🎀 文章作者:二土电子
🌸 关注公众号获取更多资源!
🐸 期待大家一起学习交流!
文章目录
- 一、现象描述
- 1.1 在C语言中(非STM32)
- 1.2 STM32中运行
- 二、基础知识复习
- 2.1 原码、反码和补码
- 2.2 按位取反
- 2.3 有符号数与无符号数
- 三、追根溯源
- 3.1 在C语言在线编辑器中
- 3.1.1 都是char型变量
- 3.1.2 都是无符号字符型变量
- 3.2 在STM32中
- 3.2.1 STM32中char的取值范围
- 四、结案
- 4.1 原因分析
- 4.2 如何避免出现错误
- 五、问题规避
- 5.1 强制类型转换
- 5.2 在判断前先对变量进行按位取反
- 5.3 深入分析
一、现象描述
1.1 在C语言中(非STM32)
我们利用C语言的在线编程来复现一下现象。
我们首先和运行一下下面的C代码
#include <stdio.h>
int main()
{
char i = 0x00;
char j = 0xff;
if (i == ~j)
{
printf ("OK!\r\n");
}
else
{
printf ("NO!\r\n");
}
return 0;
}
点击运行后可以看到输出的内容是“OK!”。
我们再运行一下下面的C代码
#include <stdio.h>
int main()
{
unsigned char i = 0x00;
unsigned char j = 0xff;
if (i == ~j)
{
printf ("OK!\r\n");
}
else
{
printf ("NO!\r\n");
}
return 0;
}
点击运行后可以看到,输出的结果是“NO!”。这到底是为什么呢?
对比一下两段C代码,区别在于我们定义的测试变量的类型,一个是有符号,一个是无符号。有符号的字符型变量和无符号的字符型变量有什么区别呢?
1.2 STM32中运行
下面我们在STM32单片机上来复现一下现象。首先我们运行一下下面一段C代码。
int main(void) //主函数代码
{
delay_init(); //延时初始化
USART_INIT(); //串口初始化,波特率设置为115200,数据位为8,停止位为1,无校验位
while(1) //执行循环
{
u8 i = 0x5e;
u8 j = 0xa1;
if (i == ~j) // 无效判断
{
printf("OK!\r\n"); //串口打印信息 隔行打印
delay_ms(1000); //延时500ms = 0.5s
}
else
{
printf("NO!\r\n"); //串口打印信息 隔行打印
delay_ms(1000); //延时500ms = 0.5s
}
}
}
查看串口输出会发现,输出的内容是“NO!”。
即使把测试变量i和j修改成正常的char型变量,输出依旧是“NO!”,这又是为什么呢?
二、基础知识复习
看了上面的现象之后,我相信大家或多或少可能都会有些疑问,在开始探究原因之前,我们先来复习一下C语言中的一些基础知识。
2.1 原码、反码和补码
- 原码
数值X的原码记为 X 原 X_原 X原,如果机器字长为 n (即采用 n 个二进制位表示数据),则最高位是符号位,0 表示正号,1 表示负号,其余的 n-1 位表示数值的绝对值。 - 反码
数值X的反码记作 X 反 X_反 X反,如果机器字长为n,则最高位是符号位,0 表示正号,1 表示负号,其余的n -1 位表示数值。正数的反码与原码相同,负数的反码是其绝对值(数值位)按位求反。 - 补码
数值X的补码记作 X 补 X_补 X补,如果机器字长为n,最高位为符号位,0 表示正号,1 表示负号。其余的n-1位表示数值。正数的补码与其原码和反码相同,负数的补码则等于其反码的末尾加1。
值得注意的是,在计算机中,数据都是用补码来表示的。
2.2 按位取反
首先我们需要了解的是,按位取反是对补码取反的。按位取反与取反码不同,按位取反是对全部的位(包括符号位)0变1,1变0。下面我们举一个按位取反的例子来更清晰的了解一下这个过程。
另外需要注意的是,在计算机中,运算也是以补码形式进行的,但是输出的是原码。
数据7 ------ 原码 0000 0111
数据7 ------ 补码 0000 0111
数据7 ------ 按位取反 1111 1000(补码形式)
按位取反后的数据 ------ 减一 1111 0111
按位取反后的数据 ------ 求原码 1000 1000
最终结果为-8。
数据-7 ------ 原码 1000 0111
数据-7 ------ 反码 1111 1000
数据-7 ------ 补码 1111 1001
数据-7 ------ 按位取反 0000 0110
按位取反后的结果就是原码,最终结果为6。
最终结果是一个正数,正数的原码、反码和补码相同,所以最终得到的结果是0000 0110,也就是6。
我们大概总结一下如何求按位取反后的数据
- 所有正整数的按位取反是其本身+1的负数
- 所有负整数的按位取反是其本身+1的绝对值
- 零的按位取反是 -1
2.3 有符号数与无符号数
