文章目录
- 什么是Redis
- Redis的特点
- Redis的应用场景
- Redis安装部署
- Redis基础命令
- Redis多数据库特性
- Redis数据类型
- Redis数据类型之string
- Redis数据类型之hash
- Redis数据类型之list
- Redis数据类型之set
- Redis数据类型之sorted set
- 案例:存储高一班的学员信息
- Redis封装工具类技巧
- 如何使用java代码操作redis
- 单连接方式
- 连接池方式
- 案例:提取RedisUtils工具类
- Redis高级特性
- expire 生存时间
- pipeline 管道
- 案例:初始化10万条数据
- info命令
- Redis的持久化
- Redis持久化之RDB
- Redis持久化之AOF
- Redis 的安全策略
- 设置数据库密码
- bind参数的应用
- 命令重命名
- 一个Redis实例最多能存放多少key?
- Redis监控命令-monitor
- Redis架构演进
- 主从复制
- Sentinel
- 集群
什么是Redis
Redis是一种面向 “Key-Value” 数据类型的内存数据库,可以满足我们对海量数据的快速读写需求
注意:首先Redis是一种内存数据库,它的数据都是放在内存里面的,
然后Redis中存储的数据都是key-value类型的
其中redis中的key只能是字符串,value支持多种数据类型
常见的有 string、hash、list、set、sortedset 等
- 字符串 string
- 哈希 hash,类似于java中的hashmap
- 字符串列表 list
- 字符串集合 set 不重复,无序
- 有序集合sorted set ,不重复,有序
Redis的特点
接下来看一下Redis的一些特点
高性能:Redis读的速度是11W次/s,写的速度是8.1W次/s
原子性:保证数据的准确性
持久存储:支持两种方式的持久化,RDB和AOF,可以把内存中的数据持久化到磁盘中
支持主从:master-slave架构,可以实现负载均衡、高可用
支持集群:从3.0版本开始支持
注意:Redis是一个 单线程 的服务,作者之所以这么设计,主要是为了保证redis的快速,高效,如果涉及了多线程,就需要使用锁机制来解决并发问题,这样执行效率反而会打折扣。
注意:Redis是一个 NoSQL 数据库,NoSQL的全称是not only sql,不仅仅是SQL,泛指非关系型数据库,这种类型的数据库不支持SQL语法。
Redis的应用场景
主要应用在高并发和实时请求的场景,例如:新浪微博
hash:关注列表、粉丝列表
string:微博数,粉丝数(避免使用select count(*) from …)
Redis安装部署
首先下载redis
使用此链接下载,可以显示Redis目前所有的版本
http://download.redis.io/releases/
我们选择目前比较稳定的5.0.9版本。
将下载好的安装包上传到bigdata04机器的/data/soft目录下
1:解压
[root@bigdata04 soft]# tar -zxvf redis-5.0.9.tar.gz
2:编译+安装
[root@bigdata04 soft]# cd redis-5.0.9
[root@bigdata04 redis-5.0.9]# make
[root@bigdata04 redis-5.0.9]# make install
只要不报错就说明编译安装成功。
注意:由于redis需要依赖于C语言环境,如果你安装的centos镜像是精简版,会缺失c语言的依赖,所以需要安装C语言环境才可以编译成功。
我们在这使用的centos镜像是完整版,里面是包含C语言环境的
3:修改redis.conf配置文件
[root@bigdata04 redis-5.0.9]# vi redis.conf
daemonize yes
logfile /data/soft/redis-5.0.9/log
bind 127.0.0.1 192.168.182.103
- daemonize参数的值默认是no,表示在前台启动Redis,但是Redis是一个数据库,我们希望把它放到后台运行,所以将参数的值改为yes
- logfile 参数的值默认为空,表示redis会将日志输出到/dev/null里面,也就是不保存了,建议在这设置一个日志路径记录redis的日志,便于后期排查问题。
- bind 参数可以绑定指定ip,这样就可以通过这里指定的ip来访问redis服务了,可以在后面指定当前机器的本地回环地址(127.0.0.1)和内网地址(192.168.182.103),指定本地回环地址是为了能够在本机自己连自己比较方便。指定内网地址是为了能够让公司局域网内的其它服务器也能连到这个redis。 如果你这台机器有外网地址的话不建议在这配置,因为使用外网地址的话就不安全了,容易受到网络攻击。
4:启动redis
[root@bigdata04 redis-5.0.9]# redis-server redis.conf
5:验证
注意:redis不是java程序,所以使用jps命令查不到,需要使用ps命令查看redis的进程
[root@bigdata04 redis-5.0.9]# ps -ef|grep redis
root 5828 1 0 16:12 ? 00:00:00 redis-server 127.0.0.1:6379
6:连接redis数据库
[root@bigdata04 redis-5.0.9]# redis-cli
127.0.0.1:6379>
注意:使用redis-cli默认可以连接本地的redis
其实redis-cli后面省略了 -h 127.0.0.1 和 -p 6379
[root@bigdata04 redis-5.0.9]# redis-cli -h 127.0.0.1 -p 6379
7:停止redis数据库
暴力一点的方式是使用kill命令直接杀进程
不过redis提供的有停止命令
[root@bigdata04 redis-5.0.9]# redis-cli
127.0.0.1:6379> shutdown
not connected>
或者这样停止也是可以的
[root@bigdata04 redis-5.0.9]# redis-cli shutdown
Redis基础命令
- 获得符合规则的键:keys
keys 后面可以指定正则表达式
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> set a 1
OK
127.0.0.1:6379> keys *
1)"a"
127.0.0.1:6379> keys a*
1) "a"
127.0.0.1:6379> keys a+
(empty list or set)
注意:在生产环境下建议禁用keys命令,因为这个命令会查询过滤redis中的所有数据,可能会造成服务阻塞,影响redis执行效率。
如果有类似的查询需求建议使用scan。scan命令用于迭代当前数据库中的key集合。它支持增量式迭代,每次执行只会返回少量元素,所以它可以用于生产环境,而不会出现像keys 命令那样可能会阻塞服务器的问题。SCAN命令是一个基于游标的迭代器。这意味着命令每次被调用都需要使用上一次调用返回的游标作为该次调用的游标参数,以此来延续之前的迭代过程。
当SCAN命令的游标参数被设置为 0 时, 服务器将开始一次新的迭代, 而当服务器向用户返回值为 0 的游标时, 表示迭代已结束。
向redis中初始化一批数据
127.0.0.1:6379> set a1 1
OK
127.0.0.1:6379> set a2 1
OK
127.0.0.1:6379> set a3 1
OK
127.0.0.1:6379> set a4 1
OK
127.0.0.1:6379> set a5 1
OK
127.0.0.1:6379> set a6 1
OK
127.0.0.1:6379> set a7 1
OK
127.0.0.1:6379> set a8 1
OK
127.0.0.1:6379> set a9 1
OK
127.0.0.1:6379> set a10 1
OK
使用scan迭代数据,后面游标参数指定为0,表示从头开始迭代key
127.0.0.1:6379> scan 0
1) "3"
2) 1) "a9"
2) "a3"
3) "a1"
4) "a10"
5) "a8"
6) "a5"
7) "a4"
8) "a"
9) "a7"
10) "a6"
SCAN 命令的返回值是一个包含两个元素的数组,
第一个元素是用于进行下一次迭代的新游标,而第二个元素则是一个数组, 这个数组中包含了所有被迭代出来的元素。
默认情况下scan返回10条数据
所以这样执行效果也是一样的
注意,游标的值并不等于返回的数据量。
- 判断键是否存在:exists
127.0.0.1:6379> exists a
(integer) 1
127.0.0.1:6379> exists b
(integer) 0
- 删除键:del
127.0.0.1:6379> del a
(integer) 1
- 获得键值的类型:type
返回值可能是这五种类型(string,hash,list,set,zset)
