编者按:随着人工智能技术的不断发展Transformer架构已经成为了当今最为热门的话题之一。前馈层作为Transformer架构中的重要组成部分,其作用和特点备受关注。本文通过浅显易懂的语言和生活中的例子,帮助读者逐步理解Transformers中的前馈层。
本文是Transformers系列的第三篇。作者的观点是:前馈层在Transformer架构中扮演着至关重要的角色,它能够有效地提高计算效率,同时也是集体智慧的体现。
文章作者首先介绍了前馈层的基本结构,它由全连接层组成,进行线性变换和线性计算。但也存在局限性,不能进行复杂的非线性变换。所以前馈层需要激活函数(如ReLU)进行非线性转换,增强网络的表达能力。为防止模型仅记忆数据特征而不具备推理能力,需要使用正则化技术如dropout。相信通过本文的阅读,读者将对Transformer中的前馈层有更深入的理解。
随着深度学习在语音、图像、自然语言处理等领域取得突破,人工智能或许正向着真正的通用人工智能迈进。但要培养通用人工智能,我们还需不断深入理解其中的原理和相关机制。
以下是译文,enjoy!
作者 | Chen Margalit
https://www.linkedin.com/in/chen-margalit/
编译 | 岳扬
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:https://towardsdatascience.com/simplifying-transformers-state-of-the-art-nlp-using-words-you-understand-part-4-feed-foward-264bfee06d9
本节将介绍前馈层(Feed-Forward layer),这是大多数深度学习架构中的基础元素。在有关深度学习的常见话题交流时,一般都会强调它们在构造 Transformer 架构中的重要作用。
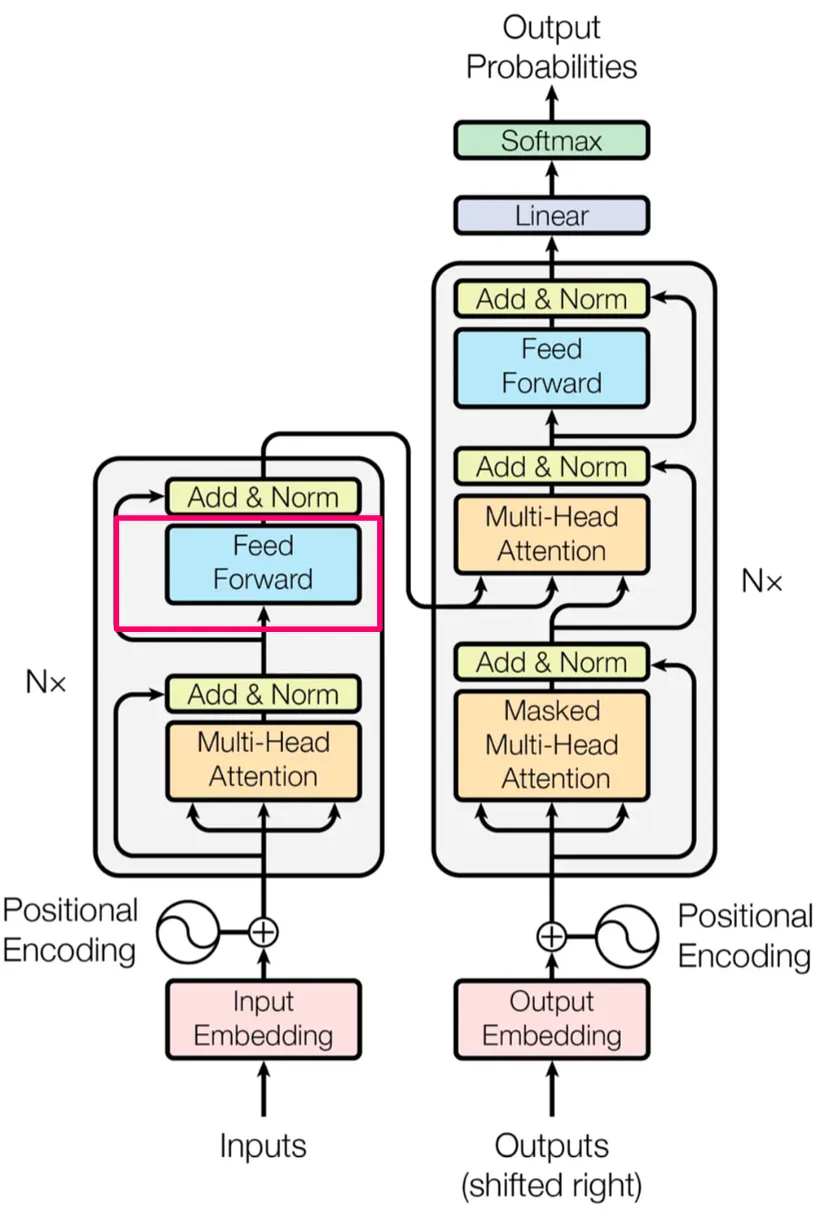
原论文中的图片[1]
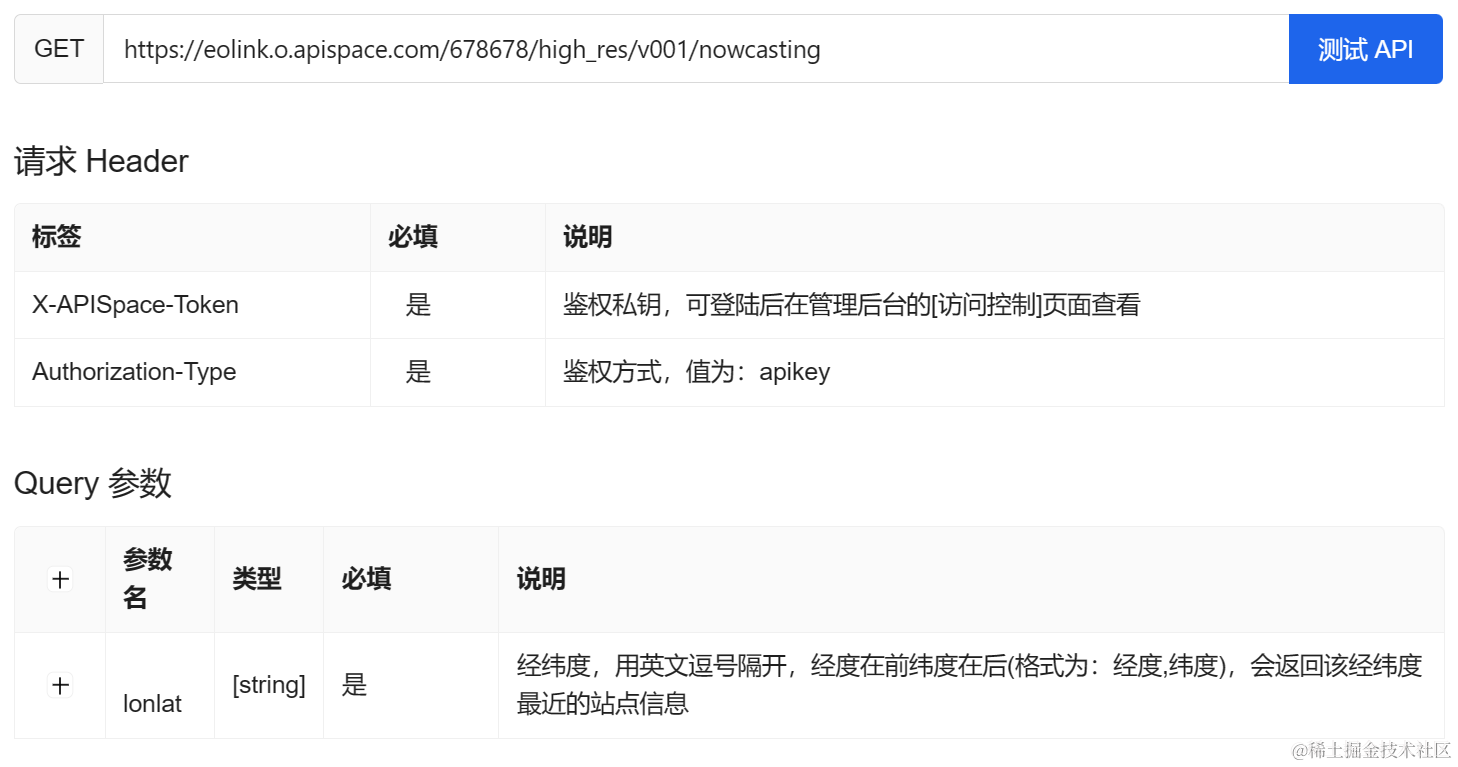
