文章目录
- 前言
- 一、XA 模式
- 1.1 XA 模式原理
- 1.2 XA 模式的优缺点及应用场景
- 1.3 Seata XA 模式在微服务中的实现
- 二、AT 模式
- 2.1 Seata AT 模式原理
- 2.2 AT 模式的脏写问题和写隔离
- 3.3 AT 模式的优缺点
- 3.4 Seata AT 模式在微服务中的实现
- 三、TCC 模式
- 3.1 TCC 模式原理
- 3.2 Seata 的 TCC 模型
- 3.3 TCC 模型事务悬挂和空回滚
- 3.4 TCC 模式的实现
- 四、SAGA 模式
- 4.1 SAGA 模式原理
- 4.2 SAGA 模式的优缺点
前言
分布式事务是在分布式系统中保持数据一致性的关键问题之一。Seata(Simple Extensible Autonomous Transaction Architecture)是一款开源的分布式事务解决方案,它提供了四种不同的事务模式,分别是XA、AT、TCC、SAGA。本文将深入探讨这四种分布式事务解决方案的原理、优缺点以及应用场景,以帮助开发人员更好地选择适合其项目的分布式事务模式。
一、XA 模式
1.1 XA 模式原理
XA 规范 是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,XA 规范描述了全局的 TM 与局部的 RM 之间的接口,几乎所有主流的数据库都对 XA 规范提供了支持。
XA 模式的事务管理可以分为两个阶段:
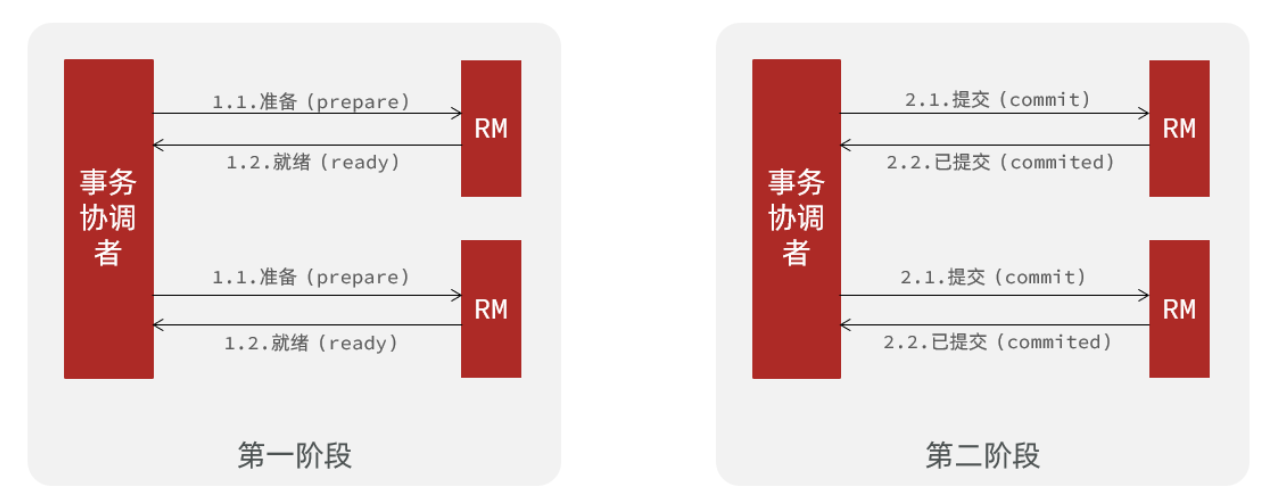
正常情况,即所有分支事务都执行成功,需要提交:
-
第一阶段: 事务协调者(TM)通知局部资源管理器(RM)准备执行业务操作。所有分支事务执行成功,RM 告知 TM 自己已经就绪准备提交事务。
-
第二阶段: TM 通知所有 RM 提交事务,即所有分支事务的更改被持久化,当所有的分支事务提交成功后告知 TM 自己已提交。
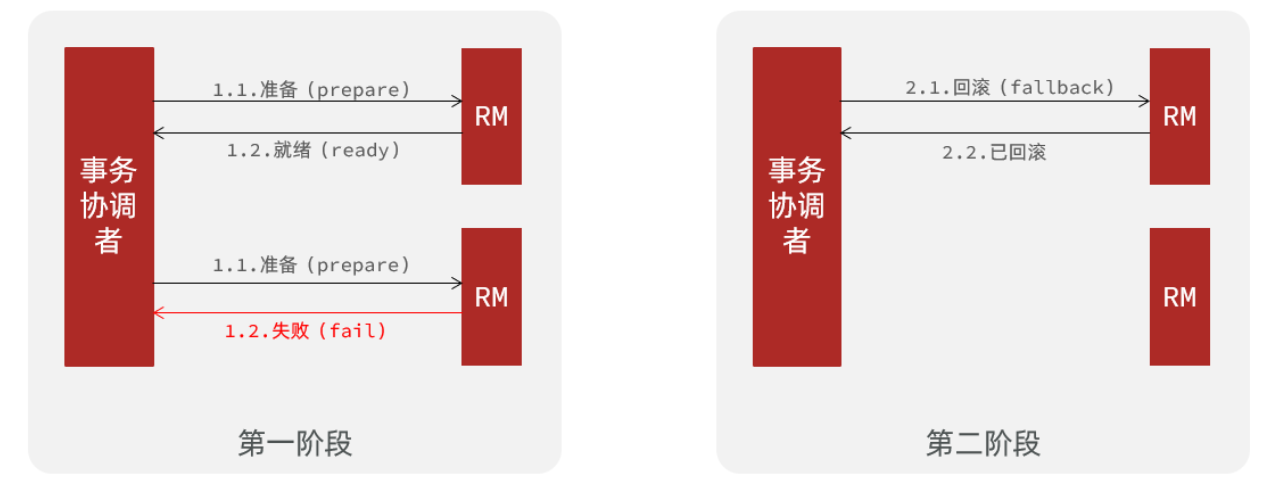
异常情况,即存在分支事务执行失败,需要回滚:
-
第一阶段: 事务协调者(TM)通知局部资源管理器(RM)准备执行业务操作,存在分支事务执行失败,就向 TM 返回自己执行失败。
-
第二阶段: 如果存在分支事务执行失败,TM 通知所有执行成功并处于就绪状态的 RM 回滚事务,即所有分支事务的更改被撤销。
Seata 的 XA 模式
Seata 对原始的 XA 模式做了简单的封装和改造,以适应自己的事务模型,基本架构如图如下:
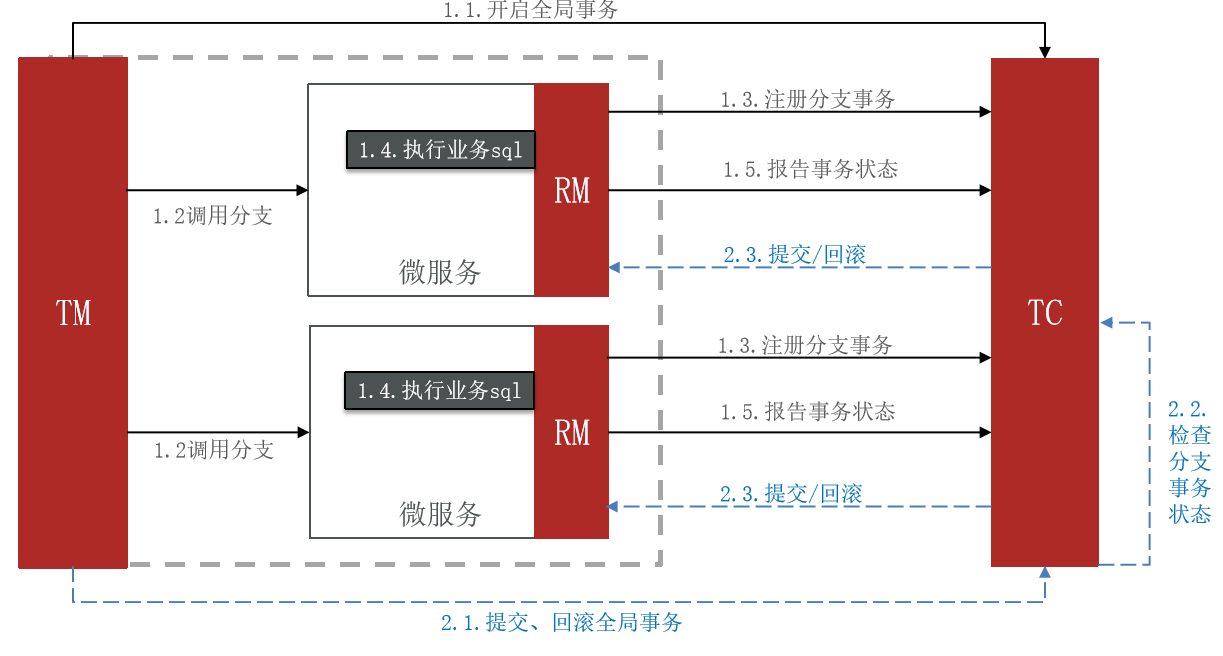
Seata 的 XA 模式与传统的 XA 模式相似,在实际工作流程中进行了一些调整。以下是 Seata XA 模式的工作原理说明:
-
RM 一阶段的工作:
- RM 将分支事务注册到全局事务协调器(TC)。
- RM 执行分支业务操作,但不提交。这确保了分支事务不会立即生效,等待全局协调后再决定是否提交。
- RM 报告分支事务执行状态给 TC。
-
TC 二阶段的工作:
- TC 检测各个分支事务的执行状态。
- 如果所有分支事务都成功,TC通知所有RM提交事务,即提交所有分支事务的更改。
- 如果有任何分支事务失败,TC通知所有RM回滚事务,即回滚所有分支事务的更改
-
RM二阶段的工作:
- RM 接收来自TC的指令,根据指令来提交或回滚分支事务。
Seata 的 XA 模式通过全局事务协调器(TC)确保分布式事务的一致性,它与传统 XA 模式的主要区别在于 Seata 对分支事务的执行进行了微调,以便更好地适应分布式事务管理的需求。这种模式允许应用在分布式环境中实现事务管理,确保数据的一致性。
1.2 XA 模式的优缺点及应用场景
优点:
-
强一致性: XA 模式保证了数据的强一致性,即要么所有事务都提交成功,要么都回滚失败。这对于需要高度一致性的应用非常重要,如金融系统或在线支付。
-
广泛支持: XA 模式是一种经典的分布式事务处理标准,几乎所有主流的数据库都支持 XA 规范,因此可以在不同的数据库和消息队列之间进行事务协调。
缺点:
-
性能开销: 由于涉及到两个阶段的协调,XA 模式通常性能开销较大。在第一阶段,需要等待所有分支事务执行完毕并报告状态,而在第二阶段,需要等待所有分支事务的提交或回滚完成。这导致了较长的事务执行时间。
-