127.0.0.1:6379> set a 1
OK
127.0.0.1:6379> type a
string
这个命令可以帮我们快速识别某一个key中存储的数据是什么类型的,因为针对存储了不同类型值的
key,操作的命令是不一样的。
-
帮助命令:help
-
退出客户端:quit/exit
ctrl+c 也可以退出redis-cli客户端
Redis多数据库特性
Redis默认支持 16 个数据库,通过 databases 参数控制的
这个参数在redis.conf配置文件中
[root@bigdata04 redis-5.0.9]# cat redis.conf | grep databases
# Set the number of databases. The default database is DB 0, you can select
# dbid is a number between 0 and 'databases'-1
databases 16
# Compress string objects using LZF when dump .rdb databases?
每个数据库对外都是以一个从0开始的递增数字命名,不支持自定义
Redis默认选择的是0号数据库,可以通过 select 命令切换
127.0.0.1:6379> select 0
OK
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> select 2
OK
127.0.0.1:6379[2]> select 15
OK
127.0.0.1:6379[15]> select 16
(error) ERR DB index is out of range
一般在工作中会使用2~3个数据库,可以根据业务类型来分库,不同业务的数据存到不同的库里面。
还有一种用法是,一个库作为测试库,一个库作为正式库。
如果没有特殊需求,一般使用0号数据库就可以了,这个库使用起来比较方便,默认就是0号库,不需要使用select切换。具体在工作中怎么用都行,只要理解它的特性就可以了。
但是有一点需要注意:多个数据库之间并不是完全隔离的,如果使用flushall命令,则会清空redis中所有数据库内的数据。
并且我们在redis中使用多个库,并不能提高redis的存储能力,因为默认这16个库共用redis的内存存储空间,如果想要提高redis的存储能力,需要给我们的服务器增加内存才可以
127.0.0.1:6379[15]> set x 1
OK
127.0.0.1:6379[15]> flushall
OK
127.0.0.1:6379[15]> keys *
(empty list or set)
127.0.0.1:6379[15]> select 0
OK
127.0.0.1:6379> keys *
(empty list or
如果只想清空当前数据库中的数据,可以使用 flushdb
127.0.0.1:6379> select 15
OK
127.0.0.1:6379[15]> set a 1
OK
127.0.0.1:6379[15]> keys *
1) "a"
127.0.0.1:6379[15]> flushdb
OK
Redis数据类型
Redis数据类型之string
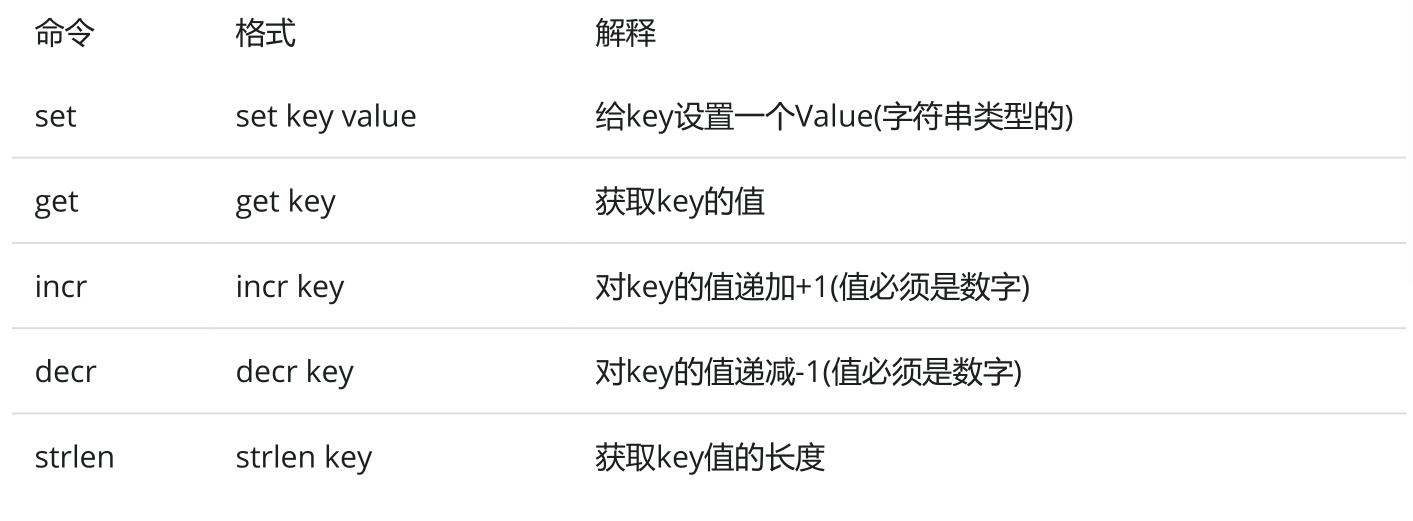
字符串类型是redis中最基本的数据类型,它能存储任何形式的内容,包含二进制数据,甚至是一张图片一个字符串类型的值存储的最大容量是1GB,一般情况下我们存储的单条数据肯定是达不到的这个限值的,所以大家不用担心string类型比较适合存储类型单一的数据。
针对string类型主要有下面这些常见命令
-
添加数据 set
-
查询数据 get
-
一次添加多条数据
127.0.0.1:6379> mset str1 a1 str2 a2
一次查询多条数据
127.0.0.1:6379> mget str1 str2
1) "a1"
2) "a2"
- 递增指定数值(整数类型)
127.0.0.1:6379> incrby num 2
(integer) 3
127.0.0.1:6379> get num
"3"
127.0.0.1:6379> incrby num 2.1
(error) ERR value is not an integer or out of range[注意:增量数值只支持integer
-
递减指定数值(整数类型)
-
获取指定key的value长度
127.0.0.1:6379> get str
"a"
127.0.0.1:6379> strlen str
(integer) 1
Redis数据类型之hash
hash类型的值存储了字段和字段值的映射,字段和字段值只能是字符串,不支持其他数据类型。
hash类型的值至多存储 2的32次方-1 个字段,一般情况下我们也达不到这个极限。
hash类型比较适合存储对象,因为对象里面是有一些属性和值的,我们就可以把这些属性和值存储到这个hash类型里面
针对hash类型主要有下面这些常见命令:

- 添加数据 hget
127.0.0.1:6379> hset user:1 name zs