前馈全连接层(feed-forward linear layer)基本上就是一堆神经元,每个神经元都与其他神经元相连接。请看下图,其中a、b、c和d是神经元。这些神经元包含了一些 input(即一些我们想要理解的数据(像素值(pixels)、词嵌入(word embeddings)等))。它们与编号为1的神经元相连。每两个神经元之间的连接都有不同的连接权重值(connection strength)。例如,a-1是0.12,b-1是-0.3,等等。实际上,左列中的所有神经元都与右列中的所有神经元相连。但是为了清晰起见,我没有在图像中展示全部的连接,你需要了解这一情况。就像图中有a-1一样,还应该有a-2、b-2、c-2、d-3等。两个神经元之间的每个连接都有不同的“连接权重”。
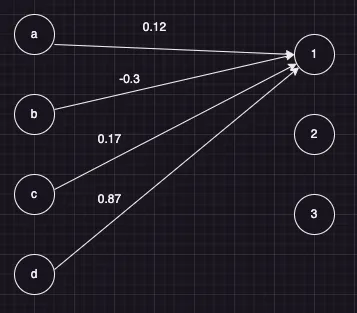
该图由原文作者绘制
该架构有两点值得注意:
- 如前所述,每个节点(神经元)都与其他节点相连。所有的a、b、c、d都与其他神经元(1、2、3)相连。可以将这幅图像看作是一条军队指挥链。1、2、3是指挥官。他们从士兵a、b、c、d那里得到情报。a知道某件事情的一些细节,但它的情报不够全面。1知道的就更多了,因为它能够从a、b、c和d那里同时得到情报。2和3也是指挥官,同样从a、b、c、d那里获取情报。这些指挥官(1、2、3)也会向更高级的指挥官传递报告。在他们之后的指挥官既从a、b、c、d那里得到情报,也从1、2、3那里得到情报,因为下一层(每列神经元为一层)也是以完全相同的方式进行全连接的。因此,首先要明白的是, 1 的情报比 a 更全面,而下一层指挥官的情报也比 1 更全面。
- 第二点需要注意的是,每个节点与下一层的每个其他节点之间的连接权重是不同的。a-1是0.12,b-1是-0.3。我在这里给出的数字显然是虚构的,但它们也是在合理的范围内,并且它们都是自动学习调整的参数(learned parameters)(例如,它们在训练过程中会发生变化)。把这些数字看作是 1 对 a、b 等的影响程度。