目录:
- 学习目标
- Dataframe合并
- df.append函数纵向追加合并df
- pd.concat函数纵向横向连接多个数据集
- df.merge合并指定关联列的多个数据集
- df.join横向合并索引值相同的多个数据集
- df合并小结
- Dataframe变形
- df.T行列转置
- df.stack()和s.unstack()变形
- df.melt宽变长将列名变为列值
- df.pivot_table透视表
- 总结
- 项目地址
1.学习目标
-
知道df.append()、pd.concat()、df.merge()、df.join()四个合并函数的区别和用法
-
知道df.T、df.stack()、df.unstack()、df.melt()的用法
-
知道df.pivot_table()透视表的用法
2. Dataframe合并
很多情况需要将多个df合并为一个新的df,常用方法如下
-
df1.append(df2)纵向合并数据集 -
pd.concat([df1,df2])横向或纵向合并数据集,df1和df2可以没有任何关系 -
df1.merge(df2)融合df1和df2,要有关联的列(两个列名相同的列) -
df1.join(df2)横向合并,df1和df2列名相同
-
导包并准备数据集
import pandas as pd
df1 = pd.DataFrame([[1, 2, 3], [1, 10, 20], [5, 6, 7], [3, 9, 0], [8, 0, 3]], columns=['x1', 'x2', 'x3'])
df2 = pd.DataFrame([[1, 2], [1, 10], [1, 3], [4, 6], [3, 9]], columns=['x1', 'x4'])
print(df1)
print(df2)
df.append函数纵向追加合并df
df.append()函数纵向连接其他df重置索引返回新的df
import pandas as pd
df1 = pd.DataFrame([[1, 2, 3], [1, 10, 20], [5, 6, 7], [3, 9, 0], [8, 0, 3]], columns=['x1', 'x2', 'x3'])
df2 = pd.DataFrame([[1, 2], [1, 10], [1, 3], [4, 6], [3, 9]], columns=['x1', 'x4'])
print(pd.concat([df1, df2]))
# 参数ignore_index默认为False 如果为 True 则重置为自增索引
print(pd.concat([df1, df2], ignore_index=True))
pd.concat函数纵向横向连接多个数据集
-
pd.concat()函数纵向连接多个数据集,N个df从上到下一个摞一个:-
不使用
join='inner'参数,数据会堆叠在一起,列名相同的数据会合并到一列,合并后不存在的数据会用NaN填充 -
使用
join='inner'参数,只保留数据中的共有部分
-
-
pd.concat(axis=1)函数横向连接多个数据集,N个df从左到右一个挨着一个:-
匹配各自行索引,缺失值用NaN表示
-
使用
join='inner'参数,只保留索引匹配的结果
-
import pandas as pd
df1 = pd.DataFrame([[1, 2, 3], [1, 10, 20], [5, 6, 7], [3, 9, 0], [8, 0, 3]], columns=['x1', 'x2', 'x3'])
