文章目录
- 进程的创建
- fork函数
- 写时拷贝的原理
- fork函数的用法和失败原因
- 进程终止
- 进程的退出
- 进程异常的问题
- 进程终止
- 进程退出
- 进程等待
- 什么是进程等待?
- 为什么要进行进程等待?
- 如何进行进程等待?
- 父进程如何知道子进程的退出信息?
- waitpid的option选项
进程的创建
fork函数
fork是Linux中一个很重要的函数,主要是在已经创建的进程中要创建一个新的进程,新进程是子进程,原来的进程被叫做父进程
fork函数在之前的进程理解中已经简单提到了,这里对它进行一些拓展等认知
当进程调用fork的时候,控制会转移到内核中的fork代码,此时内核会进行下面的一些操作
- 分配新的内存块和内存数据给子进程
- 将父进程的部分数据结构内容拷贝给子进程
- 添加子进程到系统的进程列表当中
- 令
fork的值返回,开始进行调度器的调度
也就是说,当一个进程调用了fork之后,就会有两个二进制的代码进行相同的进程,而且都会运行到一样的地方,每一个进程都可以有自己独立的过程,在系统中有很多个方面都可以对维护进程的独立性做出保证
下面举一个简单的例子来使用温习fork函数
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#define N 10
int main()
{
int i;
for(i=0;i<N;i++)
{
pid_t id = fork();
if(id==0)
{
printf("[%d],my pid:%d\n",i,getpid());
sleep(1);
exit(0);
}
}
sleep(100);
return 0;
}
上面函数就是一个简单的fork创建子进程的函数演示
写时拷贝的原理
对于前面对于进程地址空间的描述中有下面的理解:当使用fork创建了子进程后,子进程和父进程依旧共享着代码和数据,但如果子进程和父进程中有一个发生了对数据的修改,那么就会触发写时拷贝,将原来的数据拷贝一份,让改变的那个进程的数据段指向新拷贝出的数据段,这样做以维护进程之间的独立性,那么具体是如何实现的这个过程?操作系统又是如何进行拷贝的这个操作呢?
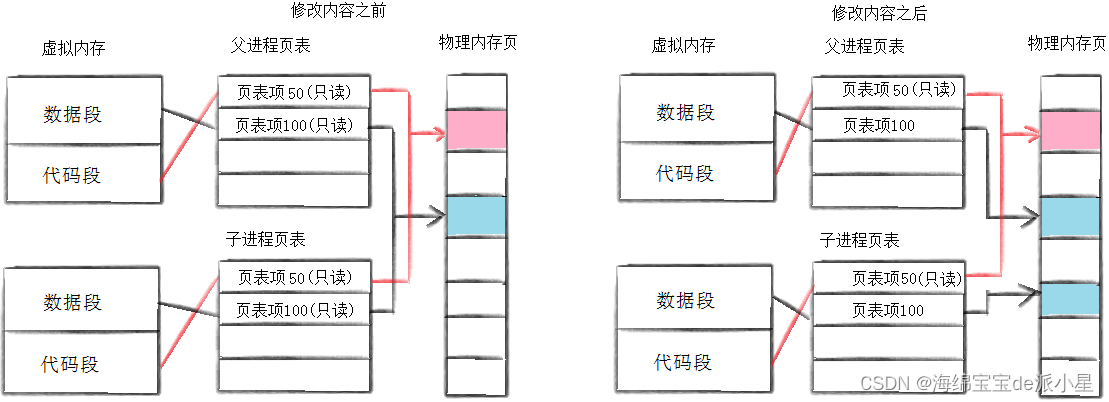
原理其实就是上图所展示的原理,当进程没有遇到fork之前都按照正常的逻辑进行运行,代码段和数据段对应页表中的访问权限是默认的情况,而当遇到fork这一系统调用的时候,在进行创建子进程的这个过程中,就会将数据段和代码段对应到页表中地址空间内的访问权限字段全部改成只读的权限,当进程运行到需要进行修改数据的操作的时候,就会通过页表去物理地址空间内进行修改,但是此时页表对应的访问权限字段的访问权限是只读,不允许发生写入的操作,此时操作系统就会去辨别这是什么原因导致的出错
也就是说,当页表的转换发生权限问题进行报错的时候,实际上是有两种可能的,一种是说真的出错了,比如要在字符常量区发生写入的改变,这肯定是不允许的,但还有一种情况是不是真的出错,而是触发了要让操作系统进行写时拷贝内容的一种策略,操作系统在观察到进程在运行到某个地方出现异常的时候就会去看具体的原因是什么,发现是触发了这个策略后,操作系统在这个时候就介入了这个阶段进行修改,进行拷贝等等的一系列操作
fork函数的用法和失败原因
一个父进程希望可以复制自己,同时父子进程还能够执行不同的代码片段,此时就可以使用fork来进行这样场景的使用,或者说一个进程要执行不同的程序
当系统中有太多进程的时候会fork失败,或者在实际用户的进程中已经超过了限制,也会调用失败