最后我们需要清楚的是,无符号数与有符号数的区别在于,无符号数全部的位都用来表示数值,而有符号数最高位用作符号位。
由于无符号数全部的位都用来表示数值,所以它能表示的范围比有符号数表示的范围更大。
| 类型 | 类型名 | 表示范围 |
|---|---|---|
| char | 字符型 | − 2 7 -2\ ^7 −2 7~ 2 7 − 1 2\ ^7 - 1 2 7−1 |
| unsigned char | 无符号字符型 | 0 0 0~ 2 8 − 1 2\ ^8 - 1 2 8−1 |
关于char型变量的更多介绍,可以移步置这篇文章中查看【C语言进阶】重新认识字符型变量,这里就不再做过多介绍了。
三、追根溯源
了解了上面的基础知识之后,下面我们就开始对上面遇到的两种现象来进行追根溯源。
3.1 在C语言在线编辑器中
我们在C语言在线编辑器中遇到的问题是测试变量定义成char和无符号的char时得到结果不同,因此我们分两种情况来看。
3.1.1 都是char型变量
我们修改一下上面的程序,增加一些输出信息。
#include <stdio.h>
int main()
{
char i = 0x5e; // 原码 0000 0000 0101 1110
// 直接按位取反 1111 1111 1010 0001
// 需要再求原码
// 先求反码 1111 1111 1010 0000
// 再求原码 1000 0000 0101 1111
char j = 0xa1; // 原码 1000 0000 0101 1111
// 先求反码 1111 1111 1010 0000
// 再求补码 1111 1111 1010 0001
// 按位取反 0000 0000 0101 1110
printf ("原始数据十进制\r\n");
printf ("%d\r\n",i);
printf ("%d\r\n",j);
printf ("原始数据十六进制\r\n");
printf ("%x\r\n",i);
printf ("%x\r\n",j);
printf ("-------------分割线------------\r\n");
printf ("按位取反后十进制结果\r\n");
printf ("%d\r\n",~i);
printf ("%d\r\n",~j);
printf ("按位取反后十六进制结果\r\n");
printf ("%x\r\n",~i);
printf ("%x\r\n",~j);
printf ("-------------分割线------------\r\n");
if (i == ~j)
{
printf ("OK!\r\n");
}
else
{
printf ("NO!\r\n");
}
return 0;
}
输出结果如下
原始数据十进制
94
-95
原始数据十六进制
5e
ffffffa1
-------------分割线------------
按位取反后十进制结果
-95
94
按位取反后十六进制结果
ffffffa1
5e
-------------分割线------------
OK!
通过注释中的求解过程和中间添加的打印信息,我们很容易能理解为什么最终的结果是OK。我们着重看一下当测试变量定义为无符号字符型变量时到底是一种什么情况。
3.1.2 都是无符号字符型变量
首先运行下面一段C代码。
#include <stdio.h>
int main()
{
unsigned char i = 0x5e; // 原码 0000 0000 0101 1110
// 直接按位取反 1111 1111 1010 0001
unsigned char j = 0xa1; // 原码 0000 0000 1010 0001
// 直接按位取反 1111 1111 0101 1110
printf ("原始数据十进制\r\n");
printf ("%d\r\n",i);
printf ("%d\r\n",j);
printf ("原始数据十六进制\r\n");
printf ("%x\r\n",i);
printf ("%x\r\n",j);
printf ("-------------分割线------------\r\n");
printf ("按位取反后十进制结果\r\n");
printf ("%d\r\n",~i);
printf ("%d\r\n",~j);
printf ("按位取反后十六进制结果\r\n");
printf ("%x\r\n",~i);
printf ("%x\r\n",~j);
printf ("-------------分割线------------\r\n");
if (i == ~j)
{
printf ("OK!\r\n");
}
else
{
printf ("NO!\r\n");
}
return 0;
}
看一下串口输出结果
原始数据十进制
94
161
原始数据十六进制
5e
a1
-------------分割线------------
按位取反后十进制结果
-95
-162
按位取反后十六进制结果
ffffffa1
ffffff5e
-------------分割线------------
NO!
