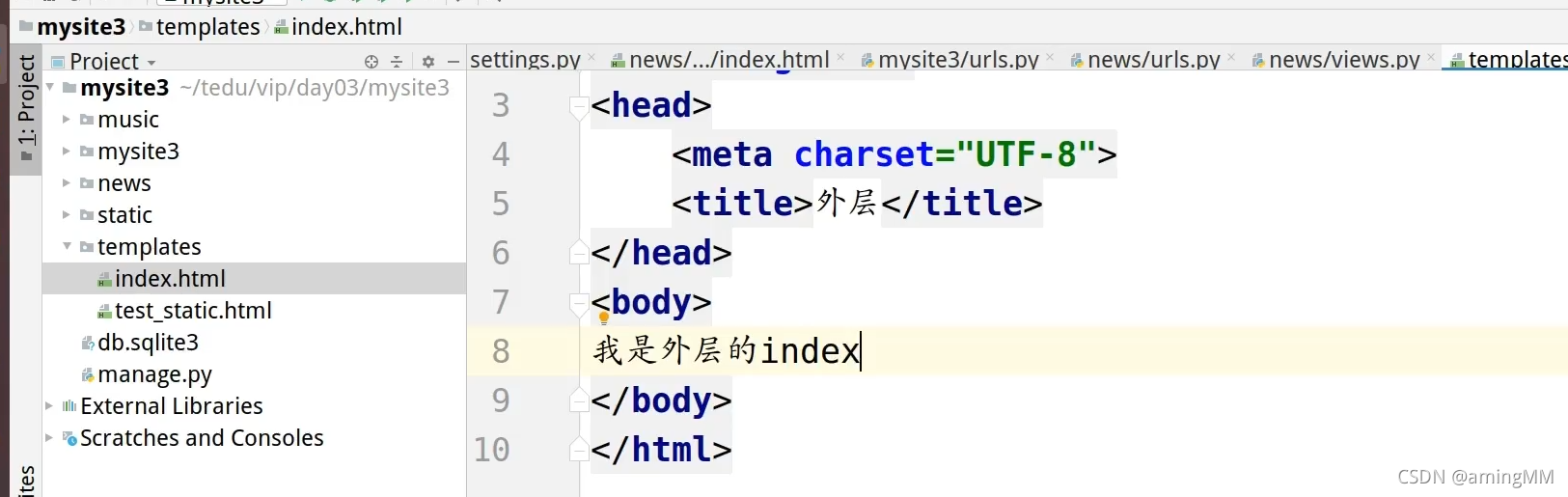
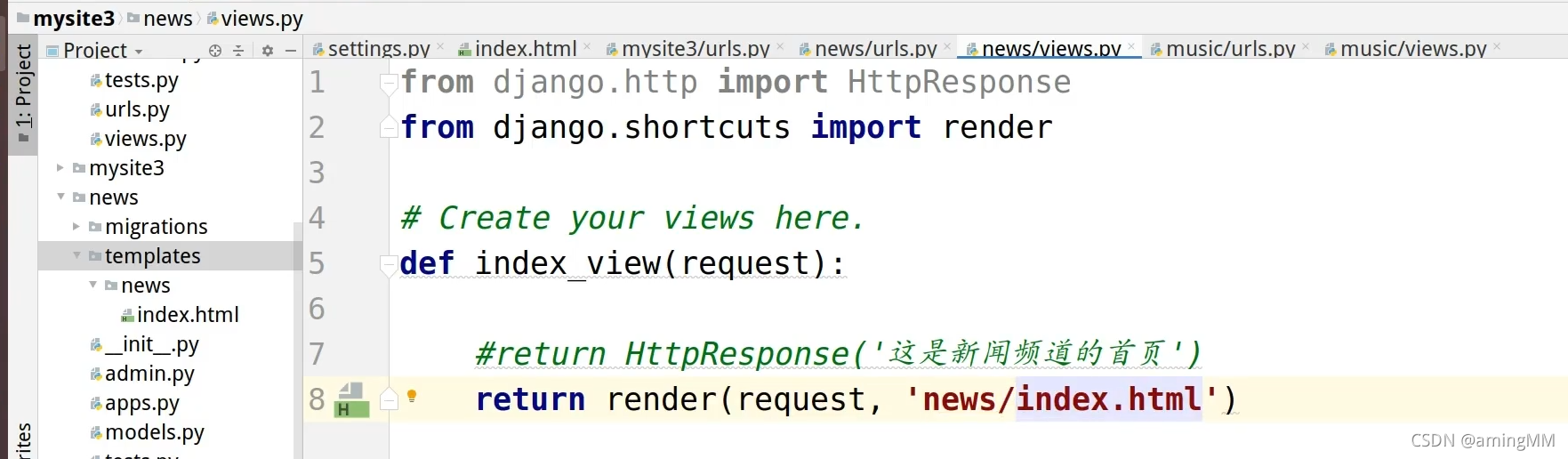
12 Django 应用及分布式路由