df2 = pd.DataFrame([[1, 2], [1, 10], [1, 3], [4, 6], [3, 9]], columns=['x1', 'x4'])
# 纵向连接,全部数据都保留
print(pd.concat([df1, df2]))
# 纵向连接,只保留共有数据
print(pd.concat([df1, df2], join='inner'))
# 横向连接,全部数据都保留
print(pd.concat([df1, df2], axis=1))
# 横向连接,保留索引值匹配的数据
print(pd.concat([df1, df2], join='inner', axis=1))
-
pd.concat()函数纵向连接多个数据集的具体使用
pd.concat([df1, df2, df3])df.merge合并指定关联列的多个数据集
- merge函数能够将df1合并指定列的df2返回新的df,merge函数有2种写法
# 写法1
df1.merge(df2, on='列名', how='固定值')
# 写法2
pd.merge(df1, df2, on='列名', how='固定值')-
merge函数有2种常用参数,参数说明如下
-
参数
on='列名',表示基于那一列进行合并操作 -
参数
how='固定值',表示合并后如何处理行索引,固定参数具体如下:-
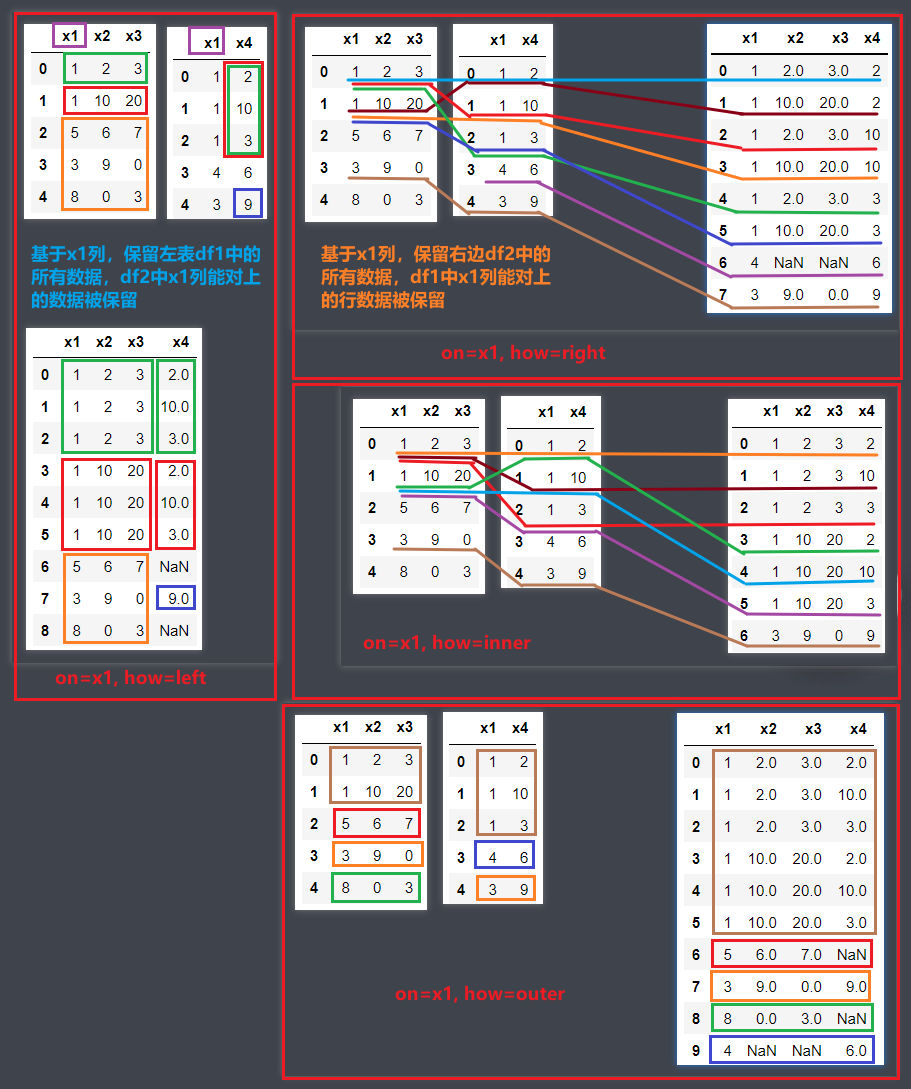
how='left'对应SQL中的left join,保留左侧表df1中的所有数据 -
how='right'对应SQL中的right join,保留右侧表df2中的所有数据 -
how='inner'对应SQL中的inner,只保留左右两侧df1和df2都有的数据 -
how='outer'对应SQL中的join,保留左右两侧侧表df1和df2中的所有数据
-
-
-
merge横向连接多个关联数据集具体使用
import pandas as pd
df1 = pd.DataFrame([[1, 2, 3], [1, 10, 20], [5, 6, 7], [3, 9, 0], [8, 0, 3]], columns=['x1', 'x2', 'x3'])
df2 = pd.DataFrame([[1, 2], [1, 10], [1, 3], [4, 6], [3, 9]], columns=['x1', 'x4'])
print(df1)
print(df2)
df3 = pd.merge(df1, df2, how='left', on='x1')
df4 = pd.merge(df1, df2, how='right', on='x1')
df5 = pd.merge(df1, df2, how='inner', on='x1')
df6 = pd.merge(df1, df2, how='outer', on='x1')
# 下图左1
print(df3)
# 下图右上
print(df4)
# 下图右中
print(df5)
# 下图右下
print(df6)
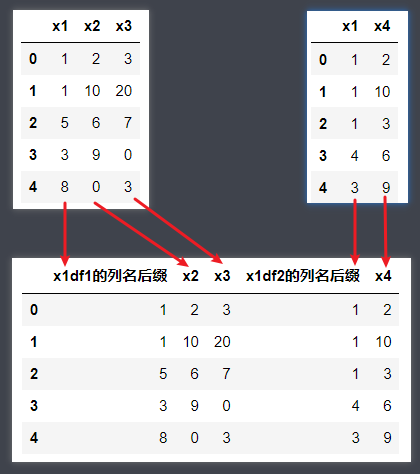
df.join横向合并索引值相同的多个数据集
- join横向合并索引值相同的多个数据集;通过
lsuffix和rsuffix两个参数分别指定左表和右表的列名后缀,how参数的用法与merge函数的how参数用法一致
import pandas as pd
df1 = pd.DataFrame([[1, 2, 3], [1, 10, 20], [5, 6, 7], [3, 9, 0], [8, 0, 3]], columns=['x1', 'x2', 'x3'])
