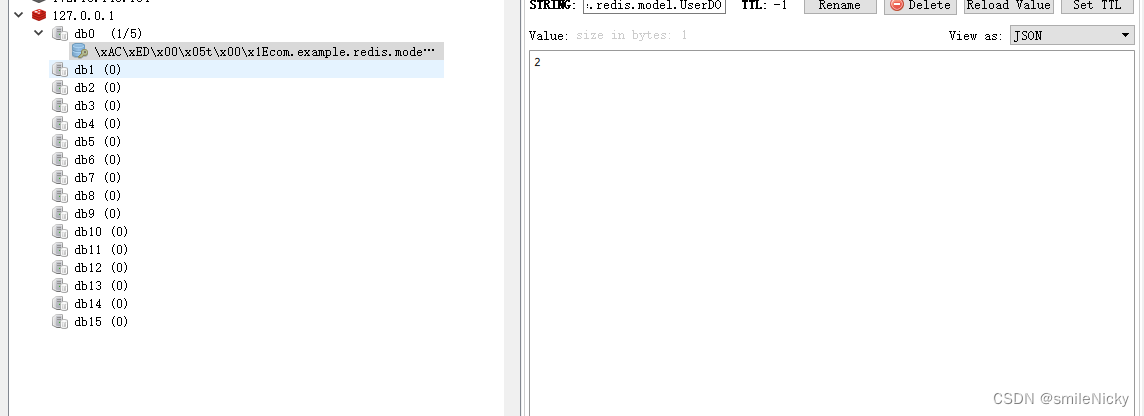
ES基本概念和关键原理
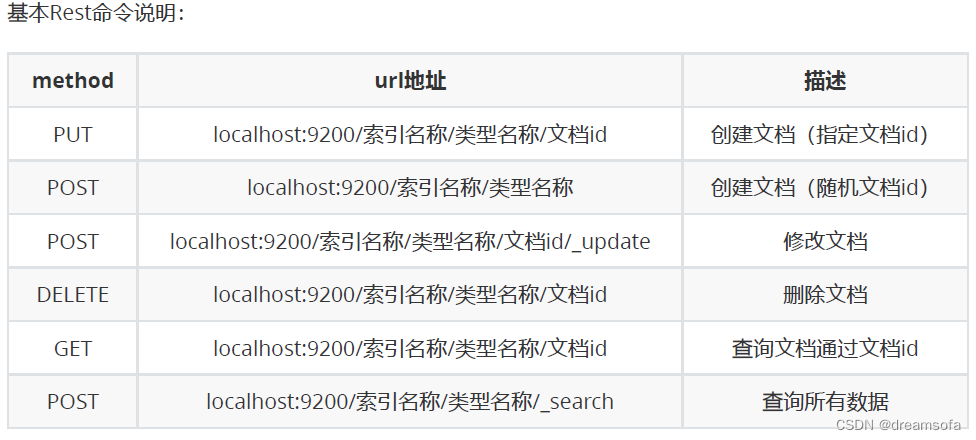
官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.17/rest-apis.html
核心概念
| 相关概念 | 关系型数据库 | ElasticSearch |
| 数据库 | Databases | Indices |
| 表 | Tables | Types |
| 行记录 | Rows | Documents |
| 字段 | Columns | fields |
ES集群中可以包含多个索引, 每个索引可以包含多个类型(目前已经弱化类型概念, 一个索引只允许一个类型,默认为_doc类型),每个类型可以存放多个文档,文档中包含多个字段
索引
indices ES集群以索引为管理单元,按索引进行分片保存,每个分片在集群的服务器上可以进行迁移。
集群节点中保存了索引的主分片和副本(复制分片)。
类型
类型是文档的逻辑定义。 对字段的定义成为映射(mapping),等同于文档在关系型数据库中的Schemal定义。 文档的无模式的概念是指在类型映射中可以不预先定义字段的类型映射, 而ES在接收到文档中包含的新字段时会进行自动映射, 比如对于数字,可能映射为整形。ES的自动映射可能带来准确性的问题, 建议同关系型数据库的使用一样,对于新增的字段,预先进行类型映射。
文档
文档是ES检索的最小单元,ES查询就是对文档进行评分排序和过滤。文档有以下属性:
- 文档同时包含字段和值。
- 文档可以是层次性的, 文档可以包含自文档
- 文档结构灵活,无需预先定义。
关键原理
倒排索引
ES使用倒排索引对所有文档进行分析提供快速检索能力。
倒排索引又称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”
传统索引通过索引确定记录所在行位置,在从记录中获取属性值。而倒排索引则相反,通过记录属性值和有该属性值的记录的地址,通过属性值来确认记录位置。
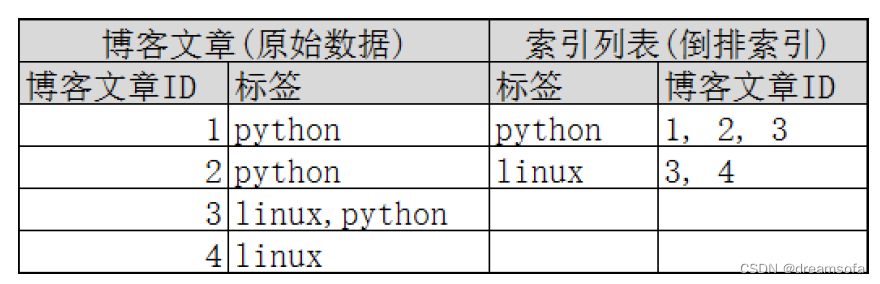
