文章目录
- 什么是Flume
- Flume的特性
- Flume高级应用场景
- Flume的三大核心组件
- Source:数据源
- channel
- sink
- Flume安装部署
- Flume的使用
- 案例:采集文件内容上传至HDFS
- 案例:采集网站日志上传至HDFS
- 各种自定义组件
- 例如:自定义source
- 例如:自定义sink
- Flume优化
- Flume进程监控
什么是Flume
Flume是一个高可用,高可靠,分布式的海量日志采集、聚合和传输的系统,能够有效的收集、聚合、移动大量的日志数据。其实通俗一点来说就是Flume是一个很靠谱,很方便、很强的日志采集工具。他是目前大数据领域数据采集最常用的一个框架。为什么它这么香呢?
主要是因为使用Flume采集数据不需要写一行代码,注意是一行代码都不需要,只需要在配置文件中随便写几行配置Flume就会死心塌地的给你干活了
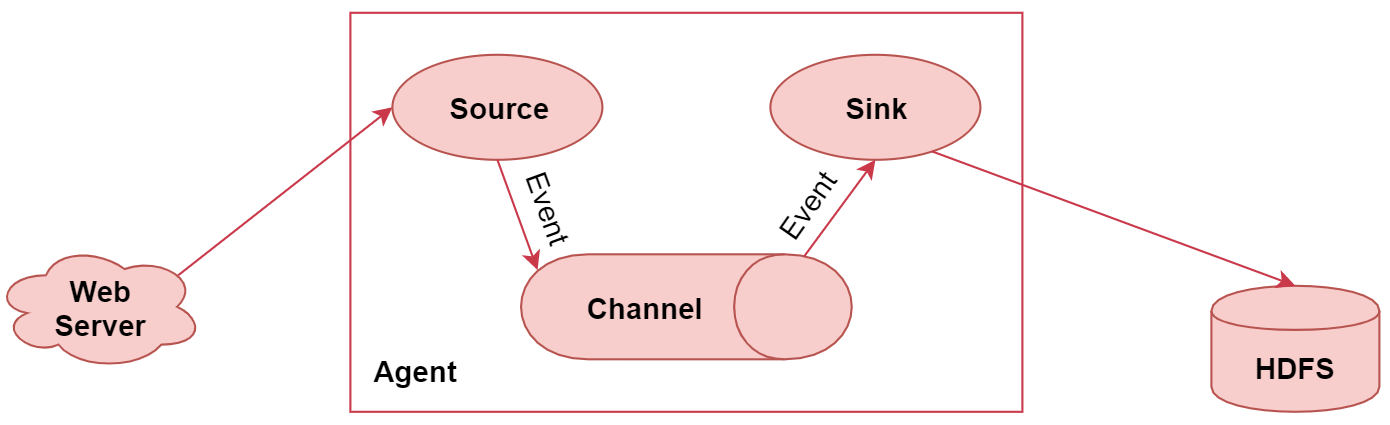
这个属于Flume的一个非常典型的应用场景,使用Flume采集数据,最终存储到HDFS上。
左边的web server表示是一个web项目,web项目会产生日志数据,通过中间的Agent把日志数据采集到HDFS中。其中这个Agent就是我们使用Flume启动的一个代理,它是一个持续传输数据的服务,数据在Agent内部的这些组件之间传输的基本单位是Event
从图中可以看到,Agent是由Source、Channel、Sink这三大组件组成的,这就是Flume中的三大核心组件,其中source是数据源,负责读取数据。channel是临时存储数据的,source会把读取到的数据临时存储到channel中。sink是负责从channel中读取数据的,最终将数据写出去,写到指定的目的地中
Flume的特性
- 它有一个简单、灵活的基于流的数据流结构,这个其实就是刚才说的Agent内部有三大组件,数据通过这三大组件流动的
- 具有负载均衡机制和故障转移机制
- 一个简单可扩展的数据模型(Source、Channel、Sink),这几个组件是可灵活组合的
Flume高级应用场景
下面这个图里面主要演示了Flume的多路输出,就是可以将采集到的一份数据输出到多个目的地中,不同目的地的数据对应不同的业务场景
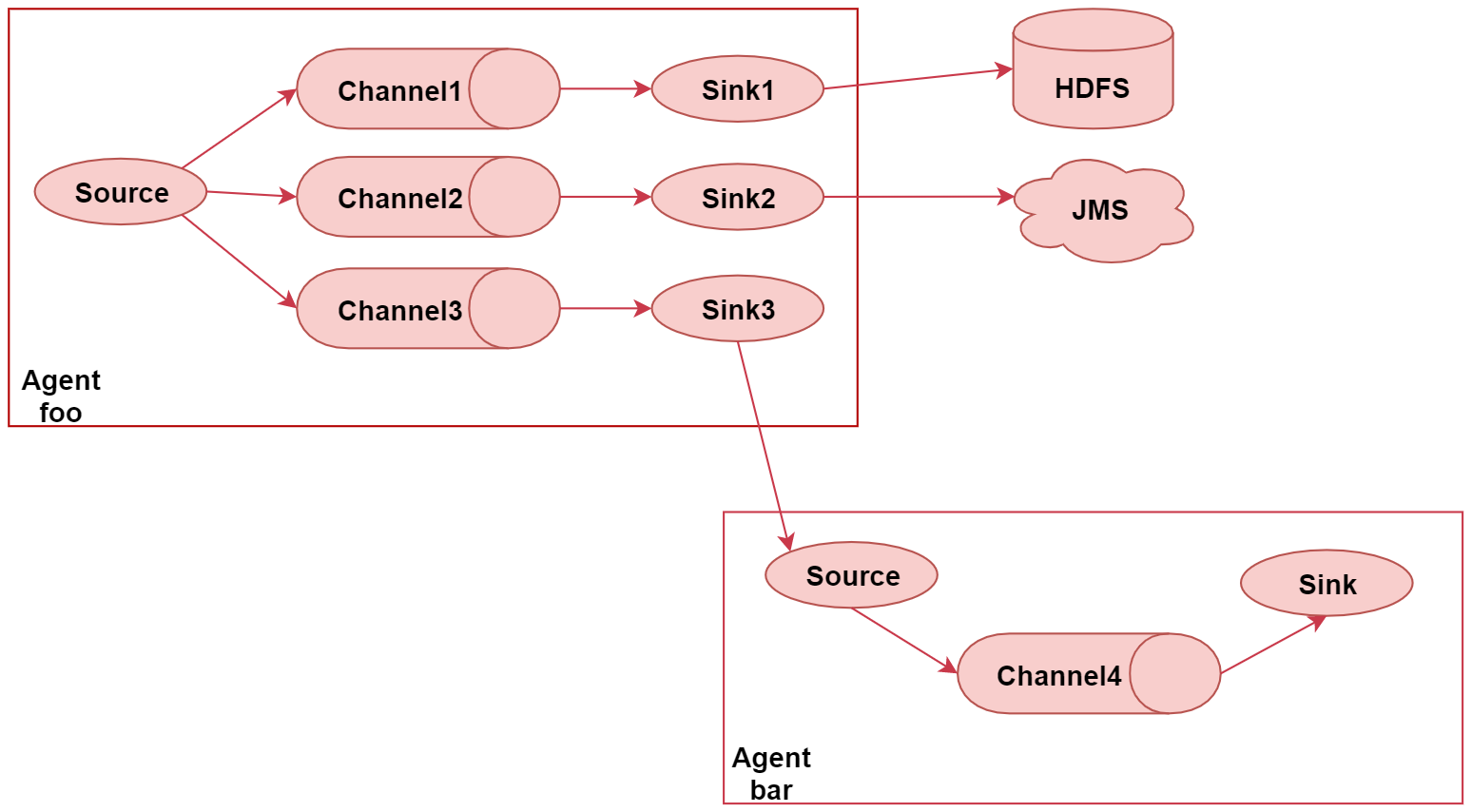
这个图里面一共有两个Agent,表示我们启动了2个Flume的代理,或者可以理解为了启动了2个flume的进程。首先看左边这个agent,给他起个名字叫 foo,这里面有一个source,source后面接了3个channel,表示source读取到的数据会重复发送给每个channel,每个channel中的数据都是一样的。针对每个channel都接了一个sink,这三个sink负责读取对应channel中的数据,并且把数据输出到不同的目的地,
sink1负责把数据写到hdfs中
sink2负责把数据写到一个Java消息服务数据队列中
sink3负责把数据写给另一个Agent
注意了,Flume中多个Agent之间是可以连通的,只需要让前面Agent的sink组件把数据写到下一个Agent的source组件中即可。
所以sink3就把数据输出到了Agent bar中。在Agent bar中同样有三个组件,source组件其实就获取到了sink3发送过来的数据,然后把数据临时存储到自己的channel4中,最终再通过sink组件把数据写到其他地方。这就是这个场景的应用,把采集到的一份数据重复输出到不同的目的地中。
下面这张图,这张图主要表示了flume的汇聚功能,就是多个Agent采集到的数据统一汇聚到一个Agent
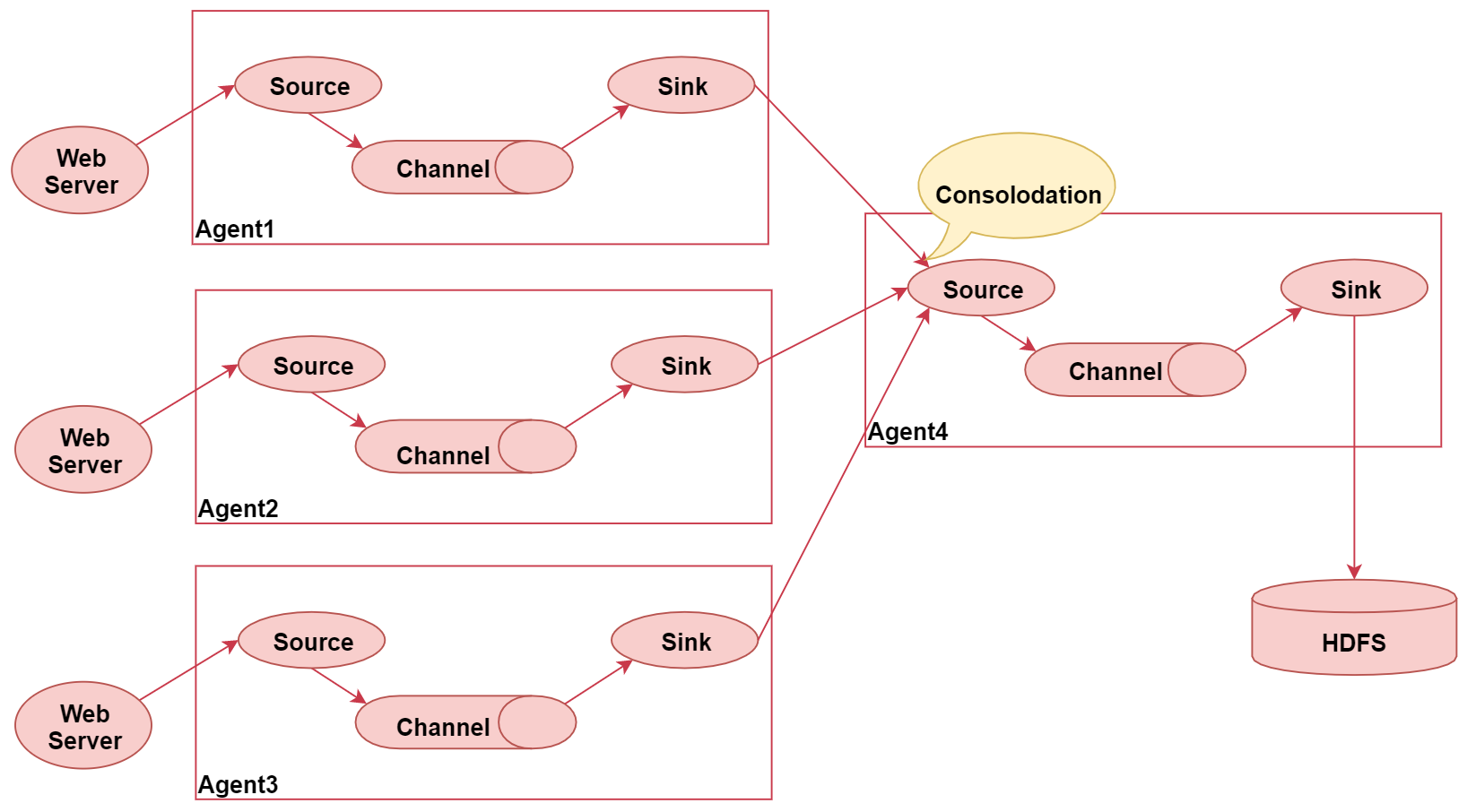
这个图里面一共启动了四个agent,左边的三个agent都是负责采集对应web服务器中的日志数据,数据采集过来之后统一发送给agent4,最后agent4进行统一汇总,最终写入hdfs。
这种架构的好处是后期如果要修改最终数据的输出目的地,只需要修改agent4中的sink即可,不需要修改agent1、2、3。但是这种架构也有弊端,
- 如果有很多个agent同时向agent4写数据,那么agent4会出现性能瓶颈,导致数据处理过慢
- 这种架构还存在单点故障问题,如果agent4挂了,那么所有的数据都断了。
不过这些问题可以通过flume中的负载均衡和故障转移机制解决
Flume的三大核心组件
- Source:数据源
- Channel:临时存储数据的管道
- Sink:目的地
接下来具体看一下这三大核心组件都是干什么的
Source:数据源
Source:数据源:通过source组件可以指定让Flume读取哪里的数据,然后将数据传递给后面的channel
Flume内置支持读取很多种数据源,基于文件、基于目录、基于TCP/UDP端口、基于HTTP、Kafka的等等、当然了,如果这里面没有你喜欢的,他也是支持自定义的
