Pandas数据分析进阶
- 第1关 Pandas 分组聚合
- 第2关 Pandas 创建透视表和交叉表
第1关 Pandas 分组聚合
任务描述
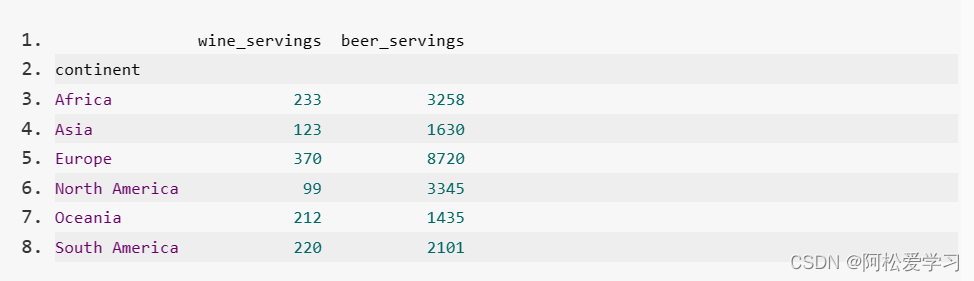
本关任务:使用 Pandas 加载 drinks.csv 文件中的数据,根据数据信息求每个大洲红酒消耗量的最大值与最小值的差以及啤酒消耗量的和。
编程要求
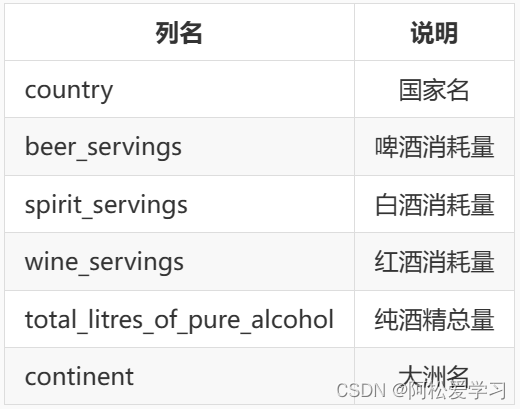
使用 Pandas 中的 read_csv() 函数读取 step1/drinks.csv 中的数据,数据的列名如下表所示,请根据 continent 分组并求每个大洲红酒消耗量的最大值与最小值的差以及啤酒消耗量的和。在右侧编辑器 Begin-End 内补充代码。
测试说明
平台会对你编写的代码进行测试:
测试输入:无;
预期输出:
开始你的任务吧,祝你成功!
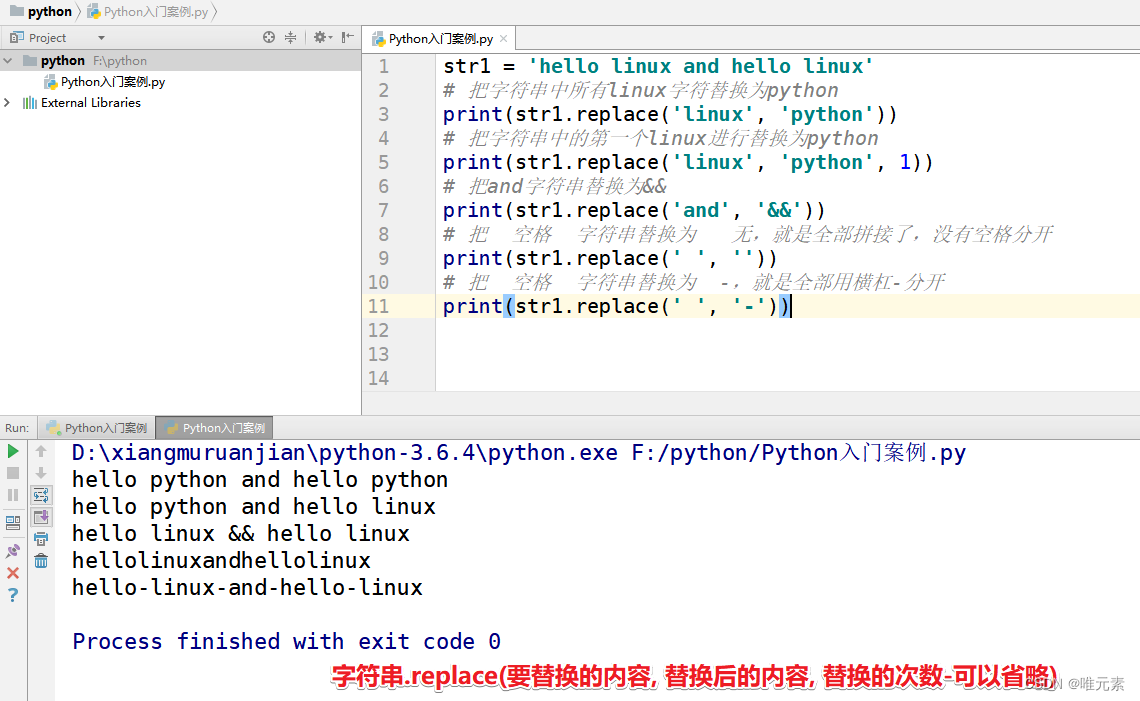
import pandas as pd
import numpy as np
#返回最大值与最小值的差
def sub(df):
######## Begin #######
return df.max()-df.min()
######## End #######
def main():
######## Begin #######
data = pd.read_csv("step1/drinks.csv",header = 0)
df = pd.DataFrame(data)
mapping = {"wine_servings":sub,"beer_servings":np.sum}
print(df.groupby("continent").agg(mapping))
######## End #######
if __name__ == '__main__':
main()
第2关 Pandas 创建透视表和交叉表
任务描述
本关任务:使用 Pandas 加载 tip.csv 文件中的数据集,分别用透视表和交叉表统计顾客在每种用餐时间、每个星期下的小费总和情况。
编程要求