解耦企业业务 每个文件夹 都是 独立的 MTV




创建之后 注册 一下
















13 模型层及ORM介绍



npm run lint -- --fix
pip install pymysql





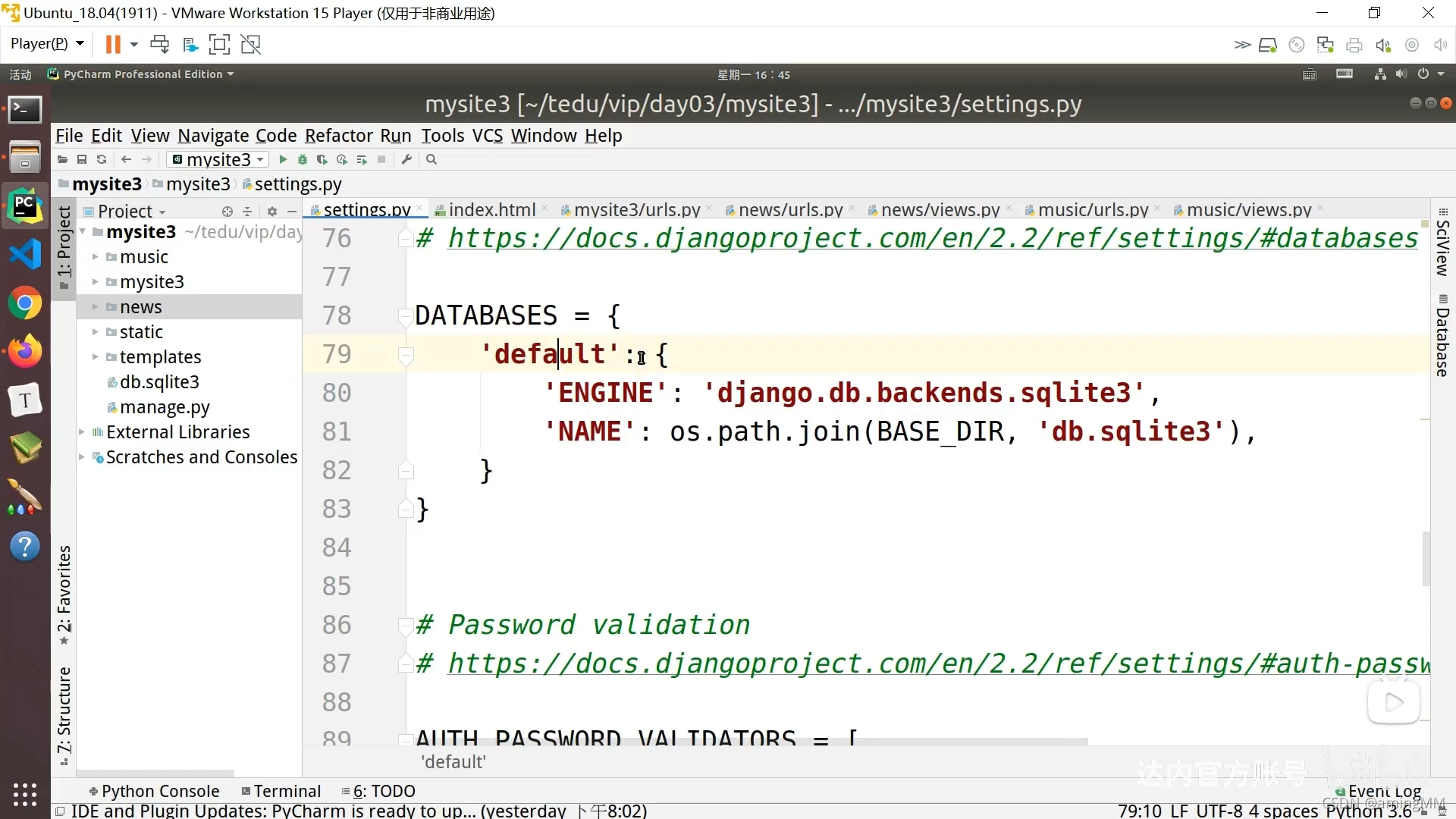















同步表结构
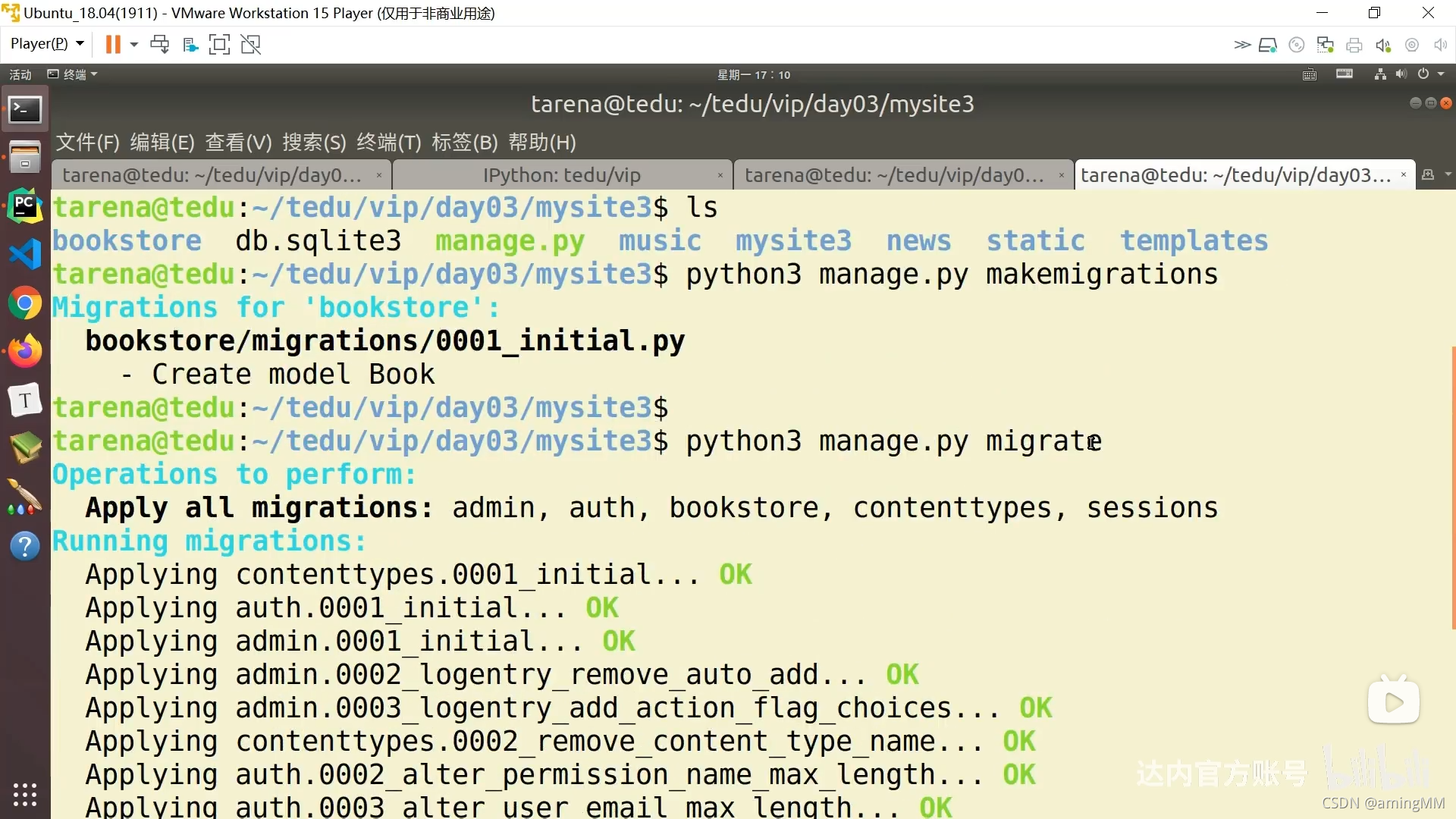



默认 初始化 id 自增



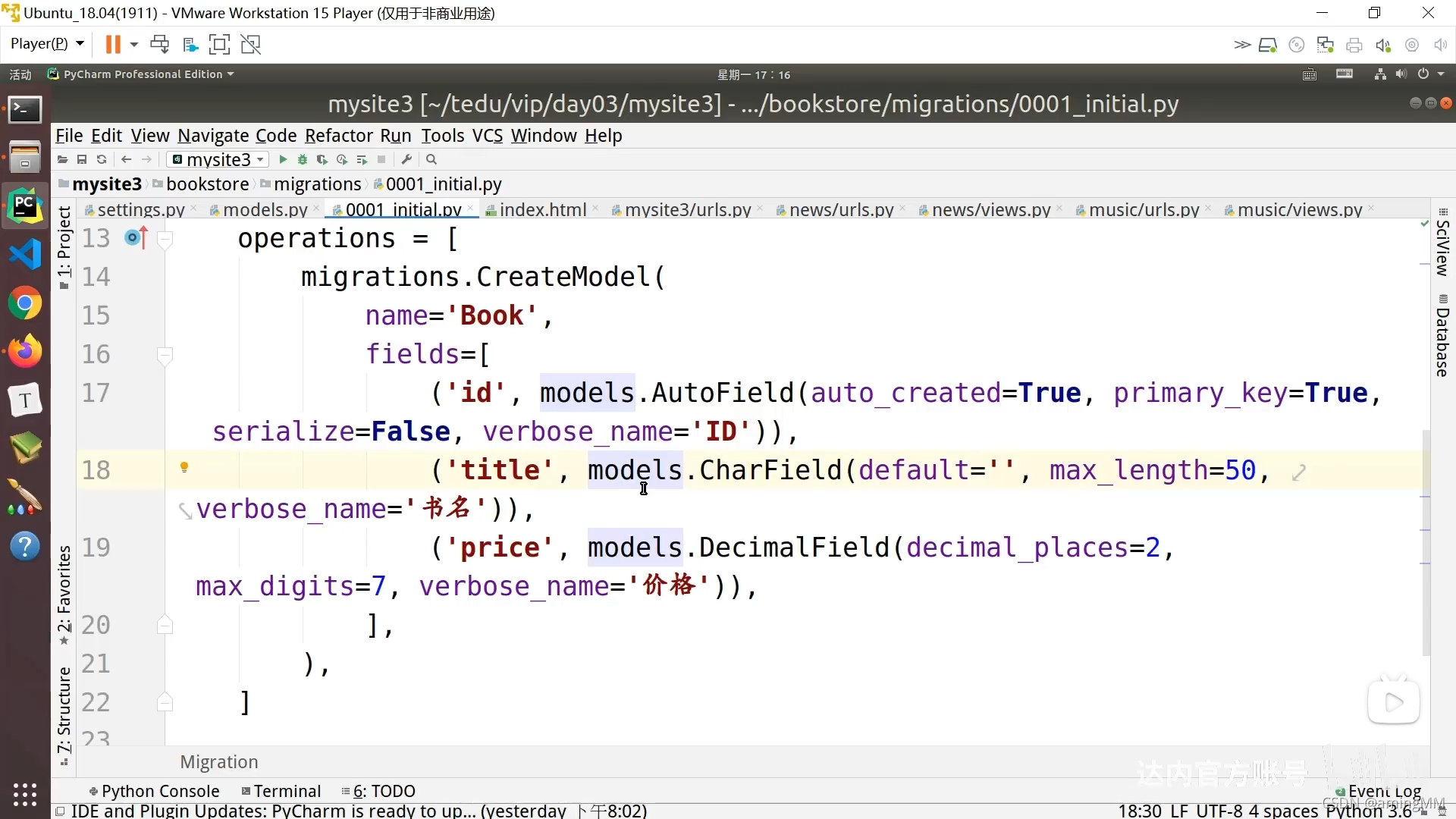


14 ORM-基础字段及选项










django 模型models 常用字段
1、models.AutoField
自增列 = int(11)
如果没有的话,默认会生成一个名称为 id 的列
如果要显式的自定义一个自增列,必须设置primary_key=True。
2、models.CharField
字符串字段
必须设置max_length参数
3、models.BooleanField
布尔类型=tinyint(1)
不能为空,可添加Blank=True
4、models.ComaSeparatedIntegerField
用逗号分割的数字=varchar
继承CharField,所以必须 max_lenght 参数
5、models.DateField
日期类型 date
DateField.auto_now:保存时自动设置该字段为现在日期,最后修改日期
DateField.auto_now_add:当该对象第一次被创建是自动设置该字段为现在日期,创建日期。
6、models.DateTimeField
日期时间类型 datetime
同DateField的参数
7、models.Decimal
十进制小数类型 = decimal
DecimalField.max_digits:数字中允许的最大位数
DecimalField.decimal_places:存储的十进制位数
8、models.EmailField
一个带有检查 Email 合法性的 CharField
9、models.FloatField
浮点类型 = double
10、models.IntegerField
整形
11、models.BigIntegerField
长整形
integer_field_ranges = {
'SmallIntegerField': (-32768, 32767),
'IntegerField': (-2147483648, 2147483647),
'BigIntegerField': (-9223372036854775808, 9223372036854775807),
'PositiveSmallIntegerField': (0, 32767),
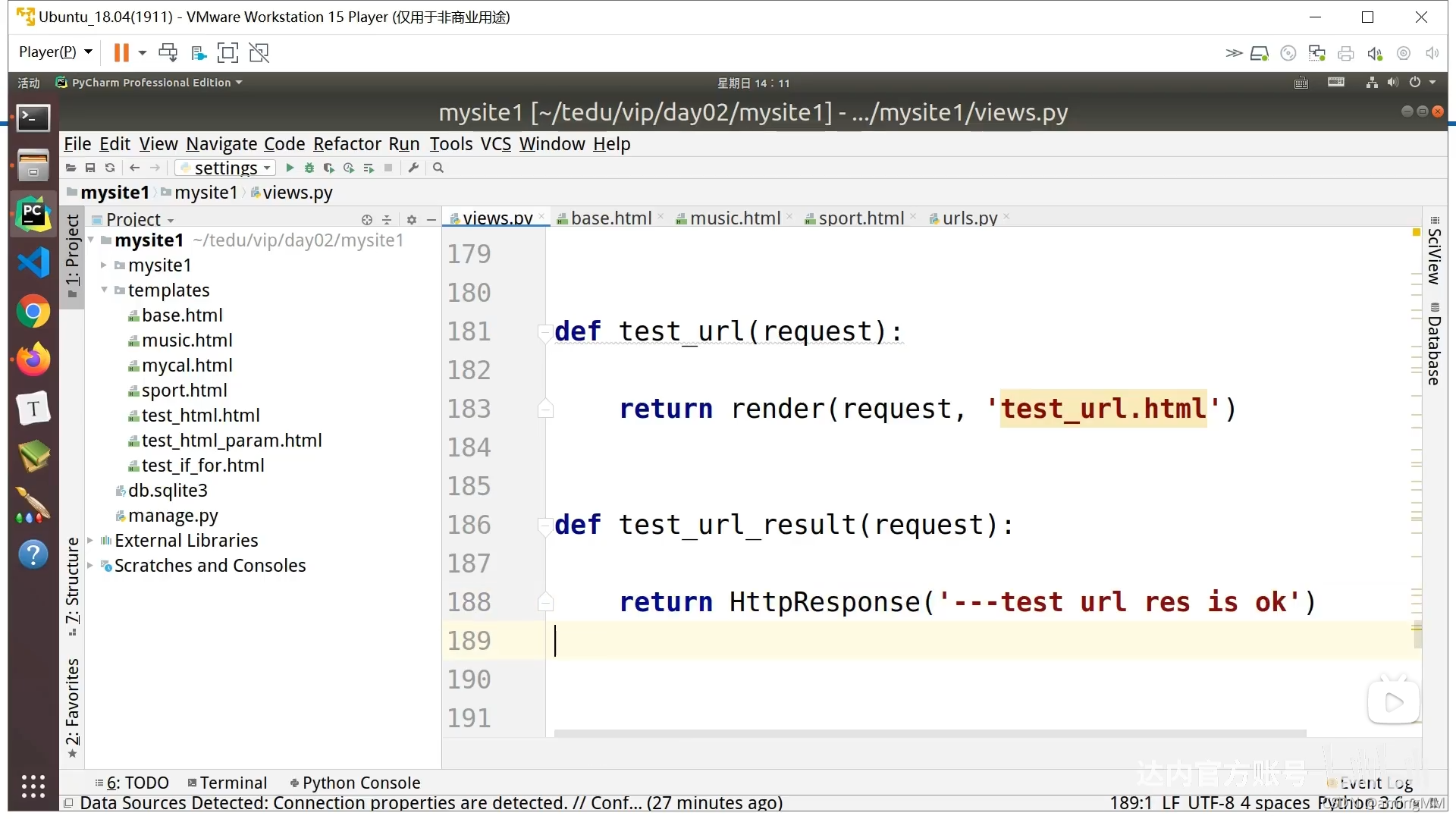
'PositiveIntegerField': (0, 2147483647),
}
12、models.GenericIPAddressField
一个带有检查 IP地址合法性的 CharField
13、models.NullBooleanField
允许为空的布尔类型
14、models.PositiveIntegerFiel
正整数
15、models.PositiveSmallIntegerField
正smallInteger
16、models.SlugField
减号、下划线、字母、数字
17、models.SmallIntegerField
数字
数据库中的字段有:tinyint、smallint、int、bigint
18、models.TextField
大文本。默认对应的form标签是textarea。
19、models.TimeField
时间 HH:MM[:ss[.uuuuuu]]
20、models.URLField
一个带有URL合法性校验的CharField。
21、models.BinaryField
二进制
存储二进制数据。不能使用filter函数获得QuerySet。
22、models.ImageField
图片
ImageField.height_field、ImageField.width_field:如果提供这两个参数,则图片将按提供的高度和宽度规格保存。
该字段要求 Python Imaging 库Pillow。
会检查上传的对象是否是一个合法图片。
23、models.FileField(upload_to=None[, max_length=100, ** options])
文件
FileField.upload_to:一个用于保存上传文件的本地文件系统路径,该路径由 MEDIA_ROOT 中设置
这个字段不能设置primary_key和unique选项.在数据库中存储类型是varchar,默认最大长度为100
24、models.FilePathField(path=None[, math=None, recursive=False, max_length=100, **options])
FilePathField.path:文件的绝对路径,必填
FilePathField.match:用于过滤路径下文件名的正则表达式,该表达式将用在文件名上(不包括路径)。
FilePathField.recursive:True 或 False,默认为 False,指定是否应包括所有子目录的路径。
例如:FilePathField(path="/home/images", match="foo.*", recursive=True)
将匹配“/home/images/foo.gif”但不匹配“/home/images/foo/bar.gif”
2. django 模型models 字段常用参数
1、null
如果是True,Django会在数据库中将此字段的值置为NULL,默认值是False
2、blank
如果为True时django的 Admin 中添加数据时可允许空值,可以不填。如果为False则必须填。默认是False。
null纯粹是与数据库有关系的。而blank是与页面必填项验证有关的
3、primary_key = False
主键,对AutoField设置主键后,就会代替原来的自增 id 列
4、auto_now 和 auto_now_add
auto_now 自动创建---无论添加或修改,都是当前操作的时间
auto_now_add 自动创建---永远是创建时的时间
5、choices
一个二维的元组被用作choices,如果这样定义,Django会select box代替普通的文本框,
并且限定choices的值是元组中的值
GENDER_CHOICE = (
(u'M', u'Male'),
(u'F', u'Female'),
)
gender = models.CharField(max_length=2,choices = GENDER_CHOICE)
6、max_length
字段长度
7、default
默认值
8、verbose_name
Admin中字段的显示名称,如果不设置该参数时,则与属性名。
9、db_column
数据库中的字段名称
10、unique=True
不允许重复
11、db_index = True
数据库索引
12、editable=True
在Admin里是否可编辑
13、error_messages=None
错误提示
14、auto_created=False
自动创建
15、help_text
在Admin中提示帮助信息
16、validators=[]
验证器
17、upload-to
文件上传时的保存上传文件的目录

