文章目录
- MapReduce性能优化
- 小文件问题
- 生成SequenceFile
- MapFile
- 案例 :使用SequenceFile实现小文件的存储和计算
- 数据倾斜问题
- 实际案例
MapReduce性能优化
针对MapReduce的案例我们并没有讲太多,主要是因为在实际工作中真正需要我们去写MapReduce代码的场景已经是凤毛麟角了,因为后面我们会学习一个大数据框架Hive,Hive支持SQL,这个Hive底层会把SQL转化为MapReduce执行,不需要我们写一行代码,所以说工作中的大部分需求我们都使用SQL去实现了,谁还苦巴巴的来写代码啊,一行SQL能抵你写的几十行代码,你还想去写MapReduce代码吗,肯定不想了。
但是MapReduce代码的开发毕竟是基本功,所以前面我们也详细的讲解了它的开发流程。
虽然现在MapReduce代码写的很少了,但是针对MapReduce程序的性能优化是少不了的,面试也是经常会问到的,所以下面我们就来分析一下MapReduce中典型的性能优化场景
- 第一个场景是:小文件问题
- 第二个场景是:数据倾斜问题
小文件问题
Hadoop的HDFS和MapReduce都是针对大数据文件来设计的,在小文件的处理上不但效率低下,而且十分消耗内存资源。针对HDFS而言,每一个小文件在namenode中都会占用150字节的内存空间,最终会导致集群中虽然存储了很多个文件,但是文件的体积并不大,这样就没有意义了。
针对MapReduce而言,每一个小文件都是一个Block,都会产生一个InputSplit,最终每一个小文件都会产生一个map任务,这样会导致同时启动太多的Map任务,Map任务的启动是非常消耗性能的,但是启动了以后执行了很短时间就停止了,因为小文件的数据量太小了,这样就会造成任务执行消耗的时间还没有启动任务消耗的时间多,这样也会影响MapReduce执行的效率。
针对这个问题,解决办法通常是选择一个容器,将这些小文件组织起来统一存储,HDFS提供了两种类型的容器,分别是SequenceFile 和 MapFileSequeceFile是Hadoop 提供的一种二进制文件,这种二进制文件直接将<key, value>对序列化到文件中。
一般对小文件可以使用这种文件合并,即将小文件的文件名作为key,文件内容作为value序列化到大文件中。但是这个文件有一个缺点,就是它需要一个合并文件的过程,最终合并的文件会比较大,并且合并后的文件查看起来不方便,必须通过遍历才能查看里面的每一个小文件。所以这个SequenceFile 其实可以理解为把很多小文件压缩成一个大的压缩包了。下面我们来具体看一下如何生成SequenceFile
生成SequenceFile
需要开发代码如下:
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.DefaultCodec;
import java.io.File;
/**
* 小文件解决方案之SequenceFile
*/
public class SmallFileSeq {
public static void main(String[] args) throws Exception{
//生成SequenceFile文件
write("D:\\smallFile","/seqFile");
//读取SequenceFile文件
read("/seqFile");
}
/**
* 生成SequenceFile文件
* @param inputDir 输入目录-windows目录
* @param outputFile 输出文件-hdfs文件
* @throws Exception
*/
private static void write(String inputDir,String outputFile)
throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata01:9000");
//获取操作HDFS的对象
FileSystem fileSystem = FileSystem.get(conf);
//删除输出文件
fileSystem.delete(new Path(outputFile),true);
//构造opts数组,有三个元素
/*
第一个是输出路径
第二个是key类型
第三个是value类型
*/
SequenceFile.Writer.Option[] opts = new SequenceFile.Writer.Option[]{
SequenceFile.Writer.file(new Path(outputFile)),
SequenceFile.Writer.keyClass(Text.class),
SequenceFile.Writer.valueClass(Text.class)};
//创建一个writer实例
SequenceFile.Writer writer = SequenceFile.createWriter(conf, opts);
//指定要压缩的文件的目录
File inputDirPath = new File(inputDir);
if(inputDirPath.isDirectory()){
File[] files = inputDirPath.listFiles();
for (File file : files) {
//获取文件全部内容
String content = FileUtils.readFileToString(file, "UTF-8");
//文件名作为key
Text key = new Text(file.getName());
//文件内容作为value
Text value = new Text(content);
writer.append(key,value);
}
}
writer.close();
}
private static void read(String inputFile)
throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata01:9000");
//创建阅读器
