【编者按】GPT 系列的面世影响了全世界、各个行业,对于开发者们的感受则最为深切。以 ChatGPT、Github Copilot 为首,各类 AI 编程助手层出不穷。编程范式正在发生前所未有的变化,从汇编到 Java 等高级语言,再到今天以自然语言为特征的 Prompt 工程,编程的门槛进一步降低,让很多开发者也不由得思考,编程的未来究竟会如何演化,在这大模型时代,开发者又该何去何从?基于此,《新程序员 007:大模型时代的开发者》特别邀请资深程序员 Phodal 撰写此文,希望能够对所有开发者在未来之路的前行上有所帮助。
注:《新程序员 007》聚焦开发者成长,其间既有图灵奖得主 Joseph Sifakis、前 OpenAI 科学家 Joel Lehman 等高瞻远瞩,又有对于开发者们至关重要的成长路径、工程实践及趟坑经验等,欢迎大家点击订阅年卡。
作者 | 黄峰达(Phodal)
责编 | 唐小引
出品 | 《新程序员》编辑部
在近一年的时间里,ChatGPT 的横空出世带来整个软件开发行业的一系列新变化。不论是个人、团队,还是公司的 CXO 们,都在关注生成式 AI 带来的效率提升。
-
在产品研发方面,生成式 AI(AIGC) 已经开始影响产品生命周期的各个阶段。它可以用于生成候选产品设计,优化产品设计,提升产品测试效率,改进产品质量。
-
在软件开发方面,从项目启动和规划,到系统设计、代码编写、测试和维护,生成式 AI 的应用广泛而多样。它可以帮助开发人员生成基于上下文的代码草稿,甚至生成测试代码。此外,它还有助于优化遗留框架的集成和迁移,并提供自然语言翻译功能, 以将旧的遗留代码转化为现代代码。
对于开发者来说,大型生成式语言模型带来了挑战,但也提供了宝贵的机会。
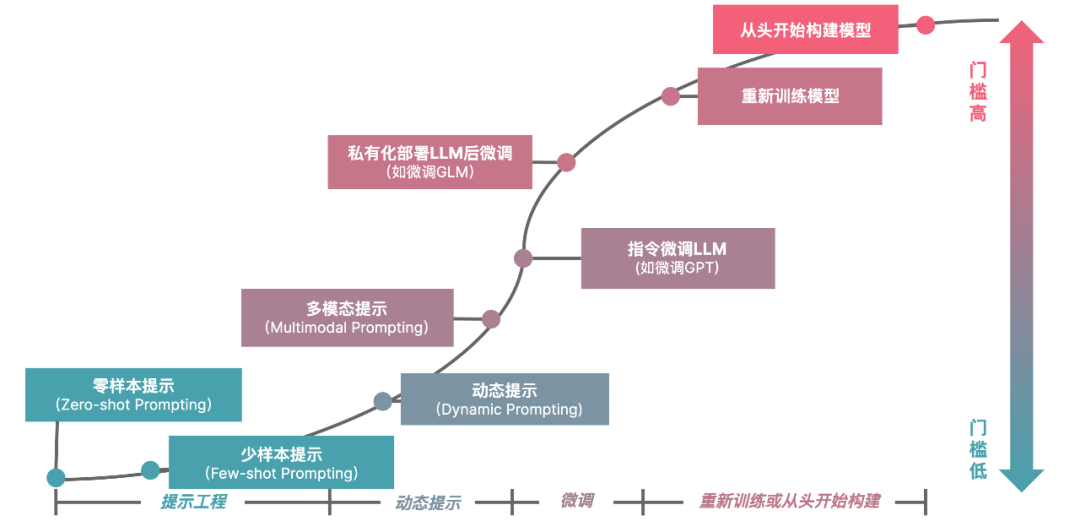
图 1 企业 AIGC 投资策略
根据我们此前分析的企业 AIGC 投资策略/难度曲线(如图 1 所示),这里也划分了三个阶段:
-
L1:学会与 LLM 相处,提升个人或团队效率。
-
L2:开发 LLM 优先应用架构,探索组织规模化落地。
-
L3:微调与训练大语言模型,深度绑定特定场景。
尽管,可能有一些企业预期生成式 AI 带来的效能提升,而进行了组织结构调整(俗称裁员)。但是,我们可以看到 AIGC 带来了更多的新机遇,它们不仅能够提高开发效率,还可以开创全新的领域和解决方案,为软件开发行业带来划时代的变革。
简单来说,开发者如果想保持自己的竞争力,我们必须掌握 LLM 能力以提升生产力,还可以加入开发 LLM 应用的大军。
L1:学会与 LLM 相处,提升个人或团队效率
在过去一年里,我们看到很多人在使用 LLM 的过程中,遇到了一些问题。但也很显然,它能在许多方面提升我们的效率,特别是在诸多繁琐的事务上,如文档、测试用例、代码等。
LLM 擅长什么,不擅长什么?
