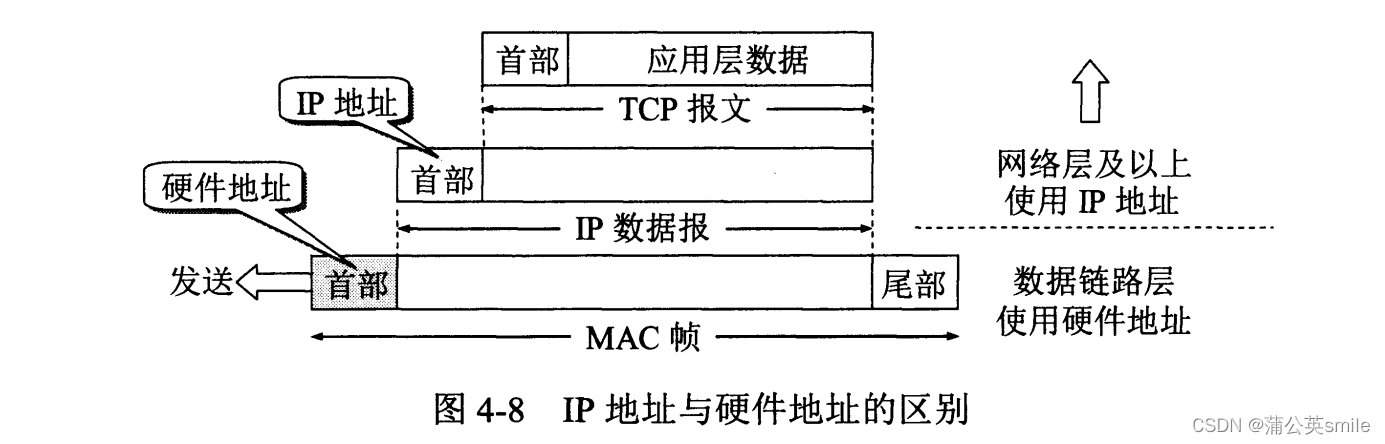
文章目录
- HBase表数据的读、写操作与综合操作
- 一、实验目标
- 二、实验要求及注意事项
- 三、实验内容及步骤
- 附:系列文章
HBase表数据的读、写操作与综合操作
一、实验目标
- 熟练掌握通过HBase shell命令来设计HBase表结构实例
- 掌握使用HBase编程创建HBase表、删除HBase表、修改HBase表和查看HBase表和表结构。
- 掌握通过HBase 编程实现HBase表数据的读、写操作
二、实验要求及注意事项
- 给出每个实验的主要实验步骤、实现代码和测试效果截图。
- 对本次实验工作进行全面的总结分析。
- 建议工程名,类名、包名或表名显示个人学号或者姓名
三、实验内容及步骤
实验任务1:使用MapReduce批量将HBase表中数据导入到HDFS上。表名和表中数据自拟。
主要实现步骤和运行效果图:
完整程序
WjwReadMapper:
package hbase;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.io.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.*;
import org.apache.hadoop.io.*;
public class WjwReadMapper extends TableMapper<Writable, Writable> {
private Text k=new Text();
private Text v=new Text();
public static final String F1="\u0001";
protected void setup(Context c){
}
public void map(ImmutableBytesWritable row,Result r,Context c){
String value=null;
String rk=new String(row.get());
byte[] family=null;
byte[] column=null;
long ts=0L;
try{
for(KeyValue kv:r.list()){
value=Bytes.toStringBinary(kv.getValue());
family=kv.getFamily();
column=kv.getQualifier();
ts=kv.getTimestamp();
k.set(rk);
v.set(Bytes.toString(family)+F1+Bytes.toString(column)+F1+value+F1+ts);
c.write(k, v);
}
}catch(Exception e){
e.printStackTrace();
System.err.println();
}
}
}
WjwReadMain:
package hbase;
import java.io.IOException;
import org.apache.hadoop.io.*;
import org.apache.commons.logging.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.util.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.output.*;
public class WjwReadMain {
public static final Log LOG = LogFactory.getLog(WjwMain.class);
public static final String NAME = "Member Test1";
public static final String TEMP_INDEX_PATH = "hdfs://master:9000/tmp/tb_wjw";
public static String inputTable = "tb_wjw";
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf = HBaseConfiguration.create();
Scan scan = new Scan();
scan.setBatch(0);
scan.setCaching(10000);
scan.setMaxVersions();
scan.setTimeRange(System.currentTimeMillis() - 3*24*3600*1000L, System.currentTimeMillis());