进程终止
在前面的C/C++学习中,main函数的最后结果返回的是一个return 0,那么这个语句究竟是什么意思呢?由此引出进程终止的概念
进程的退出
运行写好的代码变成的可执行程序的时候,程序最终会退出,常见的进程退出的原因主要有三个:
- 代码运行结束了,结果正确
- 代码运行结束了,结果不正确
- 代码压根没结束,运行异常而终止了
如何知道进程退出了?
对于所有进程的管理者操作系统来说,它需要知道关于进程的一系列信息,比如进程有没有退出,进程最后运行的结果如何,如果出错了是为什么出错的,而对于父进程来说,它创建的子进程也应该要有一定的返回值,通过不管何种形式的返回值,必须要让父进程知道,自己创建的这个子进程有没有完成自己当初交代给它的任务,如果完成了要返回完成,如果没有完成要知道没有完成的原因是什么,因此就引出了进程退出的概念
对于各种操作系统来说,都有关于进程退出的一定设置,比如有用数字来代表不同的原因,比如输出0代表成功,现在进程已经运行成功了,可以正常退出了,也有1,2,3...代表多种原因
进程的错误码
根据不同的现象,进程会返回不同的退出码,那错误码又是什么呢?
**退出码:**通常是说一个进程退出的时候,它的退出结果是什么
**错误码:**通常是衡量一个库函数或者是一个系统调用一个函数的调用情况
但都是在说,当调用失败的时候,用来衡量函数或者是进程的出错的详细原因是什么
进程异常的问题
这里要介绍一个概念:进程退出异常,本质上是进程收到了对应的信号,自己终止了
例如在Linux中有kill命令,这当中的许多选项就代表这个意思,比如有段错误导致终止,也有浮点数计算错误导致终止等等…所以说,父进程如何知道子进程有没有出现异常?只需要看有没有收到对应的信号就可以了,通过看退出码和错误码就可以观察到这样的现象
进程终止
进程退出
进程退出一般有正常终止,比如说从main函数返回,或者是调用系统调用或其他函数等;也有异常调用,比如说使用Ctrl+C来进行信号终止
exit函数和_exit函数
下面做两个实验
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
printf("i am a process\n");
sleep(1);
exit(0);
}
这是一段C语言的代码,打印一句信息后休眠一秒,然后退出进程,这是没有问题的
如果将代码改成这样:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
printf("i am a process");
sleep(1);
exit(0);
}
在用户层面会看到,会休眠一秒后,再将内容打印在屏幕上,也是没有什么问题的,因为数据被存储在缓冲区中,而缓冲区刷新可以使用fflush或者是进程结束强制刷新到界面上,但是如果将代码中的退出调用改为_exit()
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
printf("i am a process");
sleep(1);
_exit(0);
}
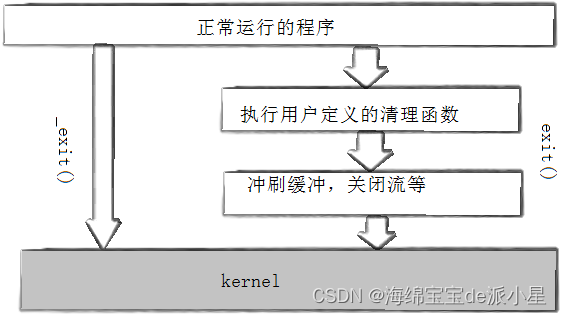
此时进程并没有将信息显示到屏幕上,而是直接结束了,这是由于_exit函数的原因,它是一个系统级别的调用,而它并没有刷新缓冲区的能力
其实从底层上看,exit函数的内部就是借助了_exit这个系统级别的调用函数,exit只是对它做了一定程度的封装,就形成了这个系统调用
进程等待
什么是进程等待?