首先,我们要建立对于 LLM 的认知。不同的模型,由于训练主料和参数等诸多原因,各有自身的擅长点。如一些微信机器人里,我们使用文心一言询问实时性的资讯内容,再结合国内外的开源、闭源模型(如 ChatGPT 等)进行优化。而一旦想编写一些英文文档、材料邮件时,则会反过来优先考虑国外的模型。
其次,我们要知道 LLM 不擅长什么。LLM 是一个语言模型,它擅长的是生成文本。究其本质它又是一个概率模型,所以它需要借助其他工具来完成自身不擅长的内容(比如数学计算)。因此,我们不应该期望 LLM 能够帮助我们完成一些数学计算,而是应该期望它能根据我们的上下文,生成数学计算的公式、代码等等。
学会与 LLM 交流,提升个人效率
LLM 的交流方式,主要是通过 Prompt,而 Prompt 的构建,是一个需要不断迭代的过程。在这个过程中,要不断地尝试,以找到最适合自己的模式。比如笔者习惯的模式是:
-
角色与任务。告知 LLM 它应该是一个什么角色,需要做什么事情。
-
背景。提供一些必要的上下文,以便于有概率地、更好地匹配到答案。
-
要求。对它提一些要求,诸如返回的格式、内容等等。
-
引导词(可选的)。让 LLM 更好地理解我们的意图。
如下是笔者在开源的 IDE 插件 AutoDev 中的测试生成的 Prompt(部分):
Write unit test for following code. You are working on a project that uses Spring MVC,Spring WebFlux,JDBC to build
RESTful APIs.
You MUST use should_xx style for test method name.
When testing controller, you MUST use MockMvc and test API only.
// class BlogController {
// blogService
// + public BlogController(BlogService blogService)
// + @PostMapping("/blog") public BlogPost createBlog(CreateBlogDto blogDto)
// + @GetMapping("/blog") public List<BlogPost> getBlog()
// }
// 选中的代码信息
Start with `import` syntax here:最后的 import 会根据用户选中的是类还是方法来决定,如果是一个方法,那么就会变为: Start with @Test syntax here: 。由于大部分的开源代码模型是基于英语的,并且用来训练的代码本身也是“英语”的,所以在效果上用英语的 Prompt 效果会更好。
精炼上下文成本,活用各类工具
笔者在经过与大量的人聊天之后,得到的一个人们使用 AIGC 工具的最大痛点:编写 Prompt 时,往往超过完成任务的时间。
也因此,从某种程度上来说,我们所需要的上下文并不一定要准确,但一定要精炼,以节省自己的时间。所以,从时间成本上来说,我们要考虑引入工具,或者构建适合自己的工具来完善这个过程。
对于开发人员来说,目前市面上流行的工具有:GitHub Copilot、ChatGPT、Midjourney 等其他内容生成工具。诸如 GitHub Copilot 在生成效果上之所以好,是因为它会根据当前的代码文件、编辑历史,分析出一些相似的上下文,再交由 LLM 处理。整个过程是全自动的,所以它能大量节省时间。在采用 Midjourney 这样的工具时,也在构建自动的 Prompt 方式 —— 从一句话需求,生成一个符合自己习惯的 Prompt,以生成对应的图片。
