一、广义策略迭代
策略迭代包括两个同时进行的交互过程,一个使价值函数与当前策略保持一致(策略评估),另一个使策略在当前价值函数下变得贪婪(策略改进)。在策略迭代中,这两个过程交替进行,每个过程在上一个过程完成之前开始,但这并不是必需的。例如,在价值迭代中,仅在每次策略改进之间执行一次策略评估的迭代。在异步DP方法中,评估和改进过程以更精细的粒度交错。在某些情况下,单个状态在一个过程中更新后才会返回另一个过程。只要两个过程都继续更新所有状态,最终结果通常是相同的-收敛到最优价值函数和最优策略。
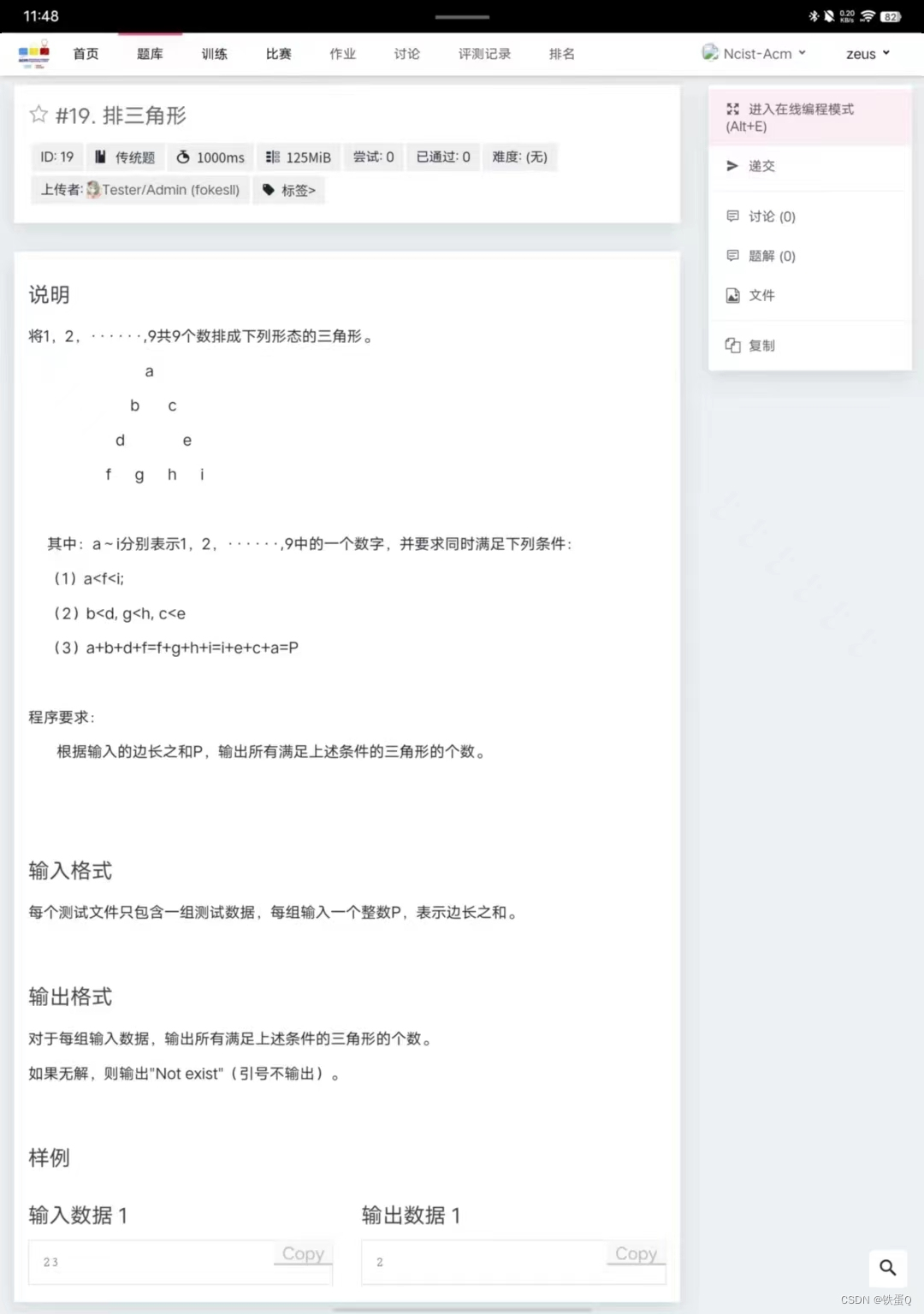
我们使用术语广义策略迭代(GPI)来指让策略评估和策略改进过程相互影响的一般思想,而不考虑这两个过程的粒度和其他细节。几乎所有的强化学习方法都可以很好地描述为GPI。即,所有方法都具有可识别的策略和价值函数,策略总是相对于价值函数进行改进,价值函数总是被驱动到该策略的价值函数。图1显示了GPI的整体架构。图1展示了广义策略迭代价值和策略函数相互作用,直到它们达到最优,从而彼此一致。
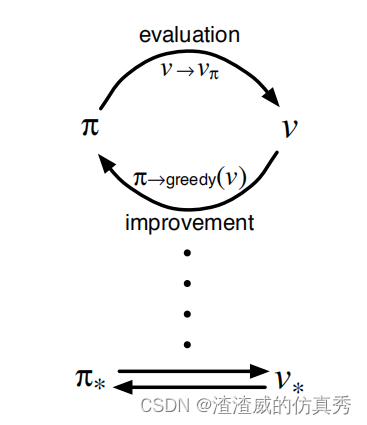
图1
