1、Flink独立集群模式
1、首先Flink的独立集群模式是不依赖于Hadoop集群。
2、上传压缩包,配置环境:
1、解压:
tar -zxvf flink-1.15.2-bin-scala_2.12.tgz
2、配置环境变量:
vim /etc/profile
export FLINK_HOME=/usr/local/soft/flink-1.15.2
export PATH=$FLINK_HOME/bin:$PATH
3、配置文件生效
source /etc/profile
3、修改配置文件
# 1、进入flink配置文件所在的位置
cd /usr/local/soft/flink-1.15.2/conf
# 1、修改flink-conf.yaml
vim flink-conf.yaml
# 修改配置
jobmanager.rpc.address: master #jobmanager的地址,选择那台机器作主节点
jobmanager.bind-host: 0.0.0.0 #0.0.0.0 表示的任何的节点都可以访问主节点
taskmanager.bind-host: 0.0.0.0
taskmanager.host: localhost #表示的是从节点的
taskmanager.numberOfTaskSlots: 1 #指定槽位的个数,用来执行Task任务
rest.address: master
rest.bind-address: 0.0.0.0
# 2、修改masters
vim masters
# 修改配置
master:8081
# 3、修改workers
vim workers
# 修改配置
node1
node24、分发到所有的服务器中:
scp -r flink-1.15.2/ node1:`pwd`
scp -r flink-1.15.2/ node2:`pwd`
# 分发之后需要单独修改node1和node2中taskmanager.host
taskmanager.host: node1
taskmanager.host: node25、启动集群:
# 在master中执行启动命令
start-cluster.sh
# web ui
http://master:8081
# 关闭集群
stop-cluster.sh
6、将任务提交到集群上的命令:
1、将任务提交到集群上的第一种方式:
1、首先将代码上传到服务器中:
flink-1.0.jar
2、提交flink任务
flink run -c 主类的名称 jar包的名称
2、将任务提交到flink集群上的第二种方式:在flink的web界面手动提交任务
a、点击Submit New Job
b、点击Add New,上传jar包
c、指定任务的主类名称、指定任务的并行度,提交任务

2、Flink ON Yarn模式
1、就是将flink任务提交到yarn上运行,不过在使用on yarn模式的时候需要注意的是需要将Flink中的独立模式关闭,并启动Hadoop。
Flink的独立集群模式和ON Yarn的模式只能使用一种,所以需要将独立集群模式关闭,并开启Hadoop
stop-cluster.sh
start-all.sh
2、配饰hadoop的hadoop classpath
# 修改/etc/profile
vim /etc/profile
# 在最后增加配置文件
export HADOOP_CLASSPATH=`hadoop classpath` #指的是获取Hadoop依赖包的路径
并且这个配置文件必须放在配置文件的最后一行
source /etc/profile3、Flink ON Yarn的三种模式:
1、per job mode:
1、类似于Spark on yarn的client的模式
2、如果出现错误,在本地是可以看见部分的错误
例如:在使用socket模拟实时的时候,突然关闭socket服务,此时错误的部分原因就会在客户端打印出来。
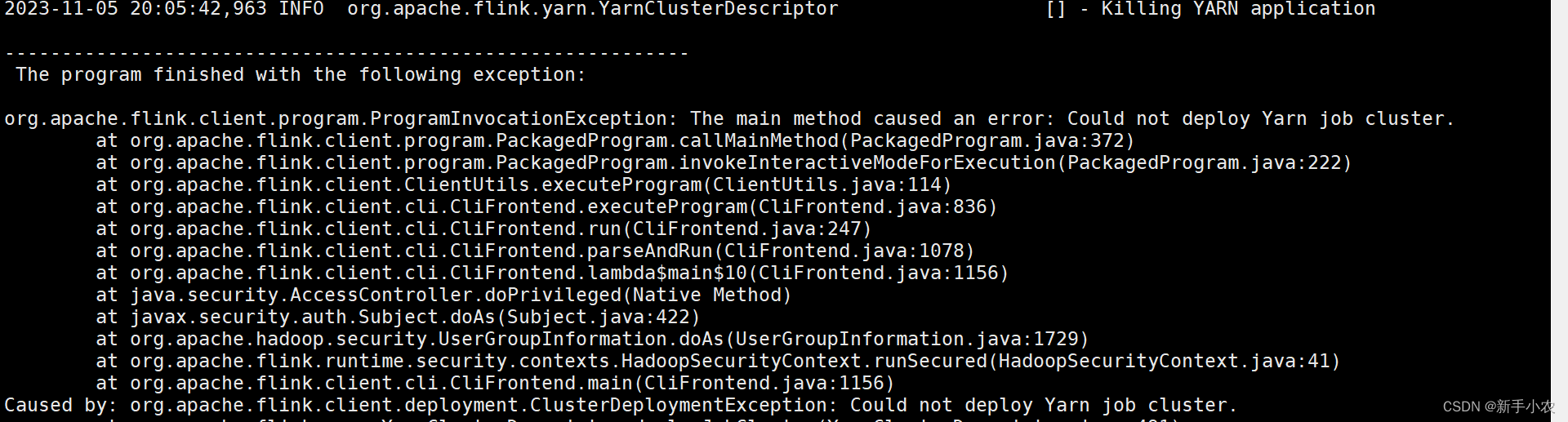
3、在本地执行main函数,构建的DataFlow图,再将DataFlow提交到JobManager上去运行
4、每一个Flink任务都是单独申请资源,启动一个JobManager和多个TaskManager,人物之间是不影响的。
提交任务:
flink run -t yarn-per-job -c 主类名 jar包的名称
对于ONE Yarn中的流处理,因为是流处理,所以进程是不会自动的停止,关闭Yarn上面进程的指令:
yarn application -kill 进程号
获取yarn中进程的logs日志的指令:
yarn logs -applicationID 进程号
2、application mode:
1、相当于Spark on yarn 中的cluster模式
2、在本地是看不见错误的
因为此时的错误在Yarn上,可以通过查看yarn上的日志来找出错误
获取yarn中进程的logs日志的指令:
yarn logs -applicationID 进程号
也可以将日志写入到一个文件中,然后拉去到桌面上去查看:
yarn logs -applicationID 进程号 >> 指定的文件
3、main函数是在JobManager中执行的,本地只需要负责提交任务
4、每一个Flink任务都是单独申请资源,启动一个JobManager和多个TaskManager,人物之间是不影响的。
5、可以用于生产环境
提交代码:
flink run-application -t yarn-application -c 主类名 jar包的名称3、session mode:
1、会现在yarn中申请一个资源启动JobManager,在来提交任务
2、提交任务会共用一个JobManager,动态的申请TaskManager,任务取消,TaskManager就会被释放。前面的两种模式都是一次只会服务一个任务,但是这个可以同时启动多个任务,此时就会产生一个问题,那就是如果其中某一个任务失败的化,那么后面的任务可能都会失败。
3、一般用于测试环境
1、启动session集群
yarn-session.sh -d
2、提交任务
flink run -t yarn-session -Dyarn.application.id= 进程号 -c 主类名 jar包名称也可以使用Web来提交任务,功能与独立集群的模式基本一致,但是不同的是他是建立在Yarn的模式上。
4、模式的抉择:
1、如果业务的要是是实时的业务,那么就选择独立集群模式,因为yarn是基于Hadoop,适合做离线的
2、如果一直使用的Hadoop,但是想要结合Flink,可以选择 on yarn的模式。