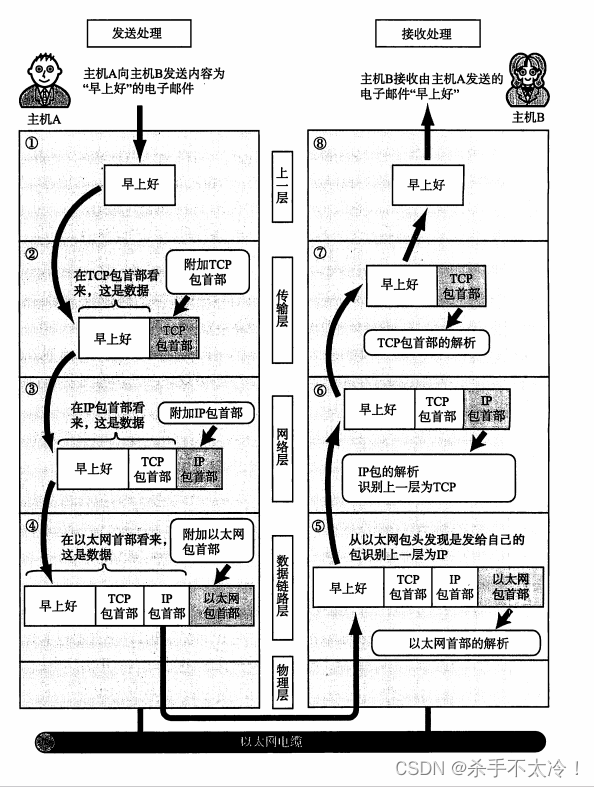
前言
本文是对jupyterlab中oneAPI_Essentials/03_Unified_Shared_Memory文档的学习记录,主要包含对统一共享内存的讲解
USM概述
USM (Unified Shared Memory)是SYCL中基于指针的内存管理。对于使用malloc或new来分配数据的C和C++程序员来说应该很熟悉。当将现有的C/ C++代码移植到SYCL时,USM简化了程序员的开发
使用USM,开发人员可以在主机和设备代码中引用相同的内存对象

Types of USM
统一共享内存为管理内存提供了显式和隐式模型
 USM初始化:下面的初始化显示了使用malloc_shared共享分配的示例,“q”队列参数提供了有关内存可访问的设备的信息
USM初始化:下面的初始化显示了使用malloc_shared共享分配的示例,“q”队列参数提供了有关内存可访问的设备的信息

下面是在host上分配内存的方法:

释放USM
数据隐式移动
下面的SYCL代码显示了使用malloc_shared的USM的实现,其中数据在主机和设备之间隐式地移动。可以用最少的代码快速获得功能,开发人员不必担心在主机和设备之间移动内存
#include <sycl/sycl.hpp>
using namespace sycl;
static const int N = 16;
int main() {
queue q;
std::cout << "Device : " << q.get_device().get_info<info::device::name>() << "\n";
//# USM allocation using malloc_shared
int *data = malloc_shared<int>(N, q);
//# Initialize data array
for (int i = 0; i < N; i++) data[i] = i;
//# Modify data array on device
q.parallel_for(range<1>(N), [=](id<1> i) { data[i] *= 2; }).wait();
//# print output
for (int i = 0; i < N; i++) std::cout << data[i] << "\n";
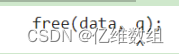
free(data, q);
return 0;
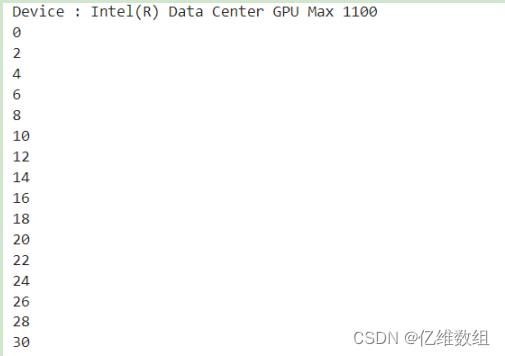
}运行结果
数据显示移动
下面的SYCL代码显示了使用malloc_device的USM实现,其中主机和设备之间的数据移动应该由开发人员使用memcpy显式地完成
#include <sycl/sycl.hpp>
using namespace sycl;
static const int N = 16;
int main() {
queue q;
std::cout << "Device : " << q.get_device().get_info<info::device::name>() << "\n";
//# initialize data on host
int *data = static_cast<int *>(malloc(N * sizeof(int)));
for (int i = 0; i < N; i++) data[i] = i;
//# Explicit USM allocation using malloc_device
int *data_device = malloc_device<int>(N, q);
//# copy mem from host to device
q.memcpy(data_device, data, sizeof(int) * N).wait();
//# update device memory
q.parallel_for(range<1>(N), [=](id<1> i) { data_device[i] *= 2; }).wait();
//# copy mem from device to host
q.memcpy(data, data_device, sizeof(int) * N).wait();
//# print output
for (int i = 0; i < N; i++) std::cout << data[i] << "\n";
free(data_device, q);
free(data);
return 0;
}运行结果