考虑到每个工具,每个月可能会产生 10~30 美元的成本,我们还是需要仔细研究一下更合适的方案是什么。
值得一提的是,尽管 LLM 能提升效能,但随之可能你的工作量更高了。所以,你掏出的工具费用,应该由您的组织来提供,因为单位时间的产能上去了。
个人发展:提升 AI 不擅长的能力
随着 AIGC 成本的进一步下降,有些部门可能会因为生成式 AI 而遭公司缩减规模。这并非因为 AIGC 能取代人类,而是人们预期提升 20~30% 的效能,并且在一些团队试点之后,也发现的确如此。
假定 AIGC 能提升一个团队 20% 的效能,那么从管理层来说,他们会考虑减少 20% 的成员。而更有意思的是,如果团队减少了 20% 的规模,那么会因为沟通成本的降低,而提升更多的效能。所以,这个团队的效能提升了不止 20%。
从短期来说,掌握好 AIGC 能力的开发人员,不会因这种趋势而被淘汰。而长期来说,本就存在一定内卷的开发行业,这种趋势会加剧。十几年前,人们想的是一个懂点 Java 的人,而今天,这个标准变成了,既懂 Java 设计模式,还要懂 Java 的各类算法。所以,从个人发展的角度, 我们要适当地提升 AI 不擅长的能力。
就能力而言,AI 不擅长解决复杂上下文的问题,比如架构设计、软件建模等等。从另一个层面上,由于 AI 作为一个知识库,它能够帮助我们解决一些软件开发的基础问题(比如某语言的语法),会使得我们更易于上手新语言,从而进一步促使开发者变成多面手,成为多语言的开发者。
与提升这些能力相比,在短期内,我们更应该加入开发大模型的大军。因为,这是一个全新的领域,无需传统 AI 的各种算法知识,只需要懂得如何工程化应用。
L2:开发 LLM 优先应用架构,探索组织规模化落地
与十年前的移动浪潮相似,生成式 AI 缺少大量的人才。而这些人才难以直接从市场上招聘到,需要由现有的技术人才转换而来。所以,既然我们可能打不过 AI,那么就加入到这个浪潮中。

AI 浪潮席卷(图源:由编者 AIGC 生成)
PoC 试验:现有产品融入 LLM,探索 LLM 优先架构
在过去的一年里,我们可以看到有大量的开发者加入了 LLM 应用的开发大军中。它并没有太复杂的技术,只需要一些简单的 Prompt 基础,以及关于用户体验等的设计。从网上各类的聊天机器人,再到集成内部的 IT 系统,以及在业务中的应用。只有真正在项目中使用,我们才会发现 LLM 的优势和不足。
考虑到不同模型之间的能力差异和能力,我们建议使用一些比较好的大语言模型,以知道最好的大模型能带来什么。从笔者的角度来说,笔者使用比较多的模型是 ChatGPT 3.5,一来是预期 2023 年年底或者 2024 年国内的模型能达到这个水平,二来是它的成本相对较低,可以规模化应用。

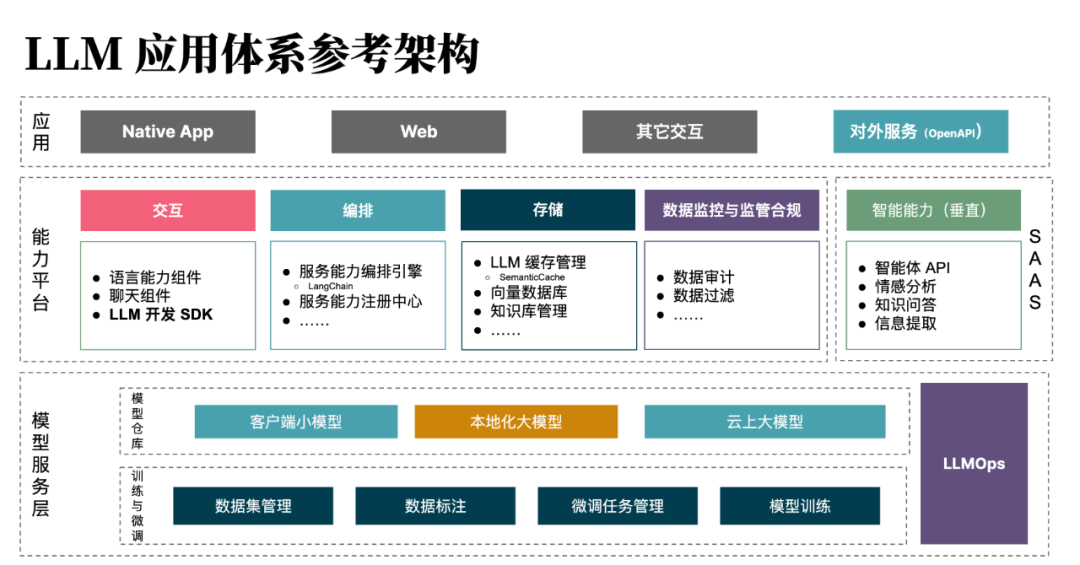
图 2 LLM 优先架构
如下是,根据我们的内外部经验,总结出的 LLM 优先架构(如图 2 所示)的四个原则:
-
用户意图导向设计。设计全新的人机交互体验,构建领域特定的 AI 角色,以更好地理解用户的意图。简单来说,寻找更适合于理解人类意图的交互方式。
-
上下文感知。构建适合于获取业务上下文的应用架构,以生成更精准的 Prompt,并探索高响应速度的工程化方式。即围绕高质量上下文的 Prompt 工程。
-
原子能力映射。分析 LLM 所擅长的原子能力,将其与应用所欠缺的能力进行结合,进行能力映射。让每个 AI 做自己擅长的事,诸如利用好 AI 的推理能力。
-
语言 API。探索和寻找合适的新一代 API ,以便于 LLM 对服务能力的理解、调度与编排。诸如自然语言作为人机 API,DSL 作为 AI 与机器间的 API 等。