(integer) 1
- 查询数据 hget
127.0.0.1:6379> hget user:1 name
"zs"
- 向一个hash中同时添加多个k-v hmset
127.0.0.1:6379> hmset user:2 name lisi age 18
OK
- 查询一个hash数据中多个k的值 hmget
127.0.0.1:6379> hmget user:2 name age
1) "lisi"
2) "18"
- 查询一个hash数据中的所有k-v hgetall
127.0.0.1:6379> hgetall user:2
1) "name"
2) "lisi"
3) "age"
4) "18"
- 判断一个hash数据中是否存在指定k hexists
127.0.0.1:6379> hexists user:2 name
(integer) 1
127.0.0.1:6379> hexists user:2 city
(integer) 0
Redis数据类型之list
list是一个有序的字符串列表,列表内部是使用双向链表(linked list)实现的。
list列表类型的值最多可以存储 2的32次方-1 个元素,一般我们也达不到这个限值。
list类型比较适合作为队列使用,使用lpush+rpop可以实现先进先出的队列
针对list类型主要有下面这些常见命令:
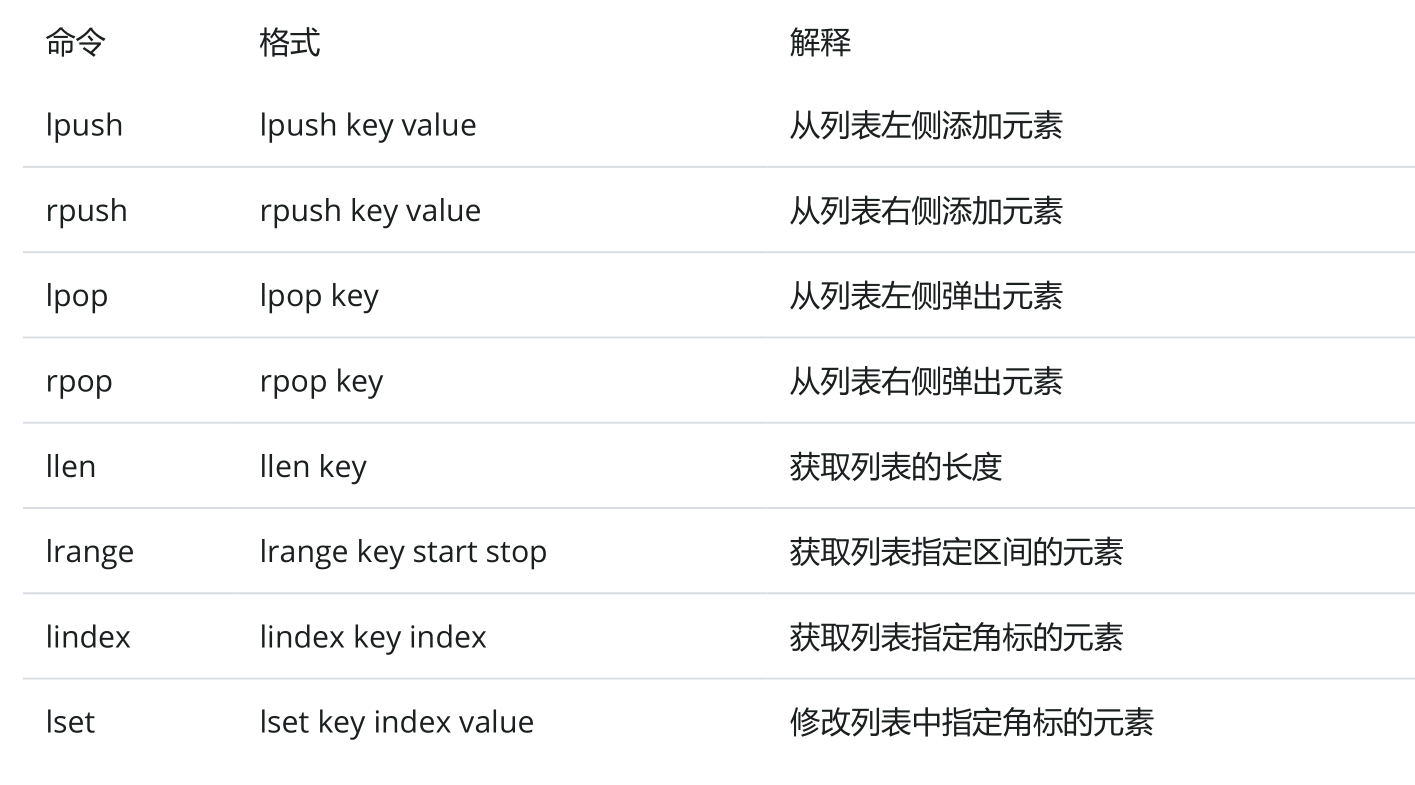
- 添加元素(左侧添加) lpush
127.0.0.1:6379> lpush list1 a
(integer) 1
127.0.0.1:6379> lpush list1 b
(integer) 2
- 取出元素(左侧取元素) lpop
127.0.0.1:6379> lpop list1
"b"
127.0.0.1:6379> lpop list1
"a"
127.0.0.1:6379> lpop list1
(nil)
- 添加元素(右侧添加) rpush
127.0.0.1:6379> rpush list2 x
(integer) 1
127.0.0.1:6379> rpush list2 y
(integer) 2
- 取出元素(右侧取元素) rpop
127.0.0.1:6379> rpop list2
"y"
127.0.0.1:6379> rpop list2
"x"
- 列表长度 llen
127.0.0.1:6379> lpush list3 a b c d
(integer) 4
127.0.0.1:6379> llen list3
(integer) 4
- 获取列表中的元素 lrange
127.0.0.1:6379> lrange list3 0 -1
1) "d"
2) "c"
3) "b"
4) "a"
- 查询指定角标元素 lindex
127.0.0.1:6379> lindex list3 1
"c"
- 修改指定角标元素 lset
127.0.0.1:6379> lset list3 1 m
OK
127.0.0.1:6379> lrange list3 0 -1
1) "d"
2) "m"
3) "b"
4) "a"
Redis数据类型之set
set是一个集合
set集合中的元素都是不重复的,无序的
set集合类型的值最多可以存储 2的32次方-1个 元素
set集合比较适合用在去重的场景下,因为它里面的元素是都不重复的
针对set类型主要有下面这些常见命令:

- 向集合中添加元素 sadd
127.0.0.1:6379> sadd set1 a
(integer) 1
127.0.0.1:6379> sadd set1 b
(integer) 1
- 获取集合中所有元素 smembers
127.0.0.1:6379> smembers set1
1) "b"
2) "a"
Redis数据类型之sorted set
有序集合,在集合类型的基础上为集合中的每个元素都关联了一个分数,根据分数进行排序,这样就实现了有序。
sorted set比较适合用在获取TopN的场景,因为它里面的数据是有序的
针对sorted set类型主要有下面这些常见命令:
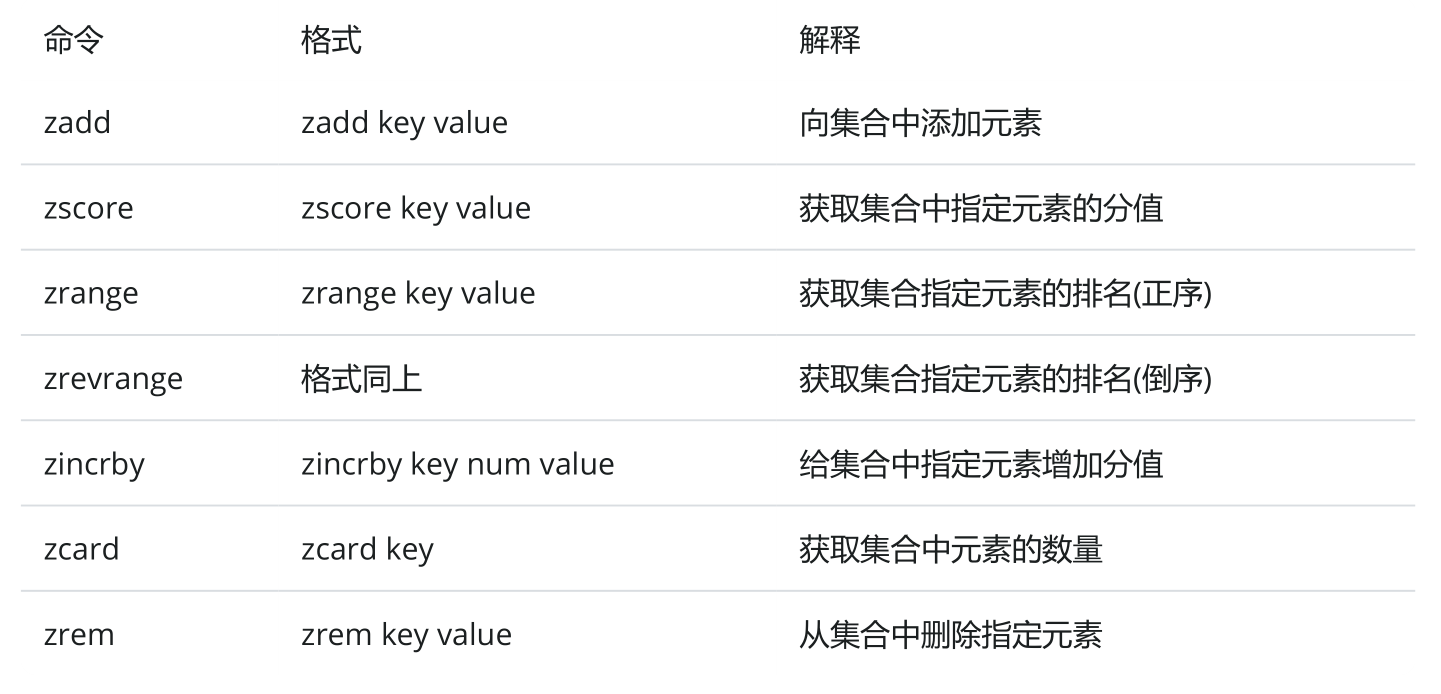
- 向集合中添加元素 zadd
127.0.0.1:6379> zadd zset1 5 a
(integer) 1
127.0.0.1:6379> zadd zset1 3 b
(integer) 1
127.0.0.1:6379> zadd zset1 4 c
(integer) 1
- 查询集合中指定元素的分值 zscore
127.0.0.1:6379> zscore zset1 a
"5"
- 根据角标获取集合中的元素(按照正序) zrange
127.0.0.1:6379> zrange zset1 0 -1
1) "b"
2) "c"
3) "a"
注意:
1:+inf(正无穷) -inf(负无穷),在给集合中的元素设置分值的时候可以使用这两个特殊数值。
2:set命令:如果key持有其它类型值,set会覆盖旧值,无视类型
案例:存储高一班的学员信息
