文章目录
- 项目介绍(开发背景)
- 主要用到的技术点
- 前端
- 后端
- Ansj分词
- 实现索引模块
- 实现Parser类
- 实现Index类
- 完善Parser类
- 优化制作索引速度
- 实现搜索模块
- 实现DocSearcher类
- 处理暂停词
- 项目编写过程中遇到的困难点
- 上传部署
- 总结
项目介绍(开发背景)
相信很多小伙伴在学习Java的过程中都会参考Java官方文档,但是这个文档存在一个问题,就是不支持用户对某个关键词进行搜索,只能够通过某个包去找到其中的某个类进行查看,显然这样的效率是比较低的。
虽然也有很多是离线的api文档是支持搜索功能的,但是我想做一个类似与百度的搜索界面,点击跳转到详细文档的效果。对此,我参考了百度搜索的页面,初步得到一个结论:搜索引擎是先输入一个查询词,会得到若干个结果,每个结果都会包含标题、部分描述展示、url等,点击标题即可完成页面跳转。
主要用到的技术点
前端
这个项目前端代码是比较简单的,只有一个页面(因为本项目只做的是搜索引擎实现的逻辑,得到结果后跳转的是官方文档详细页),数据的请求也是使用jQuery来实现的。
后端
后端部分是整个搜索引擎项目的核心部分,具体开发的流程如下:
Ansj分词
我们在输入查询词的时候,不仅仅只会是输入一个词,更有可能的是会查询一个句子,那么这时候就需要进行一个分词操作了。
我们可以选择使用一个开源的分词库,我这里选择的是Ansj,简单来说,其实就是导入一个依赖包即可:
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.6</version>
</dependency>
实现索引模块
实现Parser类
Parser类负责读取html文件,制作并生成索引数据(输出到文件中),主要的步骤:1. 从制定的路径中枚举出所有文件;2. 读取每一个文件,并从文件中解析出标题、正文内容、url。
//Description: 解析api文档的内容,完成索引的制作
public class Parser {
//指定加载文档的路径
private static final String INPUT_PATH = "D:/java_code/java-api/java8/docs/api/";
private Index index = new Index();
public void run(){
//根据指定的路径,枚举出该路径下的所有html文件(包括子目录中的所有文件)
List<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH, fileList);
//打开对应的文件,读取文件内容,进行解析并构建索引
long begin = System.currentTimeMillis();
for(File file : fileList){
//解析html文件
System.out.println("开始解析:" + file.getAbsolutePath());
parseHTML(file);
}
long end = System.currentTimeMillis();
System.out.println("遍历文件加入到索引中消耗的时间:" + (end - begin) + "ms");
}
private void parseHTML(File file) {
//解析标题、正文、url
String title = parseTitle(file);
//String content = parseContent(file);
String content = parseContentByRegex(file);
String url = parseUrl(file);
}
//解析url
private String parseUrl(File file) {
String part1 = "https://docs.oracle.com/javase/8/docs/api/";
String part2 = file.getAbsolutePath().substring(INPUT_PATH.length());
return part1 + part2;
}
//解析标题
private String parseTitle(File file) {
String name = file.getName();
return name.substring(0, name.length() - ".html".length());
}
//解析正文
private String parseContent(File file) {
try {
//手动将缓冲区设置成1M大小
BufferedReader bufferedReader = new BufferedReader(new FileReader(file), 1024 * 1024);
boolean flag = true;
StringBuilder content = new StringBuilder();
while(true){
int t = bufferedReader.read();
if(t == -1){
break;
}
char ch = (char)t;
if(flag){
if(ch == '<'){
flag = false;
continue;
}
if(ch == '\n' || ch == '\r'){
ch = ' ';
}
content.append(ch);
}else{
if(ch == '>'){
flag = true;
}
}
}
bufferedReader.close(); //记得文件的关闭
return content.toString();
} catch (IOException e) {
e.printStackTrace();
}
return "";
}
//递归完成目录的枚举
private void enumFile(String inputPath, List<File> fileList) {
File rootPath = new File(inputPath);
File[] files = rootPath.listFiles();
