爬取股票信息
爬虫爬取信息,一般有两种大的思路,分别是:
- 模拟header信息,发送请求,得到相应的数据(html文件 或者 json数据)
- 使用selenium模拟打开浏览器,然后利用selenium提供的函数抓取网页中标签信息,从而获取到页面上的数据
本文基于第二种,即selenium,爬取东方财富的股票数据。
目标网址:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
目标数据:网页table标签中的股票信息
基础版-获取到一页股票数据
思路:
- 利用selenium加载网页
- 利用beautiful soup解析网页内容
- 利用beautiful soup,根据类名或者标签,找到存储股票信息的tbody
- 根据tr标签,找到所有的tr,一个tr代表一行数据(一只股票)
- 遍历所有的tr,并提取该行中所需要的信息,输出结果
代码如下:
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.webdriver.chrome.service import Service
#webdriver的路径
gecko_driver_path = 'geckodriver.exe'
#固定搭配直接用就行了
service = Service(executable_path=gecko_driver_path)
# 创建Chrome浏览器驱动对象
driver = webdriver.Firefox(service=service)
# driver = webdriver.Chrome(service = service)
# driver = webdriver.Firefox()
# 构建URL
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
# 发起GET请求
driver.get(url)
# 等待页面加载完成
driver.implicitly_wait(10)
# page_source,就是html文本内容
page_source = driver.page_source
# print(page_source)
# 利用BeautifulSoup解析响应内容,转化为BeautifulSoup格式,方便进一步处理
soup = BeautifulSoup(page_source, "html.parser")
# print(soup)
# 分析发现:soup和page_source内容上并没有什么不同,只是soup更为精简了,去除了很多空格
# 选取代表股票信息的table节点,返回的是一个list,代表找到的所有符合条件的tbody
res = soup.select(".table_wrapper-table tbody")
print(res)
# 经分析,发现只有一个tbody,直接取之就可
tbody = res[0]
print(tbody)
# 获取所有的行,通过寻找tr节点,返回一个list
all_rows = tbody.find_all("tr")
print(len(all_rows))
# 遍历每行数据
for row in all_rows:
# 找到本行,所有的td,即所有的列数据
columns = row.find_all("td")
# print(columns)
# 提取所需的股票信息,通过.text获取节点/标签的内容
# 序号
id = columns[0].text
# 股票代码
share_code = columns[1].text
# 股票名称
stock_name = columns[2].text
# 最新价
new_price = columns[4].text
# 涨跌幅
change_percent = columns[5].text
# 涨跌额
change_price= columns[6].text
print(id,share_code,stock_name,new_price,change_percent,change_price)
# 关闭浏览器
driver.quit()
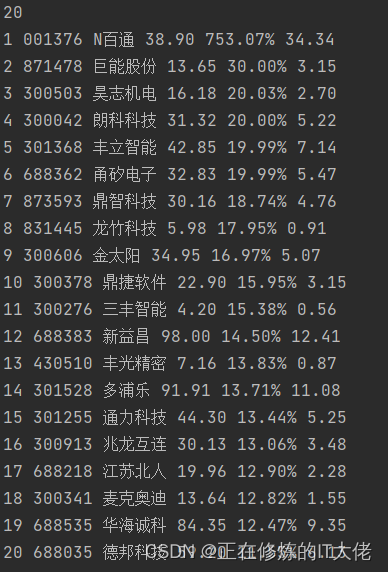
截图如下:
升级版-翻页获取所有数据并存为csv
思路:
- 模拟点击翻页
- 每读取一行数据,就将数据存到csv文件
代码如下:
import csv
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
from selenium.webdriver.chrome.service import Service
# 1、firefox浏览器配置
# 设置驱动路径
# gecko_driver_path = 'geckodriver.exe'
# service = Service(executable_path=gecko_driver_path)
# 创建Chrome浏览器驱动对象
# driver = webdriver.Firefox(service=service,options=options)
# 2、chrome浏览器配置
# 配置一些选项
chrome_driver_path = 'chromedriver.exe'
