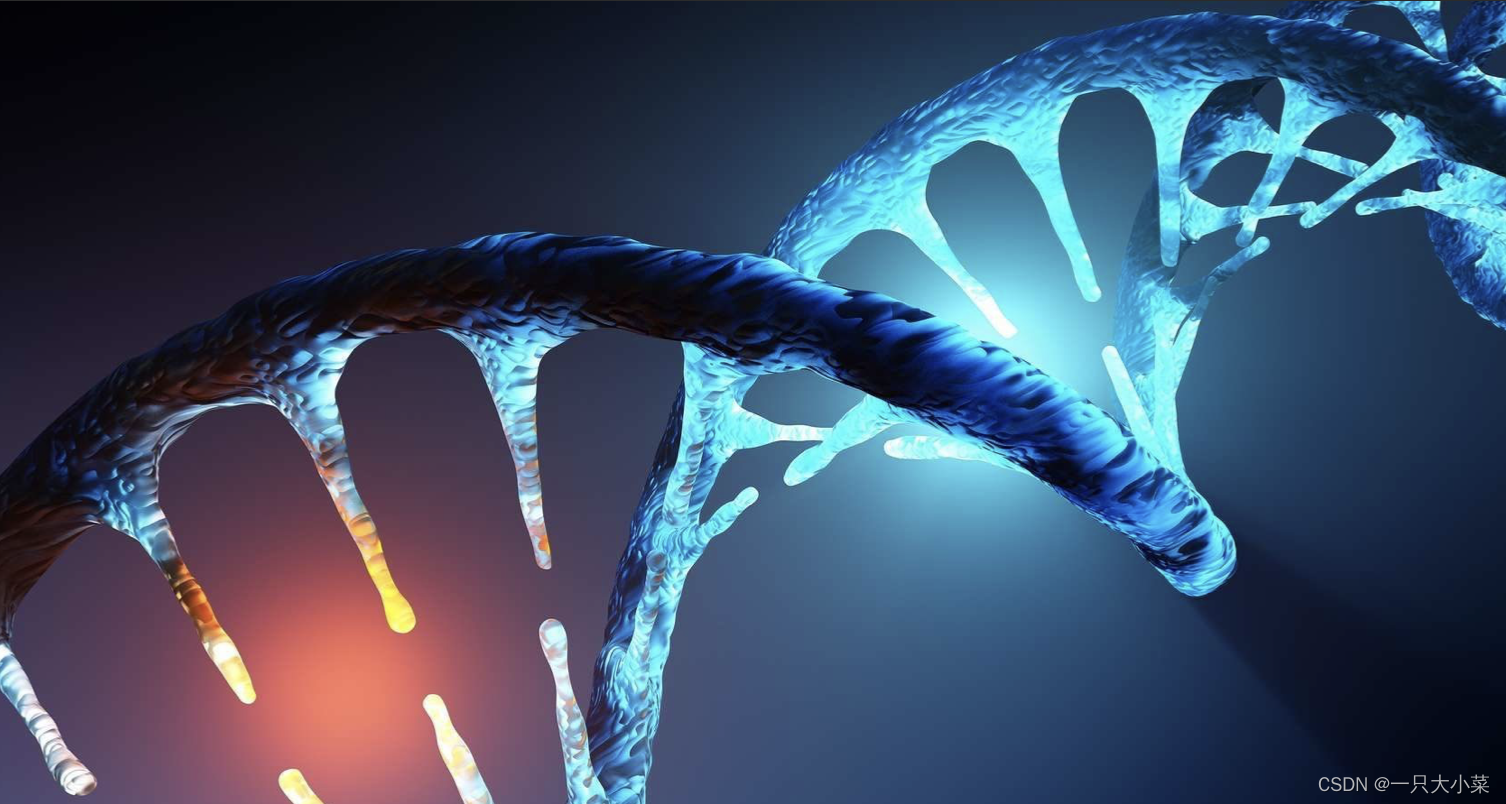
Transformer总架构图
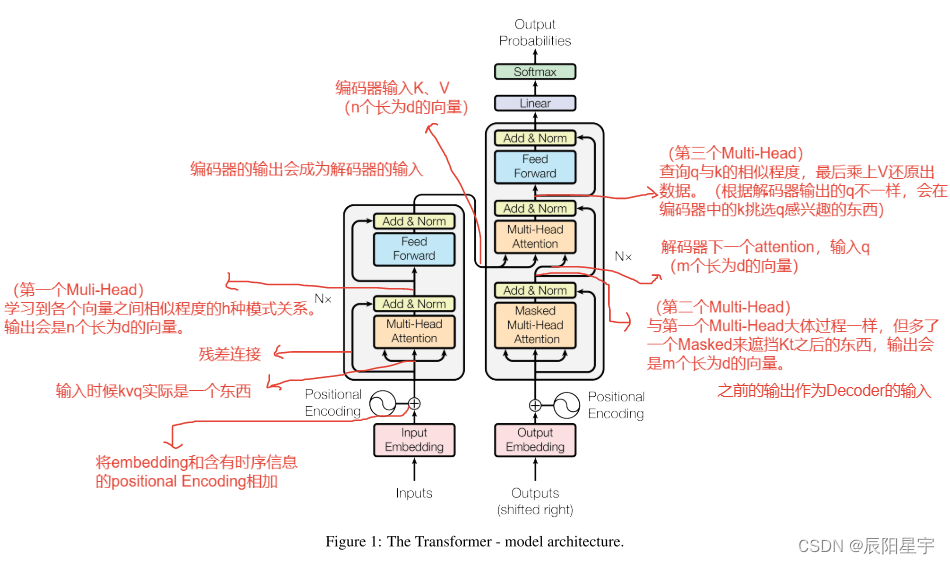
输入相关组件
输入部分:
- 源文本嵌入层+位置编码器
- 目标文本嵌入层+位置编码器
(1)Embedding
首先,需要对输入的内容进行向量化。
1)先导示例
nn.Embedding示例:
# 10代表嵌入的数不可超过10,3代表embedding的维度
embedding = nn.Embedding(10, 3)
input = torch.LongTensor([[1, 2, 4, 5], [4, 3, 2, 9]])
# # 将[1,2,4,5]和[4, 3, 2, 9]里的四个数,各自映射为四个三维向量
embedding(input)
tensor([[[-0.0251, -1.6902, 0.7172],
[-0.6431, 0.0748, 0.6969],
[ 1.4970, 1.3448, -0.9685],
[-0.3677, -2.7265, -0.1685]],
[[ 1.4970, 1.3448, -0.9685],
[ 0.4362, -0.4004, 0.9400],
[-0.6431, 0.0748, 0.6969],
[ 0.9124, -2.3616, 1.1151]]])
padding_idx作用是让被赋值的那个数在embedding时候各个维度里的值都变为0
# padding_idx等于几,哪个位置就全为0
embedding = nn.Embedding(10, 3, padding_idx=4)
input = torch.LongTensor([[4, 2, 4, 5]])
embedding(input)
tensor([[[ 0.0000, 0.0000, 0.0000],
[ 0.1535, -2.0309, 0.9315],
[ 0.0000, 0.0000, 0.0000],
[-0.1655, 0.9897, 0.0635]]])
2)Embedding实现
embedding输入
import torch
import torch.nn as nn
import math
# 使用torch里的模块,继承nn.Embedding
class Embedding(nn.Module):
# vocab: 词表长度; d_model词嵌入的维度
def __init__(self, vocab, d_model):
super(Embedding, self).__init__()
# lut:look-up table
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
# 可理解为该层的前向传播逻辑,所有层中都会有此函数。
# 当传给该类的实例化对象时,自动调用该类函数。
def forward(self, x):
# 乘上一个根号d_model来放大lut的大小,让其和positional encoding值域范围近似
return self.lut(x) * math.sqrt(self.d_model)