for(File file : files){
if(file.isDirectory()){
enumFile(file.getAbsolutePath(), fileList);
}else{
if(file.getAbsolutePath().endsWith(".html")) {
fileList.add(file);
}
}
}
}
public static void main(String[] args) throws InterruptedException {
Parser parser = new Parser();
parser.runByThread();
}
}
实现Index类
Index类负责构建索引数据结构,其中需要包含的方法有:getDocInfo(根据docId查正排)、getInverted(根据关键词查倒排)、addDoc(往索引中新增一个文档,构建正排索引和倒排索引)、save(往磁盘中写索引数据)、load(从磁盘中加载索引数据)。
整个搜索的核心思路其实就在这个类中,对于搜索的思路主要有两种:一种是直接进行暴力搜索,每次处理搜索请求的时候,拿着查询词到所有网页中都搜索一遍,并检查每个网页中是否包含查询词字符串,但是随着文档数量不断的增加,这种方法所需要的开销是非常大的,而对于搜索引擎来说,效率往往都是放在第一位的,因此该方法是不可行的;另外一种是建立倒排索引,倒排索引是一种专门针对搜索引擎场景所设计的数据结构,可以通过文档的信息来制定排序规则。
从构建倒排索引和根据关键词查倒排这两个步骤中可以看出一个问题,那就是倒排索引需要使用什么规则来构建呢?直接按照插入文档的顺序来构建显然是不行的,我们在百度搜索的时候会看到排在前面的都是比较重要的或者是搜索次数比较多的,因此,我们在构建倒排索引的时候不能仅仅按照插入顺序,而是应该自定义一个权重,我在这个项目中定义的权重是按照搜索词在文档中出现的次数(标题出现+10,正文出现+1的规则)来实行的。以下是定义权重的类:
public class Weight {
private int docId;
private int weight;
public int getDocId() {
return docId;
}
public void setDocId(int docId) {
this.docId = docId;
}
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
}
}
构建出Index类的基本骨架:
public class Index {
private static String INDEX_PATH = "D:/java_code/java-api/java8/";
private ObjectMapper objectMapper = new ObjectMapper();
private List<DocInfo> forwardIndex = new ArrayList<>(); //正排索引
private Map<String, List<Weight>> invertedIndex = new HashMap<>(); //倒排索引
//给定一个docId,通过正排索引查询到文档的详细信息
public DocInfo getDocInfo(int docId){
//TODO
}
//给定一个词,通过倒排索引查询哪些文档与这个词相关联
public List<Weight> getInverted(String term){
//TODO
}
//往索引中新增一个文档
public void addDoc(String title, String url, String content){
//TODO
}
//把内存中的索引结构保存到磁盘中
public void save(){
//TODO
}
//把磁盘中的索引数据加载到内存中
public void load(){
//TODO
}
}
查正排&查倒排:
//给定一个docId,通过正排索引查询到文档的详细信息
public DocInfo getDocInfo(int docId){
return forwardIndex.get(docId);
}
//给定一个词,通过倒排索引查询哪些文档与这个词相关联
public List<Weight> getInverted(String term){
return invertedIndex.get(term);
}
实现addDoc(构建正排索引和倒排索引):
//往索引中新增一个文档
public void addDoc(String title, String url, String content){
DocInfo docInfo = buildForward(title, url, content);
buildInverted(docInfo);
}
正排索引的构建是比较简单的,直接按照插入顺序进行构建即可:
private DocInfo buildForward(String title, String url, String content) {
DocInfo docInfo = new DocInfo();
docInfo.setTitle(title);
docInfo.setUrl(url);
docInfo.setContent(content);
docInfo.setDocId(forwardIndex.size());
forwardIndex.add(docInfo);
return docInfo;
}
倒排索引需要计算每个词的权重,我们这里可以使用哈希表来进行存储。
public class WordCnt {
private int titleCount;
private int contentCount;
public int getTitleCount() {
return titleCount;
}
public void setTitleCount(int titleCount) {
this.titleCount = titleCount;
}
public int getContentCount() {
return contentCount;