从1号指挥官的角度来看,a的情报有一定的可信度。但不应该想当然地相信他说的每一句话,可以选择性地相信他说的某些话。b则截然不同。这个节点通常会低估它接收到的输入(情报)的重要性,就像一个悠闲的人一样。“这是一只tiger吗?不,只是一只big cat。” 这是对发生的事情的过度简化,但重要的是要注意这一点:每个神经元都掌握着一些input(无论是原始输入还是经过处理的input)并进行处理后将其传递下去。
你知道“传话游戏”吗?你和其他 10 个人坐成一排,然后你向下一个人耳语一个词,比如说“Pizza”。第 2 个人听成了类似“Pazza”的词,于是他们把“Pazza”传给了第 3 个人。第 3 个人听成了 “Lassa”(毕竟是耳语),于是他把 “Lassa”传给了第 4 个人。第 4 个人听成了 “Batata”,于是他又转述了 “Batata”,以此类推。当你问第 10 个人他听到了什么?结果他回答“Shambala”,我们是怎么从“Pizza”到“Shambala”的?这个游戏与神经网络的区别在于,每个人都会对信息进行处理。第二个人不会说 “Pazza”,他会说“Pazza 是意大利菜,很好吃”。第三个人会说:“Lassa是一道意大利菜,在全世界都很常见”,等等。每个人(层)都会补充一些他们希望有用的东西。
基本情况就是这样。每个神经元获得输入,处理输入,然后继续传递。 为了与全连接层(fully connected layer)相匹配,我建议对这个游戏进行升级:从现在开始,在游戏中引入多行人,每个人都可以对每一行中的其他人说悄悄话。从每一行的第 2 位开始,每个人都会收到很多人的悄悄话,他们需要了解每个人说的话语的“权重”(重要性),这就是前馈层(Feed Forward Layer)。
为什么我们要使用前馈层?因为它们使我们的计算能够更加有效,可以将其类比为集体智慧的体现。 讲一个关于“猜测一头牛重量”的故事吧!1906年,在英国的某个地方,有人把一头牛带到一个展览会上。主持人随机挑选了 787 名观览者,请他们猜测这头牛的重量。你认为他们猜测的结果会是多少?这头牛的实际体重是多少呢?
