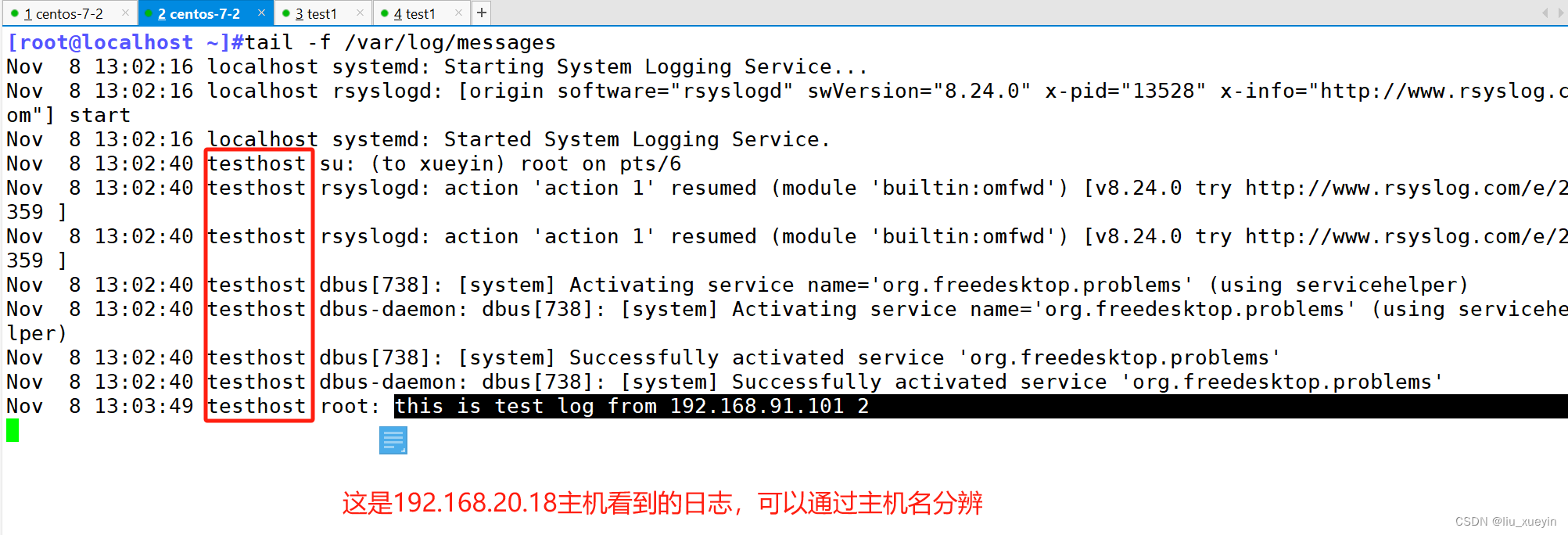
1、pd.read_csv ()
读取csv文件
import pandas as pd
df = pd.read_csv('Popular_Baby_Names.csv')
df = pd.read_csv('Popular_Baby_Names.csv', sep=';', header=0, index_col=0, skiprows=5, na_values='N/A')##读取CSV文件data.csv,使用;作为分隔符,第一行作为标题,第一列作为索引,跳过前5行,将N/ a替换为NaN2、df.describe ()
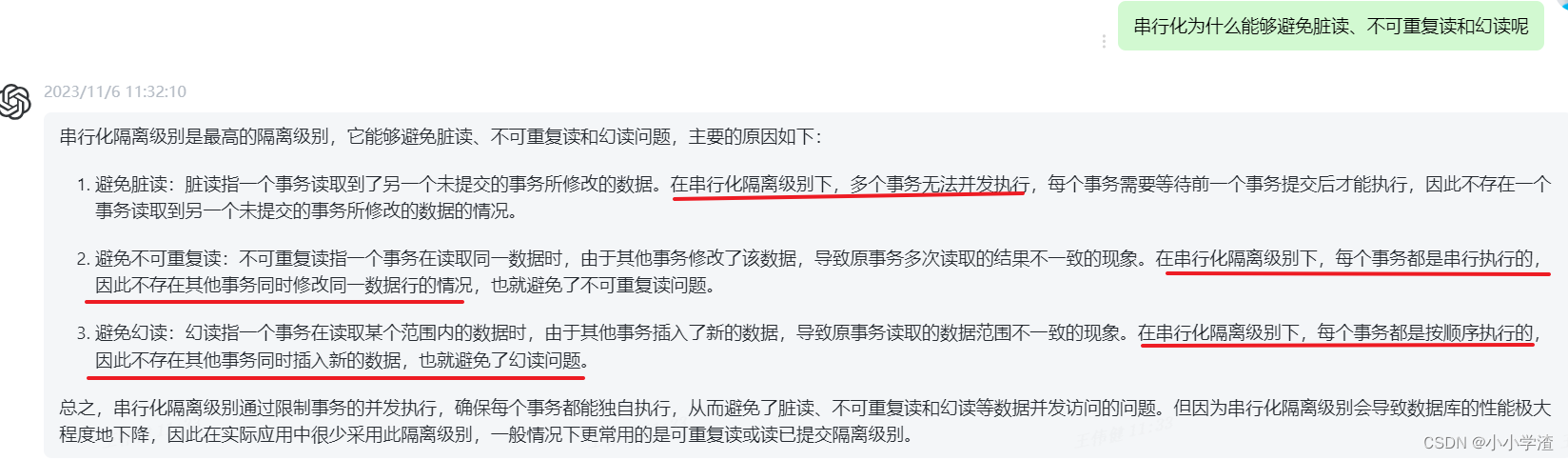
df.describe()方法用于生成DataFrame的各种特征的汇总统计信息。它返回一个新的DataFrame,其中包含原始DataFrame中每个数值列的计数、平均值、标准差、最小值、第25百分位、中位数、第75百分位和最大值。
df.describe()
df.describe(include='all') # include all columns
df.describe(exclude='number') # exclude numerical columns3、df.info ()
df.info()可以获得DataFrame的简明摘要,包括每列中非空值的数量、每列的数据类型以及DataFrame的内存使用情况。
df.info()4、df.iloc ()
iloc()函数用于根据索引选择行和列
df.iloc[起始行:最终行, 起始列:最终列]5、df.loc ()
loc()函数用于根据DataFrame中基于标签的索引选择行和列。它用于根据基于标签的位置选择行和列
df.loc[:, ['Year of Birth', 'Gender']]####选取'Year of Birth', 'Gender'列6、df.assign ()
.assign()函数用于根据现有列的计算向DataFrame添加新列。它允许您在不修改原始数据的情况下添加新列。该函数会返回一个添加了列的新DataFrame。
df_new = df.assign(count_plus_5=df['Count'] + 5)####df.assign()被用来创建一个名为'count_plus_5'的,值为count列的值 + 5的新列。7、df.query ()
.query()函数可以根据布尔表达式过滤数据。可以使用类似于SQL的查询字符串从DataFrame中选择行。该函数返回一个新的DataFrame,其中只包含满足布尔表达式的行。
df_query = df.query('Count > 30 and Rank < 20')
df_query = df.query("Gender == 'MALE'")8、df.sort_values ()
.sort_values()函数可以按一列或多列对数据进行排序。它根据一个或多个列的值按升序或对DataFrame进行排序。该函数返回一个按指定列排序的新DataFrame。
df.sort_values(by='##',axis=0,ascending=True, inplace=False, na_position='last')by:指定列名(axis=0或’index’)或索引值(axis=1或’columns’)
axis:若axis=0或’index’,则按照指定列中数据大小排序;若axis=1或’columns’,则按照指定索引中数据大小排序,默认axis=0
ascending:是否按指定列的数组升序排列,默认为True,即升序排列
Inplace:是否用排序后的数据集替换原来的数据,默认为False,即不替换
na_position {‘first’,‘last’}:设定缺失值的显示位置
9、df.sample ()