在这我们挑几个常用的看一下:
- Exec Source:实现文件监控,可以实时监控文件中的新增内容,类似于linux中的tail -f 效果。
在这需要注意 tail -F 和 tail -f 的区别
tail -F : 等同于–follow=name --retry,根据文件名进行追踪,并保持重试,即该文件被删除或改名后,如果再次创建相同的文件名,会继续追踪
tail -f :等同于–follow=descriptor,根据文件描述符进行追踪,当文件改名或被删除,追踪停止。在实际工作中我们的日志数据一般都会通过log4j记录,log4j产生的日志文件名称是固定的,每天定时给文件重命名
假设默认log4j会向access.log文件中写日志,每当凌晨0点的时候,log4j都会对文件进行重命名,在access后面添加昨天的日期,然后再创建新的access.log记录当天的新增日志数据。这个时候如果想要一直监控access.log文件中的新增日志数据的话,就需要使用tail -F - NetCat TCP/UDP Source: 采集指定端口(tcp、udp)的数据,可以读取流经端口的每一行数据
- Spooling Directory Source:采集文件夹里新增的文件
- Kafka Source:从Kafka消息队列中采集数据
注意了,前面我们分析的这几个source组件,其中execsource 和 kafkasource在实际工作中是最常见的,可以满足大部分的数据采集需求。
channel
Channel:接受Source发出的数据,可以把channel理解为一个临时存储数据的管道。
Channel的类型有很多:内存、文件,内存+文件、JDBC等
接下来我们来分析一下
- Memory Channel:使用内存作为数据的存储
优点是效率高,因为就不涉及磁盘IO
缺点有两个
1:可能会丢数据,如果Flume的agent挂了,那么channel中的数据就丢失了。
2:内存是有限的,会存在内存不够用的情况 - File Channel:使用文件来作为数据的存储
优点是数据不会丢失
缺点是效率相对内存来说会有点慢,但是这个慢并没有我们想象中的那么慢,
所以这个也是比较常用的一种channel。 - Spillable Memory Channel:使用内存和文件作为数据存储,即先把数据存到内存中,如果内存中数据达到阈值再flush到文件中
优点:解决了内存不够用的问题。
缺点:还是存在数据丢失的风险
sink
Sink:从Channel中读取数据并存储到指定目的地
Sink的表现形式有很多:打印到控制台、HDFS、Kafka等,
注意:Channel中的数据直到进入目的地才会被删除,当Sink写入目的地失败后,可以自动重写,
不会造成数据丢失,这块是有一个事务保证的。
常用的sink组件有:
- Logger Sink:将数据作为日志处理,可以选择打印到控制台或者写到文件中,这个主要在测试的时候使用
- HDFS Sink:将数据传输到HDFS中,这个是比较常见的,主要针对离线计算的场景
- Kafka Sink:将数据发送到kafka消息队列中,这个也是比较常见的,主要针对实时计算场景,数据不落盘,实时传输,最后使用实时计算框架直接处理。
Flume安装部署
在这里我重新克隆了一台Linux机器,主机名设置为bigdata04,ip设置为192.168.182.103
关闭防火墙,安装jdk并配置环境变量,因为Flume是java开发,所以需要依赖jdk环境。这些工作已经提前做好了,继续往下面分析
想要安装Flume,首先需要下载Flume,进入Flume的官网,找到Download链接
安装包下载好以后上传到linux机器的/data/soft目录下,并且解压
[root@bigdata04 soft]# ll
total 255844
-rw-r--r--. 1 root root 67938106 May 1 23:27 apache-flume-1.9.0-bin.tar.gz
drwxr-xr-x. 7 10 143 245 Dec 16 2018 jdk1.8
-rw-r--r--. 1 root root 194042837 Apr 6 23:14 jdk-8u202-linux-x64.tar.gz
[root@bigdata04 soft]# tar -zxvf apache-flume-1.9.0-bin.tar.gz
修改盘flume的env环境变量配置文件
在flume的conf目录下,修改flume-env.sh.template的名字,去掉后缀template
[root@bigdata04 conf]# mv flume-env.sh.template flume-env.sh
这样就好了,Flume的安装是不是很简单,这个时候我们不需要启动任何进程,只有在配置好采集任务之后才需要启动Flume。
Flume的使用
下面我们就想上手操作Flume,具体该怎么做呢?
