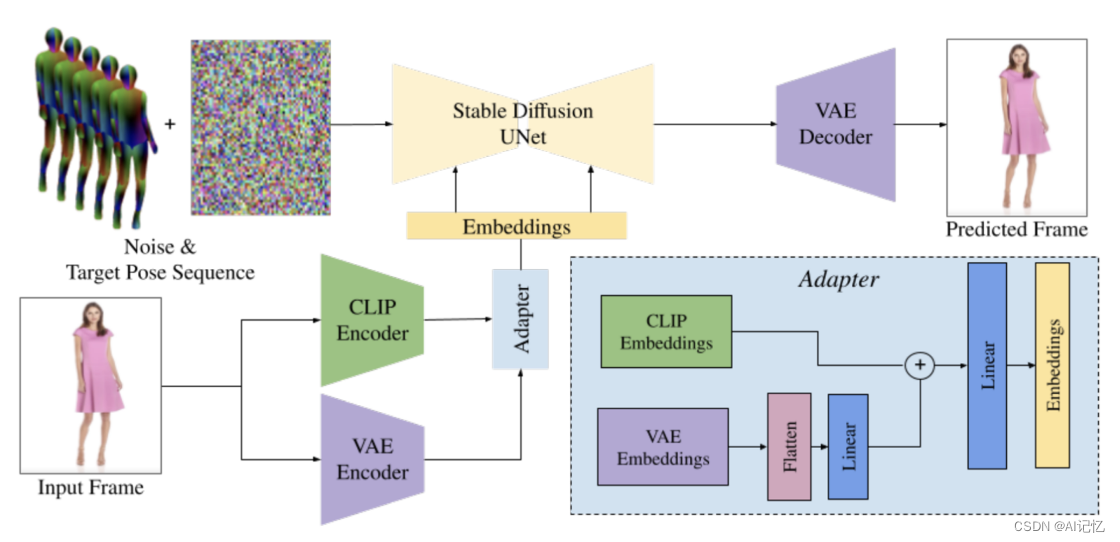
近期,不论是国外的 ChatGPT,还是国内诸多的大模型,让 AIGC 的市场一片爆火。而在 AIGC 的种种智能表现背后,均来自于堪称天文数字的算力支持。以 ChatGPT 为例,据微软高管透露,为 ChatGPT 提供算力支持的 AI 超级计算机,是微软在 2019 年投资 10 亿美元建造一台大型顶尖超级计算机,配备了数万个 NVIDIA A100 GPU,还配备了 60 多个数据中心总共部署了几十万个 NVIDIA GPU 辅助。
相信大家对 GPU 已经不陌生了,它的主要作用是帮助运行训练和部署人工智能算法所涉及的无数计算。而现在市面上繁多的 GPU 型号令人眼花缭乱,我们今天就来看看常见的 V100、A100、A800、H100、H800 这几款 GPU 有什么区别呢?