注意:
embedding里采用的L2Norm。因为各维度总和会为1,维度越大的向量归一化后单个值就会越小,因为后面还要加上positional encoding,为了保证和这个值大小差不多,需要把embedding扩大一下,就需要乘上这个权重。
示例
d_model=512
vocab=1000
x=torch.LongTensor([[100,2,421,508], [491,988,1,221]]) # 2 * 4
emb = Embedding(vocab, d_model) # 1000 * 512
test_emb = emb(x) # 2 * 4 * 512
print("embeding:", test_emb, "\nshape:", test_emb.shape)
embeding: tensor([[[-22.1368, 5.8489, -4.3048, ..., 10.1736, -8.3588, -15.9710],
[ 56.4712, 18.5326, -33.1404, ..., 13.8900, 15.6980, 0.9166],
[ -7.5599, 5.7412, 7.9309, ..., -37.1804, 2.6838, -14.5033],
[-31.7061, 8.6661, -12.8770, ..., -29.6877, -37.0234, -60.4735]],
[[ 9.1579, 10.7355, 22.1405, ..., 26.5621, -16.2131, -11.0188],
[-26.9357, -39.1481, 27.4990, ..., -4.1475, -13.0475, 29.1349],
[-52.3744, -11.6883, 12.3517, ..., 12.9772, -1.0818, 18.6217],
[ 26.1174, -23.1478, -14.2219, ..., 29.2699, 12.5628, 16.7982]]],
grad_fn=<MulBackward0>)
shape: torch.Size([2, 4, 512])
(2)Positional Encoding
因为采用的attention注意力机制只能得到词与词之间的相关程度,但不包含词与词之间的位置信息,这就会导致只要输入的文字都相同,不论以什么顺序输入这些文字,最后都会得到同样的结果。因此,需要想办法加入词序之间的信息,就有了Positional Encoding.。
1)先导示例
nn.Dropout示例:
m = nn.Dropout(p=0.1)
input1 = torch.randn(5,6)
output = m(input1)
print(output)
tensor([[ 1.7470, 0.2384, -0.7003, -0.9112, -0.2812, 0.2167],
[ 0.0000, 1.0510, -0.0268, 0.1691, -0.8758, 0.7029],