需求:将学员的姓名、年龄、性别、住址信息保存到Redis中
分析一下:
在这里我们可以把学生认为是一个对象,学生对象具备了多个属性信息,姓名,年龄,性别,住址信息所以针对学生信息非常适合使用hash类型进行存储。
我们可以给学生生成一个编号拼接到key里面,姓名、年龄、性别、住址信息存储到hash类型的value中。
注意:这里面针对key的命名,stu是student的简写,尽量不要写太多字符,否则会额外占用内存空间的,后面的:1,表示这个学生的编号是1,后期如果我们想获取所有学员的key,就可以使用
这个规则进行过滤了。
127.0.0.1:6379> hmset stu:1 name xiaoming age 18 sex 0 address beijing
OK
127.0.0.1:6379> hgetall stu:1
1) "name"
2) "xiaoming"
3) "age"
4) "18"
5) "sex"
6) "0"
7) "address"
8) "beijing"
127.0.0.1:6379> hget user:1 age
"18"
Redis封装工具类技巧
如何使用java代码操作redis
我们需要借助于第三方jar包jedis来操作
首先在idea中创建maven项目 db_redis
在pom.xml文件中添加jedis依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.3.0</version>
</dependency>
注意:jedis的版本号和redis的版本号不是一一对应的。
单连接方式
接下来使用单连接的方式操作redis
代码如下:
package com.imooc.redis;
import redis.clients.jedis.Jedis;
/**
* 单连接方式操作redis
*/
public class RedisSingle {
/**
* 注意:此代码能够正常执行的前提是
* 1:redis所在服务器的防火墙需要关闭
* 2:redis.conf中的bind参数需要指定192.168.182.103
* @param args
*/
public static void main(String[] args) {
//获取jedis连接
Jedis jedis = new Jedis("192.168.182.103",6379);
//向redis中添加数据,key=imooc,value=hello bigdata!
jedis.set("jedis","hello bigdata!");
//从redis中查询key=imooc的value的值
String value = jedis.get("jedis");
System.out.println(value);
//关闭jedis连接
jedis.close();
}
}
代码执行效果如下:
hello bigdata!
此时到redis中确认一下:
127.0.0.1:6379> keys *
1) "jedis"
127.0.0.1:6379> get imooc
"hello bigdata!"
在这你会发现,我们前面讲的那些在redis-cli中使用的命令,和jedis中提供的函数名称是一一对应
的。切换到代码中来使用也是可以直接上手的。
连接池方式
接下来使用连接池的方式操作redis
代码如下:
package com.imooc.redis;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* 连接池的方式操作redis
*/
public class RedisPool {
public static void main(String[] args) {
//创建连接池配置对象
JedisPoolConfig poolConfig = new JedisPoolConfig();
//连接池中最大空闲连接数
poolConfig.setMaxIdle(10);
//连接池中创建的最大连接数
poolConfig.setMaxTotal(100);
//创建连接的超时时间
poolConfig.setMaxWaitMillis(2000);
//表示从连接池中获取连接的时候会先测试一下连接是否可用,这样可以保证取出的连
poolConfig.setTestOnBorrow(true);
//获取jedis连接池
JedisPool jedisPool = new JedisPool(poolConfig, "192.168.182.103", 63
//从jedis连接池中取出一个连接
Jedis jedis = jedisPool.getResource();
String value = jedis.get("jedis");
System.out.println(value);
//注意:此处的close方法有两层含义
//1:如果jedis是直接创建的单连接,此时表示直接关闭这个连接
//2:如果jedis是从连接池中获取的连接,此时会把这个连接返回给连接池
jedis.close();
//关闭jedis连接池
jedisPool.close();
}
}
执行结果:
hello bigdata!