单点问题: XA 模式中需要一个全局的事务协调器(Transaction Coordinator),这可能成为系统的单点故障。如果事务协调器发生故障,整个系统的可用性将受到影响。
-
资源锁定: 在第一阶段,分支事务执行后需要等待全局事务协调器的指令,这可能导致资源锁定时间较长,影响并发性能。
-
复杂性: 实现 XA 模式的分布式事务处理需要复杂的编程和配置,开发和维护成本较高。
应用场景:
XA 模式适用于对数据强一致性要求较高的场景,其中数据的一致性比性能更为重要。一些典型的应用场景包括:
- 金融系统:在金融交易中,数据的一致性至关重要,因此需要使用 XA 模式来确保所有相关操作的一致性。
- 在线支付:在线支付系统必须确保交易的一致性,以避免出现重复扣款或未扣款的情况。
- 订单处理系统:在订单处理系统中,需要确保订单的创建、支付、发货等操作都能够保持一致性,以避免出现订单漏发或重复发货的问题。
总之,XA 模式适用于那些对数据一致性要求非常高且可以承受一定性能开销的分布式应用场景。
1.3 Seata XA 模式在微服务中的实现
这里我以前文的 seata-cloud-demo 为例,来演示 Seata 分布式事务不同的解决方案,首先是 XA 模式:
由于 Seata 的 starter 已经完成了 XA 模式的自动装配,实现就变得非常简单了,步骤如下:
-
修改
application.yml文件(每个参与事务的微服务),开启 XA 模式:seata: data-source-proxy-mode: XA # 开启数据源代理的 XA 模式 -
给发起全局事务的入口方法添加
@GlobalTransactional注解,在上面创建订单的整个微服务中,全局事务的入口就是创建订单的业务逻辑的create方法:
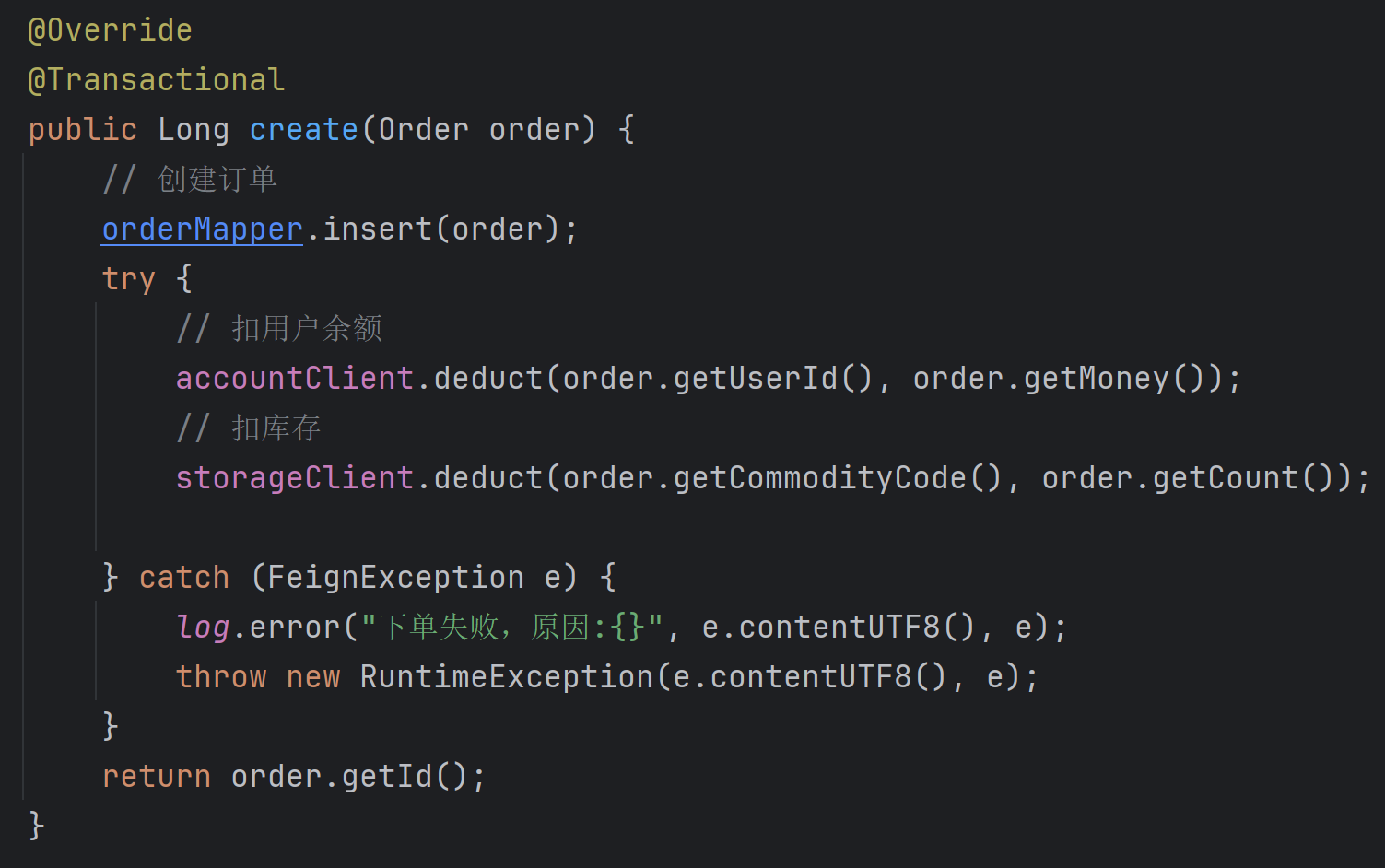
这里将@Transactional注解改成@GlobalTransactional即可:

-
当完成上面所有的配置之后,就可以启动所有的微服务,然后使用 Postman 进行测试了:
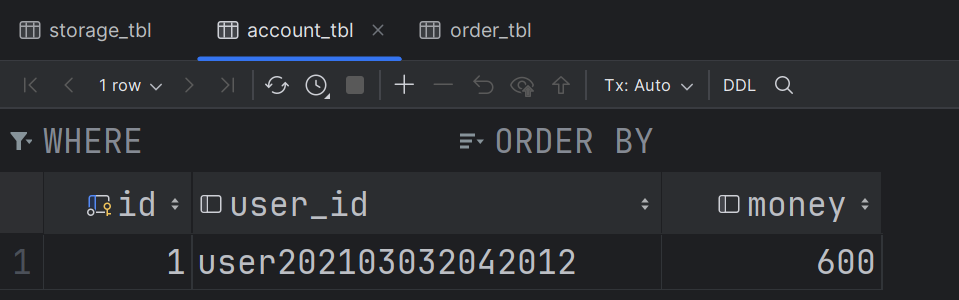
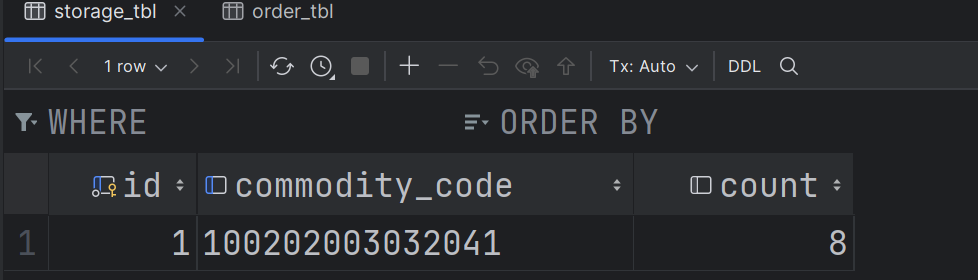
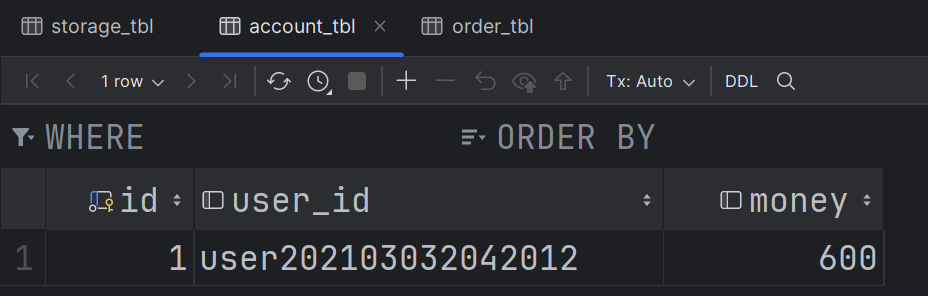
- 现在账户表和库存表的数据如下:
- 直接演示创建订单失败的情况:
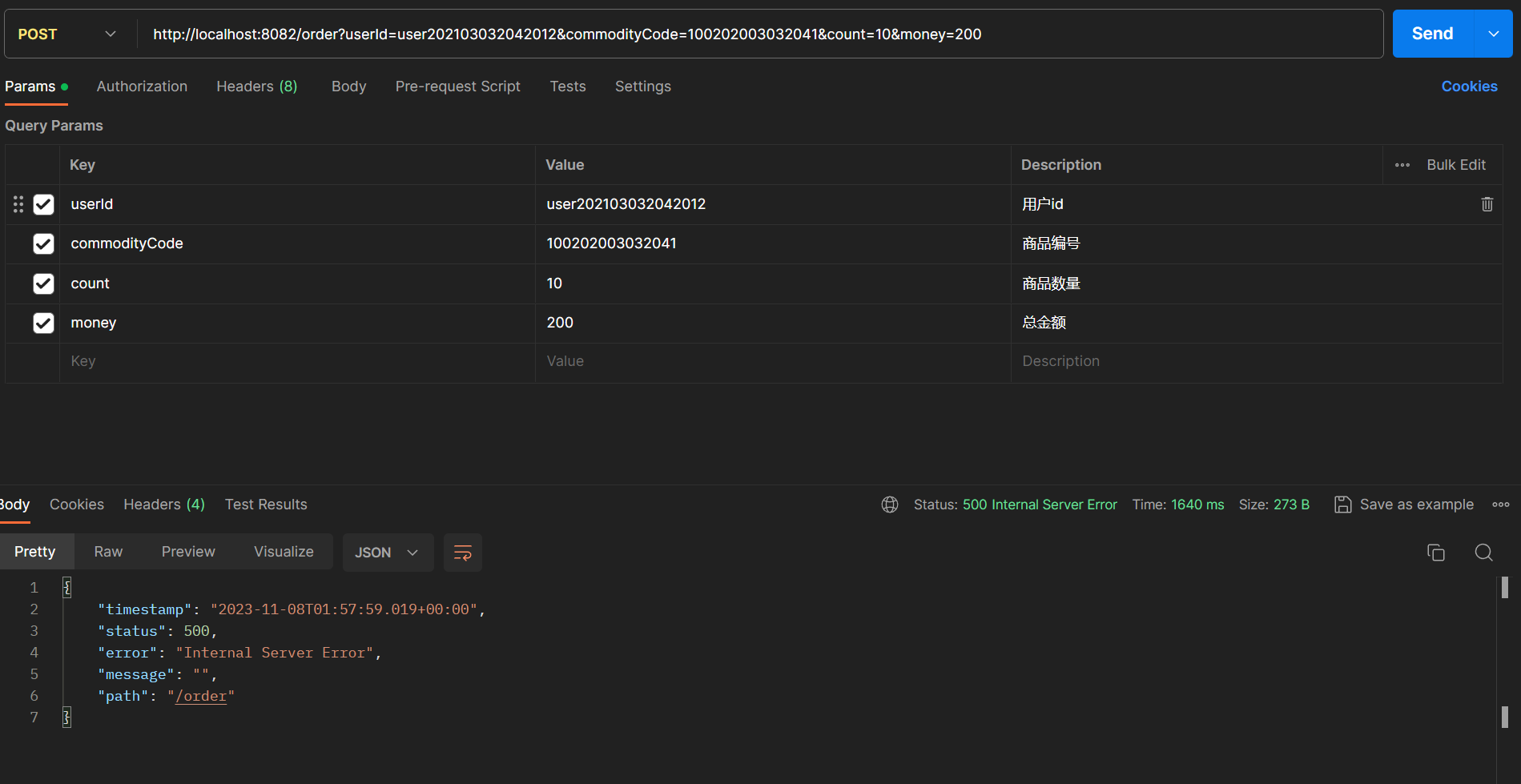
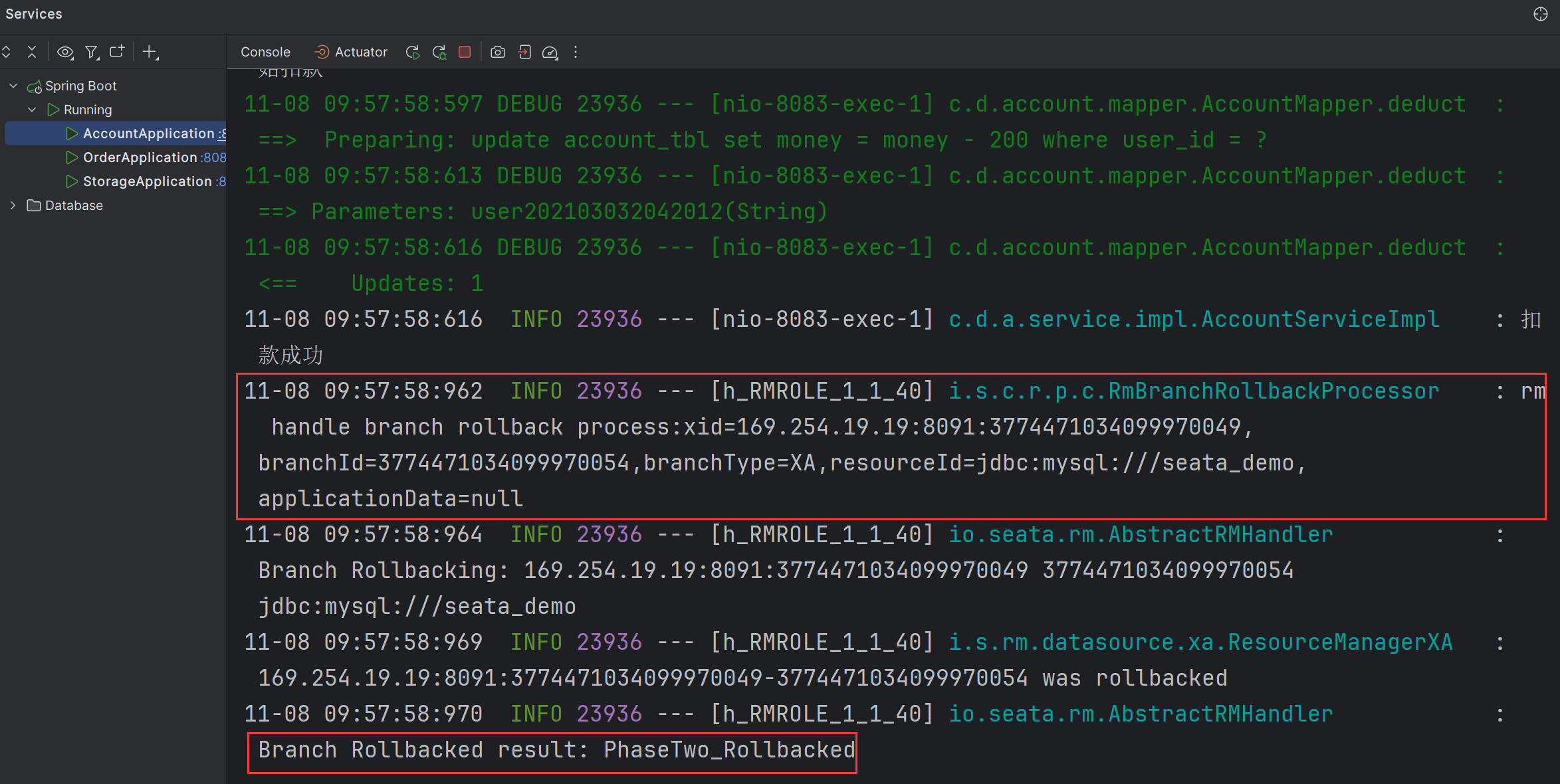
- 此时由于库存不足,创建订单失败了,在前文中因为没有实现分布式事务,因此账户服务在执行成功之后没有进行回滚,而现在实现了分布式事务,则就不应该再扣款了:
通过account-service服务的日志来看,也是先执行成功了,最后因为库存服务执行失败,进行了回滚操作:
- 现在账户表和库存表的数据如下:
二、AT 模式
AT 模式同样是分阶段提交的事务模式,不过弥补了 XA 模型中因为锁对资源而导致的周期过长问题:
2.1 Seata AT 模式原理
AT模式(Auto Transaction)是一种自动事务模式,它试图通过自动提交和回滚来实现分布式事务的一致性。与 XA 模式不同,AT 模式一阶段直接提交事务,不会锁定资源,AT 模式下数据的回滚依赖于数据库的 undo log。
在 Seata 的 AT 模式中,事务管理的架构图如下:
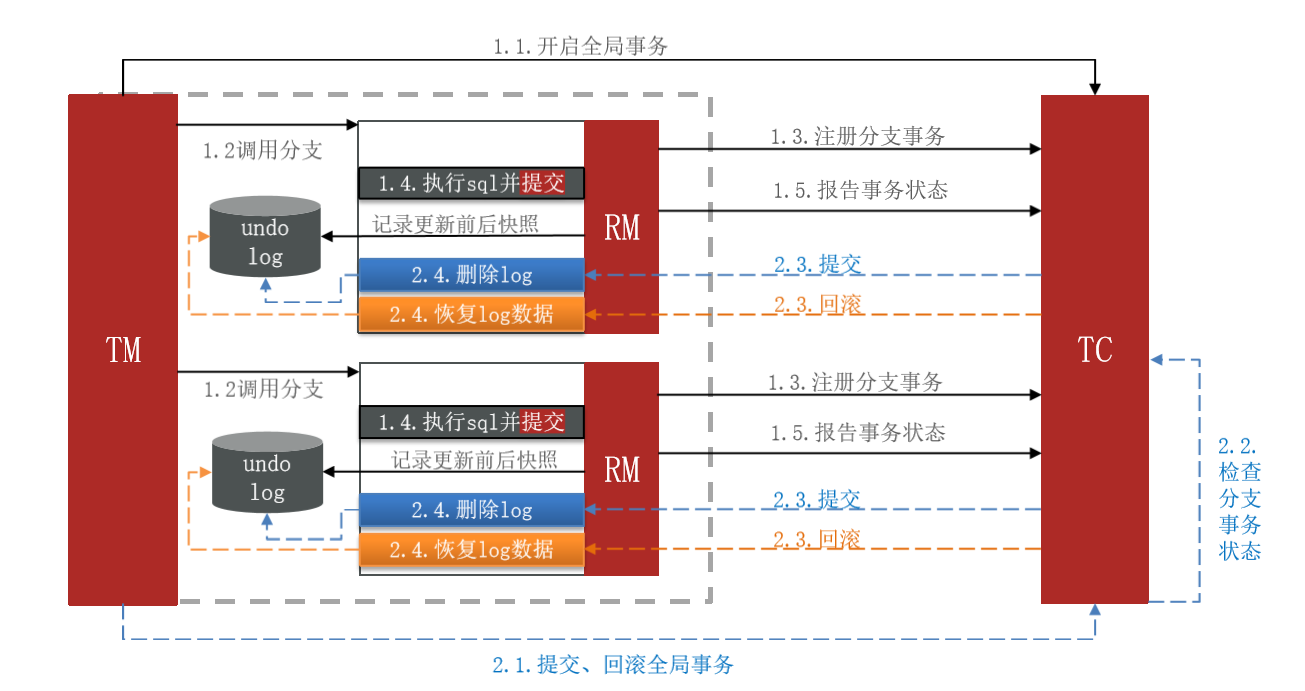
Seata AT 模式的事务管理流程:
-
阶段一 RM 的工作:
- 注册分支事务:当一个分支事务开始时,它会在本地数据库中注册自己。
- 记录
undo-log(数据快照):在分支事务执行业务SQL之前,记录当前数据的快照,以便在回滚时恢复数据。 - 执行业务SQL并提交:分支事务执行业务SQL并自动提交本地事务。这是AT模式的特点,不涉及两阶段提交。
- 报告事务状态:RM报告分支事务的执行状态给TC(Transaction Coordinator)。
-
阶段二提交时 RM 的工作:
- 在提交时,RM只需删除相应的
undo-log,因为分支事务已经自动提交,不需要额外的提交操作。
- 在提交时,RM只需删除相应的
-
阶段二回滚时 RM 的工作:
- 在回滚时,RM根据之前记录的
undo-log来恢复数据到更新前的状态。
- 在回滚时,RM根据之前记录的
