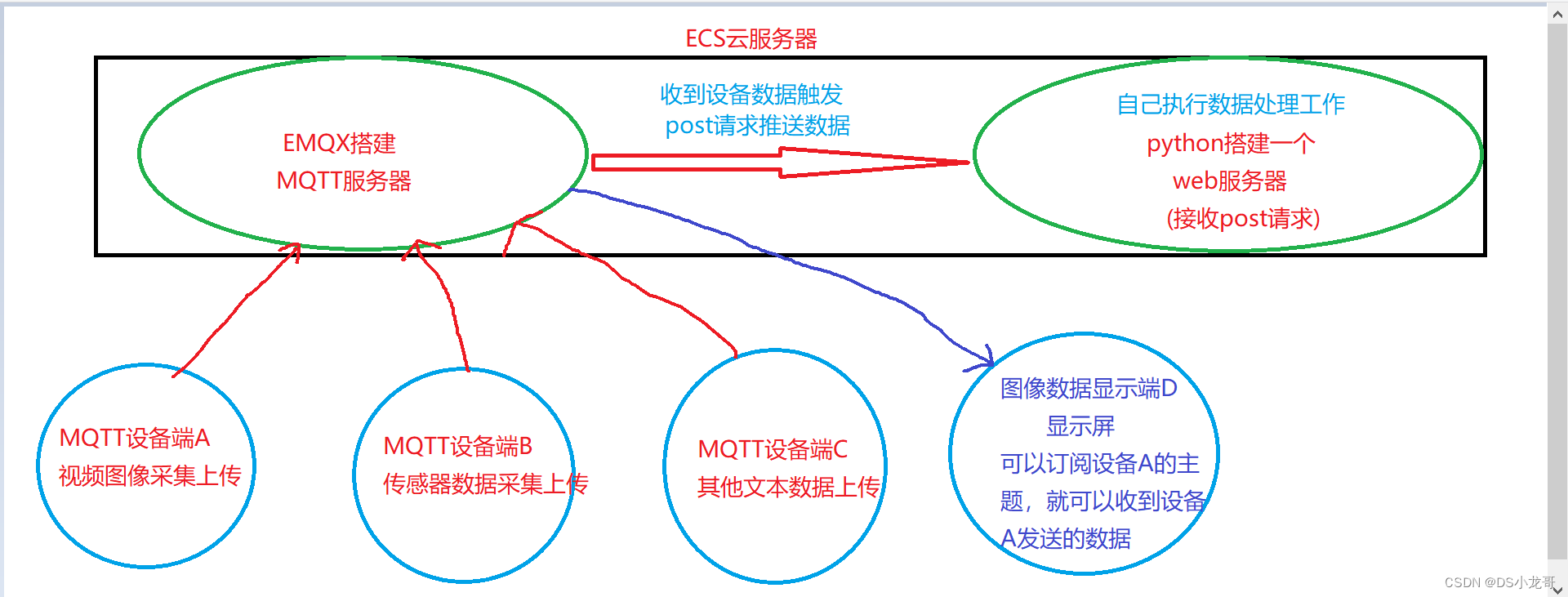
前段时间由于公司测试方向的转型,由原来的web页面功能测试转变成接口测试,之前大多都是手工进行,利用postman和jmeter进行的接口测试,后来,组内有人讲原先web自动化的测试框架移驾成接口的自动化框架,使用的是java语言,但对于一个学java,却在学python的我来说,觉得python比起java更简单些,所以,我决定自己写python的接口自动化测试框架,由于本人也是刚学习python,这套自动化框架目前已经基本完成了,于是进行一些总结,便于以后回顾温习,有许多不完善的地方,也遇到了许多的问题,希望大神们多多指教。下面我就进行今天的主要内容吧。(初学者的成功之路,哈哈哈~~)
1、首先,我们先来理一下思路。
正常的接口测试流程是什么?
