文章目录
- 索引失效案例
- 关联查询优化
- 对于左外连接
- 对于内连接
- JOIN语句原理
- 简单嵌套循环连接SNLJ
- 索引嵌套循环连接INLJ
- 块嵌套循环连接BNLJ
- Hash Join
- 子查询优化
- 排序优化
- filesort算法:双路排序和单路排序
- 分组优化
- 分页优化
- 优先考虑覆盖索引
- 索引下推ICP
- 使用条件
- 其他查询优化策略
MySQL中提高性能的最有效的方式是对数据表设计合理的索引,使用索引可以快速地定位表中的某条记录,从而提高数据库查询的速度,提高数据库的性能。如果查询时没有使用索引,查询语句就会扫描表中的所有记录,在数据量大的情况下,这样查询的速度就会很慢。
大多数情况下默认采用B+树来构建索引。
索引是否采用是由基于cost开销的优化器决定的,另外,是否使用索引跟数据库版本、数据量和数据选择度都有关系。
索引失效案例
-
全值匹配我最爱
-
最佳左前缀法则
MySQL中一个索引可以包括16个字段,它检索数据时遵守最佳左前缀匹配原则,即从联合索引的最左边字段开始匹配
用户在创建索引时,对于多列索引,过滤条件要使用索引必须按照索引建立的顺序,依次满足,一旦跳过某个字段,索引后面的字段都失效。如果查询条件中没有使用第一个字段,联合索引不会被使用 -
主键插入顺序
如果插入的主键值忽大忽小,则可能会造成页分裂和记录移位 -
计算、函数会导致索引失效 -
类型转换(自动或手动)导致索引失效 -
范围条件右边的列索引失效 -
不等于(≠或<>)索引失效 -
is null可以使用索引,
is not null索引失效 -
LIKE以通配符
%开头索引失效 -
OR前后存在非索引的列索引失效 -
数据库和表的字符集统一使用utf8mb4
关联查询优化
对于左外连接
SELECT * FROM `type` LEFT JOIN book ON type.card = book.card;
type相当于驱动表,book相当于被驱动表
如果左连接中,只能给一个字段添加索引,就要添加给被驱动表,原因是左连接左边一定都有,关键在于如何从右表搜索行。
对于内连接
由查询优化器来决定谁作为驱动表,谁作为被驱动表出现
如果表的连接条件只能有一个字段有索引,则有索引的字段所在的表会作为被驱动表
在两个表都存在索引的情况下,会选择小表作为驱动表
JOIN语句原理
简单嵌套循环连接SNLJ
索引嵌套循环连接INLJ
优化思路是减少内层表数据的匹配次数,所以要求是被驱动表上必须有索引

块嵌套循环连接BNLJ
如果被驱动表中没有索引,那么被扫描的次数太多了,IO次数也很多。
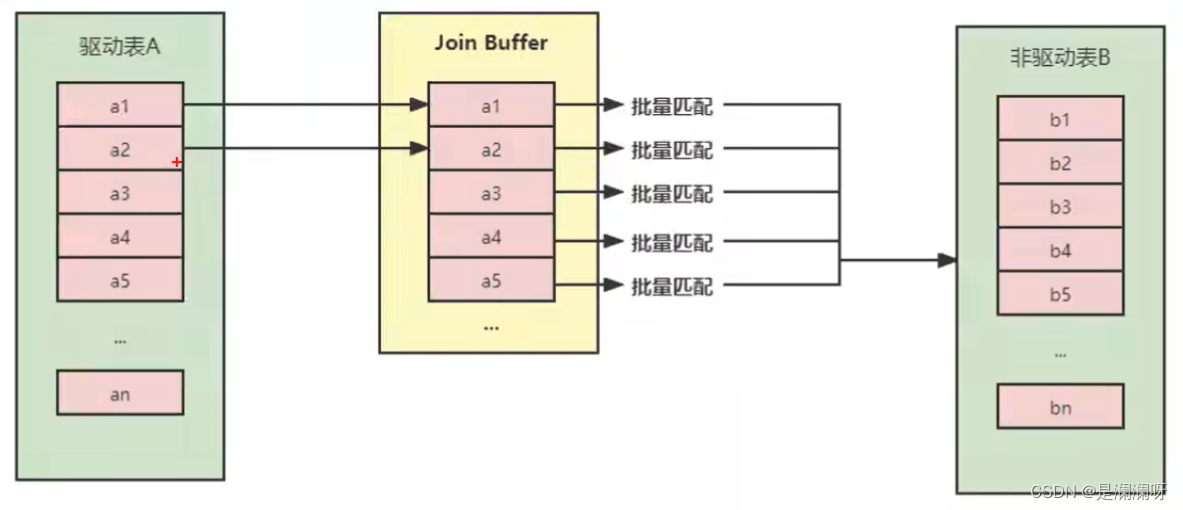
优化思路是减少被驱动表的IO次数,一块一块地获取驱动表的数据。引入join buffer缓冲区,将驱动表相关的部分数据列缓冲到join buffer中,然后全盘扫描被驱动表,被驱动表中的每一条记录一次性跟buffer中的所有驱动表记录进行匹配,降低了被驱动表的访问频率
Hash Join
是做大数据集连接时常用方式,优化器将相对较小的表在内存中建立散列值,然后扫描较大的表并探测散列值,找出与Hash表匹配的行
-
这种方式适用于较小的表完全可以放入内存中的情况,这样总成本就是访问两个表的成本之和
-
若表很大不能完全放入内存,这是优化器会将其分割成若干个不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段
-
能够很好的工作于没有索引的大表和并行查询的环境中,并提供很好的性能。
-
只能应用于等值连接,这是由hash的特点决定的
子查询优化
概念:一个SELECT查询的结果作为另一个SELECT语句的条件,使用子查询可以实现查询语句的嵌套查询
子查询的执行效率不高的原因:1.MySQL需要为内层查询语句的查询结果建立一个临时表,然后外层查询语句从临时表中查询记录,查询完毕后再撤销这些临时表。这样会消耗过多的CPU和IO资源,产生大量的慢查询
2.子查询结果集存储的临时表,不会存在索引,所以查询性能会收到影响
3.对于返回结果较大的子查询,其对查询性能的影响也就越大
使用连接查询代替子查询
SELECT * FROM student stu
WHERE stu.stuno IN (
SELECT monitor FROM class c
WHERE monitor IS NOT NULL
);
SELECT stu.* FROM student stu
JOIN class c ON stu.stuno=c.monitor
WHERE c.monitor IS NOT NULL
SELECT stu.* FROM student stu