Seata 的 AT 模式依赖于数据库的本地事务管理能力,每个分支事务在本地自动管理自己的事务。如果分支事务成功提交,那么全局事务也会提交;如果分支事务出现失败,全局事务将会回滚,确保数据的一致性。
总的来说,Seata 的 AT 模式通过自动提交和回滚分支事务,减少了全局事务协调的复杂性,同时提供了高性能的分布式事务管理方式。这种模式适用于那些可以容忍一定程度数据不一致的应用场景,特别是对性能要求较高的应用。
例如,现在用一个真实的业务来梳理下 AT 模式的原理。
比如,现在又一个数据库表,记录用户余额:
| id | money |
|---|---|
| 1 | 100 |
其中一个分支业务要执行的SQL为:
update tb_account set money = money - 10 where id = 1
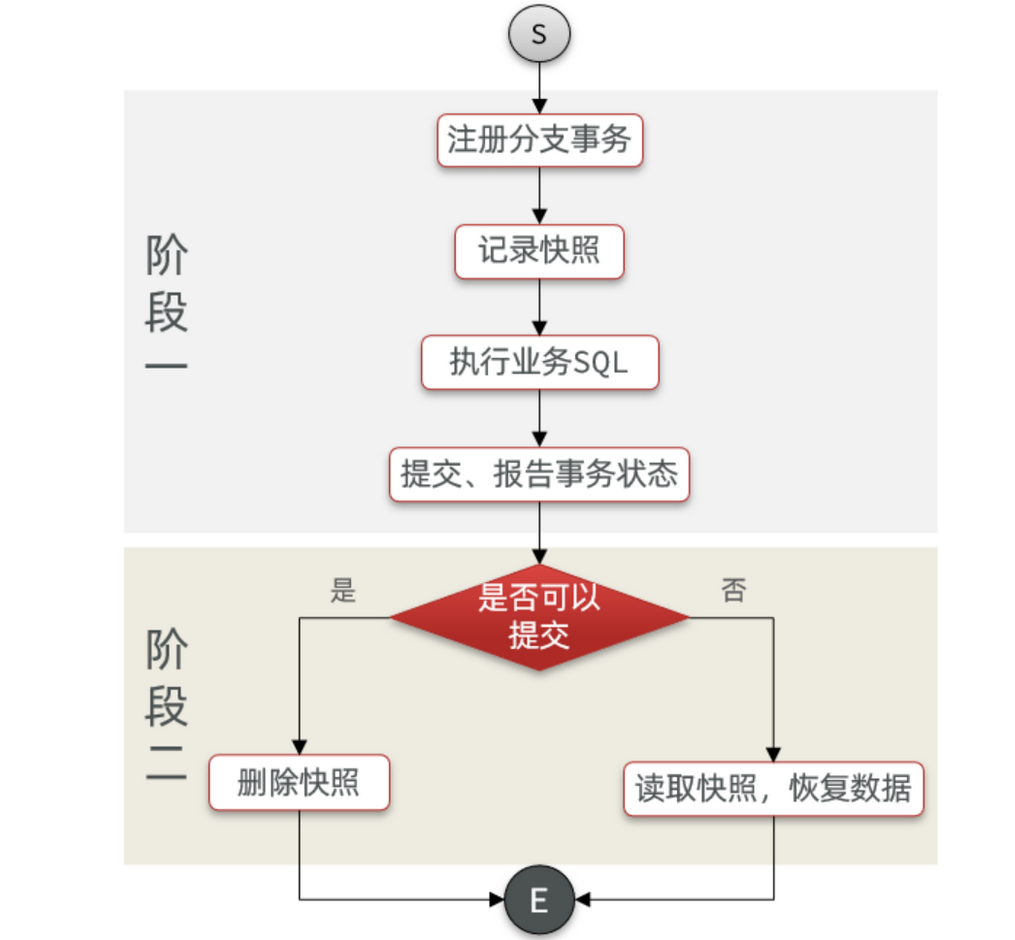
AT 模式下,当前分支事务执行流程如下:
一阶段:
-
TM 发起并注册全局事务到 TC
-
TM 调用分支事务
-
分支事务准备执行业务 SQL
-
RM 拦截业务 SQL,根据 where 条件查询原始数据,形成快照。
{ "id": 1, "money": 100 } -
RM 执行业务 SQL,提交本地事务,释放数据库锁。此时
money = 90 -
RM 报告本地事务状态给 TC
二阶段:
-
TM 通知 TC 事务结束
-
TC 检查分支事务状态
- 如果都成功,则立即删除快照
- 如果有分支事务失败,需要回滚。读取快照数据(
{"id": 1, "money": 100}),将快照恢复到数据库。此时数据库再次恢复为 100
上述过程的流程图:
2.2 AT 模式的脏写问题和写隔离
脏写问题:
在多线程并发访问 AT 模式的分布式事务时,有可能出现脏写问题,例如下图所示:

对上图中脏写问题的说明:
- 同时有两个并发的全局事务执行:
update tb_account set money = money - 10 where id = 1; - 事务 1 首先获取到了 DB 锁,保存了快照(此时
money为 100)之后,执行业务逻辑将money设置为了 90,然后提交了分支事务,并是否了 DB 锁; - 此时,事务 2 也获取到了 DB 锁,然后保存了快照(此时的
money为 90),然后执行业务将money设置成了 80,提交分支事务并是否 DB 锁; - 事务 1 因为后续的其中分支事务执行失败了,因此需要恢复前面所有提交了的分支事务,此时再次获取到了 DB 锁,然后需要根据自己的快照(
money为 100)来恢复数据。但是,此时的数据库中的money为 80,而站在事务 1 的角度则应该为 90,因此就丢失了一次更新,出现了脏写的问题。
解决方法:
为了解决上面的脏写问题,Seata 引入了全局锁,开启写隔离。即在释放 DB 锁之前,先拿到全局锁,避免同一时刻有另外一个事务来操作当前数据:
 对上述写隔离的详细说明:
对上述写隔离的详细说明:
- 同样是两个并发的全局事务执行:
update tb_account set money = money - 10 where id = 1; - 事务1 首先获取到 DB 锁,并保存了快照(
money为 100),然后执行了业务逻辑(更新money为 90),在提交分支事务之前获取了全局锁,然后提交分支事务,释放 DB 锁; - 然后事务 2 就获取到了 DB 锁,保存快照(
money为 90),然后执行业务逻辑(设置money为 80),执行完之后尝试获取全局锁,但此时全局锁被事务 1 持有,因此执行重复尝试获取,如果一直获取不到则会导致任务超时,自动回滚并释放 DB 锁; - 后面事务1因为其他分支事务执行失败,首先获取 DB 锁,然后根据快照恢复数据,快照中
money为 100,实际和 事务1 所期望的money都为 90,因此成功通过快照恢复数据。
要实现上面这个功能,需要额外引入一个数据库表,来记录当前全局锁的获取情况。
但是还是一个问题,那就是如果是一个 Seata 管理的全局事务和一个非 Seata 管理的全局事务来并发执行上述的业务逻辑,又该如何保存数据的一致性呢?
幸运的是,Seata 以及为我们考虑到了这个问题(虽然这个问题一般不会出现):
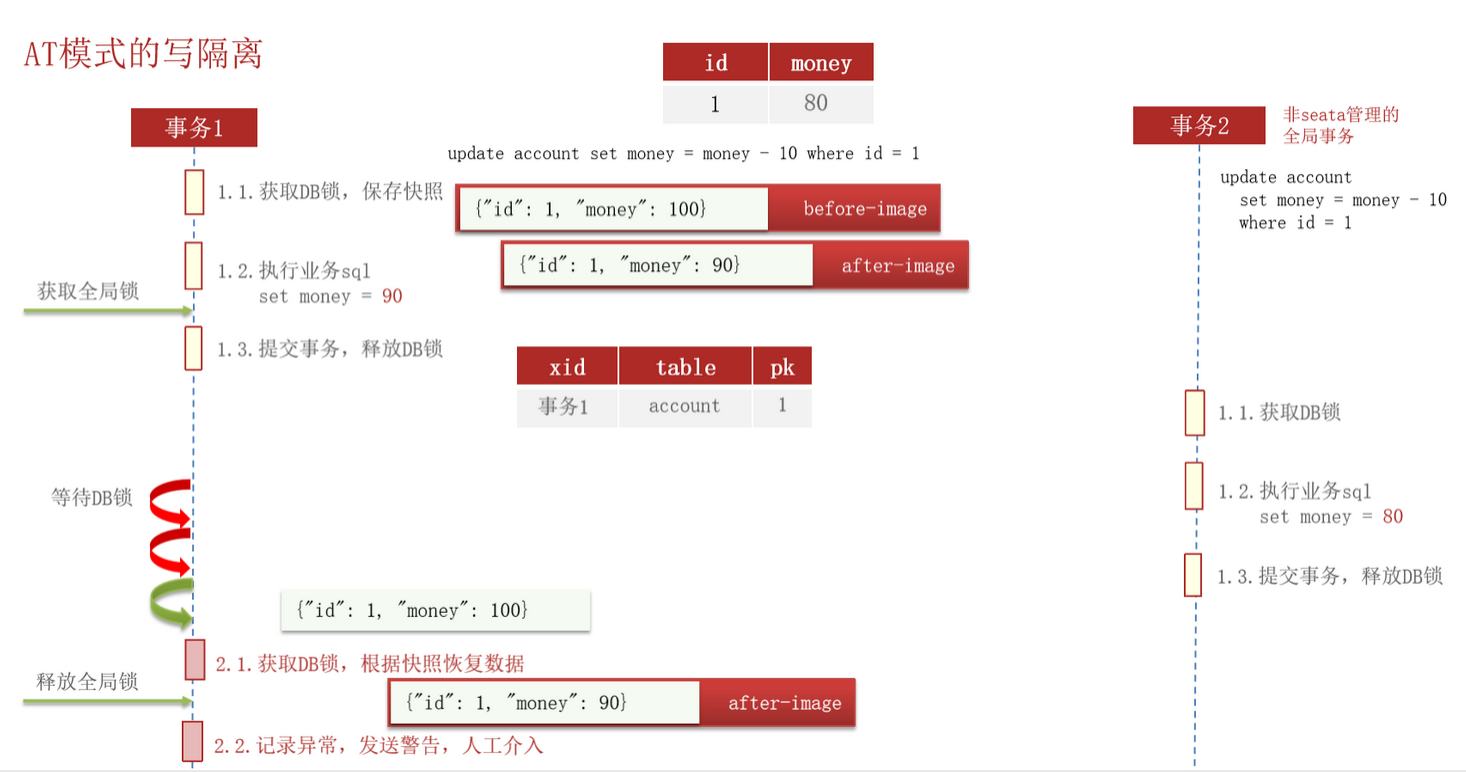 Seata 会在执行业务逻辑的前后都生成一个快照,即
