系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 系列文章目录
- 前言
- 一、pandas是什么?
- 二、使用步骤
- 1.引入库
- 2.读入数据
- 总结
前言
今年双11,我们的埋点服务,收到了大量的服务超时告警,通过下面的监控图可以看到:超时量突然大面积增加,埋点接口的QPS达到1万,接口最大的响应时间到达12秒。以下是埋点服务的系统APM 监控信息。

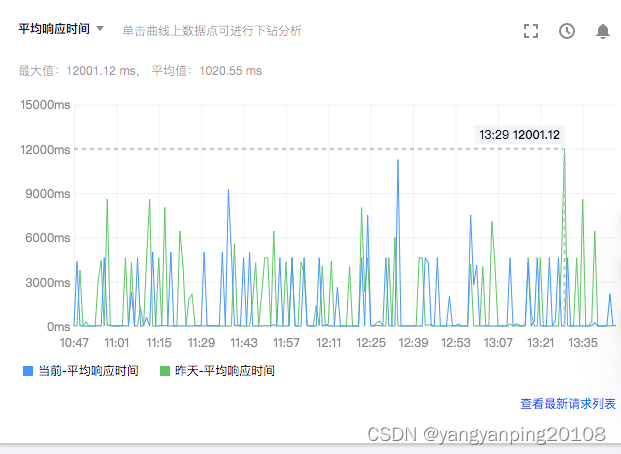
一、检查监控
收到告警后,我们第一时间查看了监控系统,立马发现了YoungGC耗时过长的异常。最长甚至达到了惊人的25秒多,GC次数也达到2K次以上。
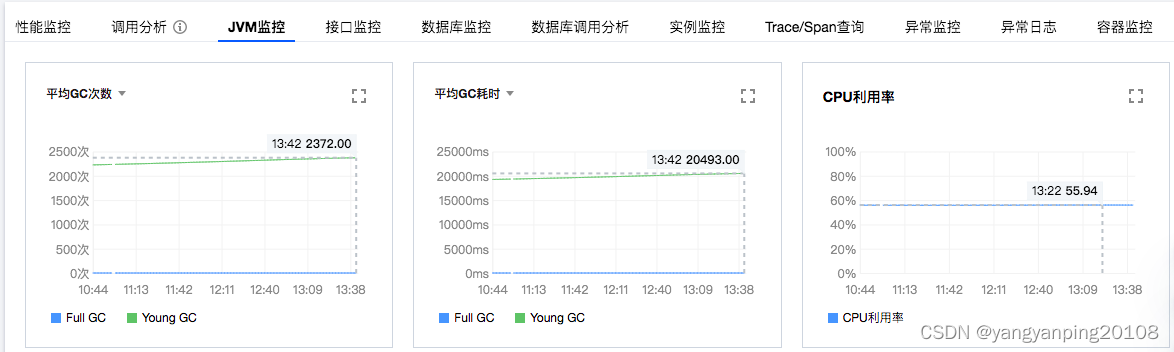
由于YGC期间程序会Stop The World,埋点接口功能巨简单,就是根据事件给各个kafka发送消息。但埋点接口耗时达到了几百毫秒,
二、确认JVM配置
-Xms6144m
-Xmx6144m
-Xmn3072m
-XX:MetaspaceSize=512m
-XX:MaxMetaspaceSize=512m
-XX:CompressedClassSpaceSize=512m
-XX:SurvivorRatio=8
-XX:MaxTenuringThreshold=5
-XX:GCTimeRatio=19
-Xnoclassgc -XX:+DisableExplicitGC
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction=0
-XX:-CMSParallelRemarkEnabled
-XX:CMSInitiatingOccupancyFraction=70
-XX:SoftRefLRUPolicyMSPerMB=0
-XX:+PrintClassHistogram -XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintHeapAtGC
-Xloggc:/opt/logs/gc.log
-Dlog4j2.formatMsgNoLookups=true
可以看到堆内存为6G,新生代和老年代均为3G,新生代采用ParNew收集器,老年代采用UseConcMarkSweepGC收集器。
三、调整JVM配置
-Xms6144m
-Xmx6144m
-Xmn3072m
-XX:MetaspaceSize=512m
-XX:MaxMetaspaceSize=512m
-XX:CompressedClassSpaceSize=512m
-XX:NewRatio=4
-XX:SurvivorRatio=4
-XX:GCTimeRatio=19
-XX:+UseParallelGC
-XX:ParallelGCThreads=4
-XX:+UseParallelOldGC
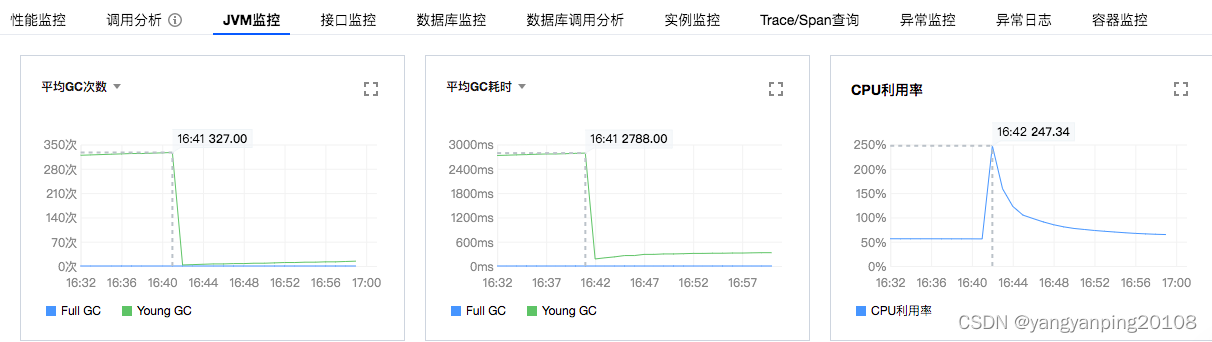
调整JVM参数,新生代采用UseParallelGC收集器,老年代采用UseParallelOldGC收集器。 JVM监控数据如下,发现GC的平均次数和GC平均耗时下降巨大。
- UseParNewGC:并发串行收集器,它是工作在新生代的垃圾收集器,它只是将串行收集器多线程化,除了这个并没有太多创新之处,而且它们共用了相当多的代码。它与串行收集器一样,也是独占式收集器,在收集过程中,应用程序会全部暂停。但它却是许多运行在Server模式下的虚拟机中首选的新生代收集器,其中有一个与性能无关但很重要的原因是,除了Serial收集器外,目前只有它能与CMS收集器配合工作。
- UseParallelGC:并行收集器,同时运行在多个cpu之间,物理上的并行收集器,跟上面的收集器一样也是独占式的,但是它最大化的提高程序吞吐量,同时缩短程序停顿时间,另外它不能与CMS收集器配合工作。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。