SequenceFile.Reader reader = new SequenceFile.Reader(conf, SequenceFi
Text key = new Text();
Text value = new Text();
//循环读取数据
while(reader.next(key,value)){
//输出文件名称
System.out.print("文件名:"+key.toString()+",");
//输出文件的内容
System.out.println("文件内容:"+value.toString());
}
reader.close();
}
}
执行代码中的write方法,可以看到在HDFS上会产生一个/seqFile文件,这个文件就是最终生成的大文件。执行代码中的read方法,可以输出小文件的名称和内容。接下来我们来看一下MapFile
MapFile是排序后的SequenceFile,MapFile由两部分组成,分别是index和data
index作为文件的数据索引,主要记录了每个Record的key值,以及该Record在文件中的偏移位置。在MapFile被访问的时候,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定Record所在文件位置,因此,相对SequenceFile而言,MapFile的检索效率是高效的,缺点是会消耗一部分内存来存储index数据。
MapFile
代码实现如下:
package com.imooc.mr;
import org.apache.commons.io.FileUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.MapFile;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import java.io.File;
/**
* 小文件解决方案之MapFile
*/
public class SmallFileMap {
public static void main(String[] args) throws Exception{
//生成MapFile文件
write("D:\\smallFile","/mapFile");
read("/mapFile");
}
/**
* 生成MapFile文件
* @param inputDir 输入目录-windows目录
* @param outputDir 输出目录-hdfs目录
* @throws Exception
*/
private static void write(String inputDir,String outputDir)
throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata01:9000");
//获取操作HDFS的对象
FileSystem fileSystem = FileSystem.get(conf);
//删除输出目录
fileSystem.delete(new Path(outputDir),true);
//构造opts数组,有两个元素
/*
第一个是key类型
第二个是value类型
*/
SequenceFile.Writer.Option[] opts = new SequenceFile.Writer.Option[]{
MapFile.Writer.keyClass(Text.class),
MapFile.Writer.valueClass(Text.class)};
//创建一个writer实例
MapFile.Writer writer = new MapFile.Writer(conf,new Path(outputDir),o
//指定要压缩的文件的目录
File inputDirPath = new File(inputDir);
if(inputDirPath.isDirectory()){
File[] files = inputDirPath.listFiles();
for (File file : files) {
//获取文件全部内容
String content = FileUtils.readFileToString(file, "UTF-8");
//文件名作为key
Text key = new Text(file.getName());
//文件内容作为value
Text value = new Text(content);
writer.append(key,value);
}
}
writer.close();
}
/**
* 读取MapFile文件
* @param inputDir MapFile文件路径
* @throws Exception
*/
private static void read(String inputDir)
throws Exception{
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata01:9000");
//创建阅读器
MapFile.Reader reader = new MapFile.Reader(new Path(inputDir),conf);
//循环读取数据
while(reader.next(key,value)){
//输出文件名称
System.out.print("文件名:"+key.toString()+",");
//输出文件的内容
System.out.println("文件内容:"+value.toString());
}
reader.close();
}
}
执行代码中的write方法,可以看到在HDFS上会产生一个/mapFile目录,这个目录里面有两个文件,一个index索引文件,一个data数据文件
执行代码中的read方法,可以输出小文件的名称和内容
案例 :使用SequenceFile实现小文件的存储和计算
小文件的存储刚才我们已经通过代码实现了,接下来我们要实现如何通过MapReduce读取SequenceFile
咱们之前的代码默认只能读取普通文本文件,针对SequenceFile是无法读取的,那该如何设置才能让mapreduce可以读取SequenceFile呢?
