提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言:
- 一、栈的定义:栈(stack)是限定仅在表尾进行插入和删除操作的线性表
- (1)栈是特殊的线性表
- (2)入栈与出栈
- 二、栈的顺序存储结构与代码操作实现
- (1)顺序栈的结构
- (2)进栈操作
- (3)出栈操作
- 三、栈的链式存储结构与代码操作实现
- (1)链式栈的结构
- (2)链式栈的入栈操作和出栈操作
- 四、栈有什么用处?
- 1.举几个例子
- 2.具体应用——递归:求斐波那契数列前n项的数
- ①斐波那契数列:0,1,1,2,3,5,8,13,.......。其前两项为0和1,之后每一项都是前两项之和。
- ②常规解法:
- ③递归解法:
- ④递归函数与栈有什么关系?
- 五、队列
- 1.队列是什么?
- 2.队列的顺序结构
- 3.队列的链式结构
- 4.队列有什么作用?
- 六、栈和队列的总结
前言:
在使用嵌入式单片机开发时,经常会用到栈和队列的知识。
比如:
栈:
函数调用:嵌入式系统中的函数调用通常使用栈来保存函数的上下文信息。每当一个函数被调用,函数的参数、局部变量以及返回地址等信息都会被保存在栈中,待函数执行完毕后再从栈中恢复上下文。
中断处理:当一个中断被触发时,嵌入式系统会将当前的执行状态保存在栈中,然后跳转到中断服务程序进行处理。处理完毕后,再从栈中恢复之前的执行状态。
数据结构:栈常用于实现其他数据结构,如深度优先搜索算法(DFS)中使用的递归调用,以及表达式求值中的操作符栈等。
队列:
任务调度:嵌入式系统中的任务调度器通常使用队列来管理任务的执行顺序。通过队列,可以按照一定的优先级或者时间片轮转的方式来调度任务的执行。
事件处理:嵌入式系统中的事件处理机制通常使用队列来存储和处理事件。当一个事件发生时,会将事件放入队列中,然后由相应的任务或中断服务程序来处理队列中的事件。
缓冲区管理:嵌入式系统中的通信和数据处理往往需要使用缓冲区来存储数据。队列可以作为缓冲区的管理机制,用于存储和传输数据。
所以栈和队列非常重要。
一、栈的定义:栈(stack)是限定仅在表尾进行插入和删除操作的线性表
在我们软件应用中,栈这种后进先出数据结构的应用是非常普遍的。比如你用浏览器上网时,不管什么浏览器都有一个“后退”键,你点击后可以按访问顺序的逆序加载浏览过的网页。比如你本来看着新闻好好的,突然看到一个链接说,有个可以让你年薪100万的工作,你毫不犹豫点击它,跳转进去一看,这都是啥呀,具体内容我也就不说了,骗人骗得一点水平都没有。此时你还想回去继续看新闻,就可以点击左上角的后退键。即使你从一个网页开始,连续点了几十个链接跳转,你点“后退”时,还是可以像历史倒退一样,回到之前浏览过的某个页面
给定一下:栈(stack)是限定仅在表尾进行插入和删除操作的线性表。
(1)我们把允许插入和删除的一端称为栈顶(top),另一端称为栈底 (bottom),不含任何数据元素的栈称为空栈。
(2)栈又称为后进先出(Last In First Out)的线性表,简称LIFO结构。
(1)栈是特殊的线性表
栈是一种特殊的线性表,它只允许在表的一端进行插入和删除操作,该端称为栈顶(Top)。栈按照“后进先出”(Last In First Out,LIFO)的原则进行操作,最后插入的元素最先被删除。
