早期的对话机器人通常采用基于规则的开放问答系统。这种系统依赖于专家系统的语义模板,即根据预先定义的模板来匹配和回答问题。这种方法的优点是准确性相对较高,因为它是基于人类专家的知识和经验来设计的。然而,这种系统的可扩展性和灵活性较差,因为它们需要手动编写和维护大量的规则和模板。
1.两种对话系统(知识图谱/端到端)
1.1基于知识图谱的问答系统
近年来,问答系统的构造经历了一次重要的转变,从传统的基于模板、规则的方法转向了基于知识图谱的方法。知识图谱是一种以图形化的方式表示知识库的系统,它利用实体、属性和关系等元素来表达和连接不同领域的知识。基于知识图谱的问答系统通过利用检索、逻辑推理等方法来查找用户问题的答案。这种方法的优点是可以利用大规模的知识库,并且可以通过不断的学习和优化来提高答案的准确性和稳定性。

虽然基于知识图谱的问答系统相对于规则具有显著的优势,但它们也存在一些不可忽视的局限性。首先,系统的性能和准确性很大程度上受到知识图谱规模的影响。当用户提出的问题超出知识图谱的范围,或者知识图谱中缺乏与问题相关的足够信息时,系统的效果可能会大打折扣,无法提供准确的答案。
其次,基于知识图谱的问答系统通常需要进行复杂的逻辑推理和分析,这需要大量的计算资源和时间。这种复杂性不仅增加了系统的运行成本,而且也可能导致系统运行速度变慢,无法满足实时问答的需求。因此,这种系统通常需要配备高性能的计算机和大量的存储资源,以确保系统能够快速有效地处理和分析大量的数据。
1.2端到端的问答系统
随着深度学习的快速发展,端到端的问答系统越来越受到青睐。端到端的问答系统指的是从输入问题到输出答案的整个过程都由机器自动完成,不需要人工干预。这种问答系统通过对问题的理解、信息检索、答案抽取以及结合知识图谱等方式,能够更加自然地回答用户的问题。端到端的问答系统通常采用深度学习模型来对问题进行建模和分析,这些模型可以自动学习和优化,从而提高系统的准确性和效率。

端到端的问答系统具有许多优点。首先,它们可以更加自然地回答用户的问题,不需要人工干预或模板匹配的过程。其次,端到端的问答系统可以利用大规模的语料库和数据集来进行训练和优化,从而提高系统的准确性和效率。最后,端到端的问答系统可以更好地处理自然语言的不确定性和复杂性,从而更好地满足用户的需求。
尽管端到端的问答系统具有许多优点,但它们也存在一些挑战和难点。
- 训练和优化深度学习模型需要大量的数据和计算资源,这需要强大的硬件和软件支持。
- 深度学习模型的可解释性较差,这使得人们难以理解模型的决策过程和答案的来源。
- 端到端的问答系统需要处理自然语言的复杂性和不确定性,这需要更加精细的训练和优化方法。
所以需要根据具体的应用场景和需求进行选择和优化。未来的发展方向是将不同类型的问答系统和深度学习模型进行集成和融合,以提高系统的准确性和效率。同时还需要解决深度学习模型的解释性和可扩展性等问题,以更好地满足实际应用的需求。
2.开放域对话系统
对于一个对话系统来说,最常使用的一个架构是由用户输入对话。
包含对话理解(Nature Language Understanding)、话题追踪(State Tracker)、知识图谱(Data Base)、对话策略(Dialog Policy)、对话生成(Nature Language Generative)5个部分。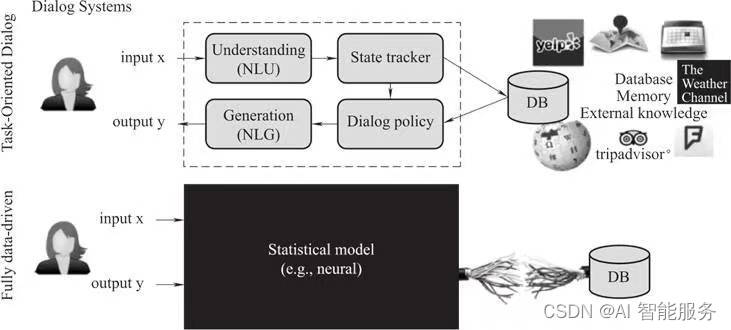
用户可以通过语音或文字输入问题,对话理解负责对问题进行解析,包括判断用户的意图和提取关键词。话题追踪则负责判断对话的当前位置,并将信息传递给知识图谱和对话策略。知识图谱通过对话解析提供所需的知识,并反馈答案给对话策略。对话策略根据用户意图、知识解析的答案以及对话策略选择回复的内容。然后,系统按照语法生成对话,并将问题的回复组合成文字答复反馈给用户,满足用户的问答需求。这套简单的架构基本上就满足了用户问答的需求。
