Integrating Knowledge in Language Models
P.s.这篇文章大部分内容来自Stanford CS224N这门课Integrating Knowledge in Language Models这一节😁
为什么需要给语言模型添加额外的知识
1.语言模型会输出看似make sense但实际上不符合事实的内容
语言模型在生成预测时通常会产生有意义的结果,例如正确的类型或语义,但并不都是事实上的正确答案。说明语言模型能够从其训练数据中学习到一些常见的知识和模式,但实际上并不能保证所有生成的答案都是在事实上准确的。

那么为什么可能出现这种情况呢,这是一些可能的原因:
-
未见过的事实:一些事实可能根本没有出现在训练语料库中,因此语言模型无法学习到这些特定的知识。
-
稀有事实:语言模型在训练过程中可能没有看到足够的示例来记忆这些罕见的事实。
-
模型敏感性:语言模型可能在训练过程中看到了某个事实,但对于问题的表述方式非常敏感。这意味着在不同的提问方式下,语言模型可能会给出不同的答案,导致在某些情况下无法正确回答问题。
-
对于“x是在y中制造的”模板问题能够正确回答,但对于“x是在y中创造的”问题则不能正确回答。
2.具备知识感知的语言模型(Knowledge-Aware Language Models)的重要性和难点
预训练语言模型的表示可以为利用知识的下游任务带来好处。比如说在提取句子中两个实体之间的关系时,如果语言模型具备对这些实体的一些知识,那么这个任务会更容易完成。
但是要训练一个这样具备知识库属性的语言模型存在这样两个难点:
-
语言模型产生答案的原因往往难以解释。由于语言模型是通过大量无监督训练学习得到的,其内部运作方式并非直接可见。因此,当语言模型提供一个答案时,很难确定模型是如何得出这个答案的,缺乏解释性可能会限制其在一些关键领域的应用。
-
在语言模型中删除或更新知识并不容易。传统的知识库可以通过增加、删除或更新实体和关系来进行维护。然而,对于语言模型而言,要修改其内部的知识表示是比较困难的。这意味着语言模型在知识更新方面可能难以跟上实时的知识变化。
如何为语言模型添加额外的知识
大体上可以分为三类方法:增加预训练的实体嵌入,使用外部知识存储器以及直接修改训练的数据
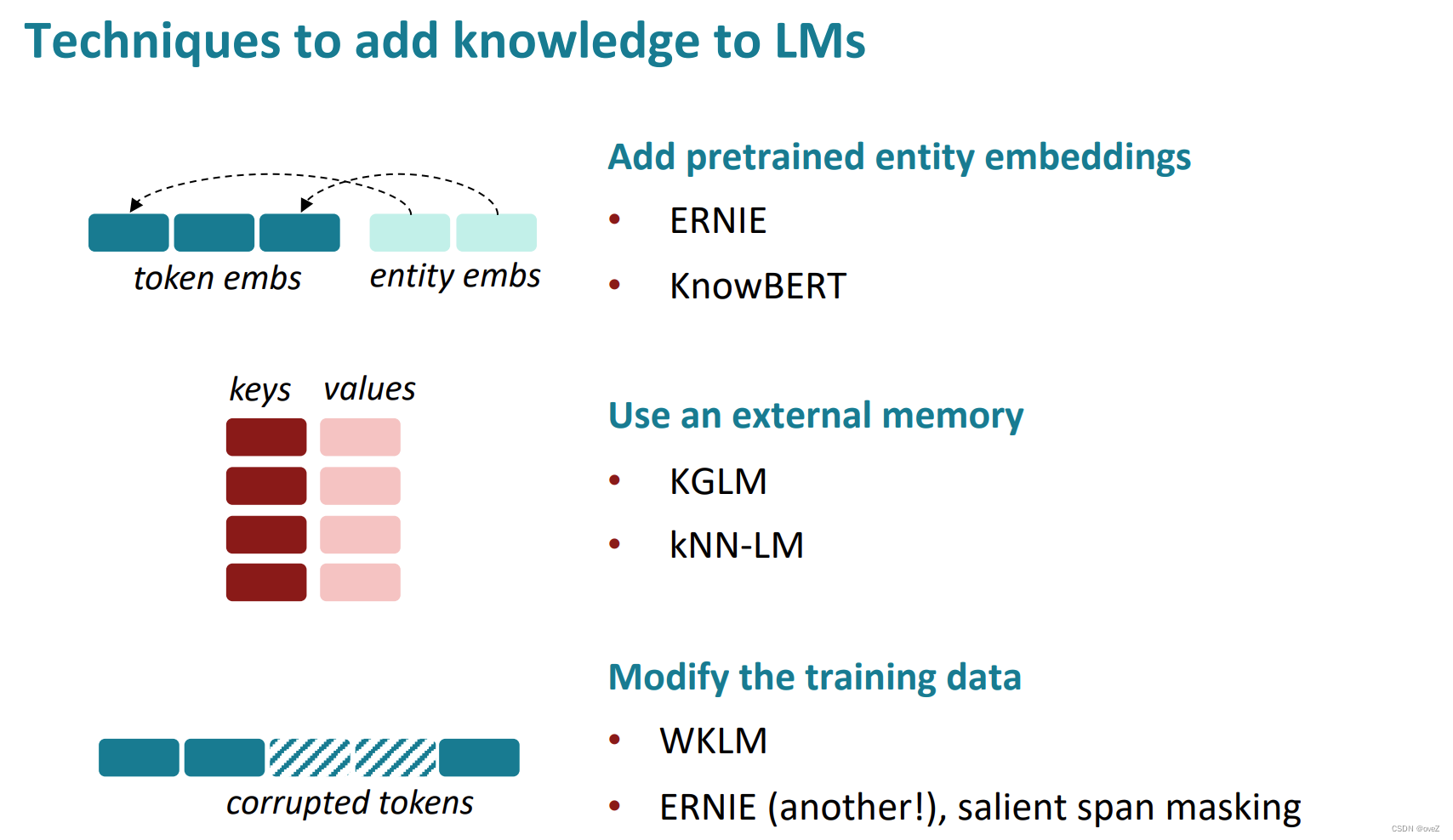
以下是每一类的解释和一些例子
1)增加预训练的实体嵌入:
方法
为了提升大型语言模型的知识表示能力,一种方法是通过添加预训练实体嵌入来处理实体相关的信息。在自然语言处理中,实体通常指代具体的人、地点、组织或物体,例如,“华盛顿是美国的第一任总统”,而这些实体之间的关系对于理解和生成自然语言文本至关重要。
传统的预训练词嵌入模型,如Word2Vec和GloVe,通常没有明确的实体概念。它们仅对单个词进行建模,而无法捕捉到实体之间的语义关联。