[-0.5565, -0.7345, 1.5827, -0.9349, 0.2578, -0.0000],
[-0.0000, 1.9349, 0.8612, -0.0000, -0.6373, 0.1144],
[-1.5473, -0.6834, 1.0102, -0.6242, -0.1893, -1.5241]])
unsqueeze示例:
h.unsqueeze(k):让h在第k个维度上扩展
x = torch.tensor([1, 2, 3, 4])
y = torch.unsqueeze(x, 0)
print(y)
z = torch.unsqueeze(x, 1)
print(z)
tensor([[1, 2, 3, 4]]) # 注意这个是两个括号
tensor([[1],
[2],
[3],
[4]])
2)Positional Encoding实现
对于Positional Encoding实际上分为四步:
(1)定义位置编码矩阵形状
(2)填充位置编码矩阵:
1)定义句子位置编码向量(长度为max_len的一个列向量);
2)定义一个形状变换向量(长度为d_model的一个行向量),用于与句子位置编码向量相乘后,向d_model方向扩充,将位置编码向量变为位置编码矩阵。
(3)扩展位置编码矩阵,将其变为含批数的三维矩阵
(4)与输入的x进行相加,截取和x相同形状部分,剩余部分丢弃(因每次构造的位置编码矩阵是按照最大长度构造的一个模板,因此只保留和x相同的部分)。
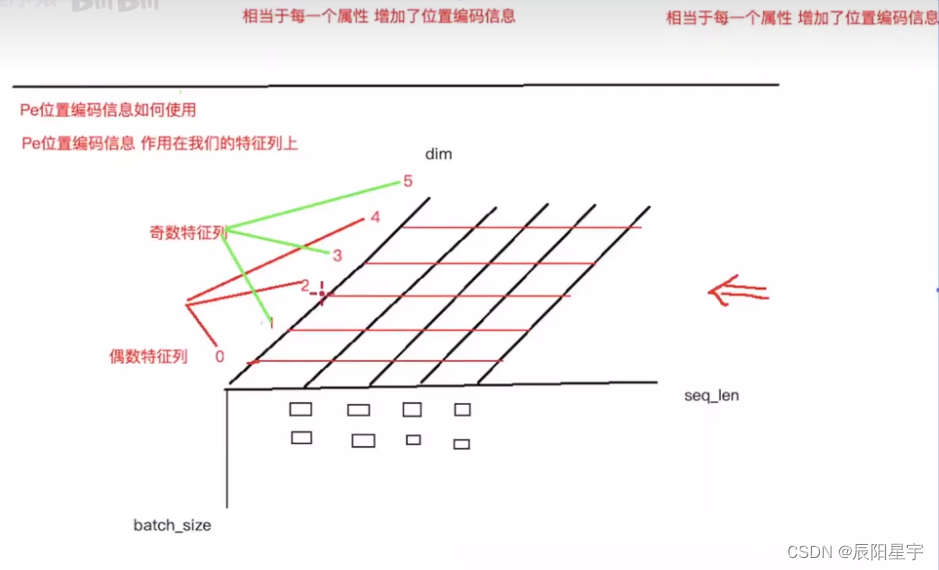

位置编码的计算函数
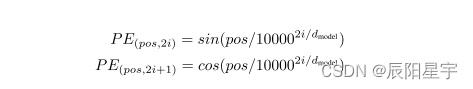
class PositionalEncoding(nn.Module):
# 输入d_model:词嵌入维度、drouput:置0比率、max_len:每个句子最大长度
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
# 实例化nn中预定义的Dropout层
self.dropout = nn.Dropout(p=dropout)
# 初始化一个位置编码矩阵 [max_len, d_model] # 当输入维度为(60 * 512)时
pe = torch.zeros(max_len, d_model) # 60 * 512
# 初始化一个绝对位置矩阵 [max_len, 1],得到一个有时序信息的向量,用于后续加入到位置编码矩阵中
position = torch.arange(0, max_len).unsqueeze(1) # 列向量 (60, 1)
# 实现 e^(-(2i/d_model)*ln(10000)) = e^(ln(10000)^(-(2i/d_model))) = 1/(10000)^(2i/d_model)
# torch.arange(0, d_model, 2)将会产生从[0, d_model]中每间隔两个数取出来一个数的集合
# 得到一个embedding对应维度的编码方式
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)) # (1 * 256)