Seata 会在执行业务逻辑的前后都生成一个快照,即before-image 和 after-image,后面当需要进行数据的恢复时就需要对比这两个快照和实际数据库中的数据是否一致,然后再执行数据的恢复操作。如果数据不一致,则需要记录异常,发出警告,通知人工介入来处理。
3.3 AT 模式的优缺点
AT(Auto Transaction)模式是Seata中的一种分布式事务模式,它具有优点和缺点如下:
优点:
-
一阶段完成直接提交事务: AT 模式的第一阶段(执行业务SQL并自动提交)不涉及全局事务协调器的参与,因此可以更快地完成事务操作,释放数据库资源,从而提高性能。
-
利用全局锁实现读写隔离: AT 模式引入全局锁和写隔离,可以防止脏写问题和提供写隔离。这有助于确保数据的一致性和避免并发写操作导致的问题。
-
没有代码侵入,框架自动完成回滚和提交: 在 AT 模式下,开发人员不需要编写特定的代码来处理分布式事务的提交和回滚,Seata 框架会自动处理这些事务管理的细节,降低了开发的复杂性。
缺点:
- 两阶段之间属于软状态: AT 模式中的两阶段提交之间是一个软状态,全局事务在第一阶段已经提交了分支事务,但最终一致性要在第二阶段进行检查和修复。这可能导致一定程度的数据不一致性,尤其是在第二阶段出现问题时。
尽管 AT 模式具有一些显著的优点,例如性能较好和较低的代码侵入性,但它仍然面临着最终一致性和软状态的挑战。开发人员需要权衡这些因素,并根据应用程序的需求选择适当的分布式事务模式。
3.4 Seata AT 模式在微服务中的实现
AT 模式中的快照生成、回滚等动作都是由框架自动完成,没有任何代码侵入,因此实现非常简单。只不过,AT 模式需要一个表来记录全局锁,另一张表来记录数据快照 undo_log。下面是实现 AT 模式的具体步骤:
- 导入数据库表,记录全局锁和快照
lock_table 用于记录全局锁,其使用对象的 seata-server,因此需要在seata数据库(由seataServer.properties配置文件指定)中创建该表:
-- ----------------------------
-- Table structure for lock_table
-- ----------------------------
DROP TABLE IF EXISTS `lock_table`;
CREATE TABLE `lock_table` (
`row_key` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`xid` varchar(96) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`branch_id` bigint(20) NOT NULL,
`resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`table_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`pk` varchar(36) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime NULL DEFAULT NULL,
`gmt_modified` datetime NULL DEFAULT NULL,
PRIMARY KEY (`row_key`) USING BTREE,
INDEX `idx_branch_id`(`branch_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
undo_log表用于记录快照,因此其使用对象是微服务,因此和账户表等创建到同一个数据库下:
-- ----------------------------
-- Table structure for undo_log
-- ----------------------------
DROP TABLE IF EXISTS `undo_log`;
CREATE TABLE `undo_log` (
`branch_id` bigint(20) NOT NULL COMMENT 'branch transaction id',
`xid` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT 'global transaction id',