为了解决这个问题,一种解决方案是为每个实体分配一个独立的嵌入。通过为每个实体分配特定的嵌入向量,语言模型可以更好地表示和理解不同实体之间的关系。例如,对于指代同一个实体的词语,如“U.S.A.”、“United States of America”和“America”,可以使用相同的实体嵌入,这样可以确保一致性和准确性。

然而,要使实体嵌入的添加对语言模型产生积极影响,需要进行准确且可靠的实体链接。就是将文本中的实体与预定义的实体进行匹配。一旦实体链接完成,语言模型就可以利用实体嵌入来更好地理解和处理实体相关的信息。
相关工作:ERNIE和 “Jointly learn to link entities with KnowBERT”
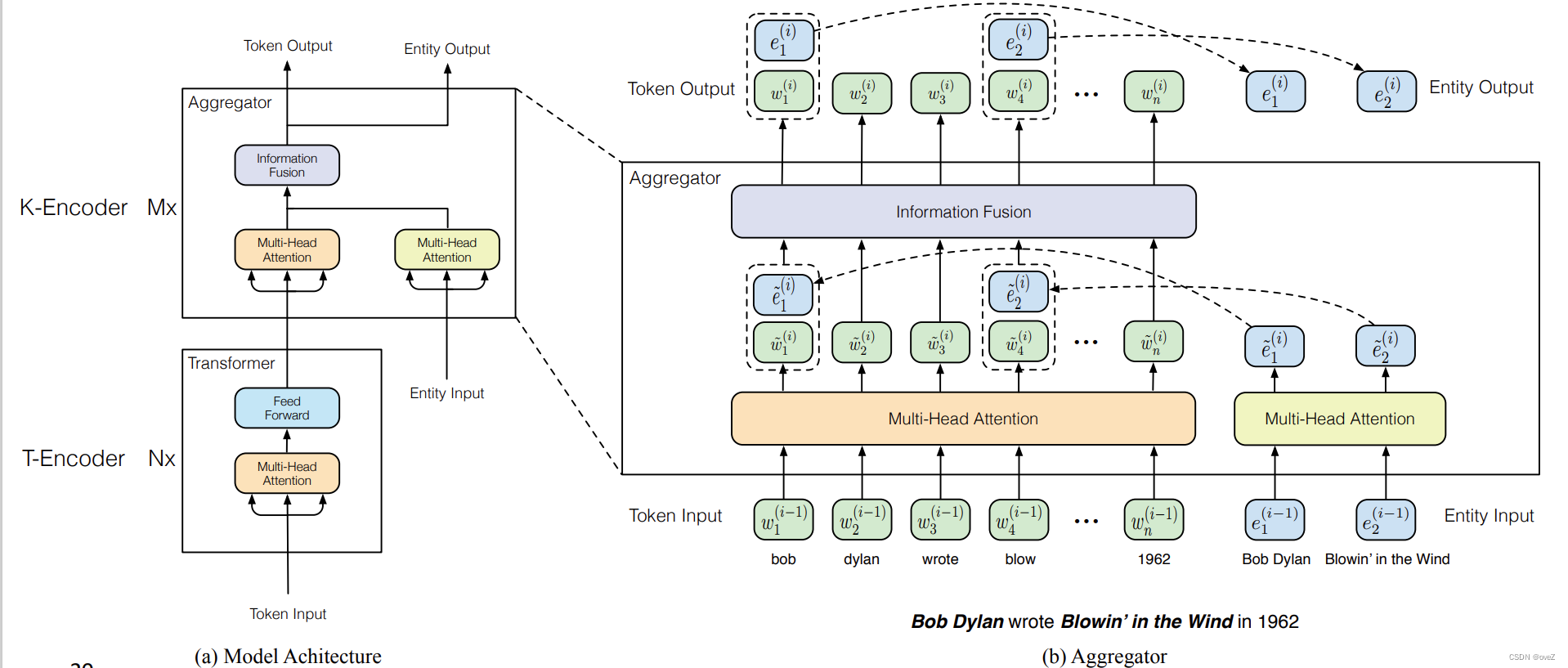
1.ERNIE
ERNIE旨在通过引入实体知识来增强语言表示能力,并改进模型对实体相关信息的理解。它使用了两个关键技术:实体识别和实体链接。
-
在实体识别阶段,ERNIE使用实体识别技术来标注文本中的实体提及。实体识别是指识别文本中表示具体人、地点、组织或物体的实体名词短语。例如,在句子"华盛顿是美国的第一任总统"中,"华盛顿"就是一个人物实体。通过实体识别,ERNIE能够确定哪些词语是实体提及,并对它们进行标注。
-