脑海里的反应是不是这样的:
确定测试接口的工具 —> 配置需要的接口参数 —> 进行测试 —> 检查测试结果(有的需要数据库辅助) —> 生成测试报告(html报告)
那么,我们就根据这样的过程来一步步搭建我们的框架。在这个过程中,我们需要做到业务和数据的分离,这样才能灵活,达到我们写框架的目的。只要好好做,一定可以成功。这也是我当初对自己说的。
接下来,我们来进行结构的划分。
我的结构是这样的,大家可以参考下:
common:存放一些共通的方法
result:执行过程中生成的文件夹,里面存放每次测试的结果
testCase:用于存放具体的测试case
testFile:存放测试过程中用到的文件,包括上传的文件,测试用例以及 数据库的sql语句
caselist:txt文件,配置每次执行的case名称
config:配置一些常量,例如数据库的相关信息,接口的相关信息等
readConfig: 用于读取config配置文件中的内容
runAll:用于执行case

既然整体结构有了划分,接下来就该一步步的填充整个框架了,首先,我们先来看看config.ini和readConfig.py两个文件,从他们入手,个人觉得比较容易走下去哒。
我们来看下文件的内容是什么样子的:
[DATABASE]
host = 50.23.190.57
username = xxxxxx
password = ******
port = 3306
database = databasename
[HTTP]
# 接口的url
baseurl = http://xx.xxxx.xx
port = 8080
timeout = 1.0
[EMAIL]
mail_host = smtp.163.com
mail_user = xxx@163.com
mail_pass = *********
mail_port = 25
sender = xxx@163.com
receiver = xxxx@qq.com/xxxx@qq.com
subject = python
content = "All interface test has been complited\nplease read the report file about the detile of result in the attachment."
testuser = Someone
on_off = 1相信大家都知道这样的配置文件,没错,所有一成不变的东西,我们都可以放到这里来。哈哈,怎么样,不错吧。
现在,我们已经做好了固定的“仓库”。来保存我们平时不动的东西,那么,我们要怎么把它拿出来为我所用呢?这时候,readConfig.py文件出世了,它成功的帮我们解决了这个问题,下面就让我们来一睹它的庐山真面目吧。
import os
import codecs
import configparser
proDir = os.path.split(os.path.realpath(__file__))[0]
configPath = os.path.join(proDir, "config.ini")
class ReadConfig:
def __init__(self):
fd = open(configPath)
data = fd.read()
# remove BOM
if data[:3] == codecs.BOM_UTF8:
data = data[3:]
file = codecs.open(configPath, "w")
file.write(data)
file.close()
fd.close()
self.cf = configparser.ConfigParser()
self.cf.read(configPath)
def get_email(self, name):
value = self.cf.get("EMAIL", name)
return value
def get_http(self, name):
value = self.cf.get("HTTP", name)
return value
def get_db(self, name):
value = self.cf.get("DATABASE", name)
return value怎么样,是不是看着很简单啊,我们定义的方法,根据名称取对应的值,是不是so easy?!当然了,这里我们只用到了get方法,还有其他的例如set方法,有兴趣的同学可以自己去探索下,这里我们就不在累述了。
话不多说,我们先来看下common到底有哪些东西。

既然配置文件和读取配置文件我们都已经完成了,也看到了common里的内容,接下来就可以写common里的共通方法了,从哪个下手呢?今天,我们就来翻“Log.py”的牌吧,因为它是比较独立的,我们单独跟他打交道,也为了以后它能为我们服务打下良好基础。
这里呢,我想跟大家多说两句,对于这个log文件呢,我给它单独启用了一个线程,这样在整个运行过程中,我们在写log的时候也会比较方便,看名字大家也知道了,这里就是我们对输出的日志的所有操作了,主要是对输出格式的规定,输出等级的定义以及其他一些输出的定义等等。总之,你想对log做的任何事情,都可以放到这里来。我们来看下代码,没有比这个更直接有效的了。
import logging
from datetime import datetime
import threading首先,我们要像上面那样,引入需要的模块,才能进行接下来的操作。
class Log:
def __init__(self):
global logPath, resultPath, proDir
proDir = readConfig.proDir
resultPath = os.path.join(proDir, "result")