很简单,只需要在job中设置输入数据处理类就行了,默认情况下使用的是TextInputFormat
job.setInputFormatClass(SequenceFileInputFormat.class)
创建一个新的类WordCountJobSeq
注意修改两个地方
- 修改job中的设置输入数据处理类
- 修改map中k1的数据类型为Text类型
package com.imooc.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
/**
* 需求:读取SequenceFile文件
*/
public class WordCountJobSeq {
public static class MyMapper extends Mapper<Text, Text,Text,LongWritable>
Logger logger = LoggerFactory.getLogger(MyMapper.class);
/**
* 需要实现map函数
* 这个map函数就是可以接收<k1,v1>,产生<k2,v2>
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(Text k1, Text v1, Context context)
throws IOException, InterruptedException {
//输出k1,v1的值
System.out.println("<k1,v1>=<"+k1.toString()+","+v1.toString()+">
//logger.info("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//k1 代表的是每一行数据的行首偏移量,v1代表的是每一行内容
//对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
//迭代切割出来的单词数据
for (String word : words) {
//把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
//把<k2,v2>写出去
context.write(k2,v2);
}
}
}
/**
* Reduce阶段
*/
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongW
Logger logger = LoggerFactory.getLogger(MyReducer.class);
/**
* 针对<k2,{v2...}>的数据进行累加求和,并且最终把数据转化为k3,v3写出去
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context co
throws IOException, InterruptedException {
//创建一个sum变量,保存v2s的和
long sum = 0L;
//对v2s中的数据进行累加求和
for(LongWritable v2: v2s){
//输出k2,v2的值
//System.out.println("<k2,v2>=<"+k2.toString()+","+v2.get()+"
//logger.info("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
sum += v2.get();
}
//组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
//输出k3,v3的值
//System.out.println("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
//logger.info("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
context.write(k3,v3);
}
}
/**
* 组装Job=Map+Reduce
*/
public static void main(String[] args) {
try{
if(args.length!=2){
//如果传递的参数不够,程序直接退出
System.exit(100);
}
//指定Job需要的配置参数
Configuration conf = new Configuration();
//创建一个Job
Job job = Job.getInstance(conf);
//注意了:这一行必须设置,否则在集群中执行的时候是找不到WordCountJob这个
job.setJarByClass(WordCountJobSeq.class);
//指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job,new Path(args[0]));
//指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//指定map相关的代码
job.setMapperClass(MyMapper.class);
//指定k2的类型
job.setMapOutputKeyClass(Text.class);
//指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
//设置输入数据处理类
job.setInputFormatClass(SequenceFileInputFormat.class);
//指定reduce相关的代码
job.setReducerClass(MyReducer.class);
//指定k3的类型
job.setOutputKeyClass(Text.class);
//指定v3的类型
job.setOutputValueClass(LongWritable.class);
//提交job
job.waitForCompletion(true);
}catch(Exception e){
e.printStackTrace();
}
}
}
重新编译打包执行
执行成功以后查看结果
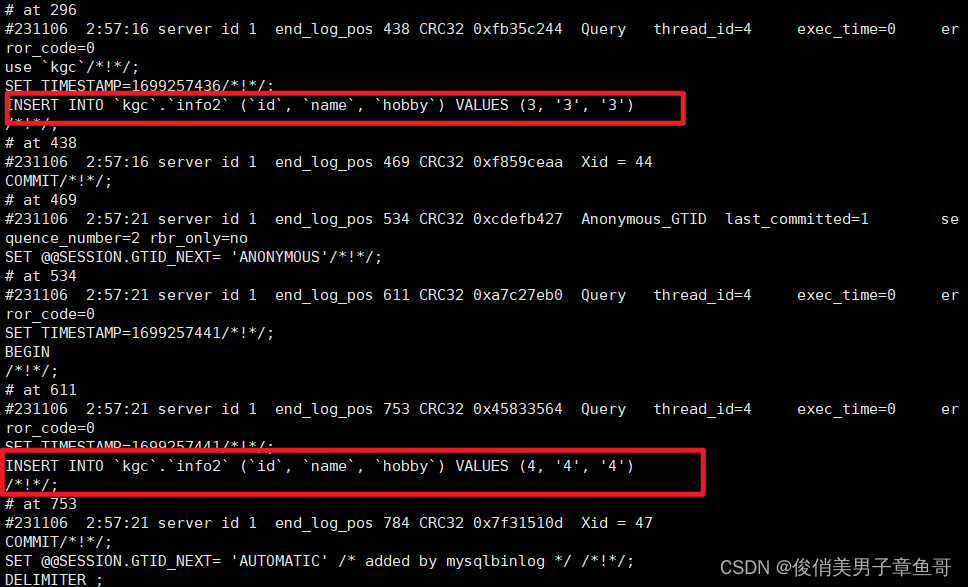
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -cat /out10/*
hello 10
you 10
数据倾斜问题
在实际工作中,如果我们想提高MapReduce的执行效率,最直接的方法是什么呢?