在实体链接阶段,ERNIE使用实体链接技术将标注的实体提及链接到预定义的实体库中的相应实体。实体链接是将文本中的实体提及与实体库中的相关实体进行匹配的过程。例如,将"华盛顿"链接到"George Washington"的实体。
ERNIE模型在预训练阶段同时学习实体嵌入和上下文嵌入,以更好地捕捉实体之间的关系和语义信息。实体嵌入是指为每个实体分配的向量表示,它能够捕捉实体的语义特征。上下文嵌入是指模型从文本上下文中学习的词语表示。通过同时学习这两种嵌入,ERNIE能够将实体的语义信息与上下文信息结合起来,提高对实体相关信息的表示能力。
2. KnowBERT+实体链接
相对的,"Jointly learn to link entities with KnowBERT"提出了一种联合学习的框架,将实体链接任务与预训练模型的训练相结合。这项工作使用了一个名为KnowBERT的模型。
在训练过程中,KnowBERT通过联合学习实体链接任务和语言模型任务来提升实体链接的性能。具体而言,它在预训练过程中通过多任务学习将实体链接任务与语言模型任务相结合。语言模型任务是通过上下文预测缺失词语,以提高模型对上下文信息的理解能力。同时,实体链接任务要求模型预测实体提及的链接实体。通过联合训练,KnowBERT能够在预训练阶段学习到更强的实体链接能力。
2) 加上外部知识库
方法
先前的方法依赖于预训练的实体嵌入来为语言模型编码知识库中的事实知识。这些实体嵌入是通过对大规模文本语料进行训练得到的,但在某些情况下,预训练的实体嵌入可能还是无法捕捉到特定领域或特定上下文的细节。因此,我们需要更直接的方式来向模型提供事实知识。