df2 = pd.DataFrame([[1, 2], [1, 10], [1, 3], [4, 6], [3, 9]], columns=['x1', 'x4'])
print(df1.join(df2, lsuffix='df1的列名后缀', rsuffix='df2的列名后缀', how='outer'))
df合并小结
-
df1.append(df2)纵向合并数据集 -
pd.concat([df1,df2])横向或纵向合并数据集,df1和df2可以没有任何关系 -
df1.merge(df2)融合df1和df2,要有关联的列(两个列名相同的列) -
df1.join(df2)横向合并,df1和df2索引值相同
3.Dataframe变形
很多情况需要对原数据集进行一些操作,最终导致数据集的形状发生改变(表格的长宽发生变化),这一类操作称之为df变形
-
df.T
-
stack & unstack
-
melt
-
指定列长变宽 pd.crosstab(df.Sex, df.Handedness, margins = True)
-
透视表pivot
-
pd.pivot_table
-
df.T行列转置
- 行变列,列变行
import pandas as pd
df1 = pd.DataFrame([[1, 2, 3], [1, 10, 20], [5, 6, 7], [3, 9, 0], [8, 0, 3]], columns=['x1', 'x2', 'x3'])
df2 = pd.DataFrame([[1, 2], [1, 10], [1, 3], [4, 6], [3, 9]], columns=['x1', 'x4'])
print(df1)
print(df1.T)
df.stack()和s.unstack()变形

import pandas as pd
# 构造示例数据集
df3 = pd.DataFrame([[1, 2, 3], [4, 5, 6]], columns=['store1', 'store2', 'store3'], index=['street1', 'street2'])
# 查看数据集
print(df3)
# 表格变花括号结构
s3 = df3.stack()
print(s3)
# 花括号变表格
print(s3.unstack())

df.melt宽变长将列名变为列值
- pd.melt()函数,又称为数据融合函数,将指定的一个或多个列名变成一个列的值;如下图所示,可以将宽df变为长df
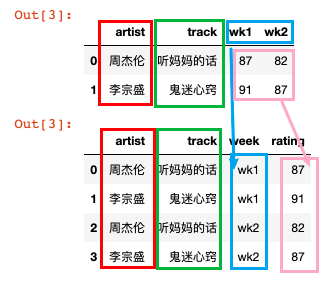
df.melt(
id_vars=['列名'], # 不变形的所有列
value_vars=['列名'], # 要变形的所有列:把多个列变成一个新列;同时所有对应的值变成第二个新列的值
var_name='新列名', # 新列的列名
value_name='新列名' # 第二个新列的列名
)-
pd.melt函数具体使用
import pandas as pd
df4 = pd.read_csv('../datas/data_set/music.csv')
print(df4)
# 除了id_vars指定的列不变以外,剩余列全部都变形
print(df4.melt(
id_vars=['artist', 'track'],
# value_vars=['wk1', 'wk2'],
var_name='week',
value_name='rating'
))
# id_vars指定的列不变,value_vars指定的列都变,其他列被丢弃
print(df4.melt(