# create result file if it doesn't exist
if not os.path.exists(resultPath):
os.mkdir(resultPath)
# defined test result file name by localtime
logPath = os.path.join(resultPath, str(datetime.now().strftime("%Y%m%d%H%M%S")))
# create test result file if it doesn't exist
if not os.path.exists(logPath):
os.mkdir(logPath)
# defined logger
self.logger = logging.getLogger()
# defined log level
self.logger.setLevel(logging.INFO)
# defined handler
handler = logging.FileHandler(os.path.join(logPath, "output.log"))
# defined formatter
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# defined formatter
handler.setFormatter(formatter)
# add handler
self.logger.addHandler(handler),现在,我们创建了上面的Log类,在__init__初始化方法中,我们进行了log的相关初始化操作。具体的操作内容,注释已经写得很清楚了(英文有点儿差,大家看得懂就行,嘿嘿……),这样,log的基本格式已经定义完成了,至于其他的方法,就靠大家自己发挥了,毕竟每个人的需求也不同,我们就只写普遍的共用方法啦。接下来,就是把它放进一个线程内了,请看下面的代码:
class MyLog:
log = None
mutex = threading.Lock()
def __init__(self):
pass
@staticmethod
def get_log():
if MyLog.log is None:
MyLog.mutex.acquire()
MyLog.log = Log()
MyLog.mutex.release()
return MyLog.log看起来是不是没有想象中的那样复杂啊,哈哈哈,就是这样简单,python比java简单了许多,这也是我为什么选择它的原因,虽然小编我也是刚刚学习,还有很多不懂的地方。希望大家跟我一同进步。好了,至此log的内容也结束了,是不是感觉自己棒棒哒~其实,无论什么时候,都不要感到害怕,要相信“世上无难事只怕有心人”。
下面,我们继续搭建,这次要做的,是configHttp.py的内容。没错,我们开始配置接口文件啦!(终于写到接口了,是不是很开心啊~)
下面是接口文件中主要部分的内容,让我们一起来看看吧。
import requests
import readConfig as readConfig
from common.Log import MyLog as Log
localReadConfig = readConfig.ReadConfig()
class ConfigHttp:
def __init__(self):
global host, port, timeout
host = localReadConfig.get_http("baseurl")
port = localReadConfig.get_http("port")
timeout = localReadConfig.get_http("timeout")
self.log = Log.get_log()
self.logger = self.log.get_logger()
self.headers = {}
self.params = {}
self.data = {}
self.url = None
self.files = {}
def set_url(self, url):
self.url = host + url
def set_headers(self, header):
self.headers = header
def set_params(self, param):
self.params = param
def set_data(self, data):
self.data = data
def set_files(self, file):
self.files = file
# defined http get method
def get(self):
try:
response = requests.get(self.url, params=self.params, headers=self.headers, timeout=float(timeout))
# response.raise_for_status()
return response
except TimeoutError:
self.logger.error("Time out!")
return None
# defined http post method
def post(self):
try:
response = requests.post(self.url, headers=self.headers, data=self.data, files=self.files, timeout=float(timeout))
# response.raise_for_status()
return response
except TimeoutError:
self.logger.error("Time out!")
