官网
文档 v1.18.0
下载
数据流上的状态计算(Stateful Computations over Data Streams)
Apache Flink是一个框架和分布式处理引擎,用于无界和有界数据流的有状态计算。Flink被设计成可以在所有常见的集群环境中运行,以内存中的速度和任何规模执行计算。
Flink功能
- 保证正确性(Correctness guarantees)
恰好一次状态一致性
事件时间处理
复杂的后期数据处理 - 分层的api (Layered APIs)
SQL on Stream & Batch Data
DataStream API & DataSet API
ProcessFunction (Time & State) - Operational focus
灵活的部署
高可用性的设置
保存点 - 可伸缩性
水平扩展架构
支持非常大的状态
增量备份(Incremental Checkpoints) - 性能
低延时
高吞吐量
内存计算
应用场景
- 事件驱动应用程序
事件驱动的应用程序是一种有状态的应用程序,它从一个或多个事件流中捕获事件,并通过触发计算、状态更新或外部操作来响应传入的事件。 - 流和批处理分析
分析工作从原始数据中提取信息和见解。Apache Flink支持对有界数据集的传统批量查询,以及对无界实时数据流的实时连续查询。 - 数据管道和ETL
提取-转换-加载(ETL)是在存储系统之间转换和移动数据的常用方法。
1、第一步
Flink旨在以闪电般的速度处理连续的数据流。这个简短的指南将向您展示如何下载Flink的最新稳定版本,安装和运行它。您还将运行一个示例Flink作业并在web UI中查看它。
1.1 下载Flink
注意:Flink也可以作为Docker镜像使用
Flink运行在所有类unix环境中,即Linux, Mac OS X和Cygwin(用于Windows)。您需要安装Java 11。要检查已安装的Java版本,请在终端输入:
$ java -version
接下来,下载最新的Flink二进制版本,然后提取存档:
$ tar -xzf flink-*.tgz
1.2 浏览项目目录
导航到解压的目录,并通过发出以下命令列出内容:
$ cd flink-* && ls -l
您应该看到如下内容:
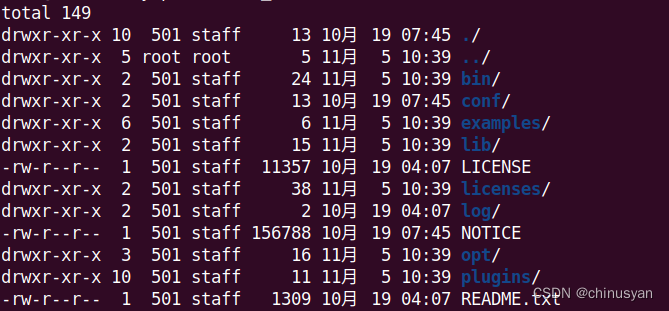
现在,您可能需要注意:
bin/目录包含flink二进制文件以及管理各种作业和任务的bash脚本。conf/目录包含配置文件,包括flink-conf.yamlexamples/目录包含可以与Flink一起使用的示例应用程序
1.3 启动和停止本地集群
要启动本地集群,请运行Flink附带的bash脚本:
$ ./bin/start-cluster.sh
你应该看到这样的输出:

Flink现在作为后台进程运行。可以使用以下命令查看其状态:
$ ps aux | grep flink
您应该能够导航到localhost:8081的web UI来查看Flink仪表板,并看到集群已经启动并运行。
要快速停止集群和所有正在运行的组件,可以使用下面的脚本:
$ ./bin/stop-cluster.sh
1.4 提交Flink job
Flink提供了一个CLI工具bin/Flink,它可以运行打包为Java archive (JAR)的程序并控制它们的执行。提交任务(job)意味着将作业的JAR文件和相关依赖项上传到正在运行的Flink集群并执行它。
Flink版本附带了示例作业,您可以在examples/文件夹中找到它们。
要将示例单词计数任务部署到正在运行的集群,请执行以下命令:
$ ./bin/flink run examples/streaming/WordCount.jar
# ./bin/flink run examples/streaming/WordCount.jar
Executing example with default input data.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID 2a2503cde256732dd86e28feb0a555b5
Program execution finished
Job with JobID 2a2503cde256732dd86e28feb0a555b5 has finished.
Job Runtime: 3454 ms
您可以通过查看日志来验证输出结果:
$ tail log/flink-*-taskexecutor-*.out
样例输出:
# tail -f ./log/flink-root-taskexecutor-0-bj.out
(to,1)
(be,1)
(or,1)
(not,1)
(to,2)
(be,2)
(that,1)
(is,1)
(the,1)
(question,1)
(whether,1)
(tis,1)
(nobler,1)
(in,1)
(the,2)
(mind,1)
(to,3)
(suffer,1)
(the,3)
(slings,1)
(and,1)
此外,您可以检查Flink的web UI来监视集群和正在运行的作业的状态。
您可以查看执行的数据流计划:
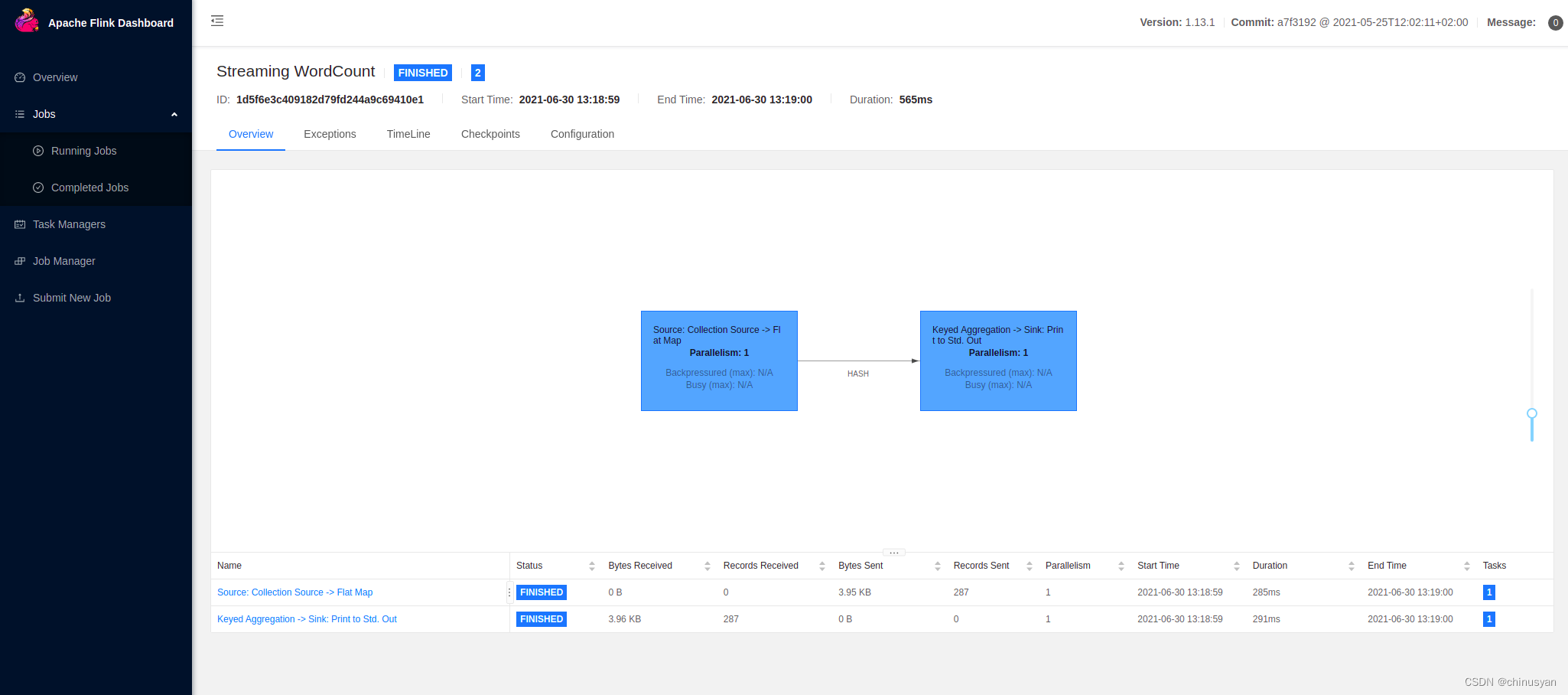
对于任务执行,Flink有两个操作符。第一个是源操作符,它从集合源读取数据。第二个运算符是转换运算符,它聚合单词的计数。了解有关数据流操作符的更多信息。
您还可以查看作业执行的时间轴:
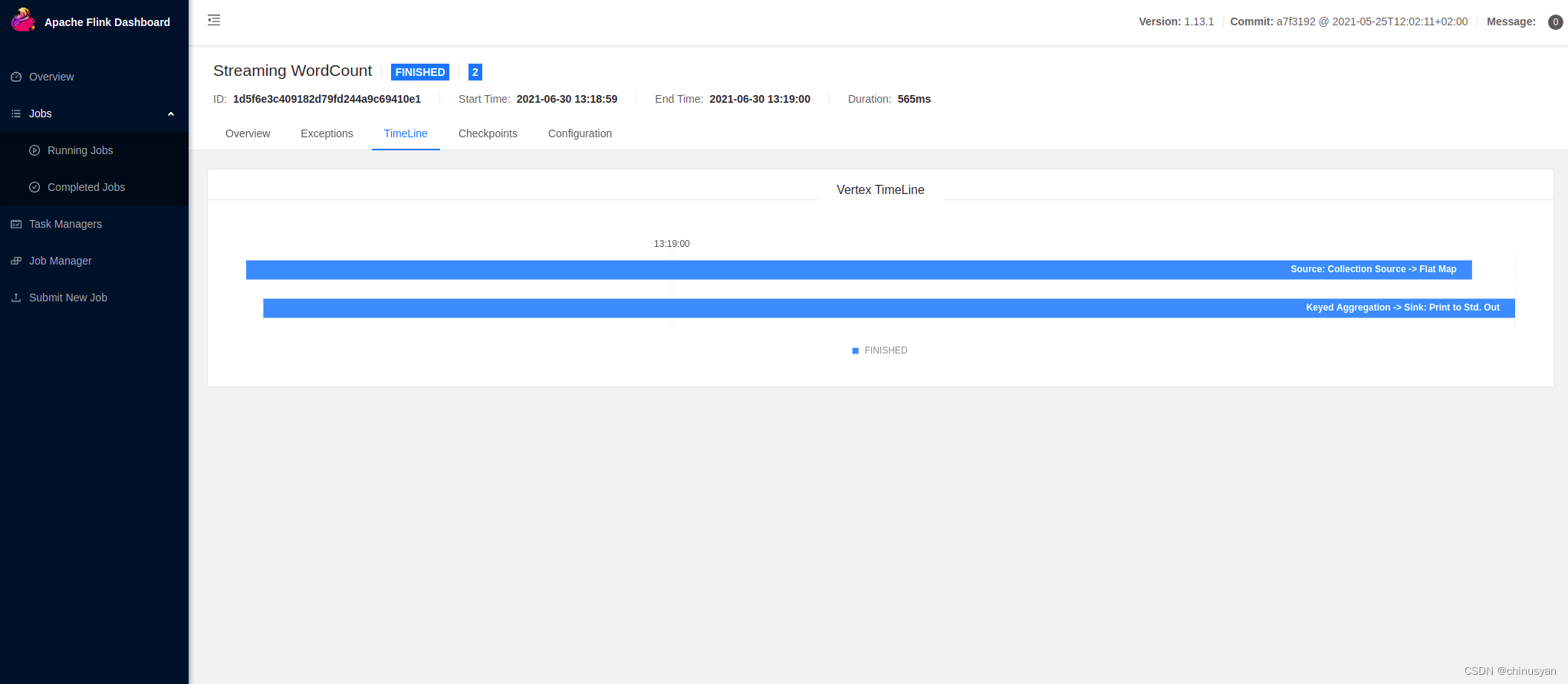
您已经成功运行了Flink应用程序!您可以随意从示例/文件夹中选择任何其他JAR归档文件,或者部署您自己的作业!