.sample()函数可以从数据帧中随机选择行。它返回一个包含随机选择的行的新DataFrame。该函数采用几个参数,可以控制采样过程。
df.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)n:这是一个可选参数, 由整数值组成, 并定义生成的随机行数。
frac:它也是一个可选参数, 由浮点值组成, 并返回浮点值*数据帧值的长度。不能与参数n一起使用。
replace:由布尔值组成。如果为true, 则返回带有替换的样本。替换的默认值为false。
权重:它也是一个可选参数, 由类似于str或ndarray的参数组成。默认值”无”将导致相等的概率加权。
如果正在通过系列赛;它将与索引上的目标对象对齐。在采样对象中找不到的权重索引值将被忽略, 而在采样对象中没有权重的索引值将被分配零权重。
如果在轴= 0时正在传递DataFrame, 则返回0。它将接受列的名称。
如果权重是系列;然后, 权重必须与被采样轴的长度相同。
如果权重不等于1;它将被标准化为1的总和。
权重列中的缺失值被视为零。
权重栏中不允许无穷大。
random_state:它也是一个可选参数, 由整数或numpy.random.RandomState组成。如果值为int, 则为随机数生成器或numpy RandomState对象设置种子。
axis:它也是由整数或字符串值组成的可选参数。 0或”行”和1或”列”。
10、df.isnull ()
isnull()方法返回一个与原始DataFrame形状相同的DataFrame,通过True或False值,指示原始DataFrame中的每个值是否缺失。缺失的值NaN或None,在结果的DataFrame中将为True,而非缺失的值将为False。
df.isnull()11、df.fillna ()
fillna()方法用于用指定的值或方法填充DataFrame中的缺失值。默认情况下,它用NaN替换缺失的值,也可以指定一个不同的值来代替
df.fillna(value = None,method = None,axis = None,inplace = False,limit = None,downcast = None)参数:
values: dict, Series, or DataFrame,用于替换空值的值,该值不能是list,如果指定某列,则会是字典的形式
method:{‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None,填充方法(向下填充,还是向上,和replace的用法一致)
axis:{0 or ‘index’, 1 or ‘columns’},填充的方向
inplace:bool, default False,if True means 修改原文件
limit:int, default None,限制填充个数
downcast:dict, default is None
12、df.dropna ()
df.dropna()可以从DataFrame中删除缺失值或空值。它从DataFrame中删除至少缺失一个元素的行或列。可以通过调用df.dropna()删除包含至少一个缺失值的所有行。
df.dropna(axis=0, how='any', thresh=None, subset=["列名1","列名2"], inplace=False)axis=0或axis='index’删除含有缺失值的行,
axis=1或axis='columns’删除含有缺失值的列,
how='all’时表示删除全是缺失值的行(列)
how='any’时表示删除只要含有缺失值的行(列)
thresh=n表示保留至少含有n个非na数值的行
subset定义要在哪些列中查找缺失值
inplace表示直接在原DataFrame修改
13、df.drop ()
df.drop()可以通过指定的标签从DataFrame中删除行或列。它可以用于删除一个或多个基于标签的行或列。