布尔型
变长字符










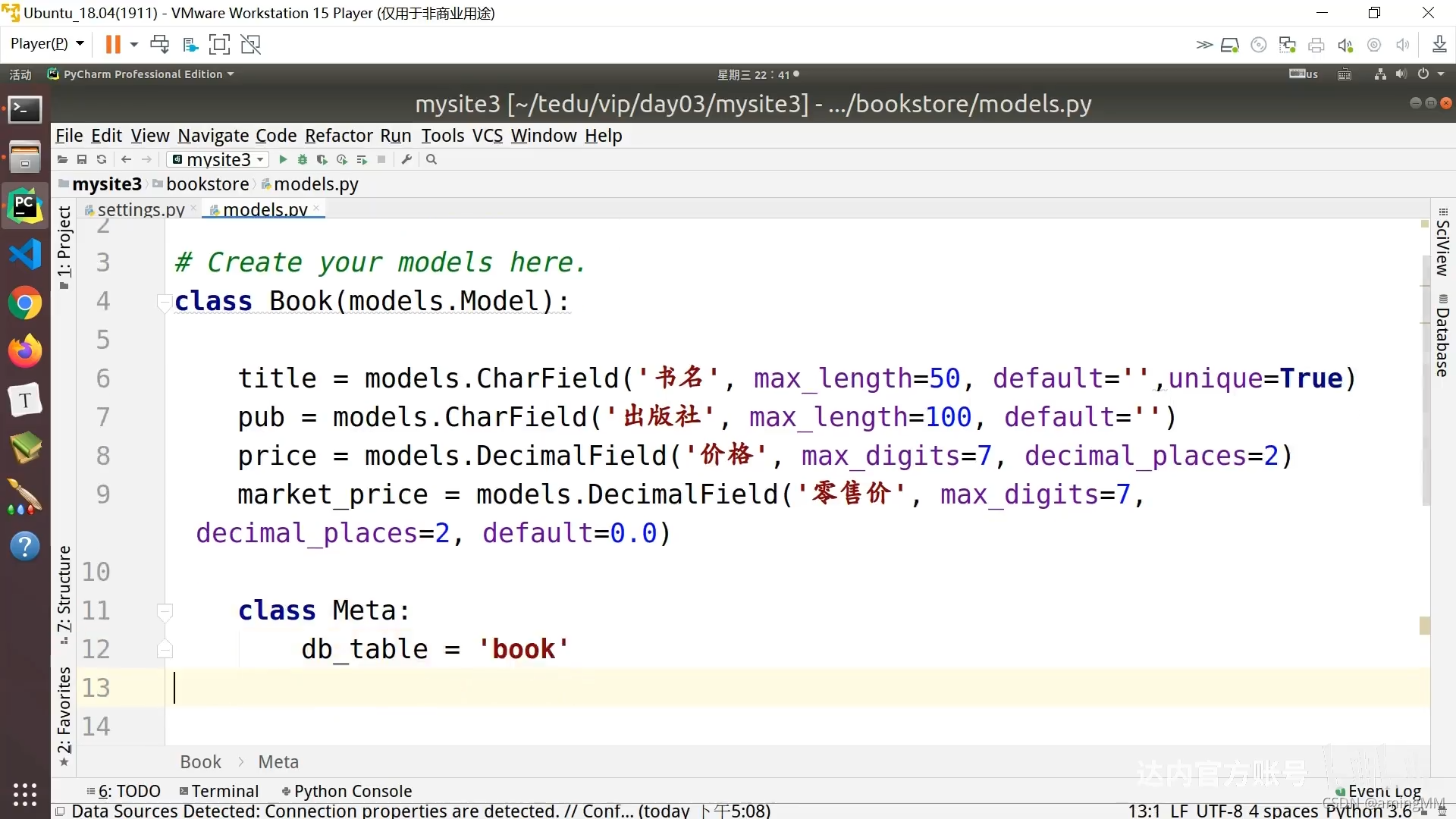
继承 Model 类属性







表明 app_模型类名


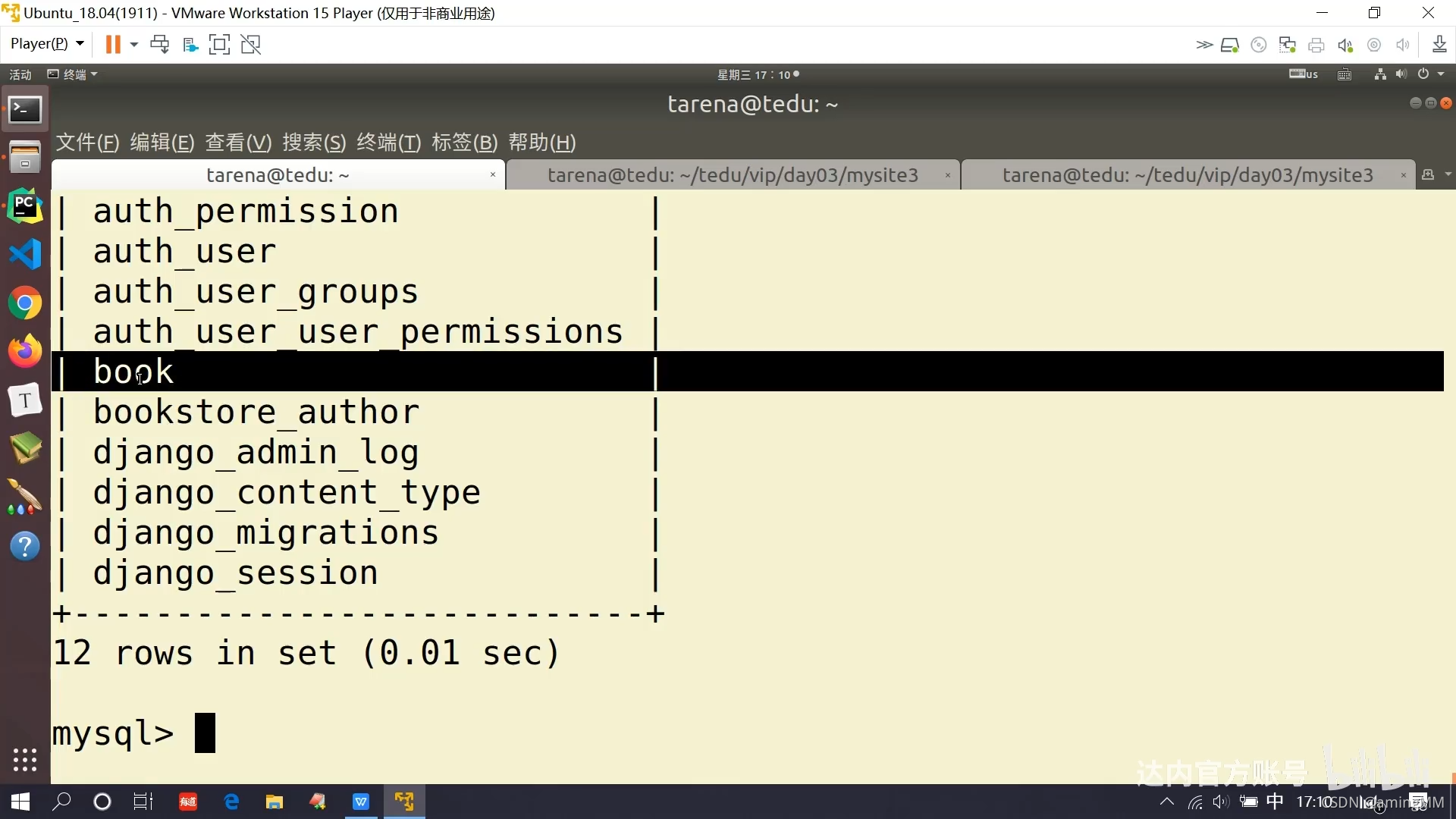

表 列 字段

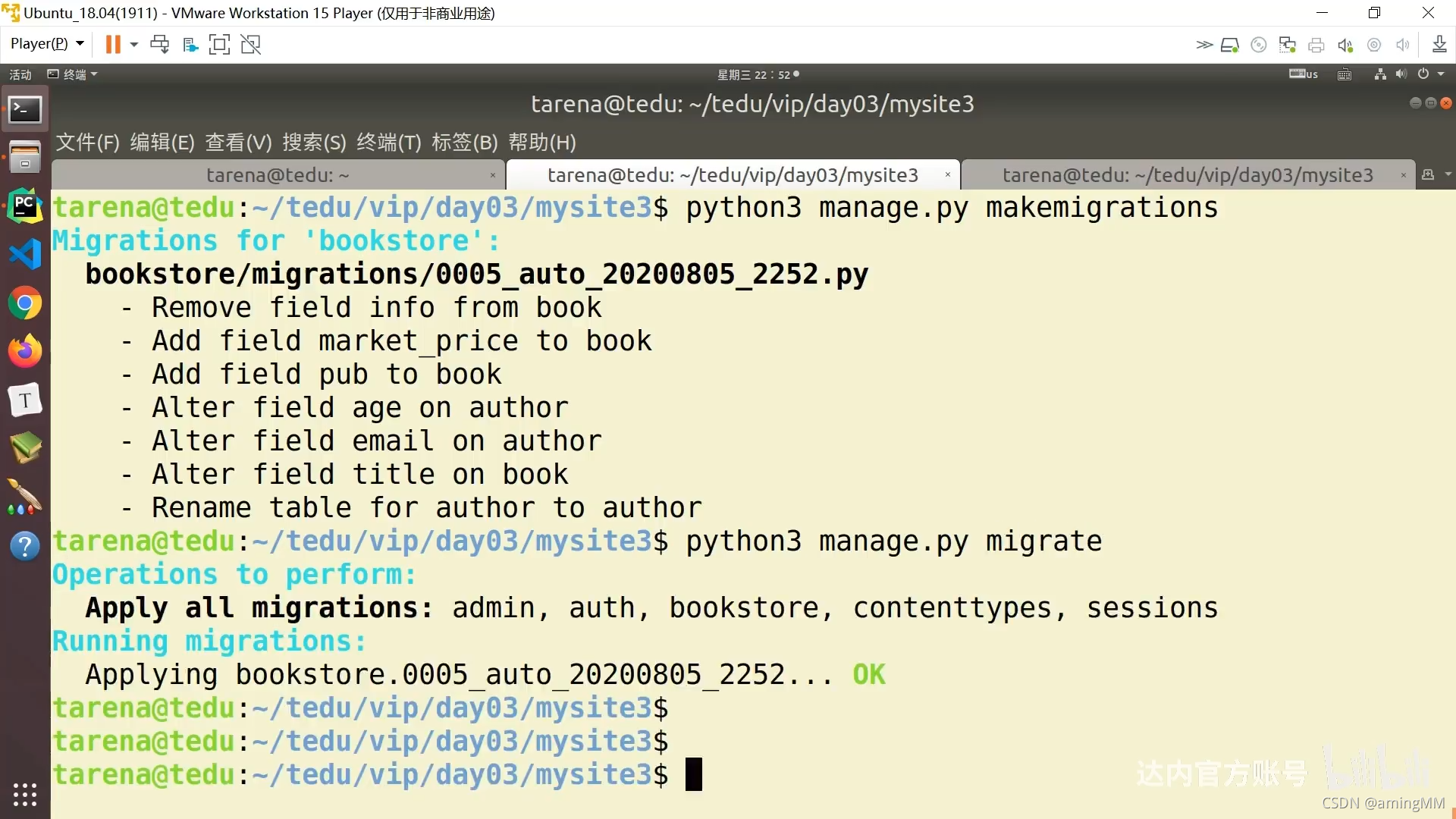



15 ORM-基本操作-创建数据





python3.7 mysql 部署 问题
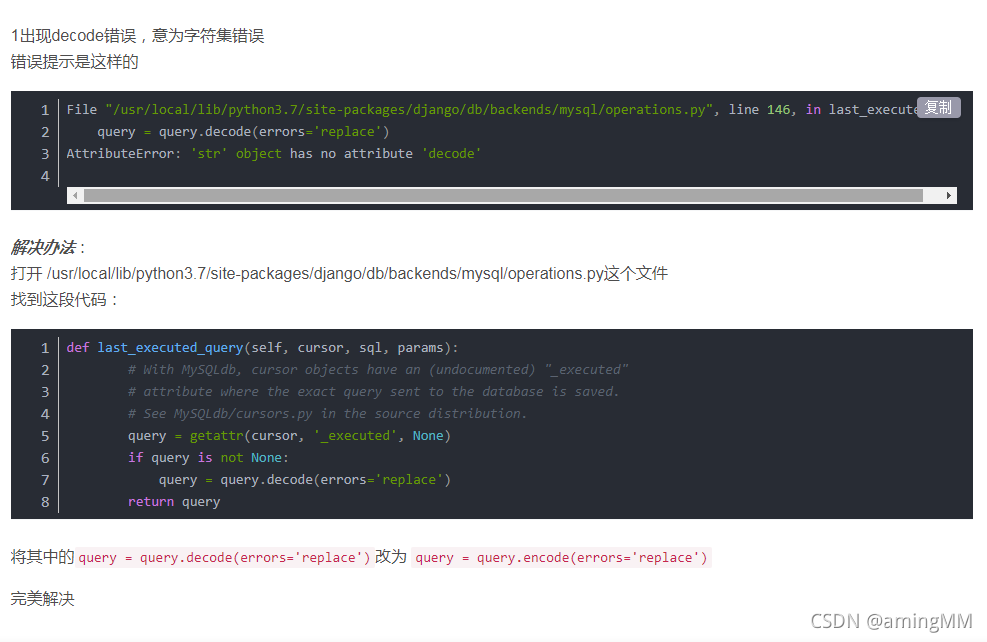
- 不要看 这个解决方案 有问题 还是 decode
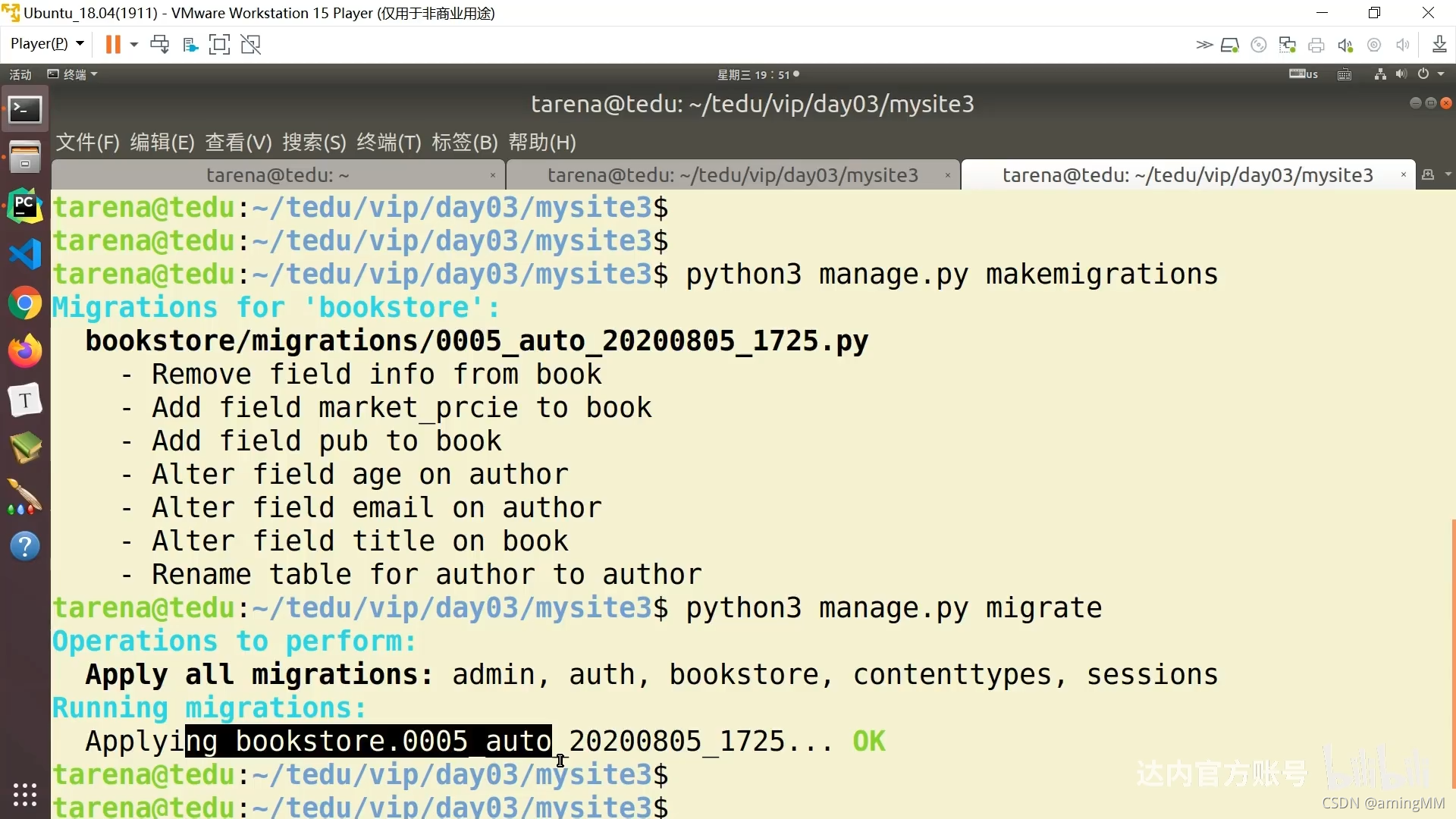
只执行 增量 文件








对象 初始化 再 save




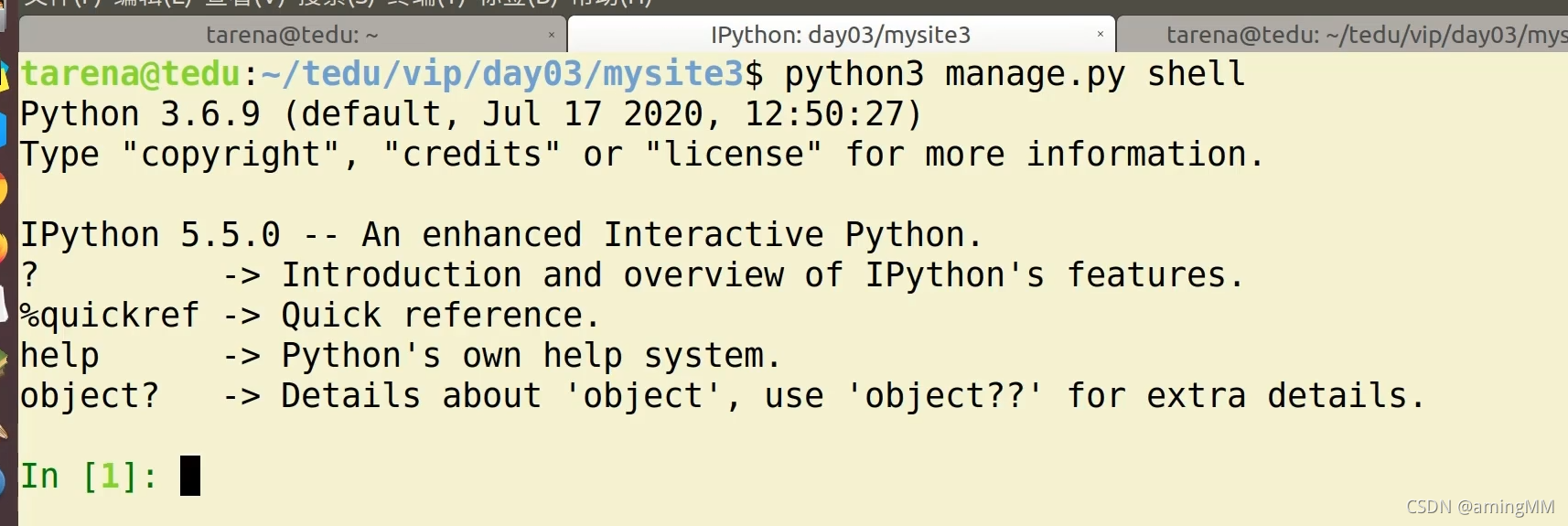
引進模型類






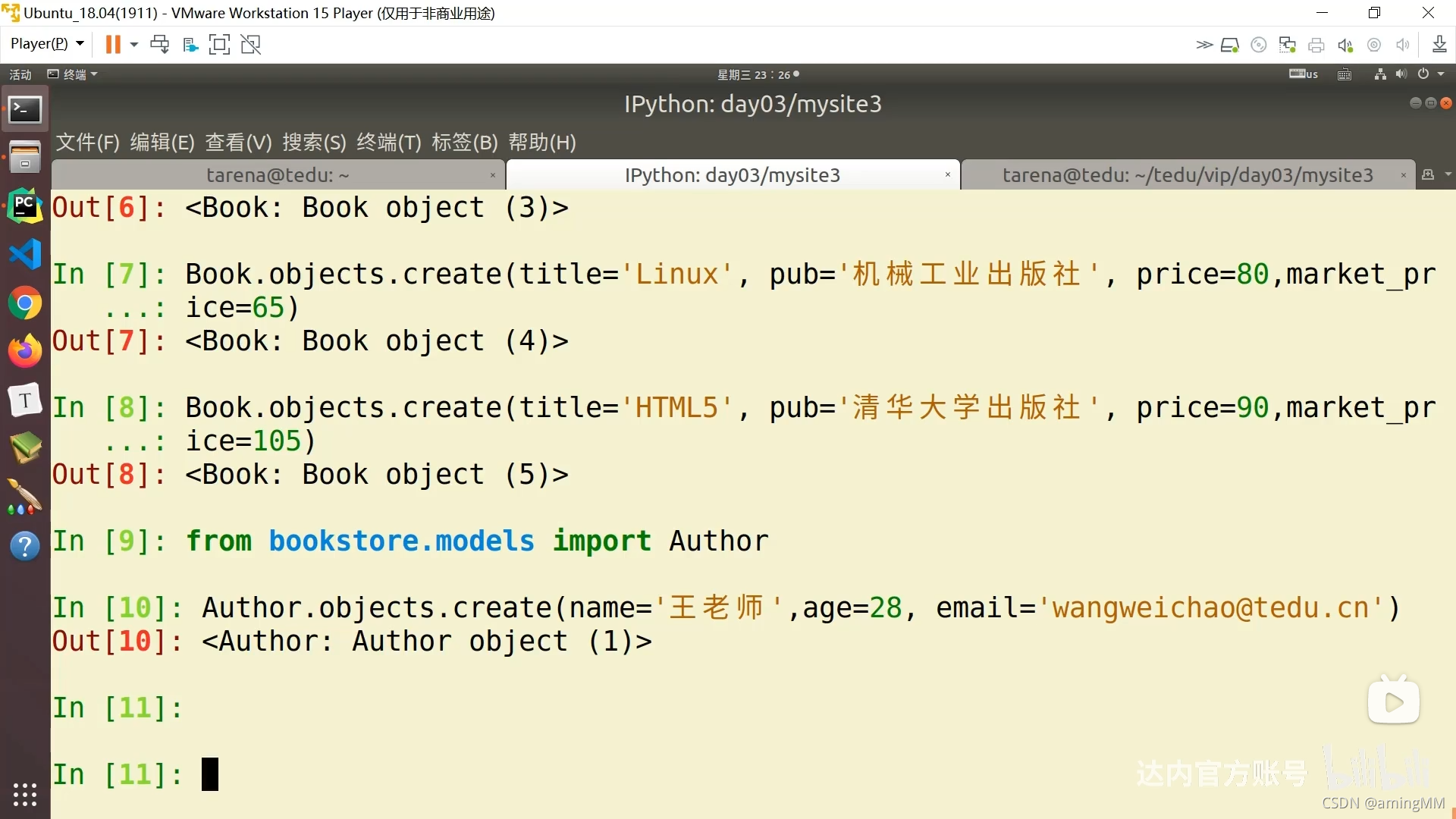

P16 ORM-查询操作





模型 類 數組 循環 索引 切片 的 操作
模型類對象 取中的 屬性




類數組 [ <Object (id) > , … ]





