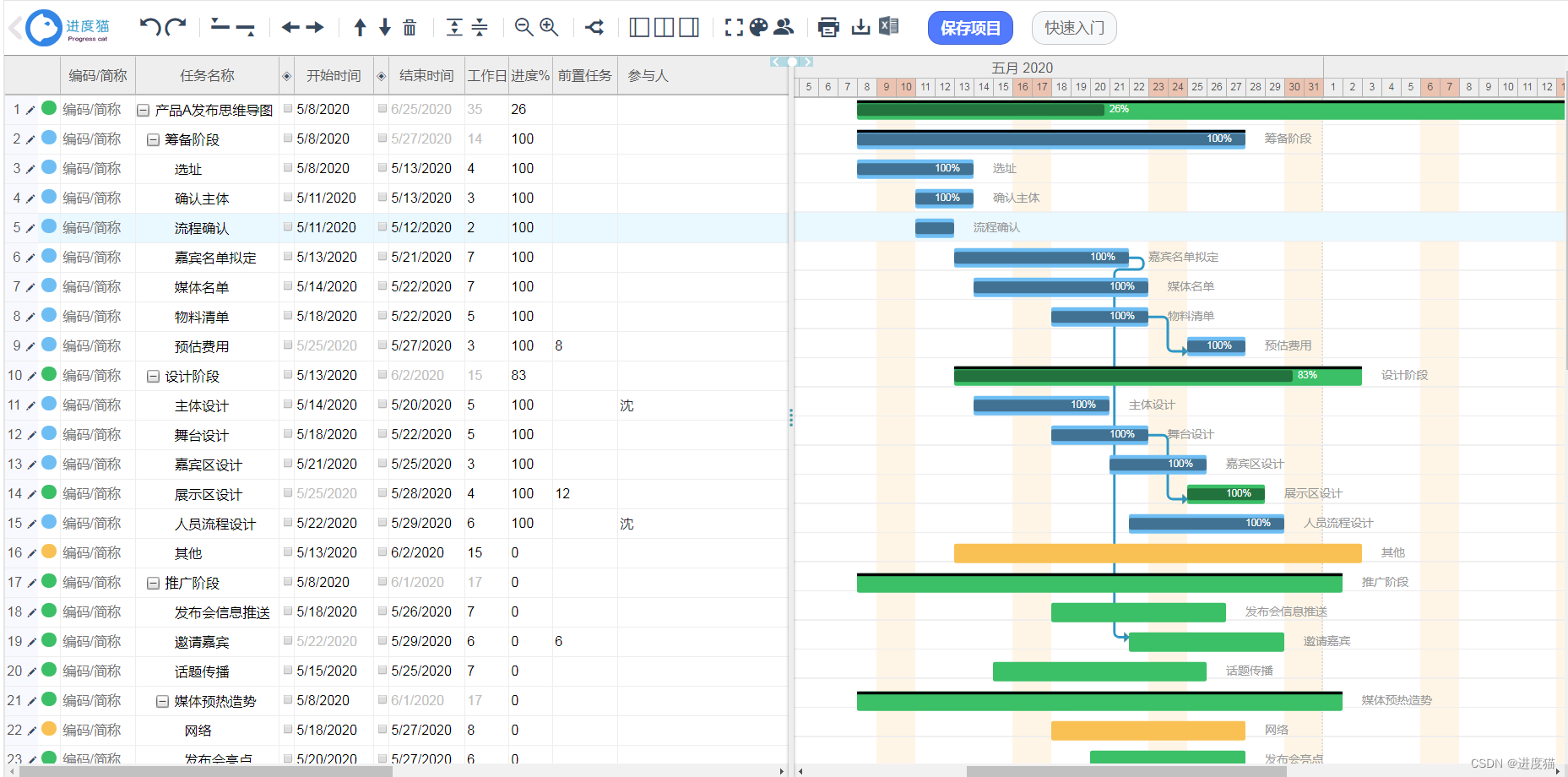
在项目开展过程中,发现大疆M30T的红外相机存在比较明显的畸变问题,因此需要对红外图像进行畸变矫正。在资料检索过程中,发现对红外无人机影像矫正的资料较少,对此,我从相机的成像原理角度出发,探索出一种效果尚可的解决思路,遂以本文记录如下。
畸变矫正模型
目前采用的主流相机畸变矫正模型基本都是Brown-Conrady模型,原论文:Decentering Distortion of Lenses
其中,该模型将畸变类型划分成两类:径向畸变和切向畸变。
径向畸变的原因是透镜表面的弧度引起的光线折射角不同,导致越靠镜头的边缘畸变越严重。根据凹凸性可分成桶型畸变和枕型畸变,示意图如下。