`context` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` longblob NOT NULL COMMENT 'rollback info',
`log_status` int(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` datetime(6) NOT NULL COMMENT 'create datetime',
`log_modified` datetime(6) NOT NULL COMMENT 'modify datetime',
UNIQUE INDEX `ux_undo_log`(`xid`, `branch_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = 'AT transaction mode undo table' ROW_FORMAT = Compact;
- 修改所有微服务的
application.yml文件,将事务模式修改为 AT 模式:
seata:
data-source-proxy-mode: AT # 开启数据源代理的 AT 模式
可以发现,AT 模式是 Seata 的默认模式:

- 重启微服务并测试
此时,以断点调试的方式发送下面的请求:
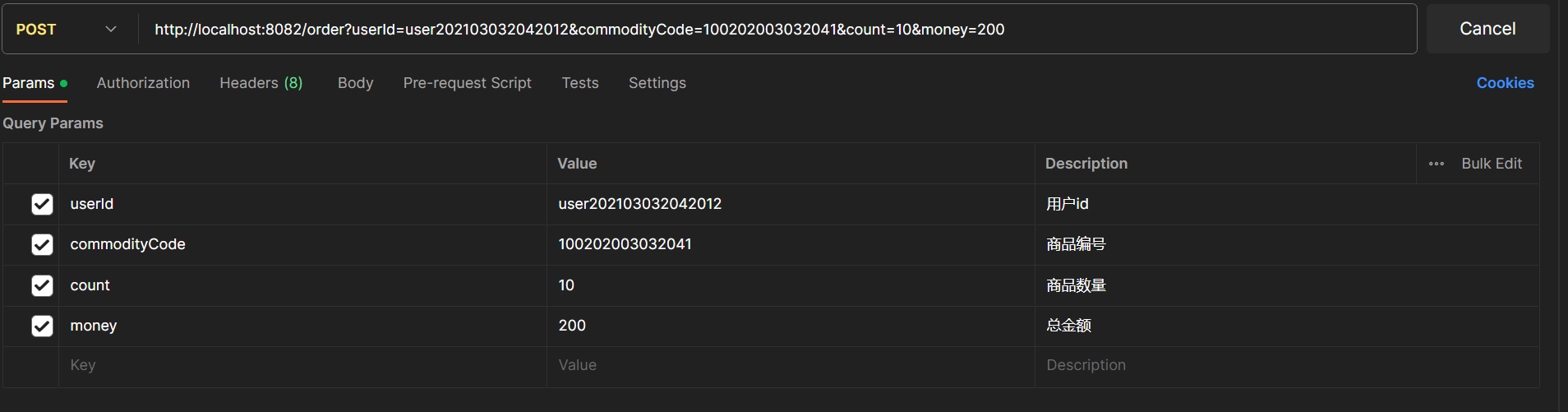
断点设置:
 启动调试,可以看到在
启动调试,可以看到在lock_table 表中为账户表和订单表都创建了全局锁:

并且 undo_log表中也创建了相应的快照:
放行之后,通过查看 account-service 服务的日志:
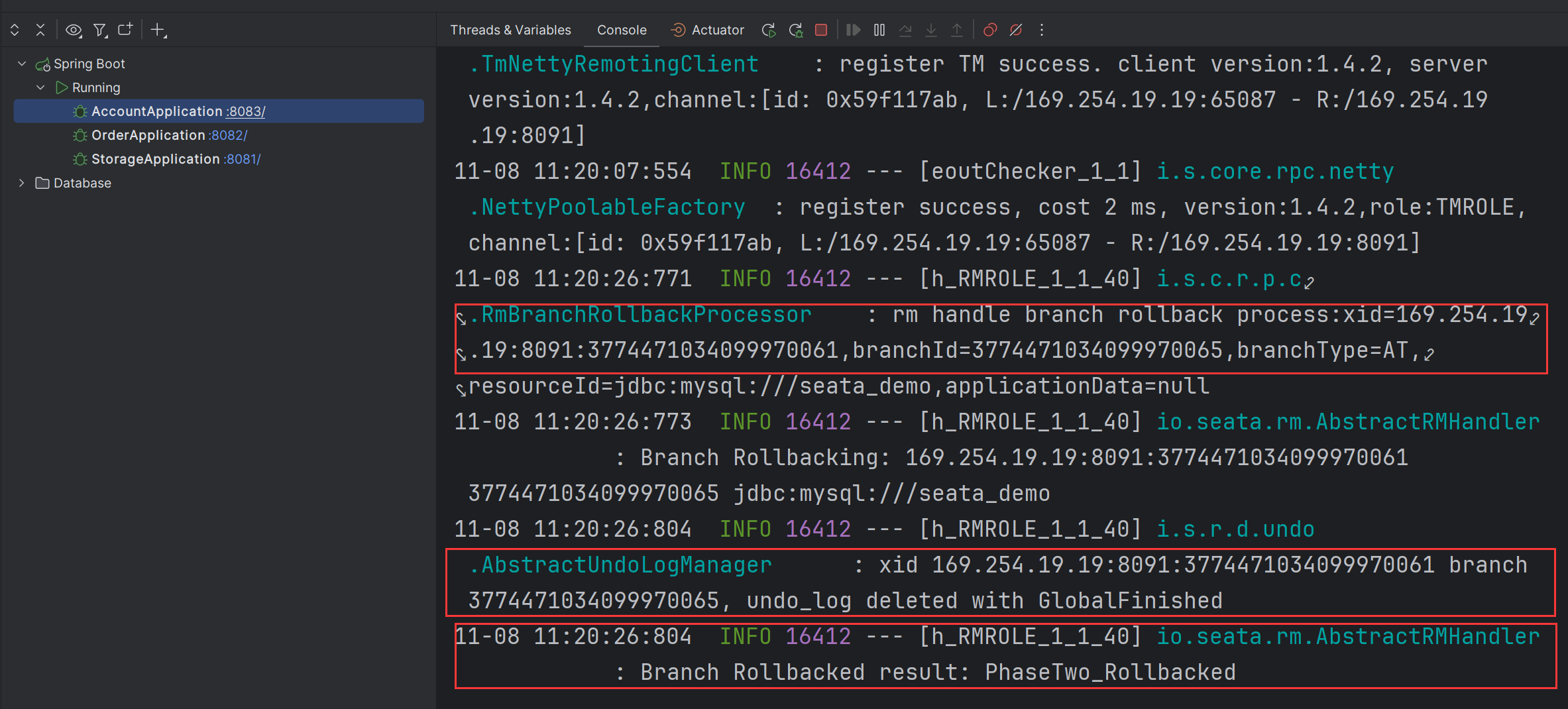
发现成功使用快照对数据进行了恢复,并且将lock_table 和 undo_log 表中的数据也进行了删除。
三、TCC 模式
3.1 TCC 模式原理
TCC模式(Try-Confirm-Cancel)与AT模式非常相似,它也是一种分布式事务模式,但不同之处在于TCC模式需要通过人工编码来实现数据恢复。在TCC模式中,需要实现三个方法:Try(尝试)、Confirm(确认)、Cancel(取消)。下面将详细介绍TCC模式的原理和流程。
TCC模式的三个方法:
-
Try(尝试): 这个方法用于资源的检测和预留。在Try阶段,事务会尝试执行业务逻辑,检查是否有足够的资源来执行操作,并预留资源以确保后续的确认或取消操作可以成功执行。
-
Confirm(确认): 这个方法用于完成资源操作业务。如果Try成功,那么在确认阶段将完成资源操作的实际业务。确认操作一定要能成功,以确保资源的变化被永久性地提交。
-
Cancel(取消): 这个方法用于资源的释放和恢复。如果Try成功但后续的确认操作出现问题,那么需要执行取消操作来释放预留的资源并恢复原始状态。
流程分析:
让我们通过一个简单的例子来说明TCC模式的流程,假设有一个扣减用户余额的业务。账户A的初始余额是100元,需要扣减30元。
阶段一(Try):
在Try阶段,我们需要检查账户余额是否充足,如果充足,就会增加冻结金额并扣除可用余额。初始余额如下:

余额充足,可以冻结30元:

此时,总金额 = 冻结金额 + 可用金额,数量依然是100元,事务可以直接提交而无需等待其他事务。
阶段二(Confirm):
如果要提交(Confirm),则需要扣减冻结金额30元,确认可以提交。不过之前的可用金额已经扣减过了,这里只需清除冻结金额:

此时,总金额 = 冻结金额 + 可用金额 = 0 + 70 = 70元。
阶段三(Cancel):
如果要回滚(Cancel),则需要扣减冻结金额30元,同时恢复可用余额30元,以释放冻结金额并恢复可用金额:

TCC模式的关键在于实现Try、Confirm和Cancel方法,以确保事务的一致性和可恢复性。如果Try成功但Confirm或Cancel出现问题,需要能够正确处理资源的释放和恢复操作。
3.2 Seata 的 TCC 模型
Seata中的TCC(Try-Confirm-Cancel)模型延续了之前介绍的事务架构,如下图所示:
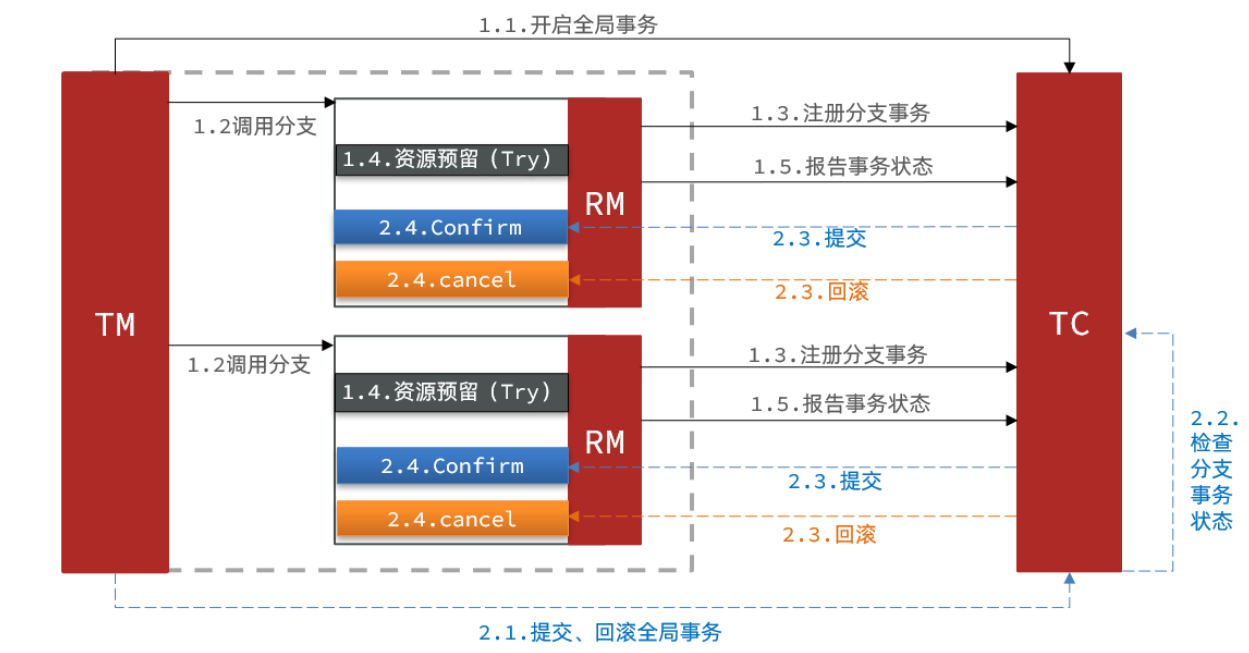
TCC模式中,每个阶段的作用如下:
-