进程等待是指通过wait/waitpid的方式,让父进程对子进程进行资源回收的等待过程
为什么要进行进程等待?
- 进程等待可以解决子进程的僵尸问题带来的内存泄漏问题
- 父进程创建子进程的目的是要让子进程完成父进程交给子进程的任务,而父进程一般而言是需要知道子进程到底把任务完成的怎么样,因此进行进程等待的另外一个作用就是要获取子进程退出的信息,也就是退出码和错误码,值得注意的是,父进程并不是一定要知道子进程的完成情况,可能在一些情况下,父进程知道子进程一定会完成这个任务,或者说父进程并不在意子进程把任务完成的怎么样,但是作为操作系统依旧应该要有提供这样信息的能力
如何进行进程等待?
对于如何进行进程等待,需要引入两个函数,一个是wait函数,一个是waitpid函数
关于wait函数:
pid_t wait(int*status);
成功返回的是被等待进程的pid,失败返回的是-1
对于参数是输出型参数,这个输出型参数可以获取的是子进程的退出状态,如果不关心可以设置为NULL
下面使用代码来进行验证wait函数的功能:
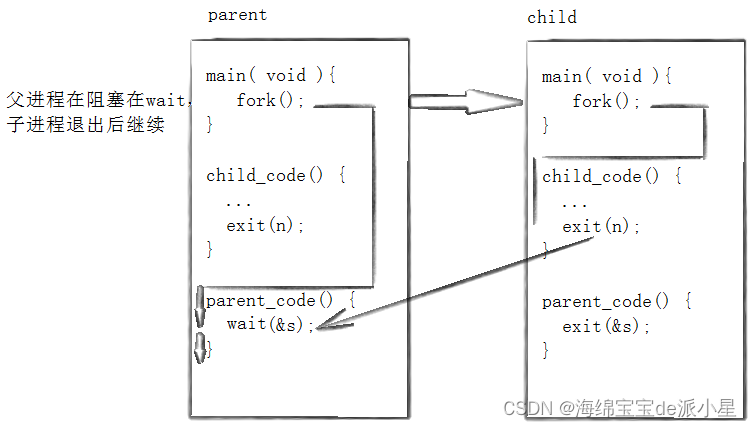
- 父进程可以回收子进程的僵尸状态
- 子进程如果不退出,父进程就必须
wait上进行阻塞等待,直到子进程僵尸,wait进行回收
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
void work()
{
int cut = 5;
while(cut)
{
printf("child process-> pid:%d ,ppid:%d ,cut:%d\n",getpid(),getppid(),cut);
cut--;
sleep(1);
}
}
int main()
{
pid_t id = fork();
if(id == 0)
{
// 子进程
work();
printf("child process exit\n");
exit(0);
}
else
{
// 父进程
sleep(8);
pid_t rid = wait(NULL);
}
sleep(100);
return 0;
}
实验结果如下所示:
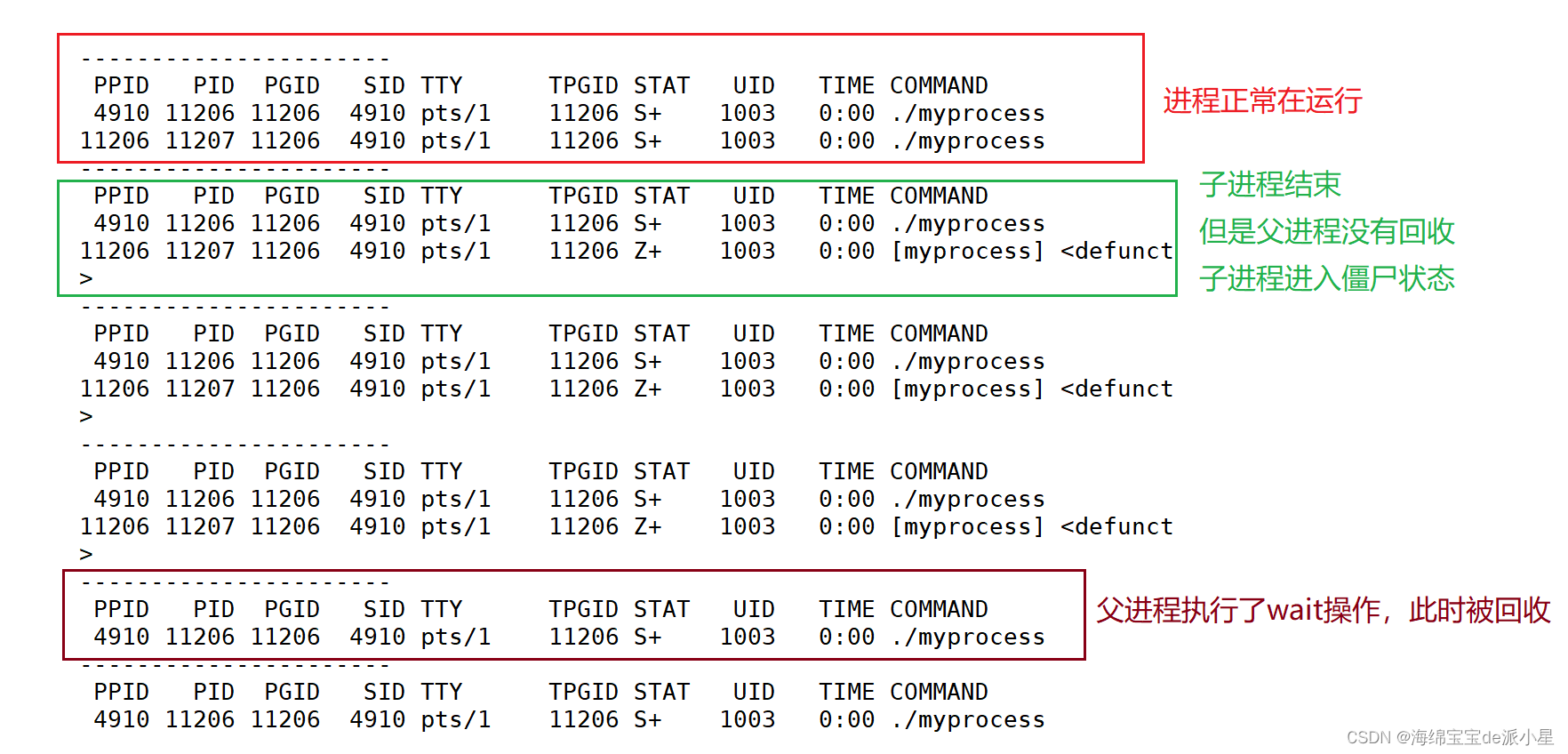
从中可以看出第一条结论,当子进程执行结束后,父进程没有及时将子进程的内容代码和数据进行回收,此时子进程会进入僵尸状态,而当父进程执行到wait函数后,父进程将子进程的代码和数据进行了回收,此时子进程就不再是僵尸状态了
下面验证第二条结论:如果子进程不退出,父进程就必须wait上进行阻塞等待,直到子进程僵尸,wait进行回收
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
void work()
{
int cut = 5;
while(cut)
{
printf("child process-> pid:%d ,ppid:%d ,cut:%d\n",getpid(),getppid(),cut);
cut--;
sleep(1);
}
}
int main()
{
pid_t id = fork();
if(id == 0)
{
// 子进程
work();
printf("child process exit\n");
exit(0);