1.5 远程访问
# 将远程 rest.bind-address 配置为 0.0.0.0
rest.bind-address: 0.0.0.0
2、使用数据流API进行欺诈检测
Apache Flink提供了一个数据流API,用于构建健壮的、有状态的流应用程序。它提供了对状态和时间的细粒度控制,从而允许实现高级事件驱动系统。在这个分步指南中,您将学习如何使用Flink的DataStream API构建有状态流应用程序。
2.1 你在构造什么?
在数字时代,信用卡诈骗日益受到关注。犯罪分子通过诈骗或侵入不安全的系统来窃取信用卡号码。被盗号码的测试方法是进行一次或多次小额购买,通常是一美元或更少。如果这种方法有效,他们就会进行更大的购买,以获得可以出售或保留给自己的物品。
在本教程中,您将构建一个欺诈检测系统,用于对可疑的信用卡交易发出警报。使用一组简单的规则,您将看到Flink如何允许我们实现高级业务逻辑和实时操作。
2.2 前提条件
本演练假设您对Java有一定的了解,但是即使您使用的是不同的编程语言,也应该能够跟上。
在IDE中运行
在IDE中运行项目可能会导致java.lang.NoClassDefFoundError异常。这可能是因为您没有将所有必需的Flink依赖项隐式加载到类路径中。
- IntelliJ IDEA: Run > Edit Configurations > Modify options > Select
include dependencies with "Provided" scope.。这个运行配置现在将包含从IDE中运行应用程序所需的所有类。
2.3 遇到困难
如果遇到困难,请查看社区支持资源。特别是,Apache Flink的用户邮件列表一直被评为Apache项目中最活跃的邮件列表之一,也是快速获得帮助的好方法。
2.4 如何跟进
如果你想跟着做,你需要一台电脑,上面有:
- Java 11
- Maven
提供的Flink Maven原型将快速创建包含所有必要依赖项的框架项目,因此您只需要专注于填写业务逻辑。这些依赖项包括flink-streaming-java,它是所有Flink流应用程序的核心依赖项,以及flink-walkthrough-common,它具有特定于此演练的数据生成器和其他类。
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-walkthrough-datastream-java \
-DarchetypeVersion=1.18.0 \
-DgroupId=frauddetection \
-DartifactId=frauddetection \
-Dversion=0.1 \
-Dpackage=spendreport \
-DinteractiveMode=false
如果愿意,您可以编辑groupId、artifactId和package。使用上述参数,Maven将创建一个名为frauddetection的文件夹,其中包含一个项目,其中包含完成本教程所需的所有依赖项。将项目导入编辑器后,您可以找到包含以下代码的文件FraudDetectionJob.java,您可以直接在IDE中运行该文件。尝试在整个数据流中设置断点,并在DEBUG模式下运行代码,以感受一切是如何工作的。
FraudDetectionJob.java
package spendreport;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.walkthrough.common.sink.AlertSink;
import org.apache.flink.walkthrough.common.entity.Alert;
import org.apache.flink.walkthrough.common.entity.Transaction;
import org.apache.flink.walkthrough.common.source.TransactionSource;
public class FraudDetectionJob {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Transaction> transactions = env
.addSource(new TransactionSource())
.name("transactions");
DataStream<Alert> alerts = transactions
.keyBy(Transaction::getAccountId)
.process(new FraudDetector())
.name("fraud-detector");
alerts
.addSink(new AlertSink())
.name("send-alerts");
env.execute("Fraud Detection");
}
}
FraudDetector.java
package spendreport;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.walkthrough.common.entity.Alert;
import org.apache.flink.walkthrough.common.entity.Transaction;
public class FraudDetector extends KeyedProcessFunction<Long, Transaction, Alert> {
private static final long serialVersionUID = 1L;
private static final double SMALL_AMOUNT = 1.00;
private static final double LARGE_AMOUNT = 500.00;
private static final long ONE_MINUTE = 60 * 1000;
@Override
public void processElement(
Transaction transaction,
Context context,
Collector<Alert> collector) throws Exception {
Alert alert = new Alert();
alert.setId(transaction.getAccountId());
collector.collect(alert);
}
}
2.5 解析代码
让我们一步一步地浏览这两个文件的代码。FraudDetectionJob类定义了应用程序的数据流,而FraudDetector类定义了检测欺诈交易的功能的业务逻辑。
我们开始描述如何在FraudDetectionJob类的main 方法中组装Job。
The Execution Environment
第一行设置了StreamExecutionEnvironment。执行环境是您为 Job设置属性、创建源并最终触发作业执行的方式。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
创建一个数据源
源将来自外部系统(如Apache Kafka、Rabbit MQ或Apache Pulsar)的数据摄取到Flink Job中。本演练使用一个源,该源生成无限的信用卡事务流供您处理。每个事务包含一个帐户ID (accountId)、事务发生时间的时间戳(timestamp)和美元金额(amount)。附加到源代码的name 只是为了调试,所以如果出现问题,我们将知道错误的来源。
DataStream<Transaction> transactions = env
.addSource(new TransactionSource())
.name("transactions");
分区事件&检测欺诈
transactions 流包含来自大量用户的大量事务,因此需要由多个欺诈检测任务并行处理。由于欺诈是在每个帐户的基础上发生的,因此必须确保同一帐户的所有事务都由欺诈检测器操作员的相同并行任务处理。
为了确保相同的物理任务处理特定键的所有记录,您可以使用DataStream#keyBy对流进行分区。process()调用添加一个operator ,该操作符将函数应用于流中的每个分区元素。通常说,紧跟在keyBy之后的操作符(在本例中是FraudDetector)是在有键的上下文(keyed context)中执行的。
DataStream<Alert> alerts = transactions
.keyBy(Transaction::getAccountId)
.process(new FraudDetector())
.name("fraud-detector");
输出结果
sink 将数据流(DataStream)写入外部系统;比如Apache Kafka、Cassandra和AWS Kinesis。AlertSink以INFO级别记录每个Alert记录,而不是将其写入持久存储,因此您可以轻松看到结果。