GPU 的核心架构及参数
在了解 V100、A100、H100 这几款 GPU 的区别之前,我们先来简单了解下 NVIDIA GPU 的核心参数,这样能够更好地帮助我们了解这些 GPU 的差别和各自的优势。
- CUDA Core:CUDA Core 是 NVIDIA GPU上的计算核心单元,用于执行通用的并行计算任务,是最常看到的核心类型。NVIDIA 通常用最小的运算单元表示自己的运算能力,CUDA Core 指的是一个执行基础运算的处理元件,我们所说的 CUDA Core 数量,通常对应的是 FP32 计算单元的数量。
- Tensor Core:Tensor Core 是 NVIDIA Volta 架构及其后续架构(如Ampere架构)中引入的一种特殊计算单元。它们专门用于深度学习任务中的张量计算,如矩阵乘法和卷积运算。Tensor Core 核心特别大,通常与深度学习框架(如 TensorFlow 和 PyTorch)相结合使用,它可以把整个矩阵都载入寄存器中批量运算,实现十几倍的效率提升。
- RT Core:RT Core 是 NVIDIA 的专用硬件单元,主要用于加速光线追踪计算。正常数据中心级的 GPU 核心是没有 RT Core 的,主要是消费级显卡才为光线追踪运算添加了 RTCores。RT Core 主要用于游戏开发、电影制作和虚拟现实等需要实时渲染的领域。
在了解了 GPU 的这些核心参数之后,我们再来看看 NVIDIA GPU 架构的演进。
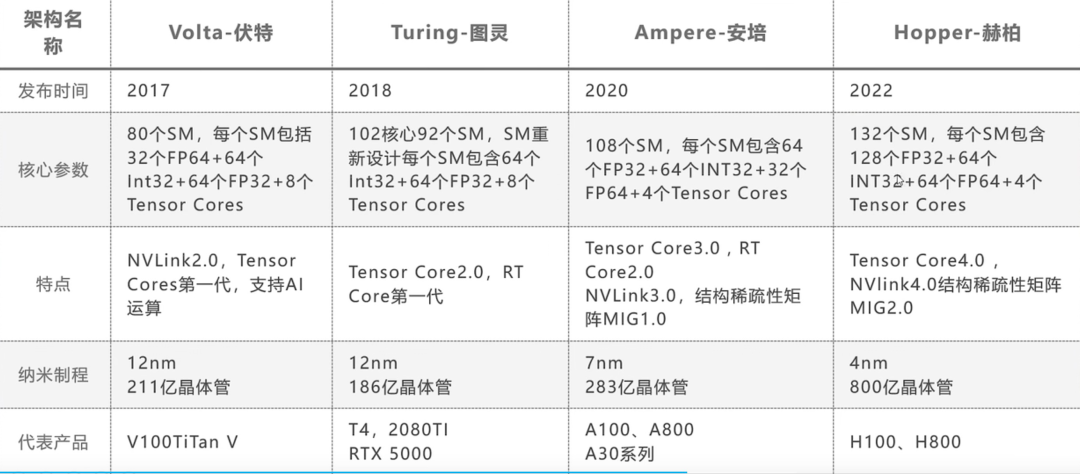
从上图中就可以看出,V100 是前一代的“卡皇”,而 H100 则是新一代的“卡皇”。我们先简单了解下这些架构:
- Volta 架构:Volta 架构是 NVIDIA GPU 的第六代架构,发布于 2017 年。Volta 架构专注于深度学习和人工智能应用,并引入了 Tensor Core。
- Turing 架构:Turing 架构是 NVIDIA GPU 的第七代架构,发布于 2018 年。Turing 架构引入了实时光线追踪(RTX)和深度学习超采样(DLSS)等重要功能。
- Ampere 架构:Ampere 架构是 NVIDIA GPU 的第八代架构,2020 年发布。Ampere 架构在计算能力、能效和深度学习性能方面都有重大提升。Ampere 架构的 GPU 采用了多个流多处理器(SM)和更大的总线宽度,提供了更多的 CUDA Core 和更高的频率。它还引入了第三代 Tensor Core,提供更强大的深度学习计算性能。Ampere 架构的 GPU 还具有更高的内存容量和带宽,适用于大规模的数据处理和机器学习任务。
- Hopper 架构:Hopper 架构是 NVIDIA GPU 的第九代架构,2022 年发布。相较于 Ampere,Hopper 架构支持第四代 Tensor Core,且采用新型流式处理器,每个 SM 能力更强。Hopper 架构在计算能力、深度学习加速和图形功能方面带来新的创新和改进。
V100 vs A100 vs H100
在了解了 GPU 的核心参数和架构后,我们接下来的对比理解起来就简单多了。
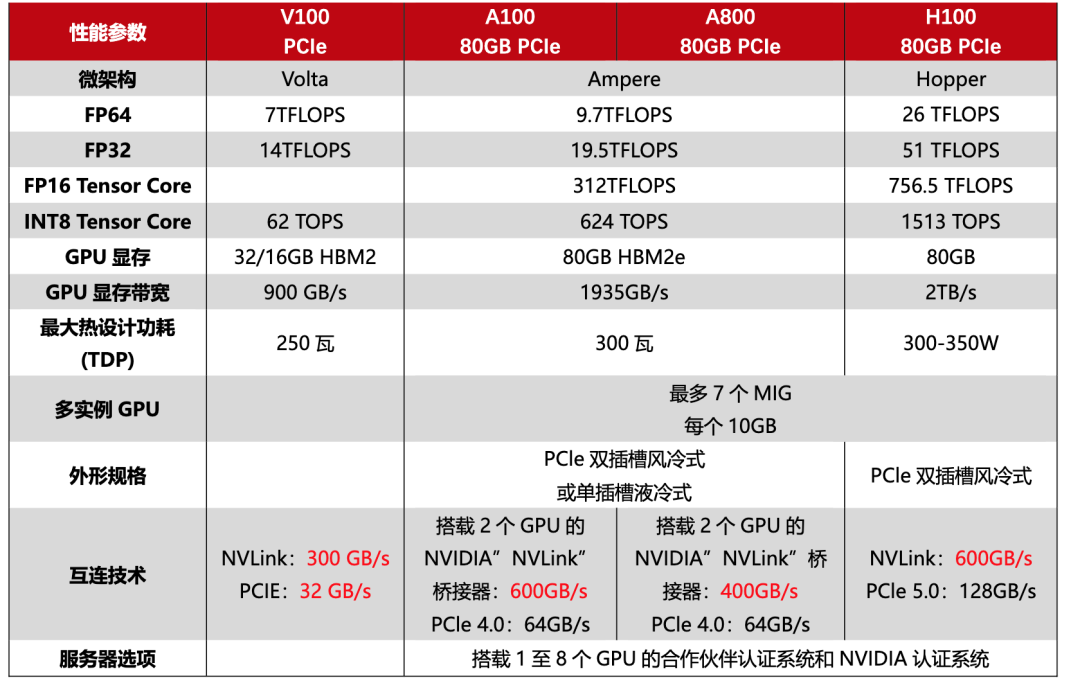
△ 图片来源于互联网,侵删
V100 vs A100