# 得到偶数列数据
pe[:, 0::2] = torch.sin(position * div_term) # (60 * 1) * (1 * 256) ==> 60 * 256
# 得到奇数列数据
pe[:, 1::2] = torch.cos(position * div_term) # (60 * 1) * (1 * 256) ==> 60 * 256
# 拓展维度更新形状,变为输入一批数据时呈现的结构
pe = pe.unsqueeze(0) # [1, 60, 512]
'''
向模块添加持久缓冲区。
这通常用于注册不应被是为模型参数的缓冲区。例如,pe不是一个参数,而是一个持久状态的一部分。
缓冲区可以使用给定的名称作为属性访问。
说明:
应该就是在内存中定义一个常量,同时,模型保存和加载的时候可以写入和读出,让其不会在梯度更新时候被再重新计算
'''
self.register_buffer('pe', pe)
def forward(self, x):
# pe[:, :x.size(1)]保证行数不变,列数与x相等。其中,行数为批数,列数为一批中的embedding个数。
x = x + self.pe[:, :x.size(1)].detach() # 使用detach可以避免其梯度被重复计算
# 最后经过Dropout层后输出
return self.dropout(x)
注意:变换思路
主要的过程,就是实现对位置编码矩阵pe的填充,通过绝对位置向量positon和d_model维度扩充向量div_term相乘构造出和pe形状相同的矩阵,再使用三角函数作用,来保证连续且在同一比较界限范围内。
注意:position和div_term相乘思路
(1)想让position的位置信息加入到位置编码矩阵中,想法就是让[max_len, 1]变为[max_len, d_model]再加到pe中。要想做成这种变换就需要每一个[1, d_model]的向量来实现形状变化,[max_len, 1] * [1, d_model] == > [max_len, d_model]
(2)除了形状变换之外,还需要将自然数的绝对位置编码缩小,有助于后续梯度下降时候可以更快收敛,因此就有了
d
i
v
=
1
(
10000
)
2
i
d
_
m
o
d
e
l
div=\frac{1}{(10000)^\frac{2i}{d\_model}}
div=(10000)d_model2i1,2i 通过torch.arange(0, d_model, 2)来实现,
d
_
m
o
d
e
l
d\_model
d_model 越大,
d
i
v
div
div 越大,从而达到调控embedding数据作用。
注意:pe[:, :x.size(1)]截取原因
pe是通过max_len得到的最大长度时候的位置编码矩阵,而实际中的x并不一定会达到max_len,因此需要统一维度进行以x为标准进行切割处理。
示例
# 定义PositionalEncoding的参数
d_model = 512
dropout = 0.1