与普通的线性表不同,栈只支持在栈顶进行插入(压入)和删除(弹出)操作,而不允许在栈底或中间进行操作。当一个新元素被插入到栈中时,它成为新的栈顶;当一个元素被删除时,栈顶指针指向下一个元素,成为新的栈顶。
(2)入栈与出栈
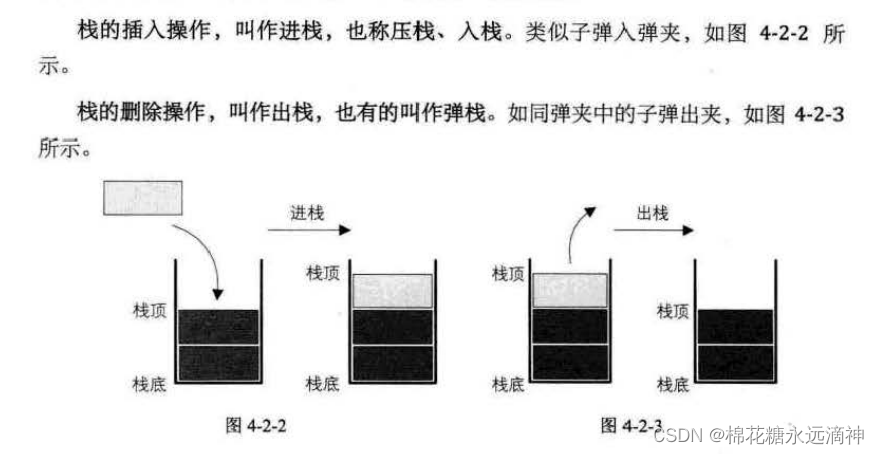
入栈与出栈会有很多种不同的可能,只要遵循栈顶的元素先出的原则即可。


二、栈的顺序存储结构与代码操作实现
(1)顺序栈的结构

有两个结构体成员,分别是数据域data和一个记录栈顶元素位置的变量top。由于顺序栈就是个数组,所以初始化栈时,栈空间是确定的,大小为MAXSIZE,所以栈内元素不能超出上限,否则就会发生堆栈溢出。
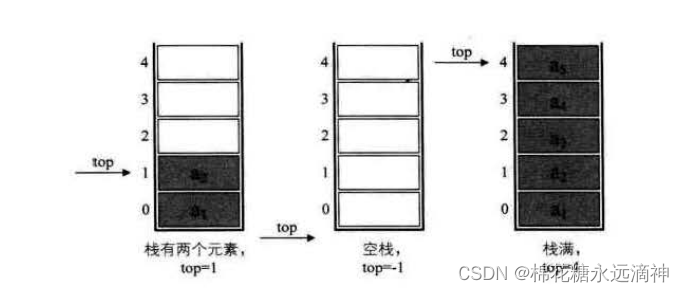
对顺序栈,即数组而言,栈顶就是下标为0的位置,空栈时栈顶变量为下标-1,进栈后栈顶变量动态变化,总是指向栈顶的那个元素。
这里要注意一个关键:top变量不是指针变量,而是一个整型变量,它记录的是栈顶元素在数组中的下标大小。
(2)进栈操作
思路:对于栈数组,进栈一个元素,那么栈指针增加一位,指向该元素。由于数组的特性,数组的首个元素的下标即为指针地址,所以第二个元素的指针地址,就是指针+1来表示,同理第三个就是+2。

代码:
#include <stdio.h>
#define MAX_SIZE 10
// 定义顺序栈结构体
typedef struct {
int data[MAX_SIZE]; // 用数组存储栈的元素
int top; // 栈顶指针
} Stack;
// 初始化栈
void initStack(Stack *stack) {
stack->top = -1; // 栈顶指针初始化为-1
}
// 判断栈是否为空
int isEmpty(Stack *stack) {
return stack->top == -1;
}
// 判断栈是否已满
int isFull(Stack *stack) {
return stack->top == MAX_SIZE - 1;
}
// 入栈操作
void push(Stack *stack, int element) {
if (isFull(stack)) {
printf("Stack is full. Cannot push element.\n");
return;
}
stack->top++; // 栈顶指针加1
stack->data[stack->top] = element; // 将元素存入栈顶位置
printf("Element %d pushed into stack.\n", element);
}
int main() {
Stack stack;
initStack(&stack);
int element = 10;
push(&stack, element);
return 0;
}
一开始,top变量值为-1,当有一个元素入栈时,top++变为0,即数组的第一个元素,给第一个元素赋值,就完成了入栈操作。
(3)出栈操作
思路:对于stack->data[stack->top],先赋值给一个变量,然后将stack->top–.