不再是 类的 实例化对象 object


取值 用 字典 取 key 的 这种方式

元组 用 索引取值
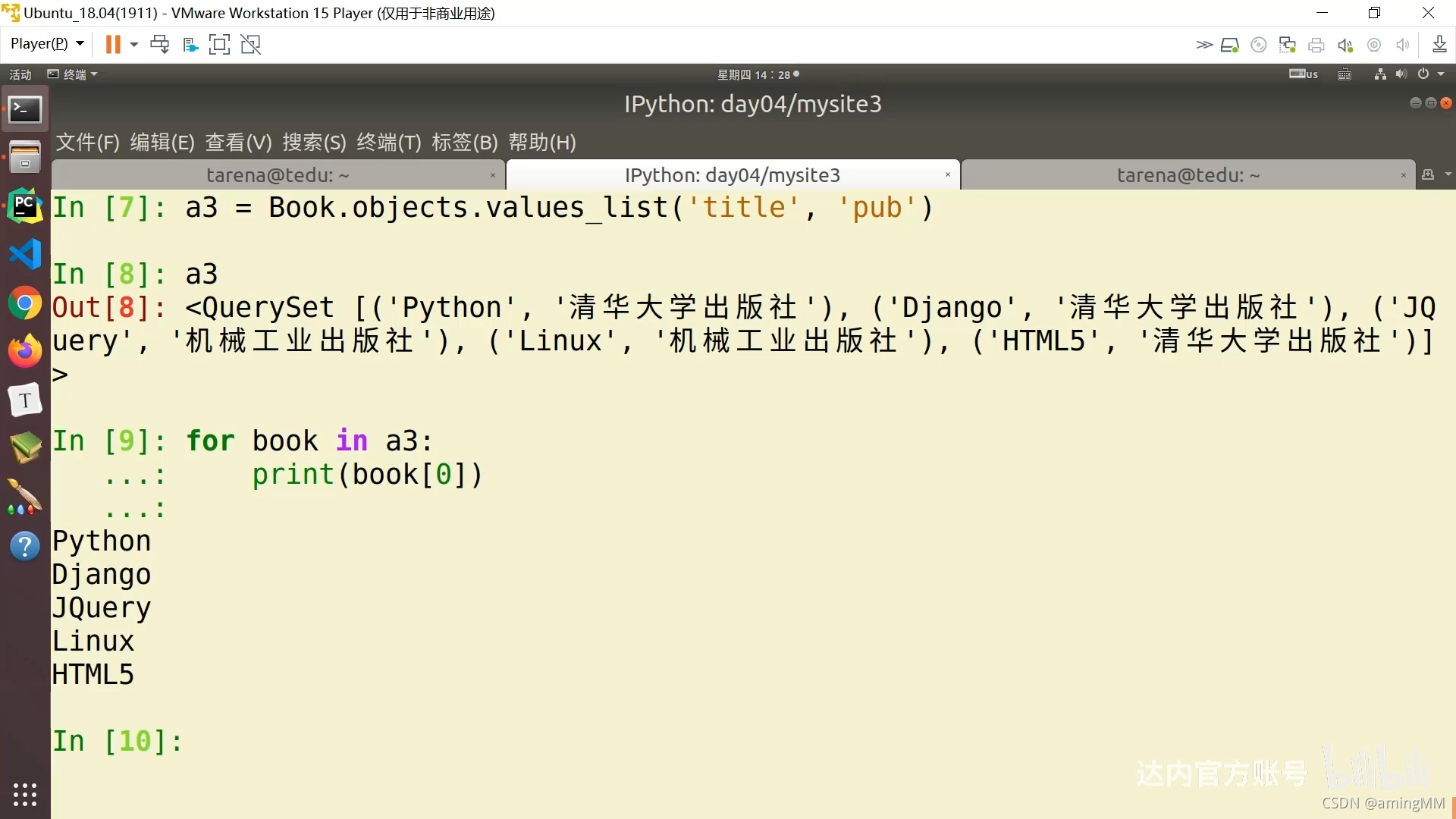

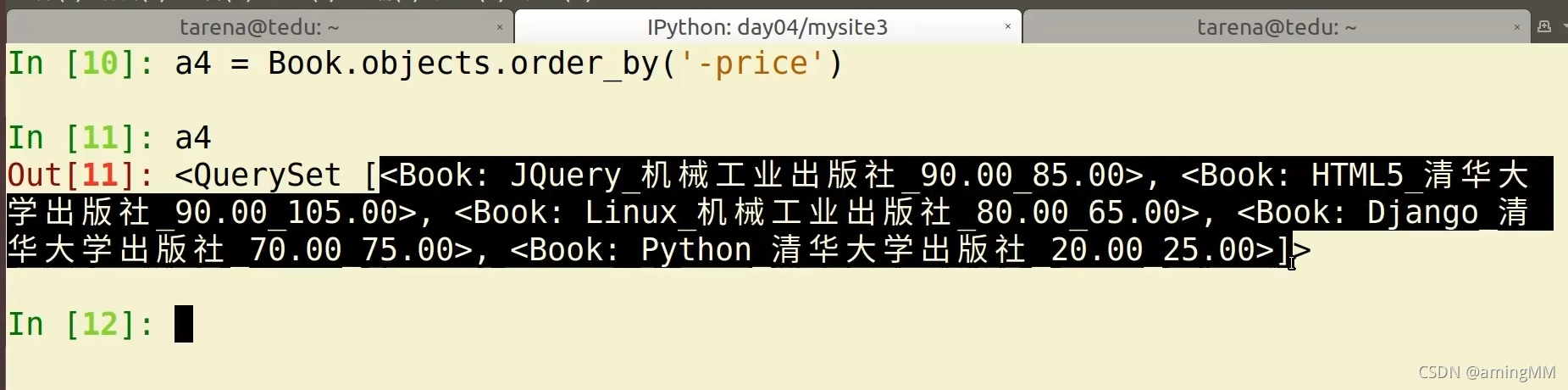
.all 的 排序 返回 object
灵活 组合 顺序 不用想




locals 把 视图函数 的 局部变量 传到 视图里

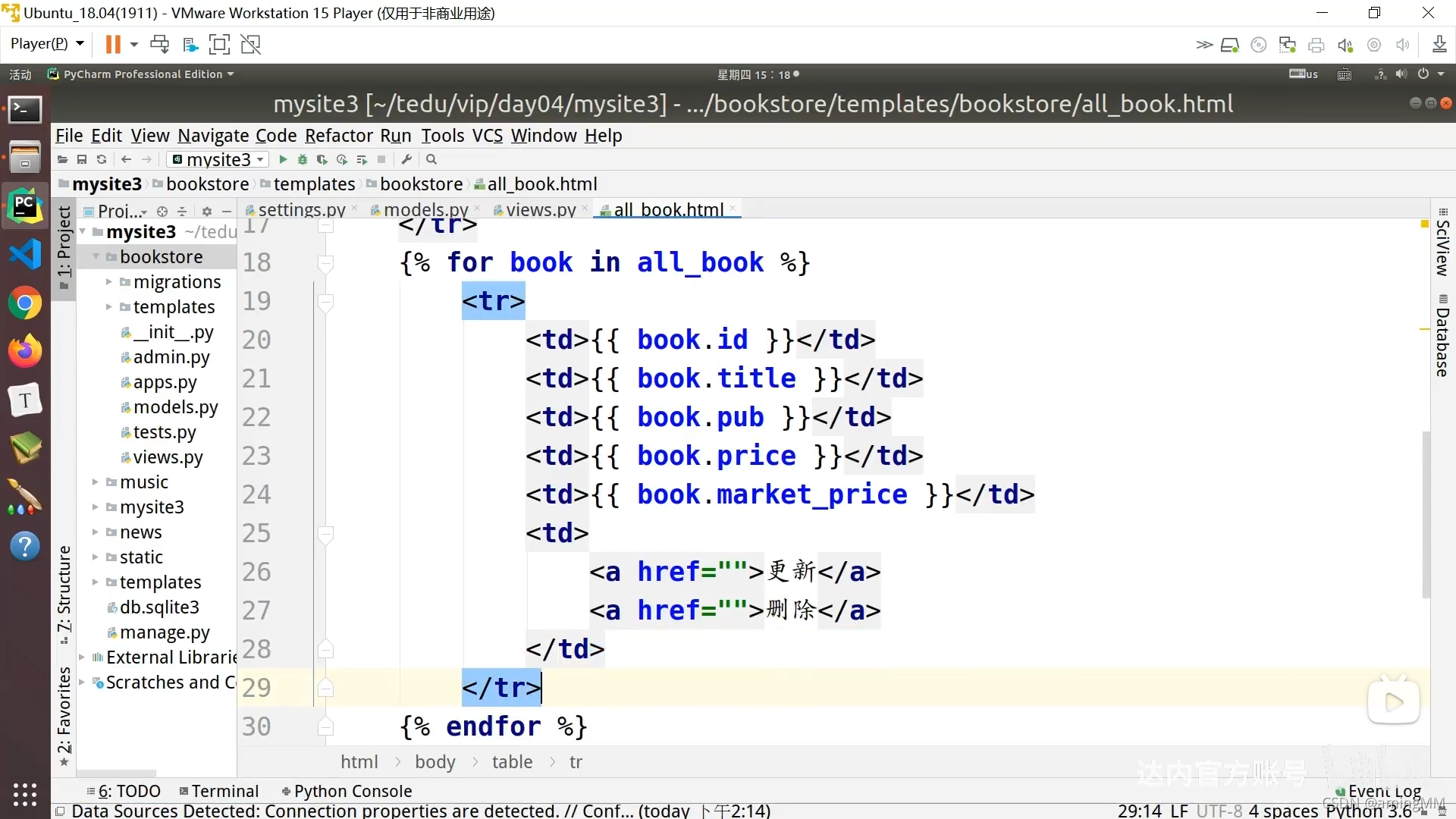



结构 的 元素 表现形式 要注意 object 字典 元组
17 ORM-查询操作

条件查询





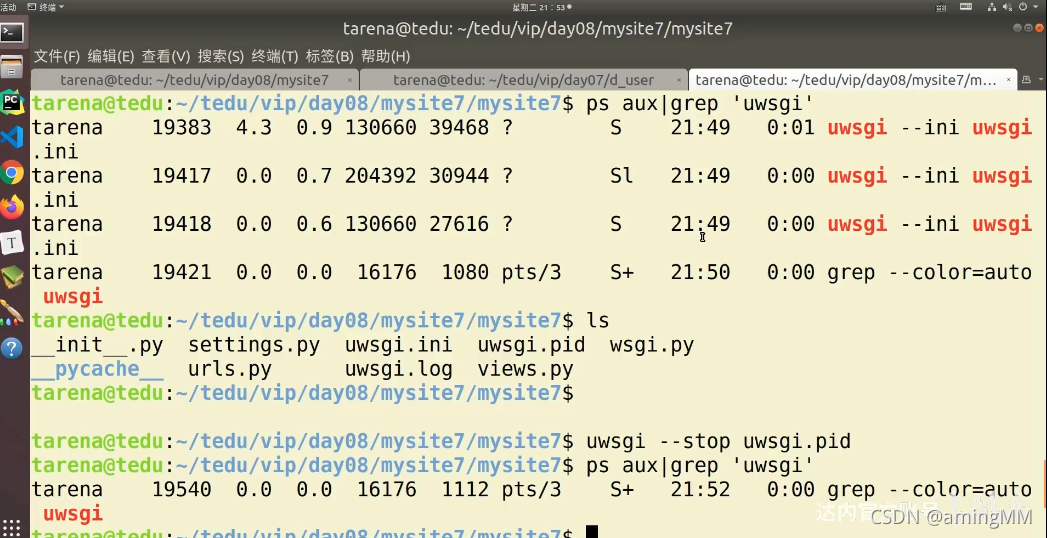
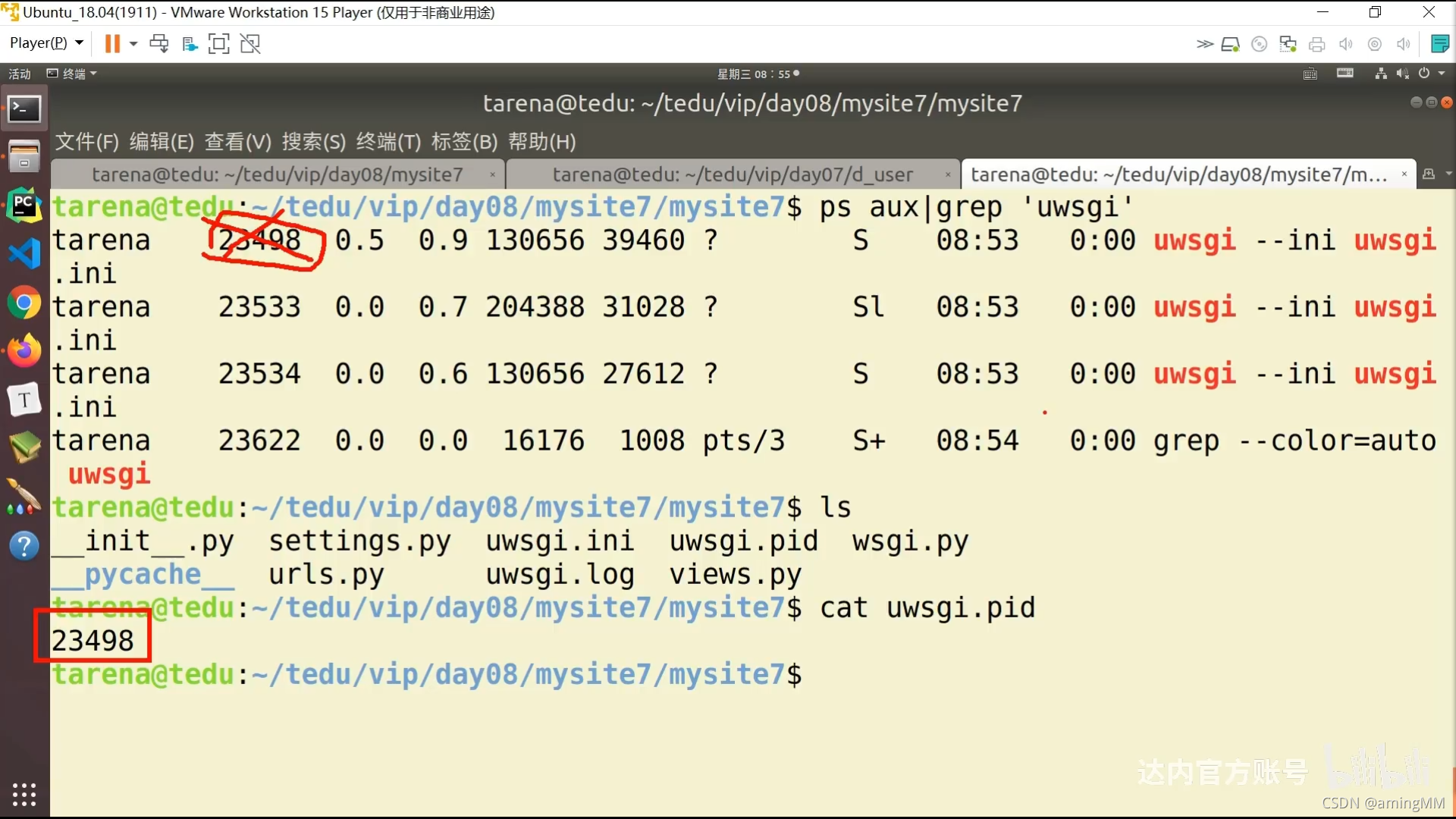
P46 8.04-项目部署-uwsgi