先来看一个入门级别的Hello World案例。
我们前面说了,启动Flume任务其实就是启动一个Agent,Agent是由source、channel、sink组成的,这些组件在使用的时候只需要写几行配置就可以了
那下面我们就看一下source、channel、sink该如何配置呢?接下来带着大家看一下官网,找到左边的documentation,查看文档信息
Flume的操作文档是非常良心的,整理的非常详细
下面有一个Agent配置的例子:
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
这个例子中首先定义了source的名字、sink的名字还有channel的名字
下面配置source的相关参数
下面配置了sink的相关参数
接着配置了channel的相关参数
最后把这三个组件连接到了一起,就是告诉source需要向哪个channel写入数据,告诉sink需要从哪个channel读取数据,这样source、channel、sink这三个组件就联通了。总结下来,配置Flume agent的主要流程是这样的
- 给每个组件起名字
- 配置每个组件的相关参数
- 把它们联通起来
注意了,在Agent中配置的三大组件为什么要这样写呢?如果我是第一次使用我也不会写啊。
三大组件的配置在文档中是有详细说明的,来看一下,在Flume Sources下面显示的都是已经内置支持的Source组件
刚才看的案例中使用的是source类型是netcat,其实就是NetCat TCP Source,看一下详细内容
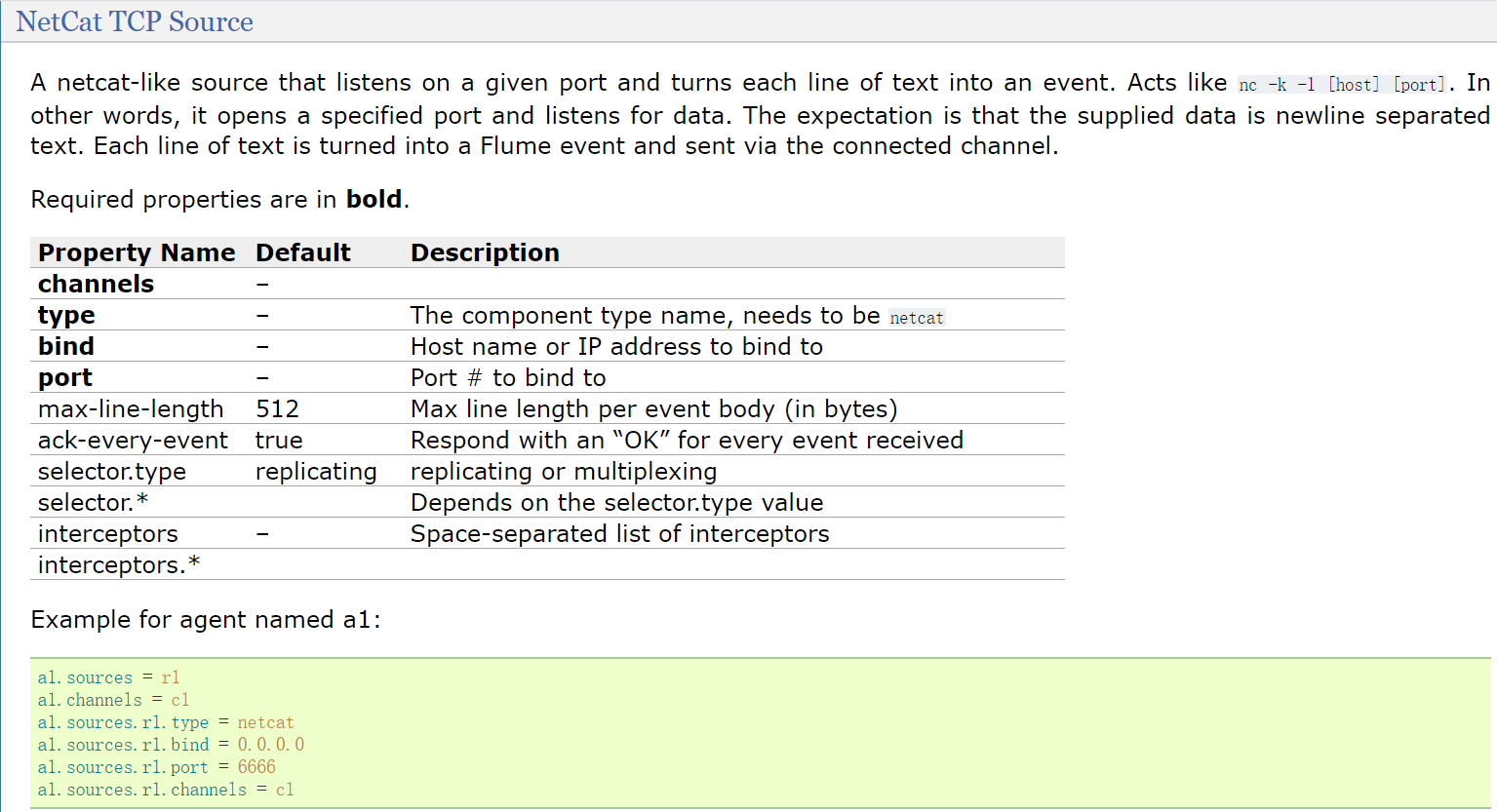
这里面的粗体字体是必选的参数
第一个参数是为了指定source需要向哪个channel写数据,这个其实是通用的参数,主要看下面这三个,type、bind、port
- type:类型需要指定为natcat
- bind:指定当前机器的ip,使用hostname也可以
- port:指定当前机器中一个没有被使用的端口
指定bind和port表示开启监听模式,监听指定ip和端口中的数据,其实就是开启了一个socket的服务端,等待客户端连接进来写入数据
在这里给agent起名为a1,所以netcat类型的配置如下,这里面还指定了source、channel的名字,并且把source和channel连接到一起了,刨除这几个配置之外就剩下了三行配置,就是刚才我们分析的那三个必填参数
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 6666
a1.sources.r1.channels = c1
注意了,bind参数后面指定的ip是四个0,这个当前机器的通用ip,因为一台机器可以有多个ip,例如:内网ip、外网ip,如果通过bind参数指定某一个ip的话,表示就只监听通过这个ip发送过来的数据了,这样会有局限性,所以可以指定0.0.0.0。下面几个参数都是可选配置,默认可以不配置。接着是channel,案例中channel使用的是memory
查看memory channel
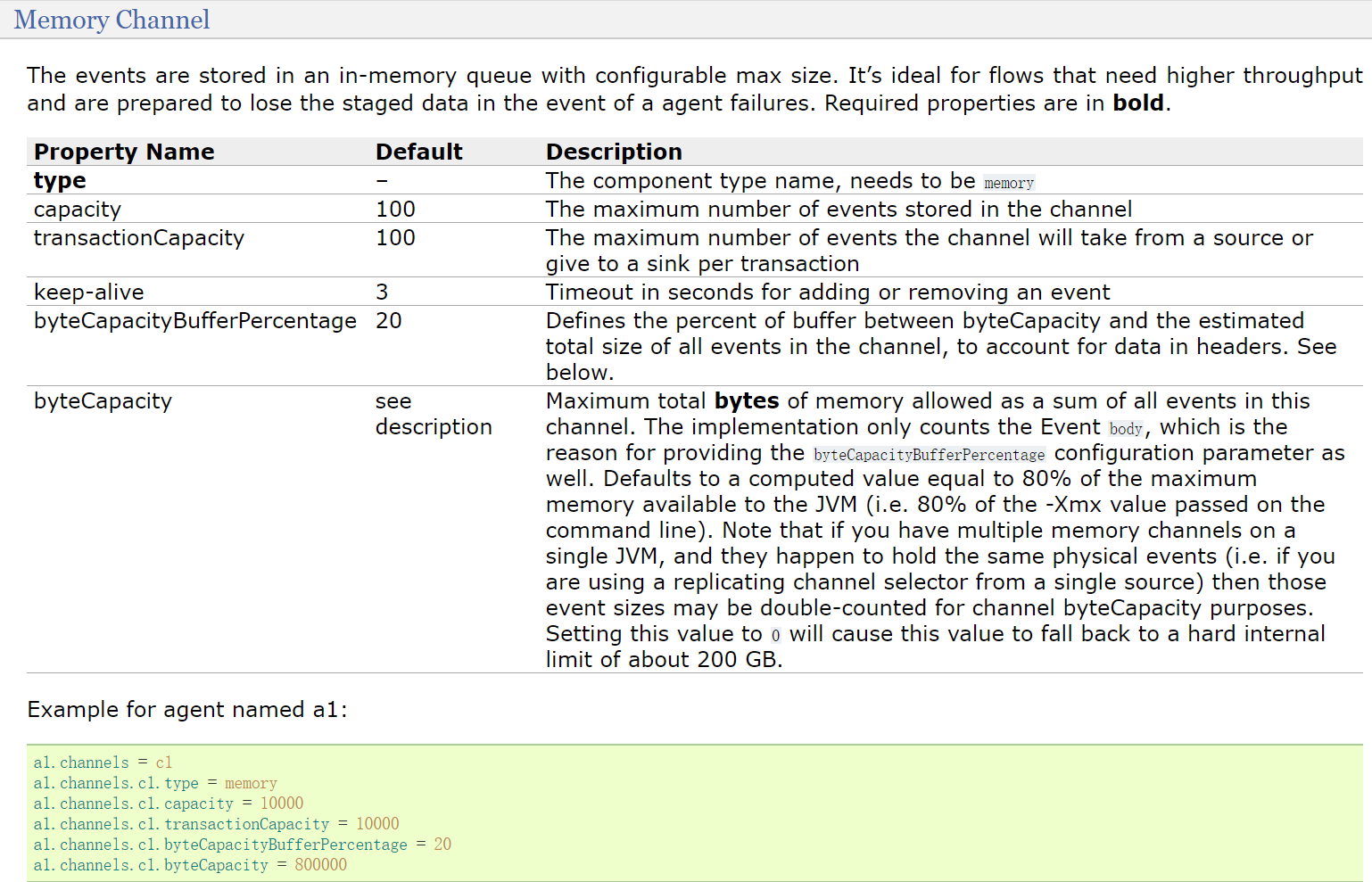
这里面只有type是必填项,其他都是可选的
最后看一下sink,在案例中sink使用的是logger,对应的就是Logger Sink
logger sink中默认也只需要指定type即可
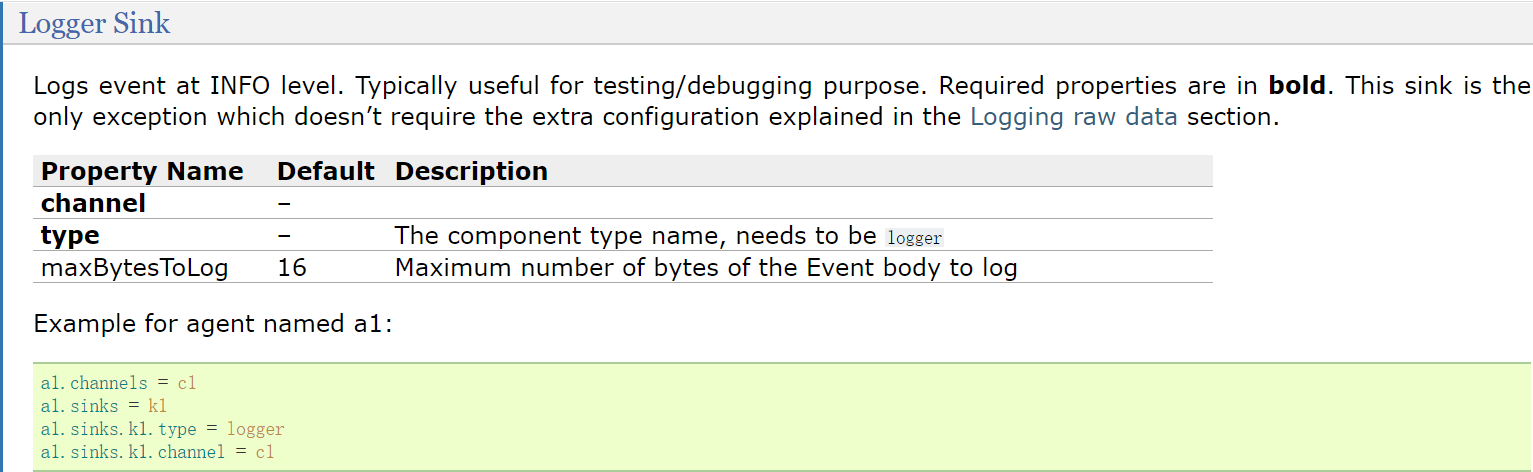
后期我们如果想要使用其他的内置组件,直接到官网文档这里查找即可,这里面的配置有很多,没有必要去记,肯定记不住,只要知道到哪里去找就可以。配置文件分析完了,可以把这些配置放到一个配置文件中,起名叫example.conf,把这个配置文件放到
[root@bigdata04 ~]# cd /data/soft/apache-flume-1.9.0-bin
[root@bigdata04 apache-flume-1.9.0-bin]# cd conf/
[root@bigdata04 conf]# vi example.conf
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
注意了,这个配置文件中的a1表示是agent的名称,还有就是port指定的端口必须是未被使用的,可以先查询一下当前机器使用了哪些端口,端口的可用范围是1-65535,如果懒得去查的话,就尽量使用偏大一些的端口,这样被占用的概率就非常低了。
Agent配置好了以后就可以启动了,下面来看一下启动Agent的命令
可以使用命令:
bin/flume-ng agent --name a1 --conf conf --conf-file example.conf -Dflume.ro
这里面使用flume-ng命令
后面指定agent,表示启动一个Flume的agent代理
--name:指定agent的名字
--conf:指定flume配置文件的根目录
