模型训练:
train.py
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='image --cache ram/disk')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)') # workers设置进程个数,最好设置为0
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--seed', type=int, default=0, help='Global training seed')
parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
# Logger arguments
parser.add_argument('--entity', default=None, help='Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='Version of dataset artifact to use')
return parser.parse_known_args()[0] if known else parser.parse_args()参数设置:
主要是这三行代码:
parser.add_argument('--weights', type=str, default '', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')- weights:指定预训练模型的权重文件路径,例如 --weights weights/yolov5s.pt。但是刚开始训练的时候一般设置为空。
- cfg:指定模型的配置文件路径,例如 --cfg models/yolov5s.yaml。
yolov5模型种类(可以填进去的参数):
- yolov5l:大型模型
- yolov5s:中等模型
- yolov5s:小型模型
- yolov5x:
- data:指定训练数据集路径,例如 --data coco.yaml。数据集文件 yaml文件指定在哪里下载数据集,如果在指定文件里,则不用使用文件里的下载连接,如果不在,则会使用文件里的download下载连接重新下载数据集,并将数据集放在指定的文件夹里。
可以填进去的参数:
- coco.yaml
- coco128.yaml
- voc.yaml
- –epochs:指定训练的 epoch 数,例如 --epochs 300。
- –batch-size:指定每个 batch 的大小,例如 --batch-size 16。
- –img-size:指定输入图片的大小,例如 --img-size 640 表示输入图片的大小为 640x640。
- –rect :指定在训练过程中是否进行图像矫正,例如 --rect 表示进行图像矫正。
- –resume:指定是否从之前的训练中断处继续训练,例如 --resume 表示从中断处继续训练。
- –nosave 不保存模型 默认False(保存)。
- –noautoanchor 不自动调整anchor, 默认False, 自动调整anchor。
- –evolve:指定是否进行超参数优化,例如 --evolve 表示进行超参数优化。
- –name:指定保存模型的名称,例如 --name my_model 表示保存模型为 my_model.pt。
- –workers:指定用于加载数据的进程数,例如 --workers 8 表示使用 8 个进程来加载数据。
以上参数可以在命令行使用,例如:
python train.py --data coco.yaml --batch-size 16 --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --device 0 --epochs 300 --img-size 640 --notest --workers 8 --rect --cache-images --name my_model --evolve
训练结果:
训练结束后,在“autodl-tmp/yolov5-5.0/runs/train/exp9”这里提取获得训练结果,在“autodl-tmp/yolov5-5.0/runs/train/exp9/weights”获得best.py文件。
best.py和last.py是保存的一些训练模型权重数据,训练好后可以作为测试环节的weights。
best.py是训练最好的模型数据
last.py是最新的模型数据。
模型测试:
detect.py
if __name__ == '__main__':
parser = argparse.ArgumentParser(prog='test.py')
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='*.data path')
parser.add_argument('--batch-size', type=int, default=32, help='size of each image batch')
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.001, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.6, help='IOU threshold for NMS')
parser.add_argument('--task', default='val', help='train, val, test, speed or study')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--verbose', action='store_true', help='report mAP by class')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-json', action='store_true', help='save a cocoapi-compatible JSON results file')
parser.add_argument('--project', default='runs/test', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()
opt.save_json |= opt.data.endswith('coco.yaml')
opt.data = check_file(opt.data) # check file
print(opt)
check_requirements()
训练好的模型放在了autodl-tmp/yolov5-5.0/runs/train/exp6/weights/best.pt
点击复制best.pt文件并粘贴到detect.py文件的同一目录。
在detect.py文件里修改权重:
将default设置为best.pt.
parser.add_argument('--weights', nargs='+', type=str, default='best.pt', help='model.pt path(s)')参数设置:
主要是修改两行代码:
# parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--weights', nargs='+', type=str, default='best.pt', help='model.pt path(s)')
# parser.add_argument('--data', type=str, default='data/coco128.yaml', help='*.data path')
parser.add_argument('--data', type=str, default='./data/mydata.yaml', help='*.data path')测试结果:
测试结果保存在该路径下“autodl-tmp/yolov5-5.0/data/images".