return None这里我们就挑重点来说吧。首先,可以看到,小编这次是用python自带的requests来进行接口测试的,相信有心的朋友已经看出来了,python+requests这个模式是很好用的,它已经帮我们封装好了测试接口的方法,用起来很方便。这里呢,我就拿get和post两个方法来说吧。(平时用的最多的就是这两个方法了,其他方法,大家可以仿照着自行扩展)
- get方法
接口测试中见到最多的就是get方法和post方法,其中,get方法用于获取接口的测试,说白了,就是说,使用get的接口,都不会对后台数据进行更改,而且get方法在传递参数后,url的格式是这样的:http://接口地址?key1=value1&key2=value2,是不是看起来很眼熟啊~(反正我看着它很眼熟~\(≧▽≦)/~啦啦啦),那我们要怎么使用它呢,请继续往下看。
对于requests提供的get方法,有几个常用的参数:
url:显而易见,就是接口的地址url啦
headers:定制请求头(headers),例如:content-type = application/x-www-form-urlencoded
params:用于传递测试接口所要用的参数,这里我们用python中的字典形式(key:value)进行参数的传递。
timeout:设置接口连接的最大时间(超过该时间会抛出超时错误)
现在,各个参数我们已经知道是什么意思了,剩下的就是往里面填值啦,是不是机械式的应用啊,哈哈,小编我就是这样机械般的学习的啦~
举个栗子:
url=‘http://api.shein.com/v2/member/logout’
header={‘content-type’: application/x-www-form-urlencoded}
param={‘user_id’: 123456,‘email’: 123456@163.com}
timeout=0.5
requests.get(url, headers=header, params=param, timeout=timeout)
- post方法
与get方法类似,只要设置好对应的参数,就可以了。下面就直接举个栗子,直接上代码吧:
url=‘http://api.shein.com/v2/member/login’
header={‘content-type’: application/x-www-form-urlencoded}
data={‘email’: 123456@163.com,‘password’: 123456}
timeout=0.5
requests.post(url, headers=header, data=data, timeout=timeout)
怎么样,是不是也很简单啊。这里我们需要说明一下,post方法中的参数,我们不在使用params进行传递,而是改用data进行传递了。哈哈哈,终于说完啦,下面我们来探(了)讨(解)下接口的返回值。
依然只说常用的返回值的操作。
text:获取接口返回值的文本格式
json():获取接口返回值的json()格式
status_code:返回状态码(成功为:200)
headers:返回完整的请求头信息(headers['name']:返回指定的headers内容)
encoding:返回字符编码格式
url:返回接口的完整url地址
以上这些,就是常用的方法啦,大家可自行取之。
关于失败请求抛出异常,我们可以使用“raise_for_status()”来完成,那么,当我们的请求发生错误时,就会抛出异常。在这里提醒下各位朋友,如果你的接口,在地址不正确的时候,会有相应的错误提示(有时也需要进行测试),这时,千万不能使用这个方法来抛出错误,因为python自己在链接接口时就已经把错误抛出,那么,后面你将无法测试期望的内容。而且程序会直接在这里当掉,以错误来计。(别问我怎么知道的,因为我就是测试的时候发现的)
好了。接口文件也讲完了,是不是感觉离成功不远了呢?嗯,如果各位已经看到了这里,那么恭喜大家,下面还有很长的路要走~哈哈哈,就是这么任性。(毕竟小编我为了让各位和我差不多的小白能够更容易理解,也是使出了体内的洪荒之力啦)
慢慢地长叹一口气,继续下面的内容。。。
快,我想学(看)习(看)common.py里的内容。
import os
from xlrd import open_workbook
from xml.etree import ElementTree as ElementTree
from common.Log import MyLog as Log
localConfigHttp = configHttp.ConfigHttp()
log = Log.get_log()
logger = log.get_logger()
# 从excel文件中读取测试用例
def get_xls(xls_name, sheet_name):
cls = []
# get xls file's path
xlsPath = os.path.join(proDir, "testFile", xls_name)
# open xls file
file = open_workbook(xlsPath)
# get sheet by name
sheet = file.sheet_by_name(sheet_name)
# get one sheet's rows
nrows = sheet.nrows
for i in range(nrows):
if sheet.row_values(i)[0] != u'case_name':
cls.append(sheet.row_values(i))
return cls
# 从xml文件中读取sql语句
database = {}
def set_xml():
if len(database) == 0:
sql_path = os.path.join(proDir, "testFile", "SQL.xml")
tree = ElementTree.parse(sql_path)
for db in tree.findall("database"):
db_name = db.get("name")
# print(db_name)
table = {}
for tb in db.getchildren():
table_name = tb.get("name")