--conf-file:指定Agent对应的配置文件(包含source、channel、sink配置的文件)
-D:动态添加一些参数,在这里是指定了flume的日志输出级别和输出位置,INFO表示日志级
其实agent的启动命令还可以这样写
bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template
这里面的-n属于简写,完整的写法就是–name
-c完整写法的–conf
-f完整写法是–conf-file
注意了,由于配置文件里面指定了agent的名称为a1,所以在–name后面也需要指定a1,还有就是通过–conf-file指定配置文件的时候需要指定conf目录下的example.conf配置文件
启动之后会看到如下信息,表示启动成功,启动成功之后,这个窗口会被一直占用,因为Agent服务一直在运行,现在属于一个前台进程。
2020-05-02 10:14:56,464 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.so
如果看到提示的有ERROR级别的日志信息,就需要具体问题具体分析了,一般都是配置文件配置错误了。接下来我们需要连接到source中通过netcat开启的socket服务端克隆一个bigdata04的会话,因为前面启动Agent之后,窗口就被占用了使用telnet命令可以连接到指定socket服务,telnet后面的主机名和端口是根据example.conf配置文件中配置的
[root@bigdata04 ~]# telnet localhost 44444
-bash: telnet: command not found
[root@bigdata04 ~]# yum install -y telnet
[root@bigdata04 ~]# telnet localhost 44444
Trying ::1...
telnet: connect to address ::1: Connection refused
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
hello world!
OK
此时Flume中Agent服务是在前台运行,这个服务实际工作中需要一直运行,所以需要放到后台运行。
Flume自身没有提供直接把进程放到后台执行的参数,所以就需要使用咱们前面学习的nohup和&了。此时就不需要指定-Dflume.root.logger=INFO,console参数了,默认情况下flume的日志会记录到日志文件中。停掉之前的Agent,重新执行。
[root@bigdata04 apache-flume-1.9.0-bin]# nohup bin/flume-ng agent --name a1 -
启动之后,通过jps命令可以查看到一个application进程,这个就是启动的Agent
案例:采集文件内容上传至HDFS
接下来我们来看一个工作中的典型案例:
采集文件内容上传至HDFS
需求:采集目录中已有的文件内容,存储到HDFS
分析:source是要基于目录的,channel建议使用file,可以保证不丢数据,sink使用hdfs
下面要做的就是配置Agent了,可以把example.conf拿过来修改一下,新的文件名为file-to-hdfs.conf
首先是基于目录的source,咱们前面说过,Spooling Directory Source可以实现目录监控。来看一下这个Spooling Directory Source。
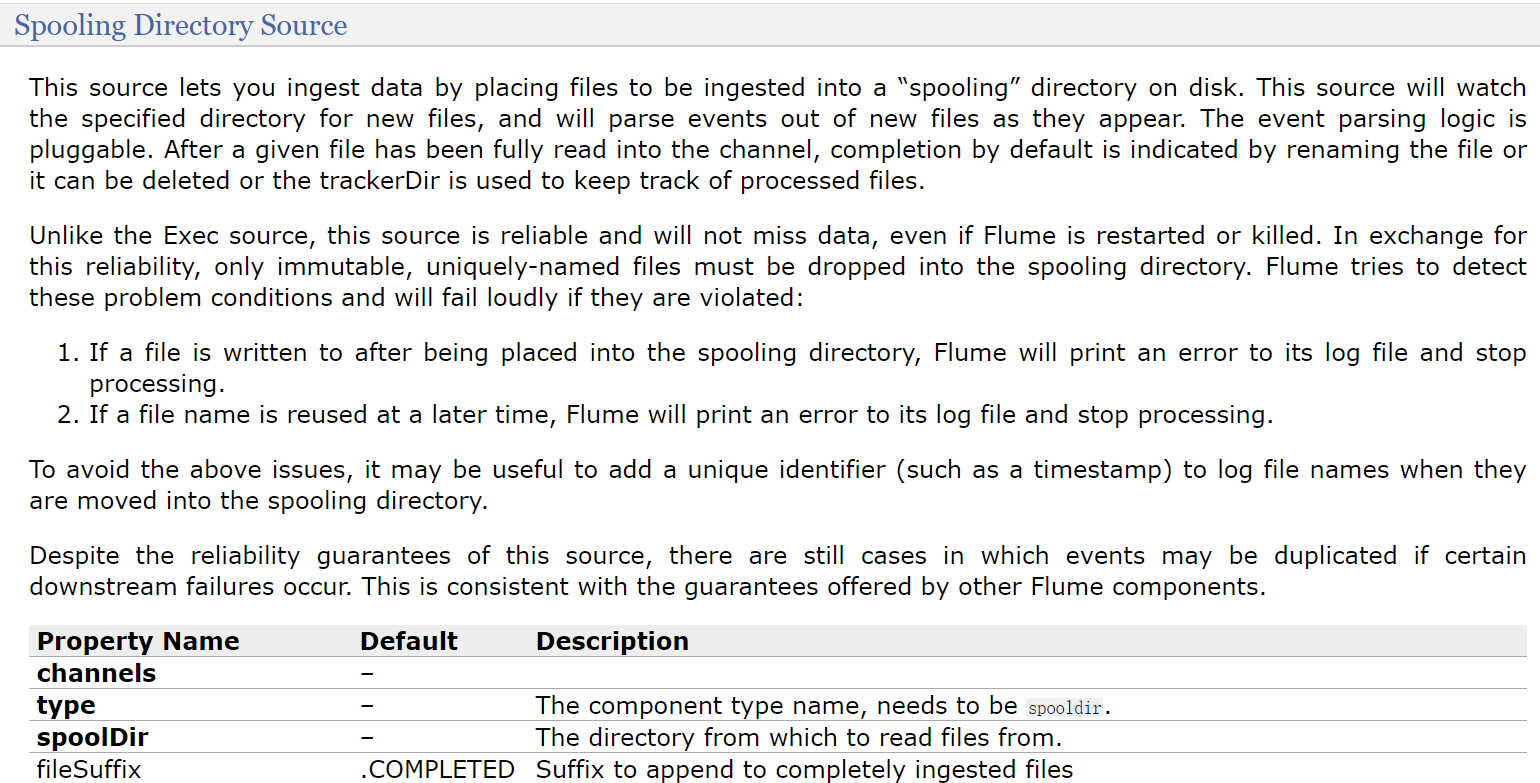
channels和type肯定是必填的,还有一个是spoolDir,就是指定一个监控的目录
看他下面的案例,里面还多指定了一个fileHeader,这个我们暂时也用不到,后面等我们讲了Event之后大家就知道这个fileHeader可以干什么了,先记着有这个事把。那来配置一下source
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /data/log/studentDir
接下来是channel了
channel在这里使用基于文件的,可以保证数据的安全性
如果针对采集的数据,丢个一两条对整体结果影响不大,只要求采集效率,那么这个时候完全可以使用基于内存的channel
咱们前面的例子中使用的是基于内存的channel,下面我们到文档中找一下基于文件的channel
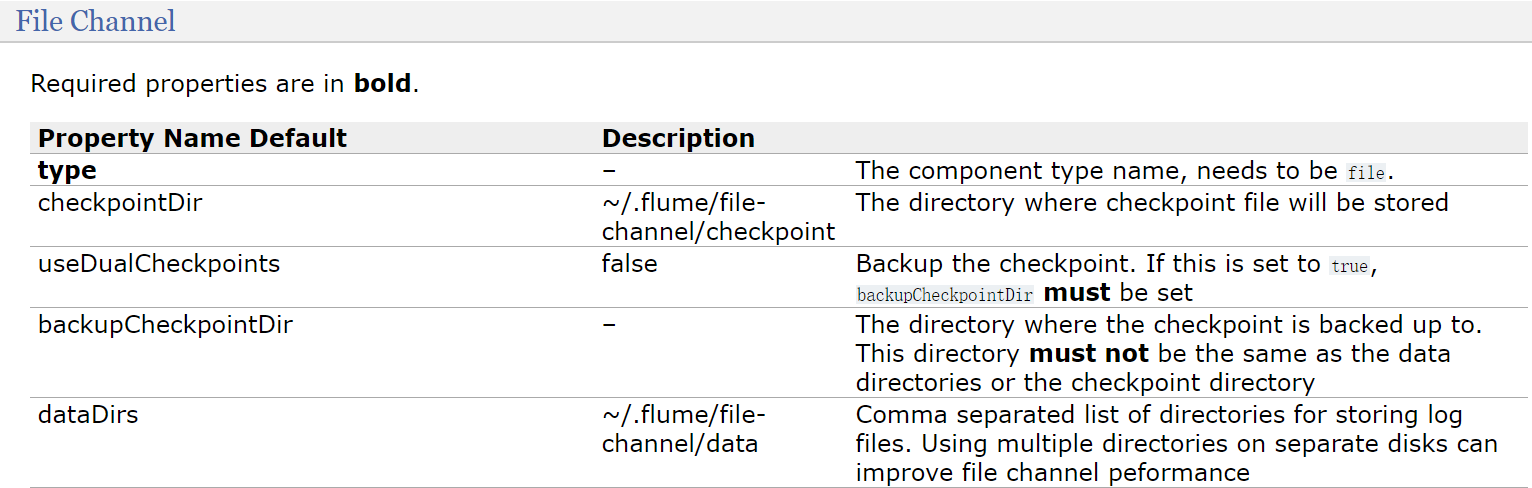
根据这里的例子可知,主要配置checkpointDir和dataDir,因为这两个目录默认会在用户家目录下生成,
建议修改到其他地方
- checkpointDir是存放检查点目录
- data是存放数据的目录
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /data/soft/apache-flume-1.9.0-bin/data/studentDir
