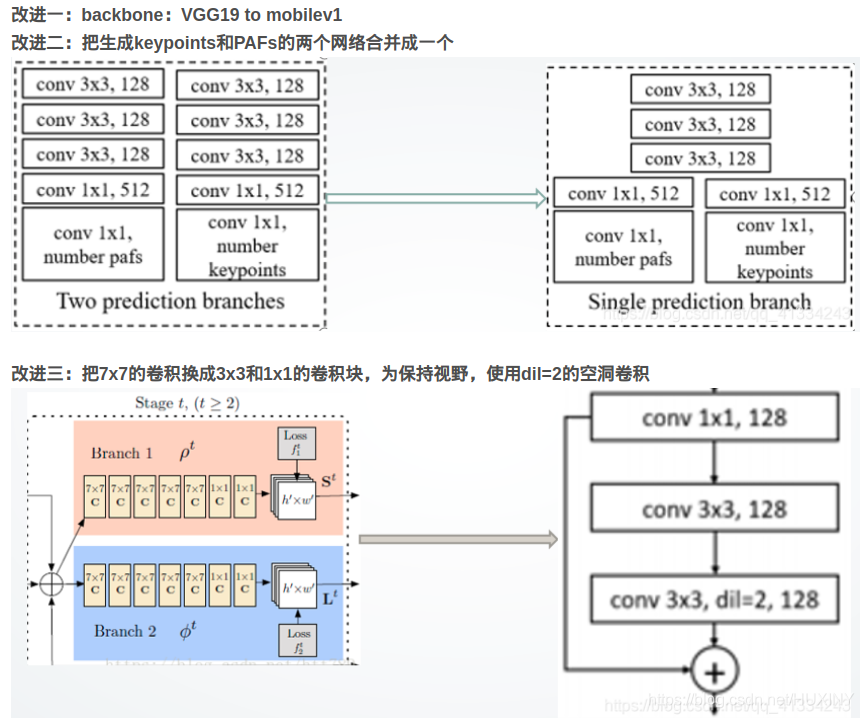
大家好,我是python222小锋老师。
近日锋哥又卷了一波Python实战课程-批量爬取美女图片网下载图片,主要是巩固下Python爬虫基础
视频版教程:
Python爬虫实战-批量爬取美女图片网下载图片 视频教程_哔哩哔哩_bilibiliPython爬虫实战-批量爬取美女图片网下载图片 视频教程作者:小锋老师官网:www.python222.com本课程旨在让大家在网站Python爬虫的基础上,实战巩固Python爬虫技术后期会继续推出进阶,高级课程,敬请期待。, 视频播放量 354、弹幕量 1、点赞数 20、投硬币枚数 8、收藏人数 21、转发人数 5, 视频作者 java1234官方, 作者简介 公众号:java1234 微信:java9266,相关视频:Python爬虫实战-批量爬取下载网易云音乐,爬虫学得好!牢饭吃到饱...全网最全爬虫JS逆向案例!企业级爬虫逆向实战(逆向各种加密、参数、验证码、滑块、算法)建议立刻收藏!,2024 一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium 【无废话版】,Gateway微服务网关视频教程(无废话版),Nacos视频教程(无废话版),打造前后端分离 权限系统 基于SpringBoot2+SpringSecurity+Vue3.2+Element Plus 视频教程 (火爆连载更新中..),2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中...,微信小程序(java后端无废话版)视频教程,Java8 Lambda表达式视频教程(无废话版),Docker快速手上视频教程(无废话版)![]() https://www.bilibili.com/video/BV1ue411X7JU/
https://www.bilibili.com/video/BV1ue411X7JU/

爬虫目标网站:
https://pic.netbian.com/4kmeinv/经过分析,第二页,第二页的规律是:

https://pic.netbian.com/4kmeinv/index_N.html复杂问题简单化:先爬取首页,然后再进行多页爬虫代码的实现。
通过开发者工具分析

img的路径是 ul.clearfix li a img
爬虫三步骤,
1,根据请求url地址获取网页源码,用requests库
2,通过bs4解析源码获取需要的数据
3,通过数据处理我们的资源,我们这里是通过图片路径下载到本地
所以我们实现首页图片下载的源码参考如下:具体代码分析,可以学习下帖子开头的视频教程
"""
爬取目标:https://pic.netbian.com/ 彼岸图网
首页地址:
https://pic.netbian.com/4kmeinv/
第N页
https://pic.netbian.com/4kmeinv/index_N.html
https://pic.netbian.com/uploads/allimg/231101/012250-16987729706d69.jpg