scan.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("keyword"));
conf.setBoolean("mapred.map.tasks.speculative.execution", false);
conf.setBoolean("mapred.reduce.tasks.speculative.execution", false);
Path tmpIndexPath = new Path(TEMP_INDEX_PATH);
FileSystem fs = FileSystem.get(conf);
if(fs.exists(tmpIndexPath)){
fs.delete(tmpIndexPath, true);
}
Job job = new Job(conf, NAME);
job.setJarByClass(WjwMain.class);
TableMapReduceUtil.initTableMapperJob(inputTable, scan, WjwMapper.class, Text.class, Text.class, job);
job.setNumReduceTasks(0);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, tmpIndexPath);
boolean success = job.waitForCompletion(true);
System.exit(success?0:1);
}
}
运行结果
创建表,用于等会将数据传入hadoop里
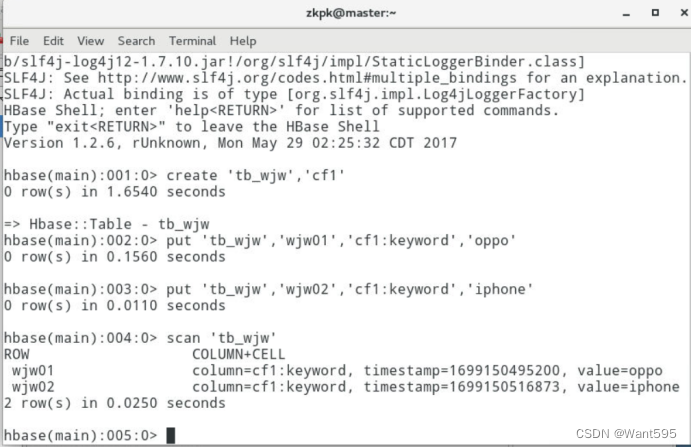
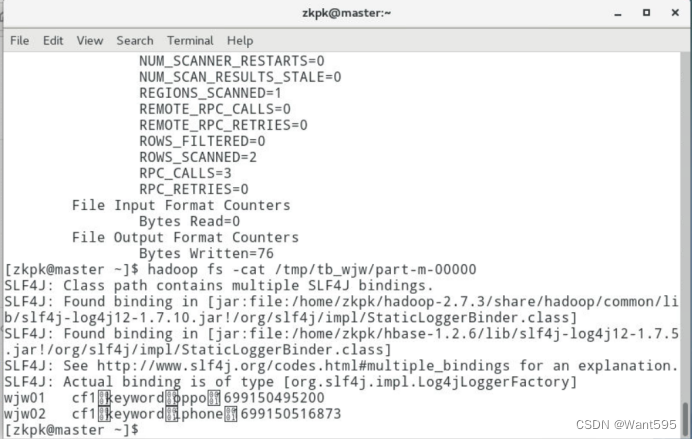
运行map程序将表数据导入hadoop,并查看是否导入成功
实验任务2:使用MapReduce批量将HDFS上的数据导入到HBase表中。表名和数据自拟,建议体现个人学号或姓名。使用Java编程创建表和删除表,表名和列族自拟。
主要实现步骤和运行效果图:
完整程序
WjwWriteMapper:
package hbase;
import java.io.*;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.io.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.io.*;
public class WjwWriteMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> {
private byte[] family=null;
private byte[] qualifier=null;
private byte[] val=null;
private String rk=null;
private long ts=System.currentTimeMillis();
protected void map(LongWritable key,Text value,Context context) throws InterruptedException, IOException{
try{
String line=value.toString();
String[] arr=line.split("\t",-1);
if(arr.length==2){
rk=arr[0];
String[] vals=arr[1].split("\u0001",-1);
if(vals.length==4){
family=vals[0].getBytes();
qualifier=vals[1].getBytes();
val=vals[2].getBytes();
ts=Long.parseLong(vals[3]);
Put put=new Put(rk.getBytes(),ts);
put.add(family,qualifier,val);
context.write(new ImmutableBytesWritable(rk.getBytes()), put);
}
}
}catch(Exception e){
e.printStackTrace();
}
}
}
WjwWriteMain:
package hbase;
import org.apache.hadoop.util.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.io.*;