我们知道MapReduce是分为Map阶段和Reduce阶段,其实提高执行效率就是提高这两个阶段的执行效率。默认情况下Map阶段中Map任务的个数是和数据的InputSplit相关的,InputSplit的个数一般是和Block块是有关联的,所以可以认为Map任务的个数和数据的block块个数有关系,针对Map任务的个数我们一般是不需要干预的,除非是前面我们说的海量小文件,那个时候可以考虑把小文件合并成大文件。其他情况是不需要调整的,那就剩下Reduce阶段了,咱们前面说过,默认情况下reduce的个数是1个,所以现在MapReduce任务的压力就集中在Reduce阶段了,如果说数据量比较大的时候,一个reduce任务处理起来肯定是比较慢的,所以我们可以考虑增加reduce任务的个数,这样就可以实现数据分流了,提高计算效率了。但是注意了,如果增加Reduce的个数,那肯定是要对数据进行分区的,分区之后,每一个分区的数据会被一个reduce任务处理。那如何增加分区呢?
我们来看一下代码,进入WordCountJob中,
其实我们可以通过 job.setPartitionerClass 来设置分区类,不过目前我们是没有设置的,那框架中是不是有默认值啊,是有的,我们可以通过 job.getPartitionerClass 方法看到默认情况下会使用 HashPartitioner 这个分区类。那我们来看一下HashPartitioner的实现是什么样子的
/** Partition keys by their {@link Object#hashCode()}. */
@InterfaceAudience.Public
@InterfaceStability.Stable
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
HashPartitioner继承了Partitioner,这里面其实就一个方法, getPartition ,其实map里面每一条数据都会进入这个方法来获取他们所在的分区信息,这里的key就是k2,value就是v2。主要看里面的实现
(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks
其实起决定性的因素就是 numReduceTasks 的值,这个值默认是1,通过 job.getNumReduceTasks() 可知。
所以最终任何值%1 都返回0,那也就意味着他们都在0号分区,也就只有这一个分区。
如果想要多个分区,很简单,只需要把 numReduceTasks 的数目调大即可,这个其实就是reduce任务的数量,那也就意味着,只要redcue任务数量变大了,对应的分区数也就变多了,有多少个分区就会有多少个reduce任务,那我们就不需要单独增加分区的数量了,只需要控制好Redcue任务的数量即可。
增加redcue任务个数在一定场景下是可以提高效率的,但是在一些特殊场景下单纯增加reduce任务个数是无法达到质的提升的。
下面我们来分析一个场景:
假设我们有一个文件,有1000W条数据,这里面的值主要都是数字,1,2,3,4,5,6,7,8,9,10,我们希望统计出来每个数字出现的次数
其实在私底下我们是知道这份数据的大致情况的,这里面这1000w条数据,值为5的数据有910w条左右,剩下的9个数字一共只有90w条,那也就意味着,这份数据中,值为5的数据比较集中,或者说值为5的数据属于倾斜的数据,在这一整份数据中,它占得比重比其他的数据多得多。
下面我们画图来具体分析一下:
假设这1000W条数据的文件有3个block,会产生3个InputSplt,最终会产生3个Map任务,默认情况下只有一个reduce任务,所以所有的数据都会让这一个reduce任务处理,这样这个Reduce压力肯定很大,大量的时间都消耗在了这里