id_vars=['artist', 'track'],
value_vars=['wk1', 'wk2'],
var_name='week',
value_name='rating'
))
# value_vars指定的列都变,其他列被丢弃
print(df4.melt(
# id_vars=['artist','track'],
value_vars=['wk1', 'wk2'],
var_name='week',
value_name='rating'
))
df.pivot_table透视表
- 数据透视表就是基于原数据表、按照一定规则呈现汇总数据,转换各个维度去观察数据;和excel的透视表在数据呈现上功能相同
df.pivot_table(
index='列名1',
columns='列名2',
values='列名3',
aggfunc='内置聚合函数名',
margins=True # 默认是False, 如果为True,就在最后一行和最后一列,按行按列分别执行aggfunc参数规定的聚合函数
)-
使用说明:以列名1作为索引,根据列名2进行分组,对列名3使用pandas内置的聚合函数进行计算,返回新的df对象
-
参数说明:
-
index:返回df的行索引,并依据其做分组;传入原始数据的列名
-
columns:返回df的列索引;传入原始数据的列名,根据该列做分组
-
values: 要做聚合操作的原始数据的列名
-
aggfunc:内置聚合函数名字符串
-
-
具体使用:加载优衣库的销售数据集,统计每个城市线下门店各种品类商品总销售额
import pandas as pd
# 读取优衣库的销售数据
df4 = pd.read_csv('../datas/data_set/uniqlo.csv')
# 获取全部线下的销售数据
df5 = df4.query('channel=="线下"')
print(df5.head())
# 每个城市线下门店各种品类商品总销售额
print(df5.pivot_table(
index='city',
columns='product',
values='revenue',
aggfunc='sum',
margins=True
))
-
图解上述代码变化过程
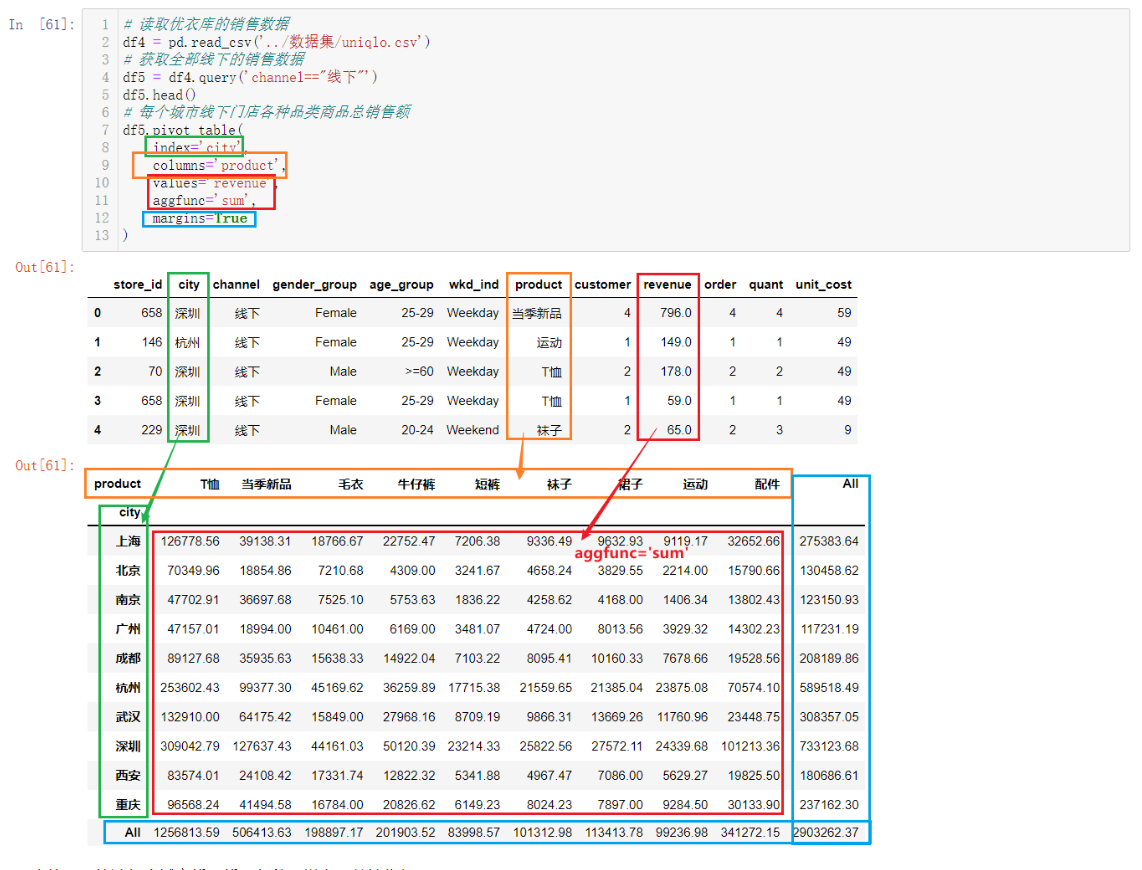
-
小练习:统计每个城市线上线下各种品类商品总销售额
import pandas as pd
# 读取优衣库的销售数据
df4 = pd.read_csv('../datas/data_set/uniqlo.csv')
print(df4.pivot_table(
index=['city', 'channel'],
columns='product',
values='revenue',
aggfunc='sum',
margins=True
))
4.总结
合并数据集
-
纵向追加合并
df1.append(df2, ignore_index=True)-
参数ignore_index默认为False 如果为 True 则重置为自增索引
-
-
pd.concat函数纵向横向连接多个数据集
-
# 纵向连接,全部数据都保留 pd.concat([df1, df2]) # 纵向连接,只保留共有数据 pd.concat([df1, df2], join='inner') # 横向连接,全部数据都保留 pd.concat([df1,df2], axis=1) # 横向连接,保留索引值匹配的数据 pd.concat([df1,df2], join='inner', axis=1)df.merge合并指定关联列的多个数据集
-