V100 是 NVIDIA 公司推出的高性能计算和人工智能加速器,属于 Volta 架构,它采用 12nm FinFET 工艺,拥有 5120 个 CUDA 核心和 16GB-32GB 的 HBM2 显存,配备第一代 Tensor Cores技术,支持 AI 运算。
A100 采用全新的 Ampere 架构。它拥有高达 6912 个 CUDA 核心和 40GB 的高速 HBM2 显存。A100 还支持第二代NVLink技术,实现快速的 GPU 到 GPU 通信,提升大型模型的训练速度。A100 增加了功能强大的新第三代 Tensor Core,同时增加了对 DL 和 HPC 数据类型的全面支持,以及新的稀疏功能,可将吞吐量进一步翻倍。
A100 中的 TF32 Tensor Core 运算提供了一种在 DL 框架和 HPC 中加速 FP32 输入/输出数据的简单路径,其运行速度比 V100 FP32 FMA 运算快 10 倍,或者在稀疏性的情况下快 20 倍。对于 FP 16/FP 32 混合精度 DL,A100 的性能是 V100 的2.5倍,稀疏性的情况下提高到 5 倍。
在跑 AI 模型时,如果用 PyTorch 框架,相比上一代 V100 芯片,A100 在 BERT 模型的训练上性能提升 6 倍,BERT 推断时性能提升 7 倍。
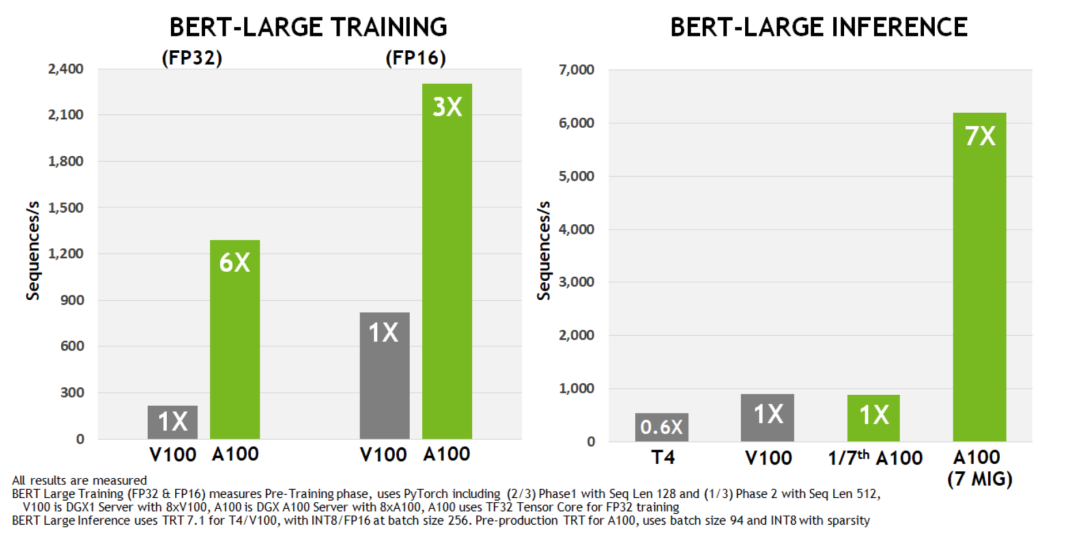
△ BERT 训练和推理上,V100 与 A100 的性能对比
A100 vs H100
NVIDIA H100 采用 NVIDIA Hopper GPU 架构,使 NVIDIA 数据中心平台的加速计算性能再次实现了重大飞跃。H100 采用专为 NVIDIA 定制的 TSMC 4N 工艺制造,拥有 800 亿个 晶体管,并包含多项架构改进。