案例:提取RedisUtils工具类
基于redis连接池的方式提取RedisUtils工具类
package com.imooc.redis;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* 基于redis连接池提取redis工具类
*/
public class RedisUtils {
//私有化构造函数,禁止new
private RedisUtils(){}
private static JedisPool jedisPool = null;
//获取连接
public static synchronized Jedis getJedis(){
if(jedisPool==null){
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxIdle(10);
poolConfig.setMaxTotal(100);
poolConfig.setMaxWaitMillis(2000);
poolConfig.setTestOnBorrow(true);
jedisPool = new JedisPool(poolConfig, "192.168.182.103", 6379);
}
return jedisPool.getResource();
}
//向连接池返回连接
public static void returnResource(Jedis jedis){
jedis.close();
}
}
使用工具类代码
package com.imooc.redis;
import redis.clients.jedis.Jedis;
public class TestRedisUtils {
public static void main(String[] args) {
//获取连接
Jedis jedis = RedisUtils.getJedis();
String value = jedis.get("jedis");
System.out.println(value);
//向连接池返回连接
RedisUtils.returnResource(jedis);
}
}
Redis高级特性
expire 生存时间
Redis中可以使用expire命令设置一个键的生存时间,到时间后Redis会自动删除它。
它的一个典型应用场景是:手机验证码
我们平时在登录或者注册的时候,手机会接收到一个验证码,上面会提示验证码的过期时间,过了这个时间之后这个验证码就不能用了。
expire支持以下操作
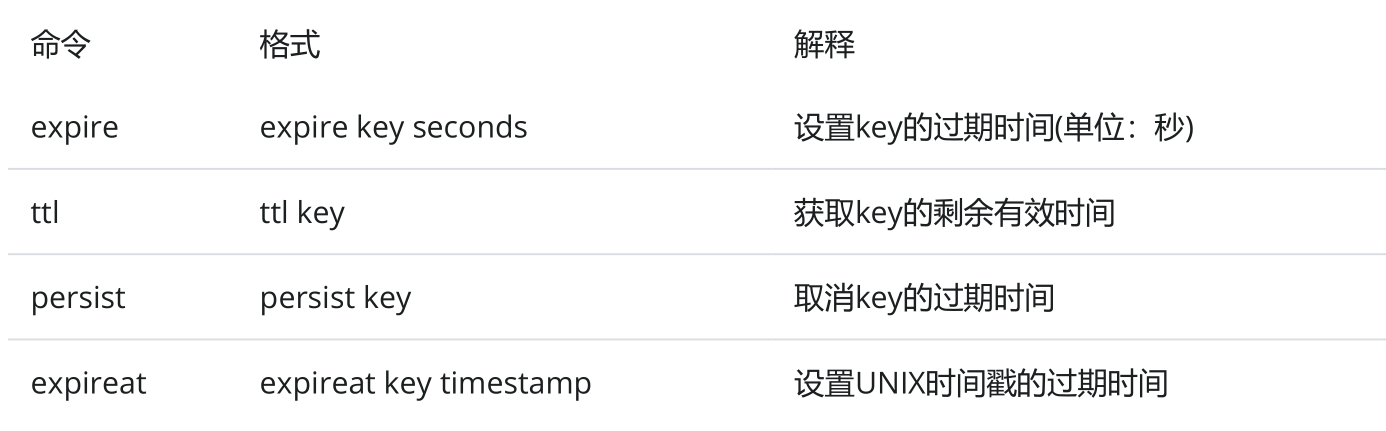
- 设置key的过期时间
127.0.0.1:6379> set abc 123
OK
127.0.0.1:6379> expire abc 200
(integer) 1
- 获取key的剩余有效时间
127.0.0.1:6379> ttl abc
(integer) 192
- 取消key的过期时间
127.0.0.1:6379> persist abc
(integer) 1
此时再查看这个key的剩余有效时间,返回的值是-1,-1表示这个key是一个永久存在的key
127.0.0.1:6379> ttl abc
(integer) -1
- 还可以通过expireat指定key在指定时间点过期
总结一下:
当key永久存在的时候,执行ttl返回的是-1,
当key被设置了过期时间之后,执行ttl返回的就是这个key剩余的有效时间
当key已经被删除了,不存在的时候,执行ttl返回的是-2
pipeline 管道
针对批量操作数据或者批量初始化数据的时候使用,效率高
Redis的pipeline功能在命令行中没有实现,在Java客户端(jedis)中是可以使用的
它的原理是这样的
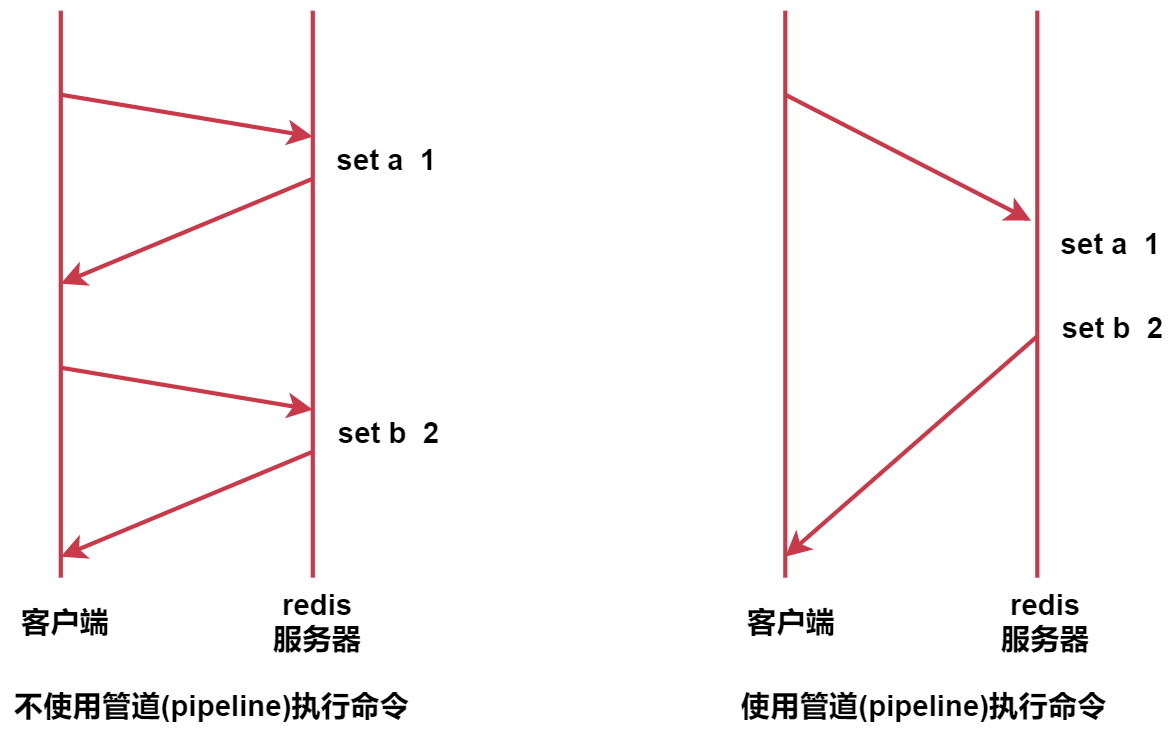
不使用管道的时候,我们每执行一条命令都需要和redis服务器交互一次
使用管道之后,可以实现一次提交一批命令,这一批命令只需要和redis服务器交互一次,所以就提高了性能。这个功能就类似于mysql中的batch批处理。
案例:初始化10万条数据
需求:使用普通方式一条一条添加和使用管道批量初始化进行对比分析
代码如下:
package com.imooc.redis;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
/**
* pipeline(管道)的使用
*/
public class PipelineOp {
public static void main(String[] args) {
//1:不使用管道
Jedis jedis = RedisUtils.getJedis();
long start_time = System.currentTimeMillis();
for(int i=0;i<100000;i++){
jedis.set("a"+i,"a"+i);
}
long end_time = System.currentTimeMillis();
System.out.println("不使用管道,耗时:"+(end_time-start_time));
//2:使用管道
Pipeline pipelined = jedis.pipelined();
start_time = System.currentTimeMillis();
for(int i=0;i<100000;i++){
pipelined.set("b"+i,"b"+i);
}
pipelined.sync();
end_time = System.currentTimeMillis();
System.out.println("使用管道,耗时:"+(end_time-start_time));
RedisUtils.returnResource(jedis);
}
}
结果如下
不使用管道,耗时:40887
使用管道,耗时:180
在代码执行的过程中,我们可以使用info命令观察数据库中的数据条数
127.0.0.1:6379> info
# Keyspace
db0:keys=200000,expires=1,avg_ttl=389945
针对海量数据的初始化,管道可以显著提高初始化性能。
info命令
这里面参数比较多
在这我们主要关注几个重点的参数
# Redis 服务器版本
redis_version:5.0.9
# Redis服务的可执行
executable:/data/soft/redis-5.0.9/redis-server
# 启动Redis时使用的配置文件路径
config_file:/data/soft/redis-5.0.9/redis.conf
# 已连接客户端的数量
connected_clients:1