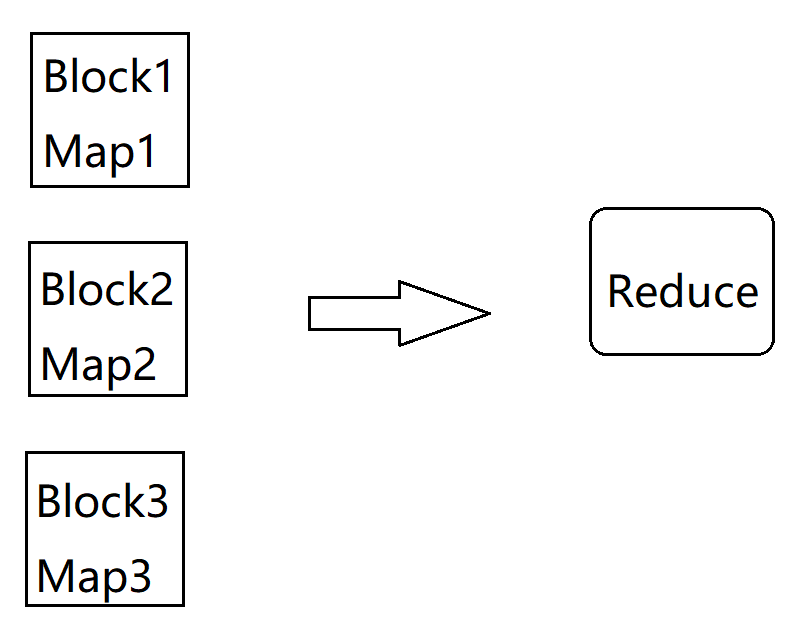
那根据我们前面的分析,我们可以增加reduce任务的数量,看下面这张图,我们把reduce任务的数量调整到10个,这个时候就会把1000w条数据让这10 个reduce任务并行处理了,这个时候效率肯定会有一定的提升,但是最后我们会发现,性能提升是有限的,并没有达到质的提升,那这是为什么呢?
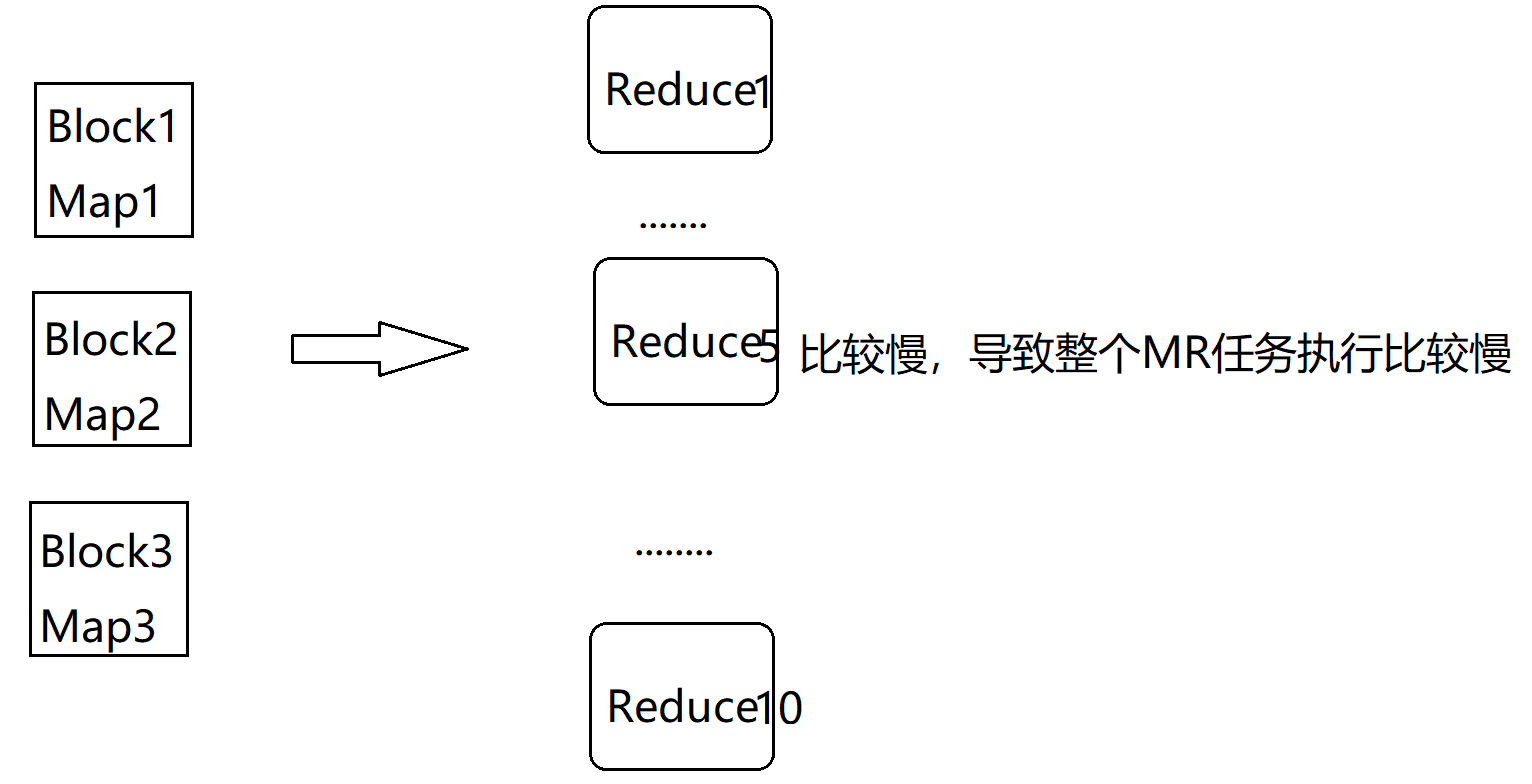
我们来分析一下,刚才我们说了我们这份数据中,值为5的数据有910w条,这就占了整份数据的90%了,那这90%的数据会被一个reduce任务处理,在这里假设是让reduce5处理了,reduce5这个任务执行的是比较慢的,其他reduce任务都执行结束很长时间了,它还没执行结束,因为reduce5中处理的数据量和其他reduce中处理的数据量规模相差太大了,所以最终reduce5拖了后腿。咱们mapreduce任务执行消耗的时间是一直统计到最后一个执行结束的reduce任务,所以就算其他reduce任务早都执行结束了也没有用,整个mapreduce任务是没有执行结束的。
那针对这种情况怎么办?
这个时候单纯的增加reduce任务的个数已经不起多大作用了,如果启动太多可能还会适得其反。其实这个时候最好的办法是把这个值为5的数据尽量打散,把这个倾斜的数据分配到其他reduce任务中去计算,这样才能从根本上解决问题。
这就是我们要分析的一个数据倾斜的问题
MapReduce程序执行时,Reduce节点大部分执行完毕,但是有一个或者几个Reduce节点运行很慢,导致整个程序处理时间变得很长。具体表现为:Ruduce阶段一直卡着不动。根据刚才的分析,有两种方案
- 增加reduce任务个数,这个属于治标不治本,针对倾斜不是太严重的数据是可以解决问题的,针对倾斜严重的数据,这样是解决不了根本问题的
- 把倾斜的数据打散
这种可以根治倾斜严重的数据。
实际案例
还使用我们刚才说的那一份数据,1000w条的,其中值为5的大致有910w条左右。其他的加起来一共90万条左右。
这个数据文件我已经生成好了,直接上传到linux服务器上就可以,上传到/data/soft目录下
[root@bigdata01 soft]# ll
total 2632200
drwxr-xr-x. 9 1001 1002 244 Apr 26 20:34 hadoop-3.2.0
-rw-r--r--. 1 root root 345625475 Jul 19 2019 hadoop-3.2.0.tar.gz
-rw-r--r--. 1 root root 1860100000 Apr 27 21:58 hello_10000000.dat
drwxr-xr-x. 7 10 143 245 Dec 16 2018 jdk1.8
-rw-r--r--. 1 root root 194042837 Apr 6 23:14 jdk-8u202-linux-x64.tar.gz
-rw-r--r--. 1 root root 147616384 Apr 27 16:22 s_name_140.dat
-rw-r--r--. 1 root root 147976384 Apr 27 16:22 s_name_141.dat
这个文件有点大,在windows本地无法打开,在这里我们去一条数据看一下数据格式,前面是一个数字,后面是一行日志,这个数据是我自己造的,我们主要是使用前面的这个数字,后面的内容主要是为了充数的,要不然文件太小,测试不出来效果。后面我们解析数据的时候只获取前面这个数字即可,前面这个数字是1-10之间的数字