三、栈的链式存储结构与代码操作实现
(1)链式栈的结构
想想看,栈只是栈顶来做插入和删除操作,栈顶放在链表的头部还是尾部呢?由于单链表有头指针,而栈顶指针也是必须的,那干吗不让它俩合二为一呢,所以比较好的办法是把栈顶放在单链表的头部(如图4-6-1所示)。另外,都已经有了栈顶在头部了,单链表中比较常用的头结点也就失去了意义,通常对于链栈来说,是不需要头结点的。
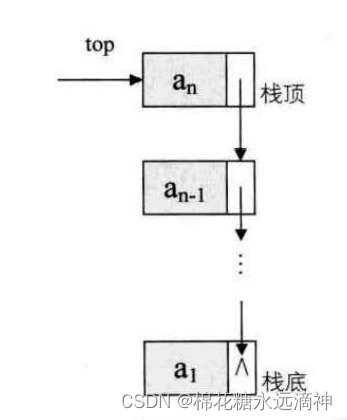
链栈由于链式结构的特性,所占空间是动态变化的,所以不会出现堆栈溢出的情况。而顺序结构由于空间提前定义好了,所以无法改变,可能会出现溢出。
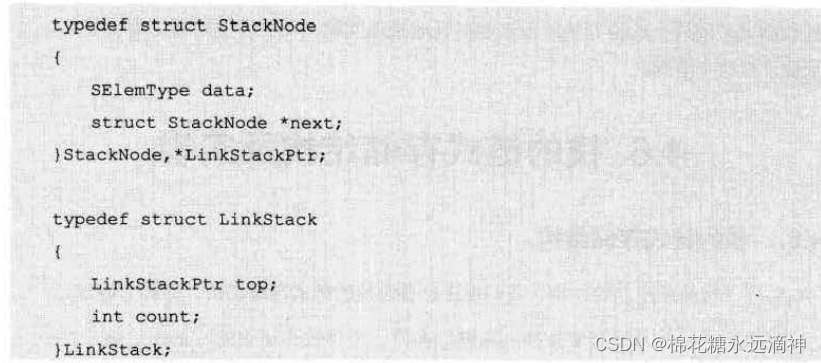
这里有两个结构体,一个是栈的节点(数据域+指针域,与链表一致),另一个是链栈(栈顶指针top)。
(2)链式栈的入栈操作和出栈操作
思路:
①链栈入栈:将新节点插入到链表头部,然后更新栈顶指针。
// 入栈操作
void push(Stack* stack, int element) {
Node* newNode = (Node*)malloc(sizeof(Node)); // 创建新节点
if (newNode == NULL) {
printf("Memory allocation failed. Cannot push element.\n");
return;
}
newNode->data = element; // 设置新节点的数据元素
newNode->next = stack->top; // 将新节点插入到链表头部
stack->top = newNode; // 更新栈顶指针
printf("Element %d pushed into stack.\n", element);
}
②出栈:保存栈顶节点的地址到temp,保存栈顶节点的数据元素到poppedElement,更新栈顶指针top为栈顶节点的下一个节点,释放temp指向的节点内存。
// 出栈操作
void pop(Stack* stack) {
if (isEmpty(stack)) {
printf("Stack is empty. Cannot pop element.\n");
return;
}
Node* temp = stack->top; // 保存栈顶节点的地址
int poppedElement = temp->data; // 保存栈顶节点的数据元素
stack->top = temp->next; // 更新栈顶指针
free(temp); // 释放栈顶节点的内存
printf("Element %d popped from stack.\n", poppedElement);
}
四、栈有什么用处?