}
public void setContentCount(int contentCount) {
this.contentCount = contentCount;
}
}
private void buildInverted(DocInfo docInfo) {
//针对标题和正文进行分词(需要分开计算),并统计每个词出现的次数
Map<String, WordCnt> wordCntMap = new HashMap<>();
List<Term> terms = ToAnalysis.parse(docInfo.getTitle()).getTerms();
for(Term term : terms){
String word = term.getName();
if(!wordCntMap.containsKey(word)){
WordCnt wordCnt = new WordCnt();
wordCnt.setTitleCount(1);
wordCnt.setContentCount(0);
wordCntMap.put(word, wordCnt);
}else{
WordCnt wordCnt = wordCntMap.get(word);
wordCnt.setTitleCount(wordCnt.getTitleCount() + 1);
}
}
terms = ToAnalysis.parse(docInfo.getContent()).getTerms();
for(Term term : terms){
String word = term.getName();
if(!wordCntMap.containsKey(word)){
WordCnt wordCnt = new WordCnt();
wordCnt.setTitleCount(0);
wordCnt.setContentCount(1);
wordCntMap.put(word, wordCnt);
}else{
WordCnt wordCnt = wordCntMap.get(word);
wordCnt.setContentCount(wordCnt.getContentCount() + 1);
}
}
for(Map.Entry<String, WordCnt> entry : wordCntMap.entrySet()){
List<Weight> invertedList = invertedIndex.get(entry.getKey());
if(invertedList == null){
List<Weight> list = new ArrayList<>();
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
weight.setWeight(entry.getValue().getTitleCount() * 10 + entry.getValue().getContentCount());
list.add(weight);
invertedIndex.put(entry.getKey(), list);
}else{
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
weight.setWeight(entry.getValue().getTitleCount() * 10 + entry.getValue().getContentCount());
invertedList.add(weight);
}
}
}
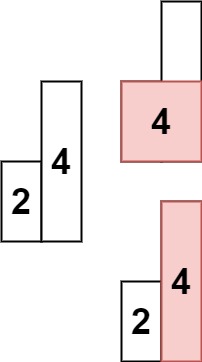
单看这段代码可以会有点绕,可以先看下图:
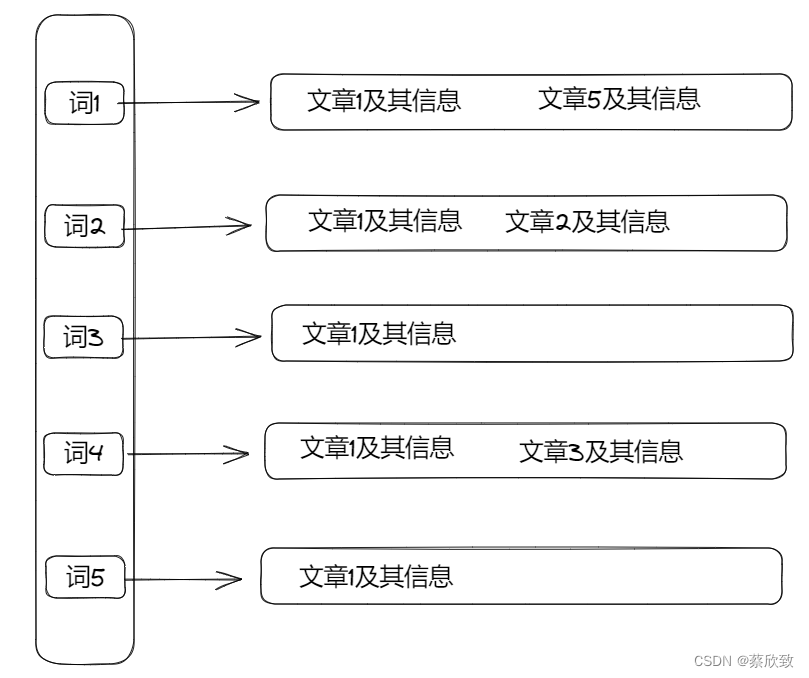
也就是说都有其对应的文章(可以多篇),这其实就类似于是一个哈希桶,当查询词是某个词的时候,就可以快速列出对应词下的文章,这就是倒排索引,当然,每一个节点中都包含了文章的信息(如词出现的次数等),方便后面对这些权重进行自定义排序。
实现save往磁盘中写索引数据(通过json格式来生成正排索引和倒排索引两个文件):
//把内存中的索引结构保存到磁盘中
public void save(){
//使用两个文件分别表示正排和倒排
//判断索引对应的文件是否存在,不存在就创建
long begin = System.currentTimeMillis();
File indexPathFile = new File(INDEX_PATH);
if(!indexPathFile.exists()){
indexPathFile.mkdirs();
}
File forwardIndexFile = new File(INDEX_PATH + "forward.txt");
File invertedIndexFile = new File(INDEX_PATH + "inverted.txt");
try {
objectMapper.writeValue(forwardIndexFile, forwardIndex);
objectMapper.writeValue(invertedIndexFile, invertedIndex);
} catch (IOException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("保存索引成功. 消耗时间:" + (end - begin) + "ms");
}
实现load将索引文件中的内容加载到内存中:
//把磁盘中的索引数据加载到内存中
public void load(){
long begin = System.currentTimeMillis();
File forwardIndexFile = new File(INDEX_PATH + "forward.txt");
File invertedIndexFile = new File(INDEX_PATH + "inverted.txt");
try {
forwardIndex = objectMapper.readValue(forwardIndexFile, new TypeReference<List<DocInfo>>() {});