# Redis目前存储数据使用的内容
used_memory_human:15.01M
# Redis可以使用的内存总量,和服务器的内存有关
total_system_memory_human:1.78G
# db0表示0号数据库,keys:表示0号数据库的key总量,expires:表示0号数据库失效被删除的
db0:keys=200001,expires=1,avg_ttl=389945
Redis的持久化
Redis持久化简单理解就是把内存中的数据持久化到磁盘中 可以保证Reids重启之后还能恢复之前的数据
Redis支持两种持久化,可以 单独使用 或者 组合使用
RDB 和 AOF
RDB是Redis默认的持久化机制
Redis持久化之RDB
RDB持久化是通过快照完成的,当符合一定条件时Redis会自动将内存中的所有数据执行快照操作并存储到硬盘上,默认存储在 dump.rdb 文件中
[root@bigdata04 redis-5.0.9]# ll
....
-rw-r--r--. 1 root root 2955661 Jan 17 12:12 dump.rdb
Redis什么时候会执行快照?
Redis执行快照的时机是由以下参数控制的,这些参数是在redis.conf文件中的
save 900 1
save 300 10
save 60 10000
save 900 1 表示900秒内至少一个key被更改则进行快照
这里面的三个时机哪个先满足都会执行快照操作。
RDB的优点:由于存储的有数据快照文件,恢复数据很方便
RDB的缺点:会丢失最后一次快照以后更改的所有数据,因为两次快照之间是由一个时间差的,这一段时间之内修改的数据可能会丢。
Redis持久化之AOF
AOF持久化是通过日志文件的方式,默认情况下没有开启,可以通过 appendonly 参数开启
[root@bigdata04 redis-5.0.9]# vi redis.conf
....
appendonly yes
....
AOF日志文件的保存位置和RDB文件相同,都是dir参数设置的,默认的文件名是 appendonly.aof
注意:dir参数的值为. 表示当前目录,也就是说我们在哪个目录下启动redis,rdb快照文件和aof
日志文件就产生在哪个目录下。
可以试验一下,换一个目录启动redis,发下redis中的数据是空的。关闭之后,重新在之前的目录启动redis,数据又回来了。
AOF方式只会记录用户的写命令,添加、修改、删除之类的命令,查询命令不会记录,因为查询命令不会影响数据的内容。
那redis什么时候会把用户的写命令同步到aof文件中呢?
# appendfsync always
appendfsync everysec
# appendfsync no
默认是每秒钟执行一次同步操作。appendfsync everysec
也可以实现每执行一次写操作就执行一次同步操作,appendfsync always,但是这样效率会有低。或者使用appendfsync no,表示不主动进行同步,由操作系统来做,30秒执行一次。
如果大家对数据的丢失确实是0容忍的话,可以使用always。
不过一般情况下,redis中存储的都是一些缓存数据,就算丢了也没关系,程序还会继续往里面写新数据,不会造成多大影响。
Redis 的安全策略
设置数据库密码
默认情况下访问redis只要网络能通就可以直接访问,这样其实是有一些不安全的,不过我们一般会限制只能在内网访问,这样其实问题也不大。
redis针对这个问题,也支持给数据库设置密码,在redis.conf中配置
[root@bigdata04 redis-5.0.9]# vi redis.conf
....
requirepass admin
....
重启redis服务
[root@bigdata04 redis-5.0.9]# redis-cli shutdown
[root@bigdata04 redis-5.0.9]# redis-server redis.conf
重新连接redis
[root@bigdata04 redis-5.0.9]# redis-cli
127.0.0.1:6379> get imooc
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth admin
OK
127.0.0.1:6379>get jedis
在代码层面,以后在使用的时候时候就需要使用auth方法先校验权限了。
package com.imooc.redis;
import redis.clients.jedis.Jedis;
/**
* 单连接方式操作redis
*/
public class RedisSingle {
/**
* 注意:此代码能够正常执行的前提是
* 1:redis所在服务器的防火墙需要关闭
* 2:redis.conf中的bind参数需要指定192.168.182.103
* @param args
*/
public static void main(String[] args) {
//获取jedis连接
Jedis jedis = new Jedis("192.168.182.103",6379);
//使用密码
jedis.auth("admin");
//向redis中添加数据,key=imooc,value=hello bigdata!
jedis.set("jedis","hello bigdata!");
//从redis中查询key=imooc的value的值
String value = jedis.get("jedis");
System.out.println(value);
//关闭jedis连接
jedis.close();
}
}
注意:在实际工作中一般不会设置密码,因为我们在这设置的密码是明文的,其实意义也不大,针对别有用心的人,你这样设置是没有意义的。
所以在实际工作中我们一般只需要控制好redis服务器的访问权限就可以了,redis服务器的访问权限其实就是使用bind参数来设置的。
所以再把刚才设置的密码取消掉,直接把对应的配置注释掉即可
bind参数的应用
在实际工作中,我们的服务器至少会有3个ip地址
127.0.0.1 这个是本机回环地址
192.168.182.103 这个是本机的内网地址
还有一个是外网地址
我们一般会使用bind绑定内网ip,这样其实就限制了redis服务器的访问范围,不会暴露在外网,只需要运维同学做好网络的访问限制就可以了,此时我们就可以认为redis是安全的了
命令重命名
前面讲过一个命令是 flushall ,这个命令是很危险的,它可以把redis中的所有数据全部清空
所以在实际工作中一般需要将这个命令给禁用掉,防止误操作。
在redis.conf配置文件中进行设置
[root@bigdata04 redis-5.0.9]# vi redis.conf
....
rename-command flushall ""
....