我们发现,我们定义的是无符号数,输出结果反而有符号,这是为什么呢?其实上面已经介绍了,在计算机中,运算是以补码的形式进行的,但是在输出时,是按照原码输出的。在printf准备输出时,认为按位取反后的数据是负数,对其进行了求原码的操作,所以最终printf输出的十进制是有符号的负数。但是我们看输出的十六进制结果,发现实际只进行了一步直接取反的操作,最终在进行判断时还是按照补码进行的,因此并不满足下面if的判断成立条件。
3.2 在STM32中
下面我们就来看一下在STM32中,为什么即使我们定义的是char类型变量,依旧无法正常判断呢?我们还是按照上面的方法,给之前的程序增加一些输出信息。
int main(void) //主函数代码
{
delay_init(); //延时初始化
USART_INIT(); //串口初始化,波特率设置为115200,数据位为8,停止位为1,无校验位
while(1) //执行循环
{
char i = 0x5e;
char j = 0xa1;
printf ("原始数据十进制\r\n");
printf ("%d\r\n",i);
printf ("%d\r\n",j);
printf ("原始数据十六进制\r\n");
printf ("%x\r\n",i);
printf ("%x\r\n",j);
printf ("-------------分割线------------\r\n");
printf ("按位取反后十进制结果\r\n");
printf ("%d\r\n",~i);
printf ("%d\r\n",~j);
printf ("按位取反后十六进制结果\r\n");
printf ("%x\r\n",~i);
printf ("%x\r\n",~j);
printf ("-------------分割线------------\r\n");
if (i == ~j) // 无效判断
{
printf("OK!\r\n"); //串口打印信息 隔行打印
delay_ms(1000); //延时500ms = 0.5s
}
else
{
printf("NO!\r\n"); //串口打印信息 隔行打印
delay_ms(1000); //延时500ms = 0.5s
}
}
}
我们看一下串口的输出结果。

从串口的输出结果来看,虽然我们定义的测试变量是一个char型变量,但是我们发现,STM32在进行处理时,竟然把全部的8位都用来表示数据!也就是说,在STM32中,在STM32中char类型变量的取值范围不是我们上面所说的 − 2 7 -2\ ^7 −2 7~ 2 7 − 1 2\ ^7 - 1 2 7−1?或者说我们的两个测试变量全部被当成无符号进行处理了嘛?
3.2.1 STM32中char的取值范围