他们猜测的平均值是 1197 磅(542 公斤)。这些都是随机抽取的群众对牛体重的估计。这个平均猜测值离真实重量相差多远呢?只有1磅差距,也就是450克。这头牛的重量是1198磅。这个故事来自这里[2],我不确定细节是否准确,但回到本文的主题,我们可以把线性层 (译者 注:此处即本文所说的前馈层) 看作是在做类似的事情。通过增加更多的参数、更多的计算(更多的猜测),就可以得到更准确的结果。

照片由 Larry Costales[3] 在 Unsplash[4] 上发布
让我们试着想象一个真实的使用场景。给神经网络输入一张图片,让它判断图片里的是苹果还是橙子。这种架构基于卷积神经网络(CNN)层,本文不会深入讨论这个知识点,因为其超出了本系列文章的范围。但该层是一个能够学习和识别图像中特定模式(specific patterns)的计算层。 (译者注:这些特定模式的识别有助于网络进行更准确的分类和判断,例如判断图像中是苹果还是橙子。) 每一层都能识别更复杂的模式。例如,第一层几乎不能识别出任何东西,该层只是传递原始像素,第二层就能够识别出垂直线条。如果下一层同时接收到有垂直线条的信息,并从其他神经元那里听说还有非常接近的垂直线条。它会将两者综合起来进行计算、分析,然后思考:不错!这是一个角落。这就是从多个来源获取输入信息的好处。
我们可能会认为,进行计算的次数越多,得到的结果就越好。但事实上,并非完全是这样,但确实有一定的道理。如果我们做更多的计算,咨询更多人(神经元)的意见,通常就能得出更好的结果。
01 激活函数 Activation Function
接下来将介绍深度学习中另一个非常重要的基本概念的关键组成部分——激活函数,并探讨它与Transformer的关系,以便更好地理解两者之间的关联。
尽管全连接层(Fully connected layers)的使用非常广泛,但也存在一个很大的缺点——它们是线性层(linear layers),只能进行线性变换和线性计算。全连接层可以进行加法和乘法运算,但无法以“创造性”的方式转换输入(input)。有时候,仅仅增加计算量是不够的,需要以完全不同的思考方式来解决问题。
如果我每天工作10个小时,每天赚10美元,如果我想更快地存下1万美元,我可以每周工作更多天,或者每天工作更多小时。但是肯定还有其他解决方案,对吧?有很多人不需要他们拥有的钱(我可以更好地利用它),或者我可以找到更高薪的工作等等。解决办法并不总是千篇一律。
同理,在本文的情况下,激活函数可以来提供帮助。激活函数能够帮助我们进行非线性变换(non-linear transformation)。例如,将一个数字列表[1, 4, -3, 5.6]转换为概率分布,就是Softmax激活函数的作用。该激活函数能够将这些数字转换为[8.29268754e-03, 1.66563082e-01, 1.51885870e-04, 8.24992345e-01]这样的输出。这5个数字相加等于1。虽然这些数字看起来有些混乱,但 e-03 表示第一个数字(8)在小数点后3个零开始(例如0.00,然后是82926。实际上该数字是0.00829268754)。这个Softmax激活函数将整数转换为0到1之间的浮点数,转换后的浮点数仍然保持了原始整数之间的相对大小关系。这种保持相对大小关系的特性在统计学中非常有用。
