目录
ScheduledThreadPoolExecutor简介
构造方法
特有方法
可周期性执行的任务-ScheduledFutureTask
DelayedWorkQueue
什么是DelayedWorkQueue?
为什么要使用DelayedWorkQueue呢?
DelayedWorkQueue的数据结构
ScheduledThreadPoolExecutor执行过程
总结
ScheduledThreadPoolExecutor简介
ScheduledThreadPoolExecutor继承自ThreadPoolExecutor(关于ThreadPoolExecutor可以看这篇文章),并实现了ScheduledExecutorService接口,因此它同时具备了线程池的基本功能和任务调度的功能。ScheduledThreadPoolExecutor可以用来延迟执行任务或者周期性执行任务,相比于传统的Timer类,其功能更加强大和灵活。
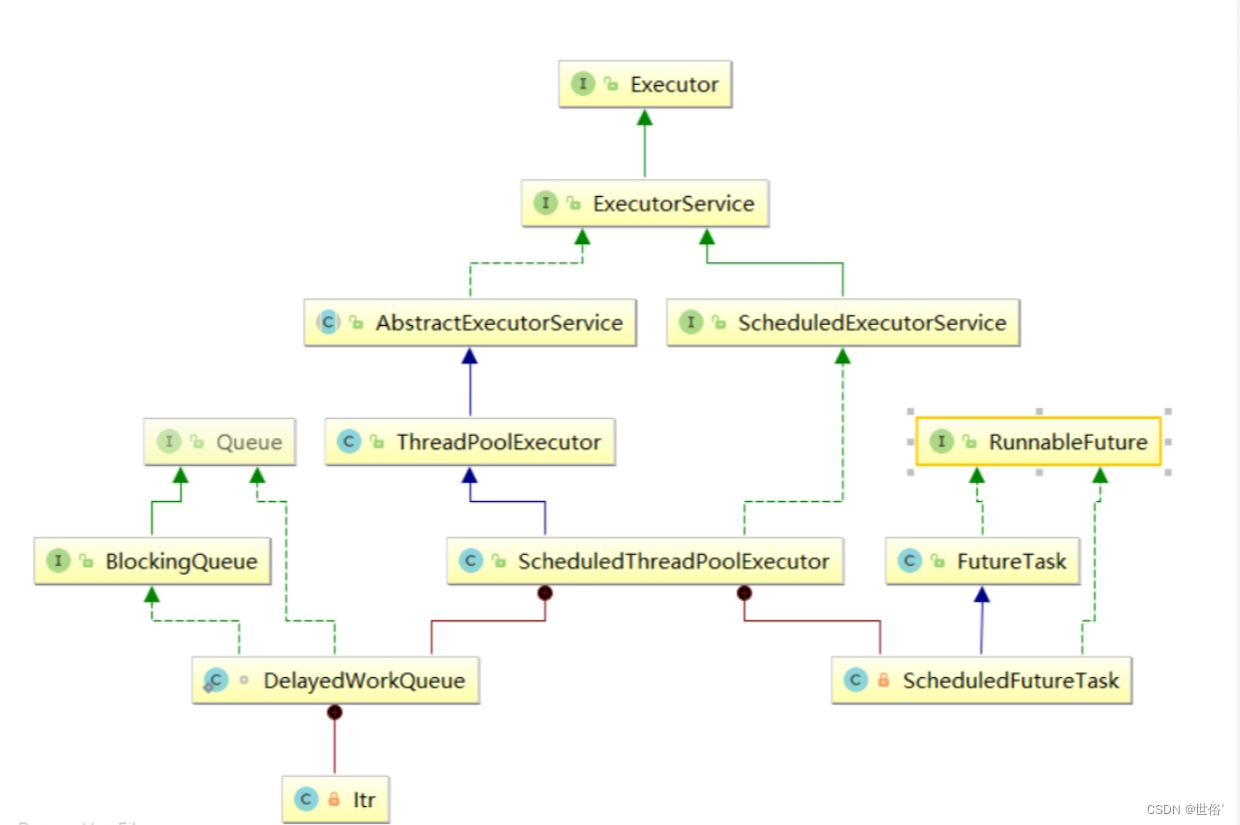
在UML图中,可以看到ScheduledThreadPoolExecutor关联了DelayedWorkQueue和ScheduledFutureTask这两个关键的内部类。DelayedWorkQueue实现了BlockingQueue接口,提供了阻塞队列的功能,用于存储延迟执行的任务。而ScheduledFutureTask继承自FutureTask类,表示异步任务的结果。
ScheduledThreadPoolExecutor的构造函数可以指定后台线程的个数,这使得开发者可以更灵活地控制任务的执行。而ScheduledExecutorService接口定义了延时执行任务和周期执行任务的方法,使得任务调度变得更加简单和便捷。
总之,ScheduledThreadPoolExecutor通过继承ThreadPoolExecutor和实现ScheduledExecutorService接口,结合内部的DelayedWorkQueue和ScheduledFutureTask类,为开发者提供了一个功能强大、灵活可控的定时任务执行框架。这使得在实际开发中,我们可以更加高效地处理定时任务相关的需求。
构造方法
对于ScheduledThreadPoolExecutor的构造方法,可以看出它继承自ThreadPoolExecutor,因此在构造方法中调用了ThreadPoolExecutor的不同重载形式。下面我将对其构造方法进行简要解释:
1、第一个构造方法
// 第一个构造方法
public ScheduledThreadPoolExecutor(int corePoolSize) {
// 调用ThreadPoolExecutor的构造方法,指定核心线程池大小为corePoolSize,
// 最大线程数为Integer.MAX_VALUE,空闲线程存活时间为0纳秒(即不保留空闲线程),
// 使用NANOSECONDS作为时间单位,以及默认的DelayedWorkQueue作为工作队列。
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}这个构造方法指定了核心线程池大小为corePoolSize,并使用了默认的拒绝策略(将任务添加到工作队列中)。最大线程数设为Integer.MAX_VALUE,保证了理论上这是一个大小无界的线程池。
2、第二个构造方法
// 第二个构造方法
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory) {
// 同样调用ThreadPoolExecutor的构造方法,指定核心线程池大小、最大线程数、空闲线程存活时间等参数,
// 但在这里允许通过ThreadFactory来自定义线程的创建方式。
