目录
1、问题说明
2、初步分析
3、字符串字符编码说明
4、进一步分析
5、为啥在日常测试时没有遇到切换摄像头失败的问题呢?
6、华为MateBook笔记本使用高通的CPU
7、最后
VC++常用功能开发汇总(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/124272585C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)
https://blog.csdn.net/chenlycly/article/details/124272585C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/125529931C++软件分析工具从入门到精通案例集锦(专栏文章正在更新中...)
https://blog.csdn.net/chenlycly/article/details/125529931C++软件分析工具从入门到精通案例集锦(专栏文章正在更新中...)![]() https://blog.csdn.net/chenlycly/article/details/131405795C/C++基础与进阶(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/article/details/131405795C/C++基础与进阶(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_11931267.html开源组件及数据库技术(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/category_11931267.html开源组件及数据库技术(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_12458859.html网络编程与网络问题分享(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/category_12458859.html网络编程与网络问题分享(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_2276111.html 最近在项目中遇到了一个因字符串编码转换时发生内存越界引发摄像头切换失败的问题,今天就来分享这个问题的排查过程,以供借鉴或参考。
https://blog.csdn.net/chenlycly/category_2276111.html 最近在项目中遇到了一个因字符串编码转换时发生内存越界引发摄像头切换失败的问题,今天就来分享这个问题的排查过程,以供借鉴或参考。
1、问题说明
最近在某个项目中,将软件部署到客户的环境中后,有台华为MateBook笔记本(后经证实这是华为新出的Pad平板电脑)在使用我们客户端音视频软件时发现切换笔记本前置摄像头时有问题。打开软件时,默认使用的是后置摄像头,客户在设置中将摄像头由后置摄像头切换到前置摄像头时:
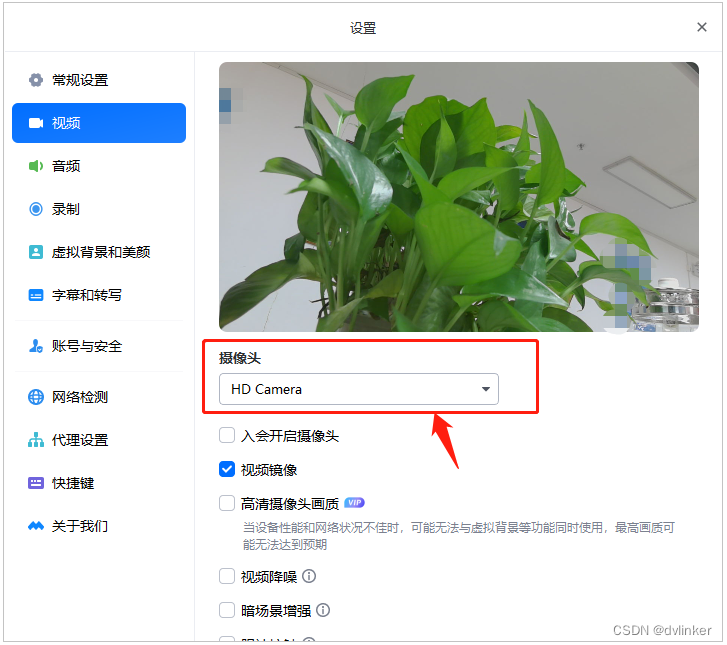
发现没有反应,显示的还是后置摄像头图像,应该是摄像头切换失败了。
2、初步分析
系统当前的摄像头列表的获取以及摄像头的切换,最终都是程序底层的音视频模块去执行的,所以优先从音视频模块查起。

这里的摄像头包括机器内置的摄像头以及USB摄像头(通过USB接口接到系统中的摄像头)。
1)台式机电脑一般使用的都是外接的USB摄像头;
2)笔记本电脑使用的是内置摄像头,也可以使用外界的USB摄像头(更清晰一点,角度可所以调整);
3)Pad平板一般会像手机一样,内置两个摄像头,一个前置摄像头,一个后置摄像头。
经过客户允许,我们使用远程桌面软件远程连接到出问题的客户笔记本上。首先,查看音视频模块的打印日志,发现调用音视频模块切换摄像头时,上层传下来的摄像头id是空的:(日志打印是排查问题最重要、最常用的手段之一!)