# print(table_name)
sql = {}
for data in tb.getchildren():
sql_id = data.get("id")
# print(sql_id)
sql[sql_id] = data.text
table[table_name] = sql
database[db_name] = table
def get_xml_dict(database_name, table_name):
set_xml()
database_dict = database.get(database_name).get(table_name)
return database_dict
def get_sql(database_name, table_name, sql_id):
db = get_xml_dict(database_name, table_name)
sql = db.get(sql_id)
return sql上面就是我们common的两大主要内容了,什么?还不知道是什么吗?让我告诉你吧。
- 我们利用xml.etree.Element来对xml文件进行操作,然后通过我们自定义的方法,根据传递不同的参数取得不(想)同(要)的值。
- 利用xlrd来操作excel文件,注意啦,我们是用excel文件来管理测试用例的。
听起来会不会有点儿懵,小编刚学时也很懵,看文件就好理解了。
excel文件:

xml文件:

至于具体的方法,我就不再一点点讲解了,总觉得大家都懂(小编刚学,望谅解),只是我个人需要详细记录,以后容易温习。
接下来,我们看看数据库和发送邮件吧(也可根据需要,不写该部分内容)
先看老朋友“数据库”吧。
小编这次使用的是MySQL数据库,所以我们就以它为例吧。
import pymysql
import readConfig as readConfig
from common.Log import MyLog as Log
localReadConfig = readConfig.ReadConfig()
class MyDB:
global host, username, password, port, database, config
host = localReadConfig.get_db("host")
username = localReadConfig.get_db("username")
password = localReadConfig.get_db("password")
port = localReadConfig.get_db("port")
database = localReadConfig.get_db("database")
config = {
'host': str(host),
'user': username,
'passwd': password,
'port': int(port),
'db': database
}
def __init__(self):
self.log = Log.get_log()
self.logger = self.log.get_logger()
self.db = None
self.cursor = None
def connectDB(self):
try:
# connect to DB
self.db = pymysql.connect(**config)
# create cursor
self.cursor = self.db.cursor()
print("Connect DB successfully!")
except ConnectionError as ex:
self.logger.error(str(ex))
def executeSQL(self, sql, params):
self.connectDB()
# executing sql
self.cursor.execute(sql, params)
# executing by committing to DB
self.db.commit()
return self.cursor
def get_all(self, cursor):
value = cursor.fetchall()
return value
def get_one(self, cursor):
value = cursor.fetchone()
return value
def closeDB(self):
self.db.close()
print("Database closed!")这就是完整的数据库的文件啦。因为小编的需求对数据库的操作不是很复杂,所以这些已基本满足要求啦。注意下啦,在此之前,请朋友们先把pymysql装起来!pymysql装起来!pymysql装起来!(重要的事情说三遍),安装的方法很简单,由于小编是使用pip来管理python包安装的,所以只要进入python安装路径下的pip文件夹下,执行以下命令即可:
pip install pymysql
哈哈哈,这样我们就可以利用python链接数据库啦~(鼓个掌,庆祝下)
小伙伴们发现没,在整个文件中,我们并没有出现具体的变量值哦,为什么呢?没错,因为前面我们写了config.ini文件,所有的数据库配置信息都在这个文件内哦,是不是感觉很方便呢,以后就算变更数据库了,也只要修改config.ini文件的内容就可以了,结合前面测试用例的管理(excel文件),sql语句的存放(xml文件),还有接下来我们要说的,businessCommon.py和存放具体case的文件夹,那么我们就已经将数据和业务分开啦,哈哈哈,想想以后修改测试用例内容,sql语句神马的工作,再也不用每个case都修改,只要改几个固定的文件,是不是顿时开心了呢?(嗯,想笑就大声的笑吧)
回归上面的configDB.py文件,内容很简单,相信大家都能看得懂,就是连接数据库,执行sql,获取结果,最后关闭数据库,没有什么不一样的地方。
该谈谈邮件啦,你是不是也遇到过这样的问题:每次测试完之后,都需要给开发一份测试报告。那么,对于我这样的懒人,是不愿意老是找人家开发的,所以,我就想,每次测试完,我们可以让程序自己给开发人员发一封email,告诉他们,测试已经结束了,并且把测试报告以附件的形式,通过email发送给开发者的邮箱,这样岂不是爽哉!