作者:小锋老师
官网:www.python222.com
"""
import os.path
import requests
from bs4 import BeautifulSoup
url = "https://pic.netbian.com/4kmeinv/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
}
# 请求网页
response = requests.get(url=url, headers=headers)
response.encoding = "gbk"
# print(response.text)
# 实例化soup
soup = BeautifulSoup(response.text, "lxml")
# 获取所有图片
img_list = soup.select("ul.clearfix li a img")
print(img_list)
def download_img(src):
"""
下载图片
:param src: 图片路径
:return:
"""
# 获取图片名称
filename = os.path.basename(src)
print(filename)
# 下载图片
try:
with open(f"./img/{filename}", "wb") as file:
file.write(requests.get("https://pic.netbian.com" + src).content)
except:
print(src, "下载异常")
for img in img_list:
print(img["src"])
download_img(img["src"])
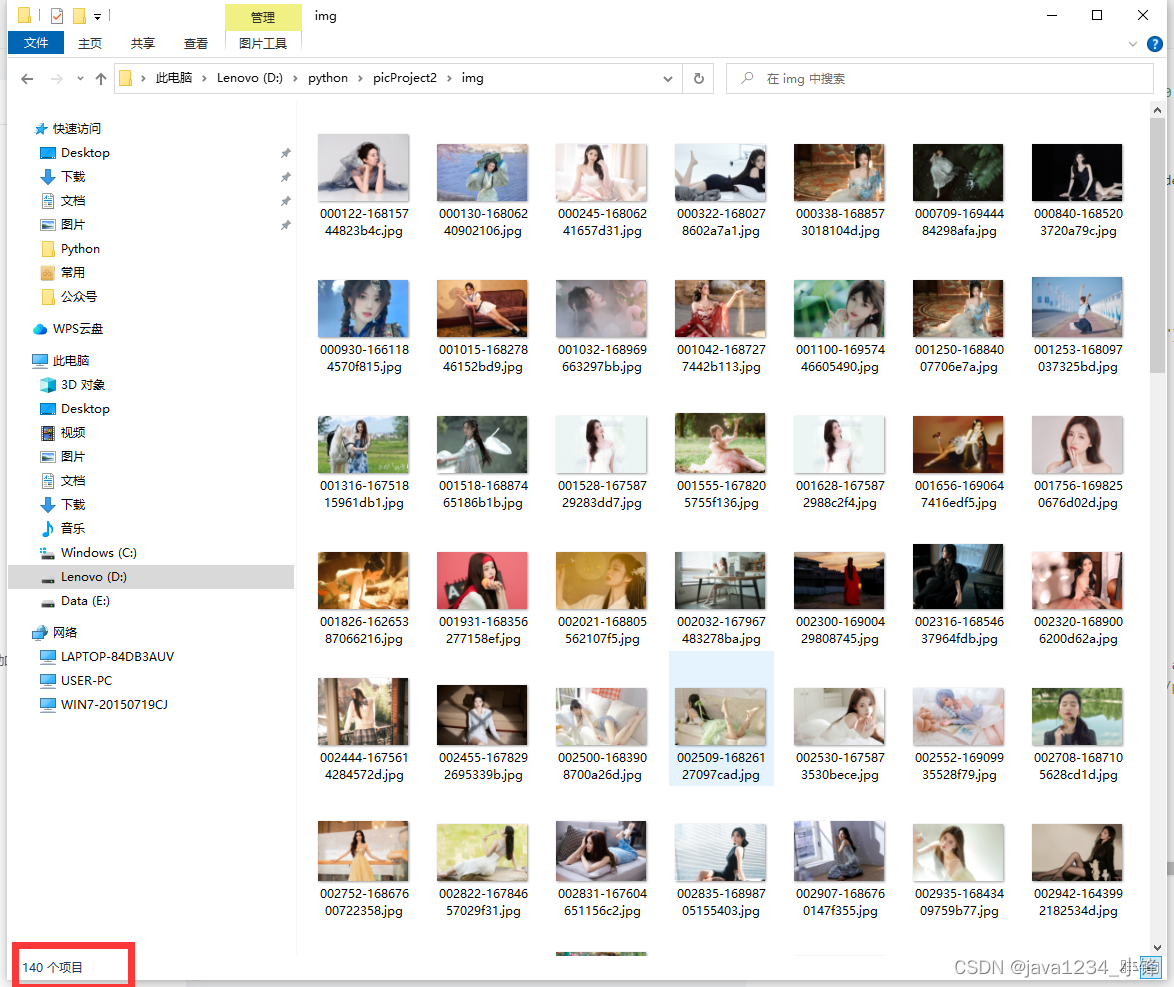
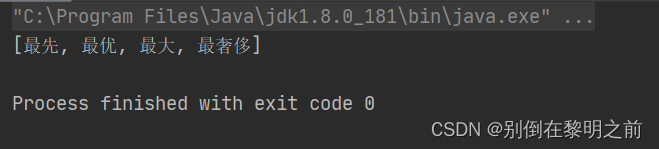
运行代码,一页数据20个。

实现多页的下载的话,我们肯定需要通过遍历所有url,然后实现批次下载;那么对于抓取网页,和解析网页,我们需要进行封装,那才方便调用。
def crawl_html(url):
"""
解析网页
:param url: 请求地址
:return: 解析后的网页源码
"""
# 请求网页
response = requests.get(url=url, headers=headers)
response.encoding = "gbk"
return response.textdef parse_html(html):
# 实例化soup
soup = BeautifulSoup(html, "lxml")
# 获取所有图片
img_list = soup.select("ul.clearfix li a img")
print(img_list)
for img in img_list:
print(img["src"])
download_img(img["src"])完整源码参考:具体代码分析,可以学习下帖子开头的视频教程