alerts.addSink(new AlertSink());
欺诈检测器(Fraud Detector )
欺诈检测器是作为KeyedProcessFunction实现的。它的方法KeyedProcessFunction#processElement 为每个事务事件调用。第一个版本对每个事务产生警报,有些人可能会说它过于保守。
本教程的后续步骤将指导您使用更有意义的业务逻辑扩展欺诈检测器。
public class FraudDetector extends KeyedProcessFunction<Long, Transaction, Alert> {
private static final double SMALL_AMOUNT = 1.00;
private static final double LARGE_AMOUNT = 500.00;
private static final long ONE_MINUTE = 60 * 1000;
@Override
public void processElement(
Transaction transaction,
Context context,
Collector<Alert> collector) throws Exception {
Alert alert = new Alert();
alert.setId(transaction.getAccountId());
collector.collect(alert);
}
}
2.6 编写一个真实的应用程序(v1)
对于第一个版本,欺诈检测器应该为任何进行小额交易后立即进行大额交易的帐户输出警报。小是指少于1美元的东西,大是指超过500美元的东西。假设您的欺诈检测器处理特定帐户的以下交易流。

交易3和4应该被标记为欺诈,因为这是一笔小额交易,0.09美元,其次是一笔大额交易,510美元。或者,交易7、8和9不是欺诈行为,因为小额的0.02美元并没有立即出现大额的0.02美元;相反,有一个中间事务打破了这个模式。
要做到这一点,欺诈检测器必须记住(remember )跨事件的信息;一笔大交易只有在前一笔很小的情况下才算欺诈。记住跨事件的信息需要状态(state),这就是我们决定使用KeyedProcessFunction的原因。它提供了对状态和时间的细粒度控制,这将允许我们在整个演练中根据更复杂的需求发展我们的算法。
最直接的实现是在处理小事务时设置布尔标志。当一个大的事务通过时,您可以简单地检查是否为该帐户设置了标志。
然而,仅仅在FraudDetector类中将标志实现为成员变量是行不通的。Flink使用FraudDetector的相同对象实例处理多个帐户的事务,这意味着如果帐户A和B通过FraudDetector的相同实例路由,则帐户A的事务可以将标志设置为true,然后帐户B的事务可以触发假警报。当然,我们可以使用像Map这样的数据结构来跟踪单个键的标志,但是,简单的成员变量不能容错,并且在发生故障时它的所有信息都会丢失。因此,如果应用程序必须重新启动才能从故障中恢复,那么欺诈检测器可能会错过警报。
为了应对这些挑战,Flink提供了容错状态的原语(primitives ),这些原语几乎和普通成员变量一样容易使用。
Flink中最基本的状态类型是ValueState,这种数据类型为它包装的任何变量增加了容错性。ValueState是keyed state的一种形式,这意味着它只在keyed context中应用的operators 中可用;紧跟在DataStream#keyBy之后的任何operators 。operators 的keyed state自动限定为当前处理的记录的键。在本例中,密钥是当前事务的帐户id(由keyBy()声明),并且FraudDetector为每个帐户维护一个独立的状态。ValueState是使用ValueStateDescriptor创建的,其中包含关于Flink应该如何管理变量的元数据。应该在函数开始处理数据之前注册状态。它的正确的hook是open()方法。
public class FraudDetector extends KeyedProcessFunction<Long, Transaction, Alert> {
private static final long serialVersionUID = 1L;
private transient ValueState<Boolean> flagState;
@Override
public void open(Configuration parameters) {
ValueStateDescriptor<Boolean> flagDescriptor = new ValueStateDescriptor<>(
"flag",
Types.BOOLEAN);
flagState = getRuntimeContext().getState(flagDescriptor);
}
ValueState是一个包装类,类似于Java标准库中的AtomicReference或AtomicLong。它提供了三种与其内容交互的方法;update 设置状态,value获取当前值,clear删除其内容。如果特定键的状态为空,例如在应用程序开始时或调用ValueState#clear之后,则ValueState#value将返回null。对ValueState#value返回的对象的修改不能保证被系统识别,因此所有更改都必须使用ValueState#update执行。否则,Flink在底层自动管理容错,因此您可以像与任何标准变量一样与它交互。
下面,您可以看到如何使用船旗国跟踪潜在欺诈交易的示例。
@Override
public void processElement(
Transaction transaction,
Context context,
Collector<Alert> collector) throws Exception {
// Get the current state for the current key
Boolean lastTransactionWasSmall = flagState.value();
// Check if the flag is set
if (lastTransactionWasSmall != null) {
if (transaction.getAmount() > LARGE_AMOUNT) {
// Output an alert downstream
Alert alert = new Alert();
alert.setId(transaction.getAccountId());
collector.collect(alert);
}
// Clean up our state
flagState.clear();
}
if (transaction.getAmount() < SMALL_AMOUNT) {
// Set the flag to true
flagState.update(true);
}
}
对于每个事务,欺诈检测器检查该帐户的标志状态。请记住,ValueState的作用域始终局限于当前键,即帐户。如果标志为非空,则该帐户看到的最后一笔交易很小,因此,如果此交易的金额很大,则检测器输出欺诈警报。
检查之后,flag state 被清除。要么是当前事务引起欺诈警报,模式结束;要么是当前事务没有引起警报,模式中断,需要重新启动。
最后,检查交易金额是否小。如果是,则设置该标志,以便下一个事件可以检查它。注意,ValueState<Boolean>有三种状态:unset (null)、true和false,因为所有ValueState都是可空的。此作业仅使用unset (null)和true来检查是否设置了标志。
2.7 Fraud Detector v2: State + Time = ❤️
骗子不会等太久才进行大笔购买,以减少他们的测试交易被发现的机会。例如,假设您想为欺诈检测器设置1分钟超时;也就是说,在前面的例子中,只有当交易3和4在1分钟内发生时才会被认为是欺诈。Flink的KeyedProcessFunction允许您设置计时器,以便在将来的某个时间点调用回调方法。
让我们看看如何修改我们的Job以符合我们的新要求:
- 当该标志被设置为true时,也要在将来设置1分钟的计时器。
- 当计时器触发时,通过清除其状态来重置标志。
- 如果标志被清除,计时器应该被取消。
要取消计时器,您必须记住它设置的时间,记住意味着状态,因此您将首先创建计时器状态和您的标志状态。
private transient ValueState<Boolean> flagState;
private transient ValueState<Long> timerState;
@Override
public void open(Configuration parameters) {
