•开篇
最近使用Elasticsearch实现画像系统,实现的dmp的数据中台能力。同时调研了竞品的架构选型。以及重温了redis原理等。特此做一次es的总结和回顾。网上没看到有人用Elasticsearch来完成画像的。我来做第一次尝试。
背景说完,我们先思考一件事,使用内存系统做数据库。他的优点是什么?他的痛点是什么?
•一、原理
这里不在阐述全貌。只聊聊通讯、内存、持久化三部分。
通讯
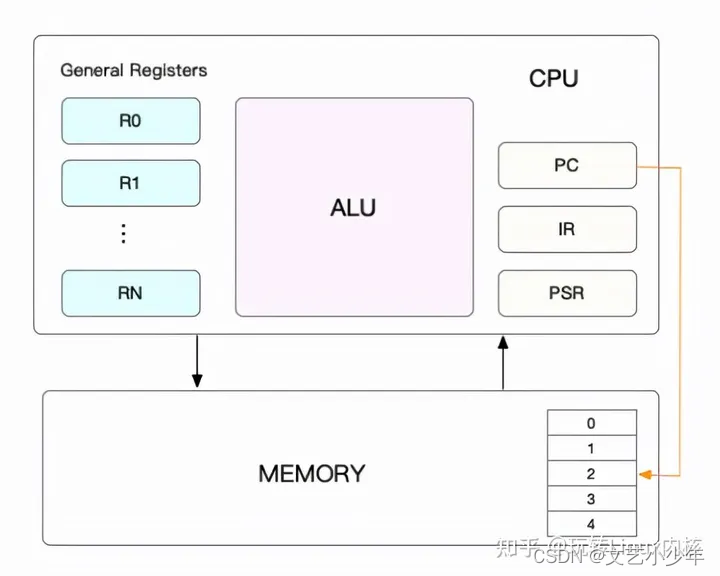
es集群最小单元是三个节点。两个从节点搭配保证其高可用也是集群化的基础。那么节点之间RPC通讯用的是什么?必然是netty,es基于netty实现了Netty4Transport的通讯包。初始化Transport后建立Bootstrap,通过MessageChannelHandler完成接收和转发。es里区分server和client,如图1。序列化使用的json。es在rpc设计上偏向于易用、通用、易理解。而不是单追求性能。
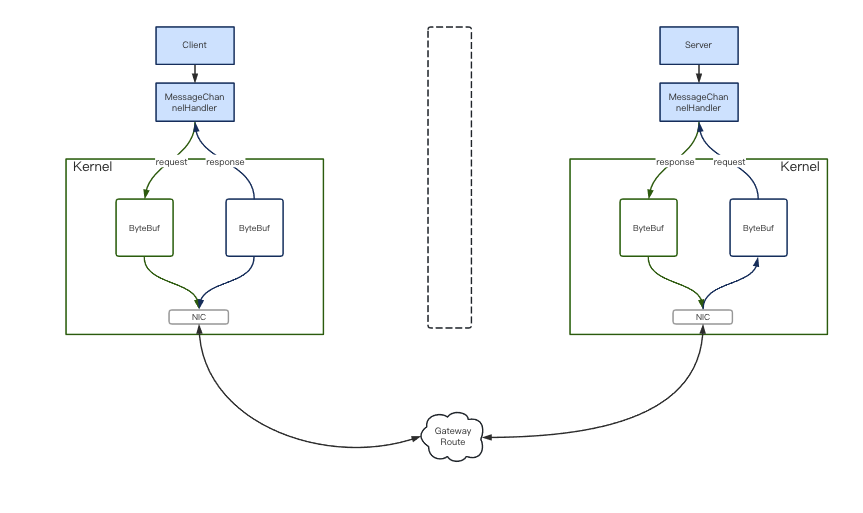
图1
有了netty的保驾护航使得es放心是使用json序列化。
内存
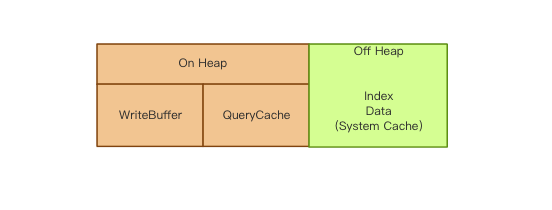
图2
es内存分为两部分【on heap】和【off heap】。on heap这部分由es的jvm管理。off heap则是由lucene管理。on heap 被分为两部分,一部分可以回收,一部分不能回收。
能回收的部分index buffer存储新的索引文档。当被填满时,缓冲区的文档会被写入到磁盘segment上。node上共享所有shards。
不能被回收的有node query cache、shard request cache、file data cache、segments cache
node query cache是node级缓存,过滤后保存在每个node上,被所有shards共享,使用bitset数据结构(布隆优化版)关掉了评分。使用的LRU淘汰策略。GC无法回收。
shard request cache是shard级缓存,每个shard都有。默认情况下该缓存只存储request结果size等于0的查询。所以该缓存不会被hits,但却缓存hits.total,aggregations,suggestions。可以通过clear cache api清除。使用的LRU淘汰策略。GC无法回收。