云端(AutoDL)训练文件
准备工作:
解压压缩包:
!unzip /content/yolov5-5.0.zip -d /content/yolov5
删除文件:
!rm -rf /content/yolov5/ MACOSX
进入当前文件夹:
%cd /content/yolov5/yolov5-5.0下载requirement:
!pip install -r requirements.txt加载tensorboard
ext是tian'jia
%load_ext tensorboard![]()
%load_ext tensorboard重新加载tensorboard
![]()
%reload_ext tensorboard启动tensorboard
%tensorboard --logdir=runs/train训练模型
!python train.py测试模型
!python test.py制作自己的数据集
制作数据集的软件:
makesense.ai
网址:
https://www.makesense.ai/进入网址:
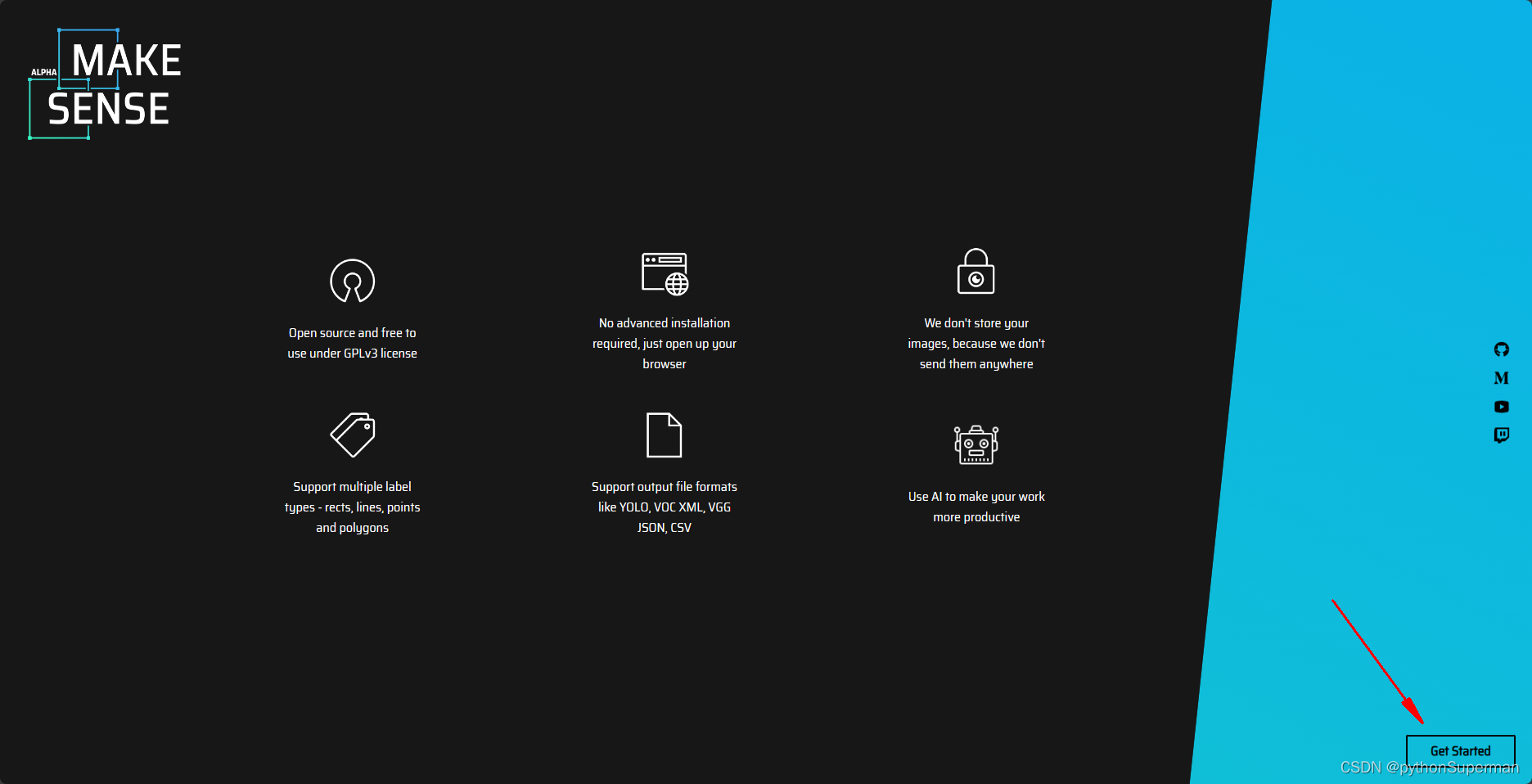
上传数据,启动目标检测

预定义类别:
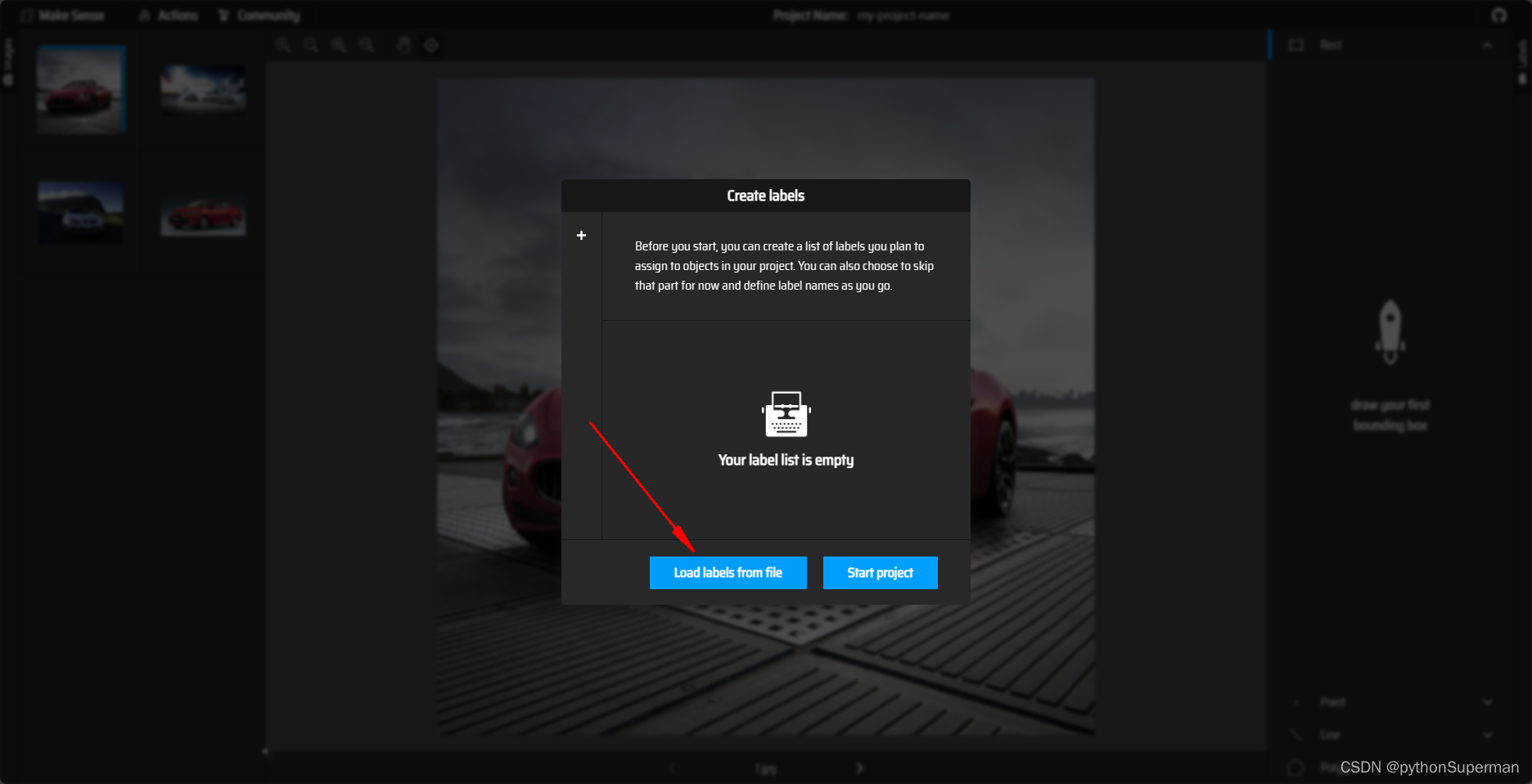
启动时添加类别:
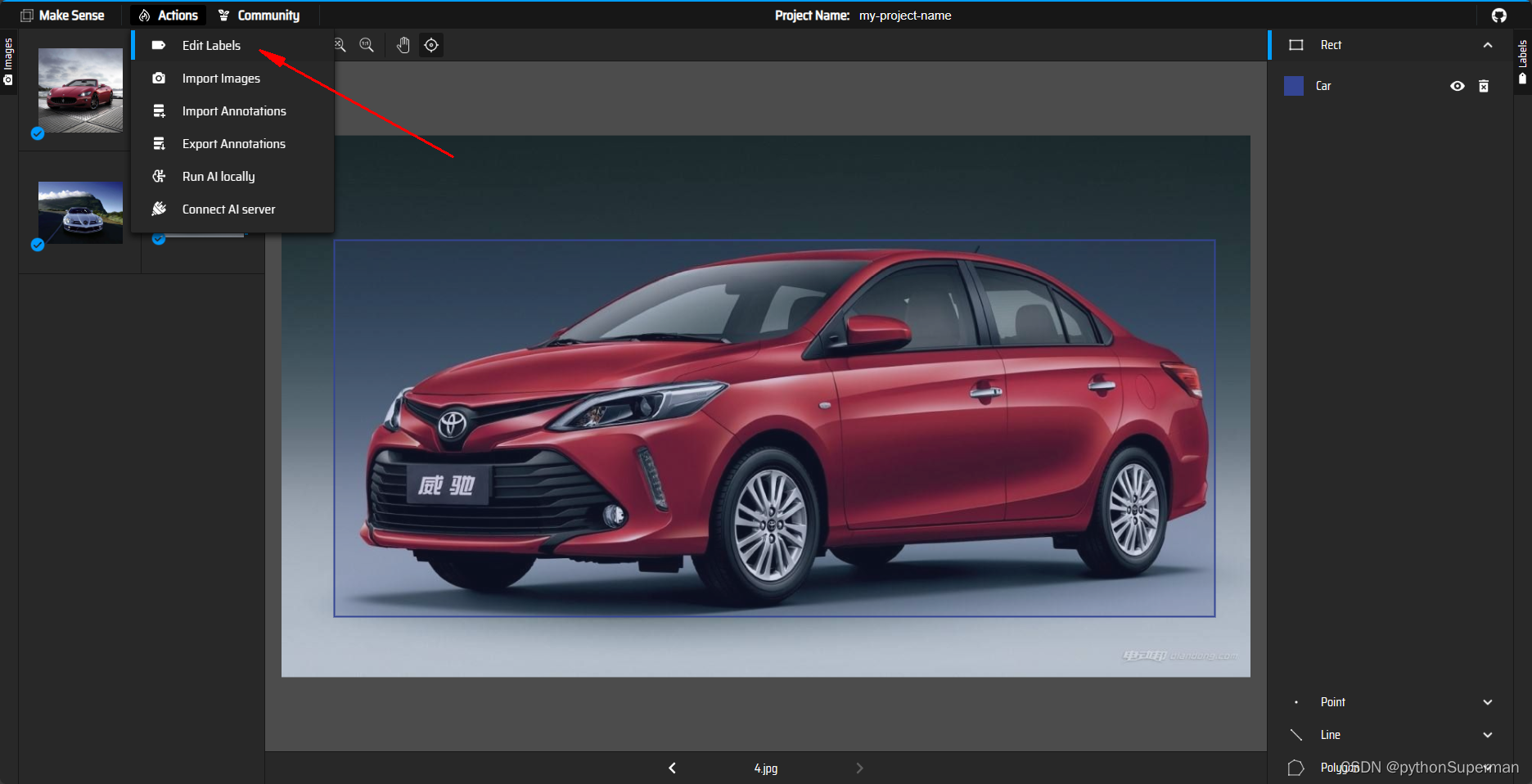
AI:
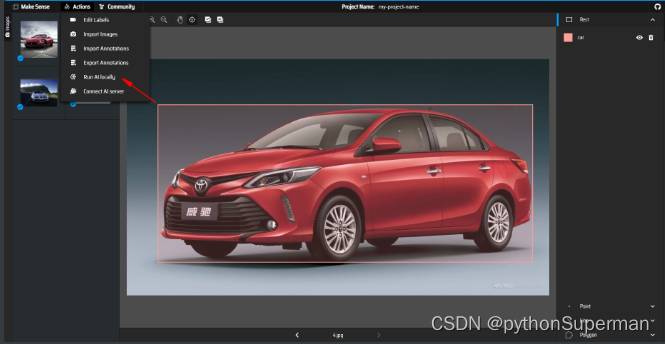
export:

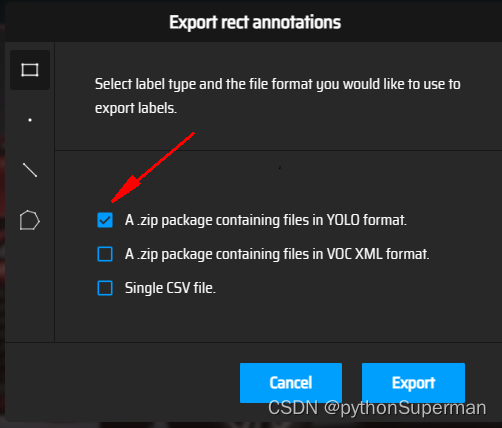
三大改动
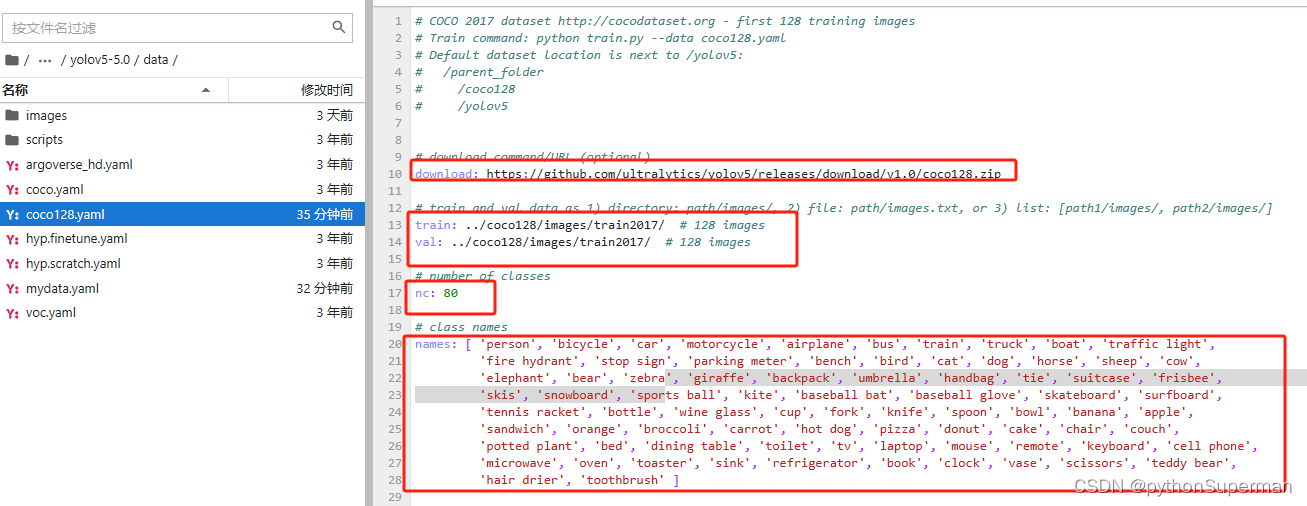
1.1 改动 dataset.yaml
# COCO 2017 dataset http://cocodataset.org - first 128 training images
# Train command: python train.py --data coco128.yaml
# Default dataset location is next to /yolov5:
# /parent_folder
# /coco128
# /yolov5
# download command/URL (optional)
download: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip
#如果数据集对应路径不存在,则通过参考链接自动下载。
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ../coco128/images/train2017/ # 128 images
val: ../coco128/images/train2017/ # 128 images
# number of classes
nc: 80
# class names
names: [ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush' ]