ValueStateDescriptor<Boolean> flagDescriptor = new ValueStateDescriptor<>(
"flag",
Types.BOOLEAN);
flagState = getRuntimeContext().getState(flagDescriptor);
ValueStateDescriptor<Long> timerDescriptor = new ValueStateDescriptor<>(
"timer-state",
Types.LONG);
timerState = getRuntimeContext().getState(timerDescriptor);
}
KeyedProcessFunction#processElement与包含计时器服务的Context 一起调用。定时器业务提供查询当前时间、注册定时器、删除定时器等功能。这样,您就可以在以后每次设置标志时设置一个1分钟的计时器,并将时间戳存储在timerState中。
if (transaction.getAmount() < SMALL_AMOUNT) {
// set the flag to true
flagState.update(true);
// set the timer and timer state
long timer = context.timerService().currentProcessingTime() + ONE_MINUTE;
context.timerService().registerProcessingTimeTimer(timer);
timerState.update(timer);
}
Processing 时间为挂钟时间,由运行机器的operator的系统时钟决定。
当计时器触发时,它调用KeyedProcessFunction#onTimer。重写此方法是实现回调以重置标志的方法。
public void onTimer(long timestamp, OnTimerContext ctx, Collector<Alert> out) {
// remove flag after 1 minute
timerState.clear();
flagState.clear();
}
最后,要取消定时器,需要删除已注册的定时器并删除定时器状态。您可以将其封装在一个helper方法中,并调用该方法而不是调用flagState.clear()。
private void cleanUp(Context ctx) throws Exception {
// delete timer
Long timer = timerState.value();
ctx.timerService().deleteProcessingTimeTimer(timer);
// clean up all state
timerState.clear();
flagState.clear();
}
这就是它,一个功能齐全,有状态的分布式流应用程序!
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.walkthrough.common.entity.Alert;
import org.apache.flink.walkthrough.common.entity.Transaction;
public class FraudDetector extends KeyedProcessFunction<Long, Transaction, Alert> {
private static final long serialVersionUID = 1L;
private static final double SMALL_AMOUNT = 1.00;
private static final double LARGE_AMOUNT = 500.00;
private static final long ONE_MINUTE = 60 * 1000;
private transient ValueState<Boolean> flagState;
private transient ValueState<Long> timerState;
@Override
public void open(Configuration parameters) {
ValueStateDescriptor<Boolean> flagDescriptor = new ValueStateDescriptor<>(
"flag",
Types.BOOLEAN);
flagState = getRuntimeContext().getState(flagDescriptor);
ValueStateDescriptor<Long> timerDescriptor = new ValueStateDescriptor<>(
"timer-state",
Types.LONG);
timerState = getRuntimeContext().getState(timerDescriptor);
}
@Override
public void processElement(
Transaction transaction,
Context context,
Collector<Alert> collector) throws Exception {
// Get the current state for the current key
Boolean lastTransactionWasSmall = flagState.value();
// Check if the flag is set
if (lastTransactionWasSmall != null) {
if (transaction.getAmount() > LARGE_AMOUNT) {
//Output an alert downstream
Alert alert = new Alert();
alert.setId(transaction.getAccountId());
collector.collect(alert);
}
// Clean up our state
cleanUp(context);
}
if (transaction.getAmount() < SMALL_AMOUNT) {
// set the flag to true
flagState.update(true);
long timer = context.timerService().currentProcessingTime() + ONE_MINUTE;
context.timerService().registerProcessingTimeTimer(timer);
timerState.update(timer);
}
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<Alert> out) {
// remove flag after 1 minute
timerState.clear();
flagState.clear();
}
private void cleanUp(Context ctx) throws Exception {
// delete timer
Long timer = timerState.value();
ctx.timerService().deleteProcessingTimeTimer(timer);
// clean up all state
timerState.clear();
flagState.clear();
}
}
期望输出
使用提供的TransactionSource运行此代码将为帐户3发出欺诈警报。您应该在任务管理器日志中看到以下输出:
17:38:01,973 INFO org.apache.flink.walkthrough.common.sink.AlertSink [] - Alert{id=3}
17:38:07,011 INFO org.apache.flink.walkthrough.common.sink.AlertSink [] - Alert{id=3}
17:38:12,045 INFO org.apache.flink.walkthrough.common.sink.AlertSink [] - Alert{id=3}
17:38:17,076 INFO org.apache.flink.walkthrough.common.sink.AlertSink [] - Alert{id=3}
3、基于 Table API 实现实时报表
Apache Flink提供了一个Table API 作为统一的关系型API,用于批处理和流处理,也就是说,查询在无界的实时流或有界的批处理数据集上以相同的语义执行,并产生相同的结果。Flink中的Table API通常用于简化数据分析、数据流水线和ETL应用程序的定义。
3.1 你将构建什么?