CentOS7安装uwsgi遇到的坑
错误原因:没有装 python-dev
注意: cnetos系统下,并不是交python-dev,而是叫python-devel
由于我的python版本是3.6.7的,所以我这里安装的是python36-devel
yum install python36-devel
yum install uwsgi
通过 yum search python3 可以搜索出python3有关的包

然后可以进行安装 uwsgi 这么解决 by:aming 2021/09/28













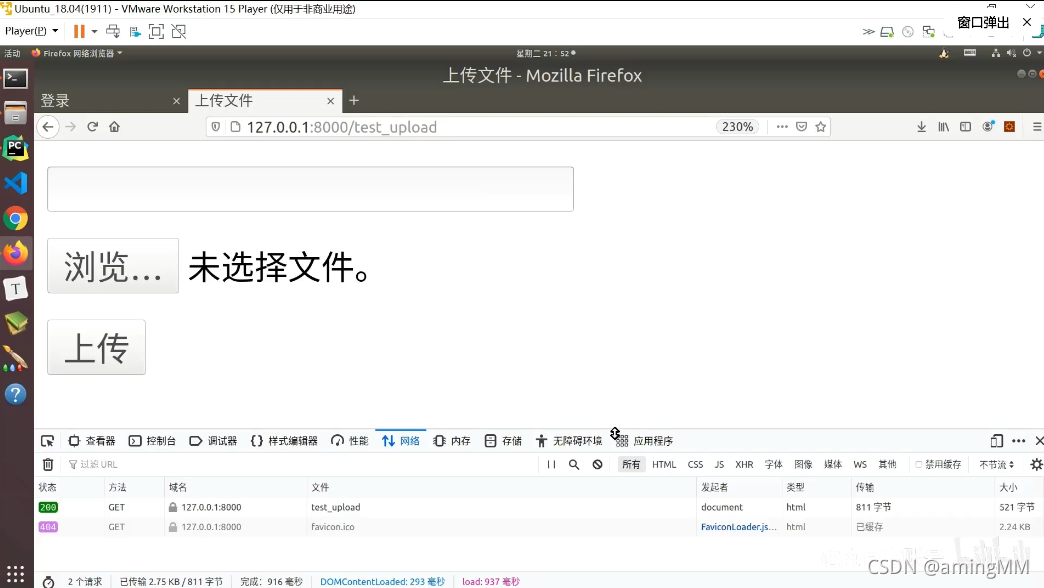





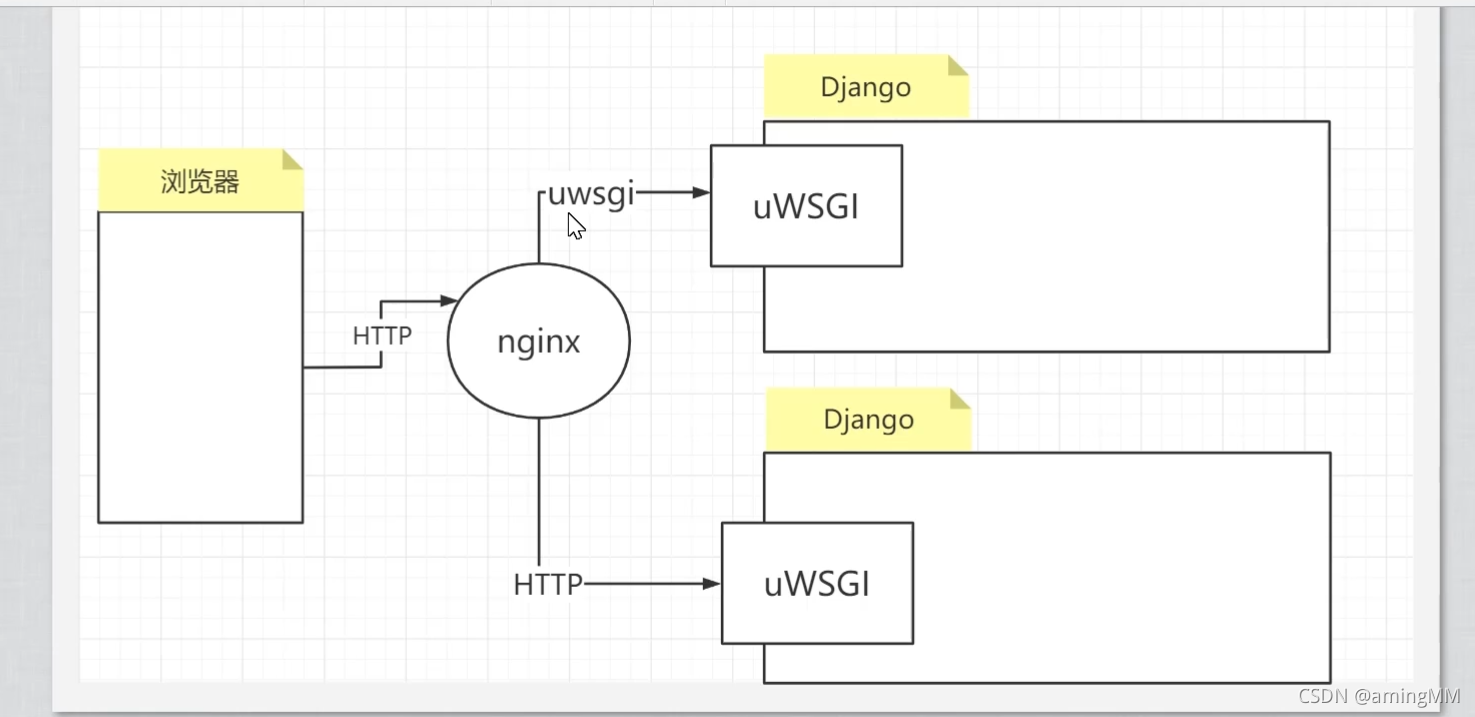
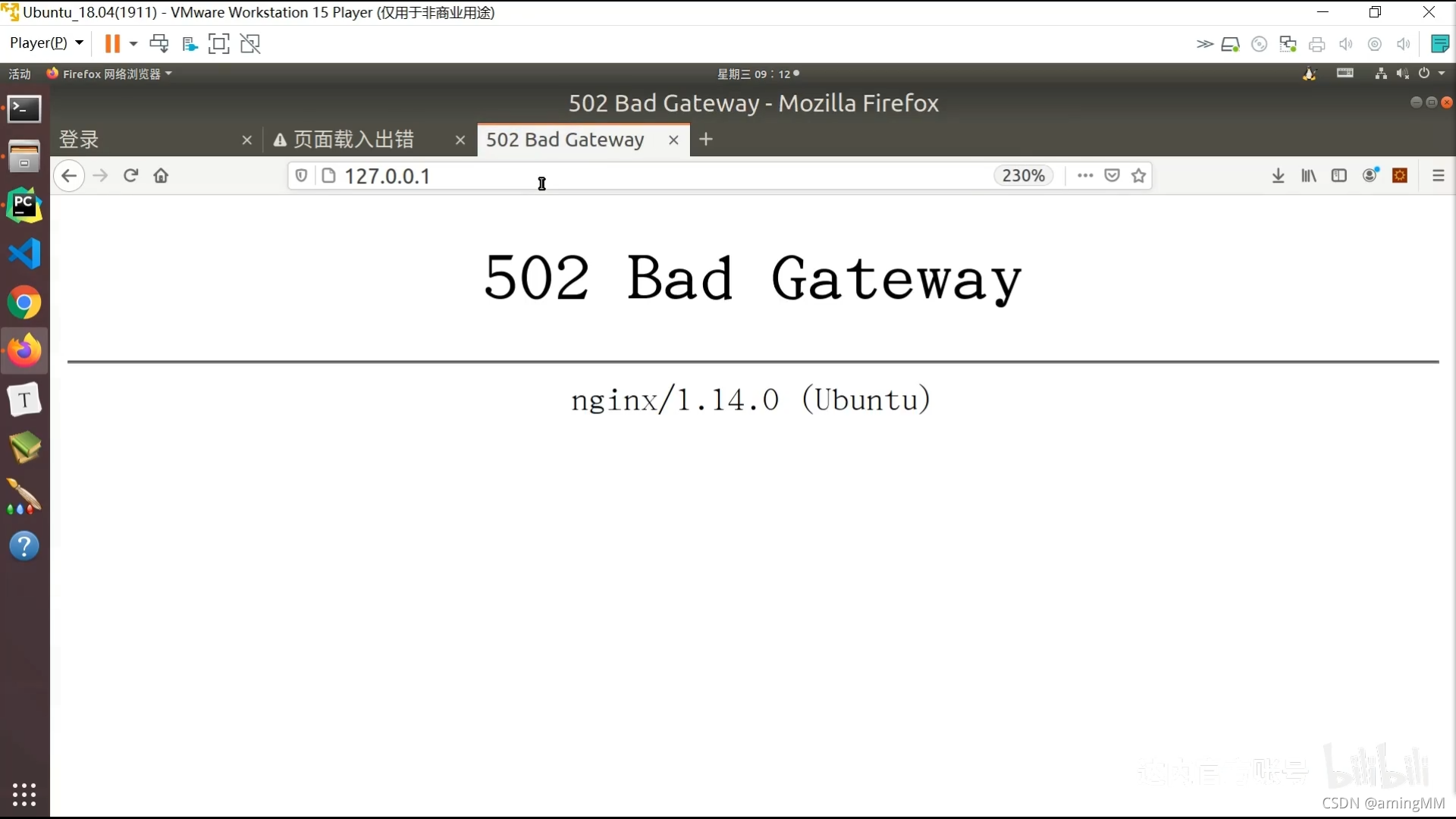
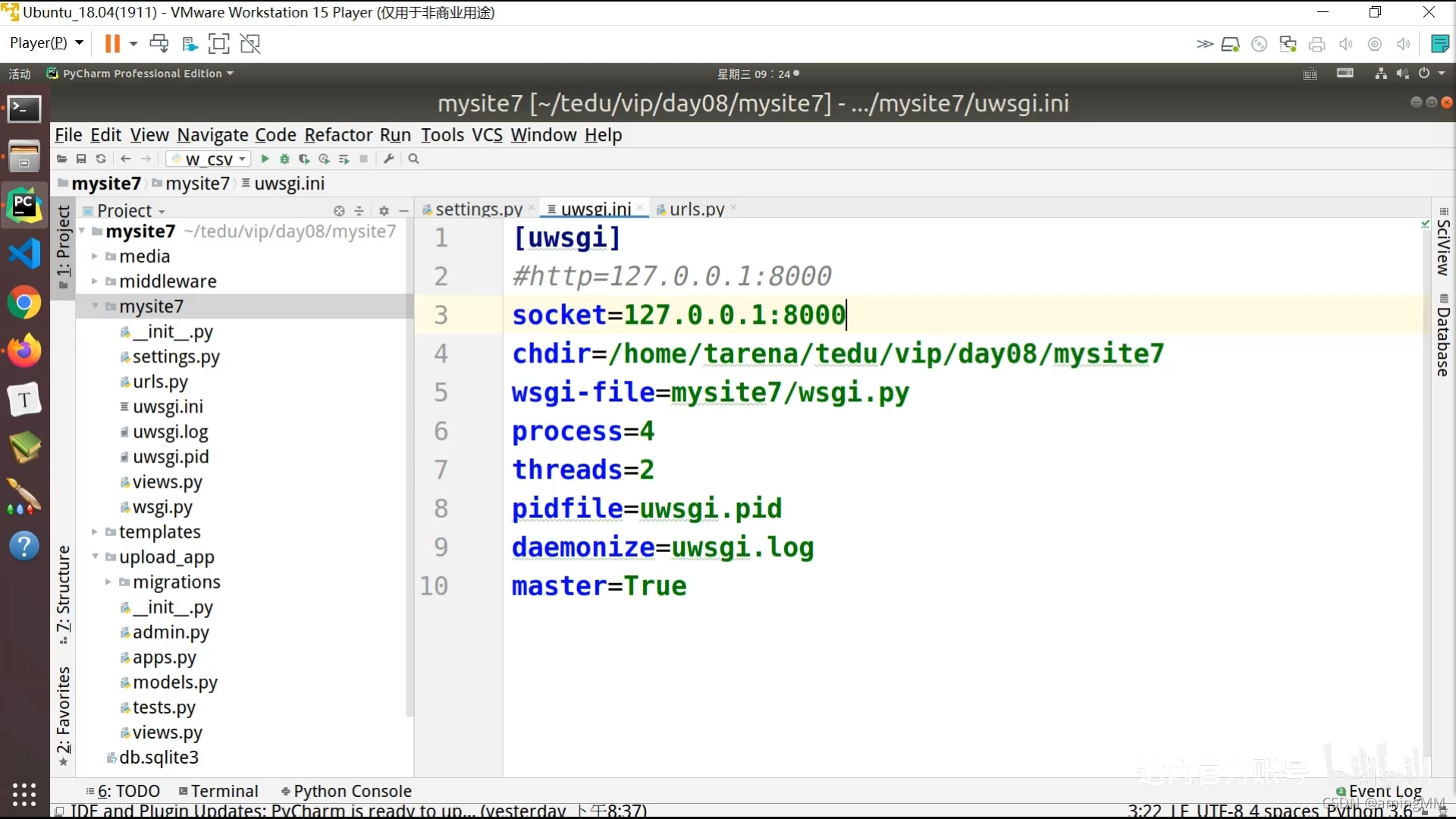
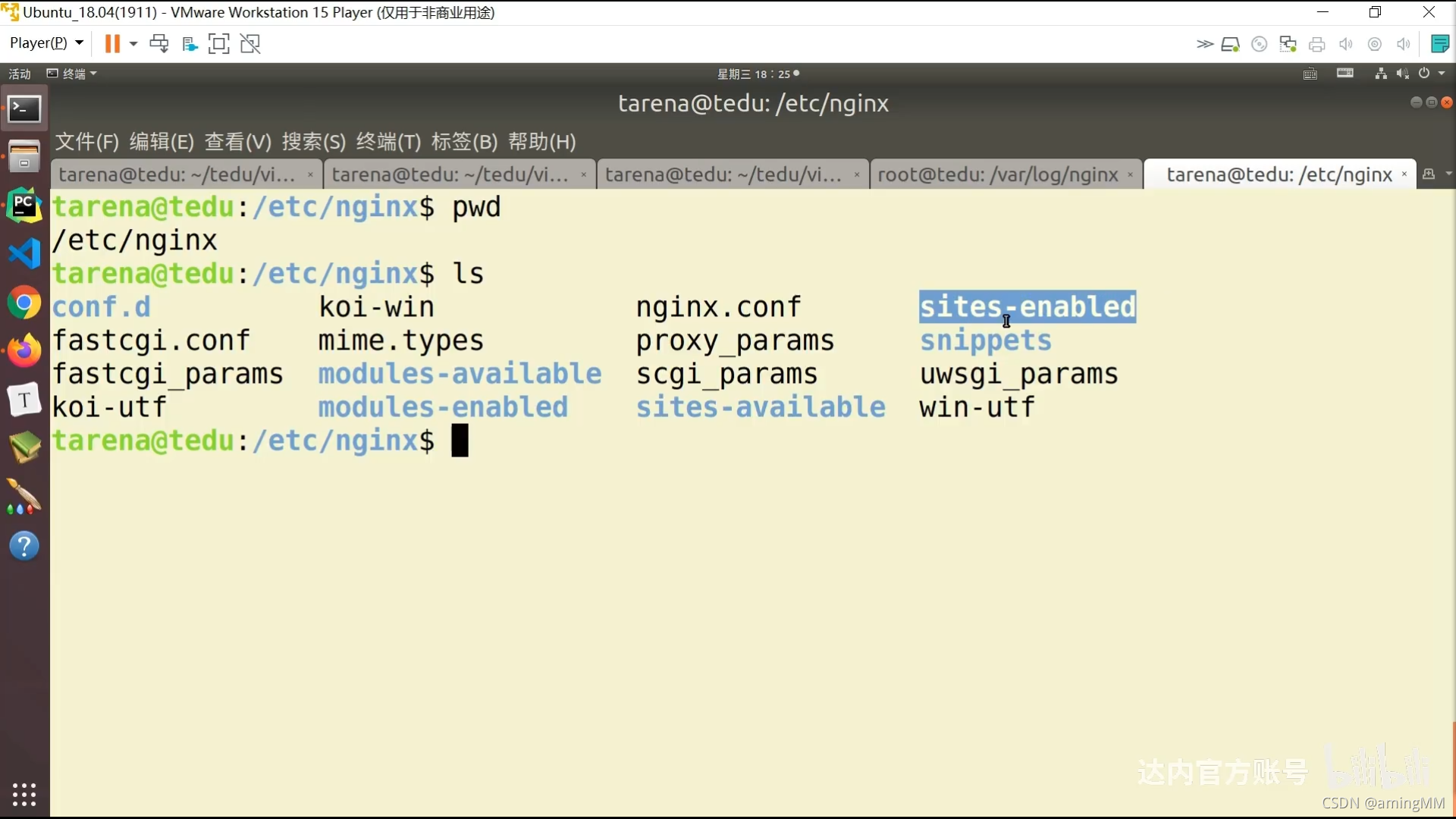
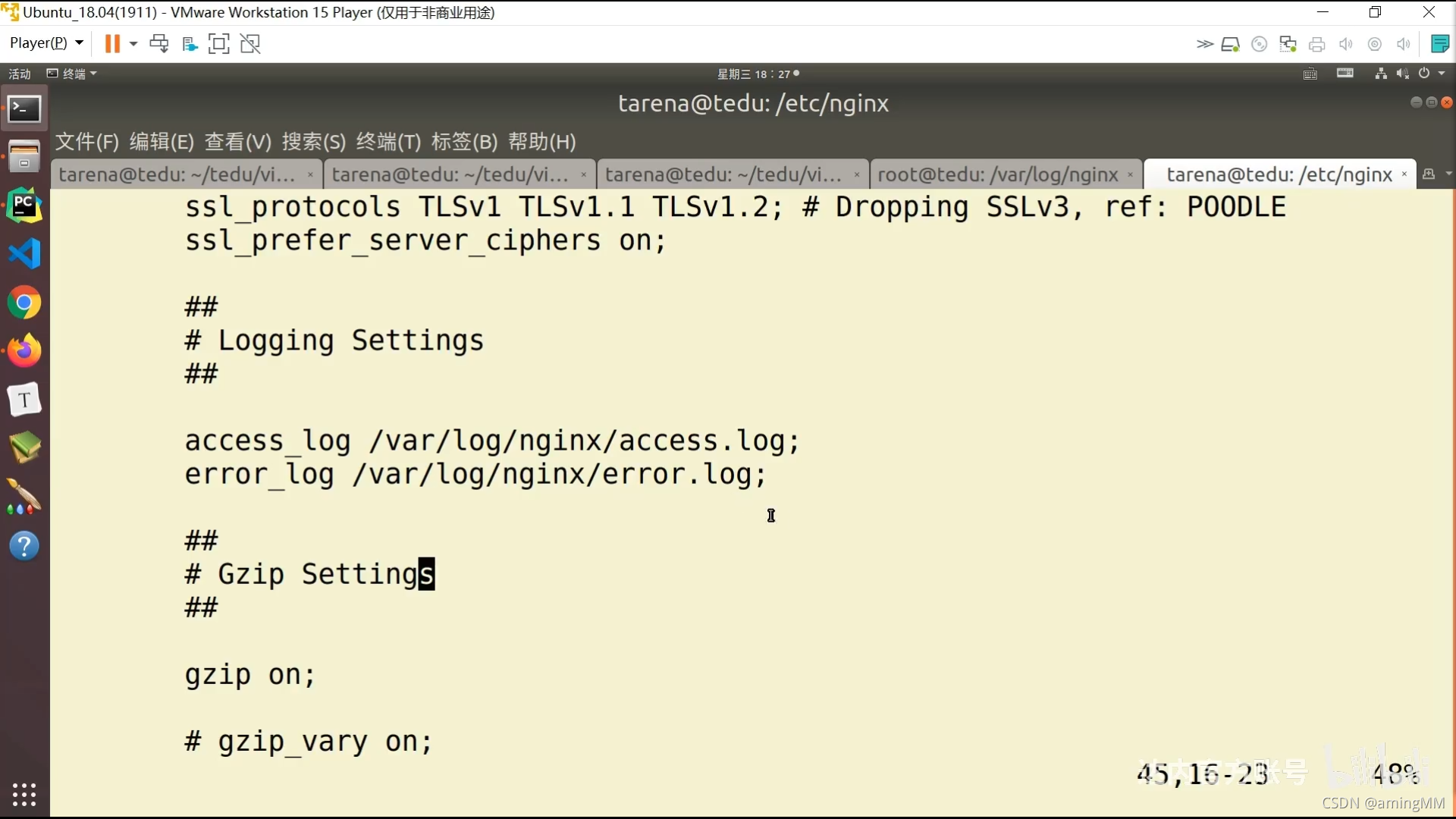
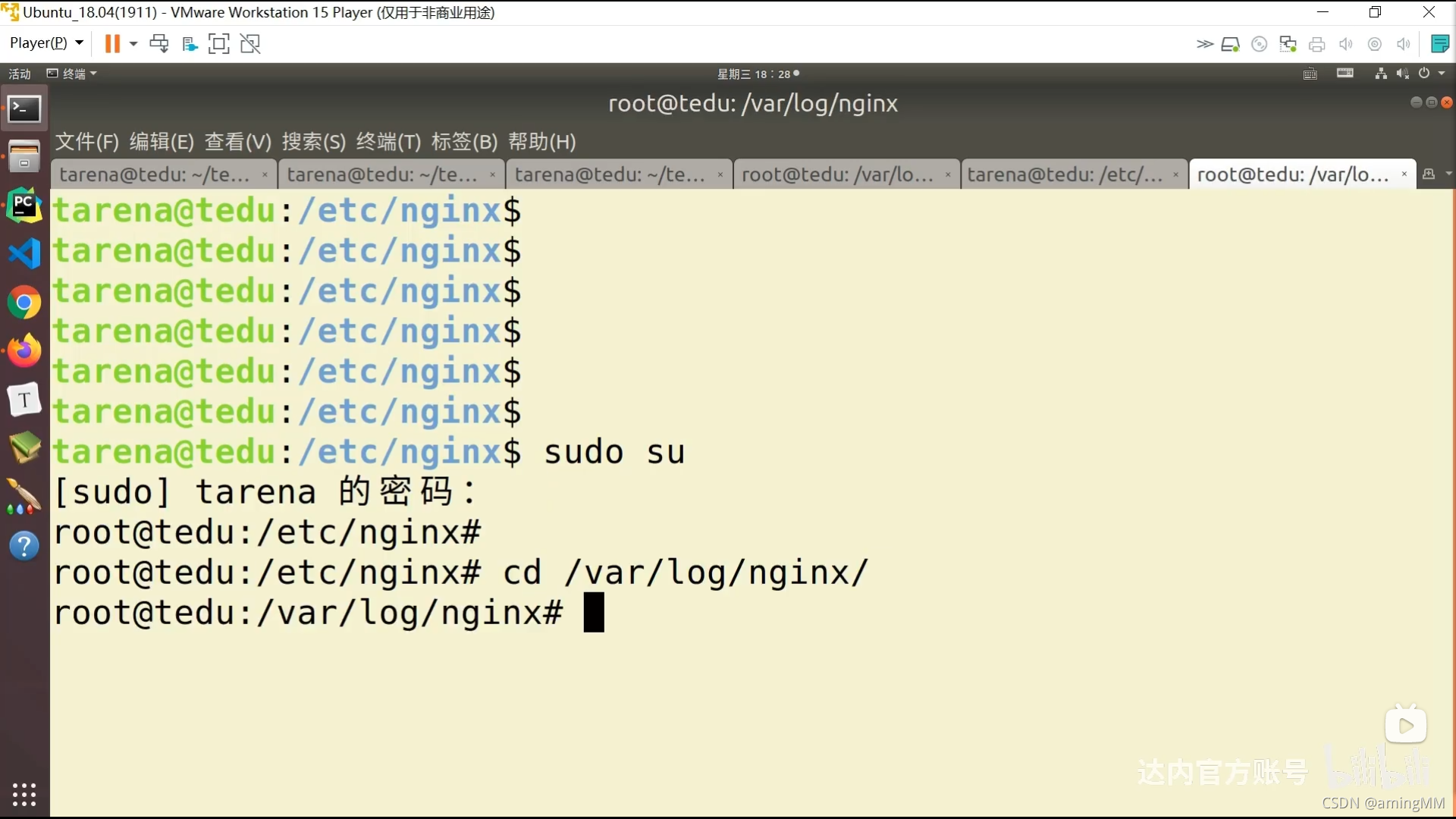
P47 8.05-项目部署-nginx