1.举几个例子
在计算机科学和编程中有广泛的应用,以下是一些栈的常见用途:
函数调用:栈用于存储函数调用时的局部变量、返回地址和函数参数等信息。当一个函数被调用时,它的局部变量和参数被压入栈中,函数执行完毕后再从栈中弹出这些信息,返回到调用点。
表达式求值:栈可以用于解析和求解数学表达式,如中缀表达式(常见的数学表达式表示方式),通过将操作符和操作数入栈并按照一定规则弹出和计算,可以实现表达式的求值。
括号匹配:栈可以用于检查表达式中的括号是否匹配。通过遍历表达式,将左括号入栈,遇到右括号时弹出栈顶元素并检查是否匹配,如果匹配则继续,否则表达式中的括号不匹配。
浏览器的历史记录:浏览器的历史记录可以使用栈来实现。每次访问一个新的网页时,将该网页入栈,当点击返回按钮时,从栈中弹出最近访问的网页,实现浏览器的返回功能。
撤销操作:在文本编辑器、图形软件等应用程序中,栈可以用于实现撤销操作。每次进行修改操作时,将修改前的状态入栈,当需要撤销操作时,从栈中弹出最近的状态,恢复到该状态。
2.具体应用——递归:求斐波那契数列前n项的数
①斐波那契数列:0,1,1,2,3,5,8,13,…。其前两项为0和1,之后每一项都是前两项之和。
②常规解法:
void Feb(int n){
for(i = 2;i < n;i++){
a[i]=a[i-1]+a[i-2];
printf("%d ", a[i]);
}
int main(){
Feb(20);
return 0;
不解释了。
③递归解法:
int fibonacci(int n) {
if (n == 0 || n == 1) {
return n;
} else {
return fibonacci(n-1) + fibonacci(n-2);
}
}
递归是什么意思呢?就是说一个函数在运行时调用了另外一个函数,只不过这个函数正好是它自己,而函数的传参不同。在高级语言中,调用自己和其它函数并没有本质的不同。我们把一个直接调用自
己或通过一系列的调用语句间接地调用自己的函数,称做递归函数。
递归程序最怕的就是陷入永不结束的无穷递归中,所以,每个递归定义必须至少有一个条件,满足时递归不再进行,即不再引用自身而是返回值退出。比如例子,总有一次递归会使得 i<2的,这样就可以执行return i的语句而不用继续递归了。
④递归函数与栈有什么关系?
递归函数和栈之间有密切的关系。
在计算机中,每当一个函数被调用时,会在内存中创建一个称为“函数调用栈”或“调用栈”的数据结构。这个栈用于存储函数的局部变量、返回地址和其他与函数调用相关的信息。
当一个函数调用另一个函数时,当前函数的执行被暂停,并将当前函数的信息(包括局部变量、返回地址等)压入栈中,然后开始执行被调用的函数。当被调用的函数执行完毕后,栈顶的函数信息被弹出栈,并恢复到原来的函数继续执行。
递归函数就是在函数执行过程中调用自身的函数。当递归函数被调用时,它会将自身的信息压入栈中,然后开始执行自身。当递归函数的终止条件满足时,递归开始回溯,即从栈中弹出函数信息并恢复上一层的函数继续执行。这个回溯的过程就是递归函数的出栈操作。
因此,递归函数的调用过程实际上就是对栈的操作。每次递归调用都会创建一个新的栈帧,将函数的局部变量和其他信息存储在该栈帧中。当递归结束时,栈会依次弹出栈帧,回到上一层函数的执行。
五、队列
1.队列是什么?