Try(尝试): 这个阶段用于资源检查和预留。事务会尝试执行业务逻辑,检查资源是否足够,并预留资源。
-
Confirm(确认): 这个阶段用于完成资源操作业务。如果Try成功,Confirm将执行实际的资源操作并提交事务。
-
Cancel(取消): 这个阶段用于资源释放和恢复。如果Try成功但Confirm出现问题,需要执行Cancel来释放资源并恢复原始状态。
TCC模式的优点包括:
-
一阶段完成直接提交事务,释放数据库资源,性能好: TCC的Try阶段可以迅速完成,无需等待其他事务,从而释放数据库资源,提高性能。
-
相比AT模式,无需生成快照,无需使用全局锁,性能最强: TCC模式相对于AT模式,减少了对数据库快照的依赖,同时也不需要全局锁,因此具有较高的性能。
-
不依赖数据库事务,而是依赖补偿操作,可以用于非事务型数据库: TCC模式不要求数据库必须支持XA事务,因此可以用于非事务型数据库。
TCC模式的缺点包括:
-
有代码侵入,需要人为编写Try、Confirm和Cancel接口,较为繁琐: TCC模式需要开发人员编写特定的Try、Confirm和Cancel方法,这可能增加了开发的复杂性。
-
软状态,事务是最终一致: TCC模式的事务具有软状态,确认和取消操作可能出现问题,需要考虑如何处理失败情况以保证最终一致性。
总之,TCC模式在性能方面表现出色,但需要开发人员编写更多的代码来处理分布式事务的逻辑。选择TCC模式还应该考虑应用程序的特定需求和数据库的支持情况。
3.3 TCC 模型事务悬挂和空回滚
在TCC(Try-Confirm-Cancel)模型中,存在两个重要问题,即事务悬挂和空回滚,它们涉及到事务的正确执行和终止。
- 空回滚:
如下图所示:
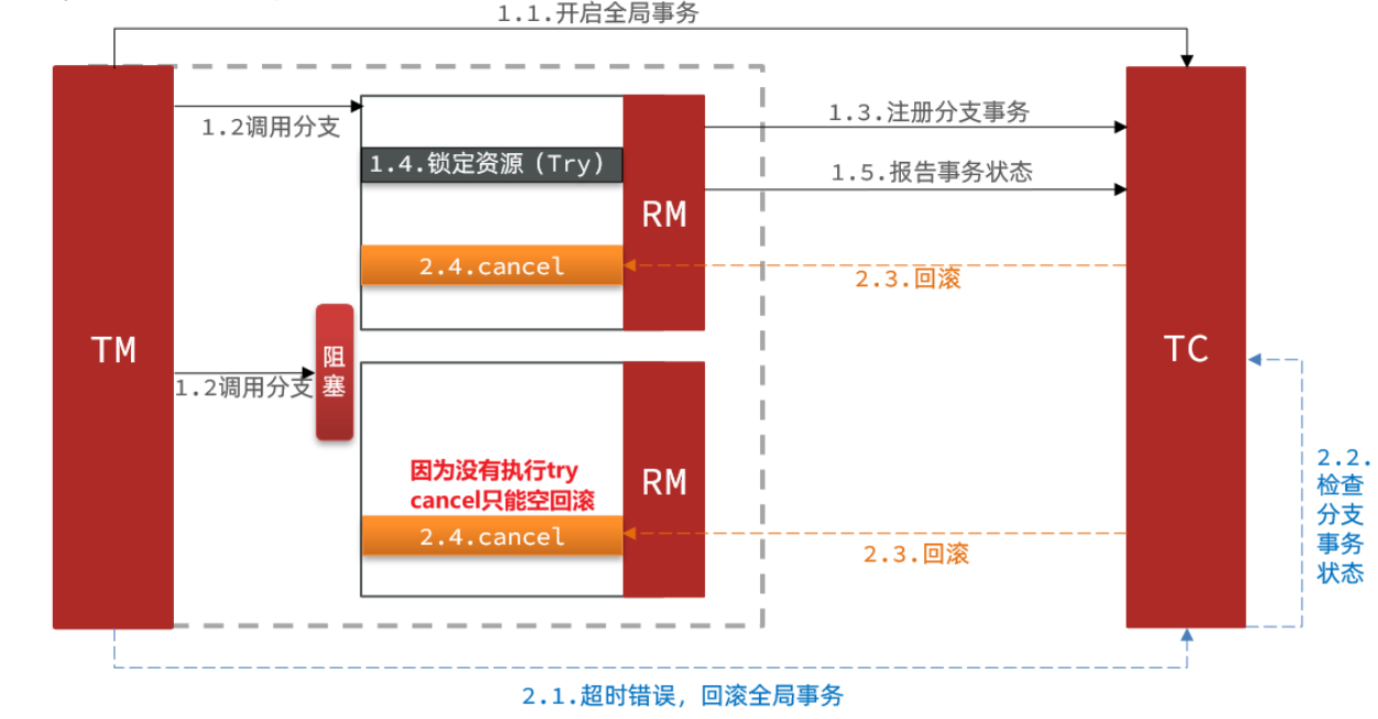
当某分支事务的Try阶段被阻塞,可在这里插入代码片能导致全局事务超时,触发二阶段的 Cancel 操作。然而,在执行Cancel操作之前,Try操作尚未执行,这种情况被称为空回滚。这意味着 Cancel 操作在 Try 操作之前执行,导致 Cancel 操作无法正常回滚已经执行的 Try 操作。空回滚是一个问题,因为它会导致事务的状态不正确。
解决空回滚的方法是在执行 Cancel 操作时,应判断 Try 是否已经执行。如果 Try 尚未执行,那么 Cancel 操作应该记录当前的状态,以等待进行 Try 操作时判断这个操作是否是 Cancel。
- 业务悬挂:
事务悬挂是在发生空回滚后的情况下出现的问题。当某个业务的 Try 操作被阻塞,已经发生了空回滚,然后之前被阻塞的 Try 操作重新启动并继续执行时,这些 Try 操作可能永远无法完成 Confirm 或 Cancel 操作,导致事务一直处于中间状态,这就是事务悬挂。
解决事务悬挂的方法是在执行 Try 操作时,判断是否已经执行了 Cancel 操作。如果 Cancel 操作已经执行,那么 Try 操作应该被阻止,以避免事务悬挂的问题。
3.4 TCC 模式的实现
TCC(Try-Confirm-Cancel)模式是一种用于实现分布式事务的模式,它通过分解事务操作为三个步骤,分别是Try、Confirm、Cancel,来实现分布式事务的一致性和可靠性。这种模式通常需要解决空回滚和业务悬挂等问题。以下是TCC模式的实现示例:
- 数据库表设计
为了解决TCC模式中的空回滚和业务悬挂问题,通常需要使用数据库表来记录事务状态。以下是一个示例数据库表的设计:
CREATE TABLE `account_freeze_tbl` (
`xid` varchar(128) NOT NULL,
`user_id` varchar(255) DEFAULT NULL COMMENT '用户id',
`freeze_money` int(11) unsigned DEFAULT '0' COMMENT '冻结金额',
`state` int(1) DEFAULT NULL COMMENT '事务状态,0:try,1:confirm,2:cancel',
PRIMARY KEY (`xid`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;
这个表的字段含义如下:
xid:全局事务的唯一标识符。user_id:用户ID,标识参与事务的用户。freeze_money:记录用户的冻结金额,用于TCC事务。state:记录事务状态,通常使用0表示Try阶段,1表示Confirm阶段,2表示Cancel阶段。
