若要训练机器学习模型,需要数据。数据科学任务通常不是 Kaggle 竞赛,在竞赛中,你有一个很好的大型策划数据集,并预先标记。有时,您必须收集、组织和清理自己的数据。在现实世界中收集和标记数据的过程可能非常耗时、繁琐、昂贵、不准确,有时甚至很危险。此外,在这个过程结束时,你最终可能会得到你在现实世界中遇到的数据,而不一定是你在质量、多样性(例如,阶级不平衡)和数量方面想要的数据。以下是处理真实数据时可能遇到的常见问题:
- 实际数据收集和标记不可扩展
- 手动标记真实数据有时是不可能的
- 真实数据存在隐私和安全问题
- 真实数据不可编程
- 仅基于真实数据训练的模型性能不够(例如,开发速度慢)
幸运的是,这样的问题可以通过合成数据来解决。您可能想知道,什么是合成数据?合成数据可以定义为人工生成的数据,通常使用模拟真实世界过程的算法创建,从其他道路使用者的行为一直到光与表面相互作用时的行为。这篇文章介绍了真实世界数据的局限性,以及合成数据如何帮助克服这些问题并提高模型性能。
真实数据收集和标记不可扩展
对于小型数据集,通常可以收集和手动标记数据;然而,许多复杂的机器学习任务需要大量的数据集进行训练。例如,为自动驾驶汽车应用训练的模型需要从连接到汽车或无人机的传感器收集大量数据。这个数据收集过程很慢,可能需要数月甚至数年的时间。一旦收集了原始数据,就必须由人工手动标注,这也是昂贵且耗时的。此外,不能保证返回的标记数据作为训练数据是有益的,因为它可能不包含告知模型当前知识差距的示例。
标记这些数据通常涉及人工在传感器数据之上手绘标签。这是非常昂贵的,因为高薪的ML团队经常花费大量时间来确保标签是正确的,并将错误发回给标签商。合成数据的一个主要优势是您可以根据需要生成任意数量的完美标记数据。您所需要的只是一种生成高质量合成数据的方法。
用于生成合成数据的开源软件: UnrealSynth虚幻合成数据生成器
手动标记真实数据有时是不可能的

有些数据是人类无法完全解释和标记的。以下是合成数据是唯一选择的一些用例:
- 从单张图像中准确估计深度和光流
- 利用人眼不可见的雷达数据的自动驾驶应用
- 生成可用于测试人脸识别系统的深度伪造
真实数据存在隐私和安全问题

合成数据对于无法轻松获取真实数据的域中的应用程序非常有用。这包括某些类型的车祸数据和大多数具有隐私限制的健康数据(例如,电子健康记录)。近年来,医疗保健研究人员一直对使用ECG和PPG信号预测心房颤动(心律不齐)感兴趣。开发心律失常检测器不仅具有挑战性,因为这些信号的注释既繁琐又昂贵,而且还因为隐私限制。这就是为什么有研究模拟这些信号的原因之一。
需要强调的是,收集真实数据不仅需要时间和精力,而且实际上可能很危险。自动驾驶汽车等机器人应用的核心问题之一是它们是机器学习的物理应用。您不能在现实世界中部署不安全的模型,并且由于缺乏相关数据而崩溃。使用合成数据扩充数据集可以帮助模型避免这些问题。
真实数据是不可编程的

一个骑自行车的被遮挡的孩子从校车后面出现,在加州郊区风格的环境中骑自行车过马路的合成图像。
自动驾驶汽车应用通常处理相对“不常见”(相对于正常驾驶条件)的事件,例如夜间行人或骑自行车的人在路中间骑行。模型通常需要数十万甚至数百万个示例来学习场景。一个主要问题是,收集的真实世界数据在质量、多样性(例如,阶级不平衡、天气条件、位置)和数量方面可能不是您想要的。另一个问题是,对于自动驾驶汽车和机器人来说,与具有固定数据集和固定基准的传统机器学习任务不同,你并不总是知道你需要什么数据。虽然一些系统或随机地改变图像的数据增强技术是有帮助的,但这些技术可能会带来自己的问题。
这就是合成数据的用武之地。合成数据生成 API 允许您设计数据集。这些 API 可以为您节省大量资金,因为在现实世界中构建机器人和收集数据非常昂贵。尝试使用合成数据集生成生成数据并弄清楚工程原理要好得多,速度也快得多。
仅根据真实数据训练的模型性能不够