如果把人机对话看作是一个决策最优化的选择,那么整个对话过程符合一个马尔可夫决策过程(Markov Decision Process,MDP)。
马尔可夫决策过程(MDP)是一种数学理论,它描述了在决策过程中,每个步骤的状态会如何改变,以及决策者会如何根据这些状态进行决策。在人机对话这个场景中,可以将每个对话回合看作是一个状态转换的过程,而决策者就是对话系统。
在对话的初始状态,用户会输入一个问题或者一段文字,这就是系统的输入。系统会根据这个输入以及当前的对话状态来选择一个动作,比如回复一段文字或者调用某个服务。这个动作会改变对话的状态,并可能会得到一个奖励,比如用户的积极反馈或者完成了一个任务。
这个过程会不断重复,直到对话结束。在每个阶段,系统都会根据当前的对话状态以及历史信息来选择一个最佳的动作,以期望达到最大的奖励。这就需要系统能够学习如何根据对话的状态和历史来选择最佳的动作,也就是学习一个最优的策略π。
人机对话的情形有很多种,比如问答、闲聊、客服等。每种情形都有不同的状态和动作空间,也就有不同的MDP。因此,对于不同的人机对话任务,需要设计不同的模型和算法来处理不同的MDP,并学习最优的策略π。
此外,由于对话的复杂性和不确定性,学习最优策略的过程可能会很困难。这就需要使用一些强化学习的方法,比如深度强化学习(DRL),来让系统自我学习和优化。同时,也需要使用一些技术来处理自然语言和理解用户的意图,比如自然语言处理(NLP)和意图识别等。
人工对话机器人根据对话的场景不同,一般可以分为3种不同的对话系统。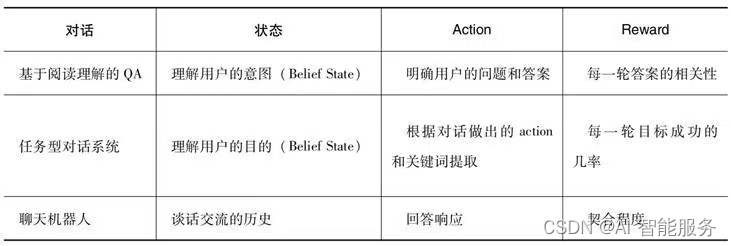
- 基于阅读理解的QA:基于阅读理解的QA可以从人们准备好的知识图谱或爬取的网页文档中得到丰富的知识,并给出问题的答案。
- 任务型对话系统:根据不同的垂直领域场景,帮助用户完成订购火车票、预订旅店、打车、订购外卖等任务。
- 聊天机器人:可以在生活中以朋友或者伙伴的角色,与人进行会话和交谈。
3.开放领域问答机器人的开发流程和方案
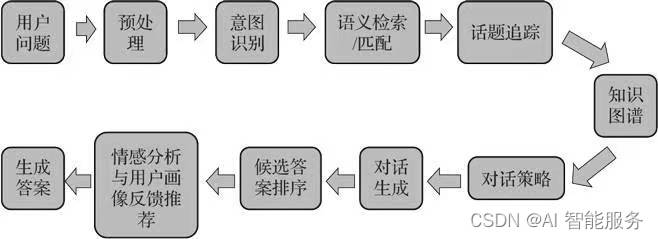
人机对话系统框架结构的细致拆解
人机对话框架模块具体说明:
用户问题模块:用户的问题一般连接着一些相关的上下文语境。在输入用户问题的时候,应该考虑到上下文,特别是上下文语境是用户对话过程的历史。

预处理模块:预处理模块主要是帮助机器在进行阅读理解之前,把改写后的标准化文本提供给后面的NLU。需要的技术一般会包括中文分词、词性标注、命名实体识别、拼写检查纠错、乱码处理、标点及颜字符处理、指代消解、长句改写、问句改写。
意图识别:在预处理后,需要判断所说的话是否是我们能够确定的单一意图,这时我们需要用文本分类的方法进行识别和确定。

语义检索和匹配:利用Elastic Search检索的方式和深度语义匹配模型并行,查找我们需要的问题答案候选。
1)Elastic Search是一个基于Lucene的高可用分布式开源搜索引擎。在效率上要比其他的搜索引擎更高,例如Solr。ES会根据知识库建立数据索引,同时也会为分类和重点内容做索引。ES的分词选项中可以配置一些专有名词或同义词,默认采用TFIDF来查询关键词。
2)深度语义匹配:我们利用QA相似度的方法来判断问题和答案的相似性。在Question Answering的问题中,问题Question用文本X来表示,答案Answer用文本Y来表示。我们利用孪生网络Siamese CBOW计算两个不同文本的语义相似度。对词向量进行预训练,然后用求和取平均的方式来表示句向量,并对标准问和相似问进行训练,添加负采样,损失函数为Contrastive Loss,让正样本之间的句向量表征尽量相似。预先算出语料的所有句向量表征,再将用户问题通过模型转化成句向量,搜索语料里最相似的若干个句向量作为候选答案列表示。
关于孪生网络,两边的模型除了CBOW以外,也可以支持LSTM、RNN、CNN。图11-4是2017年Kaggle问答比赛的冠军方案,该方案其实是在孪生网络的模型框架下用了曼哈顿LSTM模型,从而达到了一个最优效果。