根据畸变模型,可得畸变矫正公式如下:

切向畸变的原因是透镜本身与成像平面不平行。根据模型,可得畸变矫正公式如下:

式中,各符号参数含义如下:

本质上,这两个公式的形式都应用到泰勒展开,因此,需要实现畸变矫正,只需要确定5个未知量,即5个畸变参数。
通常来说,k1和k2的数值足以完成大多数的畸变,k3除了鱼眼相机外,影响不大,因此在后面使用OpenCV进行实践时,参数返回的顺序是这样:D = [k1 k2 p1 p2 k3]
目前很多主流软件算法也使用这套模型,比如在pix4d中,相机参数一栏需要填写这5个量。

畸变参数属于相机的内参,和焦距,像素大小等内参类似,一经出厂就固定,和拍摄物体的远近没有关系。一些相机厂商会提供相关的内参数值,不过大疆显然并没有提供,参考一些大疆社区的提问帖,就算询问客服也无从得知,因此需要通过自己测量得到相关的数值。
四个坐标系
由于畸变参数属于内参,在测量时,可以采用相机标定的方式,同时得到相机的内外参数。在此之前,需要先了解相机模型的四个坐标系。

- 世界坐标系 x w x_w xw- y w y_w yw- z w z_w zw:物理世界中,指定某一点形成固定不变的坐标系
- 相机坐标系 x c x_c xc- y c y_c yc- z c z_c zc:相机的光心为坐标原点
- 图像坐标系 x i x_i xi- y i y_i yi:感光芯片的中心为坐标原点
- 像素坐标系 x p x_p xp- y p y_p yp:通过图像坐标系缩放平移得到
通常对目标进行检测时,输出目标的像素是基于像素坐标系,但对其它的坐标系感知并不是很明显,除了在三维软件建模时,会感知到世界坐标系。
从世界坐标系到相机坐标系
在世界三维坐标系中确定一点,只需要利用简单的刚体变换,即左乘一个R旋转矩阵加上三个轴向的平移量,公式表示如下:

由于存在平移量的加法,会导致后续嵌套表示复杂,因此引入齐次坐标,将该表达式化成矩阵相乘的形式。

从相机坐标系到图像坐标系
这一步需要将三维坐标系中的一点投射到二维平面,用透视投影的公式表示如下:

从图像坐标系到像素坐标系
这一步只需缩放平移,可用仿射变换的公式表示如下:

整体变换公式
从世界坐标系到相机坐标系所需参数被称为外参,从相机坐标系到像素坐标系所需参数被称为内参。
联立上面几个公式可以得到在理想无畸变的情况下,从世界坐标系一点到像素坐标系上对应点的变换公式[2]:

其中,(U,V,W)为世界坐标系下一点的物理坐标,(u,v)为该点对应的在像素坐标系下的像素坐标, Z为尺度因子。
值得注意的是,在这个公式中,引入了新的一个角度 θ \theta θ,表示感光板的横边和纵边之间的角度,在上面单独部分的推导中,默认为90°,即表示无误差。
棋盘格标定法
理论思路
相机的标定有许多方法,最广泛使用的是张正友教授于1998年提出的单平面棋盘格的摄像机标定方法。
算法的推导较复杂,总体思路如下[2]:
(1) 求解内参矩阵与外参矩阵的积H,对应计算关系如下:

由于H是齐次矩阵,因此只需要求解8个独立元素值,每一对(u,v)和(U,V)点可以提供2个约束方程,因此理论上只需要标定4对点就可以求解出H。不过在实际应用中,为了避免噪声扰动,往往需要更多点来辅助计算。
(2) 求解内参矩阵A
在求解A的过程中,可以先求解 A − T A − 1 A^{-T}A^{-1} A−TA−1,记 B = A − T A − 1 B=A^{-T}A^{-1} B=A−TA−1,计算公式如下:

由于B是对称矩阵,因此实际上需要求解6个未知元素。一张图片可以提供两个约束方程,因此至少需要三张图片,就可以求解出矩阵B和A。实际中,一般需要更多图片,至少10张以上。
(3) 求解外参矩阵[R T]
求出H和A之后,外参矩阵就很容易求解: [ R T ] = A − 1 H [R T] = A^{-1}H [RT]=A−1H
实际操作
下面尝试对可见光进行去畸变操作,方法流程如下[5]:
(1)打印一张棋盘方格图
(2)从不同角度拍摄若干张模板图像
(3)检测出图像中的特征点
(4)由检测到的特征点计算出每幅图像中的平面投影矩阵H
(5)确定出摄像机的参数
首先需要打印一张图片,可以直接用网上的资源直接打印,棋盘格A4
然后调用相机从不同角度拍摄,这里可以保持相机不动图片动;也可以保持相机同图片不动,我这里采用的是前者。

不过我这里有一点没注意,导致后面用可见光矫正时效果有偏差。这里的标定纸建议贴在硬纸板上,或者直接购买一些标定板,这样可以保证棋盘格上的角点始终为同一平面,否则像图中我的棋盘纸出现弯折,影响模型计算。
我找到了别人拍摄的两组示例,可以当作参考:


拍摄完成之后,调用OpenCV的函数接口可以比较方便的定位出内角点。
- 首先根据棋盘格的内角点(内部黑白相间的点),初始化坐标对。
# 1.找棋盘格角点
# 棋盘格模板规格
# 内角点个数
W = 5
H = 8
# 世界坐标系中的棋盘格点,例如(0,0,0), (1,0,0), (2,0,0) ....,(8,5,0),去掉Z坐标,记为二维矩阵
objp = np.zeros((W * H, 3), np.float32)
objp[:, :2] = np.mgrid[0:W, 0:H].T.reshape(-1, 2)
# 储存棋盘格角点的世界坐标和图像坐标对
objpoints = [] # 在世界坐标系中的三维点
imgpoints = [] # 在图像平面的二维点
这里相邻点实际以毫米作为单位,而在官方例程中,也可以使用角点个数作为单位。
- 灰度化图像,通过
cv2.findChessboardCorners来找到角点位置,若找到,返回ret=True
img = cv2.imread(fname)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 找到棋盘格角点
# 棋盘图像(8位灰度或彩色图像) 棋盘尺寸 存放角点的位置
ret, corners = cv2.findChessboardCorners(gray, (W, H), None)
- 调用
cv2.findChessboardCorners来进一步精确调整角点位置。
# 阈值
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
# 角点精确检测
# 输入图像 角点初始坐标 搜索窗口为2*winsize+1 死区 求角点的迭代终止条件
# 增加准确度
cv2.cornerSubPix(gray, corners, (11, 11), (-1, -1), criteria)
objpoints.append(objp)
imgpoints.append(corners)
- 调用
cv2.calibrateCamera来得到标定结果 相机的内参数矩阵 畸变系数 旋转矩阵 平移向量
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, gray.shape[::-1], None, None)
print(("ret:"), ret)
print(("mtx内参数矩阵:\n"), mtx, type(mtx)) # 内参数矩阵
print(("dist畸变值:\n"), dist, type(dist)) # 畸变系数 distortion cofficients = (k_1,k_2,p_1,p_2,k_3)
print(("rvecs旋转(向量)外参:\n"), rvecs) # 旋转向量(外参数)
print(("tvecs平移(向量)外参:\n"), tvecs) # 平移向量(外参数)
np.save('mtx.npy', mtx)
np.save('dist.npy', dist)
对于畸变矫正任务来说,不需要外参,因此只需要保存内参数矩阵和畸变系数。
- 调用保存的参数,对输入图像进行去畸变操作
# 去畸变
mtx = np.load("mtx_hw.npy")
dist = np.load("dist_hw.npy")
img = cv2.imread(r'img.jpg')
h, w = img.shape[:2]
# 我们已经得到了相机内参和畸变系数,在将图像去畸变之前,
# 我们还可以使用cv.getOptimalNewCameraMatrix()优化内参数和畸变系数,
# 通过设定自由自由比例因子alpha。当alpha设为0的时候,将会返回一个剪裁过的将去畸变后不想要的像素去掉的内参数和畸变系数;
# 当alpha设为1的时候,将会返回一个包含额外黑色像素点的内参数和畸变系数,并返回一个ROI用于将其剪裁掉
newcameramtx, roi = cv2.getOptimalNewCameraMatrix(mtx, dist, (w, h), 0, (w, h)) # 自由比例参数
# undistort 得到的ROI对结果进行裁剪。
dst = cv2.undistort(img, mtx, dist, None, newcameramtx)
x, y, w, h = roi
dst = dst[y:y + h, x:x + w]
cv2.imwrite(r'result.jpg', dst)
- 计算重投影误差
进行完前五步,已经可以得到一个畸变矫正的结果。这一步的重投影误差主要是用来评估结果的准确性,类似与深度学习中的Loss。
重投影误差是指利用计算得到的内外参,将世界坐标系中的点投影到像素坐标系,和本身已知的像素坐标系上的点做误差比较。
# 计算重投影误差
total_error = 0
for i in range(len(objpoints)):
imgpoints2, _ = cv2.projectPoints(objpoints[i], rvecs[i], tvecs[i], mtx, dist)
error = cv2.norm(imgpoints[i],imgpoints2, cv2.NORM_L2)/len(imgpoints2)
total_error += error
print("total error: ", total_error/len(objpoints))
完整代码如下:
import cv2
import numpy as np
import glob
np.set_printoptions(suppress=True) # 用于控制Python中小数的显示精度 suppress:小数是否需要以科学计数法的形式输出
# 1.找棋盘格角点
# 棋盘格模板规格
W = 5 # 内角点个数,内角点是和其他格子连着的点
H = 8
# 阈值
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
# 世界坐标系中的棋盘格点,例如(0,0,0), (1,0,0), (2,0,0) ....,(8,5,0),去掉Z坐标,记为二维矩阵
objp = np.zeros((W * H, 3), np.float32)
objp[:, :2] = np.mgrid[0:W, 0:H].T.reshape(-1, 2)
# 储存棋盘格角点的世界坐标和图像坐标对
objpoints = [] # 在世界坐标系中的三维点
imgpoints = [] # 在图像平面的二维点
imgsPath = "kjg"
images = glob.glob(imgsPath + '/*.jpg') # 拍摄棋盘的图片
i = 0
for fname in images:
img = cv2.imread(fname)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 找到棋盘格角点
# 棋盘图像(8位灰度或彩色图像) 棋盘尺寸 存放角点的位置
ret, corners = cv2.findChessboardCorners(gray, (W, H), None)
# 如果找到足够点对,将其存储起来
if ret == True:
# 角点精确检测
# 输入图像 角点初始坐标 搜索窗口为2*winsize+1 死区 求角点的迭代终止条件
i += 1
# 增加准确度
cv2.cornerSubPix(gray, corners, (11, 11), (-1, -1), criteria)
objpoints.append(objp)
imgpoints.append(corners)
# 将角点在图像上显示
# cv2.drawChessboardCorners(img, (W, H), corners, ret)
# cv2.imshow('findCorners', img)
# 保存绘画出角点的图片
# cv2.imwrite('h' + str(i) + '.jpg', img)
# cv2.waitKey(10)
# 2标定、去畸变
# 2.1输入:世界坐标系里的位置 像素坐标 图像的像素尺寸大小 3*3矩阵,相机内参数矩阵 畸变矩阵
# 2.1输出:标定结果 相机的内参数矩阵 畸变系数 旋转矩阵 平移向量
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, gray.shape[::-1], None, None)
print(("ret:"), ret)
print(("mtx内参数矩阵:\n"), mtx, type(mtx)) # 内参数矩阵
print(("dist畸变值:\n"), dist, type(dist)) # 畸变系数 distortion cofficients = (k_1,k_2,p_1,p_2,k_3)
print(("rvecs旋转(向量)外参:\n"), rvecs) # 旋转向量(外参数)
print(("tvecs平移(向量)外参:\n"), tvecs) # 平移向量(外参数)
'''
可选:保存内参数矩阵和畸变系数
np.save('mtx.npy', mtx)
np.save('dist.npy', dist)
'''
# 2.2去畸变
img = cv2.imread('img.jpg')
h, w = img.shape[:2]
# 我们已经得到了相机内参和畸变系数,在将图像去畸变之前,
# 我们还可以使用cv.getOptimalNewCameraMatrix()优化内参数和畸变系数,
# 通过设定自由自由比例因子alpha。当alpha设为0的时候,将会返回一个剪裁过的将去畸变后不想要的像素去掉的内参数和畸变系数;
# 当alpha设为1的时候,将会返回一个包含额外黑色像素点的内参数和畸变系数,并返回一个ROI用于将其剪裁掉
newcameramtx, roi = cv2.getOptimalNewCameraMatrix(mtx, dist, (w, h), 0, (w, h)) # 自由比例参数
# undistort
dst = cv2.undistort(img, mtx, dist, None, newcameramtx)
# 根据前面ROI区域裁剪图片
# x, y, w, h = roi
dst = dst[y:y + h, x:x + w]
cv2.imwrite('calibresult_kjg.png', dst)
# 计算重投影误差
total_error = 0
for i in range(len(objpoints)):
imgpoints2, _ = cv2.projectPoints(objpoints[i], rvecs[i], tvecs[i], mtx, dist)
error = cv2.norm(imgpoints[i],imgpoints2, cv2.NORM_L2)/len(imgpoints2)
total_error += error
print("total error: ", total_error/len(objpoints))
经实测发现,可见光的畸变并不明显,可能是由于DJI在光学相机中本身内置了畸变矫正算法,即使广角镜头也不会有严重的畸变效果。
红外图像去畸变
在可见光图像中,将这套流程跑通后,准备直接迁移到红外图像,不过一打开镜头就傻眼了,因为红外镜头需要捕捉物体散发的红外波长的光线,比较依赖物体的材质和热量。打印的棋盘格在红外眼中别无二致,丝毫找不到角点信息。(还有我的裤子为啥莫名黑黑的,我绝对没沾水在上面。。)