这样修改之后,就把flushall命令给禁用掉了
重启redis服务
[root@bigdata04 redis-5.0.9]# redis-cli shutdown
[root@bigdata04 redis-5.0.9]# redis-server redis.conf
重新连接redis
[root@bigdata04 redis-5.0.9]# redis-cli
127.0.0.1:6379> flushall
(error) ERR unknown command `flushall`, with args beginning with:
127.0.0.1:6379>
此时会提示未知命令。
一个Redis实例最多能存放多少key?
一个Redis实例最多能存放多少key?
有没有限制?
Redis本身是不会限制存储多少key的,但是Redis是基于内存的,它的存储极限是系统中的可用内存值,如果内存存满了,那就无法再存储key了。
Redis监控命令-monitor
这个 monitor 命令是一把双刃剑。
在实际工作中要慎用。
先演示一下:
[root@bigdata04 redis-5.0.9]# redis-cli
127.0.0.1:6379> monitor
OK
执行代码 RedisSingle.java 中的代码,然后会发现monitor监控到我们对redis的所有操作
[root@bigdata04 redis-5.0.9]# redis-cli
127.0.0.1:6379> monitor
OK
1768628815.007443 [0 192.168.182.1:60633] "SET" "jedis" "hello bigdata!"
1768628815.007797 [0 192.168.182.1:60633] "GET" "jedis"
monitor可以监控我们对redis的所有操作,如果在线上的服务器上打开了这个功能,这里面就会频繁打印出来我们对redis数据库的所有操作,这样会影响redis的性能,所以说要慎用。
但是在某些特殊的场景下面它是很有用的
之前在工作中我遇到过一个很奇怪的问题,redis中的一个key总是会莫名其妙的消失。
我的一个程序会定时向redis中写入一个key,但是我发现这个key刚写进去,然后一会就没了,很奇怪,当时我仔细排查了我的代码,里面既没有设置失效时间,也没有使用删除功能。
所以这个key不是我的代码删的,肯定是有其它的代码会删除这个key,但是到底是哪的代码?
这个时候就不好排查了,我们的业务机有几十台,根本无从下手。
这个时候我突然想到了monitor这个命令,虽然开启monitor会影响redis的性能,但是这个时候需要排查问题,使用一会也是可以接受的。
所以就打开了monitor,打开之后屏幕上就打印出来很多命令,这样根本就看不清,没办法追踪,数据太多了。所以又想到了这个办法,结合grep命令来操作,这样就可以过滤出来对指定key的所有操作了。
[root@bigdata04 redis-5.0.9]# redis-cli monitor | grep key
1768629282.484868 [0 192.168.182.1:52364] "del" "key"
通过这条数据我们可以分析出来到底是哪台机器上的程序删除了这个key。然后再排查这台机器上都有哪些程序,对应的去排查代码,这样就快多了,最终发现是有一个代码里面会定时删除这个key。
这个就是monitor的典型应用。
Redis架构演进
现在我们使用的Redis是单机的,单机的Redis存在单点故障的问题,
所以Redis提供了主从复制的方案
主从复制
Redis的复制功能支持多个数据库之间的数据同步。
通过Redis的复制功能可以很好的实现数据库的 读写分离,提高服务器的负载能力。
主数据库(Master)主要进行写操作,而从数据库(Slave)负责读操作。个主数据库可以有多个从数据库,而一个从数据库只能有一个主数据库
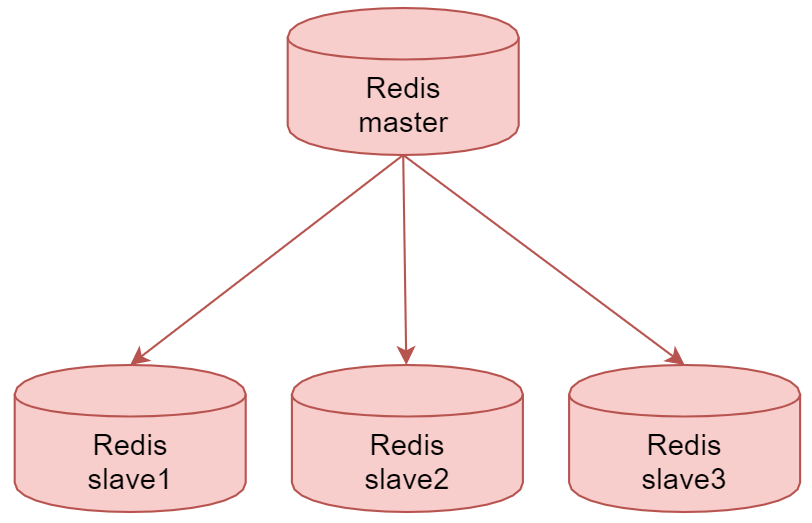