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory);
}这个构造方法除了指定了核心线程池大小和最大线程数外,还允许通过ThreadFactory来自定义线程的创建方式。
3、第三个构造方法
// 第三个构造方法
public ScheduledThreadPoolExecutor(int corePoolSize,
RejectedExecutionHandler handler) {
// 允许设置拒绝策略,当线程池和工作队列都已满时,会调用指定的拒绝策略来处理新任务。
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), handler);
}这个构造方法允许设置拒绝策略,当线程池和工作队列都已满时,会调用指定的拒绝策略来处理新任务。
4、第四个构造方法
// 第四个构造方法
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
// 组合了前两个构造方法的功能,既允许设置线程工厂,又允许设置拒绝策略。
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}这个构造方法则组合了前两个构造方法的功能,既允许设置线程工厂,又允许设置拒绝策略。
总之,ScheduledThreadPoolExecutor的构造方法提供了多种选择,可以根据实际需求来灵活配置线程池的参数,从而满足不同的调度任务需求。
特有方法
ScheduledThreadPoolExecutor 实现了 ScheduledExecutorService 接口,并且提供了以下特有方法用于延时执行和周期性执行异步任务:
- schedule(Runnable command, long delay, TimeUnit unit):在给定的延时时间后执行任务,返回一个 ScheduledFuture 对象,通过它可以获取任务的执行情况。
- <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit):类似于上一个方法,但是接受一个 Callable 对象,可以返回任务的计算结果。
- scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit):按固定的速率执行重复的任务,首次执行需要延时 initialDelay,之后每隔 period 时间执行一次任务。如果任务的执行时间超过了 period,则下一个任务会立即开始执行。
- scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit):与 scheduleAtFixedRate 类似,不同之处在于它是在前一个任务结束后,等待固定的延迟时间后再执行下一个任务。
这些方法使得 ScheduledThreadPoolExecutor 能够灵活地执行延时任务和周期性任务,并允许开发人员根据具体需求来调度异步任务的执行。
可周期性执行的任务-ScheduledFutureTask
ScheduledFutureTask 是 Java 中用于支持周期性执行任务的重要类之一。在 ScheduledThreadPoolExecutor 中,当调用 schedule、scheduleAtFixedRate 和 scheduleWithFixedDelay 方法时,实际上是将提交的任务转换成 ScheduledFutureTask 类的实例。这个转换过程发生在 decorateTask 方法中,其作用是对任务进行装饰和封装,以便进行正确的调度和执行。