}
else
{
// 父进程
//sleep(8);
pid_t rid = wait(NULL);
printf("wait success\n");
}
sleep(100);
return 0;
}
实验结果如下:
child process-> pid:16484 ,ppid:16483 ,cut:5
child process-> pid:16484 ,ppid:16483 ,cut:4
child process-> pid:16484 ,ppid:16483 ,cut:3
child process-> pid:16484 ,ppid:16483 ,cut:2
child process-> pid:16484 ,ppid:16483 ,cut:1
child process exit
wait success
上面两份代码数据证明了这个结论,一般而言,谁先运行不知道,但是一般来说都是父进程最后进行的退出,所以父进程会在wait上进行阻塞等待,一直到子进程变为僵尸,wait进行回收后,父进程返回
关于waitpid函数
waitpid通常是用来进行获取退出信息的函数,它的函数原型如下所示
pid_ t waitpid(pid_t pid, int *status, int options);
其中可以看出,它的函数参数有三个,分别代表着进程的pid,输出型参数,和一个选项参数,返回值的情况是,如果正常返回则收集子进程的pid,如果设置了选项后会返回0,如果在调用出错会返回-1
函数参数:
pid:
pid = -1表示等待任一一个子进程,和wait的功能是一样的pid>0表示等待的是某一个特定pid的子进程
- status:
- WIFEXITED(status): 若为正常终止子进程返回的状态,则为真。(查看进程是否是正常退出)
- WEXITSTATUS(status): 若WIFEXITED非零,提取子进程退出码。(查看进程的退出码)
- options:
WNOHANG: 若pid指定的子进程没有结束,则waitpid()函数返回0,不予以等待。若正常结束,则返回该子进程的ID
从上面做的实验中可以看出,关于wait和waitpid:
- 如果子进程已经退出,在调用这两个函数调用的时候,会立即进行返回,回收子进程的资源,获得子进程的退出信息
- 如果在任意时刻进行调用这两个函数,如果此时子进程正在进行正常运行,那么进程会进行阻塞
- 如果不存在子进程的,那么会返回报错
输出型参数:
下面进行介绍什么是输出型参数status
status在函数参数中是以指针的情况出现的,也就是说,是将一个int类型的数据传递到函数内部,函数内部将数据进行更换后就可以将数据进行输出了,下面对这个输出型参数进行实验
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
void work()
{
int cut = 5;
while(cut)
{
printf("child process-> pid:%d ,ppid:%d ,cut:%d\n",getpid(),getppid(),cut);
cut--;
sleep(1);
}
}
int main()
{
pid_t id = fork();
if(id == 0)
{
// 子进程
work();