[root@bigdata01 soft]# tail -1 hello_10000000.dat
10 INFO main org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: FileO
接下来把这个文件上传到hdfs上
[root@bigdata01 soft]# hdfs dfs -put hello_10000000.dat /
[root@bigdata01 soft]# hdfs dfs -ls /
-rw-r--r-- 2 root supergroup 1860100000 2020-04-27 22:01 /hello_10000000.dat
下面我们来具体跑一个这份数据,首先复制一份WordCountJob的代码,新的类名为 WordCountJobSkew
package com.imooc.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
/**
* 数据倾斜-增加Reduce任务个数
*/
public class WordCountJobSkew {
/**
* Map阶段
*/
public static class MyMapper extends Mapper<LongWritable, Text,Text,LongW
Logger logger = LoggerFactory.getLogger(MyMapper.class);
/**
* 需要实现map函数
* 这个map函数就是可以接收<k1,v1>,产生<k2,v2>
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
//输出k1,v1的值
//System.out.println("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//logger.info("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//k1 代表的是每一行数据的行首偏移量,v1代表的是每一行内容
//对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
//把单词封装成<k2,v2>的形式
Text k2 = new Text(words[0]);
LongWritable v2 = new LongWritable(1L);
//把<k2,v2>写出去
context.write(k2,v2);
}
}
/**
* Reduce阶段
*/
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongW
Logger logger = LoggerFactory.getLogger(MyReducer.class);
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context co
throws IOException, InterruptedException {
//创建一个sum变量,保存v2s的和
long sum = 0L;
//对v2s中的数据进行累加求和
for(LongWritable v2: v2s){
//输出k2,v2的值
//System.out.println("<k2,v2>=<"+k2.toString()+","+v2.get()+"
//logger.info("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