你可以通过调用df.drop()来删除特定的行,并传递想要删除的行的索引标签,并将axis参数设置为0(默认为0)。
df_drop = df.drop(0) ###删除DataFrame的第一行。
df_drop = df.drop([0,1]) ####删除DataFrame的第一行和第二行过传递想要删除的列的标签并将axis参数设置为1来删除列:
df_drop = df.drop(['Count', 'Rank'], axis=1) ###删除列Count和Rank14、df.groupby ()
df.groupby()用于根据一个或多个列对DataFrame的行进行分组。并且可以对组执行聚合操作,例如计算每个组中值的平均值、和或计数。
df.groupby()返回一个GroupBy对象,然后可以使用该对象对组执行各种操作,例如计算每个组中值的和、平均值或计数。
grouped = df.groupby('Gender')
print(grouped.mean()) ####打印平均值
print(grouped.sum()) ####打印和15、df.transpose ()
df.transpose()用于转置DataFrame的行和列,这意味着行变成列,列变成行。
也可以使用df上的T属性来实现。df.T和df.transpose()是一样的。
df_transposed = df.transpose() ###转换行列
df_transposed = df.T ###转换行列16、df.merge()
pandas的merge方法是基于共同列,将两个dataframe连接起来。merge方法的主要参数:how,on
df3 = pd.merge(df1,df2,how='inner',on='alpha')# 基于共同列alpha的内连接
df5 = pd.merge(df1,df2,how='outer',on='alpha')# 基于共同列alpha的外连接
df5 = pd.merge(df1,df2,how='left',on='alpha')# 基于共同列alpha的左连接
df6 = pd.merge(df1,df2,how='right',on='alpha')# 基于共同列alpha的右连接
df7 = pd.merge(df1,df2,on=['alpha','beta'],how='inner')# 基于共同列alpha和beta的内连接
df8 = pd.merge(df1,df2,on=['alpha','beta'],how='right')# 基于共同列alpha和beta的右连接
df9 = pd.merge(df1,df2,how='inner',left_on='beta',right_index=True)# 基于df1的beta列和df2的index连接设置参数suffixes以修改除连接列外相同列的后缀名。
df9 = pd.merge(df1,df2,how='inner',left_on='beta',right_index=True,suffixes=('_df1','_df2'))# 基于df1的alpha列和df2的index内连接17、 df.join()
join方法是基于index连接dataframe,merge方法是基于column连接,连接方法有内连接,外连接,左连接和右连接,与merge一致。
df1 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'], 'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
df2 = pd.DataFrame({'key': ['K0', 'K1', 'K2'],'B': ['B0', 'B1', 'B2']})
df3 = df1.join(df2,lsuffix='_caller', rsuffix='_other',how='inner') # lsuffix和rsuffix设置连接的后缀名