图1 博客倒排索引示意
分词器
从倒排索引的概念得知,文档最终建立在属性值中关键字的倒排索引上。因此对于相同的一个文档属性值,划分为不同的词直接影响着ES的查询结果。
英文的分词由与空格的存在有自然的分词效果, 而中文则复杂的多, 比如 我爱学习,如果每一个字都划分为词,则失去了学习这个词的语义, 因此中文需要使用专门的分词器来进行分析。
IK分词器是一个中文分词器, 提供了ik_smart和ik_max_word两种分词算法, ik_smart是最少切分, ik_max_word是最细粒度切分。
分词器的安装:
- 下载对应版本的ik分词器的包,Github地址:
GitHub - medcl/elasticsearch-analysis-ik: The IK Analysis plugin integrates Lucene IK analyzer into elasticsearch, support customized dictionary.
- 将下载文件解压到ES根目录的plugins目录中。
- 重启ES服务。
- 通过elasticsearch-plugin list命令可以看到安装的ik插件。

分词器的测试
对于ik_smart模式“中国共产党”被分析为一个词, 而ik_max_word模式则将所有可能的词都进行了切分。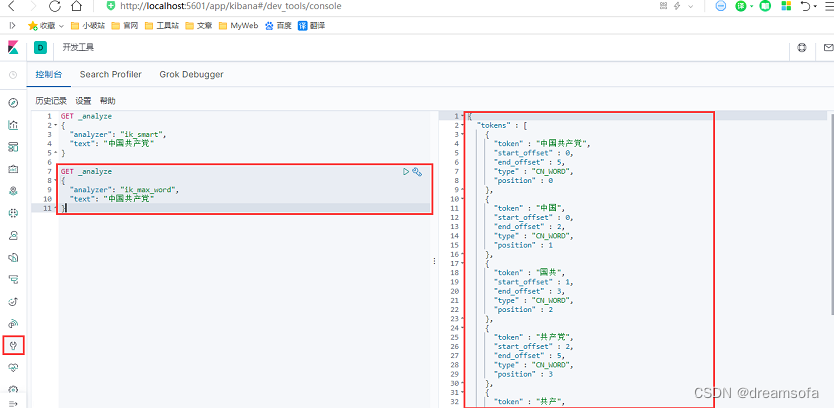
自定义词库
可以添加自定义词库帮助ik分词器进行分词。新建分词文件:xx.dic,在文件中输入自定义的词组,后将文件放置于elasticsearch/plugins/ik/config 目录下, 并修改在ik/config目录下的IKAnalyzer.cfg.xml文件。
| <properties> <comment>IK Analyzer 扩展配置</comment> <!-- 用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">my.dic</entry> <!-- 用户可以在这里配置自己的扩展停止词字典 --> <entry key="ext_stopwords"></entry> </properties> |