如果继续使用棋盘格矫正,需要购买红外的标定板,对每一个点位进行单独加热,这种板子一查基本需要四位数,太贵了。
显示器标定法
于是尝试采用土办法,既然无法用棋盘格,那只需要找到一个特征容易捕捉的平面,手动选择一些标定点,理论上也能达到类似的效果,于是我打算利用显示器的四个边界点。
首先简单写了一个交互性标注窗口,打开图片,可以点击角点进行标注,按Q退出,标注点保存为Txt文件。
import cv2
# Config
point_color = (0, 0, 255)
point_size = 5
thickness = 10
point_list = []
def get_pixel(event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
# 输出像素值和坐标信息到控制台
print(x, y)
# 在图像上绘制坐标和像素值
font = cv2.FONT_HERSHEY_SIMPLEX
txt = str(x) + ',' + str(y)
point = (x, y)
cv2.circle(img, point, point_size, point_color, thickness)
cv2.putText(img, txt, (x, y), font, 0.5, (255, 0, 0), 2)
point_list.append(point)
if __name__ == '__main__':
# 读取图像
img_name = 'hw_img.jpg'
img = cv2.imread(img_name)
# 显示图像并设置鼠标事件回调函数
cv2.namedWindow('Image')
cv2.setMouseCallback('Image', get_pixel)
while True:
# 显示图像
cv2.imshow('Image', img)
# 按q退出
k = cv2.waitKey(1)
if k == ord('q'):
break
cv2.destroyAllWindows()
with open(img_name[:-4] + ".txt", mode='a') as f:
for i in point_list:
print(i)
f.write(str(i) + '\n')