a1.channels.c1.dataDirs = /data/soft/apache-flume-1.9.0-bin/data/studentDir/d
最后是sink
因为要向hdfs中输出数据,所以可以使用hdfssink
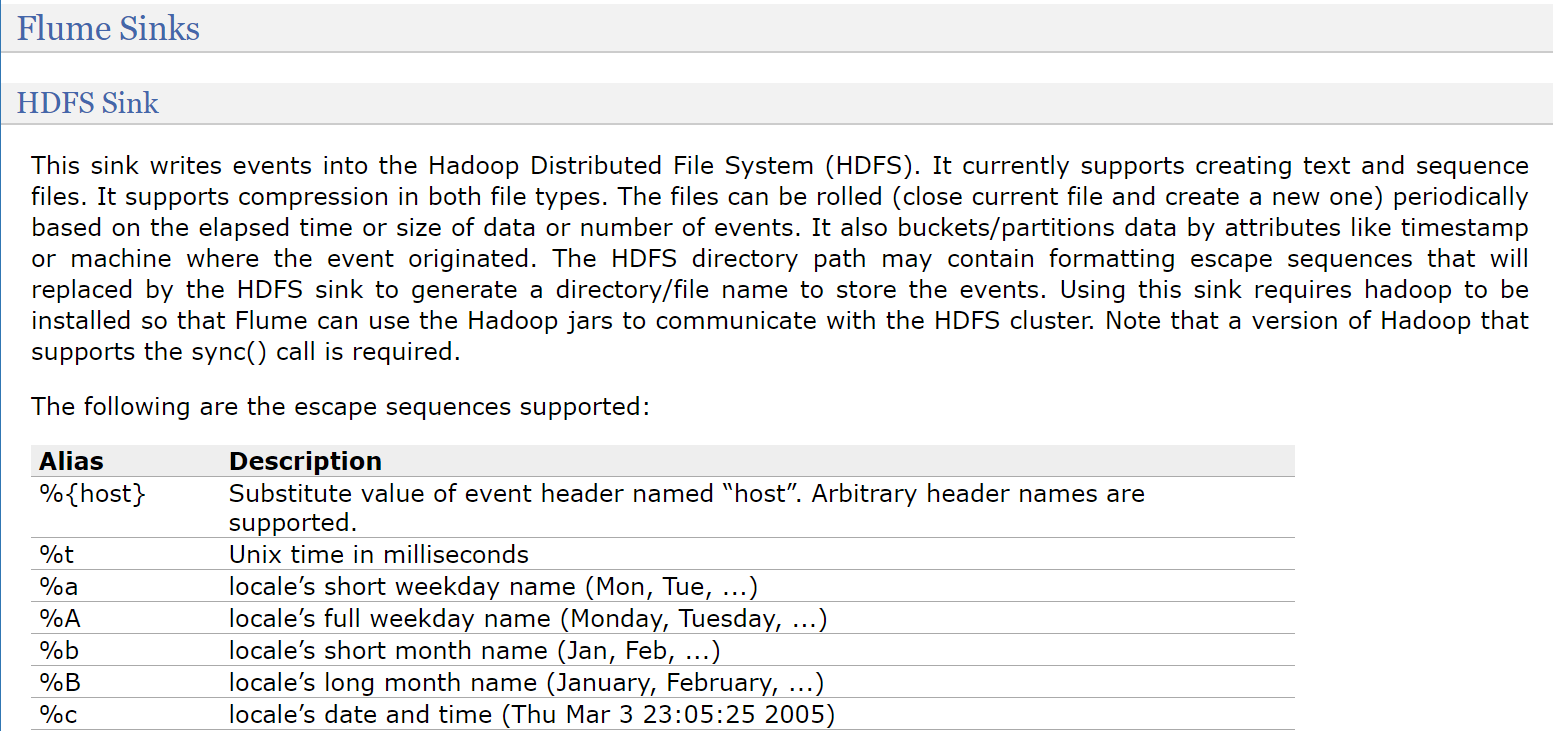

hdfs.path是必填项,指定hdfs上的存储目录
看这里例子中还指定了filePrefix参数,这个是一个文件前缀,会在hdfs上生成的文件前面加上这个前缀,这个属于可选项,有需求的话可以加上一般在这我们需要设置writeFormat和fileType这两个参数
默认情况下writeFormat的值是Writable,建议改为Text,看后面的解释,如果后期想使用hive或者impala操作这份数据的话,必须在生成数据之前设置为Text,Text表示是普通文本数据
fileType默认是SequenceFile,还支持DataStream 和 CompressedStream ,DataStream 不会对输出数据进行压缩,CompressedStream 会对输出数据进行压缩,在这里我们先不使用压缩格式的,所以选择DataStream
除了这些参数以外,还有三个也比较重要hdfs.rollInterval、hdfs.rollSize和hdfs.rollCount
- hdfs.rollInterval默认值是30,单位是秒,表示hdfs多长时间切分一个文件,因为这个采集程序是一直运行的,只要有新数据,就会被采集到hdfs上面,hdfs默认30秒钟切分出来一个文件,如果设置为0表示不按时间切文件
- hdfs.rollSize默认是1024,单位是字节,最终hdfs上切出来的文件大小都是1024字节,如果设置为0表示不按大小切文件
- hdfs.rollCount默认设置为10,表示每隔10条数据切出来一个文件,如果设置为0表示不按数据条数切文件这三个参数,如果都设置的有值,哪个条件先满足就按照哪个条件都会执行。在实际工作中一般会根据时间或者文件大小来切分文件,我们之前在工作中是设置的时间和文件小相结合,时间设置的是一小时,文件大小设置的128M,这两个哪个满足执行哪个所以针对hdfssink的配置最终是这样的
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.182.100:9000/flume/studentDir
a1.sinks.k1.hdfs.filePrefix = stu-
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
最后把组件连接到一起
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
把Agent的配置保存到flume的conf目录下的 file-to-hdfs.conf 文件中:
[root@bigdata04 conf]# vi file-to-hdfs.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /data/log/studentDir
# Use a channel which buffers events in memory
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /data/soft/apache-flume-1.9.0-bin/data/student
a1.channels.c1.dataDirs = /data/soft/apache-flume-1.9.0-bin/data/studentDir/d
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.182.100:9000/flume/studentDir
a1.sinks.k1.hdfs.filePrefix = stu-
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
下面就可以启动agent了,在启动agent之前,先初始化一下测试数据
创建/data/log/studentDir目录,然后在里面添加一个文件,class1.dat
class1.dat中存储的是学生信息,学生姓名、年龄、性别
[root@bigdata04 ~]# mkdir -p /data/log/studentDir
[root@bigdata04 ~]# cd /data/log/studentDir
[root@bigdata04 studentDir]# more class1.dat
jack 18 male
jessic 20 female
tom 17 male
启动Hadoop集群
启动Agent,使用在前台启动的方式,方便观察现象
Flume怎么知道哪些文件是新文件呢?它会不会重复读取同一个文件的数据呢?