还有其他类型的激活函数,其中最常用的之一是ReLU(修正线性单元)。这是一种非常简单(同时也非常有用)的激活函数,它能够将任何负数转化为0,而非负数保持不变。非常简单且实用。如果我将列表[1, -3, 2]输入ReLU函数,会得到[1, 0, 2]。
在介绍完复杂的Softmax之后,你可能会期望一些更复杂的东西,但有人曾经告诉我“Luck is useful”。有了激活函数后,我们就走运了。
我们之所以需要这些激活函数,是因为非线性关系(nonlinear relationship)无法通过线性计算(全连接层)来表示。如果我每工作一小时就能得到 10 美元,那么收入就是线性关系。如果我每连续工作 5 个小时,接下来的 5 个小时就能增加 10%,那么这种关系就不再是线性的了。我的工资不再是工作小时数乘以固定的小时工资。在文本生成等更复杂的任务中使用深度学习,就是因为我们要建模的关系高度非线性。 在“我喜欢”之后能出现的词并不是固定的。
ReLU 的一大优势,也许可以解释它为何被广泛使用,就是对大量数据进行计算的成本非常低。 当神经元数量较少时(比方说几万个),计算量并不重要。但是当像大语言模型那样使用数千亿个神经元时,一种更高效的计算方式会带来巨大差异。
02 正则化 Regularization
在解释Transformer中如何实现正则化(非常简单)之前,我们将介绍最后一个概念——dropout,这是一种正则化技术。由于算法是基于数据的,并且它们的任务是尽可能逼近训练目标,所以对于一个大脑聪明的人来说,有时仅仅记住一点点东西就足够了。正如我们在学校中所受到的教育,学习复杂的逻辑并不总是有用的,我们有时只需记住我们所见过的,或者记住与之接近的东西。第二次世界大战是什么时候发生的?嗯…它受到了第一次世界大战、经济危机、人民愤怒等等因素的影响…大约是1917年左右…所以我们就说是1928年吧。记住确切的日期可能更好。
可以想象,这对机器学习来说并不是好事。如果我们需要的是已经有答案的问题的答案,我们就不需要这些复杂的技术了。我们需要一个聪明的算法,因为我们无法记住所有的东西。我们需要它进行实时推理,进行思考。正则化(Regularization)是让算法仅学习不记忆的一系列技术的总称。在这些正则化技术中,一种常用的技术就是dropout。
03 Dropout
dropout可以说是一种相当简单的技术。还记得我们说过全连接层(fully connected layers)是完全连接的吗?dropout打破了这种逻辑。dropout技术将“连接权重(connection strength)”设置为0,这意味着该连接不会产生任何影响。对于1号指挥官来说,连接到士兵“a”的输入变为 0 时,“a”传递的情报会变得完全无用。不回答,不肯定,也不否定。我们在每一层中使用dropout技术时,会随机选择一定数量的神经元(由开发者配置),并将它们与其他神经元的连接权重设为0。 每次指挥官会被迫忽略不同的士兵,因此无法记住其中任何一个士兵,因为下次可能不会再遇到它们传递情报。
04 回到Transformer!
现在我们已经掌握了理解Transformer中前馈层工作原理所需的所有基础知识。接下来解释实现过程就会非常简单了。It will now be very simple.