Kill -9















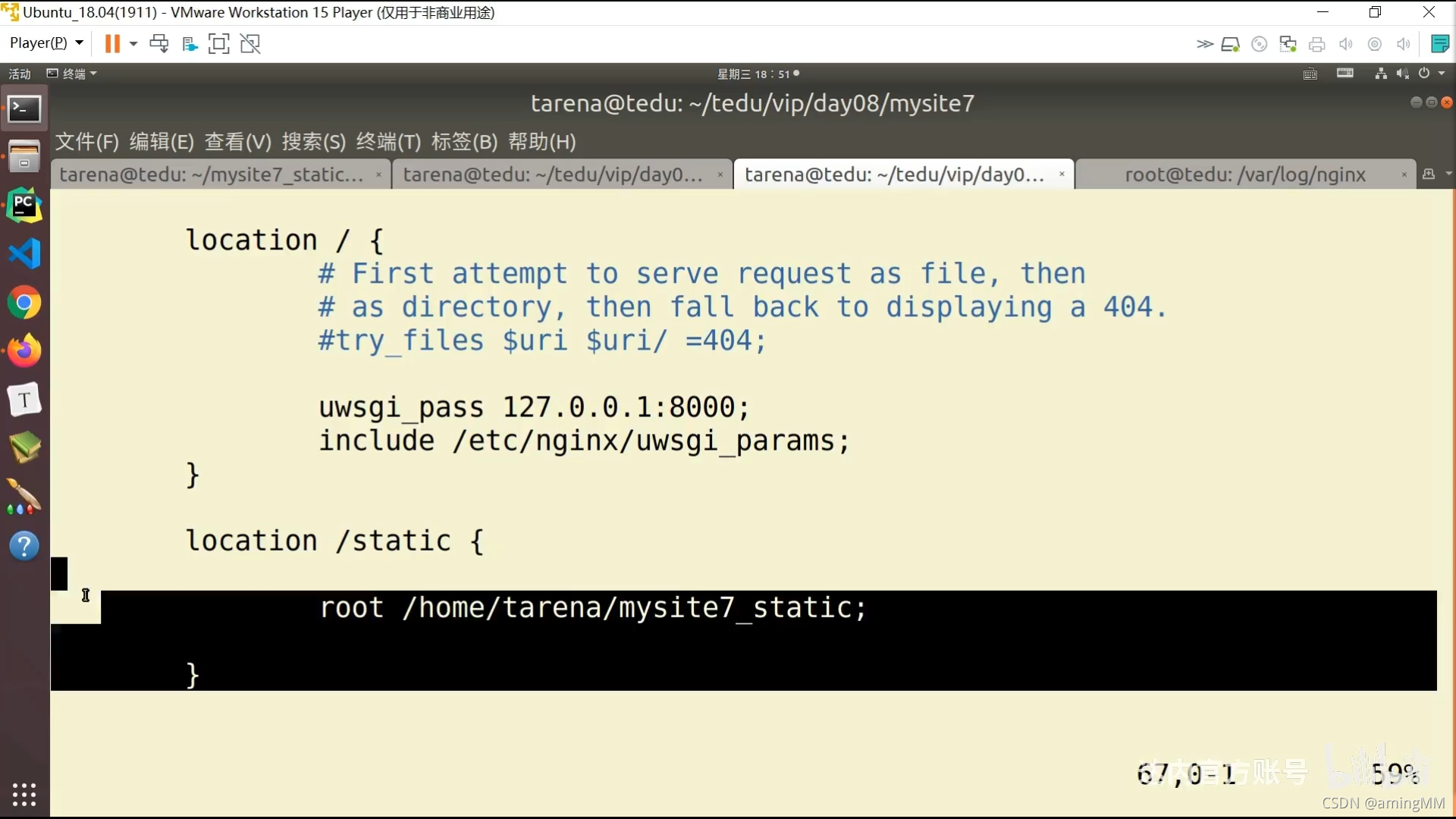
location / {
include uwsgi_params;
uwsgi_pass 127.0.0.1:xxxx; #端口要和uwsgi里配置的一样
uwsgi_param UWSGI_SCRIPT quwan_app.wsgi; #wsgi.py所在的目录名+.wsgi
uwsgi_param UWSGI_CHDIR /www/wwwroot/www.xxxx.top/; #项目路径
}
location /static/ {
alias /www/wwwroot/www.xxxx.cn/static/media/; #静态资源路径
}