max_len = 60
# 输入之前得到的embedding
pe = PositionalEncoding(d_model, dropout, max_len)
pe_res = pe(test_emb)
print("pe_res:", pe_res, "\nshape:", pe_res.shape)
'''
embeding: tensor([[[ -4.1141, -22.1936, -2.1720, ..., -1.8160, -5.8038, 3.9030],
[-26.2369, 35.3158, -26.7828, ..., 18.1910, -15.5895, -0.5780],
[ 27.6906, 7.8964, -3.2235, ..., -15.7689, -6.2119, -5.0473],
[-10.3022, 16.1367, 21.4265, ..., 28.1743, -11.6089, -24.7860]],
[[ 10.2011, 25.3486, -8.0284, ..., -13.7405, -4.7748, 30.3610],
[ 20.5093, 7.5563, -3.9737, ..., -32.6686, -14.8885, -5.9809],
[ 61.4368, 7.0695, 15.5462, ..., 27.6469, 4.0113, -17.1434],
[ 2.5992, 9.6200, -22.2852, ..., 29.4035, 52.7968, 3.9688]]],
grad_fn=<MulBackward0>)
shape: torch.Size([2, 4, 512])
'''
# 变化前后对比
pe_res: tensor([[[ -4.5712, -23.5485, -2.4134, ..., -0.0000, -6.4486, 5.4478],
[-28.2171, 39.8401, -28.8455, ..., 21.3233, -17.3215, 0.4689],
[ 31.7777, 8.3114, -2.5412, ..., -16.4098, -6.9019, -4.4970],
[-11.2900, 16.8297, 24.0796, ..., 32.4159, -12.8984, -0.0000]],
[[ 11.3345, 29.2762, -8.9204, ..., -14.1561, -5.3053, 34.8455],
[ 23.7231, 8.9963, -0.0000, ..., -35.1873, -16.5426, -5.5343],
[ 69.2735, 7.3926, 18.3140, ..., 31.8299, 4.4573, -17.9371],
[ 3.0448, 9.5888, -24.4890, ..., 33.7817, 58.6635, 5.5209]]],
grad_fn=<MulBackward0>)
shape: torch.Size([2, 4, 512])
可以看出加入位置信息后,对于每列都会有一定的数值上的变化影响。