所以,configEmail.py应运而生。当当当当……请看:
import os
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from datetime import datetime
import threading
import readConfig as readConfig
from common.Log import MyLog
import zipfile
import glob
localReadConfig = readConfig.ReadConfig()
class Email:
def __init__(self):
global host, user, password, port, sender, title, content
host = localReadConfig.get_email("mail_host")
user = localReadConfig.get_email("mail_user")
password = localReadConfig.get_email("mail_pass")
port = localReadConfig.get_email("mail_port")
sender = localReadConfig.get_email("sender")
title = localReadConfig.get_email("subject")
content = localReadConfig.get_email("content")
self.value = localReadConfig.get_email("receiver")
self.receiver = []
# get receiver list
for n in str(self.value).split("/"):
self.receiver.append(n)
# defined email subject
date = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
self.subject = title + " " + date
self.log = MyLog.get_log()
self.logger = self.log.get_logger()
self.msg = MIMEMultipart('mixed')
def config_header(self):
self.msg['subject'] = self.subject
self.msg['from'] = sender
self.msg['to'] = ";".join(self.receiver)
def config_content(self):
content_plain = MIMEText(content, 'plain', 'utf-8')
self.msg.attach(content_plain)
def config_file(self):
# if the file content is not null, then config the email file
if self.check_file():
reportpath = self.log.get_result_path()
zippath = os.path.join(readConfig.proDir, "result", "test.zip")
# zip file
files = glob.glob(reportpath + '\*')
f = zipfile.ZipFile(zippath, 'w', zipfile.ZIP_DEFLATED)
for file in files:
f.write(file)
f.close()
reportfile = open(zippath, 'rb').read()
filehtml = MIMEText(reportfile, 'base64', 'utf-8')
filehtml['Content-Type'] = 'application/octet-stream'
filehtml['Content-Disposition'] = 'attachment; filename="test.zip"'
self.msg.attach(filehtml)
def check_file(self):
reportpath = self.log.get_report_path()
if os.path.isfile(reportpath) and not os.stat(reportpath) == 0:
return True
else:
return False
def send_email(self):
self.config_header()
self.config_content()
self.config_file()
try:
smtp = smtplib.SMTP()
smtp.connect(host)
smtp.login(user, password)
smtp.sendmail(sender, self.receiver, self.msg.as_string())
smtp.quit()
self.logger.info("The test report has send to developer by email.")
except Exception as ex:
self.logger.error(str(ex))
class MyEmail:
email = None
mutex = threading.Lock()
def __init__(self):
pass
@staticmethod
def get_email():
if MyEmail.email is None:
MyEmail.mutex.acquire()
MyEmail.email = Email()
MyEmail.mutex.release()
return MyEmail.email
if __name__ == "__main__":
email = MyEmail.get_email()
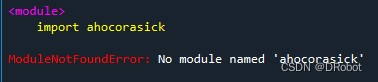
这里就是完整的文件内容了,不过可惜的是,小编我遇到一个问题,至今未解,在这里提出,希望大神给出解决办法!跪求啦!