看日志



kill掉 端口 进程 和 ini启动的 进程




P48 8.06-项目部署-nginx





















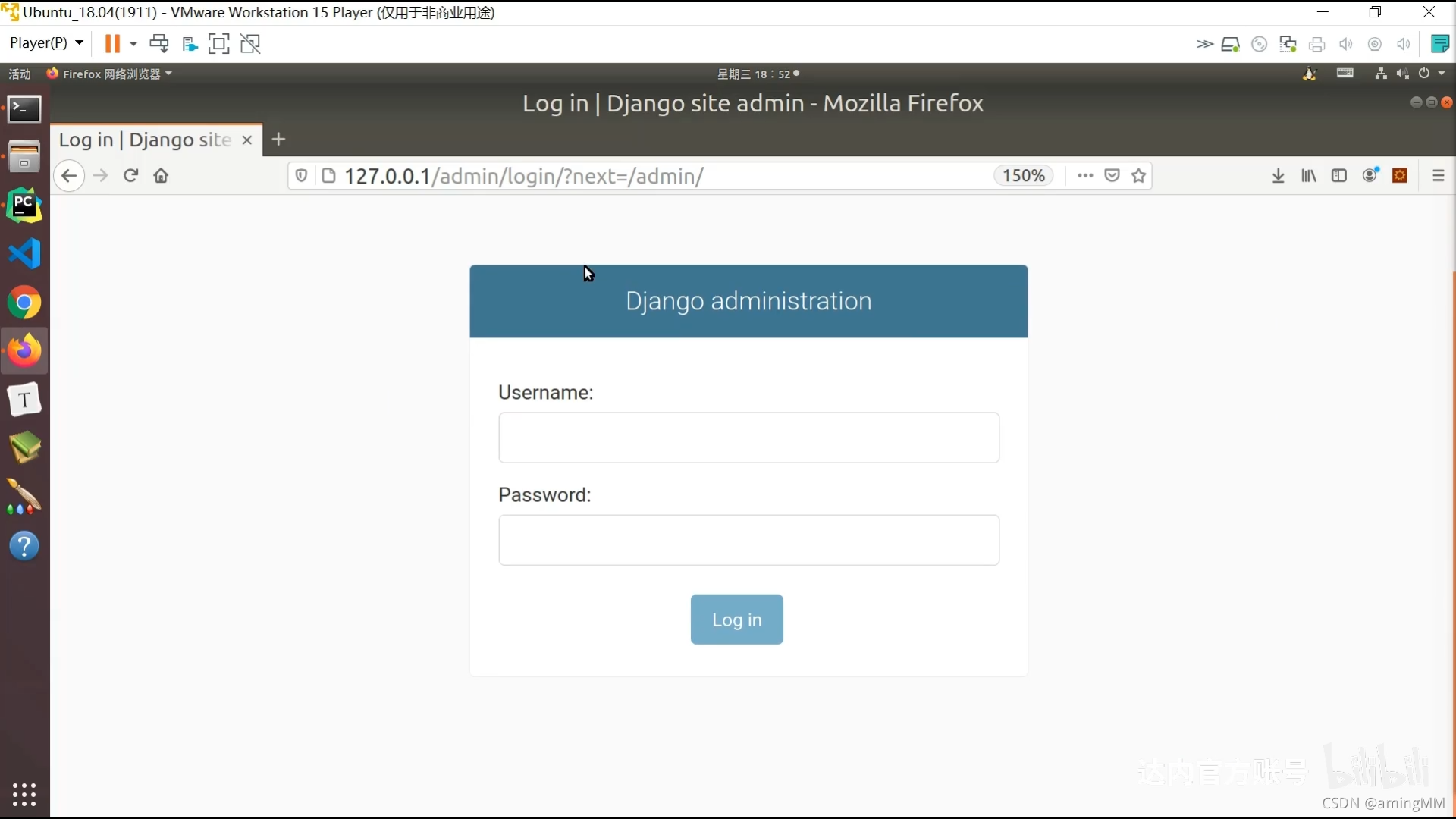











gradlew processDebugManifest --stacktrace
python -m django --version
pip freeze > requirements.txt
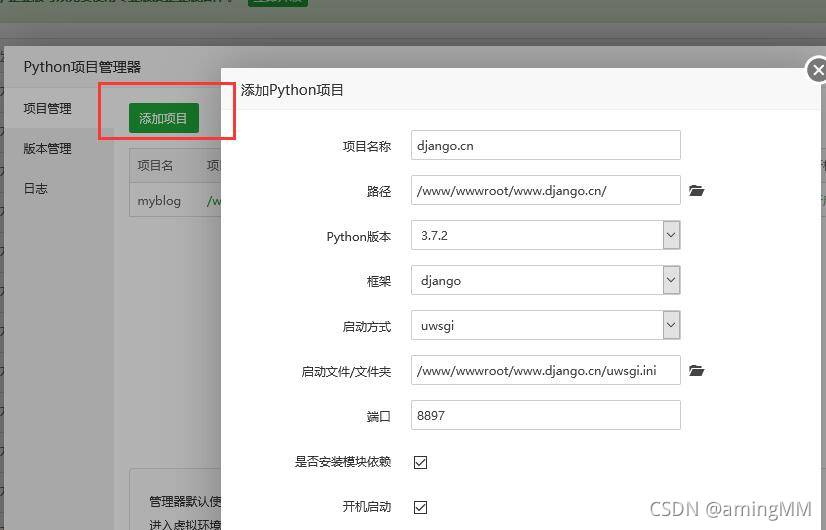
留意:
使用Python项目管理插件新建项目成功之后,会自动在项目j源码目录里创建一个虚拟环境,虚拟环境目录一般都是以项目名_venv形式命名的。
进入虚拟环境方法:
在命令行输入 source 项目路径/项目名_venv/bin/activate 如:
source /www/wwwroot/myblog/myblog_venv/bin/activate
项目管理器默认使用pip安装项目根目录requirements.txt内的模块,这也是之前我强调把环境依赖包文件放到项目目录下的原因,如有其他模块需要安装请手动进入虚拟环境安装。
#把APP静态资源收集到指定的目录下,这里我收集到static目录下
STATIC_ROOT = os.path.join(BASE_DIR, 'static')
之后在SSH终端进入项目虚拟环境:
source /www/wwwroot/myblog/myblog_venv/bin/activate

出现项目名_venv这个标记,才说明已经成功进入虚拟环境。
然后我们使用下面的命令收集静态文件:
python manage.py collectstatic
关联查询
on_delete参数的各个值的含义:
on_delete=None, # 删除关联表中的数据时,当前表与其关联的field的行为
on_delete=models.CASCADE, # 删除关联数据,与之关联也删除
on_delete=models.DO_NOTHING, # 删除关联数据,什么也不做
on_delete=models.PROTECT, # 删除关联数据,引发错误ProtectedError
# models.ForeignKey('关联表', on_delete=models.SET_NULL, blank=True, null=True)
on_delete=models.SET_NULL, # 删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空,一对一同理)
# models.ForeignKey('关联表', on_delete=models.SET_DEFAULT, default='默认值')
on_delete=models.SET_DEFAULT, # 删除关联数据,与之关联的值设置为默认值(前提FK字段需要设置默认值,一对一同理)
on_delete=models.SET, # 删除关联数据,
a. 与之关联的值设置为指定值,设置:models.SET(值)
b. 与之关联的值设置为可执行对象的返回值,设置:models.SET(可执行对象)
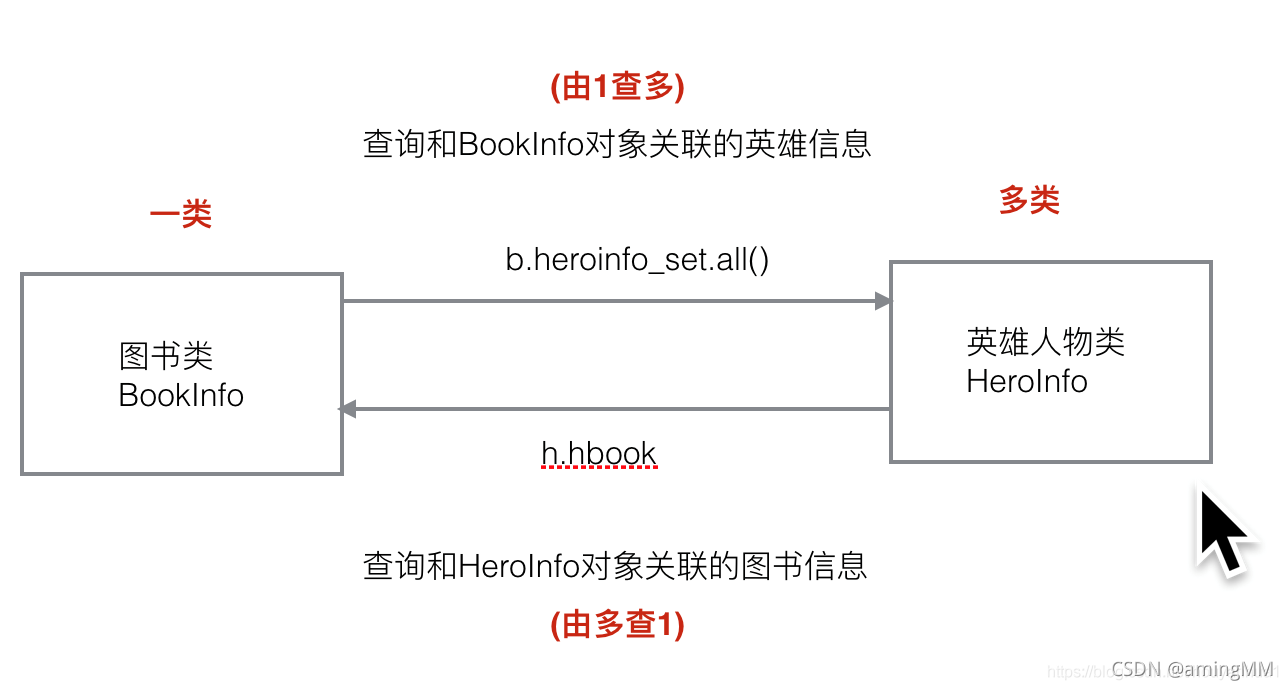
Django常用的QuerySet操作
Django常用的QuerySet操作
在这里我根据是否支持链式调用分类进行介绍
1. 支持链式调用的接口
all
使用频率比较高,相当于SELECT * FROM table 语句,用于查询所有数据。
filter
使用频率比较高,根据条件过滤数据,常用的条件基本上字段等于、不等于、大于、小于。当然,还有其他的,比如能修改成产生LIKE查询的:Model.objects.filter(content__contains="条件")。
exclude
与filter是相反的逻辑
reverse
将QuerySet中的结果倒叙排列
distinct
用来进行去重查询,产生SELECT DISTINCT这样的SQL查询
none
返回空的QuerySet
2. 不支持链式调用的接口
get
比如Post.objects.get(id=1)用于查询id为1的文章:如果存在,则直接返回对应的Post实例;如果不存在,则抛出DoesNotExist异常。所以一般情况下,要使用异常捕获处理:
1 try:
2 post = Post.objects.get(id=1)
3 except Post.DoesNotExist:
4 #做异常情况处理
create
用来直接创建一个Model对象,比如post = Post.objects.create(title="一起学习")。
get_or_create
根据条件查找,如果没查找到,就调用create创建。
update_or_create
与get_or_create相同,只是用来做更新操作。
count
用于返回QuerySet有多少条记录,相当于SELECT COUNT(*) FROM table 。
latest
用于返回最新的一条记录,但要在Model的Meta中定义:get_latest_by= <用来排序的字段>。
earliest
同上,返回最早的一条记录。
first
从当前QuerySet记录中获取第一条。
last
同上,获取最后一条。
exists
返回True或者False,在数据库层面执行SELECT (1) AS "a" FROM table LIMIT 1的查询,如果只是需要判断QuerySet是否有数据,用这个接口是最合适的方式。
不要用count或者len(queryset)这样的操作来判断是否存在。相反,如果可以预期接下来会用到QuerySet中的数据,可以考虑使用len(queryset)的方式来做判断,这样可以减少一次DB查询请求。
bulk_create
同create,用来批量创建记录。
in_ bulk
批量查询,接收两个参数id_ list和filed_ name。可以通过Post.objects. in_ bulk([1, 2, 3])查询出id为1、2、3的数据,返回结果是字典类型,字典类型的key为查询条件。返回结果示例: {1: <Post 实例1>, 2: <Post实例2>,3:<Post实例3>}。
update
用来根据条件批量更新记录,比如: Post.objects.filter(owner__name='123').update(title='测试更新')。
delete
同update,这个接口是用来根据条件批量删除记录。需要注意的是,和delete都会触发Djiango的signal
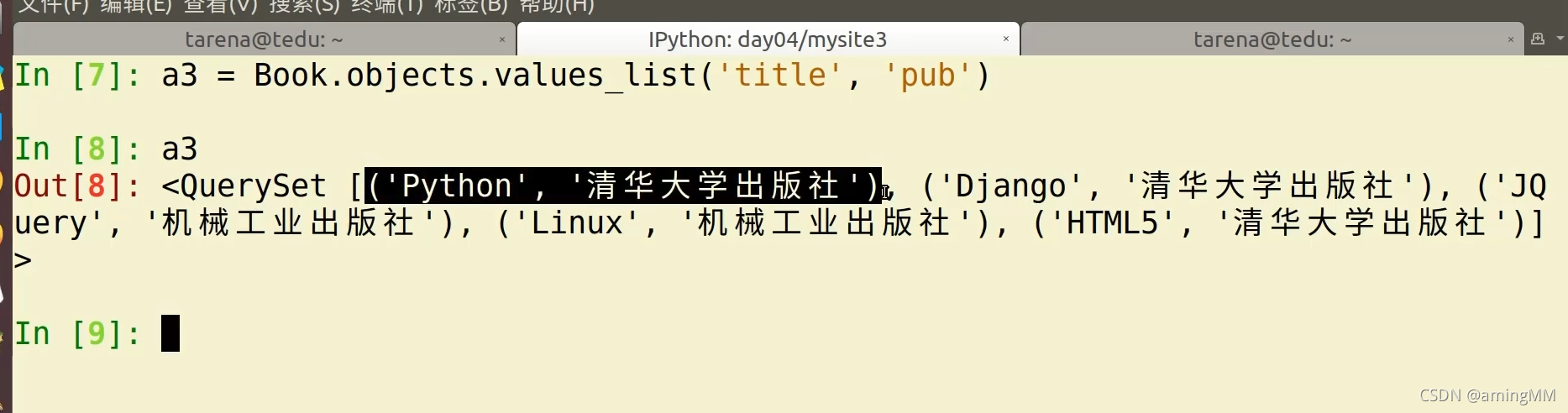
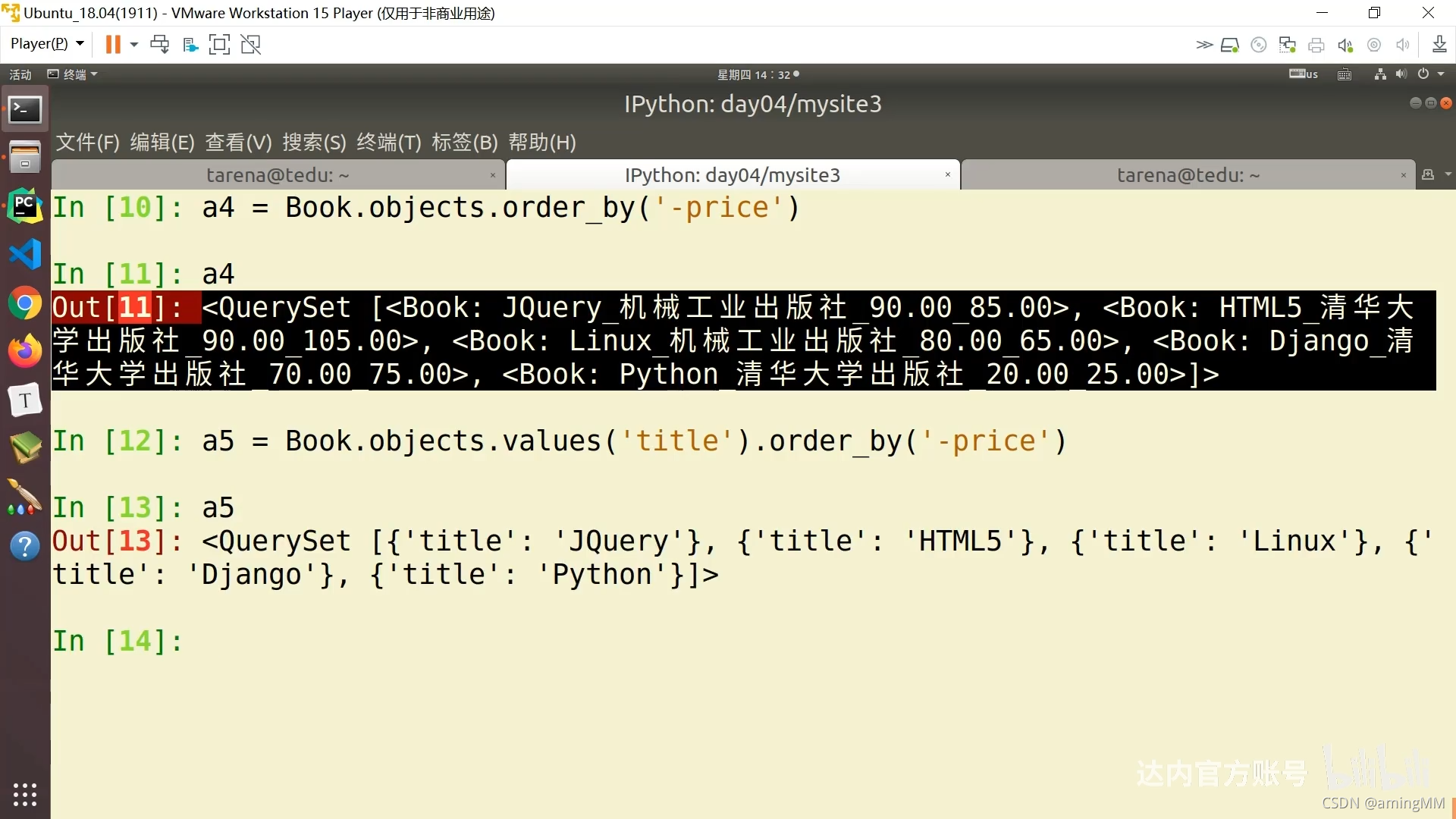
values
当我们明确知道只需要返回某个字段的值,不需要Model实例时,用它,用法如下:
1 title_list = Post.objects.filter(category_id=1).values('title')
返回的结果包含dict的QuerySet,类似这样: <QuerySet [{'title' :xxx},]>
values_list
同values,但是直接返回的是包含tuple的QuerySet:
1 titles_list = Post.objects.filter(category=1).values_list('title')
返回结果类似: <QuerySet[("标题",)]>
如果只是一个字段的话,可以通过增加flat=True参数,便于我们后续 处理:
1 title_list = Post.objects.filter(category=1).values_list('title',flat=True)
2 for title in title__list:
3 print(title)
2.1进阶接口
除了上面介绍的常用接口外,还有其他用来提高性能的接口,在下面介绍。 在优化Django项目时,尤其要考虑这几种接口的用法。
defer
把不需要展示的字段做延迟加载。比如说,需要获取到文章中除正文外的其他字段,就可以通过posts = Post.objects.all() .defer('content'),这样拿到的记录中就不会包含content部分。但是当我们需要用到这个字段时,在使用时会去加载。代码:
1 posts = Post.objects.all().defer('content')
2 for post in posts: #此时会执行数据库查询
3 print (post.content) #此时会执行数据查询,获取到content
当不想加载某个过大的字段时(如text类型的字段),会使用defer,但是上面的演示代产生N+1的查询问题,在实际使用时千万要注意!
注意:上面的代码是个不太典型的 N+1查询的问题, 一般情况下 由外键查询产生的N+1问题比较多,即一条查询请求返回N条数据,当我们操作数据时,又会产生额外的请求。这就是N+1问题,所有的ORM框架都存在这样的问题。
only
同defer接口刚好相反, 如果只想获取到所有的title记录,就可以使用only,只获取title的内容,其他值在获取时会产生额外的查询。
select_related
这就是用来解决外键产生的N+1问题的方案。我们先来看看什么情况下会产生这个问题:
posts = Post.objects.all ()
for post in posts: #产生数据库查询
print (post.owner) #产生额外的数据库查询
代码同上面类似,只是这里用的是owenr(是关联表)。它的解决方法就是用select_ related接口:
post = Post.objects.all() .select_related('category')
for post in posts: # 产生数据库查询,category数据也会一次性查询出来
print (post.category)
当然,这个接口只能用来解决一对多的关联关系。对于多对多的关系,还得使用下面的接口。
prefetch_related
针对多对多关系的数据,可以通过这个接口来避免N+1查询。比如,post和tag的关系可以通过这种方式来避免:
posts = Post.objects.all().prefetch_related('tag')
for post in posts:#产生两条查询语句,分别查询post和tag
print(post.tag.al1())
3.常用的字段查询
contains
包含,用来进行相似查询。
icontains
同contains,只是忽略大小写。
exact
精确匹配。
iexact
同exact,忽略大小写。
in
指定某个集合,比如Post.objects.filter(id__in=[1, 2, 3])相当于SELECT FROM table WHERE IN (1, 2, 3);。
gt
大于某个值。比如:Post.objects.filter(id__gt=1)
注意:是__gt
gte
大于等于某个值。
lt
小于某个值。
lte
小于等于某个值。
startswith
以某个字符串开头,与contains类似,只是会产生LIKE '<关键词>%'这样的SQL。
istartswith
同startswith, 忽略大小写。
endswith
以某个字符串结尾。
iendswith
同endswith,忽略大小写。
range
范围查询,多用于时间范围,如Post.objects.filter(created_time__range= ('2018-05-01','2018-06-01'))会产生这样的查询: SELECT .. . WHERE created_ time BETWEEN '2018-05-01' AND '2018-06-01' ;。
关于日期类的查询还有很多,比如date、year和month等,具体等需要时查文档即可。
这里你需要理解的是,Django之所以提供这么多的字段查询,其原因是通过ORM来操作数据库无法做到像SQL的条件查询那么灵活。
因此,这些查询条件都是用来匹配对应SQL语句的,这意味着,如果你知道某个查询在SQL中如何实现,可以对应来看Django提供的接口。
3.1 进阶查询
除了上面基础的查询语句外,Django还提供了其他封装,来满足更复杂的查询,比如 SELECT ... WHERE id = 1 OR id = 2 这样的查询,用上面的基础查询就无法满足。
F
F表达式常用来执行数据库层面的计算,从而避免出现竞争状态。比如需要处理每篇文章的访问量,假设存在post.pv这样的字段,当有用户访问时,我们对其加1:
post = Post.objects.get(id=1)
post.pv = post.pv+1
post.save()
这在多线程的情况下会出现问题,其执行逻辑是先获取到当前的pv值,然后将其加1后赋值给post .pv.最后保存。
如果多个线程同时执行了post = Post.objects.get(id=1),那么每个线程里的post .pv值都是一样的, 执行完加1和保存之后,相当于只执行了一个加1,而不是多个。
这时通过F表达式就可以方便地解决这个问题:
from ajango.ab. models import F
post = Post.objects.get(id=1)
post.pv = F('pv') + 1
post.save():
这种方式最终会产生类似这样的SQL语句: UPDATE table SET pv = pv +1 WHERE ID = 1。 它在数据库层面执行原子性操作。
Q
Q表达式就是用来解决前面提到的那个OR查询的,可以这么用:
from django.db.mode1s import Q
Post.objects.filter(Q(id=1) | Q(id=2))
或者进行AND查询:
Post.objects.filter(Q(id=1) & Q(id=2))
Count
用来做聚合查询,比如想要得到某个分类下有多少篇文章,简单的做法就是:
category = Category.objects.get(id=1)
posts_count = category.post_set.count()
但是如果想要把这个结果放到category上呢?通过category.post_count可以访问到:
from django.db.models import Count
categories = Category.objects.annotate(posts_count=Count('post'))
print(categories[0].posts_count)
这相当于给category动态增加了属性post_count,而这个属性的值来源于Count('post'),最后可以用int取整。
Sum
同Count类似,只是它是用来做合计的。比如想要统计所有数据字段的总和,可以这么做:
from django.db.models import Sum
Post.objects.all().aggregate(a=Sum('字段'))
#输出类似结果:{'a':487}为字典
python中对字典中键值对的获取:
for i in book:
print(i)#键的获取
print(book[i])#值的获取
上面演示了QuerySet的annotate和aggregate的用法,其中前者用来給QuerySet结果増加属性,后者只用来直接计算结果,这些聚合表达式都可以与它们结合使用。
除了Count和Sum外,还有Avg、Min和Max等表达式,均用来满足我们对SQL査洵的需求。