在本教程中,您将学习如何构建实时仪表板来按帐户跟踪金融交易。该管道将从Kafka读取数据并将结果写入通过Grafana可视化的MySQL。
3.2 前提条件
本演练假设您对Java有一定的了解,但是即使您使用的是不同的编程语言,也应该能够跟上。它还假设您熟悉基本的关系概念,如SELECT和GROUP BY子句。
3.3 遇到困难
如果遇到困难,请查看社区支持资源。特别是,Apache Flink的用户邮件列表一直被评为Apache项目中最活跃的邮件列表之一,也是快速获得帮助的好方法。
如果在Windows上运行docker并且您的数据生成器容器无法启动,那么请确保您使用的shell是正确的。例如,
table-walkthrough_data-generator_1容器的docker-entrypoint.sh需要bash。如果不可用,它将抛出一个错误standard_init_linux.go:211: exec user process caused “no such file or directory”。一种解决方法是在docker-entrypoint.sh的第一行将shell切换为sh。
3.4 如何跟进
如果你想跟着做,你需要一台电脑,上面有:
- Java 11
- Maven
- Docker
所需的配置文件可在flink-playgrounds存储库中获得。下载后,在IDE中打开项目flink-playground/table-walkthrough,并导航到文件SpendReport。
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode();
TableEnvironment tEnv = TableEnvironment.create(settings);
tEnv.executeSql("CREATE TABLE transactions (\n" +
" account_id BIGINT,\n" +
" amount BIGINT,\n" +
" transaction_time TIMESTAMP(3),\n" +
" WATERMARK FOR transaction_time AS transaction_time - INTERVAL '5' SECOND\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'transactions',\n" +
" 'properties.bootstrap.servers' = 'kafka:9092',\n" +
" 'format' = 'csv'\n" +
")");
tEnv.executeSql("CREATE TABLE spend_report (\n" +
" account_id BIGINT,\n" +
" log_ts TIMESTAMP(3),\n" +
" amount BIGINT\n," +
" PRIMARY KEY (account_id, log_ts) NOT ENFORCED" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://mysql:3306/sql-demo',\n" +
" 'table-name' = 'spend_report',\n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'sql-demo',\n" +
" 'password' = 'demo-sql'\n" +
")");
Table transactions = tEnv.from("transactions");
report(transactions).executeInsert("spend_report");
3.5 解析代码
执行环境
前两行设置了TableEnvironment。通过表环境,您可以为 Job 设置属性,指定是编写批处理应用程序还是流应用程序,并创建源。本演练创建一个使用流执行的标准表环境。
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode();
TableEnvironment tEnv = TableEnvironment.create(settings);
Registering Tables
接下来,在当前 catalog 中注册表,您可以使用这些表连接到外部系统,以读写批处理和流数据。表源提供对存储在外部系统(如数据库、键值存储、消息队列或文件系统)中的数据的访问。表接收器(table sink)将表发送到外部存储系统。根据源和接收的类型,它们支持不同的格式,如CSV、JSON、Avro或Parquet。
tEnv.executeSql("CREATE TABLE transactions (\n" +
" account_id BIGINT,\n" +
" amount BIGINT,\n" +
" transaction_time TIMESTAMP(3),\n" +
" WATERMARK FOR transaction_time AS transaction_time - INTERVAL '5' SECOND\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'transactions',\n" +
" 'properties.bootstrap.servers' = 'kafka:9092',\n" +
" 'format' = 'csv'\n" +
")");
注册两个表;一个transaction 输入表和一个支出报告输出表。交易( transactions )表允许我们读取信用卡交易,其中包含帐户ID (account_id)、时间戳(transaction_time)和美元金额(amount)。该表是Kafka主题上的逻辑视图,该主题称为transactions,包含CSV数据的 。
tEnv.executeSql("CREATE TABLE spend_report (\n" +
" account_id BIGINT,\n" +
" log_ts TIMESTAMP(3),\n" +
" amount BIGINT\n," +
" PRIMARY KEY (account_id, log_ts) NOT ENFORCED" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://mysql:3306/sql-demo',\n" +
" 'table-name' = 'spend_report',\n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'sql-demo',\n" +
" 'password' = 'demo-sql'\n" +
")");
第二个表spend_report存储聚合的最终结果。它的底层存储是MySql数据库中的一个表。
The Query
配置好环境并注册好表之后,就可以开始构建第一个应用程序了。从TableEnvironment中,您可以from 输入表中读取其行,然后使用executeInsert将这些结果写入输出表。报表功能是您实现业务逻辑的地方。它目前尚未实现。
Table transactions = tEnv.from("transactions");
report(transactions).executeInsert("spend_report");
3.6 Testing
该项目包含一个次要测试类SpendReportTest,用于验证报告的逻辑。它以批处理模式创建一个表环境。
EnvironmentSettings settings = EnvironmentSettings.inBatchMode();
TableEnvironment tEnv = TableEnvironment.create(settings);
Flink的独特属性之一是它在批处理和流处理之间提供一致的语义。这意味着您可以在静态数据集上以批处理模式开发和测试应用程序,并将其作为流应用程序部署到生产环境。
3.7 尝试下
现在有了Job设置的框架,就可以添加一些业务逻辑了。目标是构建一个报告,显示每个帐户在一天中每个小时的总支出。这意味着时间戳列的粒度需要从毫秒降低到小时。
Flink支持纯SQL或使用Table API开发关系应用程序。Table API是受SQL启发的流畅DSL,可以用Java或Python编写,并支持强大的IDE集成。就像SQL查询一样,Table程序可以选择所需的字段并按键分组。这些特性以及floor和sum等内置函数使您能够编写此报告。
public static Table report(Table transactions) {
return transactions.select(
$("account_id"),
$("transaction_time").floor(TimeIntervalUnit.HOUR).as("log_ts"),
$("amount"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts"),
$("amount").sum().as("amount"));
}
3.8 用户自定义函数
Flink包含有限数量的内置函数,有时需要使用用户定义的函数对其进行扩展。如果floor不是预定义的,您可以自己实现它。
import java.time.LocalDateTime;
import java.time.temporal.ChronoUnit;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.functions.ScalarFunction;
public class MyFloor extends ScalarFunction {
public @DataTypeHint("TIMESTAMP(3)") LocalDateTime eval(
@DataTypeHint("TIMESTAMP(3)") LocalDateTime timestamp) {
return timestamp.truncatedTo(ChronoUnit.HOURS);
}
}
然后将其快速集成到您的应用程序中。
public static Table report(Table transactions) {
return transactions.select(
$("account_id"),
call(MyFloor.class, $("transaction_time")).as("log_ts"),
$("amount"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts"),
$("amount").sum().as("amount"));
}
该查询使用transactions 表中的所有记录,计算报表,并以高效、可伸缩的方式输出结果。使用此实现运行测试将通过。
3.8 Adding Windows
基于时间对数据进行分组是数据处理中的一种典型操作,特别是在处理无限流时。基于时间的分组称为窗口,Flink提供了灵活的窗口语义。最基本的窗口类型称为滚筒式窗口(Tumble window),它具有固定的大小,并且其桶不重叠。
public static Table report(Table transactions) {
return transactions
.window(Tumble.over(lit(1).hour()).on($("transaction_time")).as("log_ts"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts").start().as("log_ts"),
$("amount").sum().as("amount"));
}
这将您的应用程序定义为使用基于时间戳列的一小时滚动窗口。因此,将时间戳为2019-06-01 01:23:47的行放入2019-06-01 01:00:00窗口中。
基于时间的聚合是唯一的,因为与其他属性相反,时间通常在连续流应用程序中向前移动。与floor 和UDF不同,窗口函数是内在的( intrinsics),它允许运行时应用额外的优化。在批处理上下文中,windows提供了一个方便的API,可以根据时间戳属性对记录进行分组。