用电脑时有没有经历过,机器有时会处于疑似死机的状态,鼠标点什么似乎都没用,双击任何快捷方式都不动弹。就当你失去耐心,打算reset时。突然它像酒醒了一样,把你刚才点击的所有操作全部都按顺序执行了一遍。这其实是因为操作系统中的多个程序因需要通过一个通道输出,而按先后次序排队等待造成的。
再比如像移动、联通、电信等客服电话,客服人员与客户相比总是少数,在所有的客服人员都占线的情况下,客户会被要求等待,直到有某个客服人员空下来,才能让最先等待的客户接通电话。这里也是将所有当前拨打客服电话的客户进行了排队处理。
操作系统和客服系统中,都是应用了一种数据结构来实现刚才提到的先进先出的排队功能,这就是队列。
所以:队列是一种先进先出 First 10 First 的线性衰,简称 FIFO 。允许插入的一端称为队尾,允许删除的一端称为队头。

2.队列的顺序结构
上代码:
#include <stdio.h>
#include <stdlib.h>
#define MAX_QUEUE_SIZE 10
typedef struct {
int data[MAX_QUEUE_SIZE];
int front;
int rear;
} Queue;
void initQueue(Queue *q) {
q->front = 0;
q->rear = 0;
}
void enqueue(Queue *q, int value) {
if ((q->rear + 1) % MAX_QUEUE_SIZE == q->front) {
printf("Queue is full.\n");
return;
}
q->data[q->rear] = value;
q->rear = (q->rear + 1) % MAX_QUEUE_SIZE;
}
int dequeue(Queue *q) {
if (q->front == q->rear) {
printf("Queue is empty.\n");
return -1;
}
int value = q->data[q->front];
q->front = (q->front + 1) % MAX_QUEUE_SIZE;
return value;
}
int main() {
Queue q;
initQueue(&q);
enqueue(&q, 1);
enqueue(&q, 2);
enqueue(&q, 3);
printf("%d\n", dequeue(&q));
printf("%d\n", dequeue(&q));
printf("%d\n", dequeue(&q));
printf("%d\n", dequeue(&q)); // Queue is empty.
return 0;
}
定义了一个结构体Queue来表示队列,包含一个数组data用于存储队列元素,以及front和rear分别表示队头和队尾的下标。initQueue函数用于初始化队列,enqueue函数用于入队,dequeue函数用于出队。在入队和出队时,需要进行判断队列是否已满或已空,以防止出现越界访问的错误。
入队操作是将一个元素添加到队列的末尾。实现队列的顺序结构时,我们需要维护队列的rear指针,它指向队列的末尾元素。当我们要入队一个元素时,我们需要先检查队列是否已满。如果队列已满,则无法入队,否则可以将元素添加到队列末尾,并将rear指针后移一位。由于队列是先进先出的数据结构,新入队的元素总是在队列末尾,等待出队。
出队操作是将队列的头部元素移除,并返回它的值。实现队列的顺序结构时,我们需要维护队列的front指针,它指向队列的头部元素。当我们要出队一个元素时,我们需要先检查队列是否为空。如果队列为空,则无法出队,否则可以将队列的头部元素移除,并将front指针后移一位。由于队列是先进先出的数据结构,出队的元素总是队列中最早入队的元素。
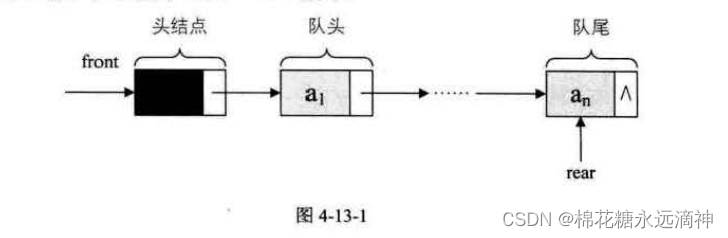
3.队列的链式结构
#include <stdio.h>
#include <stdlib.h>
typedef struct Node {
int data;
struct Node *next;
} Node;
typedef struct {
Node *front;
Node *rear;
} Queue;
void initQueue(Queue *q) {
q->front = NULL;
q->rear = NULL;
}
void enqueue(Queue *q, int value) {
Node *newNode = (Node*) malloc(sizeof(Node));
newNode->data = value;
newNode->next = NULL;
if (q->rear == NULL) {
q->front = newNode;
q->rear = newNode;
} else {
q->rear->next = newNode;
q->rear = newNode;
}
}
int dequeue(Queue *q) {
if (q->front == NULL) {
printf("Queue is empty.\n");
return -1;
}
int value = q->front->data;
Node *temp = q->front;
q->front = q->front->next;
free(temp);
if (q->front == NULL) {
q->rear = NULL;
}
return value;
}
int main() {
Queue q;
initQueue(&q);
enqueue(&q, 1);
enqueue(&q, 2);
enqueue(&q, 3);
printf("%d\n", dequeue(&q));
printf("%d\n", dequeue(&q));
printf("%d\n", dequeue(&q));
printf("%d\n", dequeue(&q)); // Queue is empty.