正常的摄像头id是类似于这样的字符串:\\?\usb#vid_046d&pid_0825&mi_00#6&259ee562&0&0000#{65e8773d-8f56-11d0-a3b9-00a0c9223196}\{bbefb6c7-2fc4-4139-bb8b-a58bba724083}
音视频模块是通过上层传下来的设备id去匹配对应的摄像头设备,找到目标摄像头后,将摄像头源切换过去。根据打印,上层在调用音视频模块切换摄像头的接口时传入的是摄像头id为空,肯定匹配不到摄像头设备,所以没法切换到目标摄像头,摄像头切换失败了。
客户端UI层模块,也会保存摄像头列表数据(包含摄像头名和id),UI层调用切换摄像头的接口时是从UI层的内存中去找对应的设备id,然后将要切换到的目标摄像头id传递给底层。难道UI层内存中保存的摄像头列表中的id有问题?id为空?于是去查看UI层的打印日志,通过日志得知,UI层保存的摄像头列表数据是正常的,id也不为空,是有效的!
3、字符串字符编码说明
本案例中的问题与字符编码转换有关,所以此处给大家大概地介绍一下字符编码及相互转换的相关内容。
很多人在处理字符串编码及转换时可能会有不解或疑惑,甚至有多年工作经验的朋友也搞不清楚,所以这个地方很有必要给大家介绍一下字符编码相关的内容!
有字符串的地方,就会涉及到字符编码,是对字符串的编码。常用的字符编码有ANSI窄字节编码、UNICODE宽字节编码和UTF8可变长度编码,其中UNICODE编码在Windows系统中普遍的使用。
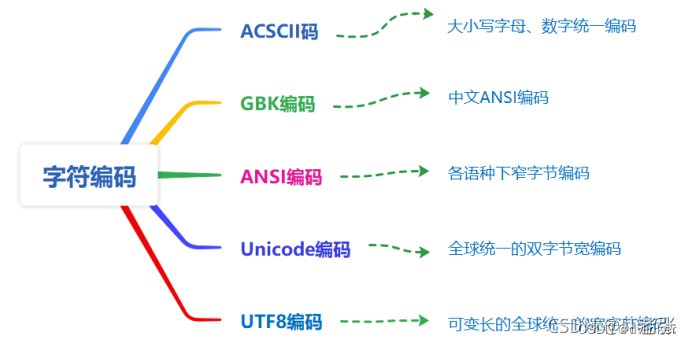
ANSI编码是本地语言编码,不是全球统一编码,不同国家语言文字的ANSI编码可能是相同的。中文字符的ANSI编码也被成为GBK编码(是对GB2312编码的扩展)。
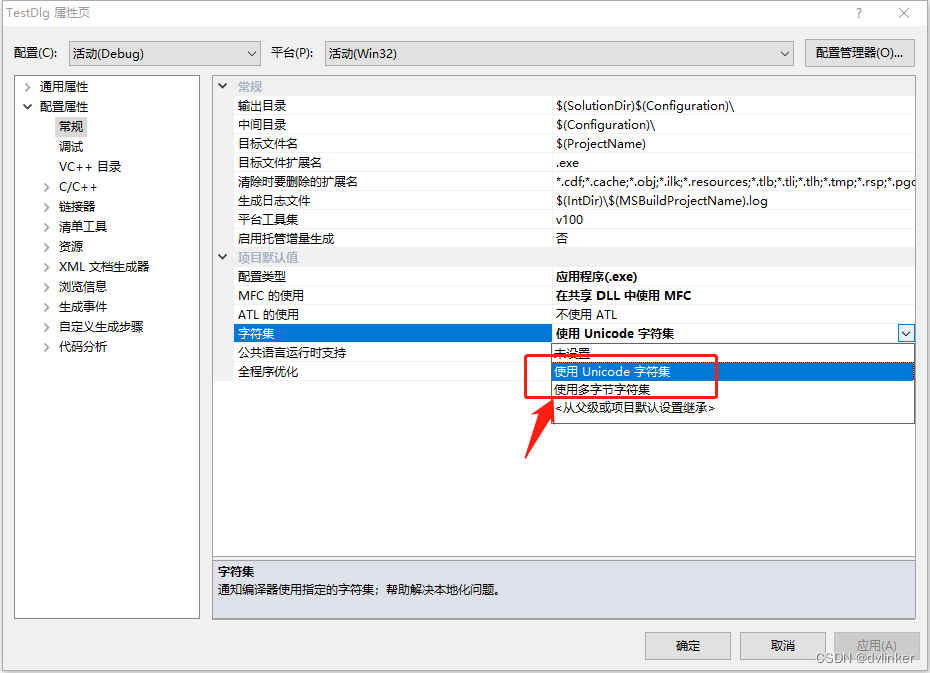
UNICODE编码则是全球统一的双字节编码(1个字符使用两个字节编码来表示),不同国家文字字符的UNICODE编码是全球唯一的,不重复的。在Windows平台上开发的软件,要支持多国语言,则软件中的字符要使用UNICODE编码。用Visual Studio开发的软件,如果要使用UNICODE编码,一般需要工程属性中需要字符集设置为“使用 Unicode 字符集”:(VS会在工程中自动添加UNICODE宏)
涉及到字符串参数的系统API函数,一般都有两个版本,一个ANSI窄字节版本,一个UNICODE宽字节版本,比如获取窗口文字的API函数GetWindowText的声明如下:
int
WINAPI
GetWindowTextA(
_In_ HWND hWnd,