df3 = df1.set_index('key').join(df2.set_index('key'),how='inner') # 基于key列进行连接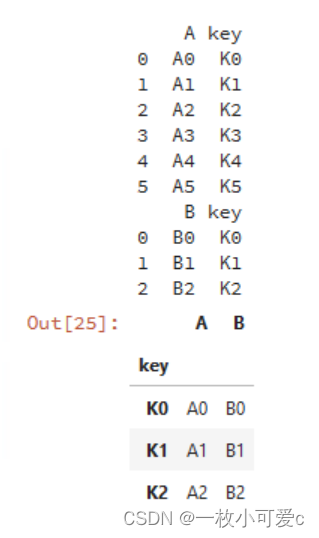
18、concat()
concat方法是拼接函数,有行拼接和列拼接,默认是行拼接,拼接方法默认是外拼接(并集),拼接的对象是pandas数据类型。
(1)、series类型的拼接方法
df1 = pd.Series([1.1,2.2,3.3],index=['i1','i2','i3'])
df2 = pd.Series([4.4,5.5,6.6],index=['i2','i3','i4'])
df3 = pd.concat([df1,df2]) # 行拼接
行拼接若有相同的索引,为了区分索引,我们在最外层定义了索引的分组情况。
pd.concat([df1,df2],keys=['fea1','fea2']) # 对行拼接分组
列拼接
默认以并集的方式拼接:
pd.concat([df1,df2],axis=1) # 列拼接,默认是并集以交集的方式拼接:
pd.concat([df1,df2],axis=1,join='inner') # 列拼接的内连接(交)
对指定的索引拼接:
pd.concat([df1,df2],axis=1,join_axes=[['i1','i2','i3']]) # 指定索引[i1,i2,i3]的列拼接
(2)、 dataframe类型的拼接方法
行拼接
df1 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3', 'K4', 'K5'],
'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']})
df2 = pd.DataFrame({'key': ['K0', 'K1', 'K2'],
'B': ['B0', 'B1', 'B2']})
df3 = pd.concat([df1,df2]) # 行拼接
pd.concat([df1,df2],axis=1) # 列拼接
19、df.rename ()
df.rename()可以更改DataFrame中一个或多个列或行的名称。可以使用columns参数更改列名,使用index参数更改行名。
df_rename = df.rename(columns={'Count': 'count', 'Rank':'rank'}) ##将Count列名改为count,Rank列名改为rank
df_rename = df.rename(index={0:'first',1:'second',2:'third'})###将第1列列名改为first,第2列改为second,第3列改为third20、df.to_csv ()
df.to_csv()可以将DataFrame导出到CSV文件。与上面的Read_csv作为对应。调用df.to_csv()将DataFrame导出到CSV文件:
df.to_csv('data.csv')可以通过传递sep参数来指定CSV文件中使用的分隔符。默认情况下,它被设置为“,”。
df.to_csv('path/to/data.csv', sep='\t')也可以通过将列名列表传递给columns参数来只保存DataFrame的特定列,通过将布尔掩码传递给索引参数来只保存特定的行。
df.to_csv('path/to/data.csv', columns=['Rank','Count'])还可以使用index参数指定在导出的CSV文件中包含或不包含dataframe的索引。
df.to_csv('path/to/data.csv', index=False)使用na_rep参数将导出的CSV文件中缺失的值替换为指定的值。
df.to_csv('path/to/data.csv', na_rep='NULL')