一种解决方法是通过为模型提供对外部内存的访问,这个外部内存可以是一个键值存储系统,其中存储了知识图谱的三元组或其他上下文信息。模型可以通过查询这个外部内存来获取特定的事实知识,并将其应用于生成文本或回答问题的过程中。

使用外部内存具有以下这些优势:
-
更好地支持注入和更新事实知识:通过访问外部内存,模型可以直接获取和更新知识库中的事实信息。例如,如果有新的知识需要添加到知识库中,可以通过向外部内存添加新的键值对来实现。这种方式使得模型能够灵活地获取和更新知识,而无需重新训练整个模型。
-
具备更好的可解释性:通过访问外部内存,模型的知识获取和使用过程更加透明和可解释。模型可以直接查询外部内存中的键值对,从而使研究者能够更好地理解模型的推理和决策过程。
相关工作: KGLM和kNN-LM
1.KGLM
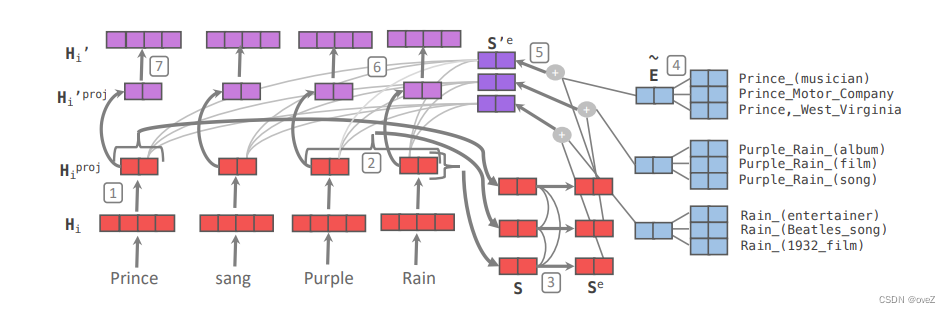
KGLM采用了一种创新性的的方法将知识图谱集成到语言模型中:
-
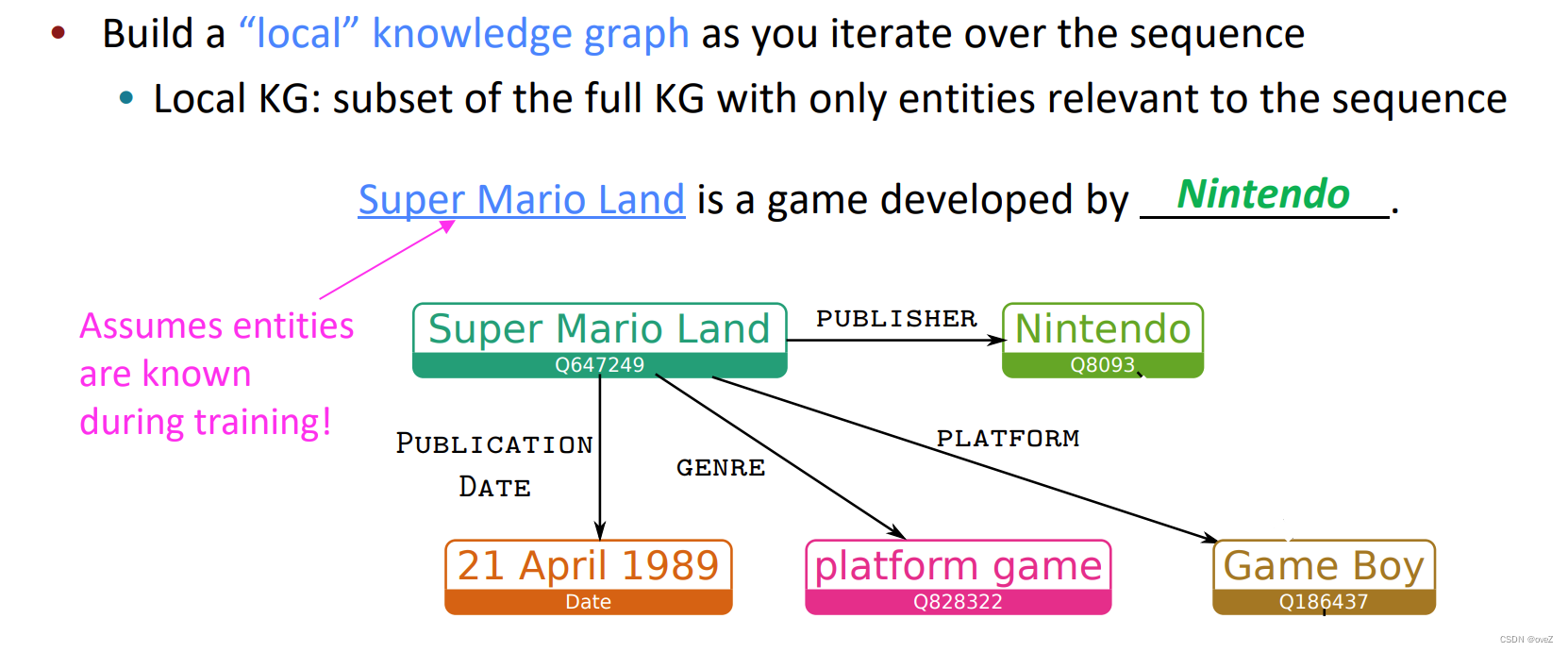
知识图谱表示:KGLM使用预先存在的知识图谱,其中包含实体、关系和属性之间的关联信息。知识图谱通常以三元组的形式表示,如(subject, relation, object)。对于每个实体和关系,KGLM利用嵌入技术将其表示为高维向量。