import org.apache.hadoop.hbase.mapreduce.*;
import java.io.IOException;
import org.apache.commons.logging.*;
public class WjwWriteMain extends Configured implements Tool{
static final Log LOG=LogFactory.getLog(WjwWriteMain.class);
public int run(String[] args)throws Exception{
if(args.length!=2){
LOG.info("2 parameters needed!");
}
String input="hdfs://master:9000/tmp/tb_wjw/part-m-00000";
String table="tb_wjw01";
Configuration conf=HBaseConfiguration.create();
Job job=new Job(conf,"Input from file "+input+" into table "+table);
job.setJarByClass(WjwWriteMain.class);
job.setMapperClass(WjwWriteMapper.class);
job.setJarByClass(WjwWriteMain.class);
job.setMapperClass(WjwWriteMapper.class);
job.setOutputFormatClass(TableOutputFormat.class);
job.getConfiguration().set(TableOutputFormat.OUTPUT_TABLE,table);
job.setOutputKeyClass(ImmutableBytesWritable.class);
job.setOutputValueClass(Waitable.class);
job.setNumReduceTasks(0);
FileInputFormat.addInputPath(job, new Path(input));
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws IOException {
Configuration conf=new Configuration();
String[] otherArgs=new GenericOptionsParser(conf,args).getRemainingArgs();
try {
System.out.println(ToolRunner.run(conf, new WjwWriteMain(),otherArgs));
}catch(Exception e) {
e.printStackTrace();
}
}
}
运行结果
创建一个空表tb_wjw01,用于等会将tb_wjw的数据导入tb_wjw01
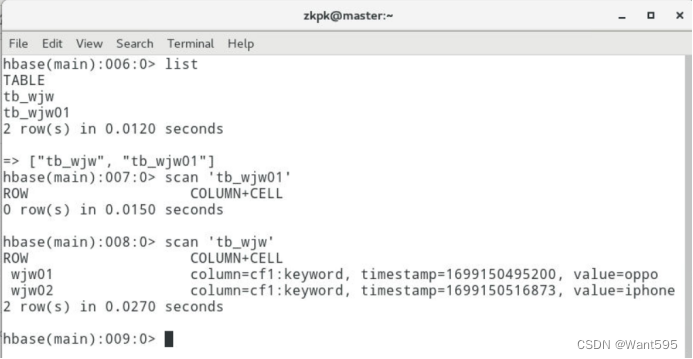
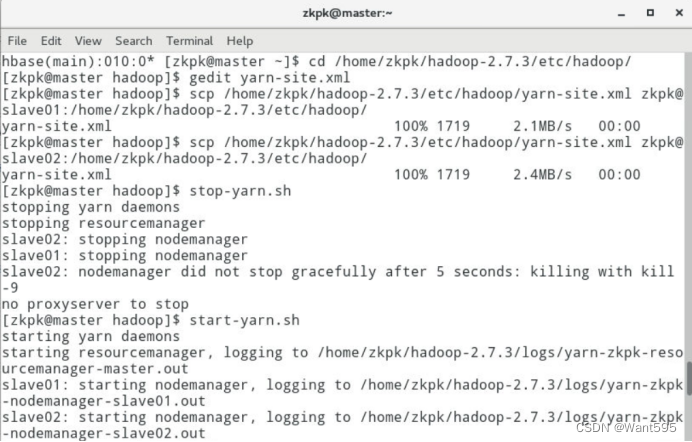
配置yarn,并运行map程序
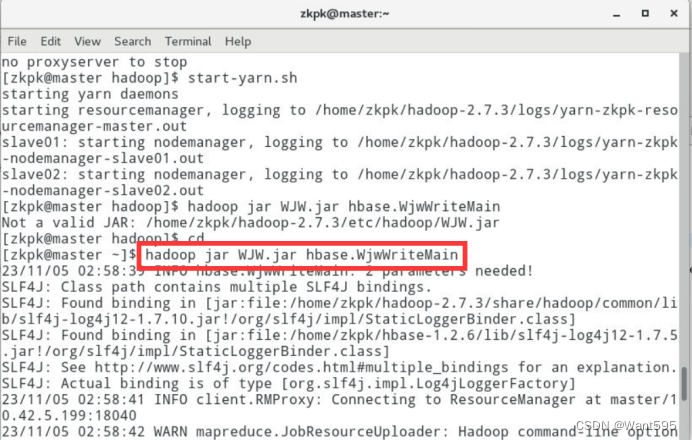
查看hadoop里的表tb_wjw
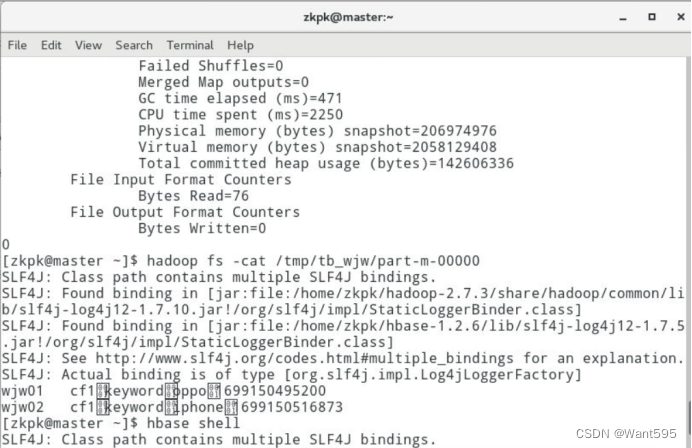
将hadoop里tb_wjw的数据导入hbase里的tb_wjw01里面
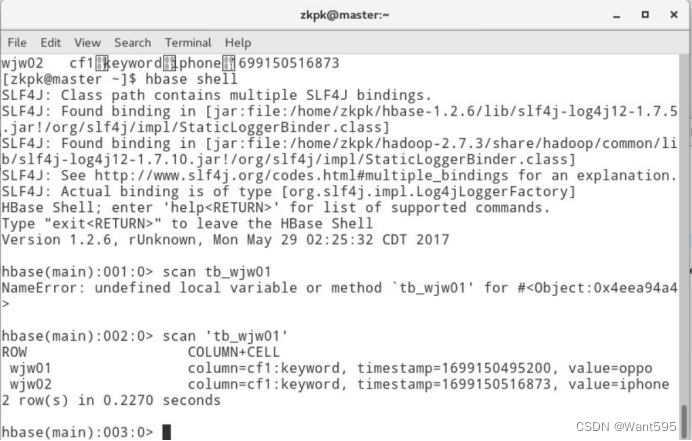
实验任务3:在实验任务1和实验任务2的基础上,通过HBase编程,实现创建HBase表,修改HBase表(包括增加列族和删除列族),向HBase表中写入数据,读取HBase表中数据,查看HBase数据库中所有表和表结构功能,建议在一个类中定义多个方法实现上述功能,并进行验证。表名和数据自拟。
主要实现步骤和运行效果图:
完整程序
package hbase;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
public class WjwHbase{
private static Configuration conf = HBaseConfiguration.create();
public static void createTable(String tableName, String[] families)
throws IOException {