sum += v2.get();
//模拟Reduce的复杂计算消耗的时间
if(sum % 200 ==0){
Thread.sleep(1);
}
}
//组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
//输出k3,v3的值
//System.out.println("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
//logger.info("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
// 把结果写出去
context.write(k3,v3);
}
}
/**
* 组装Job=Map+Reduce
*/
public static void main(String[] args) {
try{
if(args.length!=3){
//如果传递的参数不够,程序直接退出
System.exit(100);
}
//指定Job需要的配置参数
Configuration conf = new Configuration();
//创建一个Job
Job job = Job.getInstance(conf);
//注意了:这一行必须设置,否则在集群中执行的时候是找不到WordCountJob这个
job.setJarByClass(WordCountJobSkew.class);
//指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job,new Path(args[0]));
//指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//指定map相关的代码
job.setMapperClass(MyMapper.class);
//指定k2的类型
job.setMapOutputKeyClass(Text.class);
//指定v2的类型
//指定reduce相关的代码
job.setReducerClass(MyReducer.class);
//指定k3的类型
job.setOutputKeyClass(Text.class);
//指定v3的类型
job.setOutputValueClass(LongWritable.class);
//设置reduce任务个数
job.setNumReduceTasks(Integer.parseInt(args[2]));
//提交job
job.waitForCompletion(true);
}catch(Exception e){
e.printStackTrace();
}
}
}
对项目代码进行重新编译、打包,提交到集群去执行
第一次先使用一个reduce任务执行
只需要在map中把k2的值修改一下就可以了,这样就可以把值为5的数据打散了。编译打包,提交到集群
但是这个时候我们获取到的最终结果是一个半成品,还需要进行一次加工,其实我们前面把这个倾斜的数据打散之后相当于做了一个局部聚合,现在还需要再开发一个mapreduce任务再做一次全局聚合,其实也很简单,获取到上一个map任务的输出,在map端读取到数据之后,对数据先使用空格分割,然后对第一列的数据再使用下划线分割,分割之后总是取第一列,这样就可以把值为5的数据还原出来了,这个时候数据一共就这么十几条,怎么处理都很快了,这个代码就给大家留成作业了,我们刚才已经把详细的过程都分析过了,大家下去之后自己写一下,如果遇到了问题,可以在咱们的问答区一块讨论,或者直接找我都是可以的。这就是针对数据倾斜问题的处理方法,面试的时候经常问到,大家一定要能够把这个思路说明白。