如我们在构建一个文本生成 SQL、图表、UI 的应用时,做的第一个设计就是:用户输入一句话,让 LLM 根据我们给定的上下文分析用户的意图,再生成对应的 DSL。如下是这一类工具思维链的精炼版本:
思考:是否包含了用户故事和布局信息,如果明确请结束询问,如果不明确,请继续询问。
行动:为 ”CONTINUE” 或者 ”FINISH”
询问:想继续询问的问题
最终输出:完整的问题
思考-行动-询问可以循环数次,直到最终输出随后,在有了用户的意图之后,我们会根据用户的意图,生成对应的 DSL,再由 DSL 生成对应的 SQL、图表、UI 等等。如下是一个简单的 DSL:
pageName: 博客详情页
usedComponents: Grid, Avatar, Date, Typography, CardMedia, Button,
------------------------------------------------------
| NavComponent(12x) |
------------------------------------------------------
| Text(6x, "标题") | Empty(6x) |
------------------------------------------------------
|Avatar(3x, "头像") | Date(3x, "发布时间")| Empty(6x)|
------------------------------------------------------
| CardMedia(8x) | Empty(4x) |
------------------------------------------------------
| Typography(12x, "内容") |
------------------------------------------------------
| FooterComponent(12x) |
------------------------------------------------------然后,根据关联的组件示例代码、业务上下文信息,生成最后的应用代码。
LLM as Co-pilot:贴合自己的习惯,构建和适用 Copilot 型应用
相信大部分读者已经对于 GitHub Copilot 有一定的经验,对于这一类围绕于个体角色的 AI 工具,我们都会称其为 Copilot 型应用。所以,在这个阶段,我们会将其称为 LLM as Co-pilot:
即,不改变软件工程的专业分工,但增强每个专业技术,基于 AI 的研发工具平台辅助工程师完成任务,影响个体工作。
它主要用于解决 “我懒得做” 及 “我重复做” 的事儿。在 Thoughtworks 内部,不同的角色也构建了自己的 Copilot 型应用,诸如:
-
面向产品经理的 BoBa AI。用于做行业调研、设计参与计划、为研讨会做准备等。
-
面向业务分析师的 BA Copilot。帮助业务分析人员,将一句话需求,转换为验收条件、测试用例等等。
-
面向开发人员的 AutoDev。用于代码完成和生成、测试生成、代码解释、代码翻译、文档生成等。
-
面向测试人员的:SpeedTest。用于生成测试用例、UI 测试代码生成、API 测试代码生成等等。
-
……
在构建这一类工具时,我们需要深入了解每个角色的工作方式,以及他们的痛点。比如开发人员在使用 IDE 时,不止会编写代码,于是像 JetBrains AI Assistant 的自带 IDE AI 插件就会,在:
-
在用户重命名方法时,让 AI 生成可能的类名、方法名、变量名。
-
在用户出现错误时,让 AI 生成可能的解决方案。
-
在用户编写提交信息时,让 AI 生成可能的提交信息。
-
……