H100 是 NVIDIA 的第 9 代数据中心 GPU,旨在为大规模 AI 和 HPC 实现相比于上一代 NVIDIA A100 Tensor Core GPU 数量级的性能飞跃。H100 延续了 A100 的主要设计重点,可提升 AI 和 HPC 工作负载的强大扩展能力,并显著提升架构效率。
新的 SM 架构
H100 SM 基于 NVIDIA A100 Tensor Core GPU SM 架构而构建。由于引入了 FP8,与 A100 相比,H100 SM 将每 SM 浮点计算能力峰值提升了 4 倍,并且对于之前所有的 Tensor Core 和 FP32 / FP64 数据类型,将各个时钟频率下的原始 SM 计算能力增加了一倍。
与上一代 A100 相比,采用 Hopper 的 FP8 Tensor Core 的新 Transformer 引擎使大型语言模型的 AI 训练速度提升 9 倍,AI 推理速度提升 30 倍。针对用于基因组学和蛋白质测序的 Smith-Waterman 算法,Hopper 的新 DPX 指令可将其处理速度提升 7 倍。
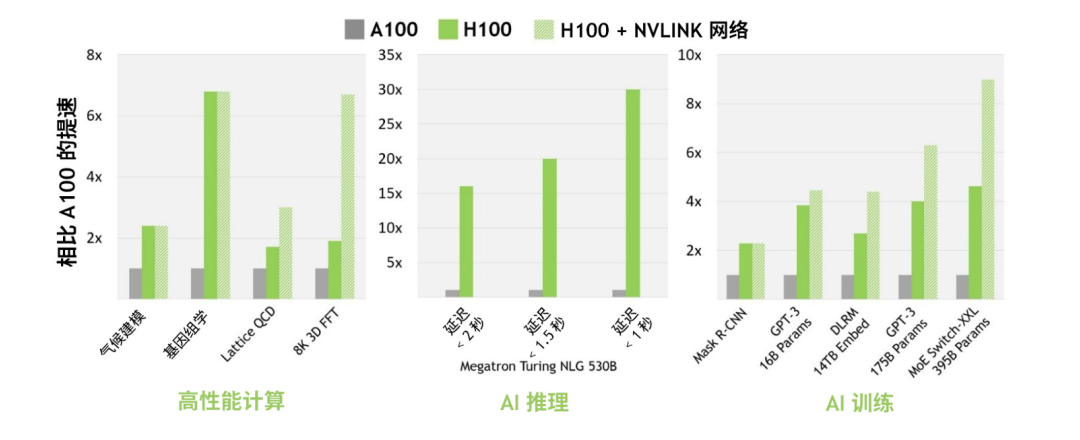
第四代 Tensor Core 架构
Hopper 新的第四代 Tensor Core、Tensor 内存加速器以及许多其他新 SM 和 H100 架构的总体改进,在许多其他情况下可令 HPC 和 AI 性能获得最高 3 倍的提升。
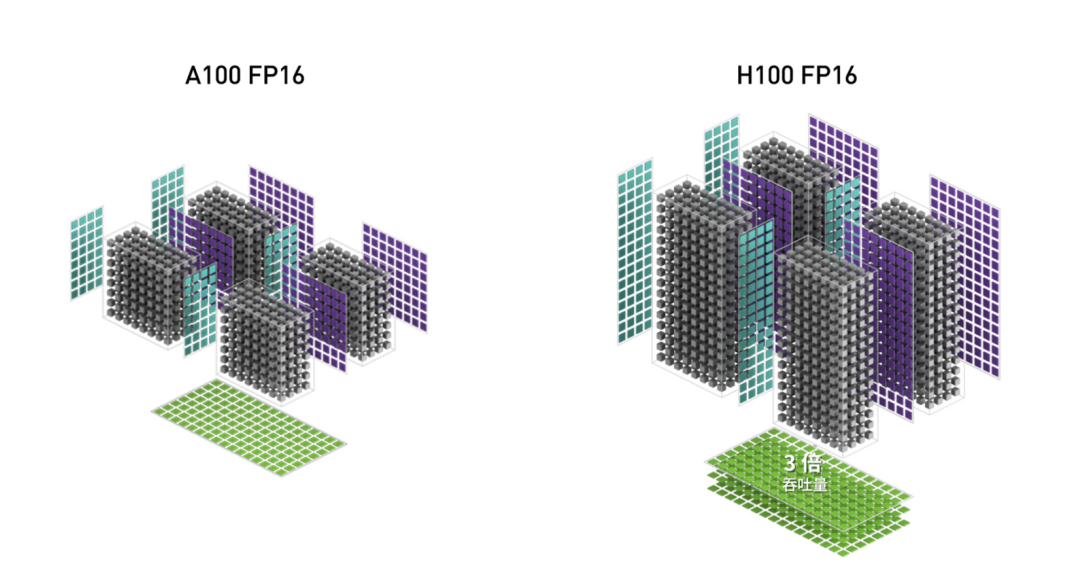