话题追踪:负责判断在整个对话流程中,现阶段对话处于哪个位置,同时把信息传送给知识图谱和对话策略判断。

知识图谱:知识图谱的内容在上面章节里面已经有了比较细致的概括,这里不再赘述。
对话策略:负责根据解析的用户意图及知识解析的答案根据对话策略选择回复什么样的信息给用户。然后按照语法生成对话并把问题的回复组合成文字答复反馈给用户,让用户知晓所问问题的答案是什么。

候选答案排序:通过索引可以得到若干个答案,将这若干个答案合并去除重复的答案之后,就进入排序模块。
自然语言生成(NLG):是人工智能(AI)的一个细分,旨在减少机器和人类之间的沟通差距。该技术通常接收非语言格式的输入,并将其转换为人类可理解的格式。
4.开发案例
(以下来自斯坦福大学SQuAD标注阅读理解问答测试)
1.BERT做文本分类(即用户意图识别)
2.利用BERT源程序做基于英语维基百科语料的阅读理解问答QA问题
SQuAD,全称Stanford Question Answering Dataset,是由Rajpurkar等人于2016年底提出的全新阅读理解数据集。这个数据集拥有超过10万个(问题、原文、答案)三元组,这些三元组是从536篇维基百科文章中提取出来的。特别的是,问题的构建是通过众包的方式,让标注人员提出最多5个基于文章内容的问题并提供正确答案,且答案在原文中都有所体现。
与之前的完形填空类阅读理解数据集(如CNN/DM、CBT等)相比,SQuAD的最大特点是答案不再是一个单独的实体或单词,而可能是一段短语,这使得其答案更难以预测。SQuAD包含了公开的训练集和开发集,以及一个隐藏的测试集。测试集的评测方式与ImageNet类似,采用封闭评测方式。研究人员需要将算法提交到一个开放平台,然后由SQuAD的官方人员进行测试并公布结果。
自SQuAD数据集公布以来,很多具有代表性的模型开始涌现。这些模型极大地推动了机器阅读理解领域的发展。以下是对SQuAD榜单上具有代表性的模型进行的介绍:
由于SQuAD的答案需要在原文中寻找,所以模型的主要任务是判断原文中的哪些词是答案。因此,这是一种抽取式的问答任务,而不是生成式的任务。几乎所有用于SQuAD的模型都可以概括为同一种框架:包括嵌入层(Embed layer)、编码层(Encode layer)、交互层(Interaction layer)和答案层(Answer layer)。
嵌入层负责将原文和问题中的tokens映射为向量表示;编码层主要使用RNN对原文和问题进行编码,这样每个token的向量就包含了上下文的语义信息;交互层是大多数研究工作的重点,该层主要负责捕捉问题和原文之间的交互关系,并输出编码问题语义信息的原文表示,即Query-Aware的原文表示;最后,答案层基于Query-Aware的原文表示来预测答案范围。
使用bert进行fine-tuning
Sentence(and sentence-pair)classification tasks。在运行训练之前,将训练样本和BERT-Base checkpoint解压到不同目录下(如$GLUE_DIR和$BERT_BASE_DIR),运行命令如下,并使用run_classifier.py进行训练。
python run_classifier.py\\
--task_name=MRPC\\
--do_train=true\\
--do_eval=true\\
--data_dir=$GLUE_DIR/MRPC\\
--vocab_file=$BERT_BASE_DIR/vocab.txt\\
--bert_config_file=$BERT_BASE_DIR/bert_config.json\\
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt\\
--max_seq_length=128\\
--train_batch_size=32\\