Connection conn = ConnectionFactory.createConnection(conf);
Admin admin = conn.getAdmin();
if (admin.tableExists(TableName.valueOf(tableName))) {
System.out.println("Table already exists!");
} else {
HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf(tableName));
for (String family : families) {
tableDesc.addFamily(new HColumnDescriptor(family));
}
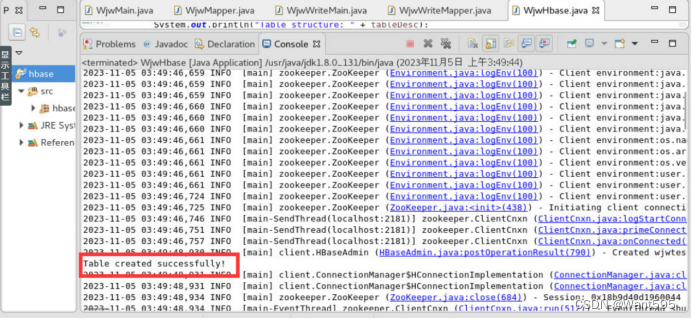
admin.createTable(tableDesc);
System.out.println("Table created successfully!");
}
admin.close();
conn.close();
}
public static void addRecord(String tableName, String rowKey,
String family, String qualifier, String value) throws IOException {
Connection conn = ConnectionFactory.createConnection(conf);
Table table = conn.getTable(TableName.valueOf(tableName));
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes(family), Bytes.toBytes(qualifier), Bytes.toBytes(value));
table.put(put);
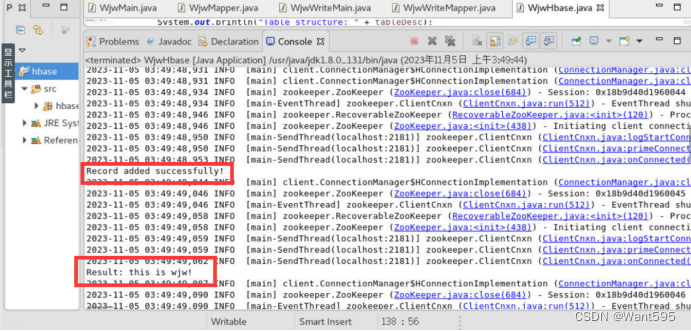
System.out.println("Record added successfully!");
table.close();
conn.close();
}
public static void deleteRecord(String tableName, String rowKey,
String family, String qualifier) throws IOException {
Connection conn = ConnectionFactory.createConnection(conf);
Table table = conn.getTable(TableName.valueOf(tableName));
Delete delete = new Delete(Bytes.toBytes(rowKey));
delete.addColumn(Bytes.toBytes(family), Bytes.toBytes(qualifier));
table.delete(delete);
System.out.println("Record deleted successfully!");
table.close();
conn.close();
}
public static void deleteTable(String tableName) throws IOException {
Connection conn = ConnectionFactory.createConnection(conf);
Admin admin = conn.getAdmin();
if (admin.tableExists(TableName.valueOf(tableName))) {
admin.disableTable(TableName.valueOf(tableName));
admin.deleteTable(TableName.valueOf(tableName));
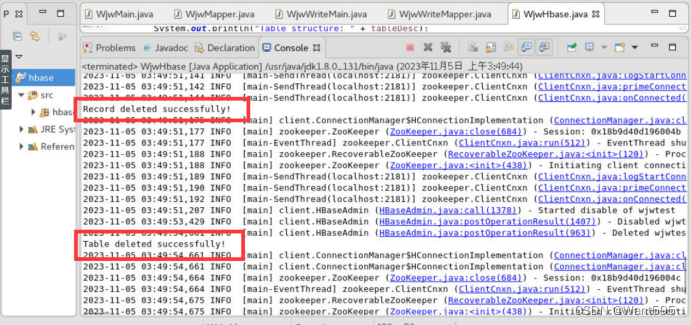
System.out.println("Table deleted successfully!");
} else {
System.out.println("Table does not exist!");
}
admin.close();
conn.close();
}
public static void addColumnFamily(String tableName, String columnFamily) throws IOException {
