前言
想必各位开发者一定使用过关系型数据库MySQL去存储我们的项目的数据,也有部分人使用过非关系型数据库Redis去存储我们的一些热点数据作为缓存,提高我们系统的响应速度,减小我们MySQL的压力。那么你有听说过向量数据库吗?知道向量数据库是用来做什么的吗?
向量数据库是什么?
向量是 AI 世界对世间万物的表示形式,是具有一定大小和方向的量,可以简单理解为一串数字的集合,就像一行多列的矩阵,比如:[2,0,1,9,0,6,3,0]。每一行代表一个数据项,每一列代表一个该数据项的各个属性。随着大模型等AI技术的发展和普及,向量数据的存算需求一定会得到极大的释放。
特征向量是包含事物重要特征的向量。大家比较熟知的一个特征向量是RGB (红-绿-蓝)色彩。每种颜色都可以通过对红®、绿(G)、蓝(B)三种颜色的比例来得到。这样一个特征向量可以描述为:颜色 = [红,绿,蓝]。
向量检索是指从向量库中检索出距离目标向量最近的 K 个向量。一般我们用两个向量间的欧式距离,余弦距离等来衡量两个向量间的距离,一次来评估两个向量的相似度。
向量数据库是一种特殊的数据库,它以多维向量的形式保存信息,包括文本、图像、音频和视频,使用各种过程(如机器学习模型、词嵌入或特征提取技术)将其转换为向量。简单下个定义,因为喂给Transformer的知识首先需要做embedding,所以用于存储embedding之后数据的数据库即可称为向量数据库。
矢量数据库的主要优点是它能够根据数据的矢量接近度或相似性快速准确地定位和检索数据。这允许基于语义或上下文相关性的搜索,而不是像传统数据库那样仅仅依赖于精确匹配或设置标准。
关键功能
因为向量数据库是基于embedding之后的向量的存储与检索。所以首先需要提供存储能力,其次更重要的是检索。 即如何根据一个query快速找到相关的embedding内容。 关于检索,主要是计算两个向量之间的相似度。
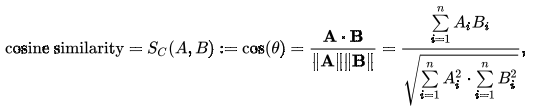
应用场景
-
推荐系统: 向量数据库可以用于存储用户和物品的特征向量,以便实现个性化推荐。通过计算相似度,可以找到与用户历史行为或兴趣相似的物品,从而提供更好的推荐体验。
-
图像搜索: 图像可以表示为高维向量,向量数据库可以用于存储和检索图像数据。用户可以通过查询相似图像来进行图像搜索,这在电子商务、社交媒体和图像库管理等领域非常有用。