invertedIndex = objectMapper.readValue(invertedIndexFile, new TypeReference<Map<String, List<Weight>>>() {});
} catch (IOException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("数据加载成功. 消耗时间:" + (end - begin) + "ms");
}
完善Parser类
接下来,我们可以在Parser类中实例化Index对象,在每次解析出信息的时候就调用Index对象添加到索引中,同时将内存中的索引数据保存到指定文件中:
private Index index = new Index();
private void parseHTML(File file) {
//解析标题、正文、url
String title = parseTitle(file);
//String content = parseContent(file);
String content = parseContentByRegex(file);
String url = parseUrl(file);
//将解析出的信息加入到索引中
index.addDoc(title, url, content);
}
public void run(){
//根据指定的路径,枚举出该路径下的所有html文件(包括子目录中的所有文件)
List<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH, fileList);
//打开对应的文件,读取文件内容,进行解析并构建索引
long begin = System.currentTimeMillis();
for(File file : fileList){
//解析html文件
System.out.println("开始解析:" + file.getAbsolutePath());
parseHTML(file);
}
long end = System.currentTimeMillis();
System.out.println("遍历文件加入到索引中消耗的时间:" + (end - begin) + "ms");
//内存中构造的索引数据结构保存到指定文件中
index.save();
}
优化制作索引速度
索引的制作是会比较耗时间的,特别是数据量大的时候,那么需要如何优化这个过程呢?显然,我们可以通过多线程来进行优化:
//实现多线程制作索引
public void runByThread() throws InterruptedException {
//根据指定的路径,枚举出该路径下的所有html文件(包括子目录中的所有文件)
List<File> fileList = new ArrayList<>();
enumFile(INPUT_PATH, fileList);
//打开对应的文件,读取文件内容,进行解析并构建索引(引入线程池)
CountDownLatch countDownLatch = new CountDownLatch(fileList.size());
ExecutorService executorService = Executors.newFixedThreadPool(4);
long begin = System.currentTimeMillis();
for(File file : fileList){
executorService.submit(new Runnable() {
@Override
public void run() {
//解析html文件
System.out.println("开始解析:" + file.getAbsolutePath());
parseHTML(file);
countDownLatch.countDown();
}
});
}
countDownLatch.await();
long end = System.currentTimeMillis();
System.out.println("遍历文件加入到索引中消耗的时间:" + (end - begin) + "ms");
executorService.shutdown(); //手动销毁线程池中的线程
//内存中构造的索引数据结构保存到指定文件中
index.save();
}
我这里创建的是4个线程(已经可以提升很高的效率了),需要注意的是:在使用多线程的时候需要检查代码中是否存在写操作,如果存在,需要对这个操作整体进行加锁操作。我们在检查代码的时候就发现有几个地方是需要修改的:
(1)在建立倒排索引的时候,我们需要不断地对出现词次数进行修改,所以在出现修改操作部分的代码都需要加上锁:
private void buildInverted(DocInfo docInfo) {
//针对标题和正文进行分词(需要分开计算),并统计每个词出现的次数
Map<String, WordCnt> wordCntMap = new HashMap<>();
List<Term> terms = ToAnalysis.parse(docInfo.getTitle()).getTerms();
for(Term term : terms){
synchronized (locker1){
String word = term.getName();
if(!wordCntMap.containsKey(word)){
WordCnt wordCnt = new WordCnt();
wordCnt.setTitleCount(1);
wordCnt.setContentCount(0);
wordCntMap.put(word, wordCnt);
}else{
WordCnt wordCnt = wordCntMap.get(word);
wordCnt.setTitleCount(wordCnt.getTitleCount() + 1);
}
}
}