△ H100 FP16 的吞吐量是 A100 FP16 的 3 倍
与 A100 相比,H100 中新的第四代 Tensor Core 架构可使每时钟每个 SM 的原始密集计算和稀疏矩阵运算吞吐量提升一倍,考虑到 H100 比 A100 拥有更高的 GPU 加速频率,其甚至会达到更高的吞吐量。其支持 FP8、FP16、BF16、TF32、FP64 和 INT8 MMA 数据类型。新的 Tensor Core 还能够实现更高效的数据管理,最高可节省 30% 的操作数传输功耗。
Hopper FP8 数据格式
H100 GPU 增加了 FP8 Tensor Core,可加速 AI 训练和推理。FP8 Tensor Core 支持 FP32 和 FP16 累加器,以及两种新的 FP8 输入类型:E4M3(具有 4 个指数位、3 个尾数位和 1 个符号位)和E5M2(具有 5 个指数位、2 个尾数位和 1 个符号位)。E4M3 支持动态范围更小、精度更高的计算,而 E5M2 可提供更宽广的动态范围和更低的精度。与 FP16 或 BF16 相比,FP8 可将所需要的数据存储空间减半,并将吞吐量提升一倍。
新的 Transformer 引擎可结合使用 FP8 和 FP16 精度,减少内存使用并提高性能,同时仍能保持大型语言模型和其他模型的准确性。
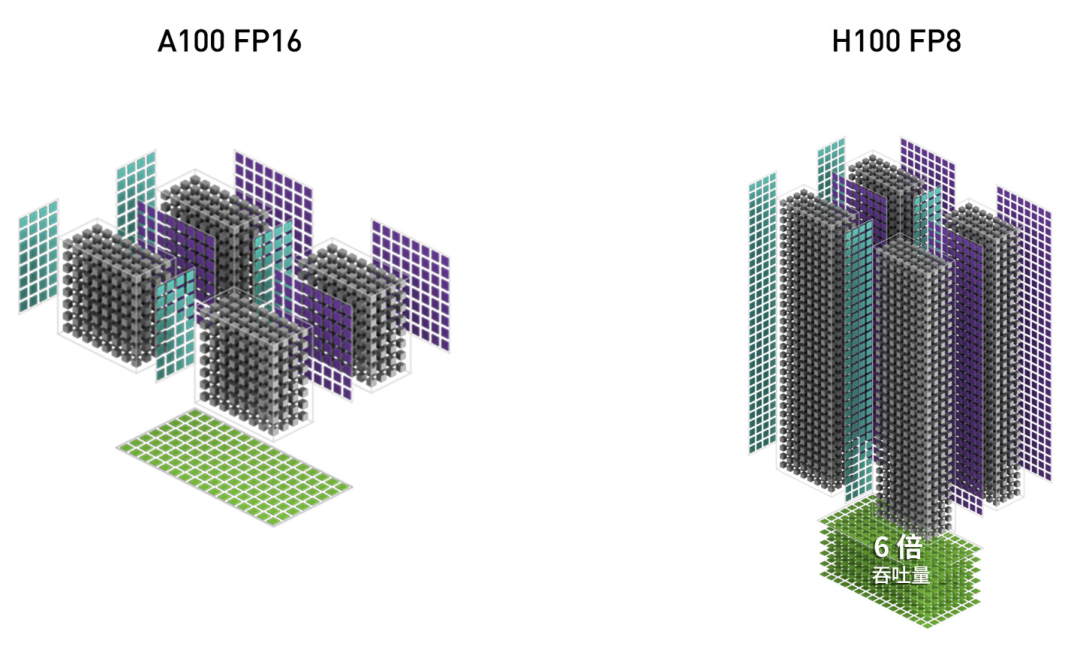
△ H100 FP8 的吞吐量是 A100 FP16 的 6 倍
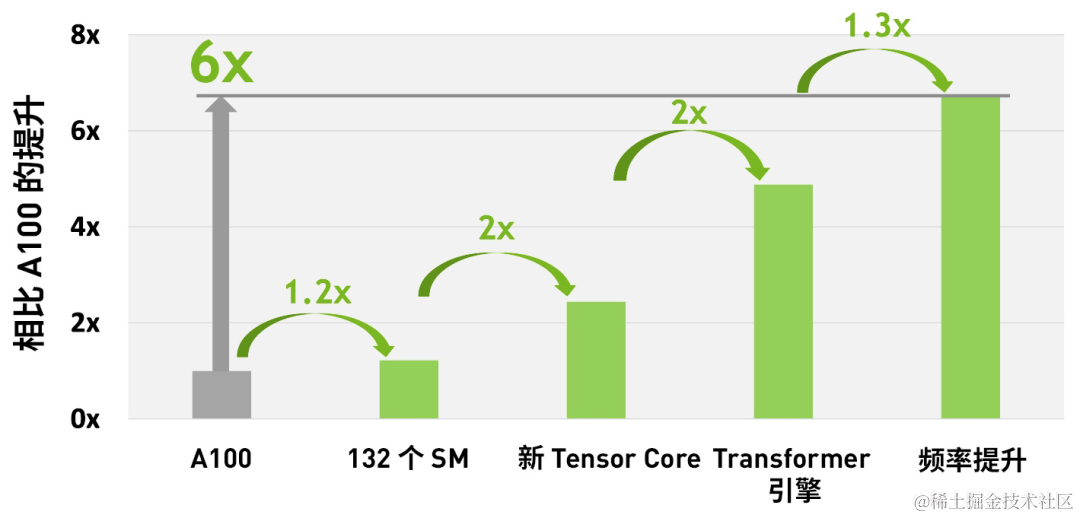
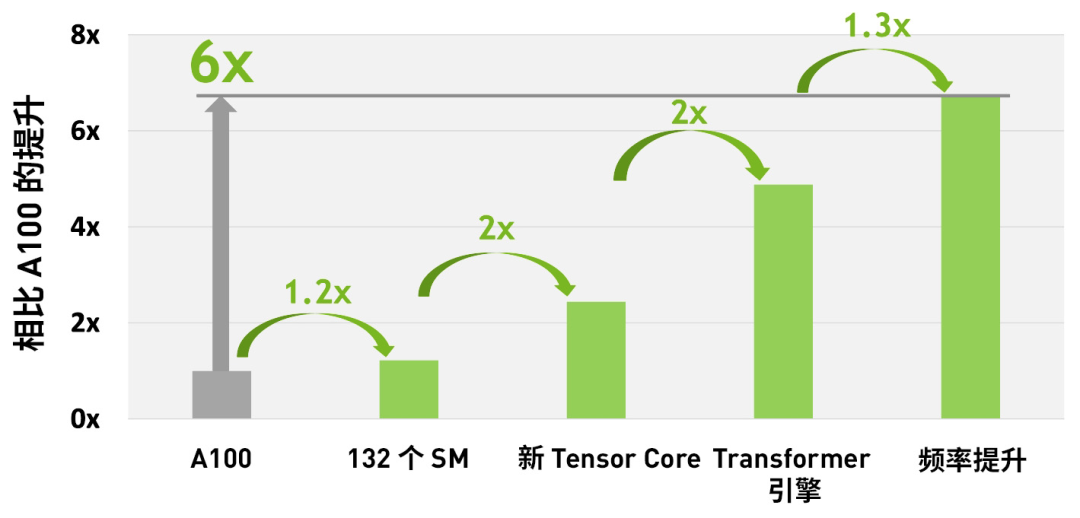
