摘要
V3Det:一个庞大的词汇视觉检测数据集,在大量真实世界图像上具有精确注释的边界框,其包含13029个类别中的245k个图像(比LVIS大10倍),数据集已经开源!
图片的数量比COCO多一些,类别种类比较多!数据集大小由33G,数据集标注格式和COCO一致!
论文链接:https://arxiv.org/abs/2304.03752
这个数据集最大的特点就是类别多,还有些千奇百怪不可描述的图片!

下载V3Det的标注文件
官方提供了两种下载方式,见:https://v3det.openxlab.org.cn/download
第一种,点击左侧的链接,将其中的文件都下载下来!
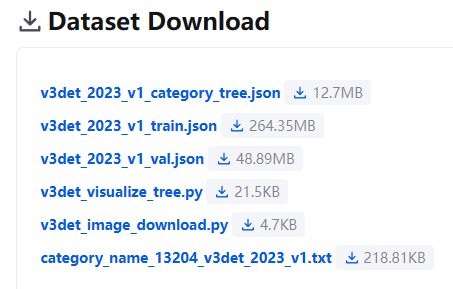
v3det_2023_v1_train.json和v3det_2023_v1_val.json是数据集!
v3det_image_download.py是下载图片的脚本。
category_name_13204_v3det_2023_v1.txt 是类别!
第二种下载方式如下:
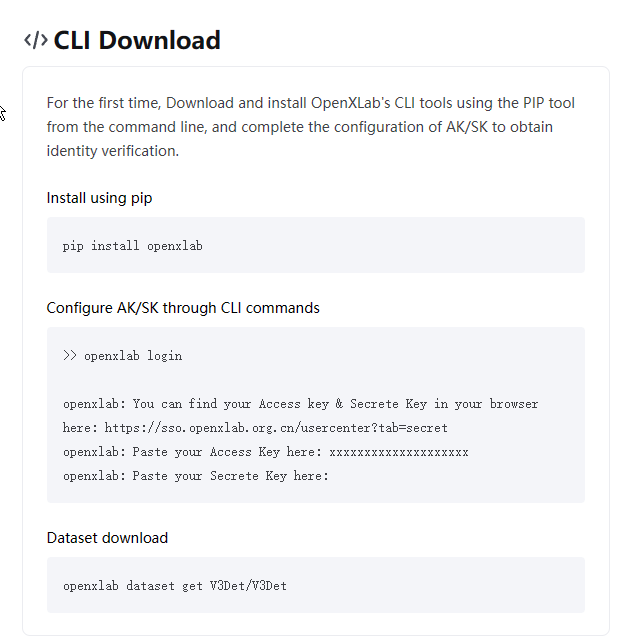
采用命令行,注册后输入密钥就能下载!下载下来的文件和第一种下载方式的文件一样,都没有图像,只能运行脚本下载图片!
下载图片的脚本
由于总所周知的原因不太好链接,多试几次,总有成功的时候。
import io
import argparse
import concurrent.futures
import json
import os
import time
import urllib.error
import urllib.request
from tqdm import tqdm
parser = argparse.ArgumentParser()
parser.add_argument("--output_folder", type=str, default="V3Det")
parser.add_argument("--max_retries", type=int, default=3)
parser.add_argument("--max_workers", type=int, default=16)
args = parser.parse_args()
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'}
def cache(response):
f = io.BytesIO()
block_sz = 8192
while True:
buffer = response.read(block_sz)
if not buffer:
break
f.write(buffer)
return f
def download_image(url, path, timeout):
result = {
"status": "",
"url": url,
"path": path,
}
cnt = 0
while True:
try:
response = urllib.request.urlopen(urllib.request.Request(url=url, headers=headers), timeout=timeout)
image_path = os.path.join(args.output_folder, path)
os.makedirs(os.path.dirname(image_path), exist_ok=True)
f = cache(response)
with open(image_path, "wb") as fp:
fp.write(f.getvalue())
result["status"] = "success"
except Exception as e:
if not isinstance(e, urllib.error.HTTPError):
cnt += 1
if cnt <= args.max_retries:
continue
if isinstance(e, urllib.error.HTTPError):
result["status"] = "expired"
else:
result["status"] = "timeout"
break
return result
def main():
start = time.time()
if os.path.exists(args.output_folder) and os.listdir(args.output_folder):
try:
c = input(
f"'{args.output_folder}' already exists and is not an empty directory, continue? (y/n) "
)
if c.lower() not in ["y", "yes"]:
exit(0)
except KeyboardInterrupt:
exit(0)
if not os.path.exists(args.output_folder):
os.makedirs(args.output_folder)
image_folder_path = os.path.join(args.output_folder, "images")
record_path = os.path.join(args.output_folder, "records.json")
record = {'success': [], 'expired': [], 'timeout': []}
if os.path.isfile(record_path):
try:
with open(record_path, encoding="utf8") as f:
record['success'] = json.load(f)['success']
except:
pass
if not os.path.exists(image_folder_path):
os.makedirs(image_folder_path)
list_url = 'https://raw.githubusercontent.com/V3Det/v3det_resource/main/resource/download_list.txt'
response = urllib.request.urlopen(urllib.request.Request(url=list_url, headers=headers), timeout=100)
url_list = [url for url in response.read().decode('utf-8').split('\n') if len(url) > 0]
image2url = {}
for url in url_list:
response = urllib.request.urlopen(urllib.request.Request(url=url, headers=headers), timeout=100)
image2url.update(eval(response.read().decode('utf-8')))
data = []
rec_suc = set(record['success'])
for image, url in image2url.items():
if image not in rec_suc:
data.append((url, image))
with tqdm(total=len(data)) as pbar:
with concurrent.futures.ThreadPoolExecutor(max_workers=args.max_workers) as executor:
# Submit up to `chunk_size` tasks at a time to avoid too many pending tasks.
chunk_size = min(5000, args.max_workers * 500)
for i in range(0, len(data), chunk_size):
futures = [
executor.submit(download_image, url, path, 10)
for url, path in data[i: i + chunk_size]
]
for future in concurrent.futures.as_completed(futures):
r = future.result()
record[r["status"]].append(r["path"])
pbar.update(1)
with open(record_path, "w", encoding="utf8") as f:
json.dump(record, f, indent=2)
end = time.time()
print(f"consuming time {end - start:.1f} sec")
print(f"{len(record['success'])} images downloaded.")
print(f"{len(record['timeout'])} urls failed due to request timeout.")
print(f"{len(record['expired'])} urls failed due to url expiration.")
if len(record['success']) == len(image2url):
os.remove(record_path)
print('All images have been downloaded!')
else:
print('Please run this file again to download failed image!')
if __name__ == "__main__":
main()
V3Det转Yolo
V3Det的标注文件和COCO是一致的!
import json
import os
import shutil
from pathlib import Path
import numpy as np
from tqdm import tqdm
def make_folders(path='../out/'):
# Create folders
if os.path.exists(path):
shutil.rmtree(path) # delete output folder
os.makedirs(path) # make new output folder
os.makedirs(path + os.sep + 'labels') # make new labels folder
os.makedirs(path + os.sep + 'images') # make new labels folder
return path
def convert_coco_json(json_dir='./image_1024/V3Det___V3Det/raw/v3det_2023_v1_val.json',out_dir=None):
# fn_images = 'out/images/%s/' % Path(json_file).stem.replace('instances_', '') # folder name
os.makedirs(out_dir,exist_ok=True)
# os.makedirs(fn_images,exist_ok=True)
with open(json_dir) as f:
data = json.load(f)
print(out_dir)
# Create image dict
images = {'%g' % x['id']: x for x in data['images']}
# Write labels file
for x in tqdm(data['annotations'], desc='Annotations %s' % json_dir):
if x['iscrowd']:
continue
img = images['%g' % x['image_id']]
h, w, f = img['height'], img['width'], img['file_name']
file_path='coco/'+out_dir.split('/')[-2]+"/"+f
# The Labelbox bounding box format is [top left x, top left y, width, height]
box = np.array(x['bbox'], dtype=np.float64)
box[:2] += box[2:] / 2 # xy top-left corner to center
box[[0, 2]] /= w # normalize x
box[[1, 3]] /= h # normalize y
if (box[2] > 0.) and (box[3] > 0.): # if w > 0 and h > 0
with open(out_dir + Path(f).stem + '.txt', 'a') as file:
file.write('%g %.6f %.6f %.6f %.6f\n' % (x['category_id'] - 1, *box))
convert_coco_json(json_dir='./image_1024/V3Det___V3Det/raw/v3det_2023_v1_val.json',out_dir='out/labels/val/')
convert_coco_json(json_dir='./image_1024/V3Det___V3Det/raw/v3det_2023_v1_train.json',out_dir='out/labels/train/')
复制图片到指定目录
将图片放到和Label同级的images文件夹
import glob
import os
import shutil
image_paths = glob.glob('V3Det/images/*/*.jpg')
dir_imagepath = {}
for image_path in image_paths:
image_key = image_path.replace('\\', '/').split('/')[-1].split('.')[0]
dir_imagepath[image_key] = image_path
os.makedirs('out/images/train',exist_ok=True)
os.makedirs('out/images/val',exist_ok=True)
def txt_2_image(txt_dir='out/labels/train/', out_path='out/images/train'):
txt_paths = glob.glob(txt_dir + '*.txt')
for txt in txt_paths:
txt_key = txt.replace('\\', '/').split('/')[-1].split('.')[0]
if txt_key in dir_imagepath:
image_path = dir_imagepath[txt_key]
shutil.copy(image_path, out_path)
else:
os.remove(txt)
txt_2_image(txt_dir='out/labels/train/', out_path='out/images/train')
txt_2_image(txt_dir='out/labels/val/', out_path='out/images/val')
生成类别
找到类别文件,生成YoloV5或V8的类别格式,如下图:
代码如下:
with open('image_1024/V3Det___V3Det/raw/category_name_13204_v3det_2023_v1.txt','r') as files:
list_class=files.readlines()
for i, c in enumerate(list_class):
print(str(i)+": "+c.replace('\n',''))
将生成的类别复制到YoloV8或者V5的数据集配置文件中!
总结
这个数据集比COCO数据集大一些,种类更加丰富,可以使用这个数据集训练,做预训练权重!
经测验,使用V3Det训练的模型做预训练权重,训练COCO可以提升1MAp!