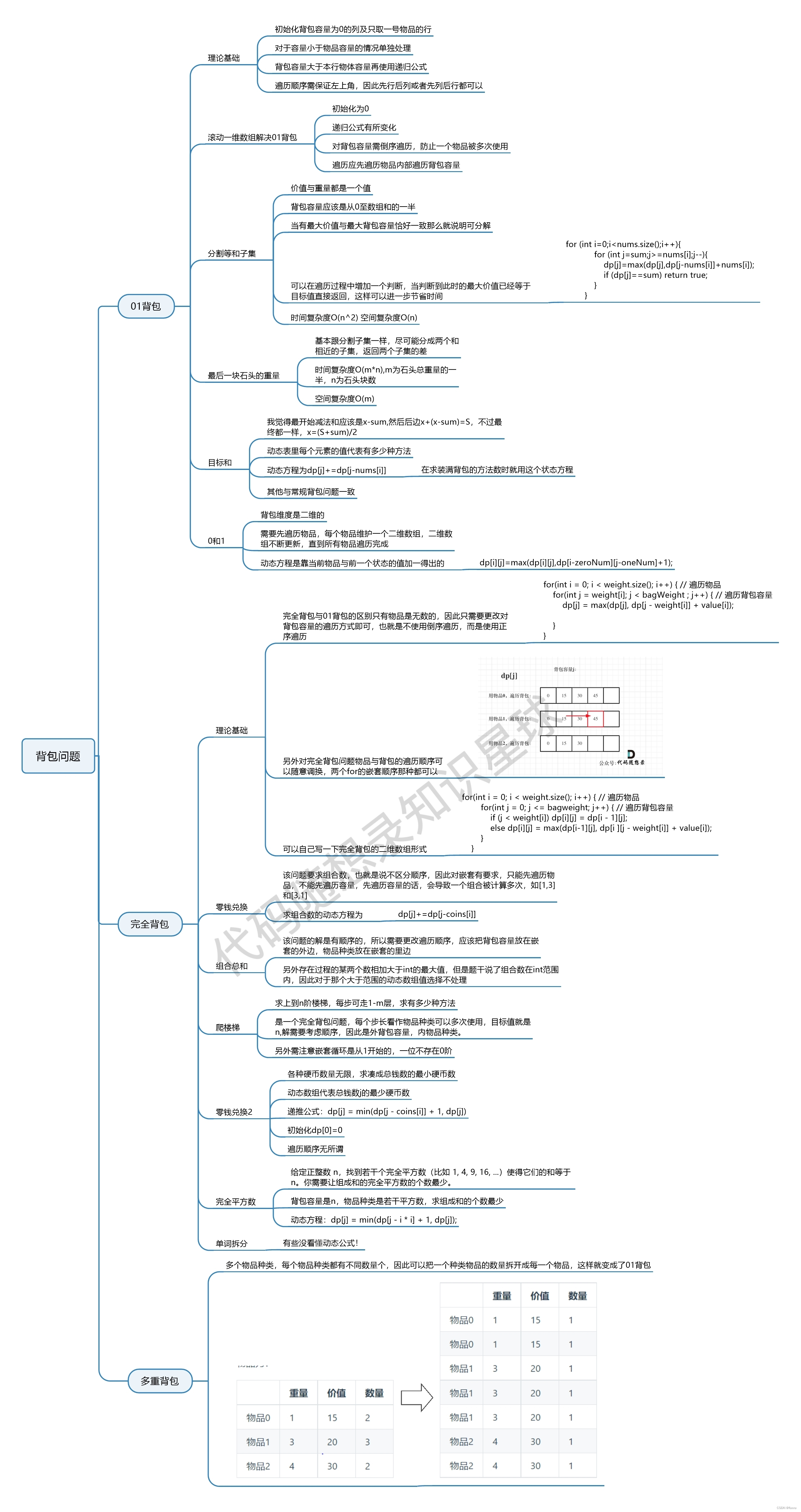
从商业计算机的出现开始,数据处理就一直推动着计算机的发展。事实上,数据处理自动化早于计算机的出现。Herman Hollerith 发明的穿孔卡片,早在20世纪初就用来记录美国的人口普查数据,并且用机械系统来处理这些卡片和列出结果。穿孔卡片后来被广泛用作将数据输入计算机的一种手段。

数据存储和处理技术发展的年表如下:
- 20世纪50年代和20世纪60年代初: 磁带被用于数据存储。诸如工资单这样的数据处理已经自动化了,数据存储在磁带上。数据处理包括从一个或多个磁带上读取数据,并将数据写回到新的磁带上。数据也可以由一叠穿孔卡片输入,而输出到打印机上。例如,工资增长的处理是通过将增长表示到穿孔卡片上,在读入一叠穿孔卡片时同步地读入保存主要工资细节的磁带。记录必须有相同的排列顺讯。工资的增加额将被加入到从主磁带读出的工资中,并被写到新的磁带上,新磁带将成为新的主磁带。
磁带(和卡片组)都只能顺序读取,数据规模可以比内存大得多,因此,数据处理程序被迫以一种特定的顺序来对数据进行处理,读取和合并来来自磁带和卡片组的数据。