使用此实现运行测试也将通过。
3.9 Once More, 使用 Streaming!
这就是它,一个功能齐全,有状态的分布式流应用程序!查询不断地消耗来自Kafka的事务流,计算每小时的支出,并在准备好后立即发布结果。由于输入是无界的,因此查询将一直运行,直到手动停止为止。由于Job使用基于时间窗口的聚合,所以Flink可以执行特定的优化,例如当框架知道某个特定窗口不会再有记录到达时进行状态清理。
表是完全dockerized的,可以作为流应用程序在本地运行。该环境包含一个Kafka主题、一个连续数据生成器、MySql和Grafana。
从table-walkthrough文件夹中启动docker-compose脚本。
$ docker-compose build
$ docker-compose up -d
您可以通过Flink控制台查看正在运行的作业的信息。
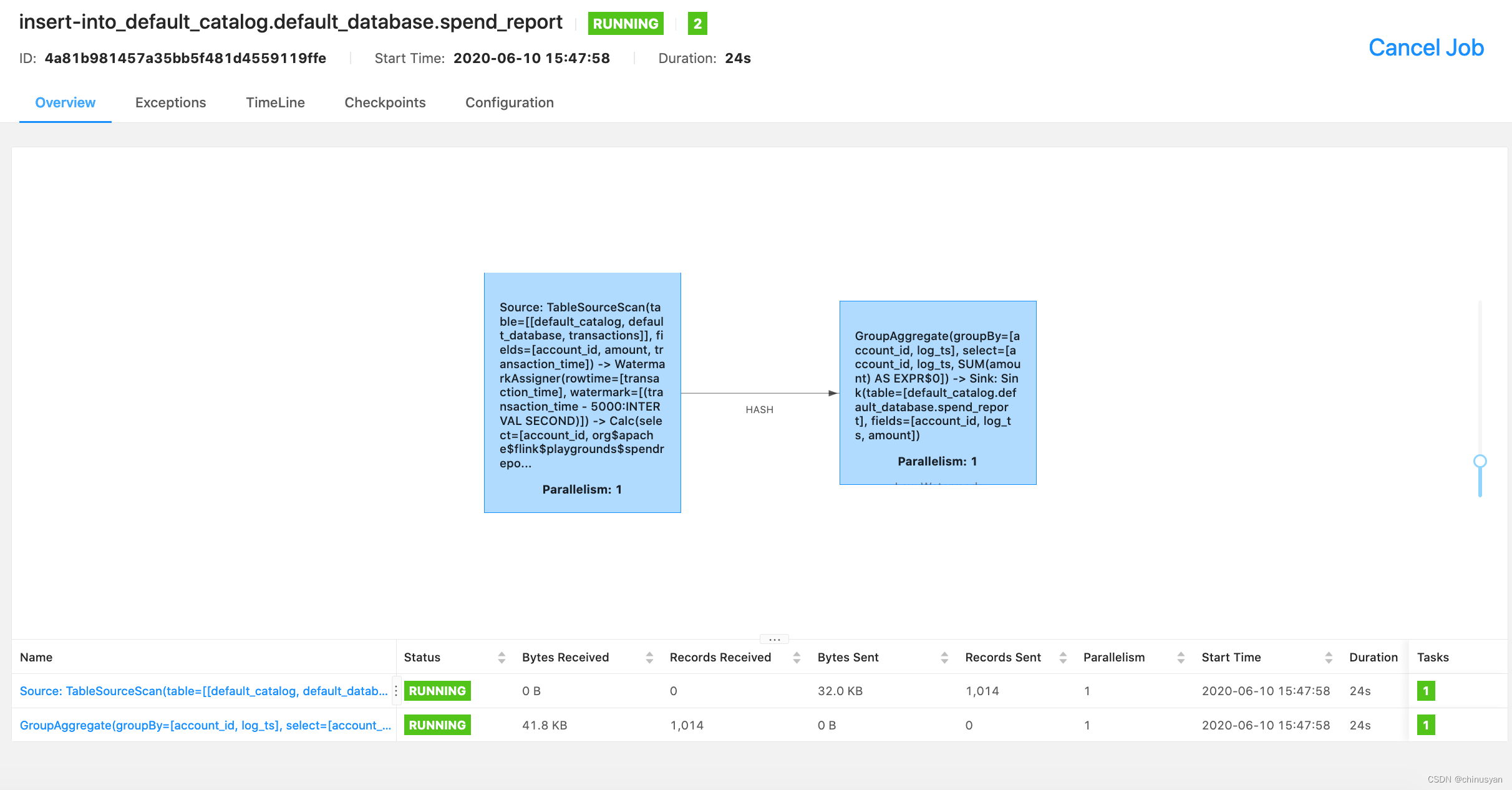
探索MySQL内部的结果。
$ docker-compose exec mysql mysql -Dsql-demo -usql-demo -pdemo-sql
mysql> use sql-demo;
Database changed
mysql> select count(*) from spend_report;
+----------+
| count(*) |
+----------+
| 110 |
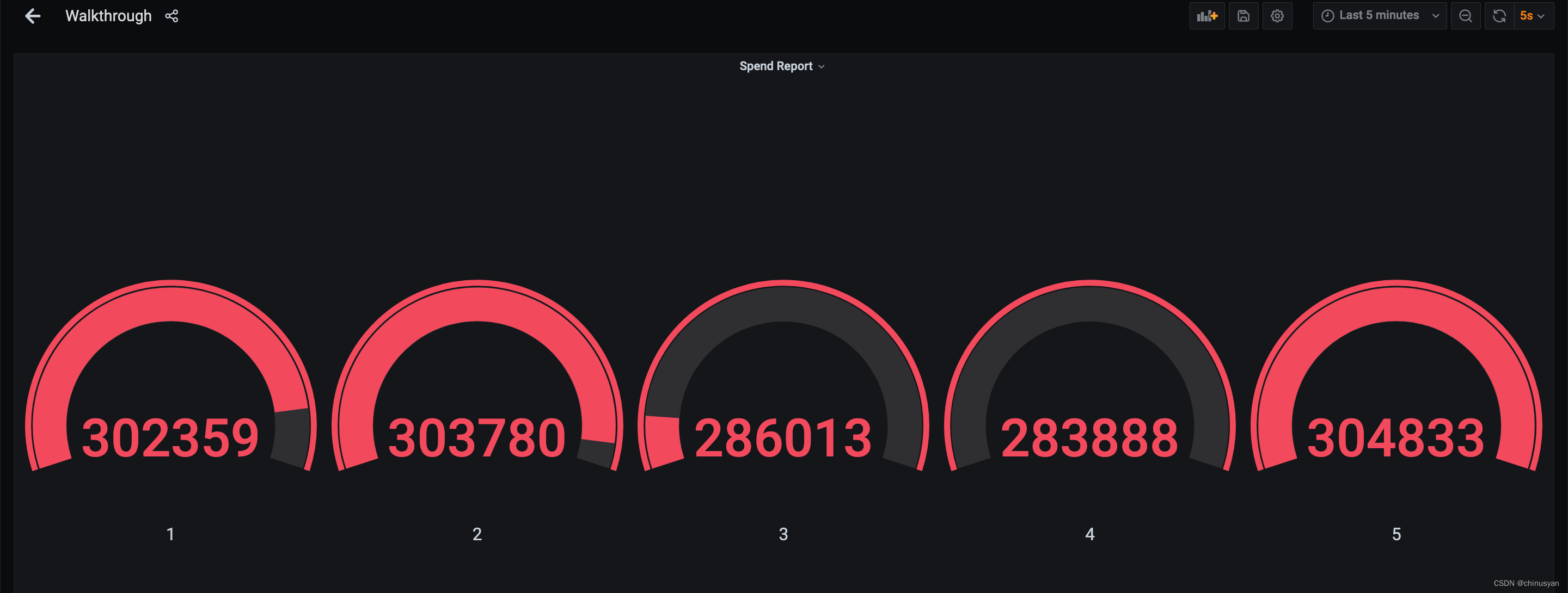
最后,去Grafana查看完全可视化的结果!
4、Flink 操作场景
在各种环境中部署和操作Apache Flink的方法有很多种。无论这种变化如何,Flink Cluster的基本构建块保持不变,并且适用类似的操作原则。