在 ScheduledFutureTask 中,重写了 run 方法以支持周期性执行的逻辑。在这个重写的 run 方法中,首先判断当前任务是否是周期性任务。如果不是周期性任务,则直接调用 run 方法来执行任务;如果是周期性任务,则会重新设置下一次执行任务的时间,并将下一次任务放入到延迟队列中,以便在指定的时间再次执行。
因此,ScheduledFutureTask 的主要功能是根据任务的周期性特性,对任务进行进一步封装和调度。对于非周期性任务,它直接执行 run 方法;对于周期性任务,则在每次执行完后重新设置下一次执行的时间,并将下一次任务继续放入到延迟队列中。
总的来说,ScheduledFutureTask 在实现周期性任务调度时起到了关键的作用,能够有效地管理和执行周期性任务。这样的设计使得 ScheduledThreadPoolExecutor 能够将任务和线程进行解耦,实现了任务的延时执行和周期性执行的功能。
一个小例子
import java.util.concurrent.*;
public class main {
public static void main(String[] args) {
ScheduledThreadPoolExecutor scheduler = new ScheduledThreadPoolExecutor(1);
// 创建一个周期性执行的任务
Runnable periodicTask = new Runnable() {
private long interval = 1000; // 初始执行间隔为1秒
@Override
public void run() {
System.out.println("在执行定期任务 " + System.currentTimeMillis() + " 带间隔 " + interval);
if (interval != 3000) {
interval += 1000; // 每次执行后增加1秒的执行间隔,直到达到3秒
rescheduleTask(this, interval, TimeUnit.MILLISECONDS); // 重新调度任务
}
}
};
// 使用 schedule 方法提交任务,并获得 ScheduledFuture 实例
ScheduledFuture<?> scheduledFuture = scheduler.schedule(periodicTask, 1, TimeUnit.SECONDS);
// 关闭 scheduler
scheduler.shutdown();
}
// 动态重新调度任务的方法
private static void rescheduleTask(Runnable task, long delay, TimeUnit unit) {
ScheduledThreadPoolExecutor executor = (ScheduledThreadPoolExecutor) Executors.newScheduledThreadPool(1);
executor.schedule(task, delay, unit);
executor.shutdown();
}
}
在这个示例中,我们首先创建了一个 ScheduledThreadPoolExecutor 实例 scheduler,然后定义了一个周期性执行的任务 periodicTask。在任务执行时,我们动态地改变了执行间隔,通过调用 rescheduleTask 方法重新调度任务。rescheduleTask 方法中,我们新建了一个临时的 ScheduledThreadPoolExecutor 实例,用于重新调度任务。
通过这个示例,我们展示了如何在运行时动态地改变周期性任务的执行间隔,并且演示了任务是如何被转换成 ScheduledFutureTask 实例,并且如何进行动态调度的。
DelayedWorkQueue
什么是DelayedWorkQueue?