这个就是redis的主从复制架构
master节点,是主数据库,负责写操作,下面的3个slave节点是从数据库,负责读操作。
当我们把数据写入到master节点之后,master节点会把数据同步给下面的3个从节点。
这就是Redis的主从复制架构。这种架构其实存在一个问题,如果主节点挂了,从节点是无法自动切换为主节点的。所以这个时候只能读数据,不能写数据。这样肯定还是存在单点故障的。所以redis在这个架构的基础上又提供了sentinel 哨兵机制。
Sentinel
这个sentinel哨兵机制提供了三个功能
- 监控:Sentinel实时监控主服务器和从服务器运行状态
- 提醒:当被监控的某个Redis服务器出现问题时,Sentinel 可以向系统管理员发送通知, 也可以通过API向其它程序发送通知
- 自动故障转移:当一个主服务器不能正常工作时,Sentinel可以将一个从服务器升级为主服务器, 并对其它从服务器进行配置,让它们使用新的主服务器。
看下面这个图:
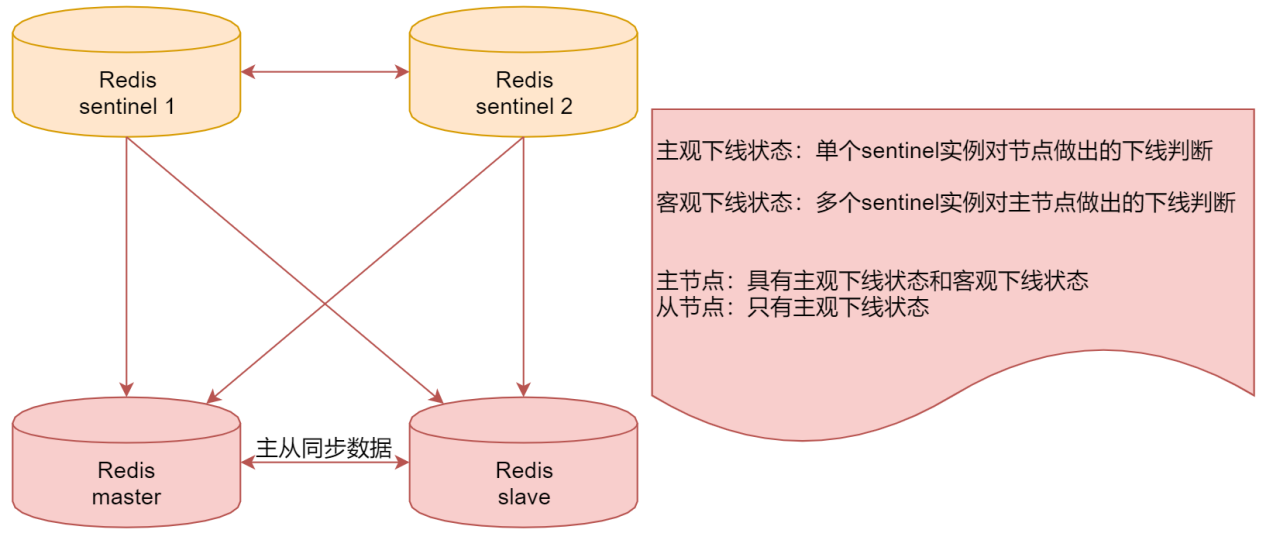
上面这两个sentine1和sentinel2就是使用redis启动的哨兵服务。
他们两个可以监控下面的这个主从架构的redis,当发现master宕机之后,会把slave切换为。master。
这里面涉及两个概念,大家需要注意一下一个是主观下线状态,一个是客观下线状态
主观下线状态表示是单个sentinel实例对节点做出的下线判断
客观下线状态表示是多个sentinel实例对主节点做出的下线判断
注意:针对主节点,它具有主观下线状态和客观下线状态,在这个架构里面,如果sentinel1
认为master节点挂了,那么会给它标记为主观下线状态,此时,并不会进行故障转移,有可能是sentinel1误判了,当sentinel2也认为master节点挂了,那么此时会给master标记为客观下线状态,因为这个时候不是一个人认为它挂了,当被标记为客观下线状态之后,此时就会进行故障转移了,slave节点就会变成master节点了。针对从节点而言,只有主观下线状态,就算是误判也没有什么影响。这就是Redis中的sentinel哨兵机制。
sentinel哨兵机制虽然解决了主从节点故障自动转移的问题,但是还存在一个问题,针对这种架构,不管你使用多少台机器,redis的最终存储能力还是和单台机器有关的。如果我们想存储海量数据的话,这种架构理论上是实现不了的。基于此,Redis提供了集群这种架构。
集群
Redis集群是一个无中心的分布式Redis存储架构,可以在多个节点之间数据共享,解决了Redis高可用、可扩展等问题。
一个Redis集群包含 16384 个哈希槽(hash slot),数据库中的每个数据都属于这16384个哈希槽中的一个集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽,集群中的每一个节点负责维护一部分哈希槽。
集群中的每个节点都有1个至N个复制品,其中一个是主节点其余的是从节点,如果主节点下线了,集群就会把这个主节点的一个从节点设置为新的主节点,继续工作。
注意:如果某一个主节点和它所有的从节点都下线的话,集群就会停止工作了
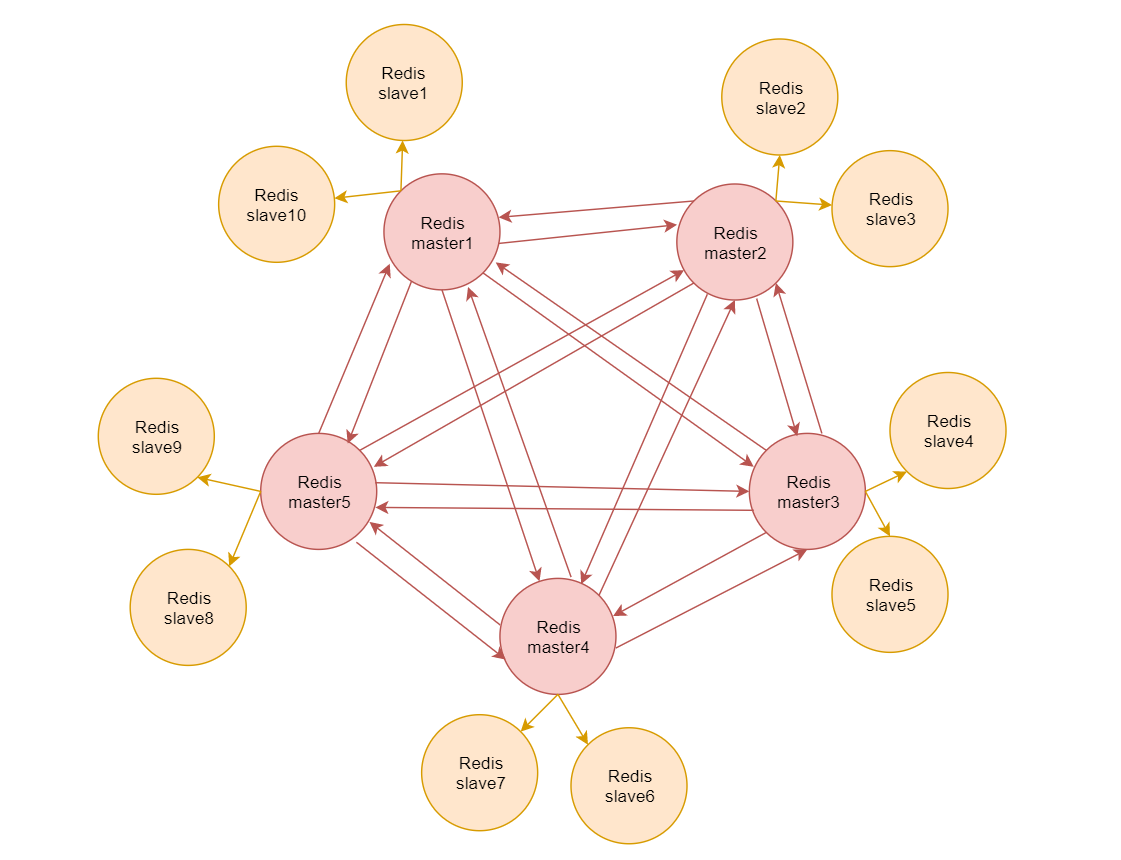
里面红色的表示是5个master节点,此时redis集群的存储能力就是这5个master节点内存的总和。
针对每一个master节点,外面都有两个从节点,master节点宕机之后,对应的slave节点会自动切换为master节点,保证集群的稳定性和可用性。
如果master1和slave2、slave10这三个节点都宕机了,那么此时集群就无法使用了。
针对Redis集群而言,它是一个无中心节点的分布式存储架构。
我们在操作集群的时候,可以连接到集群的任意一个节点去操作,都是可以的,在使用的时候不用管数据到底存储在哪个节点上面,这个是redis底层去处理的,我们只需要连接到任意一台机器去操作即可。集群架构里面已经包含了主从架构和sentinel的功能,不需要单独配置了。