_Out_writes_(nMaxCount) LPSTR lpString,
_In_ int nMaxCount);
_Ret_range_(0, nMaxCount)
WINUSERAPI
int
WINAPI
GetWindowTextW(
_In_ HWND hWnd,
_Out_writes_(nMaxCount) LPWSTR lpString,
_In_ int nMaxCount);
#ifdef UNICODE
#define GetWindowText GetWindowTextW
#else
#define GetWindowText GetWindowTextA
#endif // !UNICODE如果有定义UNICODE,则指向宽字节版本。如果在Visual Studio的字符集选项中选择“使用多字节字符集”,则对应ANSI窄字节编码。
UTF8编码,是可变长字符编码,也是一种全球统一编码,之所以称之为可变长编码,因为不同类型的字符的编码长度是不同的,比如一个数字或英文字母的编码只占1个字节,一个中文文字的编码则占3个字节。
UTF8编码一般用于客户端和服务器之间交互的字符数据的统一编码格式,比如服务器中的Linux系统支持直接操作UTF8编码的字符数据,对于Windows客户端程序,在UI界面展现字符串数据时,需要先将服务器给过来的UTF8编码的字符转换成ANSI或UNICODE编码的字符,然后再将字符串拿到UI界面上显示。
软件中可能会涉及到不同字符编码的转换,关于常用字符编码的详细说明以及编码之间转换的源码实现,可以参见我之前写的文章:
一文带你弄懂C++中的ANSI、Unicode和UTF8三种字符编码及相互转换![]() https://blog.csdn.net/chenlycly/article/details/121070073VC++中ANSI、UNICODE与UTF-8字符编码之间的转换(附源码)
https://blog.csdn.net/chenlycly/article/details/121070073VC++中ANSI、UNICODE与UTF-8字符编码之间的转换(附源码)![]() https://blog.csdn.net/chenlycly/article/details/123589349
https://blog.csdn.net/chenlycly/article/details/123589349
4、进一步分析
这就奇怪了,UI层的摄像头列表数据没问题,音视频模块中的摄像头列表数据也没问题,为啥上层调用音视频模块的切换摄像头接口时传入的目标摄像有id为空呢?其实,在UI层与音视频模块之间还有个业务组件模块,难道是中间的业务组件模块的代码有问题?