使用 Pandas 中的 read_csv 函数加载 step2/tip.csv 文件中的数据集,分别用透视表和交叉表统计顾客在每种用餐时间(time) 、每个星期下(day) 的 小费(tip)总和情况。在右侧编辑器 Begin-End 内补充代码。
数据集列名信息如下表:
测试说明
平台会对你编写的代码进行测试:
测试输入:无;
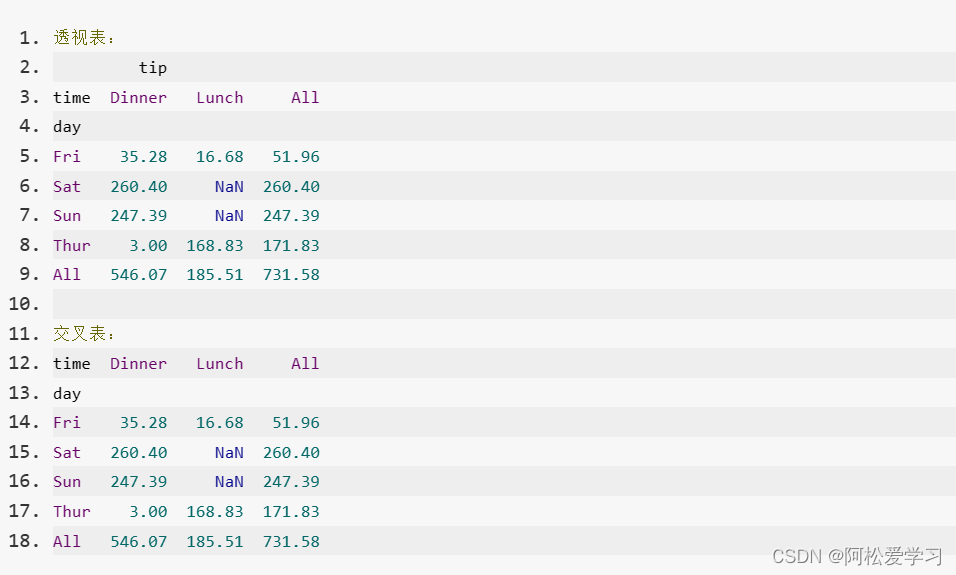
预期输出:
开始你的任务吧,祝你成功!
#-*- coding: utf-8 -*-
import pandas as pd
#创建透视表
def create_pivottalbe(data):
###### Begin ######
df = pd.DataFrame(data)
x = df.pivot_table(index = ['day'],columns = ['time'],values = ['tip'],aggfunc = sum , margins = True)
return x
###### End ######
#创建交叉表
def create_crosstab(data):
###### Begin ######
df = pd.DataFrame(data)
y = pd.crosstab(index = df['day'],columns = df['time'],values = df['tip'],aggfunc =sum,margins = True)
return y
###### End ######
def main():
#读取csv文件数据并赋值给data
###### Begin ######
data = pd.read_csv("step2/tip.csv",header = 0)
###### End ######
piv_result = create_pivottalbe(data)
cro_result = create_crosstab(data)
print("透视表:\n{}".format(piv_result))
print("交叉表:\n{}".format(cro_result))
if __name__ == '__main__':
main()