-
20世纪60年代末和20世纪70年代: 20世纪60年代末硬盘的广泛使用极大地改变了数据处理的情况,因为硬盘允许直接对数据进行访问。数据在磁盘上的位置是无关紧要的,因为磁盘上的任何位置都可在几十毫秒内访问到。数据由此摆脱了顺序访问的限制。有了磁盘,我们就可以创建网状和层次的数据库,它可以将表和树这样的数据结构保存在磁盘上。程序员可以构建和操作这些数据结构。
📒 由 Codd[1970] 撰写的一篇具有里程碑意义的论文定义了关系模型和在关系模型中查询数据的非过程方法,由此关系型数据库诞生了。关系模型的简单性和能够对程序员屏蔽所有实现细节的能力具有真正的诱惑力。随后,Codd 因其所做的工作获得了声望很高的 ACM 图灵奖。

-
20世纪80年代: 尽管关系模型在学术上很受重视,但是最初并没有实际的应用,这是因为它被认为性能不好;关系型数据库在性能上还不能和当时已有的网状和层次数据库相提并论。这种情况直到 System R 的出现才得以改变,这是 IBM 研究院的一个突破性项目,它开发了可以构造高效的关系型数据库系统的技术。Astrahan 等[1976] 和 Chamberlin 等 [1981] 给出了关于 System R 的很好的综述。完整功能的 System R 原型导致了 IBM 的第一个关系型数据库产品 SQL/DS 的出现。与此同时,加州大学伯克利分校开发了 Ingres 系统。它后来发展成具有相同名字的商品化关系数据库系统。最初的商品化关系型数据库系统,如 IBM DB2、Oracle、Ingres 和 DECRdb,在推动高效处理声明性查询的技术上起到了主要的作用。到了20世纪80年代初期,关系型数据库已经可以在性能上与网状和层次型数据库进行竞争了。关系型数据库是如此简单易用,以至于最后它完全取代了网状/层次型数据库,因为程序员在使用后者时,必须处理许多底层的实现细节,并且不得不将他们要做的查询任务编码成过程化的形式。更重要的,他们在设计应用程序时还要实时考虑效率问题,而这需要付出很大的努力。相反,在关系型数据库中,几乎所有的底层工作都由数据库自动来完成,使得程序员可以只考虑逻辑层的工作。自从在20世纪80年代取得了统治地位以来,关系模型在数据模型中一直独占鳌头。
📒 在20世纪80年代人们还对并行和分布式数据库进行了很多研究,同样在面向对象数据库方面也有初步的工作。
-
20世纪90年代初: SQL 语言主要是为决策支持应用设计的,这类应用是查询密集的;而20世纪80年代数据库的支柱是事务处理应用,它们是更密集的。决策支持和查询再度成为数据库的一个主要应用领域。分析大量数据的工具有了很大的发展。
📒 在这个时期许多数据库厂商推出了并行数据库产品。数据库厂商还开始在他们的数据库中加入 对象 - 关系 的支持。
-
20世纪90年代: 最重大的事件就是互联网的爆炸式发展。数据库比以前有了更加广泛的应用。现在数据库系统必须支持很高的事务处理速度,而且还要有很高的可靠性和 24 x 7 的可用性(一天24小时,一周7天都可用,也就是没有进行维护的停机时间)。数据库系统还必须支持对数据的 Web 接口。
-
21世纪第一个十年: 21世纪的最初五年中,我们看到了 XML 的兴起以及与之相关联的 XQuery 查询语言成为了新的数据库技术。虽然 XML 广泛应用于数据交换和一些复杂数据类型的存储,但关系数据库仍然构成大多数大型数据库应用系统的核心。在这个时期,我们还见证了 “自主计算/自动管理” 技术的成长,其目的是减少系统管理开销;我们还看到了开源数据库系统应用的显著增长,特别是 PostgreSQL 和 MySQL。
📒 在21世纪第一个十年的后几年中,用于数据分析的专门的数据库有很大增长,特别是将一个表的每一列高效地存储为一个单独的数组的列存储,以及为非常大的数据集的分析而设计的高度并行的数据库系统。有几个新颖的分布式数据库存储系统被构建出来,以应对非常大的 Web 节点如 Amazon、Facebook、Google、Microsoft 和 Yahoo!的数据库管理需求,并且这些系统中的某些现在可以作为 Web 服务提供给应用开发人员使用。在管理和分析流数据如股票市场报价数据或计算机网络检测数据方面也有重要的工作。数据挖掘技术现在被广泛部署应用,应用实例包括基于 Web 的产品推荐系统和 Web 页面上的相关广告自动布放。