return 0;
}
链式队列的入队操作是在队列尾部添加一个新的元素,实现过程如下:
创建一个新节点,将要插入的元素值存储在新节点的数据域中。
将新节点的next指针指向队列的尾节点的下一个节点(即为NULL)。
将队列的尾节点的next指针指向新节点。
将队列的尾节点指针指向新节点。
如果队列为空,那么插入的新节点既是队列的头节点,也是队列的尾节点。
链式队列的出队操作是删除队列的头节点,实现过程如下:
如果队列为空,则无法进行出队操作,返回错误信息。
将头节点的数据域保存到一个临时变量中。
让头节点的指针指向下一个节点。
释放被删除的头节点。
如果队列为空,那么将尾节点的指针也置为NULL。
4.队列有什么作用?
队列是一种基本的数据结构,它可以在计算机科学中被广泛应用。以下是队列的一些主要应用:
1.任务调度:队列可以用于处理任务的调度,例如在操作系统中,可以使用队列来管理进程和线程的调度。
2.缓存管理:队列可以被用来管理缓存,例如在Web应用程序中,可以使用队列来处理缓存中的请求。
3.广度优先搜索:队列可以用于实现广度优先搜索算法,例如在图论中,可以使用队列来实现广度优先搜索。
4.消息传递:队列可以用于消息传递,例如在消息队列系统中,可以使用队列来传递和处理消息。
5.多线程编程:队列可以用于实现线程之间的通信,例如在多线程编程中,可以使用队列来传递数据和控制信息。
6.模拟系统:队列可以用于模拟系统的行为,例如在模拟排队系统中,可以使用队列来管理排队的顾客、服务员和服务窗口。
六、栈和队列的总结
栈和队列都是常用的数据结构,两者在概念上和实现上也有很多相似之处,但它们的操作方式和应用场景有很大的不同。
栈是一种后进先出(Last In First Out, LIFO)的数据结构,只允许在栈顶进行插入和删除操作,因此插入和删除的时间复杂度都是O(1)。栈的应用场景包括表达式求值、函数调用、回溯算法等。
队列是一种先进先出(First In First Out, FIFO)的数据结构,允许在队列尾部进行插入操作,在队列头部进行删除操作,因此插入和删除的时间复杂度都是O(1)。队列的应用场景包括广度优先搜索、缓存管理、CPU任务调度等。
在实现上,栈和队列都可以用数组或链表来实现。数组实现的栈和队列比较简单,但大小固定,需要预先分配空间。链表实现的栈和队列比较灵活,可以动态地添加和删除元素,但需要处理指针和内存管理问题。
综上所述,栈和队列是两种不同的数据结构,它们在应用场景和实现方式上都有很大的不同。在选择数据结构时,需要根据具体的需求来选择。