代码解释
本代码让数据在主机区和设备区显示移动,提高了开发人员对数据的可控性
首先本代码使用malloc在主机分配内存,然后给这些内存赋值,然后使用malloc_device在设备区分配内存,然后把主机区的内存拷贝到设备区的这些内存中,然后在设备区加速处理这些数据之后再拷贝到主机区的原内存中,最后使用cout输出
USM的优势
SYCL*缓冲区功能强大且优雅,但是,在c++程序中用缓冲区替换所有指针和数组可能会给程序员带来负担,因此在这种情况下可以考虑使用USM
1.当把c++代码移植到sycl时,想要尽可能更改少的代码
2.当需要控制数据移动时,使用显式USM分配
3.在移植代码时使用共享分配可以快速获得功能
Data dependency in USM
程序员可以显式地使用wait对象,也可以使用命令组中的depends_on方法来指定在任务开始之前必须完成的事件列表
在下面的示例中,两个内核任务正在更新相同的数据数组,这两个内核可以同时执行,并且可能导致错误的结果

Different options to manage data dependency when using USM:
wait()
在内核任务上使用q.wait()来等待下一个依赖的任务可以开始,但是它会阻塞主机上的执行

in_order queue property
为队列使用in_order 队列属性,这将序列化所有内核任务。注意,即使队列没有数据依赖关系,执行也不会重叠

depends_on
在命令组中使用h.depends_on(e)方法来指定任务开始之前必须完成的事件

简化版

Code Example: USM and Data dependency
这个例子主要演示了上面三种方法的使用
初始代码

想要修改上面代码,只需下面三种方法三选一
使用wait

使用in_order queue property
![]()
使用depends_on

运行结果

Lab Exercise: Unified Shared Memory
实验要求

下面是我已经补全的代码和运行结果
#include <sycl/sycl.hpp>
#include <cmath>
using namespace sycl;
static const int N = 1024;
int main() {
queue q;
std::cout << "Device : " << q.get_device().get_info<info::device::name>() << "\n";
//intialize 2 arrays on host
int *data1 = static_cast<int *>(malloc(N * sizeof(int)));
int *data2 = static_cast<int *>(malloc(N * sizeof(int)));
for (int i = 0; i < N; i++) {
data1[i] = 25;
data2[i] = 49;
}
//# STEP 1 : Create USM device allocation for data1 and data2
//# YOUR CODE GOES HERE
int *data_device1 = malloc_device<int>(N, q);
int *data_device2 = malloc_device<int>(N, q);
//# STEP 2 : Copy data1 and data2 to USM device allocation
//# YOUR CODE GOES HERE
q.memcpy(data_device1, data1, sizeof(int) * N).wait();
q.memcpy(data_device2, data2, sizeof(int) * N).wait();
//# STEP 3 : Write kernel code to update data1 on device with sqrt of value
q.parallel_for(N, [=](auto i) {
//# YOUR CODE GOES HERE
data_device1[i] = (int)std::sqrt(float(data_device1[i]));
}).wait();
//# STEP 3 : Write kernel code to update data2 on device with sqrt of value
q.parallel_for(N, [=](auto i) {
//# YOUR CODE GOES HERE
data_device2[i] = (int)std::sqrt(float(data_device2[i]));
}).wait();
//# STEP 5 : Write kernel code to add data2 on device to data1
q.parallel_for(N, [=](auto i) {
//# YOUR CODE GOES HERE
data_device1[i] += data_device2[i];
}).wait();
//# STEP 6 : Copy data1 on device to host
//# YOUR CODE GOES HERE
q.memcpy(data1, data_device1, sizeof(int) * N).wait();
//# verify results
int fail = 0;
for (int i = 0; i < N; i++) if(data1[i] != 12) {fail = 1; break;}
if(fail == 1) std::cout << " FAIL"; else std::cout << " PASS";
std::cout << "\n";
//# STEP 7 : Free USM device allocations
//# YOUR CODE GOES HERE
free(data_device1, q);
free(data_device2, q);
free(data1);
free(data2);
//# STEP 8 : Add event based kernel dependency for the Steps 2 - 6
return 0;
}运行结果

注:

这里可能转成double或者什么也不转都会报错,我电脑对这一块好像仅支持单精度,只能转成float才能运行,具体原理也不理解