通过这张表,可以追踪每个全局事务的状态,从而解决空回滚和业务悬挂问题。
- 声明TCC接口
TCC模式的 Try、Confirm、Cancel 方法都需要在接口中基于注解进行声明。在service包下创建一个接口,并声明 TCC 的三个方法:
@LocalTCC
public interface AccountTCCService {
@TwoPhaseBusinessAction(name = "deduct", commitMethod = "confirm", rollbackMethod = "cancel")
void deduct(@BusinessActionContextParameter(paramName = "userId") String userId,
@BusinessActionContextParameter(paramName = "money") int money);
boolean confirm(BusinessActionContext context);
boolean cancel(BusinessActionContext context);
}
- 编写实现类
然后,在account-service服务的service.impl包下创建一个类,实现 TCC 业务:
@Service
@Slf4j
public class AccountTCCServiceImpl implements AccountTCCService {
@Autowired
private AccountMapper accountMapper;
@Autowired
private AccountFreezeMapper accountFreezeMapper;
@Override
@Transactional
public void deduct(String userId, int money) {
// 0. 获取事务id
String xid = RootContext.getXID();
// 1. 处理业务悬挂,判断 freeze 中是否有冻结记录,如果有,一定是执行过 CANCEL,因此拒绝业务
AccountFreeze oldFreeze = accountFreezeMapper.selectById(xid);
if(oldFreeze != null){
// 执行过 CANCEL,因此拒绝业务
return;
}
// 2. (由于是 unsigned 类型)直接扣减可用余额
accountMapper.deduct(userId, money);
// 3. 记录冻结金额,事务状态
AccountFreeze freeze = new AccountFreeze();
freeze.setUserId(userId);
freeze.setFreezeMoney(money);
freeze.setState(AccountFreeze.State.TRY);
freeze.setXid(xid);
accountFreezeMapper.insert(freeze);
}
@Override
public boolean confirm(BusinessActionContext context) {
// 1. 获取事务 id
String xid = context.getXid();
// 2. 根据id删除冻结记录
int count = accountFreezeMapper.deleteById(xid);
return count == 1;
}
@Override
public boolean cancel(BusinessActionContext context) {
// 0. 查询冻结记录
String xid = context.getXid();
String userId = (String) context.getActionContext("userId");
AccountFreeze freeze = accountFreezeMapper.selectById(xid);
// 1. 空回滚判断,判断 freeze 是否为 null
if (freeze == null) {
// 为 null 则证明 try 没有执行,需要空回滚
freeze = new AccountFreeze();