不会的,我们到/data/log/studentDir目录看一下你就知道了
我们发现此时这个文件已经被加了一个后缀 .COMPLETED ,表示这个文件已经被读取过了,所以Flume在读取的时候会忽略后缀为 .COMPLETED 的文件。
案例:采集网站日志上传至HDFS
需求是这样的,
- 将A和B两台机器实时产生的日志数据汇总到机器C中
- 通过机器C将数据统一上传至HDFS的指定目录中
注意:HDFS中的目录是按天生成的,每天一个目录
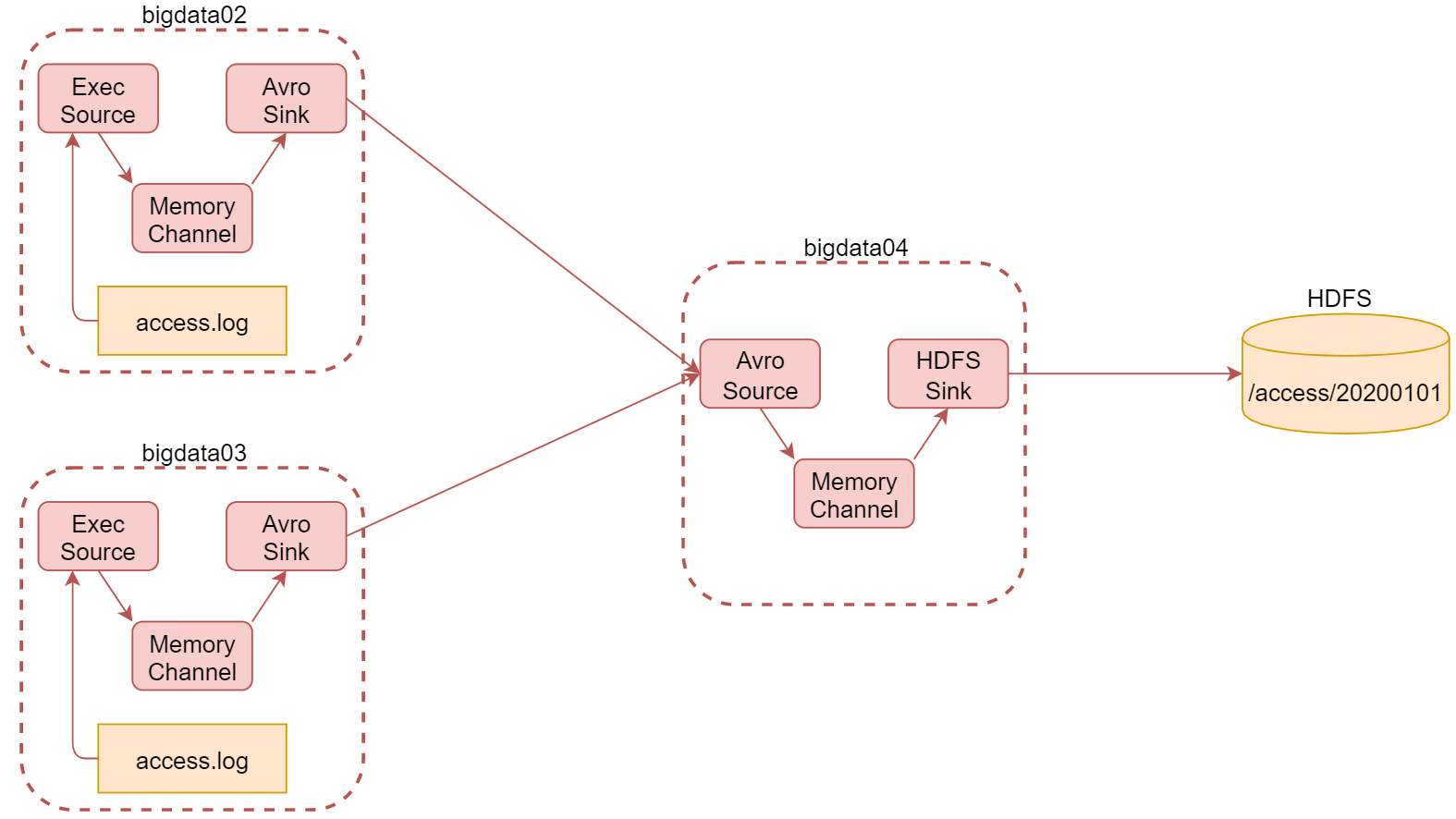
根据刚才的需求分析可知,我们一共需要三台机器
这里使用bigdata02和bigdata03采集当前机器上产生的实时日志数据,统一汇总到bigdata04机器上。其中bigdata02和bigdata03中的source使用基于file的source,ExecSource,因为要实时读取文件中的新增数据
channel在这里我们使用基于内存的channel,因为这里是采集网站的访问日志,就算丢一两条数据对整体结果影响也不大,我们只希望采集到的数据可以快读进入hdfs中,所以就选择了基于内存的channel。
由于bigdata02和bigdata03的数据需要快速发送到bigdata04中,为了快速发送我们可以通过网络直接传输,sink建议使用avrosink,avro是一种数据序列化系统,经过它序列化的数据传输起来效率更高,并且它对应的还有一个avrosource,avrosink的数据可以直接发送给avrosource,所以他们可以无缝衔接。
这样bigdata04的source就确定了 使用avrosource、channel还是基于内存的channel,sink就使用
hdfssink,因为是要向hdfs中写数据的。
这里面的组件,只有execsource、avrosource、avrosink我们还没有使用过,其他的组件都使用过了。最终需要在每台机器上启动一个agent,启动的时候需要注意先后顺序,先启动bigdata04上面的,再启动bigdata02和bigdata03上面的。
具体实现这个案例
1:在bigdata02上安装Flume并配置Agent
上传Flume的安装包,解压
[root@bigdata02 soft]# tar -zxvf apache-flume-1.9.0-bin.tar.gz
在flume的conf目录下,修改flume-env.sh.template的名字,去掉后缀template
[root@bigdata02 soft]# cd apache-flume-1.9.0-bin/conf
[root@bigdata02 conf]# mv flume-env.sh.template flume-env.sh
配置Agent,创建文件 file-to-avro-101.conf
[root@bigdata02 conf] vi file-to-avro-101.conf
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /data/log/access.log
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.182.103
a1.sinks.k1.port = 45454
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
这里面的配置没有特殊配置,直接参考官网文档就可以搞定
2:在bigdata03上安装Flume并配置Agent
上传Flume的安装包,解压
配置Agent,创建文件file-to-avro-102.conf
[root@bigdata03 conf] vi file-to-avro-102.conf
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /data/log/access.log
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.182.103
a1.sinks.k1.port = 45454
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3:在bigdata04上安装Flume并配置Agent
这台机器我们已经安装过Flume了,所以直接配置Agent即可
在指定Agent中sink配置的时候注意,我们的需求是需要按天在hdfs中创建目录,并把当天的数据上传到当天的日期目录中,这也就意味着hdfssink中的path不能写死,需要使用变量,动态获取时间,查看官方文档可知,在hdfs的目录中需要使用%Y%m%d
在这还有一点需要注意的,因为我们这里需要抽取时间,这个时间其实是需要从数据里面抽取,咱们前面说过数据的基本单位是Event,Event是一个对象,后面我们会详细分析,在这里大家先知道它里面包含的既有我们采集到的原始的数据,还有一个header属性,这个header属性是一个key-value结构的,我们现在抽取时间就需要到event的header中抽取,但是默认情况下event的header中是没有日期的,强行抽取是会报错的,会提示抽取不到,返回空指针异常。
java.lang.NullPointerException: Expected timestamp in the Flume event headers, but it was null
那如何向header中添加日期呢? 其实官方文档中也说了,可以使用hdfs.useLocalTimeStamp或者时间拦截器,时间拦截器我们后面会讲,暂时最简单直接的方式就是使用hdfs.useLocalTimeStamp,这个属性的值默认为false,需要改为true。

配置Agent,创建文件 avro-to-hdfs.conf
[root@bigdata04 conf] vi avro-to-hdfs.conf
# agent的名称是a1
# 指定source组件、channel组件和Sink组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# 配置source组件
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 45454
# 配置channel组件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink组件
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.182.100:9000/access/%Y%m%d
a1.sinks.k1.hdfs.filePrefix = access
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# 把组件连接起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
注意:bigdata02和bigdata03中配置的a1.sinks.k1.port 的值45454需要和bigdata04中配置的三台机器中的Flume Agent都配置好了,在开始启动之前需要先在bigdata02和bigdata03中生成测试数据,为了模拟真实情况,在这里我们就开发一个脚本,定时向文件中写数据
#!/bin/bash
# 循环向文件中生成数据
while [ "1" = "1" ]
do
# 获取当前时间戳
curr_time=`date +%s`
# 获取当前主机名
name=`hostname`
echo ${name}_${curr_time} >> /data/log/access.log
# 暂停1秒
sleep 1
done
在bigdata02和bigdata03中使用这个脚本生成数据
首先在bigdata02上创建/data/log目录,然后创建 generateAccessLog.sh 脚本
[root@bigdata02 ~]# mkdir -p /data/log
[root@bigdata02 ~]# cd /data/log/
[root@bigdata02 log]# vi generateAccessLog.sh
#!/bin/bash
# 循环向文件中生成数据
while [ "1" = "1" ]
do
# 获取当前时间戳
curr_time=`date +%s`
# 获取当前主机名
name=`hostname`
echo ${name}_${curr_time} >> /data/log/access.log
# 暂停1秒
sleep 1
done
接着在bigdata03上创建/data/log目录,然后创建 generateAccessLog.sh 脚本
[root@bigdata03 ~]# mkdir /data/log
[root@bigdata03 ~]# cd /data/log/
[root@bigdata03 log]# vi generateAccessLog.sh
#!/bin/bash
# 循环向文件中生成数据
while [ "1" = "1" ]
do
# 获取当前时间戳
curr_time=`date +%s`
# 获取当前主机名
name=`hostname`
echo ${name}_${curr_time} >> /data/log/access.log
# 暂停1秒
sleep 1
done
接下来开始启动相关的服务进程
首先启动bigdata04上的agent服务
接下来启动bigdata-02上的agent服务和shell脚本
[root@bigdata02 apache-flume-1.9.0-bin]# bin/flume-ng agent --name a1 --conf
[root@bigdata02 log]# sh -x generateAccessLog.sh
最后启动bigdata-03上的agent服务和shell脚本
[root@bigdata03 apache-flume-1.9.0-bin]# bin/flume-ng agent --name a1 --conf
[root@bigdata03 log]# sh -x generateAccessLog.sh
验证结果,查看hdfs上的结果数据,在bigdata01上查看
[root@bigdata01 soft]# hdfs dfs -cat /access/20200502/access.1588426157482.tmp
bigdata02_1588426253
bigdata02_1588426254
bigdata02_1588426255
bigdata02_1588426256
bigdata02_1588426257
bigdata02_1588426258
注意:启动之后稍等一会就可以看到数据了,我们观察数据的变化,会发现hdfs中数据增长的不是很快,它会每隔一段时间添加一批数据,实时性好像没那么高?