很容易看出,如果评估过程和改进过程都稳定下来,即不再产生变化,那么价值函数和策略必定是最佳的。只有当价值函数与当前策略一致时,价值函数才会稳定下来,而只有当策略对当前价值函数贪婪时,策略才会稳定下来。因此,只有当已经找到一个策略,该策略对其自身的评估函数表现出贪婪时,这两个过程才会稳定下来。这意味着贝尔曼最优性方程成立,因此策略和价值函数都是最优的。
通用策略迭代中的评估和改进过程可以被视为既相互竞争又相互合作。从某种意义上说,它们相互竞争,因为它们朝着相反的方向拉动。使策略对价值函数表现出贪婪,通常会使价值函数对已改变的策略不正确,而使价值函数与策略一致,通常会导致该策略不再贪婪。然而,从长远来看,这两个过程相互作用,找到一个单一的联合解决方案:最优价值函数和最优策略。
二、典型示例
可以将通用策略迭代中评估和改进过程之间的相互作用视为两个约束或目标——例如,作为二维空间中的两条线,如图2。
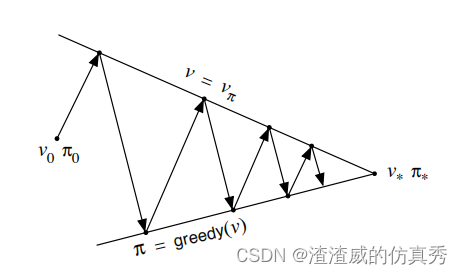
图2
尽管真实的几何比这要复杂得多,但该图表明了真实情况下会发生什么。每个过程都驱动价值函数或策略朝向代表两个目标之一的直线的其中一条。这两个目标相互作用,因为两条线不是正交的。直接朝向一个目标会导致远离另一个目标的移动。然而,不可避免的是,联合过程会更加接近整体最优目标。该图中箭头对应于策略迭代的行为,每个箭头都将系统完全实现两个目标之一。在通用策略迭代中,人们也可以向每个目标迈出更小的、不完整的步骤。无论哪种情况,这两个过程共同实现了整体最优的目标,尽管任何一个过程都不是直接尝试实现该目标。