terms = ToAnalysis.parse(docInfo.getContent()).getTerms();
for(Term term : terms){
synchronized (locker2){
String word = term.getName();
if(!wordCntMap.containsKey(word)){
WordCnt wordCnt = new WordCnt();
wordCnt.setTitleCount(0);
wordCnt.setContentCount(1);
wordCntMap.put(word, wordCnt);
}else{
WordCnt wordCnt = wordCntMap.get(word);
wordCnt.setContentCount(wordCnt.getContentCount() + 1);
}
}
}
for(Map.Entry<String, WordCnt> entry : wordCntMap.entrySet()){
synchronized (locker3){
List<Weight> invertedList = invertedIndex.get(entry.getKey());
if(invertedList == null){
List<Weight> list = new ArrayList<>();
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
weight.setWeight(entry.getValue().getTitleCount() * 10 + entry.getValue().getContentCount());
list.add(weight);
invertedIndex.put(entry.getKey(), list);
}else{
Weight weight = new Weight();
weight.setDocId(docInfo.getDocId());
weight.setWeight(entry.getValue().getTitleCount() * 10 + entry.getValue().getContentCount());
invertedList.add(weight);
}
}
}
}
(1)在建立正排索引的时候,我们也需要不断地对id进行修改,所以在出现修改操作部分的代码都需要加上锁:
private DocInfo buildForward(String title, String url, String content) {
DocInfo docInfo = new DocInfo();
docInfo.setTitle(title);
docInfo.setUrl(url);
docInfo.setContent(content);
synchronized (locker4){
docInfo.setDocId(forwardIndex.size());
forwardIndex.add(docInfo);
}
return docInfo;
}
实现搜索模块
实现DocSearcher类
简单介绍一下这个类需要实现的功能,这个类主要负责实现搜索功能,得到用户输入的查询词后,对查询词进行分词处理,之后对每一个分词都查找一下之前存的倒排索引,得到一个倒排哈希桶,将这些结构合并到一个结果集中,并对其中的这些结果按照指定的权重降序排序后返回结果即可。
public List<Result> search(String query){
//分词
List<Term> oldTerms = ToAnalysis.parse(query).getTerms();
List<Term> terms = new ArrayList<>();
//过滤
for(Term term : oldTerms){
terms.add(term);
}
//触发
List<List<Weight>> termResult = new ArrayList<>();
for(Term term : terms){
String word = term.getName();
List<Weight> invertedList = index.getInverted(word);
if(invertedList == null){
continue;
}
termResult.add(invertedList);
}
//合并
List<Weight> allTermResult = mergeResult(termResult);
//排序(降序)
allTermResult.sort((o1, o2) -> {
return o2.getWeight() - o1.getWeight();
});
//包装
List<Result> results = new ArrayList<>();
for(Weight weight : allTermResult){
DocInfo docInfo = index.getDocInfo(weight.getDocId());
Result result = new Result();
result.setTitle(docInfo.getTitle());
result.setUrl(docInfo.getUrl());
result.setDesc(GenDesc(docInfo.getContent(), terms));
results.add(result);
}
return results;
}
对于其中的合并操作,我们可以使用优先级队列来辅助实现(其实这就涉及到多路归并算法的思想):
private List<Weight> mergeResult(List<List<Weight>> source) {
//针对每一行进行排序(按照id升序排序)
for(List<Weight> curRow : source){
curRow.sort(new Comparator<Weight>(){
@Override
public int compare(Weight o1, Weight o2) {
return o1.getDocId() - o2.getDocId();
}
});