-
自然语言处理(NLP): 在NLP任务中,将文本转换为嵌入向量是一种常见的方法。向量数据库可以用于存储文本嵌入向量,以便进行语义搜索、情感分析和文本聚类等任务。
-
语音识别: 语音特征可以表示为高维向量,向量数据库可用于存储和检索音频数据。这对于语音识别、说话人识别和音频检索等应用非常重要。
-
3D 模型和点云处理: 在计算机图形学和计算机视觉中,3D 模型和点云数据通常表示为向量或嵌入向量。向量数据库可以用于存储和检索这些数据,支持虚拟现实、增强现实和三维建模等应用。
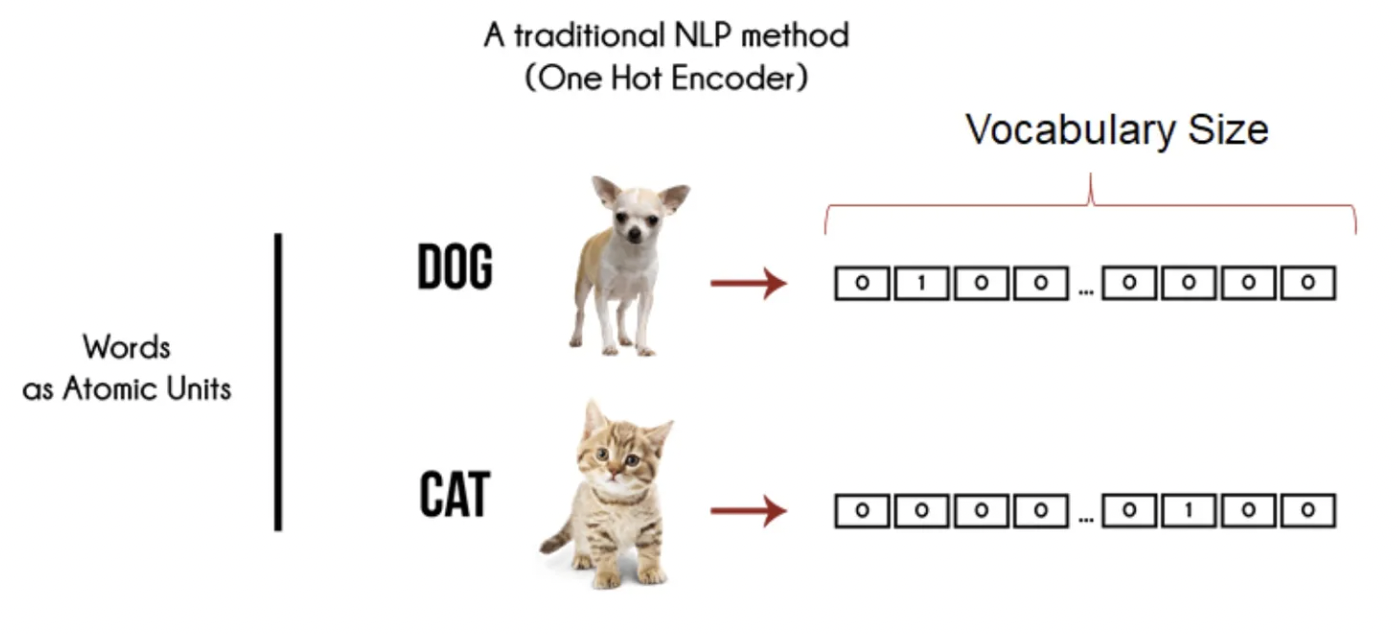
例如,通过向量嵌入,我们可以将词语"dog"和"cat"表示为两个不同的数值向量,并可以通过计算两个向量的距离来判断它们的相似度。
亚马逊云科技Amazon OpenSearch Serverless 向量引擎
Amazon OpenSearch Serverless向量引擎预览版,为我们提供了一种简单、可扩展且高性能的相似性搜索功能,使用户能够轻松地创建现代化机器学习(ML)增强的搜索体验和生成式AI应用程序,同时无需管理底层的向量数据库基础设施。
1、构建于 Amazon OpenSearch Serverless 的向量引擎天然具备稳健性。所以因为亚马逊云科技向量引擎可自动调整资源,来适应不断变化的工作负载模式和需求,从而提供始终如一的快速性能和适当规模。我们也就不必担心后端基础设施的选型、调优和扩展问题。
2、有开源OpenSearch 项目中的 k 近邻(kNN)搜索功能提供支持,Amazon OpenSearch Serverless 向量引擎能够给我们提供可靠而精确的结果。
3、向量引擎支持不同领域的广泛用例,包括但不限于图像搜索、文档搜索、音乐检索、产品推荐。
结论
向量数据库是一种新型的数据库,它在处理高维度的数据和复杂的查询时具有显著的优势。与传统的关系数据库和非关系数据库相比,向量数据库可以更高效地处理大规模的、非结构化的数据,这使得它们在许多领域,如机器学习和人工智能,都有广泛的应用。
总的来说,选择哪种类型的数据库取决于我们的具体需求和应用场景。无论是关系数据库、非关系数据库,还是向量数据库,它们都是我们数据处理工具箱中的重要工具,我们需要根据实际情况选择最适合的工具。