https://github.com/kohya-ss/sd-scripts/blob/main/docs/config_README-ja.md![]() https://github.com/kohya-ss/sd-scripts/blob/main/docs/config_README-ja.md[Stable Diffusion]训练你的LoRA(Linux) - 知乎简介LoRA 是一种参数高效微调方法(PEFT),最早由 LoRA: Low-Rank Adaptation of Large Language Models 提出并应用于微调语言大模型之中,后来由 Low-rank Adaptation for Fast Text-to-Image Diffusion Fine-tu…
https://github.com/kohya-ss/sd-scripts/blob/main/docs/config_README-ja.md[Stable Diffusion]训练你的LoRA(Linux) - 知乎简介LoRA 是一种参数高效微调方法(PEFT),最早由 LoRA: Low-Rank Adaptation of Large Language Models 提出并应用于微调语言大模型之中,后来由 Low-rank Adaptation for Fast Text-to-Image Diffusion Fine-tu…![]() https://zhuanlan.zhihu.com/p/640144661配置文件格式TOML:
https://zhuanlan.zhihu.com/p/640144661配置文件格式TOML:
[general]
shuffle_caption = true
caption_extension = '.txt'
keep_tokens = 1
# This is a DreamBooth-style dataset
[[datasets]]
resolution = 512
batch_size = 4
keep_tokens = 2
[[datasets.subsets]]
image_dir = 'C:\hoge'
class_tokens = 'hoge girl'
# This subset has keep_tokens = 2 (using the value of the parent datasets)
[[datasets.subsets]]
image_dir = 'C:\fuga'
class_tokens = 'fuga boy'
keep_tokens = 3
[[datasets.subsets]]
is_reg = true
image_dir = 'C:\reg'
class_tokens = 'human'
keep_tokens = 1
# This is a fine-tuning-style dataset
[[datasets]]
resolution = [768, 768]
batch_size = 2
[[datasets.subsets]]
image_dir = 'C:\piyo'
metadata_file = 'C:\piyo\piyo_md.json'
# This subset has keep_tokens = 1 (using the general value)在此示例中,将训练三个目录作为512x512(批量大小4)的dreambooth数据集,以及一个目录作为768x768(批量大小2)的微调数据集。
C:\
├─ hoge -> [[datasets.subsets]] No.1 ┐ ┐
├─ fuga -> [[datasets.subsets]] No.2 |-> [[datasets]] No.1 |-> [general]
├─ reg -> [[datasets.subsets]] No.3 ┘ |
└─ piyo -> [[datasets.subsets]] No.4 --> [[datasets]] No.2 ┘所有方法均可使用的参数:[general]
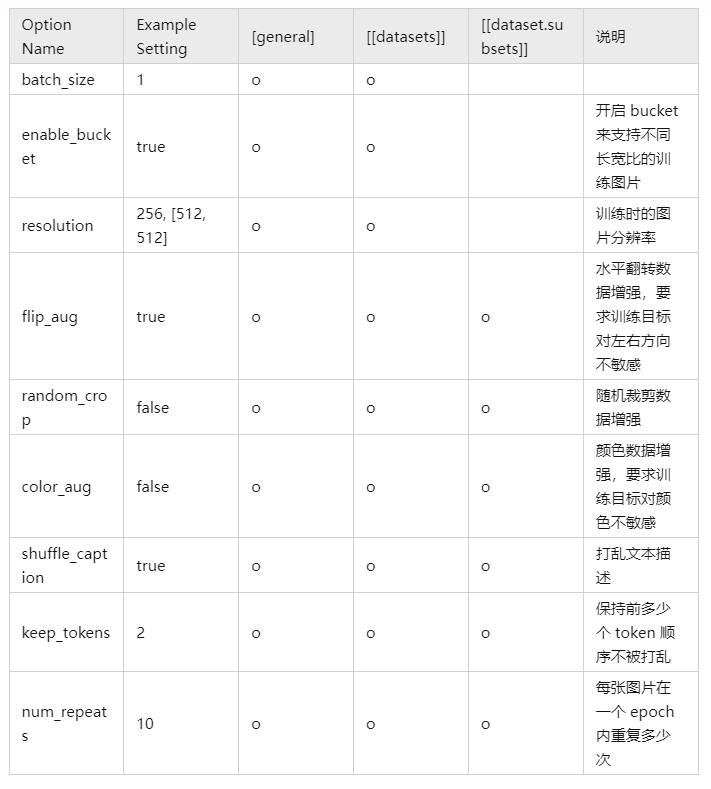
dreambooth-style 特有的参数:
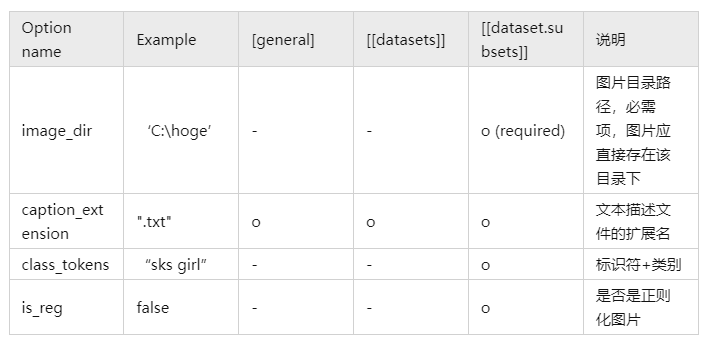
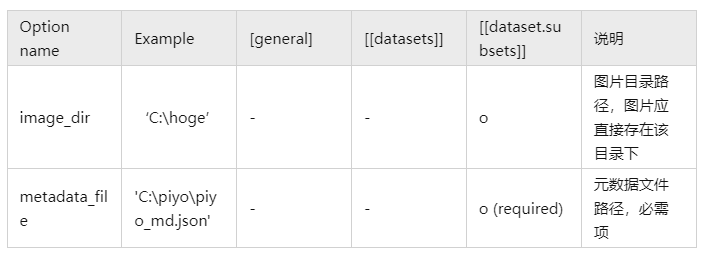
fine-tuning-style特有的参数:




![[鹏程杯2023]复现](https://img-blog.csdnimg.cn/4a8bb8034efe4f14b8880ef8cd8e55df.png)