df1.merge(df2, on='列名', how='固定值') # 参数on='列名',表示基于那一列进行合并操作 # 参数how='固定值',表示合并后如何处理行索引,固定参数具体如下: # how='left' 对应SQL中的left join,保留左侧表df1中的所有数据 # how='right' 对应SQL中的right join,保留右侧表df2中的所有数据 # how='inner' 对应SQL中的inner,只保留左右两侧df1和df2都有的数据 # how='outer' 对应SQL中的join,保留左右两侧侧表df1和df2中的所有数据df.join横向合并索引值相同的多个数据集;通过
lsuffix和rsuffix两个参数分别指定左表和右表的列名后缀,how参数的用法与merge函数的how参数用法一致 -
df1.join( df2, lsuffix='df1的列名后缀', rsuffix='df2的列名后缀', how='outer' ) -
df1.join( df2, lsuffix='df1的列名后缀', rsuffix='df2的列名后缀', how='outer' )
-
合并df的四个函数总结
-
df1.append(df2)纵向合并数据集 -
pd.concat([df1,df2])横向或纵向合并数据集,df1和df2可以没有任何关系 -
df1.merge(df2)融合df1和df2,要有关联的列(两个列名相同的列) -
df1.join(df2)横向合并,df1和df2索引值相同
-
df变形
-
df.T 行变列、列变行
-
df.stack()把df变为树状花括号形式(Seriers对象);df.unstack()是df.stack()的逆操作
-
pd.melt()函数,将指定的一个或多个列名变成新df的一个列的值,原列值变成新df的另一个列的值
-
df.melt( id_vars=['列名'], # 不变形的所有列 value_vars=['列名'], # 要变形的所有列:把多个列变成一个新列;同时所有对应的值变成第二个新列的值 var_name='新列名', # 新列的列名 value_name='新列名' # 第二个新列的列名 )df.pivot_table透视表:按照一定规则提取并展示汇总数据,方便我们转换各个维度去观察数据
-
# 以列名1作为索引 # 根据列名2进行分组 # 对列名3使用pandas内置的聚合函数进行计算 # 返回新的df对象 df.pivot_table( index='列名1', columns='列名2', values='列名3', aggfunc='内置聚合函数名', margins=True # 默认是False, 如果为True,就在最后一行和最后一列,按行按列分别执行aggfunc参数规定的聚合函数 ) # index:返回df的行索引,并依据其做分组;传入原始数据的列名 # columns:返回df的列索引;传入原始数据的列名,根据该列做分组 # values: 要做聚合操作的原始数据的列名 # aggfunc:内置聚合函数名字
5.项目地址
Python: 66666666666666 - Gitee.com





![[SUCTF 2019]CheckIn1](https://img-blog.csdnimg.cn/1d66e61fe9c64d27b773d2c864579bc7.png)



![[OS]11.9.2023 中断](https://img-blog.csdnimg.cn/18d0ca71e6dd43d4b7405c349333a48c.png)