printf("child process exit\n");
exit(1);
}
else
{
// 父进程
//sleep(8);
int status = 0;
pid_t rid = waitpid(id,&status,0);
printf("wait success,status=%d\n",status);
}
//sleep(100);
return 0;
}
输出结果为
child process-> pid:26732 ,ppid:26731 ,cut:5
child process-> pid:26732 ,ppid:26731 ,cut:4
child process-> pid:26732 ,ppid:26731 ,cut:3
child process-> pid:26732 ,ppid:26731 ,cut:2
child process-> pid:26732 ,ppid:26731 ,cut:1
child process exit
wait success,status=256
那么为什么status是256呢?status到底是什么呢?
status的组成:
wait和waitpid中都有一个status参数,这是一个输出型参数并且是由操作系统进行自动补充- 如果传递的是空指针,说明不关心子进程的进程状态退出信息
- 如果传递的是变量的地址,操作系统就会根据参数,将子进程的退出信息反馈给父进程
status并不是一个数,要把status当成一个位图来理解,下面是status的具体实现细节
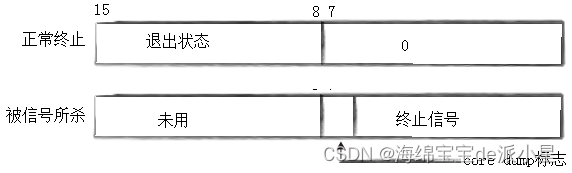
status的类型是一个int类型的数据,而int类型的数据是四个字节,占据的是32个比特位,这里研究的是低地址的16个比特位
如果子进程是被正常终止的,那么在status的位图中的后八个比特位会存储的是进程的退出状态,而如果是被信号所杀,比如说调用kill命令强行进行终止,那么就会在前七个比特位中显示出终止的信号,而第八个比特位中存储的是一个标志
这样显示出的位图status是不方便查看的,那么借助位运算,可以把前八个比特位和后八个比特位分别分开来进行计算:
前八个比特位:status & 0x7F
后八个比特位:(status >> 8) & 0xFF
因此使用下面的测试代码进行测试:
#include <sys/types.h>
#include <unistd.h>
#include <sys/wait.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
int main()
{
pid_t id = fork();
if (id == -1)
perror("fork"), exit(1);
if (id == 0)
{
sleep(20);
exit(10);
}
else
{
int st;
int ret = wait(&st);
if (ret > 0 && (st & 0X7F) == 0)
{
// 正常退出
printf("child exit code:%d\n", (st >> 8) & 0XFF);
}
else if (ret > 0)
{
// 异常退出
printf("sig code : %d\n", st & 0X7F);
}
}
}

父进程如何知道子进程的退出信息?