file data cache 是把聚合、排序后的data缓存起来。初期es是没有doc values的,所以聚合、排序后需要有一个file data来缓存,避免磁盘IO。如果没有足够内存存储file data,es会不断地从磁盘加载数据到内存,并删除旧的数据。这些会造成磁盘IO和引发GC。所以2.x之后版本引入doc values特性,把文档构建在indextime上,存储到磁盘,通过memory mapped file方式访问。甚至如果只关心hits.total,只返回doc id,关掉doc values。doc values支持keyword和数值类型。text类型还是会创建file data。
segments cache是为了加速查询,FST永驻堆内内存。FST可以理解为前缀树,加速查询。but!!es 7.3版本开始把FST交给了堆外内存,可以让节点支持更多的数据。FST在磁盘上也有对应的持久化文件。
off heap 即Segments Memory,堆外内存是给Lucene使用的。 所以建议至少留一半的内存给lucene。
es 7.3版本开始把tip(terms index)通过mmp方式加载,交由系统的pagecache管理。除了tip,nvd(norms),dvd(doc values), tim(term dictionary),cfs(compound)类型的文件都是由mmp方式加载传输,其余都是nio方式。tip off heap后的效果jvm占用量下降了78%左右。可以使用_cat/segments API 查看 segments.memory内存占用量。
由于对外内存是由操作系统pagecache管理内存的。如果发生回收时,FST的查询会牵扯到磁盘IO上,对查询效率影响比较大。可以参考linux pagecache的回收策略使用双链策略。
持久化
es的持久化分为两部分,一部分类似快照,把文件缓存中的segments 刷新(fsync)磁盘。另一部分是translog日志,它每秒都会追加操作日志,默认30分钟刷到磁盘上。es持久化和redis的RDB+AOF模式很像。如下图
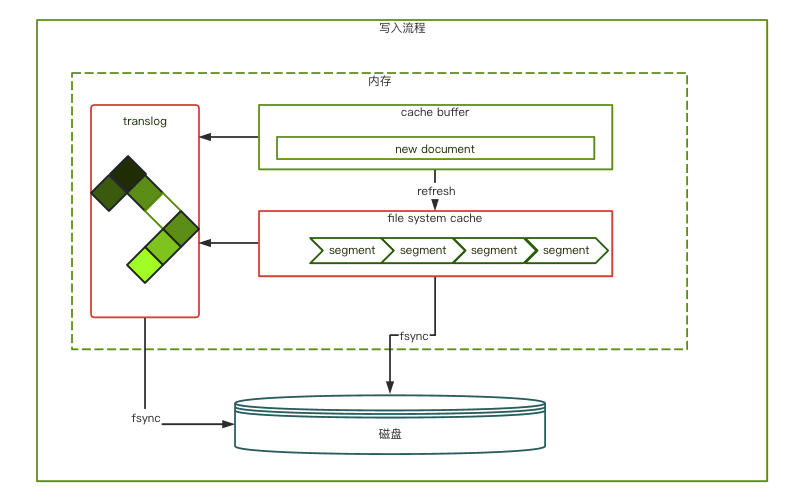
图3
上图是一个完整写入流程。磁盘也是分segment记录数据。这里濡染跟redis很像。但是内部机制没有采用COW(copy-on-write)。这也是查询和写入并行时load被打满的原因所在。
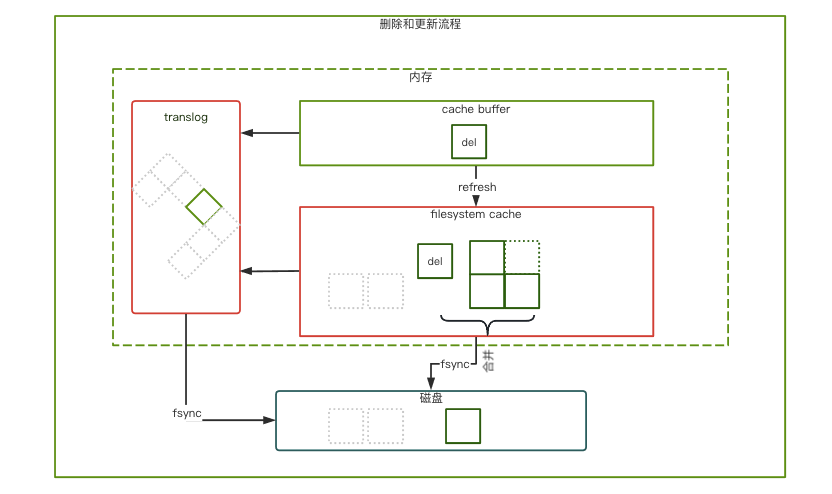
图4
如果删除操作,并不是马上物理清除被删除的文档,而是标记为delete状态;更新操作,标记原有的文档为delete状态,再插入一条新的文档。( 如图4)
系统中会产生很多的Segment file文件。所以定期要执行合并(merge)操作,将多个Segment file文件合并为一个。在合并的过程中,会将标记删除的文件进行物理删除操作。
ES记录每个Segment file文件的提交点(commit point),用于管理所有的Segment file文件。