问题:使用163免费邮箱服务器进行邮件的发送,但是,每次发送邮件,都会被163邮件服务器退信,抛出的错误码是:554
官方说明如下:

但是,however,but……小编在整合email进本框架之前写的发送email的小demo是可以正常发送邮件的。这个问题困扰着我,目前仍没有解决,望大神赐教。
离成功不远了,简单说明下HTMLTestRunner.py文件,这个文件呢,也不是小编写的,小编只是它的搬运工,哈哈哈,这个文件是从网上下载的,大神写好的,用于生成html格式的测试报告,什么?想知道生成测试报告的样子?好,这就满足好奇的你:

看上去不错吧,嗯,聪明的你们,也可以自己去探索下这个文件,修改修改,变成你自己的style哦~
好了,重头戏来了,就是我们的runAll.py啦。请看主角登场。
这是我们整个框架运行的入口,上面内容完成后,这是最后一步啦,写完它,我们的框架就算是完成了。(鼓掌,撒花~)
import unittest
import HTMLTestRunner
def set_case_list(self):
fb = open(self.caseListFile)
for value in fb.readlines():
data = str(value)
if data != '' and not data.startswith("#"):
self.caseList.append(data.replace("\n", ""))
fb.close()
def set_case_suite(self):
self.set_case_list()
test_suite = unittest.TestSuite()
suite_model = []
for case in self.caseList:
case_file = os.path.join(readConfig.proDir, "testCase")
print(case_file)
case_name = case.split("/")[-1]
print(case_name+".py")
discover = unittest.defaultTestLoader.discover(case_file, pattern=case_name + '.py', top_level_dir=None)
suite_model.append(discover)
if len(suite_model) > 0:
for suite in suite_model:
for test_name in suite:
test_suite.addTest(test_name)
else:
return None
return test_suite
def run(self):
try:
suit = self.set_case_suite()
if suit is not None:
logger.info("********TEST START********")
fp = open(resultPath, 'wb')
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title='Test Report', description='Test Description')
runner.run(suit)
else:
logger.info("Have no case to test.")
except Exception as ex:
logger.error(str(ex))
finally:
logger.info("*********TEST END*********")
# send test report by email
if int(on_off) == 0:
self.email.send_email()
elif int(on_off) == 1:
logger.info("Doesn't send report email to developer.")
else:
logger.info("Unknow state.")
上面我贴出了runAll里面的主要部分,首先我们要从caselist.txt文件中读取需要执行的case名称,然后将他们添加到python自带的unittest测试集中,最后执行run()函数,执行测试集。
终于呢,整个接口自动化框架已经讲完了,大家是不是看明白了呢?什么?之前的之前贴出的目录结构中的文件还有没说到的?嘿嘿,,,相信不用小编多说,大家也大概知道了,剩下文件夹的作用了。嗯~思索万千,还是决定简单谈谈吧。直接上图,简单明了:

result文件夹会在首次执行case时生成,并且以后的测试结果都会被保存在该文件夹下,同时每次测试的文件夹都是用系统时间命名,里面包含了两个文件,log文件和测试报告。

testCase文件夹下,存放我们写的具体的测试case啦,上面这些就是小编写的一些。注意喽,所有的case名称都要以test开头来命名哦,这是因为,unittest在进行测试时会自动匹配testCase文件夹下面所有test开头的.py文件

testFile文件夹下,放置我们测试时用来管理测试用例的excel文件和用于数据库查询的sql语句的xml文件哦。
最后就是caselist.txt文件了,就让你们瞄一眼吧:
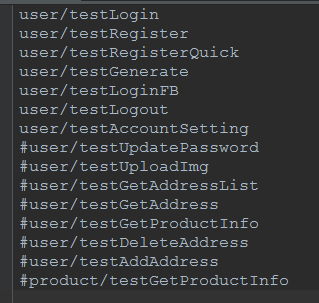
凡是没有被注释掉的,都是要被执行的case名称啦。在这里写上你要执行的case名称就可以啦。
Python接口自动化测试零基础入门到精通(2023最新版)