DelayedWorkQueue 在 ScheduledThreadPoolExecutor 中扮演着重要的角色,它是用来存储需要延迟执行或周期执行的任务的数据结构。DelayedWorkQueue 的实现基于堆的数据结构,类似于 DelayQueue 和 PriorityQueue。
在执行定时任务时,每个任务的执行时间各不相同,因此 DelayedWorkQueue 的工作是按照执行时间的升序排列这些任务,确保执行时间距离当前时间越近的任务排在队列的前面。这样,线程池中的工作线程在获取任务时会优先选择执行时间最近的任务,从而实现了延迟执行和周期执行任务的功能。
DelayedWorkQueue 内部实际上使用了一个数组来存储任务,并通过堆的数据结构对任务按照执行时间进行排序。这种设计使得 ScheduledThreadPoolExecutor 能够高效地管理延迟任务,并按照预定的顺序和时间执行这些任务,从而满足异步任务和周期性任务的执行需求。
综上所述,DelayedWorkQueue 在 ScheduledThreadPoolExecutor 中扮演着关键的角色,通过其基于堆的数据结构和按照执行时间排序的机制,能够确保任务按照预期得到执行,为延迟执行和周期执行任务提供了可靠的支持。
为什么要使用DelayedWorkQueue呢?
使用 DelayedWorkQueue 的主要原因是确保定时任务能够按照预定的执行时间顺利进行。DelayedWorkQueue 本质上是一个优先级队列,它能够保证每次出队的任务都是当前队列中执行时间最靠前的,这正是它在 ScheduledThreadPoolExecutor 中的作用所在。
由于 DelayedWorkQueue 基于堆结构实现,在执行插入和删除操作时的时间复杂度为 O(logN),这使得它能够高效地管理延迟任务,并且保证任务按时执行。通过堆结构的特性,DelayedWorkQueue 能够快速找到最近要执行的任务,并将其置于队列的最前面,从而保证任务能够按时得到执行。
综上所述,DelayedWorkQueue 作为基于堆结构的优先级队列,能够有效地管理延迟任务,并确保任务按照预定的执行时间顺利进行。这种设计使得 ScheduledThreadPoolExecutor 能够高效地调度和执行定时任务,提高系统的可维护性和性能。
DelayedWorkQueue的数据结构
DelayedWorkQueue 的数据结构是基于数组构成的,其中数组元素类型为实现了 RunnableScheduledFuture 接口的类(实际上是 ScheduledFutureTask)。在具体实现中,DelayedWorkQueue 使用一个大小为 16 的数组来存储任务,初始大小定义如下:
// 初始容量为16
private static final int INITIAL_CAPACITY = 16;
// 使用数组作为存储结构,初始大小为INITIAL_CAPACITY
private RunnableScheduledFuture<?>[] queue = new RunnableScheduledFuture<?>[INITIAL_CAPACITY];
// 用于在多线程环境下对队列进行加锁操作的ReentrantLock对象
private final ReentrantLock lock = new ReentrantLock();
// 追踪队列中实际存储的元素个数
private int size = 0;
这意味着 DelayedWorkQueue 内部使用一个固定大小的数组来管理任务。当任务需要执行时,会根据任务的延迟时间将其放入数组中适当的位置,以保持任务按照执行时间顺序进行排序。这样,待执行时间越近的任务会被放置在队列的前面,以便最先执行。
总的来说,DelayedWorkQueue 的数据结构是基于数组构成的,通过数组来实现对延迟任务的管理和排序,以确保任务能够按照预定的执行时间顺利进行。
ScheduledThreadPoolExecutor执行过程
ScheduledThreadPoolExecutor 的执行过程如下:
1、任务提交:调用 schedule() 方法提交一个任务,该方法将任务转换成 ScheduledFutureTask 对象。
2、延时执行:在 schedule() 方法中调用 delayedExecute() 方法,将任务放入阻塞队列中进行调度。如果线程池已经关闭,则拒绝任务;否则将任务加入到阻塞队列中。具体源码为:
public ScheduledFuture<?> schedule(Runnable command,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