service = Service(executable_path=chrome_driver_path)
options = Options()
# 不打开浏览器,提升效率
options.add_argument("--headless")
# 禁用GPU加速,提升效率
options.add_argument("--disable-gpu")
# 创建Chrome浏览器驱动对象
driver = webdriver.Firefox(service=service,options=options)
# 构建URL
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
# 发起GET请求
driver.get(url)
# 等待页面加载完成
# 显式等待,最长等待10秒
wait = WebDriverWait(driver, 10)
# 直到表格元素可见
wait.until(EC.visibility_of_element_located((By.CSS_SELECTOR, ".table_wrapper-table")))
# 创建CSV文件
csv_file = open("股票数据.csv", "w", newline="", encoding="utf-8-sig")
writer = csv.writer(csv_file)
# 写入表头信息
writer.writerow([
'序号','股票代码','股票名称','最新价格','涨跌幅','涨跌额'
])
page_count = 0
while True:
# 强制等待:每次等待0.5秒再执行
time.sleep(0.5)
# 解析响应内容
soup = BeautifulSoup(driver.page_source, "html.parser")
# 获取股票信息表格
res = soup.select(".table_wrapper-table tbody")
tbody = res[0]
all_rows = tbody.find_all("tr")
# 遍历当前页面所有数据
for row in all_rows:
# 获取每列数据
columns = row.find_all("td")
# 提取所需的股票信息
# 序号
id = columns[0].text
# 股票代码
share_code = columns[1].text
# 股票名称
stock_name = columns[2].text
# 最新价
new_price = columns[4].text
# 涨跌幅
change_percent = columns[5].text
# 涨跌额
change_price = columns[6].text
# 写入 一行数据 至CSV文件
writer.writerow([
id,share_code,stock_name,new_price,change_percent,change_price
])
page_count += 1
print('写入第', page_count, '页')
# 查找下一页按钮
# 标签类名 class ="next paginate_button"
next_page_button = driver.find_element(By.CSS_SELECTOR, ".paginate_button.next")
print(next_page_button.text)
# 判断下一页按钮是否可点击,如果不可点击,则表示已经是最后一页
if "disabled" in next_page_button.get_attribute("class"):
break
# 点击下一页按钮
next_page_button.click()
# 等待页面加载完成
# 直到表格元素可见
wait.until(EC.visibility_of_element_located((By.CSS_SELECTOR, ".table_wrapper-table")))
# 关闭CSV文件
csv_file.close()
# 关闭浏览器
driver.quit()
代码中的技术点:
- 设置options,禁止GPU渲染
- 设置options,禁止打开浏览器
- 设置selenium时间等待策略,防止潜在的由于元素未加载完成而导致的错误
遇到的问题
问题1:缺乏驱动报错
selenium.common.exceptions.NoSuchDriverException: Message: Unable to obtain driver for chrome using Selenium Manager.; For documentation on this error, please visit: https://www.selenium.dev/documentation/webdriver/troubleshooting/errors/driver_location
网络上有多种解决方案:
**方案1:**经过研究发现,下载相应版本的浏览器、浏览器驱动,然后将驱动与python程序同文件夹下,但是并不能解决问题,还是找不到驱动。虽然无法解解决问题,但是下载相应驱动肯定是必须的一个环节。
在python中使用selenium的话,首先需要下载浏览器以及浏览器驱动,相应的资源链接如下:
- 火狐的各历史版本:Firefox各历史版本链接
- 火狐各驱动历史版本:Firefox_selenium驱动各版本
- chrome驱动的各历史版本:Chrome各历史版本
- chrome浏览器的历史版本:谷歌浏览器历史版本
- chrome驱动:https://chromedriver.chromium.org/downloads
- chrome以及驱动的 最新版本、测试版本等:https://googlechromelabs.github.io/chrome-for-testing/
备注:需要注意,驱动与浏览器需要互相匹配,前四个链接存在版本不全的问题,chrome最新版本可以从最下边的链接下载。
**方案2:**同时发现有其他博主遇到类似的问题,同样的代码,python310不行,311却可以。
其解决方法是,修改模块的源代码,具体见如下链接:
https://blog.csdn.net/qq_63401240/article/details/132406123
不过经过实践,注释掉模块中的相关代码也还是报错,依然找不到驱动。
**方案3:**有网友提出,直接指定驱动地址,最终经过验证,解决了”找不到驱动“的问题
from selenium.webdriver.chrome.service import Service
gecko_driver_path = 'C:\All\software\Anaconda\geckodriver.exe'
service = Service(executable_path=gecko_driver_path)
driver = webdriver.Firefox(service=service)
参考链接为:
https://blog.csdn.net/CcReborn/article/details/132656781
问题2:爬取过程总是中断
描述:使用不打开浏览器的方式爬取数据,爬着爬着,就会报错,每次到达的页面都不一样,每次报错的代码也不一样
分析:大概率是由于某些元素未加载完成导致的,且与电脑的网络状态存在一定关联
解决:
在每次执行相关操作前,添加等待策略,包括强制等待、隐式等待、显式等待等,发现隐式等待、显式等待不太奏效。
强制等待,每次操作之前都设置time.sleep(),最终爬取过程很顺利,没有再遇到问题。
总体来讲,遇到元素未加载完成导致的错误,可以考虑三种策略结合使用。sleep作用最强,但是有时候也最耗时。
问题3:数据重复写入
描述:有几行数据被写入两次
分析:写入CSV文件时,数据出现冲突
解决:可以考虑先把所有数据存到变量里边,最后统一写入文件(仅限于数据量比较小,不会使内存爆炸的情况)。不过该问题属于小问题,并没有去解决。
问题4:禁止GPU加速、禁止打开浏览器,仅chrome支持
描述:相关的option配置不支持firefox,暂时没有研究原因。有可能只是针对chrome的特色功能。
补充:selenium等待策略
Selenium中常用的等待时间方式有三种:
- 强制等待:time.sleep()
- 隐式等待:implicitly_wait()
- 显式等待:WebDriverWait()
强制等待
设置等待最简单的方法就是强制等待,其实就是time.sleep()方法。不管它什么情况,让程序暂停运行一定时间,时间过后继续运行。
优点:简单暴力,可以解决大多数错误。
缺点:不智能。如果设置的时间太短,元素还没有加载出来一样会报错。设置的时间太长,则会浪费时间。
隐式等待
WebDriver提供了mplicitly_wait()方法来实现隐式等待。隐式等待相当于设置全局等待,在定位元素时,对所有元素设置的超时时间。implicitly_wait()默认参数的单位为秒,默认设置超时时间为0,设置后这个隐式等待会在WebDriver对象实例的整个生命周期起作用。
优点:可以解决大部分错误
缺点:实际应用场景中,driver(浏览器)要等待的元素和脚本要操作的元素未必相同,也就是说,脚本要操作的元素已经出现,但因为设置了全局等待,driver(浏览器)也会继续等待页面上其他无关元素,直至整个页面加载完毕。所以与显式等待相比,可能会出现一些无效等待的情况。
示例:
# 等待页面加载完成,隐式等待,最长等待10秒
driver.implicitly_wait(10)
显式等待
显示等待是一种更智能的等待方式。显示等待比隐式等待更节省测试时间,个人更推荐使用显示等待的方式来判断页面元素是否出现。程序会每隔一段时间(默认为0.5秒,可自定义)执行一下判断条件,等待某个条件成立时继续执行,否则在达到最大时长抛出超时异常。
优点:智能化、节约时间
缺点:个别场景貌似无法解决问题(个别场景:比如上百页的数据需要去爬取、去点击,但是不绝对)
示例:
# 等待页面加载完成
# 显式等待,最长等待10秒
wait = WebDriverWait(driver, 10)
# 直到表格元素可见
wait.until(EC.visibility_of_element_located((By.CSS_SELECTOR, ".table_wrapper-table")))
等待策略参考链接:
https://www.cnblogs.com/wuzm/p/12421811.html
https://zhuanlan.zhihu.com/p/581883844