"""
爬取目标:https://pic.netbian.com/ 彼岸图网
首页地址:
https://pic.netbian.com/4kmeinv/
第N页
https://pic.netbian.com/4kmeinv/index_N.html
https://pic.netbian.com/uploads/allimg/231101/012250-16987729706d69.jpg
作者:小锋老师
官网:www.python222.com
"""
import os.path
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
}
def crawl_html(url):
"""
解析网页
:param url: 请求地址
:return: 解析后的网页源码
"""
# 请求网页
response = requests.get(url=url, headers=headers)
response.encoding = "gbk"
return response.text
def download_img(src):
"""
下载图片
:param src: 图片路径
:return:
"""
# 获取图片名称
filename = os.path.basename(src)
print(filename)
# 下载图片
try:
with open(f"./img/{filename}", "wb") as file:
file.write(requests.get("https://pic.netbian.com" + src).content)
except:
print(src, "下载异常")
def parse_html(html):
# 实例化soup
soup = BeautifulSoup(html, "lxml")
# 获取所有图片
img_list = soup.select("ul.clearfix li a img")
print(img_list)
for img in img_list:
print(img["src"])
download_img(img["src"])
# # 第一页
# url = "https://pic.netbian.com/4kmeinv/"
# parse_html(crawl_html(url))
# # 第二页到第七页
# for i in range(2, 8):
# parse_html(crawl_html(f"https://pic.netbian.com/4kmeinv/index_{i}.html"))
urls = ["https://pic.netbian.com/4kmeinv/"] + [
f"https://pic.netbian.com/4kmeinv/index_{i}.html"
for i in range(2, 8)
]
print(urls)
for url in urls:
parse_html(crawl_html(url))
运行下载,正好7页的图片,140个。