//将提交的任务转换成ScheduledFutureTask
RunnableScheduledFuture<?> t = decorateTask(command,
new ScheduledFutureTask<Void>(command, null,
triggerTime(delay, unit)));
//延时执行任务ScheduledFutureTask
delayedExecute(t);
return t;
}
3、确保线程启动:在 delayedExecute() 方法中会调用 ensurePrestart() 方法,该方法的主要逻辑是确保至少有一个线程处于启动状态,即使核心线程数为 0。在 ensurePrestart() 方法中会调用 addWorker() 方法来添加新的 Worker 线程。
private void delayedExecute(RunnableScheduledFuture<?> task) {
if (isShutdown())
//如果当前线程池已经关闭,则拒绝任务
reject(task);
else {
//将任务放入阻塞队列中
super.getQueue().add(task);
if (isShutdown() &&
!canRunInCurrentRunState(task.isPeriodic()) &&
remove(task))
task.cancel(false);
else
//保证至少有一个线程启动,即使corePoolSize=0
ensurePrestart();
}
}
4、Worker 线程执行任务:当 Worker 线程启动时,它会不断地从阻塞队列中获取任务并执行,直到获取的任务为 null,此时线程结束终止。
5、当需要执行周期性任务时,Worker 线程在执行完当前任务后会重新计算下一次任务的执行时间,并将任务重新放入阻塞队列,以便下一次执行。
void ensurePrestart() {
int wc = workerCountOf(ctl.get());
if (wc < corePoolSize)
addWorker(null, true);
else if (wc == 0)
addWorker(null, false);
}
通过上述步骤,ScheduledThreadPoolExecutor 能够按照预定的时间执行任务,并且能够确保至少有一个线程处于启动状态,以便执行任务。整个流程涉及任务的转换、延时执行、线程池状态的检查、线程的启动和任务的执行等关键步骤。注意:addWorker方法是ThreadPoolExecutor类中的方法,对ThreadPoolExecutor的源码分析可以看这篇文章,很详细。
总结
ScheduledThreadPoolExecutor继承了ThreadPoolExecutor类,因此在整体功能上保持一致。线程池的主要职责是创建线程(Worker类),而线程则不断地从阻塞队列中获取新的异步任务,直到队列中没有任务为止。相较于ThreadPoolExecutor,ScheduledThreadPoolExecutor具有延时执行任务和定期执行任务的能力。它重新设计了任务类ScheduleFutureTask,并重写了run方法以实现延时执行和周期性执行任务。此外,它使用了DelayedWorkQueue作为阻塞队列,这是一个可根据优先级排序的队列,采用了堆的底层数据结构,使得与当前时间相比,待执行时间越接近的任务被放置在队列的前面,以便线程优先获取并执行这些任务。
在设计线程池时,无论是ThreadPoolExecutor还是ScheduledThreadPoolExecutor,都将任务、执行者和任务结果进行了解耦。执行者的任务执行机制完全交由Worker类负责,任务提交后首先进入阻塞队列,然后通过addWork方法创建Worker类,并通过runWorker方法启动线程,不断地从阻塞队列中获取异步任务执行,直至队列为空为止。任务指的是实现了Runnable接口和Callable接口的实现类,在ThreadPoolExecutor中会将任务转换成FutureTask类,而在ScheduledThreadPoolExecutor中,为了实现延时执行和周期性执行任务的特性,任务会被转换成ScheduledFutureTask类,该类继承了FutureTask,并重写了run方法。提交任务后,可以通过Future接口的类获取任务结果,在ThreadPoolExecutor中是FutureTask类,而在ScheduledThreadPoolExecutor中是ScheduledFutureTask类。