下面来验证我们的猜测,在STM32中char类型变量的取值范围到底是不是上面所说的 − 2 7 -2\ ^7 −2 7~ 2 7 − 1 2\ ^7 - 1 2 7−1。这个很容易编写程序通过串口输出来测试,例程就不再给出了。最终你会发现,在STM32中,char类型变量的取值范围是-256~255。
四、结案
4.1 原因分析
在发现上面的问题后,博主观察了在定义字符型变量时的汇编代码,发现不管有没有超出正常范围,实际汇编代码是完全一样的。

至此,博主其实并未发现最根本的原因,目前猜测是Keil自身的原因导致的。小伙伴们有兴趣的可以继续追查此案,博主这里就不再继续了,如果查到结果,还请在评论区指教一二。
4.2 如何避免出现错误
我们既然发现了问题,那么在以后的使用过程中就需要对这个问题进行规避。个人认为分为以下两种情况
- char类型变量只用作数值
比如我只用char类型变量来记数或者只用作标志位,这些都是不需要考虑上面的问题的,但是注意取值范围是-256~255。 - char类型变量进行按位取反判断
此时就需要注意我们上面描述的问题了。
五、问题规避
5.1 强制类型转换
我们在进行按位取反判断时,具体要怎么避免出现上面的问题呢?答案是强制类型转换。我们可以将if改写成以下形式,增加一个强制类型转换。
if (i == (char)~j) // 有效判断
{
printf("OK!\r\n"); //串口打印信息 隔行打印
delay_ms(1000); //延时500ms = 0.5s
}
else
{
printf("NO!\r\n"); //串口打印信息 隔行打印
delay_ms(1000); //延时500ms = 0.5s
}
这样我们最终的判断结果是OK。
5.2 在判断前先对变量进行按位取反
我们在进行if判断时先对变量进行按位取反,再进行判断,也是可以规避上面的问题的。
char i = 0x5e;
char j = 0xa1;
j = ~j;
if (i == j) // 有效判断
{
printf("OK!\r\n"); //串口打印信息 隔行打印
delay_ms(1000); //延时500ms = 0.5s
}
else
{
printf("NO!\r\n"); //串口打印信息 隔行打印
delay_ms(1000); //延时500ms = 0.5s
}
5.3 深入分析
我们上面给出了两种规避方法,可是这两种方法相比之前的程序,到底哪里不同呢?我们从汇编的角度来看一下
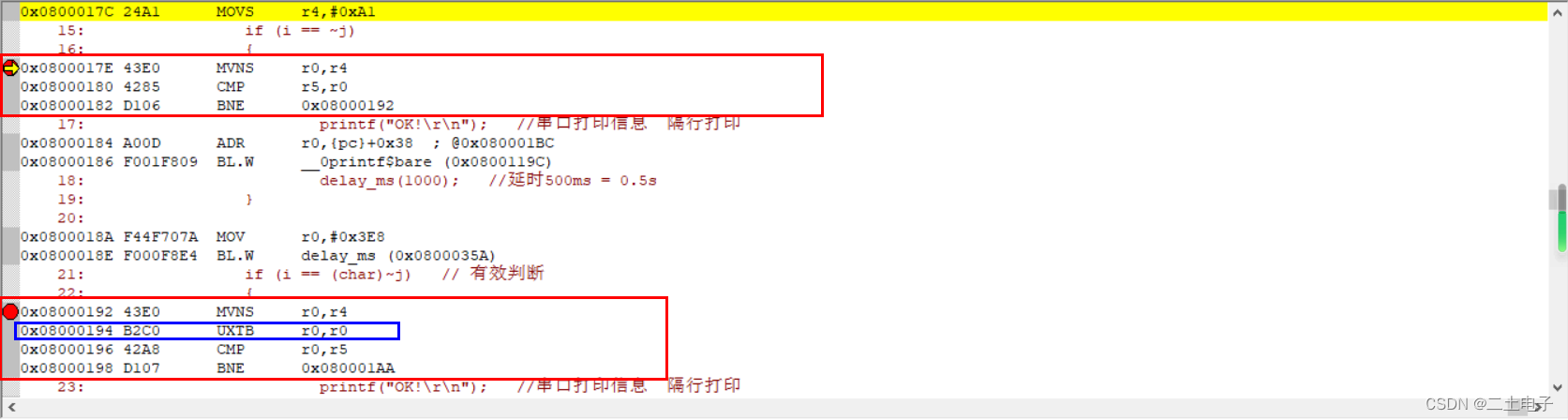
我们可以看到,if里面加前后置类型转换之后,相比没加强制类型转换实际多出了一条将4个字节的其中一个字节提取出来,然后转成一个新的32位整型的汇编指令UXTB。
我们再看一下如果先转换再判断,是不是也是多了一个强制类型转换的操作,只是他在汇编层面我们没有看出来?
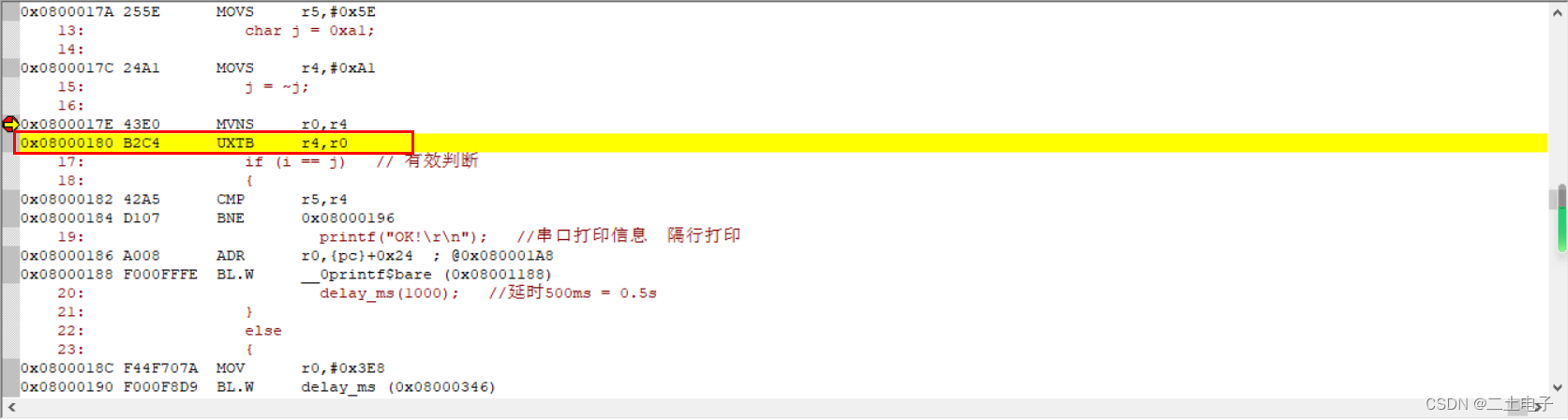
事实证明,我们的猜测是对的,我们直接在if外面进行按位取反时,实际也有一步强制类型转换,只是在C语言层面我们没看出来而已。