--learning_rate=2e-5\\
--num_train_epochs=3.0\\
--output_dir=/tmp/mrpc_output/*****Eval results*****
eval_accuracy=0.845588
eval_loss=0.505248
global_step=343
loss=0.505248使用run_classifier.py进行预测,训练完模型后,设置--do_predict=true。在input文件夹中需要有一个名为test.tsv的文件。在mrpc_output文件夹中生成名为test_results.tsv的文件。行代表每个样本的输出,列代表每一类的概率。
python run_classifier.py\\
--task_name=MRPC\\
--do_predict=true\\
--data_dir=$GLUE_DIR/MRPC\\
--vocab_file=$BERT_BASE_DIR/vocab.txt\\
--bert_config_file=$BERT_BASE_DIR/bert_config.json\\
--init_checkpoint=$TRAINED_CLASSIFIER\\
--max_seq_length=128\\
--output_dir=/tmp/mrpc_output/
4)SQuAD 2.0
首先需要下载数据集到$SQUAD_DIR中,数据集包含以下3个文件:train-v2.0.json、dev-v2.0.json和evaluate-v2.0.py。
python run_squad.py\\
--vocab_file=$BERT_DIR/vocab.txt\\
--bert_config_file=$BERT_DIR/bert_config.json\\
--init_checkpoint=$BERT_DIR/bert_model.ckpt\\
--do_train=True\\
--train_file=$SQUAD_DIR/train-v2.0.json\\
--do_predict=True\\
--predict_file=$SQUAD_DIR/dev-v2.0.json\\
--train_batch_size=24\\
--learning_rate=3e-5\\
--num_train_epochs=2.0\\
--max_seq_length=384\\
--doc_stride=128\\
--output_dir=/tmp/SQuAD_output/\\
--use_tpu=False\\
--version_2_with_negative=True
接着,运行以下脚本调整阈值并以此来预测空答案与非空答案。
python$SQUAD_DIR/evaluate-v2.0.py$SQUAD_DIR/dev-v2.0.json
/tmp/SQuAD_output/predictions.json--na-prob-file
/tmp/SQuAD_output/null_odds.json
运行后输出文件为“best_f1_thresh”THRESH(值一般在-1.0~5.0)。接着重新运行模型以使用派生阈值来生成预测文件,或者可以从nbest_predictions.json文件中提取相应的答案。
python run_squad.py\\
--vocab_file=$BERT_DIR/vocab.txt\\
--bert_config_file=$BERT_DIR/bert_config.json\\
--init_checkpoint=$BERT_DIR/bert_model.ckpt\\
--do_train=False\\
--train_file=$SQUAD_DIR/train-v2.0.json\\
--do_predict=True\\