小结
es内存和磁盘的设计上非常巧妙。零拷贝上采用mmap方式,磁盘数据映射到off heap,也就是lucene。为了加速数据的访问,es每个segment都有会一些索引数据驻留在off heap里;因此segment越多,瓜分掉的off heap也越多,这部分是无法被GC回收!
结合以上两点可以清楚知道为什么es非常吃内存了。
二、应用
用户画像系统中有以下难点需要解决。
1.人群预估:根据标签选出一类人群,如20-25岁的喜欢电商社交的男性。20-25岁∩电商社交∩男性。通过与或非的运算选出符合特征的clientId的个数。这是一组。
我们组与组之前也是可以在做交并差的运算。如既是20-25岁的喜欢电商社交的男性,又是北京市喜欢撸铁的男性。(20-25岁∩电商社交∩男性)∩(20-25岁∩撸铁∩男性)。对于这样的递归要求在17亿多的画像库中,秒级返回预估人数。
2.人群包圈选:上述圈选出的人群包。 要求分钟级构建。
3.人包判定:判断一个clientId是否存在若干个人群包中。要求10毫秒返回结果。
我们先尝试用es来解决以上所有问题。
人群预估,最容易想到方案是在服务端的内存中做逻辑运算。但是圈选出千万级的人群包人数秒级返回的话在服务端做代价非常大。这时候可以吧计算压力抛给es存储端,像查询数据库一样。使用一条语句查出我们想要的数据来。
例如mysql
select a.age from a where a.tel in (select b.age from b);
对应的es的dsl类似于
{"query":{"bool":{"must":[{"bool":{"must":[{"term":{"a9aa8uk0":{"value":"age18-24","boost":1.0}}},{"term":{"a9ajq480":{"value":"male","boost":1.0}}}],"adjust_pure_negative":true,"boost":1.0}},{"bool":{"adjust_pure_negative":true,"boost":1.0}}],"adjust_pure_negative":true,"boost":1.0}}}
这样使用es的高检索性能来满足业务需求。无论所少组,组内多少的标签。都打成一条dsl语句。来保证秒级返回结果。
使用官方推荐的RestHighLevelClient,实现方式有三种,一种是拼json字符串,第二种调用api去拼字符串。我使用第三种方式BoolQueryBuilder来实现,比较优雅。它提供了filter、must、should和mustNot方法。如
/**
* Adds a query that <b>must not</b> appear in the matching documents.