从个人的角度来说,这些工具是面向通用的场景构建的,可以将其称为通用型 AI 工具。而在企业内部或者自身有能力,我们可以构建更加贴合自己的 AI 工具,以提升效率。笔者在开发 AutoDev 的过程中,便在思考这个问题,如何构建一个更加贴合自己的 AI 工具。于是,加入了大量可以自定义规范、IDE 智能行为、文档生成等功能,以提升自己的效率。举个例子,你可以在代码库中加入自定义的智能行为,如直接选中代码,让它生成测试:
---
interaction: AppendCursorStream
---
你是一个资深的软件开发工程师,你擅长使用 TDD 的方式来开发软件,你需要根据用户的需求,帮助用户编写测试代码。
${frameworkContext}
当前类相关的代码如下:
${beforeCursor}
用户的需求是:${selection}
请使用 @Test 开头编写你的代码块:这类工具应该在完成通用的功能之后,提供一些自定义的能力,以提升个人的效率。
LLM as Co-Integrator:探索知识型团队的构建,加速团队间集成
除了上述的单点工具之外,如何在跨角色、跨团队之间形成这种全力协作的效果,是我们需要持续探索的问题。在软件研发领域,我们将这个阶段称之为 LLM as Co-Integrator,其定义是:
跨研发职责及角色的协同增效,基于 AI 的研发工具平台解决不同的角色沟通提效,影响角色互动。
其主要用于解决信息沟通对齐的问题。在非软件开发领域,诸如内部 IT 系统中,它也是相似的,如何让 AI 根据团队间的信息,辅助实现信息的对齐。比如我们可以通过获取个人日历信息,帮助团队进行自动排期,并结合 IM(即时聊天)来辅助会议时间的确定。
在这些场景上,我们可以看到诸多企业都是以构建内部的知识问答系统作为起点,探索这一类工具的应用,以进一步探索 AIGC 可能性。在一些领先的企业上,直接构建的是内部知识平台,员工只需上传自己的文档、代码等,就可以基于其作为上下文来问答。而在一些成熟的 MLOps/LLMOps 平台上,它可以直接提供基于知识平台的 API,以直接插入应用中。
而这些基于 LLM 问答工具的核心是 RAG(检索增强生成)模式,也是开发者在构建 AIGC 所需要掌握的核心能力。如下是一个简单的 RAG 表示(基于 RAGScript):
@file:DependsOn("cc.unitmesh:rag-script:0.4.1")
import cc.unitmesh.rag.*
rag {
// 使用 OpenAI 作为 LLM 引擎
llm = LlmConnector(LlmType.OpenAI)
// 使用 SentenceTransformers 作为 Embedding 引擎
embedding = EmbeddingEngine(EngineType.SentenceTransformers)
// 使用 Memory 作为 Retriever
store = Store(StoreType.Memory)
indexing {
// 从文件中读取文档
val document = document("filename.txt")
// 将文档切割成 chunk
val chunks = document.split()
// 建立索引
store.indexing(chunks)
}
querying {
// 查询
store.findRelevant("workflow dsl design ").also {
println(it)
}
}
}一个典型的 LLM + RAG 应用,分为两个阶段:
-
索引阶段。将文档、代码等切割成 chunk,再建立索引。
-
查询阶段。根据用户的查询,从索引中找到相关的 chunk,再根据 chunk 生成答案。