如图所示,我从一段红外视频中,截取出不同位姿的十几帧图片,如图所示标记四个点,然而运行时直接报错:
cv2.error: OpenCV(4.8.0) D:\a\opencv-python\opencv-python\opencv\modules\calib3d\src\calibration.cpp:1173: error: (-2:Unspecified error) in function ‘void __cdecl cvFindExtrinsicCameraParams2(const struct CvMat *,const struct CvMat *,const struct CvMat *,const struct CvMat *,struct CvMat *,struct CvMat *,int)’
DLT algorithm needs at least 6 points for pose estimation from 3D-2D point correspondences. (expected: ‘count >= 6’), where
‘count’ is 4
must be greater than or equal to
‘6’ is 6
原来虽然理论上只需要标记四个点,但OpenCV采用的DLT算法,至少需要6个点才能产出结果。
于是标记9个点。

最后得到的结果仍不如人意,分析原因,主要是显示器中间那5个点为推测标注,并不是很精准导致。
停车场标记法
离标定物体越远,人工标记所带来的误差越小,在一番思索后,我找到了比较适合标定的场景:俯视角度的停车场。
在夜晚的红外视角中,停车场如图一个巨大的棋盘,并且还在同一平面,简直是天然的标定板。
于是我采了27张不同角度拍摄的车位图片,每张图片标记如图所示的16个点,这里标记时需要注意按预先设计的坐标轴顺序,与设定的图像坐标系点位对应。