Connection conn = ConnectionFactory.createConnection(conf);
Admin admin = conn.getAdmin();
if (admin.tableExists(TableName.valueOf(tableName))) {
HColumnDescriptor columnDesc = new HColumnDescriptor(columnFamily);
admin.addColumn(TableName.valueOf(tableName), columnDesc);
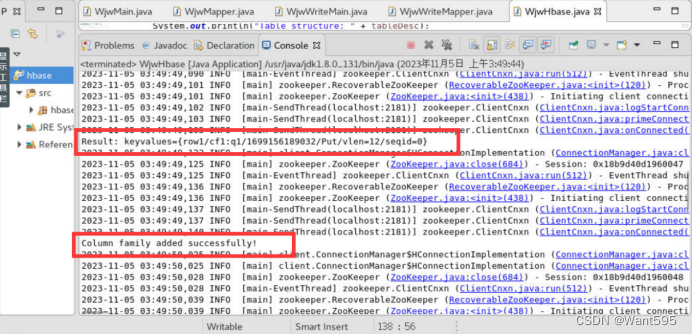
System.out.println("Column family added successfully!");
} else {
System.out.println("Table does not exist!");
}
admin.close();
conn.close();
}
public static void deleteColumnFamily(String tableName, String columnFamily) throws IOException {
Connection conn = ConnectionFactory.createConnection(conf);
Admin admin = conn.getAdmin();
if (admin.tableExists(TableName.valueOf(tableName))) {
admin.deleteColumn(TableName.valueOf(tableName), Bytes.toBytes(columnFamily));
System.out.println("Column family deleted successfully!");
} else {
System.out.println("Table does not exist!");
}
admin.close();
conn.close();
}
public static void getRecord(String tableName, String rowKey,
String family, String qualifier) throws IOException {
Connection conn = ConnectionFactory.createConnection(conf);
Table table = conn.getTable(TableName.valueOf(tableName));
Get get = new Get(Bytes.toBytes(rowKey));
Result result = table.get(get);
byte[] value = result.getValue(Bytes.toBytes(family), Bytes.toBytes(qualifier));
System.out.println("Result: " + Bytes.toString(value));
table.close();
conn.close();
}
public static void scanTable(String tableName) throws IOException {
Connection conn = ConnectionFactory.createConnection(conf);
Table table = conn.getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
System.out.println("Result: " + result);
}
table.close();
conn.close();
}
public static void listTables() throws IOException {
Connection conn = ConnectionFactory.createConnection(conf);
Admin admin = conn.getAdmin();
HTableDescriptor[] tableDescs = admin.listTables();
List<String> tableNames = new ArrayList<String>();
for (HTableDescriptor tableDesc : tableDescs) {
tableNames.add(tableDesc.getNameAsString());
}