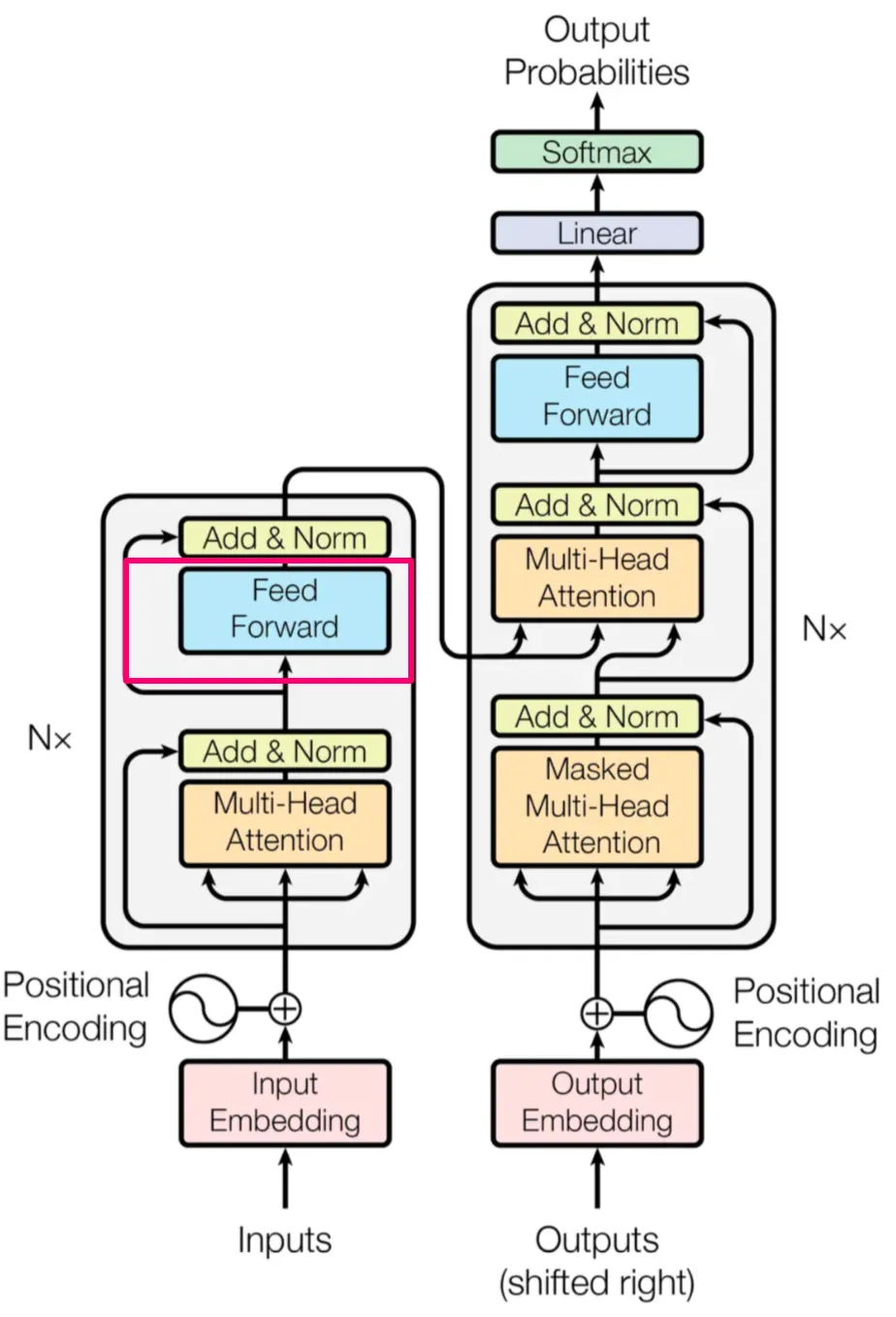
图片来自 Vaswani, A. 等人的论文[5]
在原论文中的架构图中,前馈线性层只做了四件事情:
- 对文本中的每个位置(用向量表示),进行逐位置的线性计算。
- 对线性运算的输出应用ReLU函数。
- 对上一步骤ReLU运算的输出进行再一次线性运算。
- 最后,将其添加到第 3 层的输出中。
就是这样。如果你有深度学习领域的相关经验,那么理解这一部分对你来说可能很容易。如果你没有经验,可能稍显吃力,但你已经理解了深度学习中一个极为重要的组成部分。
在下一部分,我们将介绍Transformer中的解码器(Decoder)部分相关知识!
END
参考资料
[1]https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
[2]https://www.wondriumdaily.com/the-wisdom-of-crowds/#:~:text=An%20Astonishing%20Example%20of%20the%20Wisdom%20of%20Crowds&text=The%20actual%20weight%20of%20the,that%20weight%20was%201%2C197%20pounds.
[3]https://unsplash.com/@larry3?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
[4]https://unsplash.com/photos/Ahf1ZmcKzgE?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
[5]https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf




![[机缘参悟-118] :如何做到:从无到有,从0到1设计一个新系统或产品?如何做到总是能快速的解决复杂技术难题?](https://img-blog.csdnimg.cn/91dfe26d385a4df3b709dc352c15c7f2.png)