同时估算停车场位的长宽约为4m x 2m,因此可以利用棋盘格类似的方式去做标定,代码如下:
import cv2
import numpy as np
import glob
W = 4
H = 4
obj_list = np.array([
(0, 0),
(0, 4000),
(0, 8000),
(0, 12000),
(2000, 0),
(2000, 4000),
(2000, 8000),
(2000, 12000),
(4000, 0),
(4000, 4000),
(4000, 8000),
(4000, 12000),
(6000, 0),
(6000, 4000),
(6000, 8000),
(6000, 12000)
])
# 世界坐标系中的位点,例如(0,0,0), (1,0,0), (2,0,0) ....,(8,5,0),去掉Z坐标,记为二维矩阵
objp = np.zeros((W * H, 3), np.float32)
objp[:, :2] = np.mgrid[0:W, 0:H].T.reshape(-1, 2)
objp[:, 0] = obj_list[:, 0]
objp[:, 1] = obj_list[:, 1]
# 储存棋盘格角点的世界坐标和图像坐标对
objpoints = [] # 在世界坐标系中的三维点
imgpoints = [] # 在图像平面的二维点
imgsPath = "video/hw_bd3"
images = glob.glob(imgsPath + '/*.jpg')
for fname in images:
img = cv2.imread(fname)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
b = []
# 读取txt标记点位
txt_frame = fname[:-4] + ".txt"
with open(txt_frame, 'r') as f:
contents = f.readlines()
for i in contents:
i = i.strip('\n')
j = eval(i)
b.append([[np.float32(j[0]), np.float32(j[1])]])
corners = np.array(b)
objpoints.append(objp)
imgpoints.append(corners)
# 2标定、去畸变
# 2.1输入:世界坐标系里的位置 像素坐标 图像的像素尺寸大小 3*3矩阵,相机内参数矩阵 畸变矩阵
# 2.1输出:标定结果 相机的内参数矩阵 畸变系数 旋转矩阵 平移向量
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, gray.shape[::-1], None, None)
print(("ret:"), ret)
print(("mtx内参数矩阵:\n"), mtx, type(mtx)) # 内参数矩阵
print(("dist畸变值:\n"), dist, type(dist)) # 畸变系数 distortion cofficients = (k_1,k_2,p_1,p_2,k_3)
print(("rvecs旋转(向量)外参:\n"), rvecs) # 旋转向量(外参数)
print(("tvecs平移(向量)外参:\n"), tvecs) # 平移向量(外参数)
np.save('mtx_hw3.npy', mtx)
np.save('dist_hw3.npy', dist)
# 2.2去畸变
img = cv2.imread('video/hw_bd3/DJI_20231103213150_0002_T_1.jpg')
h, w = img.shape[:2]
# 我们已经得到了相机内参和畸变系数,在将图像去畸变之前,
# 我们还可以使用cv.getOptimalNewCameraMatrix()优化内参数和畸变系数,
# 通过设定自由自由比例因子alpha。当alpha设为0的时候,将会返回一个剪裁过的将去畸变后不想要的像素去掉的内参数和畸变系数;
# 当alpha设为1的时候,将会返回一个包含额外黑色像素点的内参数和畸变系数,并返回一个ROI用于将其剪裁掉
newcameramtx, roi = cv2.getOptimalNewCameraMatrix(mtx, dist, (w, h), 0, (w, h)) # 自由比例参数
# undistort
dst = cv2.undistort(img, mtx, dist, None, newcameramtx)
cv2.imwrite('calibresult_hw3.png', dst)
# 计算重投影误差
# 反投影误差
total_error = 0
for i in range(len(objpoints)):
imgpoints2, _ = cv2.projectPoints(objpoints[i], rvecs[i], tvecs[i], mtx, dist)
error = cv2.norm(imgpoints[i],imgpoints2, cv2.NORM_L2)/len(imgpoints2)
total_error += error
print("total error: ", total_error/len(objpoints)) # total error: 0.45538816886228306
最终得到的重映射误差为 0.455,小于0.5。
查看矫正效果:

可以看到,矫正效果很不错,之前因畸变弯曲的线条被重新纠正成直线。
于是尝试将该参数迁移到其它场景,仍然可以work,叠在一起看,效果很明显。

总结和拓展
相机标定对我来说是全新的领域,从工程角度出发,没有对理论刨根问底,如需对理论进一步推导研究,可以参看参考资料[6][7]。
另外,相机标定的另一大用途是在自动驾驶领域,通过标定将车周围一圈图像转换成鸟瞰图视角,这部分可以参考资料[8]。
参考资料
[1] https://www.zywvvd.com/notes/study/camera-imaging/photo-distortion/photo-distortion
[2] https://zhuanlan.zhihu.com/p/94244568
[3] https://blog.csdn.net/weixin_44368569/article/details/130414934
[4] https://zhuanlan.zhihu.com/p/423473576
[5] https://blog.csdn.net/m0_47682721/article/details/124696148
[6] https://www.bilibili.com/video/BV1C54y1B7By
[7] https://www.bilibili.com/video/BV1ct4y1H76h
[8] https://zhuanlan.zhihu.com/p/449195936