在这两个阶段,由于场景不同,需要考虑结合不同的 RAG 模式以提升检索质量,进而提升答案质量。如在代码索引场景,在索引阶段,依赖于代码的拆分规则, 会有不同的拆分方式;而在查询阶段,则会结合不同的模式,以提升答案质量。如下是一些常见的用于代码领域的 RAG 模式:
-
Query2Doc。对原始 Query 拓展出与用户需求关联度高的改写词, 多个改写词与用户搜索词一起做检索。
-
HyDE(假设性文档)。通过生成虚构文档、代码,并将其转化成向量,来帮助搜索系统在没有相关性标签的情况下找到相关信息。
-
LostInTheMiddle。当相关信息出现在输入上下文的开头或结尾时,性能通常最高,但当模型必须在长上下文的中间访问相关信息时,性能显著下降。
受限于篇幅,我们不会在这里继续展开讨论。
设计与开发内部框架,规模化应用 LLM
随着我们在组织内部构建越来越多的大模型应用,我们会发现:如何规模化应用生成式 AI 应用,会变成我们的下一个挑战。对于这个问题,不同的组织有不同的思路,有的会通过构建大模型平台,并在平台上构建一系列的通用能力,以帮助团队快速构建应用。然而,这种模式只限于大型的 IT 组织,在小型组织中,我们需要构建的是更加轻量级的框架。这个框架应该融入内部的各种基础设施,以提供一些通用的能力。
尽管有一定数量的开发者都已经使用 LangChain 开发过 AIGC 应用,但由于它是一个大型框架,且用的是 Python 语言。对于使用 JVM 语言体系的企业来说,要直接与业务应用集成并非易事。也因此,要么我们围绕 LangChain 构建 API 服务层,要么我们得考虑提供基于 JVM 语言的 SDK。
LLM SDK 在 LLM 参考架构中的位置
在这一点上,Spring 框架的试验式项目 Spring AI 就提供了一个非常好的示例,它参考了 LangChain、LlamaIndex 的一系列思路,并构建了自己的模块化架构 —— 通过 Gradle、Maven 依赖按需引入模块。但对于企业来说,受限于我们的场景、基础设施, 它并不能好地融入我们的应用中。
所以,在我们的软件应用开发场景里构建了自己的 LLM SDK —— Chocolate Factory。它除了提供基本的 LLM 能力封装外,专门针对于研发场景,加入了 自己的一些特性,诸如基于语法分析的代码拆分(split)、Git 提交信息解析、Git 提交历史分析等。
L3:微调与训练大语言模型,深度绑定特定场景
在过去的几个月里,涌现了一系列的开源模型,都加入到游戏中,改变这个游戏的规则。对于多数的组织来说,我们不需要自己构建模型,而是直接使用开源模型即可,所以开发者并不需要掌握模型训练或微调的能力。当然,笔者在这方面的能力也比较有限,但它是开发者非常值得考虑的一个方向。
构建 LLMOps 平台,加速大模型应用落地
LLMOps 平台是一种用于管理大型语言模型(LLM)的应用程序生命周期的平台。它包括了开发、部署、维护和优化 LLM 的一系列工具和最佳实践。LLMOps 平台的目的是让开发者能够高效、可扩展和安全地使用 LLM 来构建和运行实际应用程序,例如聊天机器人、写作助手、编程助手等。—— Bing Chat
与开发大模型应用相比,构建 LLMOps 平台的难度就要稍微大一点。因为,它需要考虑的问题更多,从模型的部署与微调,到模型的监控、管理与协作,再到作为使用者的开发者的体验设计。
从本质来说,LLMOps 所做的事情是加速 LLM 应用的快速落地,所以它需要考虑的问题也更多:
-
快速 PoC(概念验证)。如何快速在平台上构建出 PoC,以验证业务需求可行性?
-
多模型路由。如何统一相同类型的大模型 API,以便于开发者快速接入与测试,诸如 ChatGLM、Baichuan、LLaMA 2 等等。
-
合规管理。如何通过平台避免数据出境等带来的数据安全?确保数据的可审计?