这是因为avrosink中有一个配置batch-size,它的默认值是100,也就是每次发送100条数据,如果数据不够100条,则不发送。
具体这个值设置多少合适,要看你source数据源大致每秒产生多少数据,以及你希望的延迟要达到什么程度,如果这个值设置太小的话,会造成sink频繁向外面写数据,这样也会影响性能。最终,依次停止bigdata02、bigdata03中的服务,最后停止bigdata04中的服务
各种自定义组件
咱们前面讲了很多组件,有核心组件和高级组件
source、channel、sink以及Source Interceptors,Channel Selectors、Sink Processors
针对这些组件,Flume都内置提供了组件的很多具体实现,在实际工作中,95%以上的数据采集需求都是可以满足的,但是谁也不敢保证100%都能满足,因为什么奇葩的需求都会有,那针对系统内没有提供的一些组件怎么办呢?
假设我们想把flume采集到的数据输出到mysql中,那这个时候就需要有针对mysql的sink组件了,但是Flume中并没有,因为这种需求不常见,往mysql中写的都是结构化数据,数据的格式是固定的,但是flume采集的一般都是日志数据,这种属于非结构化数据,不支持也是正常的,但是我们在这里就是需要使用Flume往mysql中写数据,那怎么办?
要不我们考虑换一个采集工具把,当然这也是一种解决方案,如果有其他采集工具支持向mysql中写数据的话那可以考虑换一个采集工具,如果所有的采集工具都不支持向mysql中写数据呢,也就是说你这个需求就是前无古人后无来者的,怎么破?
不用担心,天无绝人之路,其实咱们使用的Flume提供的那些内置组件也都是作者一行代码一行代码写出来的,那我们是不是也可以自己写一个自定义的组件呢?可以的,并且flume也很欢迎你这样去做,它把开发文档什么的东西都给你准备好了。
注意了,就算没有文档,我们也要想办法去自定义,没有文档的话就需要去抠Flume的源码了。
在这里Flume针对自定义组件提供了详细的文档说明,我们来看一下通过Flume User Guide可以看到,针对source、channle、sink、Source Interceptors,Channel Selectors、都是可以的,这里面都显示了针对自定义的组件如何配置使用Sink Processors目前暂时不支持自定义。
那这些支持自定义的组件具体开发步骤是什么样的呢?代码该写成什么样的呢?大家还记得Flume有两个文档链接吗?Flume Developer Guide
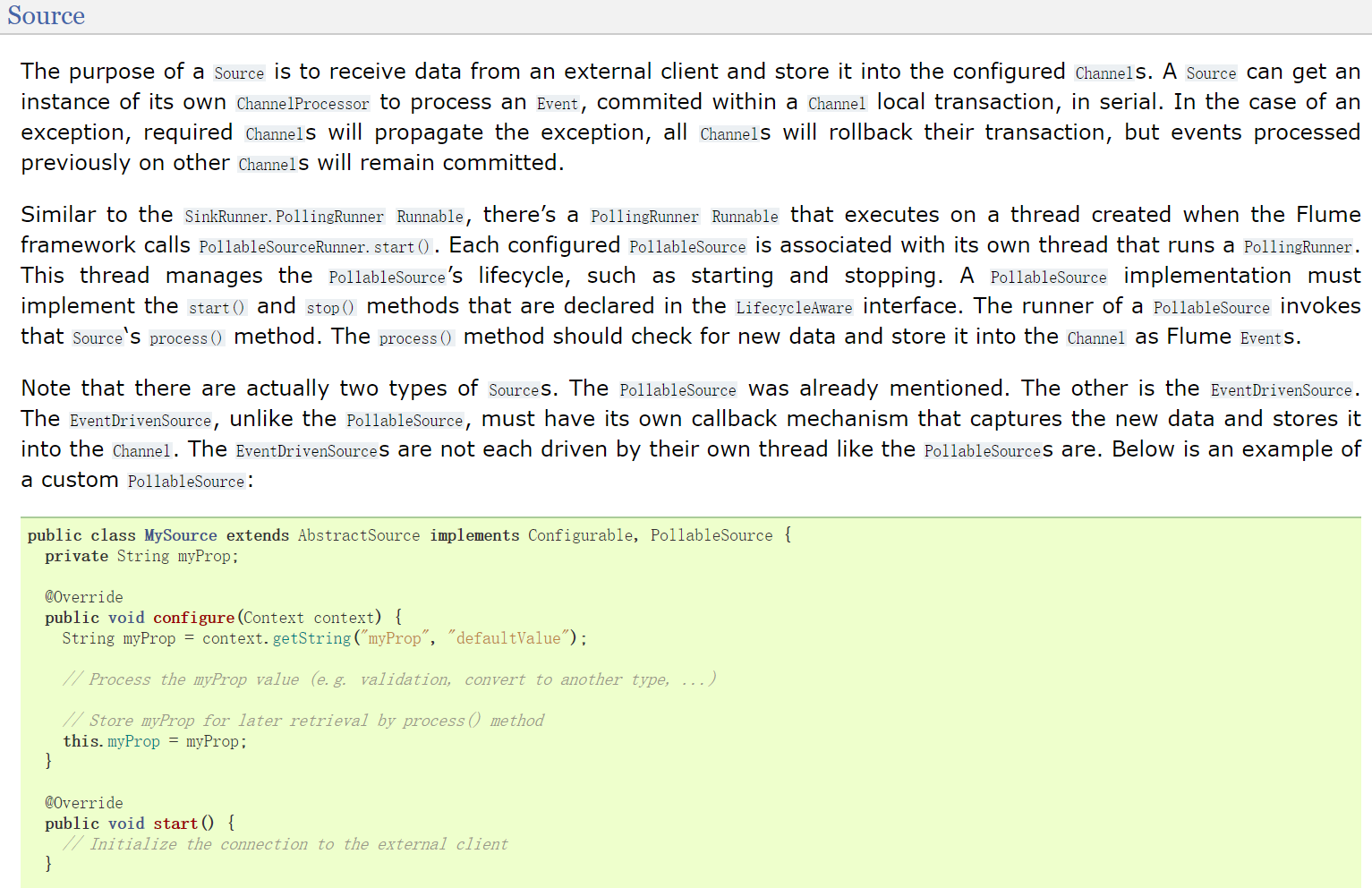
例如:自定义source
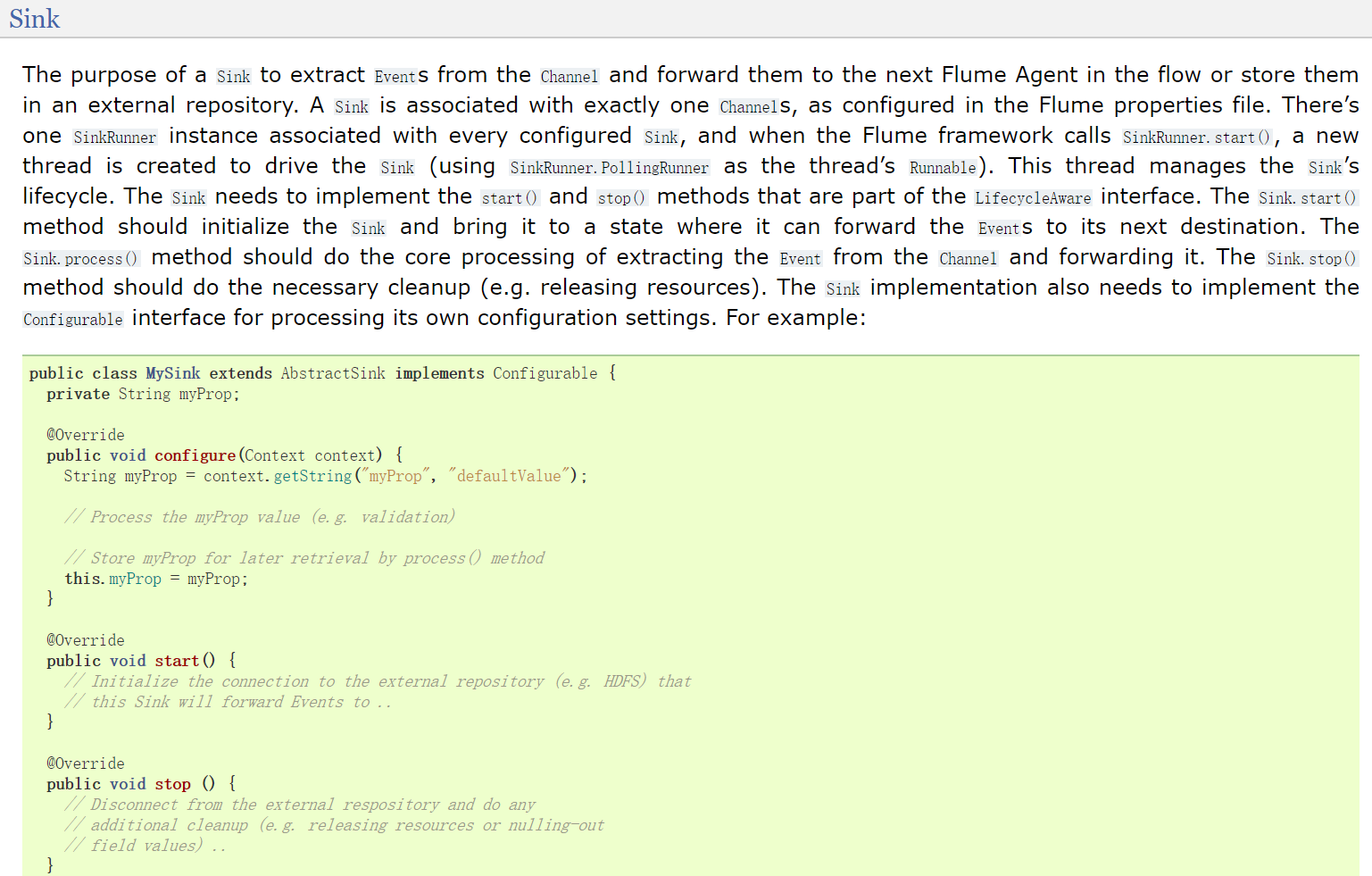
例如:自定义sink
自定义channel的内容目前还没完善,如果你确实想自定义这个组件,就需要到Flume源码中找到目前支持的那些channel的代码,参考着实现我们自定义的channel组件。
大家在这里知道可以自定义,并且知道自定义组件的文档在哪里就可以了,目前来说,需要我们自定义组件的场景实在是太少了,几乎和买彩票中奖的概率差不多。
前面我们掌握了Flume的基本使用和高级使用场景,下面我们来看一下针对Flume的一些企业级优化和监控手段
Flume优化
- 调整Flume进程的内存大小,建议设置1G~2G,太小的话会导致频繁GC
因为Flume进程也是基于Java的,所以就涉及到进程的内存设置,一般建议启动的单个Flume进程(或者说单个Agent)内存设置为1G~2G,内存太小的话会频繁GC,影响Agent的执行效率。
那具体设置多少合适呢?