音视频模块库是业务组件层封装起来的,即音视频模块的接口是业务组件层调用的,于是到业务组件层中查看调用音视频模块的切换摄像头接口的函数,如下所示:
因为上层与组件层之间交互涉及到字符串的,都统一使用UTF8字符编码,而音视频模块切换摄像头的接口声明如下:
// 选择视频源
unsigned short SelectVideoSource(const TVideoCapParam *ptVideoCapParam, const wchar_t *pszDevName = NULL, const wchar_t *pszDevGUID = NULL);该函数的第二个参数pszDevName(摄像头名称)和第三个参数pszDevGUID(摄像头id)都是wchar_t类型宽字节字符,在Windows平台上就是上面讲的UNICODE。而上层传过来的摄像头名称和id字符串都是UTF8编码的,所以在调用上述SelectVideoSource之前,需要将UTF8编码的字符串转换成UNICODE编码的字符串,代码中确实调用了UTF8转换到UNICODE的接口Utf8Tolnicode。
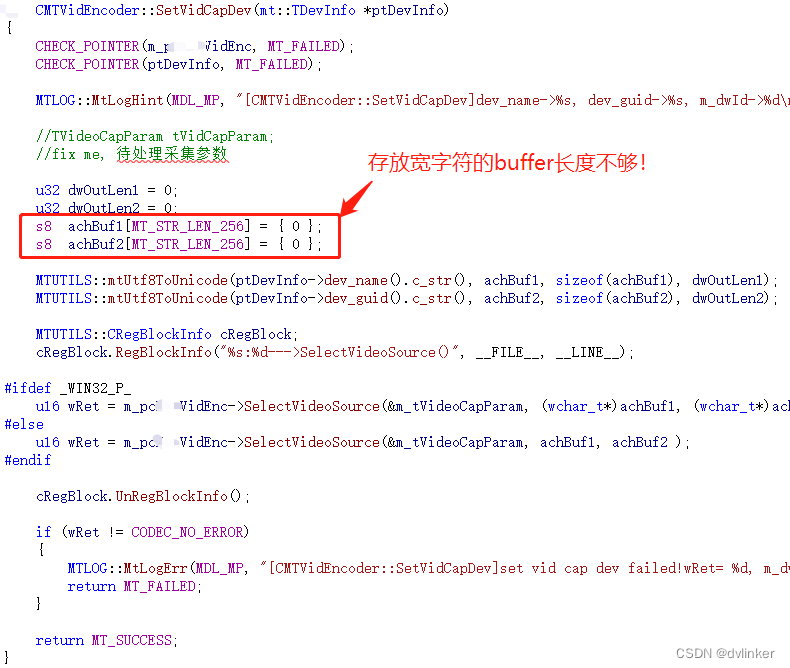
看到这里突然想到,是不是摄像头id比较长,在进行字符编码转换时存放转换后的字符串的buffer长度不足,导致内存越界了?(我们经常与字符编码打交道,对这方面的问题比较敏感)所以导致底层音视频模块的切换摄像头接口中收到的id为空的问题?于是将之前在日志中看到的目标摄像头的id拷贝到notepad++中查看到字符串的长度:
全选拷贝进来的摄像头id字符串,然后再notepad++状态栏显示的字符个数,得知摄像头id字符串的字符个数为130个,这些字符是键盘上的数字、字母等字符的组合,在UTF8编码中保存的是ASCII码,只占用1个字节。
如果将上述字符串转成UNICODE编码的字符串,在UNICODE编码中一个字符占两个字节,对于数字和字母,其编码值就是ACSII码,只需要一个字节就能存放了,但还是要固定的占两个字节(高位填充0)。所以,上述130个字符的字符串,转成UNICODE编码后需要130*2 = 260字节,如果要包含字符串\0结尾符,那就需要262字节了!而编码转换的代码中却使用了256字节的buffer去接收转换出来的UNICODE编码:

所以,在调用Utf8Tolnicode接口转换时肯定发生内存越界了!所以引发了音视频模块的切换摄像头的接口内部收到的id为空的问题。
按讲此处即使有越界,按讲传入的id不应该为空,因为在打印字符串时会直到找到字符串\0结尾符才会结束,此处就没再深究了,反正是存放转换出的UNICODE字符串的buffer长度不够导致的问题,修改后就正常了。
解决办法很简单,直接将接收UNICODE字符串的buffer长度由256改成512就可以了。
此外,在Windows平台上主要是调用API函数MultiByteToWideChar实现的,其实我们在调用MultiByteToWideChar接口时第五个参数(接收转码后的字符串buffer地址)传入NULL,MultiByteToWideChar返回的就是转码后字符串的长度,然后再调用一次MultiByteToWideChar进行转换,相关代码如下所示:
int nTmpLen = MultiByteToWideChar( CP_UTF8, 0, pchSrc, -1, NULL, 0 );
WCHAR* pWTemp = new WCHAR[nTmpLen+1];
memset( pWTemp, 0, (nTmpLen+1)*sizeof(WCHAR) );
MultiByteToWideChar( CP_UTF8, 0, pchSrc, -1, pWTemp, nTmpLen+1 );5、为啥在日常测试时没有遇到切换摄像头失败的问题呢?
遇到问题时,我们要多思考,要搞清楚问题的来龙去脉,甚至可以和正常的场景做比较。本案例中的问题以前从来没遇到过,这个到底有什么不一样的地方呢?我们的音视频软件需要使用到摄像头,不管是内置的摄像头,还是外插的USB摄像头。我们的软件已经有很多年了,为啥到现在才暴露出这个问题呢?

于是到使用USB摄像头的测试电脑上,看看USB摄像头id和客户的摄像头id有什么不同。通过打印日志,拿到USB摄像头id的打印:(当前用的是外接的USB摄像头,id中包含usb字样)
\\?\usb#vid_046d&pid_0825&mi_00#6&259ee562&0&0000#{65e8773d-8f56-11d0-a3b9-00a0c9223196}\{bbefb6c7-2fc4-4139-bb8b-a58bba724083}
把这个id串拷贝到notepad++中:
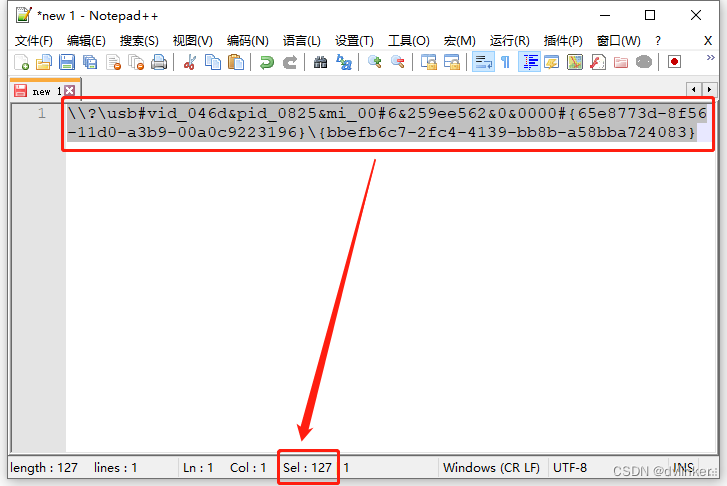