* No {@code null} value allowed.
*/
public BoolQueryBuilder mustNot(QueryBuilder queryBuilder) {
if (queryBuilder == null) {
throw new IllegalArgumentException("inner bool query clause cannot be null");
}
mustNotClauses.add(queryBuilder);
return this;
}
/**
* Gets the queries that <b>must not</b> appear in the matching documents.
*/
public List<QueryBuilder> mustNot() {
return this.mustNotClauses;
}
使用api的可以大大的show下编代码的能力。
构建人群包。目前我们圈出最大的包有7千多万的clientId。想要分钟级别构建完(7千万数据在条件限制下35分钟构建完)需要注意两个地方,一个是es深度查询,另一个是批量写入。
es分页有三种方式,深度分页有两种,后两种都是利用游标(scroll和search_after)滚动的方式检索。
scroll需要维护游标状态,每一个线程都会创建一个32位唯一scroll id,每次查询都要带上唯一的scroll id。如果多个线程就要维护多个游标状态。search_after与scroll方式相似。但是它的参数是无状态的,始终会针对对新版本的搜索器进行解析。它的排序顺序会在滚动中更改。scroll原理是将doc id结果集保留在协调节点的上下文里,每次滚动分批获取。只需要根据size在每个shard内部按照顺序取回结果即可。
写入时使用线程池来做,注意使用的阻塞队列的大小,还要选择适的拒绝策略(这里不需要抛异常的策略)。批量如果还是写到es中(比如做了读写分离)写入时除了要多线程外,还有优化写入时的refresh policy。
人包判定接口,由于整条业务链路非常长,这块检索,上游服务设置的熔断时间是10ms。所以优化要优化es的查询(也可以redis)毕竟没负责逻辑处理。使用线程池解决IO密集型优化后可以达到1ms。tp99高峰在4ms。
•三、优化、瓶颈与解决方案
以上是针对业务需求使用es的解题方式。还需要做响应的优化。同时也遇到es的瓶颈。
1.首先是mapping的优化。画像的mapping中fields中的type是keyword,index要关掉。人包中的fields中的doc value关掉。画像是要精确匹配;人包判定只需要结果而不需要取值。es api上人包计算使用filter去掉评分,filter内部使用bitset的布隆数据结构,但是需要对数据预热。写入时线程不易过多,和核心数相同即可;调整refresh policy等级。手动刷盘,构建时index.refresh_interval 调整-1,需要注意的是停止刷盘会加大堆内存,需要结合业务调整刷盘频率。构建大的人群包可以将index拆分成若干个。分散存储可以提高响应。目前几十个人群包还是能支撑。如果日后成长到几百个的时候。就需要使用bitmap来构建存储人群包。es对检索性能很卓越。但是如遇到写操作和查操作并行时,就不是他擅长的。比如人群包的数据是每天都在变化的。这个时候es的内存和磁盘io会非常高。上百个包时我们可以用redis来存。也可以选择使用MongoDB来存人包数据。
四、总结
以上是我们使用Elasticsearch来解决业务上的难点。同时发现他的持久化没有使用COW(copy-on-write)方式。导致在实时写的时候检索性能降低。
使用内存系统做数据源有点非常明显,就是检索块!尤其再实时场景下堪称利器。同时痛点也很明显,实时写会拉低检索性能。当然我们可以做读写分离,拆分index等方案。
除了Elasticsearch,我们还可以选用ClickHouse,ck也是支持bitmap数据结构。甚至可以上Pilosa,pilosa本就是BitMap Database。










![[HCTF 2018]WarmUp最详细解释](https://img-blog.csdnimg.cn/d18294d527f648e9b6698de8f65819eb.png)
![[unity]切换天空盒](https://img-blog.csdnimg.cn/038a37cba1934496b06f5f9cffb6d338.png)