WHERE stu.stuno NOT IN (
SELECT monitor FROM class c
WHERE monitor IS NOT NULL
);
SELECT stu.* FROM student stu
LEFT OUTER JOIN class c ON stu.stuno=c.monitor
WHERE c.monitor IS NOT NULL
排序优化
排序使用索引的原因:索引可以保证数据的有序性,效率更高,filesort排序一般在内存中进行,占用CPU较多,如果待排序结果较大,会产生临时文件IO到磁盘进行排序的情况,效率较低。
-
增加
LIMIT过滤条件索引有效 -
保证
字段顺序索引有效 -
升序降序一致或顺序全不一致索引有效
filesort算法:双路排序和单路排序
双路排序:扫描磁盘读取order列,在buffer中进行排序,再按照排序列表从磁盘中读取其他字段
单路排序:从磁盘读取所有列,在buffer中按照order进行排序,之后输出。它的效率更快一点,避免了第二次读取数据,并且把随机IO变成了顺序IO,但是他会使用更多的空间
分组优化
类似于排序优化
分页优化
-
在索引上完成排序分页操作,然后根据主键关联回原表查询所需要的其他列内容
-
将LIMIT查询转换为某个位置的查询
优先考虑覆盖索引
概念:建索引的字段覆盖了查询条件所涉及的字段。索引的叶子节点存储了所需要的数据,通过读取索引就可以得到所需数据无需回表
好处:避免进行回表;可以把随机IO变成顺序IO
弊端:索引字段的维护是有代价的
索引下推ICP
是MySQL5.6的新特性,是一种在存储引擎层使用索引过滤数据的优化方式。ICP可以减少回表的次数以及MySQL服务器访问存储引擎的次数
启用ICP后,如果WHERE条件可以使用索引中的列进行筛选,则MySQL服务器会把这部分条件使用索引条目进行筛选数据,最后才回表读取数据
使用条件
-
只能用于二级索引
-
EXPLAIN显示的执行计划中type值为range、ref、eq_ref和ref_or_null
-
只有在索引列中的WHERE条件字段才可以用ICP筛选
-
ICP可以用于MyISAM和InnoDB存储引擎
-
当SQL使用覆盖索引时,不支持ICP优化方法
-
相关子查询条件不能使用ICP
其他查询优化策略
-
EXISTS和IN的区分
SELECT * FROM A WHERE cc IN (SELECT cc FROM B),哪个表小就用哪个表来驱动,A表小就用EXISTS,B表小就用IN -
COUNT()、COUNT(1)和COUNT(具体字段)的效率
· COUNT()和COUNT(1)都是统计所有结果,本质上没有区别,如果有WHERE子句,则是对所有符合条件的数据行进行统计,如果没有WHERE子句,则是对数据表的数据行数进行统计
· 如果是MyISAM,统计数据表的行数只需要O(1)的复杂度,因为每个数据表都有一个meta信息存储了row_count值,其一致性由表级锁保证;如果是InnoDB,因为其支持事务,采用行级锁和MVCC机制,无法维护一个row_count变量,因此需要扫描全表,是O(n)的复杂度
· 在InnoDB中,如果采用COUNT(具体字段)来统计具体数据行数,尽量采用二级索引。因为聚簇索引包含的信息多。对于COUNT(*)、COUNT(1),不需要查找具体的行,只是统计行数,系统会自动采用空间更小的二级索引来统计 -
SELECT(*)
尽量不要使用**,因为需要通过查询数据字典转换为所有列名,这会耗费资源和时间;且无法使用覆盖索引 -
LIMIT 1对优化的影响
针对全盘扫描,如果确定结果集只有一条,加上LIMIT 1,扫描到一条结果就不会再扫描,这样会加快查询速度。如果对字段已经建立了唯一索引,则不会进行全盘扫描,不需要加LIMIE 1 -
多使用COMMIT
程序性能会得到提高,需求会因为COMMIT所释放的资源而减少。COMMIT所释放的资源有:回滚段上用于恢复数据的信息,被程序语句获得的锁,redo / undo log buffer中的空间,管理上述3中资源的内部花费
![[移动通讯]【Carrier Aggregation-13】【Carrier Aggregation】](https://img-blog.csdnimg.cn/aa81d55d3f7e4e5eb946ce6203561378.png)







![[科研图像处理]用matlab平替image-j,有点麻烦,但很灵活!](https://img-blog.csdnimg.cn/72dc461bc457472eae9e23816043765e.png#pic_center)