复制粘贴一个新的coco128.yaml文件的内容,文件命名为mydata.yaml:
-
路径位置:autodl-tmp/yolov5-5.0/data/mydata.yaml
-
修改四处地方
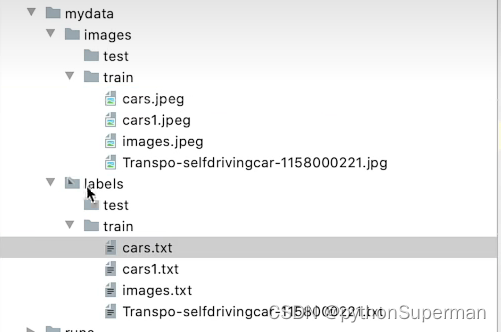
1,2 构建自己的数据集文件夹组织结构
以下是直观的文件组织目录:
1.3 主要是在train.py文件的main函数里改动两个:
1、weight权重文件的路径
2、yaml数据集文件的路径
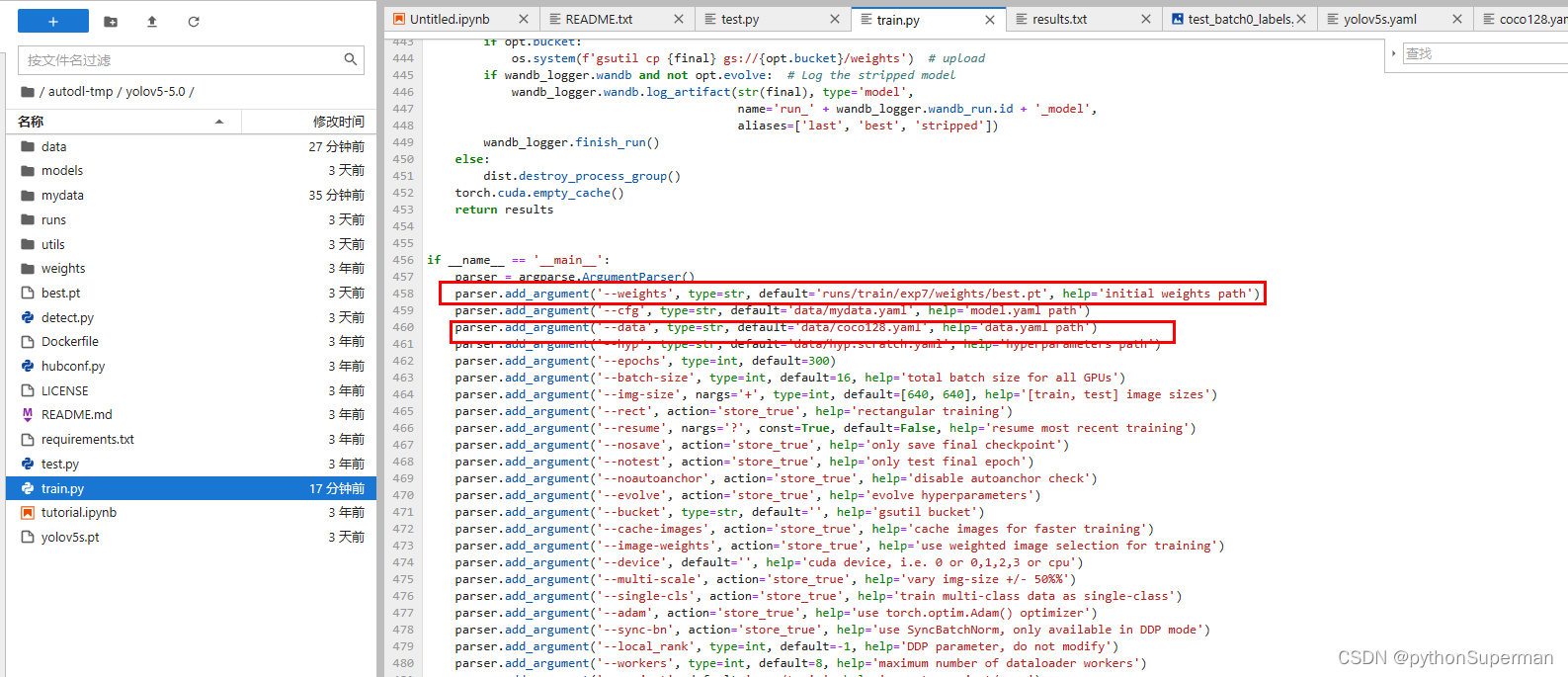
解释yaml文件:
在yolov5目标检测项目里,yaml文件用来当做中介,是模型训练时的data数据集,然后通过键值对映射到真正的数据集,训练集,种类数量,种类名称。
YAML(YAML Ain't Markup Language)是一种人类可读、用于数据序列化的格式。它采用了类似于其他编程语言中的键值对的结构。YAML文件通常用于配置文件和数据交换,具有简洁、易读、易写的特点。
YAML文件使用缩进和空格来表示层次结构,而不是像XML或JSON那样使用标签或大括号。这使得YAML文件更加清晰、易于阅读和编辑。
下面是一个简单的YAML示例:
yamlCopy Code# 注释以 # 开头
name: John Smith
age: 30
email: john@example.com
address:
street: 123 Main St
city: New York