选中所有字符,看到一共有127个字符,那么将这个字符串转成UNICODE编码,需要127*2 = 254字节(如果要包含\0结尾符,则需要256个字节),所以上述代码中给出256字节是够用的,没有问题。
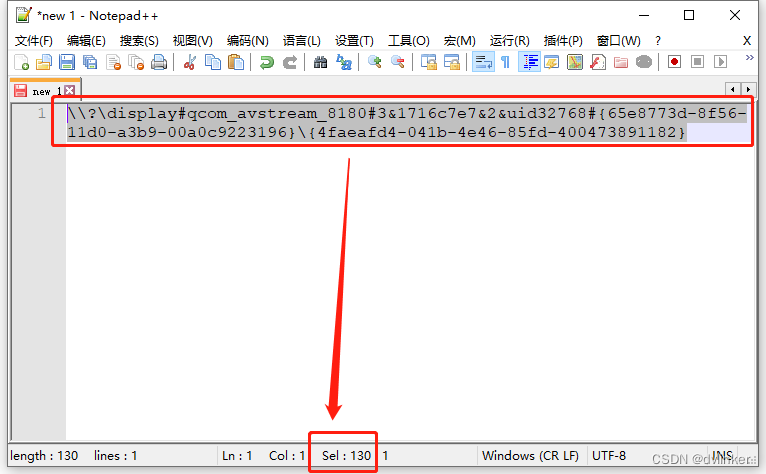
但在本案例中的客户笔记本电脑上,出问题的摄像头id为:(笔记本自带摄像头,是内置的,id中包含了display字样)
\\?\display#qcom_avstream_8180#3&1716c7e7&2&uid32768#{65e8773d-8f56-11d0-a3b9-00a0c9223196}\{4faeafd4-041b-4e46-85fd-400473891182}
比较两个摄像头id字符串得知,id字符串的前半部分是不同的。
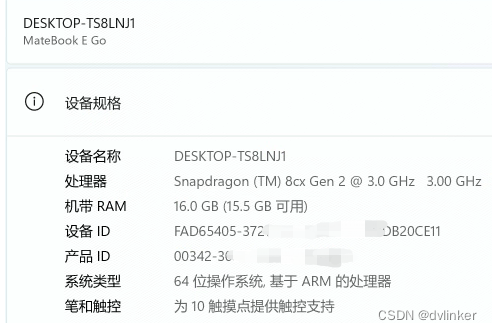
6、华为MateBook笔记本使用高通的CPU
在我们的印象中,高通主要是做手机CPU芯片的,没想到华为的MateBook笔记本也使用高通的Snapdragon骁龙CPU,相关截图如下:
高通CPU是基于ARM架构的,Windows系统也是支持ARM架构的CPU的。
笔记本电脑的CPU一般使用Intel或AMD的CPU,第一次见到用高通CPU的,很是好奇!于是以Snapdragon 8cx Gen 2型号到网上搜索这款CPU的说明,在CPUBenchmark测评工具的官网上看到了该CPU的说明:
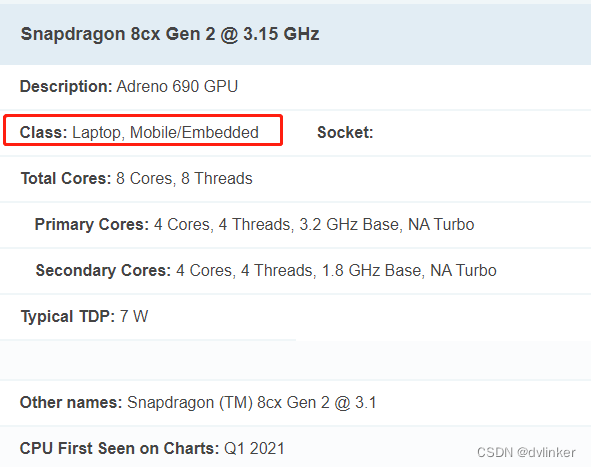
这款CPU 8核8线程,支持平台有移动端、嵌入式和笔记本电脑(Laptop)。
这款笔记本型号是MateBook E Go,后来到华为商城上搜了一下,这个是类似微软Surface的平板电脑,屏幕和键盘是可以分开的,本质上还属于Pad平板电脑,和一般意义上的笔记本还是有些不一样的。
7、最后
这个问题其实相对比较简单,但其中涉及到的字符编码及编码转换的部分内容,正好趁此机会给大家普及一下,希望能给大家提供一定的借鉴或参考。

![[直播自学]-[汇川easy320]搞起来(3)看文档安装软件 查找设备](https://img-blog.csdnimg.cn/a5a6afd00f7f43ecb82e4694abcbfb84.png)