这个需求需要根据Agent读取的数据量的大小和速度有关系,所以需要具体情况具体分析,当Flume的Agent启动之后,对应就会启动一个进程,我们可以通过jstat -gcutil PID 1000来看看这个进程GC的信息,每一秒钟刷新一次,如果GC次数增长过快,说明内存不够用。使用jps查看目前启动flume进程
[root@bigdata04 ~]# jps
2957 Jps
2799 Application
执行 jstat -gcutil PID 1000
[root@bigdata04 ~]# jstat -gcutil 2799 1000
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
100.00 0.00 17.54 42.80 96.46 92.38 8 0.029 0 0.000 0
100.00 0.00 17.54 42.80 96.46 92.38 8 0.029 0 0.000 0
100.00 0.00 17.54 42.80 96.46 92.38 8 0.029 0 0.000 0
100.00 0.00 17.54 42.80 96.46 92.38 8 0.029 0 0.000 0
100.00 0.00 17.54 42.80 96.46 92.38 8 0.029 0 0.000 0
100.00 0.00 17.54 42.80 96.46 92.38 8 0.029 0 0.000 0
在这里主要看YGC YGCT FGC FGCT GCT
- YGC:表示新生代堆内存GC的次数,如果每隔几十秒产生一次,也还可以接受,如果每秒都会发生一次YGC,那说明需要增加内存了
- YGCT:表示新生代堆内存GC消耗的总时间
- FGC:FULL GC发生的次数,注意,如果发生FUCC GC,则Flume进程会进入暂停状态,FUCC GC执行完以后Flume才会继续工作,所以FUCC GC是非常影响效率的,这个指标的值越低越好,没有更好。
- GCT:所有类型的GC消耗的总时间
如果需要调整Flume进程内存的话,需要调整 flume-env.s h脚本中的 JAVA_OPTS 参数把 export JAVA_OPTS 参数前面的#号去掉才会生效。
export JAVA_OPTS="-Xms1024m -Xmx1024m -Dcom.sun.management.jmxremote"
建议这里的 Xms 和 Xmx 设置为一样大,避免进行内存交换,内存交换也比较消耗性能。
- 在一台服务器启动多个agent的时候,建议修改配置区分日志文件
因为在conf目录下有log4j.properties,在这里面指定了日志文件的名称和位置,所有使用conf目录下面配置启动的Agent产生的日志都会记录到同一个日志文件中,如果我们在一台机器上启动了10几个Agent,后期发现某一个Agent挂了,想要查看日志分析问题,这个时候就疯了,因为所有Agent产生的日志都混到一块了,压根都没法分析日志了。
所以建议拷贝多个conf目录,然后修改对应conf目录中log4j.properties日志的文件名称(可以保证多个agent的日志分别存储),并且把日志级别调整为warn(减少垃圾日志的产生),默认info级别会记录很多日志信息。这样在启动Agent的时候分别通过–conf参数指定不同的conf目录,后期分析日志就方便了,每一个Agent都有一个单独的日志文件。
以bigdata04机器为例:
复制conf-failover目录,以后启动sink的failover任务的时候使用这个目录
修改 log4j.properties中的日志记录级别和日志文件名称,日志文件目录可以不用修改,统一使用logs目录即可。
[root@bigdata04 apache-flume-1.9.0-bin]# cp -r conf/ conf-failover
[root@bigdata04 apache-flume-1.9.0-bin]# cd conf-failover/
[root@bigdata04 conf-failover]# vi log4j.properties
.....
flume.root.logger=WARN,LOGFILE
flume.log.dir=./logs
flume.log.file=flume-failover.log
再启动的时候就是这样的了
[root@bigdata04 apache-flume-1.9.0-bin]# nohup bin/flume-ng agent --name a1 -
这样就会在flume的logs目录中产生 flume-failover.log 文件,并且文件中只记录WARN和ERROR级别
的日志,这样后期排查日志就很清晰了。
[root@bigdata04 apache-flume-1.9.0-bin]# cd logs/
[root@bigdata04 logs]# ll
total 4
-rw-r--r--. 1 root root 478 May 3 16:25 flume-failover.log
[root@bigdata04 logs]# more flume-failover.log
03 May 2020 16:25:38,992 ERROR [SinkRunner-PollingRunner-FailoverSinkP
rocessor] (org.apache.flume.SinkRunner$PollingRunner.run:158) - Unabl
e to deliver event. Exception follows.
org.apache.flume.EventDeliveryException: All sinks failed to process,
nothing left to failover to
at org.apache.flume.sink.FailoverSinkProcessor.process(Failove
rSinkProcessor.java:194)
at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.ja
va:145)
at java.lang.Thread.run(Thread.java:748)
Flume进程监控
Flume的Agent服务是一个独立的进程,假设我们使用source->channel->sink实现了一个数据采集落盘的功能,如果这个采集进程被误操作干掉了,这个时候我们是发现不了的,什么时候会发现呢?
可能第二天,产品经理找到你了,说昨天的这个指标值有点偏低啊,你来看下怎么回事,然后你就一顿操作猛如虎,结果发现原始数据少了一半多,那是因为Flume的采集程序在昨天下午的时候被误操作干掉了。
找到问题之后,你就苦巴巴的手工去补数据,重跑计算程序,最后再找产品经理确认数据的准确性。类似的问题会有很多,这说明你现在是无法掌控你手下的这些程序,他们都是不受控的状态,说不定哪天哪个程序不高兴,他就自杀了,不干活了,过了好几天,需要用到这个数据的时候你才发现,发现的早的话还能补数据,发现晚的话数据可能都补不回来了,这样对公司来说就是属于比较严重的数据故障问题,这样你年终奖想拿18薪就不太现实了。
所以针对这些存在单点故障的进程,我们都需要添加监控告警机制,最起码出问题能及时知道,再好一点的呢,可以尝试自动修复重启。
那针对Flume中的Agent我们就来实现一个监控功能,并且尝试自动重启
大致思路是这样的,
- 首先需要有一个配置文件,配置文件中指定你现在需要监控哪些Agent
- 有一个脚本负责读取配置文件中的内容,定时挨个检查Agent对应的进程还在不在,如果发现对应的进程不在,则记录错误信息,然后告警(发短信或者发邮件) 并尝试重启
创建一个文件 monlist.conf文件中的第一列指定一个Agent的唯一标识,后期需要根据这个标识过滤对应的Flume进程,所以一定要保证至少在一台机器上是唯一的,
等号后面是一个启动Flume进程的脚本,这个脚本和Agent的唯一标识是一一对应的,后期如果根据
Agent标识没有找到对应的进程,那么就需要根据这个脚本启动进程
example=startExample.sh
这个脚本的内容如下: startExample.sh
#!/bin/bash
flume_path=/data/soft/apache-flume-1.9.0-bin
nohup ${flume_path}/bin/flume-ng agent --name a1 --conf ${flume_path}/conf/ -
接着就是要写一个脚本来检查进程在不在,不在的话尝试重启
创建脚本 monlist.sh
#!/bin/bash
monlist=`cat monlist.conf`
echo "start check"
for item in ${monlist}
do
# 设置字段分隔符
OLD_IFS=$IFS
IFS="="
# 把一行内容转成多列[数组]
arr=($item)
# 获取等号左边的内容
name=${arr[0]}
# 获取等号右边的内容
script=${arr[1]}
echo "time is:"`date +"%Y-%m-%d %H:%M:%S"`" check "$name
if [ `jps -m|grep $name | wc -l` -eq 0 ]
then
# 发短信或者邮件告警
echo `date +"%Y-%m-%d %H:%M:%S"`$name "is none"
sh -x ./${script}
fi
done
注意:这个需要定时执行,所以可以使用crontab定时调度
* * * * * root /bin/bash /data/soft/monlist.sh