- 语法
- 路径导向

- 蟒蛇—> google
- 双态 动态 静态 自动记忆管理(java 有 C没有)

- 符号处理 后端平行处理
- 语法形态
- 数值应用 运算
- 连续 分散
- 语法适合 特别学术需求

- 框架转换


- 空白键 缩排 跳行 有意义 (其他语言得 “ ;”{ }“)
- \ 转义字符


- 模组 变量
- 区分大小写



















前后端分离跨域方案
跨域请求存在诸多安全问题,例如CSRF攻击等,
浏览器针对这个安全问题会有一个同源策略,必须是我们上面说到的同源请求,才能顺利发出请求。
解决方案
1.JSONP,比较原始的方法,
本质上是利用html的一些不受同源策略影响的标签,
诸如:、、、
2.CORS,Cross-Origin Resource Sharing,是一个新的 W3C 标准,
它新增的一组HTTP首部字段,允许服务端其声明哪些源站有权限访问哪些资源。
换言之,它允许浏览器向声明了 CORS 的跨域服务器,发出 XMLHttpReuest 请求
,从而克服 Ajax 只能同源使用的限制。
在我们的django框架中就是利用CORS来解决跨域请求的问题。
Django中如何使用CORS
打开cmd,执行命令:pip install django-cors-headers

修改django项目中的setting.py,
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'corsheaders',#这是我们的主角,放在新建的其他项目之前
'app01',
]
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'corsheaders.middleware.CorsMiddleware', #注意顺序,必须放在这儿
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
CORS_ALLOW_CREDENTIALS = True
CORS_ORIGIN_ALLOW_ALL = True
#允许所有的请求头
CORS_ALLOW_HEADERS = ('*')
pip freeze > requirements.txt
服务器 中 重新 安装 依赖
pip install -r requirements.txt
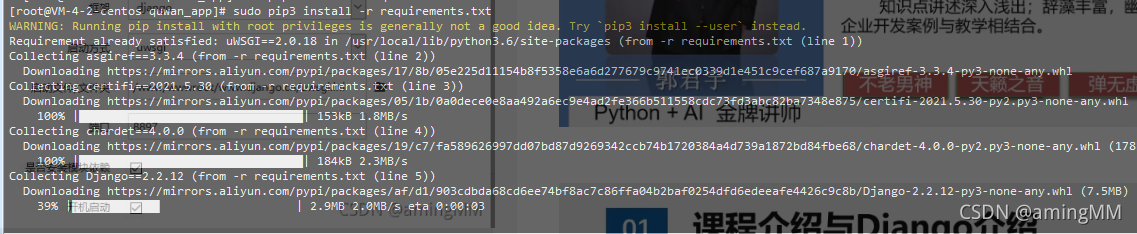
- 更新 settings 文件

centos django uwsgi 指定版本
系统版本


wget http://projects.unbit.it/downloads/uwsgi-latest.tar.gz

tar zxvf uwsgi-latest.tar.gz
编译:
python uwsgiconfig.py --build
这里的python 即指定uwsgi项目运行的python环境,在这之前,我做了软链接指向了我的python3.7环境
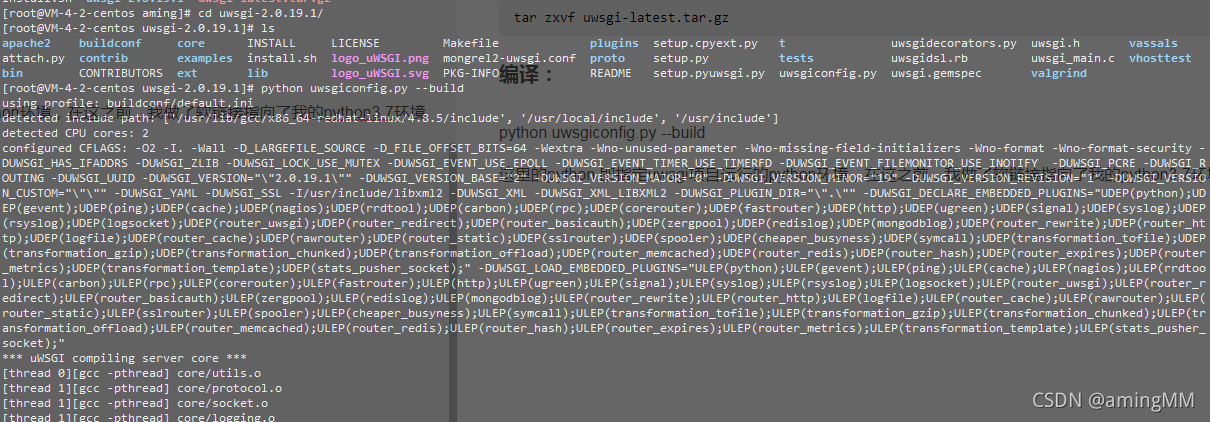
安装:
python3 setup.py install



然后进行软链接、系统便能够识别uwsgi命令
ln -s uwsgi目录 /usr/bin/uwsgi
ln -s /root/myProject/uwsgi/uwsgi-2.0.17.1/uwsgi /usr/bin/uwsgi
之后再用uwsgi去运行项目时、会自动调用上面编译的环境。

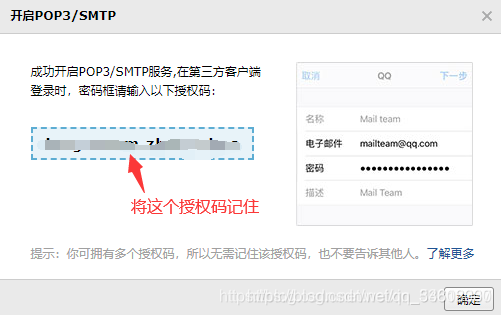
使用Django生成验证码 并发送qq邮箱
一、登录QQ邮箱–>设置–>账户–>POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务

# 设置邮件域名 发送邮件服务器:smtp.qq.com
EMAIL_HOST = 'smtp.qq.com'
# 设置端口号,为数字 使用SSL,端口号465或587
EMAIL_PORT = 25
# 设置发件人邮箱
EMAIL_HOST_USER = 'xxxxxxx'
# 设置发件人授权码
EMAIL_HOST_PASSWORD = 'xxxxxxxx'
# 设置是否启用安全连接
EMAIL_USE_TLS = True
# redis连接
REDIS_CON = redis.StrictRedis(host='localhost', port=6379)
# 随机验证码
def vercode(user):
res1 = ''
for i in range(4):
num = random.randint(0, 9)
res1 += str(num)
REDIS_CON.set(f'{user}', res1)
REDIS_CON.expire(f'{user}', 10)
return res1
class Send_Email(View):
def get(self, request):
re_send = request.GET.get('email')
sbj = '测试邮箱发送验证码'
msg = f'您的验证码为:{vercode(re_send)}'
from_send = EMAIL_HOST_USER
# subject 标题 message 内容 from_email 发送人 recipient_list 接收人(多个)
res = send_mail(subject=sbj, message=msg, from_email=from_send, recipient_list=[re_send])
if res == 1:
return render(request, 'send_email.html')
else:
return render(request, 'send_email.html')
class register(View):
def get(self, request):
code = request.GET.get('code')
email = request.GET.get('email')
if email:
scode = REDIS_CON.get(email)
if scode:
if code == scode.decode('utf-8'):
print('验证成功')
else:
print('验证码不正确')
else:
print('验证码已失效')
else:
print('邮箱不正确')
return HttpResponse('ok')
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>发送邮箱</title>
<script type="text/javascript" src="https://cdn.bootcss.com/jquery/3.2.1/jquery.min.js"></script>
</head>
<body>
邮箱:<input type="text" name="email" id="email_id">
<input type='submit' value="发送邮箱" onclick="send()">
</body>
<script>
function send() {
$.ajax({
url:'http://127.0.0.1:8000/app01/send_email/',
method:'get',
data:{
'email':document.getElementById('email_id').value
}
})
}
</script>
</html>
![[MySQL] MySQL库的基础操作](https://img-blog.csdnimg.cn/c461496986f64c47ba5b6d4abc970ac0.png)