}
//使用优先级队列对每一行进行合并
List<Weight> target = new ArrayList<>();
PriorityQueue<Pos> queue = new PriorityQueue<>(new Comparator<Pos>() {
@Override
public int compare(Pos o1, Pos o2) {
return source.get(o1.row).get(o1.col).getDocId() - source.get(o2.row).get(o2.col).getDocId();
}
});
for(int row = 0; row < source.size(); row++){
queue.offer(new Pos(row, 0));
}
while(!queue.isEmpty()){
Pos minPos = queue.poll();
Weight curWeight = source.get(minPos.row).get(minPos.col);
if(target.size() > 0){
Weight lastWeight = target.get(target.size() - 1);
if(lastWeight.getDocId() == curWeight.getDocId()){
lastWeight.setWeight(lastWeight.getWeight() + curWeight.getWeight());
}else{
target.add(curWeight);
}
}else{
target.add(curWeight);
}
Pos newPos = new Pos(minPos.row, minPos.col + 1);
if(newPos.col >= source.get(newPos.row).size()){
continue;
}
queue.offer(newPos);
}
return target;
}
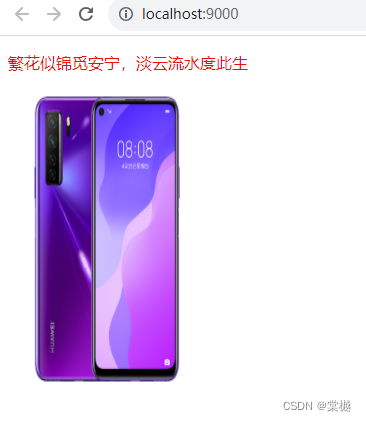
以下这段代码表示需要截取内容的部分简介显示到页面上:
private String GenDesc(String content, List<Term> terms) {
int firstPos = -1;
for(Term term : terms){
String word = term.getName();
content = content.toLowerCase().replaceAll("\\b" + word + "\\b", " " + word + " ");
firstPos = content.indexOf(" " + word + " ");
if(firstPos >= 0){
break;
}
}
if(firstPos == -1){
return content.substring(0, Math.min(60, content.length())) + "...";
}
String desc = "";
int descBeg = firstPos < 30 ? 0 : firstPos - 30;
desc = content.substring(descBeg, Math.min(descBeg + 100, content.length())) + "...";
for(Term term : terms){
String word = term.getName();
desc = desc.replaceAll("(?i) " + word + " ", "<i>" + " " + word + " " + "</i>");
}
return desc;
}
处理暂停词
我们在网上搜索到一些常见的暂停词后将它们保存到一个文件夹中,每次从文件中获取这些暂停词,看是否有存在于查询词中的,若有,直接跳过即可。
private static String STOP_WORD_PATH = "D:/java_code/java-api/java8/stop_word.txt";
private Set<String> stopWords = new HashSet<>();
将暂停词从磁盘加载到内存中:
public void loadStopWords(){
try {
BufferedReader bufferedReader = new BufferedReader(new FileReader(STOP_WORD_PATH));
while(true){
String line = bufferedReader.readLine();
if(line == null){
break;
}
stopWords.add(line);
}
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
之后就是补充上面search方法中的代码,在查询词中发现暂停词时,直接进行过滤操作:
//过滤
for(Term term : oldTerms){
if(stopWords.contains(term.getName())){
continue;
}
terms.add(term);
}
项目编写过程中遇到的困难点
这个项目是基础版的搜索引擎,所以总体来说是中规中矩的,没有特别难解决的问题,唯一一个比较难编写的是最后的使用多路归并算法来实现权重的合并。
上传部署
将打包后的jar包以及正排、倒排索引和暂停词放在同一个目录底下,输入命令:java -jar [jar包名]就可以打开SpringBoot项目;持久运行需要输入命令:nohup java -jar [jar包名] &。

总结
简单总结一下这个Java文档搜索引擎项目:
有点:使用了主流的SpringBoot框架进行开发,运用多线程来提高代码的运行效率,包含了基本搜索引擎中所需要的数据结构和算法。
缺点:扩展性弱,这个搜索引擎只能够针对Java文档进行搜索,比较合理的实现是需要搭配爬虫实现对页面数据的获取,当然,这个难度也是比较大的。
关于本项目的全部代码我都放在了我的个人Gitee账户下,有需要的可以点击查看:Java文档搜索引擎项目存放代码。