在工业中,有很多因素会影响机器学习项目在开发和生产中的可行性/性能(例如,数据采集、注释、模型训练、扩展、部署、监控、模型重新训练和开发速度)。最近,18 名机器学习工程师参加了一项访谈研究,旨在了解跨组织和应用程序(例如,自动驾驶汽车、计算机硬件、零售、广告、推荐系统等)的常见 MLOps 实践和挑战。该研究的结论之一是开发速度的重要性,它可以粗略地定义为快速原型设计和迭代想法的能力。
影响开发速度的一个因素是需要有数据来进行初始模型训练和评估,以及频繁的模型重新训练,因为模型性能会随着时间的推移而下降,这是由于数据漂移、概念漂移,甚至是训练训练服务偏差。

该研究还报告说,这种需求导致一些组织成立了一个团队来频繁标记实时数据。这既昂贵又耗时,并且限制了组织频繁重新训练模型的能力。
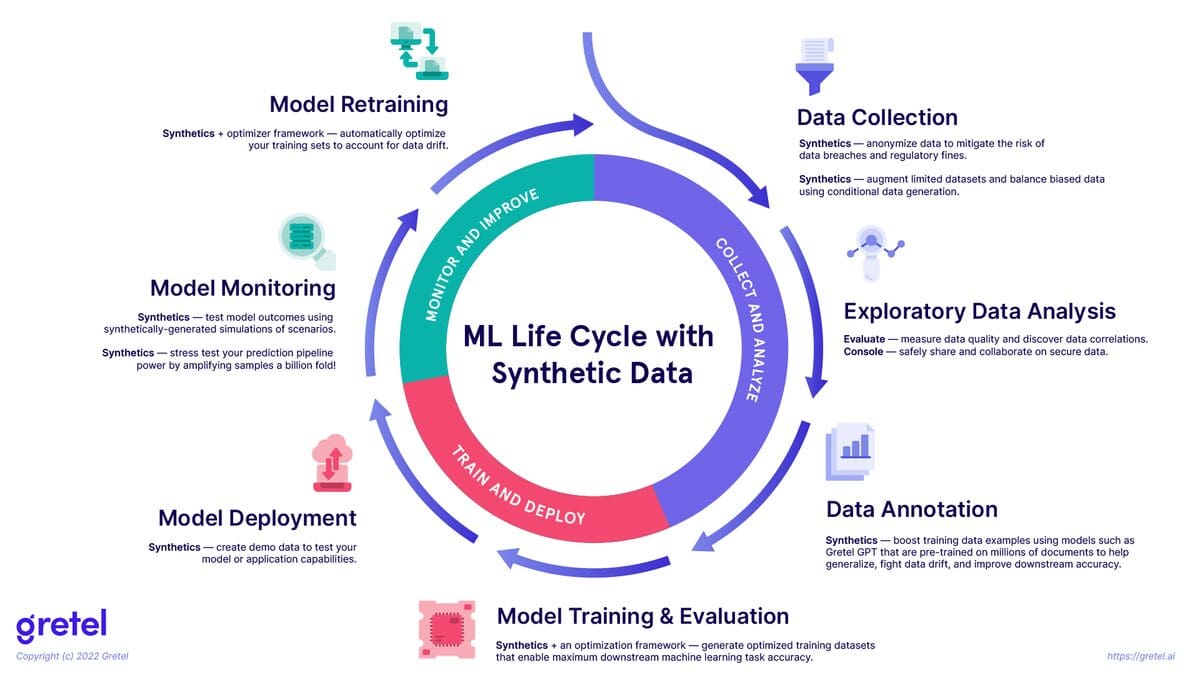
请注意,此图并未涵盖如何将合成数据也用于推荐器中的 MLOps 测试等操作。
合成数据有可能与机器学习生命周期中的真实数据一起使用(如上图所示),以帮助组织更长时间地保持其模型的性能。
结论
合成数据生成在机器学习工作流程中变得越来越普遍。事实上,Gartner 预测,到 2030 年,合成数据将比现实世界的数据更多地用于训练机器学习模型。
转载:合成数据的被需要的5 个重要原因 (mvrlink.com)