在本教程中,您将学习如何管理和运行Flink job。您将了解如何部署和监视应用程序,体验Flink如何从Job失败中恢复,以及执行升级和伸缩等日常操作任务。
4.1 场景说明
这个场景由一个长期存在的Flink会话集群和一个Kafka集群组成。
Flink集群总是由一个JobManager和一个或多个Flink Taskmanager组成。JobManager负责处理Job提交、监督Job以及资源管理。Flink任务管理器(TaskManagers)是工作进程,负责执行组成Flink Job的实际任务。在这个场景上,你将从一个任务管理器开始,但后来扩展到更多的任务管理器。此外,这个场景附带了一个专用的客户(client)端容器,我们用它来提交Flink Job,并在以后执行各种操作任务。Flink Cluster本身不需要客户端容器,只是为了方便使用而包含它。
Kafka集群由一个Zookeeper服务器和一个Kafka Broker组成。
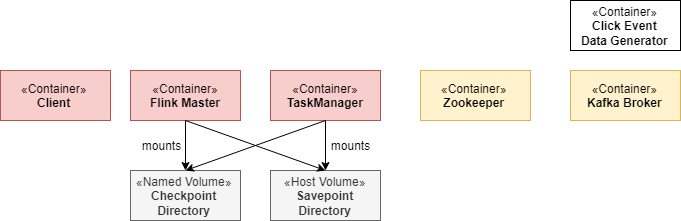
当场景启动时,一个名为Flink Event Count的Flink Job将被提交给JobManager。此外,还创建了两个Kafka主题input 和output 。
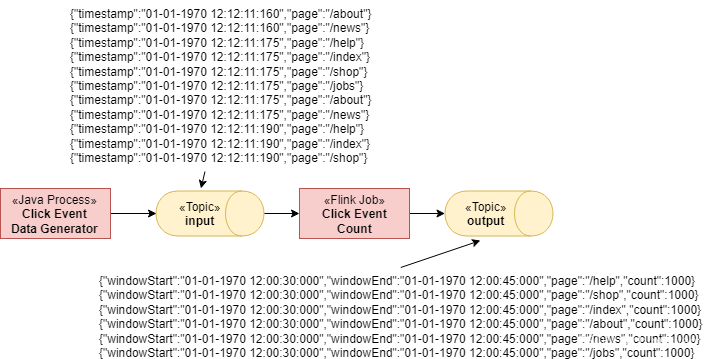
Job使用来自input 主题的ClickEvents,每个事件都有一个时间戳(timestamp )和一个页面(page)。然后按page 输入事件,并在15秒的窗口内计数。结果被写入output主题。
有6个不同的页面,我们在15秒内每页生成1000个点击事件。因此,Flink作业的输出应该显示每个页面和窗口有1000个视图。