-
快速应用接入。诸如上传内部的文档和资料,就能提供对外 API,以便于开发者快速接入。
在这基础上,对于 LLMOps 平台,一个 AI 2.0 时代的平台,它还需要提供模型训练、微调与优化的能力。以面向不同的业务场景,提供低门槛的模型优化能力。
也因此,对于开发者来说,能加入这样的平台开发,亦是能快速成长起来。
适应特定任务场景下的模型微调
对于包括笔者在内的大多数开发者,想加入训练模型的大军,几乎不可能。因为我们需要大量的数据、计算资源、时间,才能训练出一个好的模型。所以,我们只能在微调模型上下工夫,以提升模型的效果。
在模型微调上,我们可以看到,只需要一个家用 GPU(如 RTX 3090)就能进行微调。考虑到笔者一直用的是 Macbook Pro,所以在进行微调时使用的都是网上的云 GPU。模型微调做的事情是,将预训练的语言模型适应于特定任务或领域。比如在 ChatGPT 提供的 API 中有一个能力是 Function Calling(函数调用),简单来说它能根据用户的输入,输出我们预设的函数调用参数,即识别并格式化输出。所以,我们可以收集 10000+ 相关的数据,并在一个百亿级的模型上进行微调,以使得这个模型能实现相应的功能。
也因此,模型微调的本质是借助高质量数据,快速构建出一个特定任务、场景下的模型。一旦进行了微调,在执行其他任务的能力时,就会变得非常差。所以, 这时需要在平台上结合动态的 LoRA 加载能力(诸如 Stable Diffusion 上相似的能力),以提升更好的灵活力。
而于开发者们而言,就需掌握包括数据收集及清洗、模型微调、模型评估和部署等在内的一系列技能。此外,了解如何使用动态加载和其他模型增强技术也很重要, 以满足不同的需求。
自研企业、行业大模型
基础的开源模型使用的都是公开的语料,缺少特定行业的语料。举个例子,在编程领域,根据 StarCoder 的训练语料(主要基于 GitHub):
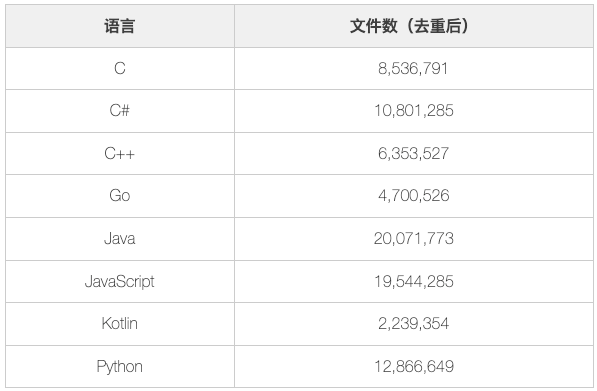
在一些通信行业的大型企业里,他们有大量的相关代码是基于 C 语言的,并且还构建了专有的通信协议,这些代码并不是公开的。所以,这些企业在基于开源语料 + 内部语料情况下,可以构建出更好的模型,基于这些模型的工具可以更好地提升代码的接受率。
所以,对于大型企业而言,这些通用模型并不能满足他们的需求。但如果想自研模型,除了需要大量的公开语料之外,还需要大量的内部语料。由于笔者在这方面的经验有限,所以在这里不会展开讨论。
总结
在大模型时代,开发者面临着巨大的机遇和挑战。生成式 AI(AIGC)正日益改变着软件开发行业的方方面面,从产品研发到代码编写,从测试到维护,甚至到工作任务的安排与协调(LLM as Co-Facilitator)。
作为开发者,我们可以逐步地掌握这些能力:
1. 先学会与大型语言模型(LLM)相处,以提升个人或团队效率。包括了解 LLM 的能力,学会高效使用 Prompt 与 LLM 进行交流,以及活用各类工具。
2. 着眼于开发 LLM 优先应用架构,探索组织规模化落地。这包括了进行各种原型试验,将大模型融入现有产品,构建 Copilot 型应用,以及设计和开发内部框架来规模化应用开发。
3. 深入微调与训练大语言模型,将其深度绑定到特定场景。尽管并不是每个开发者都需要掌握模型训练和微调的能力,但这是一个非常值得考虑的方向。
而其实如果我们放眼来看,国外在大模型结合生物、医药的领域探索也相当的多,也是一个值得我们关注的点。回到国内,我们可以看到国内正在百花齐放,此时不加入 AI 开发大军,更待何时。
作者简介:
黄峰达(Phodal),Thoughtworks 中国区开源负责人、技术专家,CSDN 博客专家,是一个极客和创作者。著有《前端架构:从入门到微前端》《自己动手设计物联网》《全栈应用开发:精益实践》等书。主要专注于 AI + 工程效能,还有架构设计、IDE 和编译器相关的领域。