freeze.setUserId(userId);
freeze.setFreezeMoney(0);
freeze.setState(AccountFreeze.State.CANCEL);
freeze.setXid(xid);
accountFreezeMapper.insert(freeze);
return true;
}
// 2. 幂等判断
if(freeze.getState() == AccountFreeze.State.CANCEL){
// 以及处理过一次 CANCEL 操作
return true;
}
// 3. 恢复可用余额
accountMapper.refund(freeze.getUserId(), freeze.getFreezeMoney());
// 4. 将冻结金额清零,状态改为CANCEL
freeze.setFreezeMoney(0);
freeze.setState(AccountFreeze.State.CANCEL);
int count = accountFreezeMapper.updateById(freeze);
return count == 1;
}
}
这里,首先声明了TCC的Try、Confirm、Cancel方法,并在实现类中编写了相应的逻辑。在Try方法中,我们扣减可用余额并记录冻结金额和事务状态。在Confirm方法中,我们根据事务ID删除冻结记录。在Cancel方法中,我们恢复可用余额,将冻结金额清零,并将事务状态改为CANCEL。这些操作将确保TCC事务的正常执行,即使出现空回滚或业务悬挂情况也能进行处理。
四、SAGA 模式
4.1 SAGA 模式原理
SAGA 模式是一种分布式事务处理模式,旨在解决大规模分布式系统中的事务问题。其原理如下:
-
事务分解:将一个复杂的分布式事务分解为多个小事务,每个小事务可以独立执行。这些小事务可以跨越不同的服务和系统。
-
事务状态迁移:每个小事务有两个关键操作,即
compensating(回滚)和confirming(确认)。事务状态可以从一个状态迁移到另一个状态,例如从Started(已开始)到Completed(已完成),或从Started到Compensated(已回滚)。 -
协调器:有一个中央协调器或协调服务来管理整个事务的执行。协调器负责确保事务的状态迁移按正确的顺序发生,以保持事务的一致性。
-
异常处理:如果某个小事务失败,协调器会触发相应的
compensating操作来撤销之前已经执行的小事务,以确保事务的一致性。 -
事务状态管理:协调器跟踪和管理每个小事务的状态变化,以确保最终事务能够成功完成或者回滚到一致的状态。
-
最终一致性:SAGA 模式追求最终一致性,即事务可能会暂时处于不一致状态,但最终会达到一致状态。这意味着SAGA模式在处理大规模分布式事务时牺牲了一些一致性,以提高性能和可伸缩性。
4.2 SAGA 模式的优缺点
优点:
-
分布式事务处理:SAGA 模式是专门用于处理分布式事务的模式,能够有效解决跨多个服务的复杂事务问题。
-
高可伸缩性:由于事务被分解成多个小事务,这些小事务可以并行执行,提高了系统的可伸缩性。
-
容错性:SAGA 模式可以容忍某些小事务失败,通过回滚操作来保持整体事务的一致性。
-
降低锁竞争:与传统的两阶段提交(2PC)相比,SAGA 模式可以减少全局锁的使用,从而降低锁竞争。
-
灵活性:SAGA 模式允许在事务的执行过程中动态调整事务的状态迁移路径,更加灵活适应不同的业务需求。
缺点:
-
复杂性:SAGA 模式的实现相对复杂,需要编写和维护
compensating和confirming操作,以及确保正确的状态迁移。 -
最终一致性:SAGA 模式只追求最终一致性,可能会在事务过程中出现一时的不一致,需要额外的处理来处理这些不一致。
-
性能开销:由于SAGA 模式需要在协调器上执行状态管理和协调操作,可能会引入一些性能开销。
-
难以调试:SAGA 模式中的事务状态管理和回滚操作可能会增加调试的难度,特别是在复杂的分布式环境中。
总的来说,SAGA 模式适用于需要处理大规模分布式事务的场景,但在实施时需要权衡复杂性、一致性和性能之间的关系。
![洛谷 P1020 [NOIP1999 普及组] 导弹拦截【一题掌握三种方法:动态规划+贪心+二分】最长上升子序列LIS解法详解](https://img-blog.csdnimg.cn/4fb46ed83a3b4a1f8bab1fd16fbb7472.png)