-
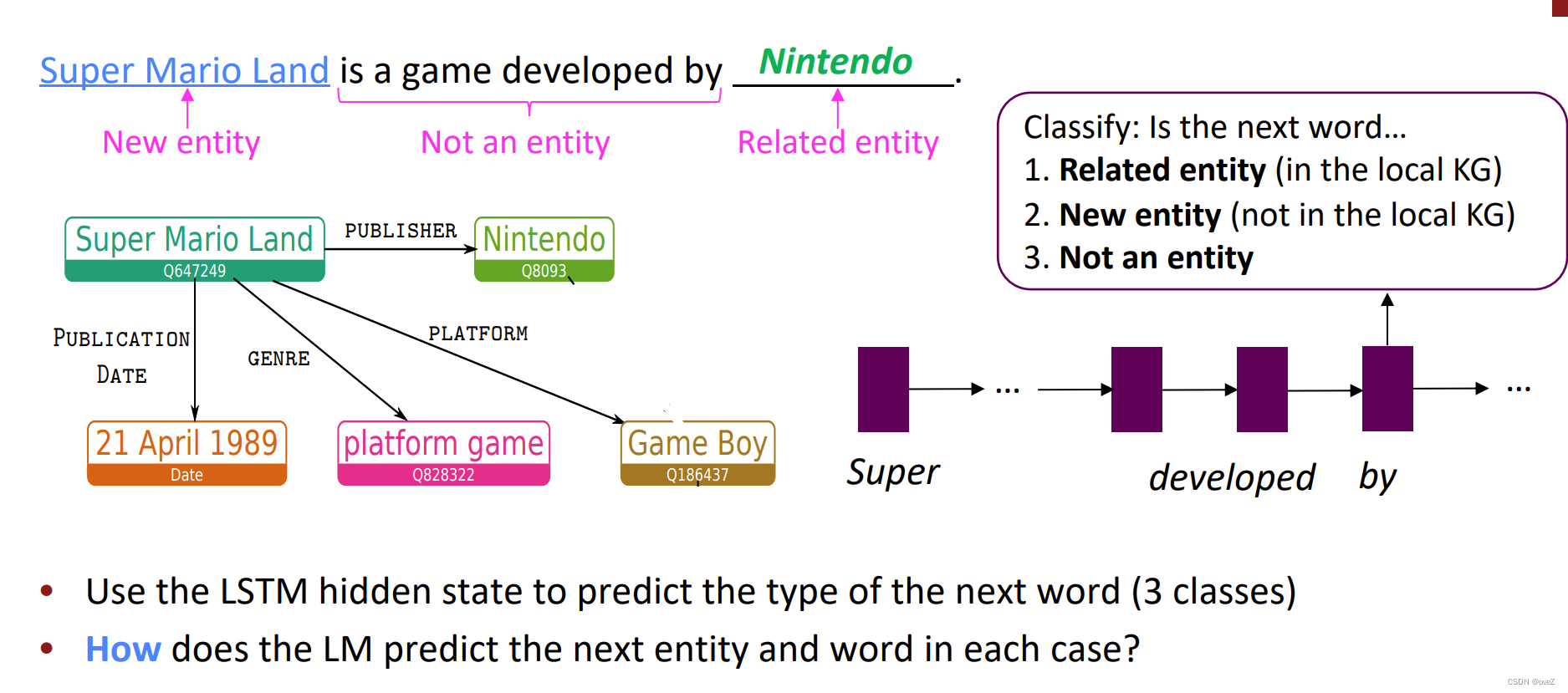
输入扩展:在生成过程中,KGLM将输入序列与知识图谱进行对齐。它使用实体链接技术将输入文本中的单词或短语与知识图谱中的相应实体进行匹配。如图,如果输入文本中提到"Super Mario Land",它可以链接到知识图谱中的"Nintendo"实体。
-
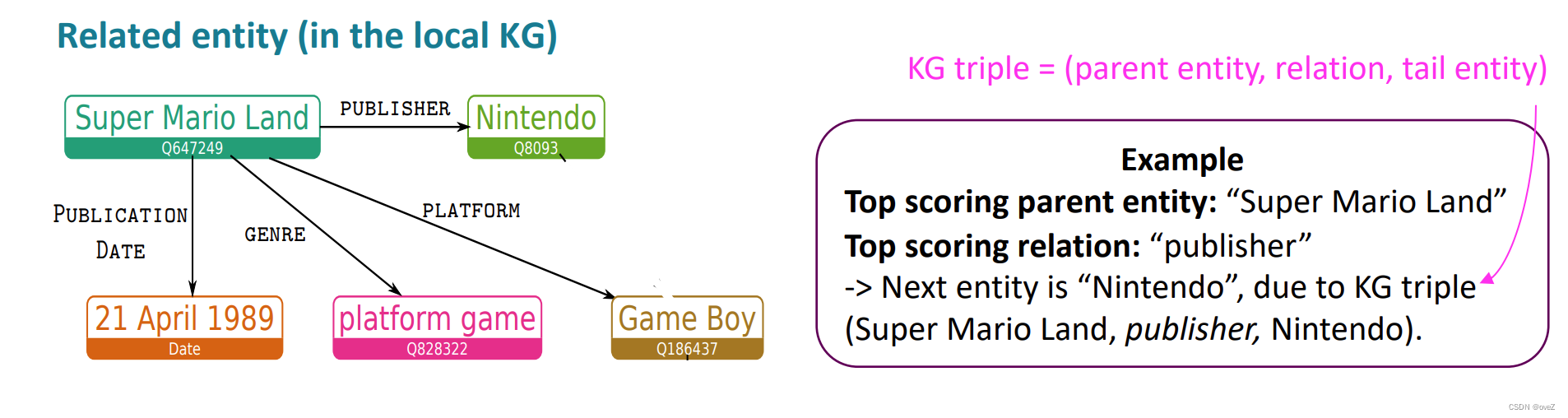
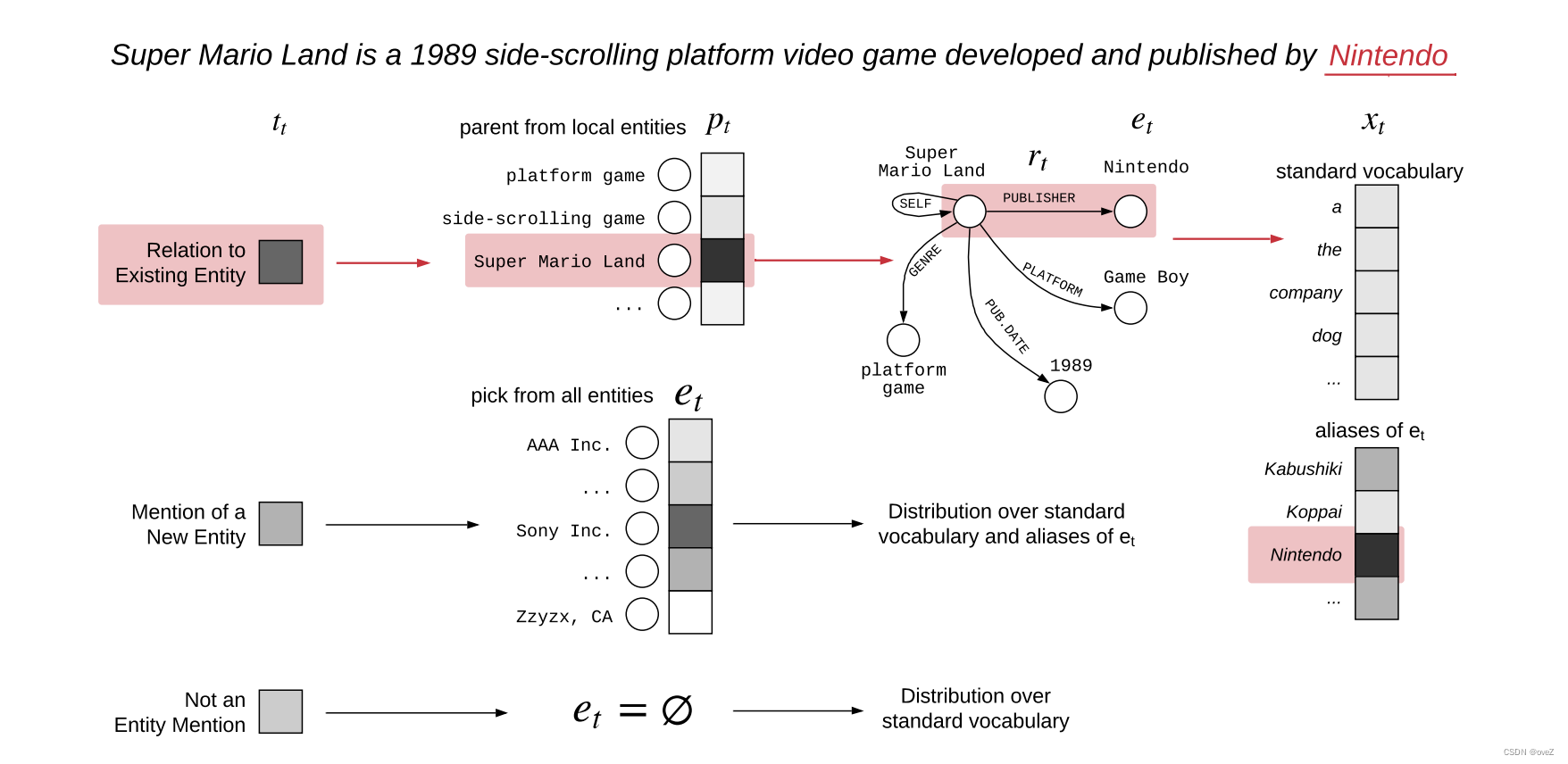
知识图谱嵌入:通过将知识图谱中的实体和关系嵌入到输入序列中,KGLM扩展了输入的表示。这样,模型可以同时利用输入文本和知识图谱的信息来生成回复。嵌入的表示可以是通过简单的拼接或更复杂的方式融合到输入序列中。
2.kNN-LM
kNN-LM旨在通过利用大规模文本数据集中的最近邻来改进语言模型。
-
文本表示索引:kNN-LM使用大规模文本数据集构建一个索引,用于存储短语或句子的表示。
-
最近邻检索:在生成回复时,kNN-LM从给定的上下文中检索最近邻的k个短语或句子。这些最近邻被视为候选回复。检索过程使用索引来计算输入上下文与索引中存储的短语或句子之间的相似度。
-
回复选择和调整:从最近邻的候选回复中,kNN-LM选择最相似、句法兼容性较高且多样性较大的回复。然后模型可以根据需要对选定的回复进行调整,以更好地适应给定上下文。