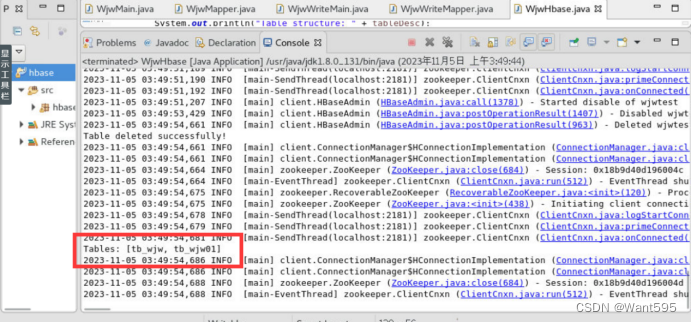
System.out.println("Tables: " + tableNames);
admin.close();
conn.close();
}
public static void describeTable(String tableName) throws IOException {
Connection conn = ConnectionFactory.createConnection(conf);
Admin admin = conn.getAdmin();
HTableDescriptor tableDesc = admin.getTableDescriptor(TableName.valueOf(tableName));
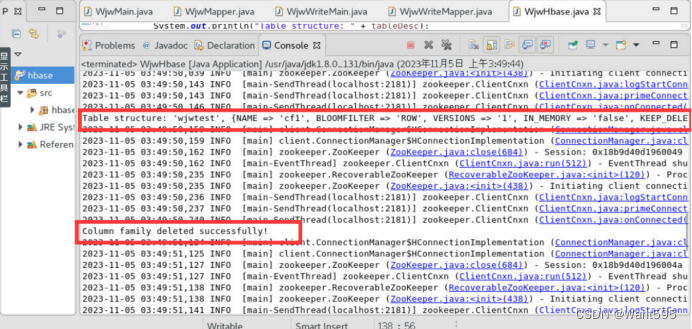
System.out.println("Table structure: " + tableDesc);
admin.close();
conn.close();
}
public static void main(String[] args) throws IOException {
String tableName = "wjwtest";
String rowKey = "row1";
String family = "cf1";
String qualifier = "q1";
String value = "this is wjw!";
String columnFamily = "cf2";
String[] families = {family};
createTable(tableName, families);
addRecord(tableName, rowKey, family, qualifier, value);
getRecord(tableName, rowKey, family, qualifier);
scanTable(tableName);
addColumnFamily(tableName, columnFamily);
describeTable(tableName);
deleteColumnFamily(tableName, columnFamily);
deleteRecord(tableName, rowKey, family, qualifier);
deleteTable(tableName);
listTables();
}
}
运行结果
附:系列文章
| 实验 | 文章目录 | 直达链接 |
|---|---|---|
| 实验01 | Hadoop安装部署 | https://want595.blog.csdn.net/article/details/132767284 |
| 实验02 | HDFS常用shell命令 | https://want595.blog.csdn.net/article/details/132863345 |
| 实验03 | Hadoop读取文件 | https://want595.blog.csdn.net/article/details/132912077 |
| 实验04 | HDFS文件创建与写入 | https://want595.blog.csdn.net/article/details/133168180 |
| 实验05 | HDFS目录与文件的创建删除与查询操作 | https://want595.blog.csdn.net/article/details/133168734 |
| 实验06 | SequenceFile、元数据操作与MapReduce单词计数 | https://want595.blog.csdn.net/article/details/133926246 |
| 实验07 | MapReduce编程:数据过滤保存、UID 去重 | https://want595.blog.csdn.net/article/details/133947981 |
| 实验08 | MapReduce 编程:检索特定群体搜索记录和定义分片操作 | https://want595.blog.csdn.net/article/details/133948849 |
| 实验09 | MapReduce 编程:join操作和聚合操作 | https://want595.blog.csdn.net/article/details/133949148 |
| 实验10 | MapReduce编程:自定义分区和自定义计数器 | https://want595.blog.csdn.net/article/details/133949522 |