country: USA在上面的示例中,name,age,email和address都是键,它们对应的值可以是字符串、数字、布尔值或其他复杂类型。address键下面有一个嵌套的层次结构,使用缩进来表示。
YAML还支持列表和复杂的数据结构,例如包含多个对象的列表或嵌套的字典。此外,YAML还可以使用特殊标记来表示日期、正则表达式等特殊类型。
总而言之,YAML是一种用于配置文件和数据序列化的格式,它采用简洁、易读、易写的结构,并使用缩进和空格来表示层次结构。
解释txt文件:
Create Labels
After using an annotation tool to label your images, export your labels to YOLO format, with one
*.txtfile per image (if no objects in image, no*.txtfile is required). The*.txtfile specifications are:
One row per object
Each row is
class x_center y_center width heightformat.Box coordinates must be in normalized xywh format (from 0 - 1). If your boxes are in pixels, divide
x_centerandwidthby image width, andy_centerandheightby image height.Class numbers are zero-indexed (start from 0).
txt文件的解释
2 0.111111 0.22222 0.333333 0.444444
第一个:类别
第二个:x的中心
第三个:y的中心
第四个:宽度
第五个:高度
后面四位数字是做了归一化的(0到1)
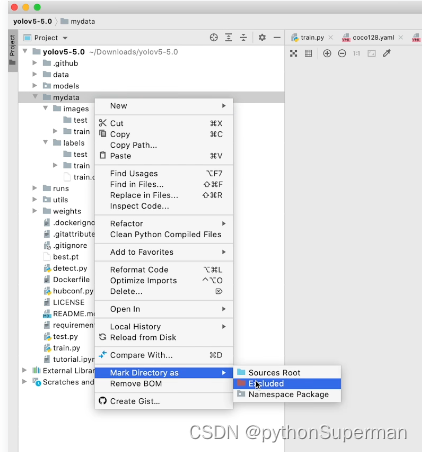
小修改-exclude无关数据集
防止花时间去检索没必要的数据集
在AutoDL上调试yolov5
由于实验室服务器的环境不匹配,需要重新再在的包很多,我转成了云上服务器AutoDL。
通过github我下载了yolov5的5.0版本“yolov5-5.0”.
下载之后会有tutoral.py的教程文件。
通过Setup模块来配置相关环境:
!git clone https://github.com/ultralytics/yolov5 # clone repo
%cd yolov5
%pip install -qr requirements.txt # install dependencies
import torch
from IPython.display import Image, clear_output # to display images
clear_output()
print('Setup complete. Using torch %s %s' % (torch.__version__, torch.cuda.get_device_properties(0) if torch.cuda.is_available() else 'CPU'))这第一行代码是直接下载yolov5文件的压缩包,即通过github下载了一次yolov5文件,再下载一个。
第二行代码是进入yolov5文件夹的意思。
第三行代码是一次性下载所有相关包的意思。
在终端运行"python train.py"之后出现的报错问题
Exception has occurred:
RemoteDisconnected Remote end closed connection without response
关了梯子,成功运行
untimeError: Given groups=1, weight of size [512, 1024, 1, 1], expected input[1, 512, 8, 8] to have 1024 channels, but got 512 channels instead
在train.py文件中:
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path')
修改if name == ‘main’:里的
cfg的dafault为‘models/yolov5s.yaml’即可
WARNING: Dataset not found, nonexistent paths: ['/root/autodl-tmp/coco128/images/train2017']
按照提示在指定文件夹下创建文件夹,完善目录结构