3)调整训练的数据:
方法
第三种方法是通过修改训练数据来将知识融入到模型中。传统方法通常通过预训练的嵌入或外部存储器显式地引入知识。那是否可以通过非结构化文本隐式地融入知识呢?实际上,我们可以通过对数据进行掩盖或损坏的方式,引入需要事实知识的额外训练任务。
这种方法的优势:
-
不需要额外的内存或计算资源,也不需要对模型的架构进行修改。通过简单地改变训练数据,可以引入额外的任务,要求模型具备对事实知识的理解和处理能力。例如,可以通过掩盖文本中的某些单词或短语,要求模型根据上下文填充缺失的信息。这样,模型在训练过程中会学习到识别和推理事实的能力。
-
可以隐式地利用知识,而无需显式的知识表示或查询。在训练数据中引入需要事实知识的任务,模型会自动学习到与之相关的特征和表示。
相关工作:WKLM和ERNIE
1.WKLM:Weakly Supervised Knowledge Pretrained Language Model
这个模型的关键思想是训练模型区分真实的知识和错误的知识。为了实现这个目标,模型在文本中替换提及的实体,将其替换为同一类型的不同实体,从而创建负面的知识陈述。模型需要预测实体是否被替换了。这种替换操作是为了引入错误的知识,用于训练模型识别和区分正确和错误的知识。