答案依旧是存在于进程的PCB中,当子进程要退出的时候,会修改状态Z,并且将子进程的退出信号和退出码写到它自己的PCB中,这样父进程就可以接受到信息了
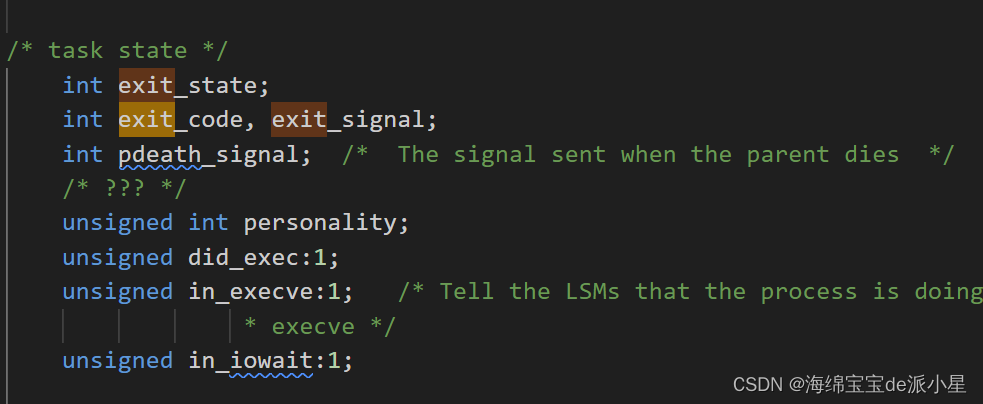
在Linux内核源码中,也有对其的详细描述
int exit_state;
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
/* ??? */
unsigned int personality;
unsigned did_exec:1;
unsigned in_execve:1; /* Tell the LSMs that the process is doing an
* execve */
unsigned in_iowait:1;
waitpid的option选项
在waitpid的函数参数中,有一个参数是option选项:
option选项有两个选项,一个是0,一个是WNOHANG,代表的分别是采用阻塞等待和非阻塞等待来进行回收资源
什么是阻塞等待和非阻塞等待?
简单来用一个场景来描述阻塞和非阻塞等待:现在父进程创建了子进程,子进程正在完成自己的任务,如果此时父进程采用的是阻塞等待,那么父进程就会卡在wait函数这里,一直阻塞着直到子进程完成了自己的任务,返回了信息,父进程接收到了返回的信息后进行了返回,这就是阻塞等待,而非阻塞等待就是,父进程不在这一直等着子进程,而是去做一些其他的事,这些事不是很耗费时间,一直等待子进程完成了自己的任务返回了一些必要的信息参数,这就是非阻塞等待
非阻塞等待往往需要进行重复的调用,好处就是,在进行进程等待的过程中,可以做一些自己的事情,不用一直进行等待
如何实现阻塞的原理?
其实所谓进程的阻塞等待,就是将进程链入到对应的进程等待的队列中,因此现在对于进程是动态的又多了一层新的理解,所谓进程的动态过程,就是进程不断的被链到不同的队列中,在被需要的时候被不停的调度,不断的从运行队列放到等待队列,再或者从等待队列调度到运行队列等等,整个过程是一个动态的过程





![[C/C++]数据结构 链表OJ题: 链表分割](https://img-blog.csdnimg.cn/e83bd78a0e484286b71df9472560503e.png)

![[动态规划] (十) 路径问题 LeetCode 174.地下城游戏](https://img-blog.csdnimg.cn/img_convert/564dbdb8c3471240feac7343a8771b57.png)