--predict_file=$SQUAD_DIR/dev-v2.0.json\\
--train_batch_size=24\\
--learning_rate=3e-5\\
--num_train_epochs=2.0\\
--max_seq_length=384\\
--doc_stride=128\\
--output_dir=/tmp/SQuAD_output/\\
--use_tpu=False\\
--version_2_with_negative=True
--null_score_diff_threshold=$THRESH注意事项:
1)如何生成预训练数据的格式?
首先,我们需要输入文本文件,其中每行代表一个句子,而不同的文章之间则通过空行进行分隔。我们的输出文件应为一组以TFRecord文件格式进行序列化的tf.train.Examples。为了实现这一转换,我们可以利用现有的工具如Spacy、nltk等进行句子划分。具体来说,create_pretraining_data.py脚本可以将各个句子拼接起来,使其达到最大的序列长度,从而尽量减少因填充(Padding)导致的计算资源浪费。不过,为了使模型在处理非句子输入时表现得更为稳健,我们可能需要在输入数据中人为地引入少量的噪声(例如,随机截断2%的输入段)。
create_pretraining_data.py将输入文件中所有的Examples存储在内存中,因此对于大型数据文件,应该对输入文件进行分割并多次调用该脚本。
max_predictions_per_seq是masked LM预测每个序列的最大长度,并将其设置为
max_seq_length*masked_lm_prob。
python create_pretraining_data.py\\
--input_file=./sample_text.txt\\
--output_file=/tmp/tf_examples.tfrecord\\
--vocab_file=$BERT_BASE_DIR/vocab.txt\\
--do_lower_case=True\\
--max_seq_length=128\\
--max_predictions_per_seq=20\\
--masked_lm_prob=0.15\\
--random_seed=12345\\
--dupe_factor=52)预训练过程是如何进行的?
如果选择从零开始进行预训练,则无需使用init_checkpoint。在模型配置(包括Vocab_Size)中指定bert_config_file。此代码的预训练过程虽然只经过了约20步,但实际上可以将num_train_steps设置为10000步甚至更多。同时,请确保在run_pretraining.py和create_pretraining_data.py中的max_seq_length和max_predictions_per_seq设置相同。
往期文章:
基础课22——云服务(SaaS、Pass、laas、AIaas)-CSDN博客文章浏览阅读22次。云服务是一种基于互联网的计算模式,通过云计算技术将计算、存储、网络等资源以服务的形式提供给用户,用户可以通过网络按需使用这些资源,无需购买、安装和维护硬件设备。云服务具有灵活扩展、按需使用、随时随地访问等优势,可以降低用户成本,提高资源利用效率。随着云计算技术的不断发展,云服务的应用范围也将越来越广泛。https://blog.csdn.net/2202_75469062/article/details/134212001?spm=1001.2014.3001.5501基础课19——客服系统知识库的搭建流程-CSDN博客文章浏览阅读210次。作为一名人工智能训练师,客服系统知识库的搭建流程是怎样的?
https://blog.csdn.net/2202_75469062/article/details/134210866?spm=1001.2014.3001.5501