具体来说,对于一个真实的知识陈述,比如"J.K.罗琳是《哈利·波特》的作者",将其中的实体替换为同类型的不同实体,比如"J.R.R.托尔金是《哈利·波特》的作者",就得到了一个负面的知识陈述。模型需要学会判断哪些实体是被替换了,从而区分真实和错误的知识。
2.ERNIE: Enhanced Representation through Knowledge Integration
ERNIE的核心思想是将外部知识与模型的表示空间进行融合。模型首先在大规模的文本语料上进行预训练,学习到一种通用的语言表示。然后,为了引入外部知识,模型使用了一个预训练的百科全书。这个百科全书中包含了丰富的知识,如实体关系、常识知识等。模型通过联合训练预训练语言模型和百科全书,使得模型的表示能力更好地涵盖了外部知识。
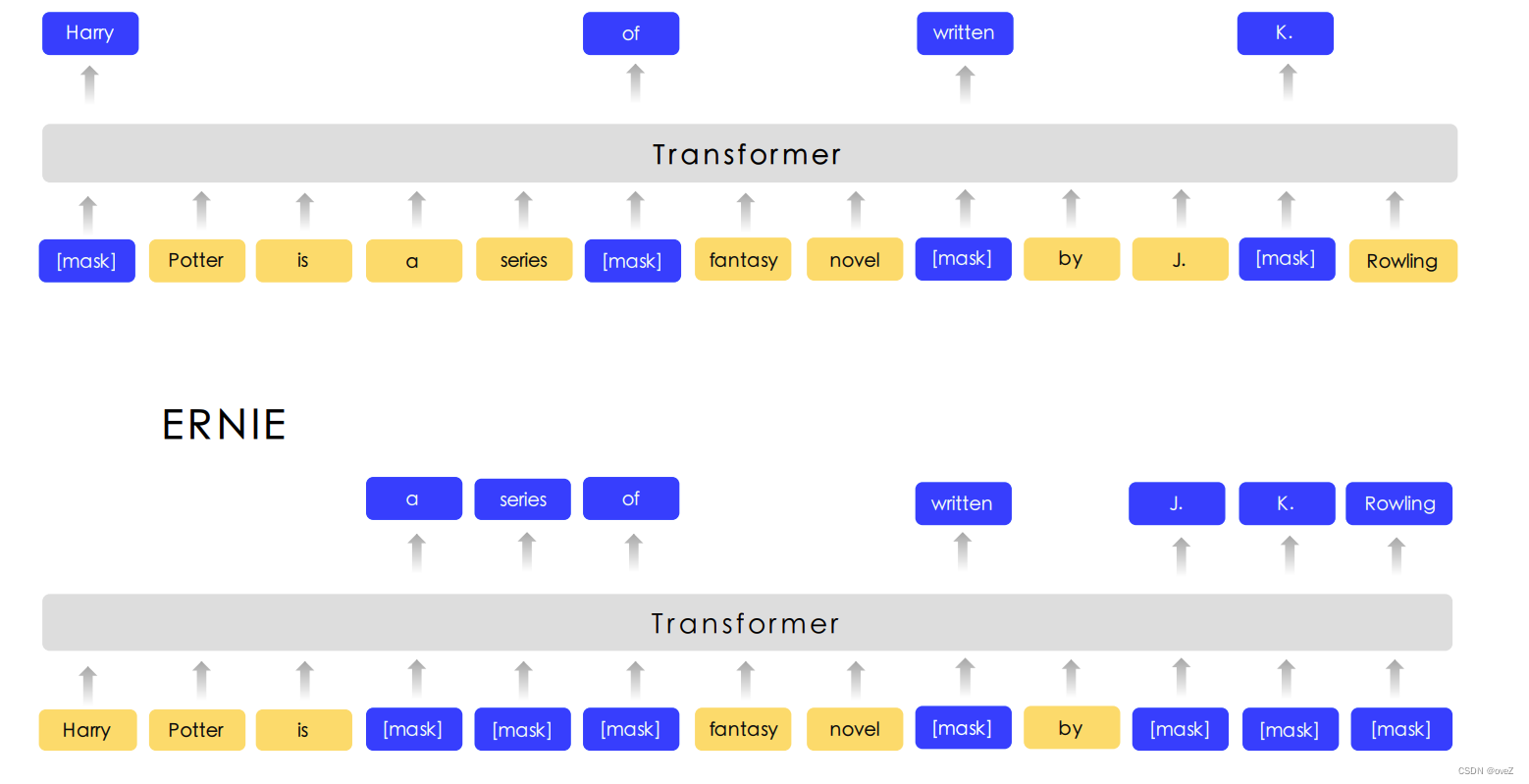
在训练过程中,ERNIE1采用了一种特殊的任务设计,即知识遮蔽 (Knowledge Masking)。这个任务要求模型在遮蔽了部分文本中的知识信息后,能够根据上下文来预测被遮蔽的知识。通过这个任务,模型被迫学习从文本中抽取并利用知识,从而提高了模型对知识的理解和应用能力。
此外,ERNIE1还使用了一种自适应层归一化 (Adaptive Layer Normalization) 的技术来进一步优化模型的性能。这种归一化方法可以根据输入样本的特征动态地调整参数,从而更好地适应不同样本之间的差异。