综合 H100 中所有新的计算技术进步的因素,H100 的计算性能比 A100 提高了约 6 倍。首先是 H100 配备 132 个 SM,比 A100 的 108 个 SM 增加了 22%。由于采用新的第四代 Tensor Core,每个 H100 SM 的速度都提升了 2 倍。在每个 Tensor Core 中,新的 FP8 格式和相应的 Transformer 引擎又将性能提升了 2 倍。最后,H100 中更高的时钟频率将性能再提升了约 1.3 倍。通过这些改进,总体而言,H100 的峰值计算吞吐量大约为 A100 的 6 倍。
A800 和 H800
说好 V100、A100、A800、H100、H800 这些 GPU 来做对比的,怎么没见 A800 和 H800 呢?从型号上看,莫非它们的性能是 A100、H800 的好几倍?
事实不然。虽然从数字上来看,800 比 100 数字要大,其实是为了合规对 A100 和 H100 的某些参数做了调整。A800 相对比 A100 而言,仅限制了 GPU 之间的互联带宽,从 A100 的 600GB/s 降至 400GB/s,算力参数无变化。而 H800 则对算力和互联带宽都进行了调整。
△ 图片来源于互联网,侵删
A800 虽然在互联带宽上有所降低,但和 A100 在双精方面算力一致,在高性能科学计算领域没有影响。
相信聊了这么多,大家对 NVIDIA 这么多款 GPU 有了一定了解。




![[C++随笔录] AVL树](https://img-blog.csdnimg.cn/bbb04436ce0d4ae080e9662d68e99674.png)